

































 Математика
Математика Биология
БиологияПохожие презентации:






")



Биостатистика. Сравнение выборок
1.
Биостатистика4. Сравнение выборок
Рубанович А.В.
Институт общей генетики им. Н.И. Вавилова РАН
2.
Сравнение среднихСамая первая и основная задача - сравнение средних для двух выборок.
Например, рост в выборках «М» и «Ж»:
Кроме таблицы надо посмотреть
все иллюстрации различий:
Plot of Means and Conf. Intervals (95,00%)
Рост
180
Categ. Box & Whisker Plot: Рост
175
200
170
180
Values
165
Histogram: Рост
Пол: M Рост = 34*10*normal(x; 167,6657; 19,3972)
Пол: Ж Рост = 66*10*normal(x; 148,7613; 16,5892)
160
160
22
20
Рост
155
150
18
140
16
14
145
120
No of obs
12
140
M
Ж
Пол
100
Рост
10
8
6
80
M
Ж
Пол
Median
25%-75%
Min-Max
4
2
0
90
110
100
130
120
150
140
170
160
190
180
210
200
90
110
100
Пол: M
130
120
150
140
170
160
190
180
210
200
Пол: Ж
Рост
Нулевая гипотеза состоит в предположении, что обе выборки изъяты из одной
генеральной совокупности (т.е. различий нет): Н0: x1 x 2
Н1: x1 x 2 (двусторонний тест)
Дальше надо предложить способ оценить вероятность ошибки I рода
3.
Сравнение среднихНа прошлом занятии мы рассмотрели достаточно универсальный способ
построения статистических критериев: Z – статистика, т.е. Z /
x1 x 2
, т.е. разность средних, деленная
Z
x1 x 2
на стандартное отклонение этой разности.
Есть надежда, что эта величина имеет нормальное распределение со средним 0
и дисперсией 1. Так оно и есть, но только при больших объемах выборок!
x1 x 2
Для не очень больших выборок распределение величины t
x1 x 2
следует распределению Стьюдента.
Это распределение случайной величины, равной
t
0
, где все i - нормальны
1 2
( 1 22 ... k2 )
k
k – число степеней свободы
Вильям Стьюдент (Госсет) (1876-1936)
Работал на пивоваренном заводе Гиннесса
Опубликовал «распределение Стьюдента» в 1908 г.
4.
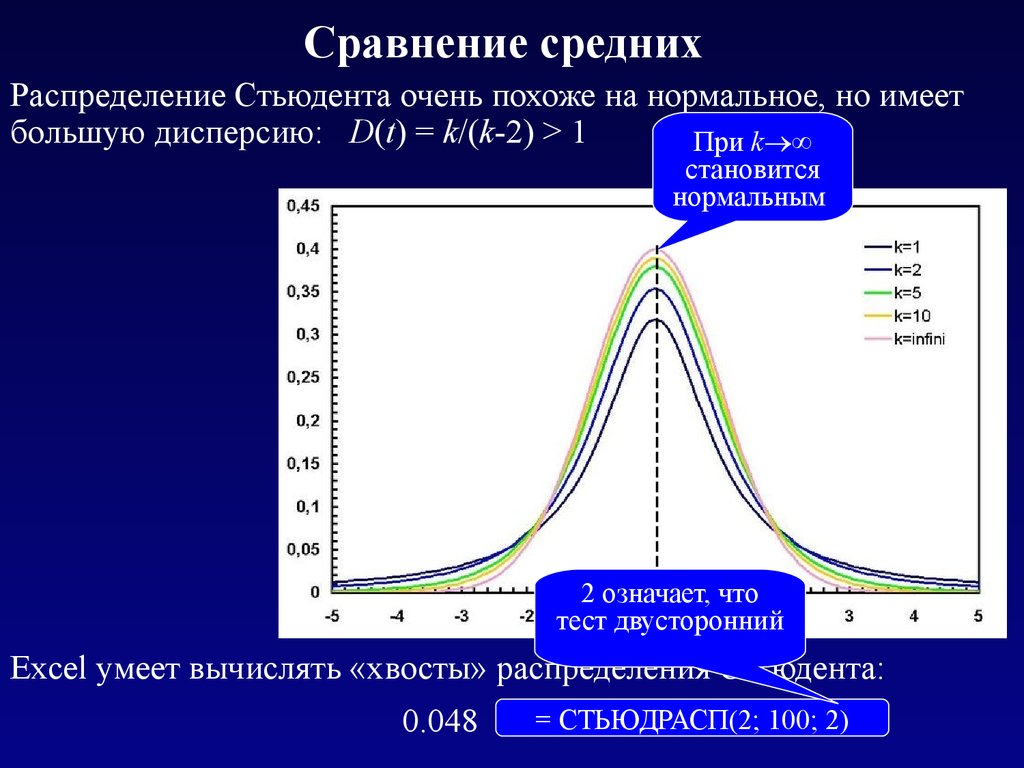
Сравнение среднихРаспределение Стьюдента очень похоже на нормальное, но имеет
большую дисперсию: D(t) = k/(k-2) > 1
При k ∞
становится
нормальным
2 означает, что
тест двусторонний
Excel умеет вычислять «хвосты» распределения Стьюдента:
0.048
= СТЬЮДРАСП(2; 100; 2)
5.
Сравнение средних3 варианта использования теста Стьюдента:
Сравнение выборочного среднего с известным числом
Сравнение двух зависимых выборок
Для каждой особи проводят 2 однотипных замера:
- до и после приема лекарства,
- в этом году и в прошлом году и т.д.
Сравнение двух выборочных средних для независимых
выборок
6.
Упражняемся …15 октября 2011 г. президент Д. Медведев сообщил, что средняя
продолжительность жизни в РФ составляет
69означает,
лет
Эта запись
что
наша величина имеет
распределение
Стьюдента
В этом месяце в районном морге побывало
100 клиентов,
и получена другая
с
n-1
степенями
свободы
оценка: 62 3 года. Отличается ли эта оценка от средней по стране?
2 означает, что
x
x тест двусторонний
x
~ t ( n 1)
Вычисляем величину
x
SE
/ n
Р = 0.022 = СТЬЮДРАСП((69-62)/3; 100-1; 2)
Вывод: нулевая гипотеза отвергается. Вероятность того, что при этом отвергли
правильную нулевую гипотезу равна 0.022 (ошибка I рода). Выборка по данным
районного морга не соответствует среднему по стране.
Различия статистически значимы.
Никогда не пишите, что различия достоверны!
Достоверно это то, что происходит с вероятностью 1
В данном примере среднее для одной выборки сравнивалось с заранее
известной величиной. Это так называемый одновыборочный тест
(мы это уже делали: помните 470 из 1000?)
7.
Сравнение среднихв случае зависимых выборок
Это простой случай. Вычисляется t-статистика
t
x1 x 2
x1 x 2
x1 x 2
SE12 SE22
и вес хвостов распределения Стьюдента с n1+n2-2 степенями свободы.
Можно ни о чем этом не думать
и использовать
=ТТЕСТ(массив1; массив2; 2; 1)
2 означает, что
тест двусторонний
1 означает, что
выборки
зависимы
Для независимых выборок все несколько сложнее…
8.
Сравнение среднихв случае независимых выборок
При сравнении средних двух независимых выборок возможны 2 ситуации:
1 = 2 , т.е. изменчивость данных в обеих выборках одинакова
x1 x 2
t
~ t (n1 n2 2)
Тогда все просто: вычисляется статистика
2
2
SE1 SE2
1 ≠ 2 , т.е. изменчивость данных в выборках неодинакова, и эти различия
статистически значимы. Тогда вычисляется объединенная дисперсия для двух
выборок. Число степеней свободы тоже модифицируется.
В Excel это делается так:
=ТТЕСТ(массив1; массив2; 2; 2)
2 означает, что
тест двусторонний
2 - 1 = 2
3 - 1 ≠ 2
Excel при этом не проверяет статистическую значимость 1 ≠ 2 .
Более адекватно в STATISTICA:
9.
Сравнение среднихc помощью программы STATISTICA
Случай равных дисперсий
Дисперсии
выборок значимо
не различаются
10.
Сравнение среднихc помощью программы STATISTICA
Случай неравных дисперсий
Дисперсии
выборок значимо
различаются
11.
Сравнение дисперсийР. Фишер построил критерий (односторонний) для сравнения
дисперсий (F-тест) и вычислил функцию распределения
соответствующей статистики.
22
F 2
1
(большая на меньшую),
F- распределение имеет 2 параметра:
df1 = n1-1, df2 = n2-1
В Excel имеется функция,
вычисляющая это распределение
Можно также сравнить
дисперсии двух выборок
Н0: 1 = 2 против Н1: 1 < 2
=FРАСП(1,5;100;100)
= 0.022
=ФТЕСТ(массив1; массив2)
Не путайте статистику (критерий) Фишера с точным тестом Фишера!
12.
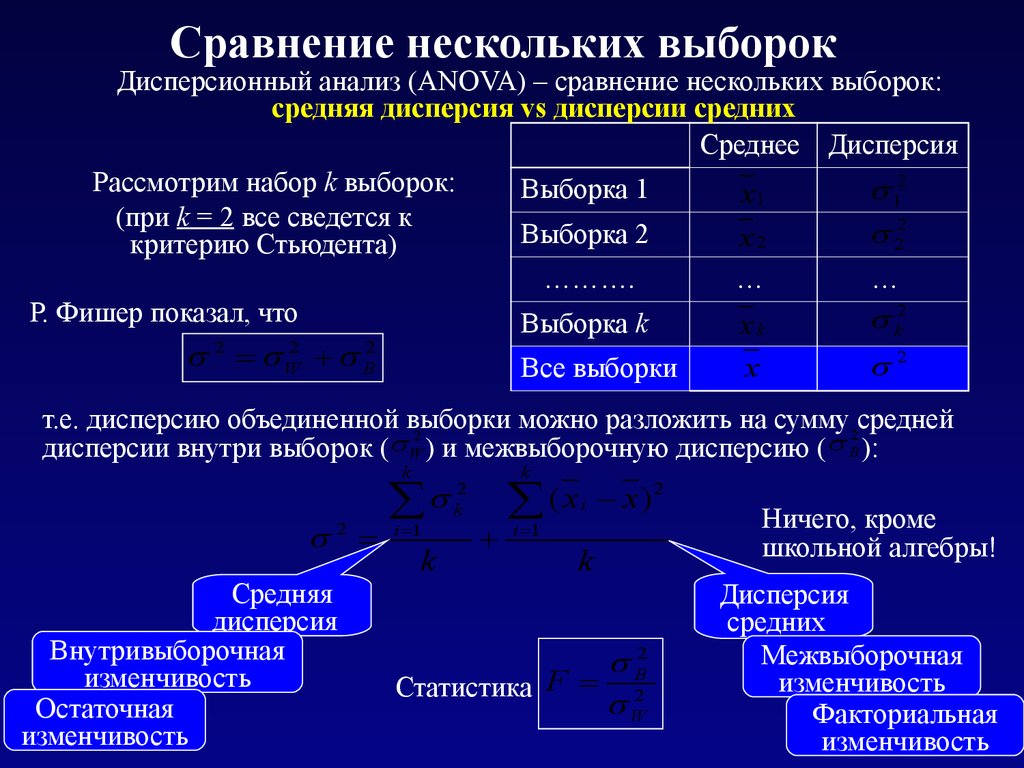
Сравнение нескольких выборокДисперсионный анализ (ANOVA) – сравнение нескольких выборок:
средняя дисперсия vs дисперсии средних
Среднее Дисперсия
Рассмотрим набор k выборок:
Выборка 1
12
x1
(при k = 2 все сведется к
2
Выборка
2
x
2
2
критерию Стьюдента)
……….
…
…
Р. Фишер показал, что
2
Выборка k
xk
2
2
W
k
2
B
Все выборки
x
2
т.е. дисперсию объединенной выборки
можно разложить на сумму2средней
2
дисперсии внутри выборок ( W ) и межвыборочную дисперсию ( B ):
k
2
Средняя
дисперсия
Внутривыборочная
изменчивость
Остаточная
изменчивость
i 1
k
2
k
k
2
(
x
x
)
i
i 1
k
B2
Статистика F 2
W
Ничего, кроме
школьной алгебры!
Дисперсия
средних
Межвыборочная
изменчивость
Факториальная
изменчивость
13.
Сравнение нескольких выборокДисперсионный анализ (ANOVA) – сравнение нескольких выборок:
средняя дисперсия vs дисперсии средних
Даты
Объемы
выборок
равны n
Среднее Дисперсия
Выборка 1
x1 j
x1
Выборка 2
x2 j
……….
…
xkj
x2
…
Выборка k
12
22
…
k2
xk
xij
2
Все выборки
x 2
( xij x i )( x i x ) xij x i x xij x i x x i
i , j даты в i-ой
i, j
Номер
i - номер выборки,
выборке, j =21, 2, ... ,
2
i = 1, … , k
n x i n x x i n nx i n x x i
i, j
i, j
i, j
i
Могучий прием:
x
ij
x
xij x
i, j
2
2
i
i
xij x ( xij x i ) ( x i x )
i
( xij x i ) 2 ( x i x ) 2 2( xij x i )( x i x )
( xij x i ) 2 ( x i x ) 2 2 ( xij x i )( x i x )
i, j
i, j
i, j
14.
Сравнение нескольких выборокДисперсионный анализ (ANOVA) – сравнение нескольких выборок:
средняя дисперсия vs дисперсии средних
Даты
Объемы
выборок
равны n
Среднее Дисперсия
Выборка 1
x1 j
x1
Выборка 2
x2 j
……….
…
xkj
x2
…
Выборка k
xij
Все выборки
ij
…
xk
k2
x
2
Номер даты в i-ой
выборке, j = 1, 2, ... ,
n
i - номер выборки,
i = 1, … , k
x
12
22
xij x ( xij x i ) ( x i x )
( x x ) ( x x) 2( x x )( x x)
x x ( x x ) ( x x)
x
2
2
ij
2
i
i
ij
2
i, j
ij
2
i, j
ij
i
i
i
2
i, j
i
SST
SSW
SS B
Total
Within
Between
- обозначения Фишера
15.
Сравнение нескольких выборокДисперсионный анализ (ANOVA) – сравнение нескольких выборок:
средняя дисперсия vs дисперсии средних
SST SSW SS B
или, как часто пишут:
SS SS Err SS Factor
Табличка Фишера:
Source of
Variation
Degrees of
Freedom
Sum of
Squares
Mean Square
F
Between
Groups
k-1
SSB
MSB = SSB./(k-1)
MSB / MSW
Within
Groups
n-k
SSW
MSW = SSW./(n-k)
Total
n-1
SSТ
Статистика F
MS B
(число степеней свободы k-1, n-k)
MSW
Н0: x1 x 2 ... x k vs Н1: хотя бы одно среднее отличается
F-статистика не дает указаний на то, в какой выборке среднее больше!
Это одновременное сравнение совокупности выборок.
«Разборки» со средними называются Post Hoc Tests
16.
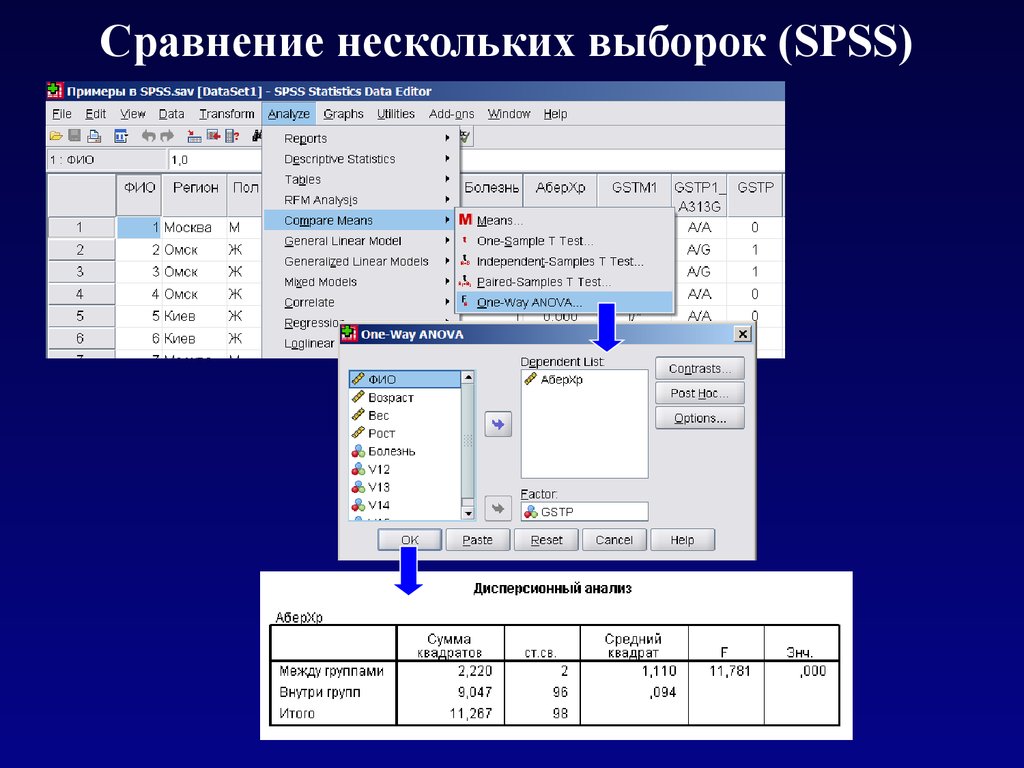
Сравнение нескольких выборок (SPSS)17.
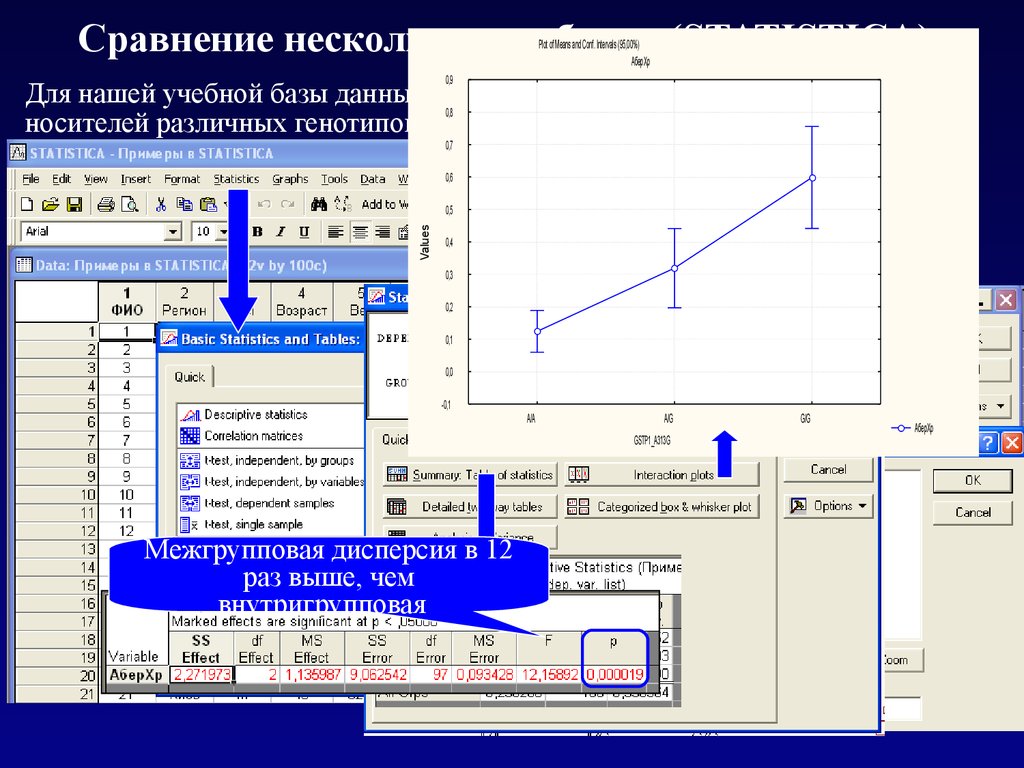
Сравнение нескольких выборок (STATISTICA)Plot of Means and Conf. Intervals (95,00%)
АберХр
0,9
Для нашей учебной базы данных сравним
частоты аберраций хромосом для
0,8
носителей различных генотипов по локусу GSTP1
0,7
0,6
Values
0,5
0,4
0,3
0,2
0,1
0,0
-0,1
A/A
A/G
GSTP1_A313G
Межгрупповая дисперсия в 12
раз выше, чем
внутригрупповая
G/G
АберХр
18.
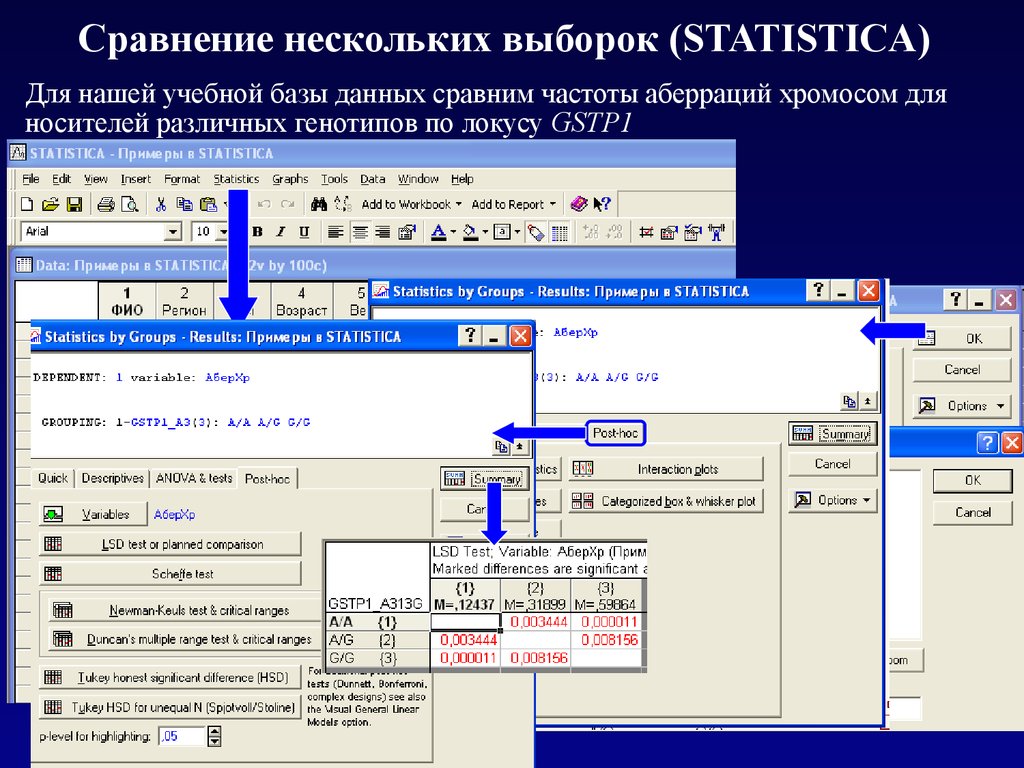
Сравнение нескольких выборок (STATISTICA)Для нашей учебной базы данных сравним частоты аберраций хромосом для
носителей различных генотипов по локусу GSTP1
19.
Важное предупреждениеt-тест (Стьюдента)
F-тест (Фишера)
Дисперсионный анализ
только для нормально распределенных данных!
(особенно при небольших выборках)
В противном случае можно получить совершенно абсурдный результат:
Средние
Фирма 1
Фирма 2
100
120
100
120
100
120
100
120
110
120
110
500
103.3
183.3
В какой фирме зарплата выше?
=ТТЕСТ(массив1; массив2; 2; 3)
Р = 0.235
Эти средние значимо не различаются
по тесту Стьюдента!
Вспомните «мажорирующие выборки»:
6! 6!
p 2
0.0022
12!
На этом примере видно, что в ряде случаев надо сравнивать не сами данные,
а их порядковые ранги (номера в последовательности)
20.
Ранговые статистикиДанные
Средние
Ранги
Фирма 1
Фирма 2
Фирма 1
Фирма 2
100
120
1
7
100
120
2
8
100
120
3
9
100
120
4
10
110
120
5
11
110
500
6
12
103.3
183.3
3.5
9.5
0.0002 =ТТЕСТ(массив1; массив2; 2; 2)
Другое дело! Хотя и это некорректно…
21.
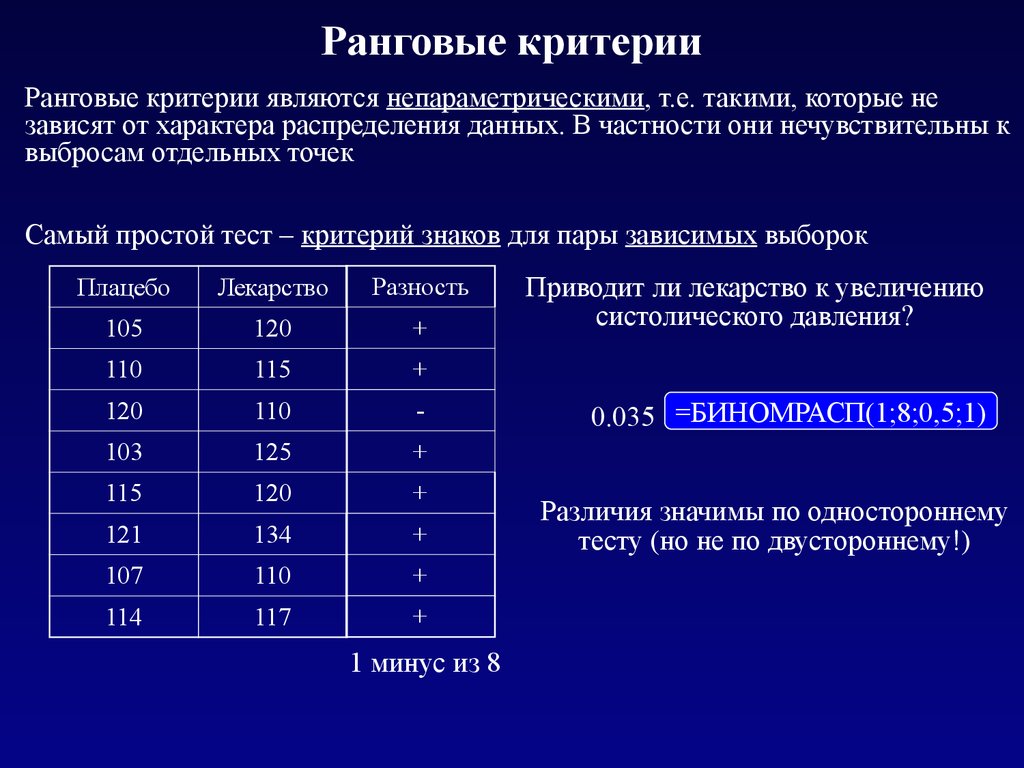
Ранговые критерииРанговые критерии являются непараметрическими, т.е. такими, которые не
зависят от характера распределения данных. В частности они нечувствительны к
выбросам отдельных точек
Самый простой тест – критерий знаков для пары зависимых выборок
Плацебо
Лекарство
Разность
105
120
+
110
115
+
120
110
-
103
125
+
115
120
+
121
134
+
107
110
+
114
117
+
1 минус из 8
Приводит ли лекарство к увеличению
систолического давления?
0.035 =БИНОМРАСП(1;8;0,5;1)
Различия значимы по одностороннему
тесту (но не по двустороннему!)
22.
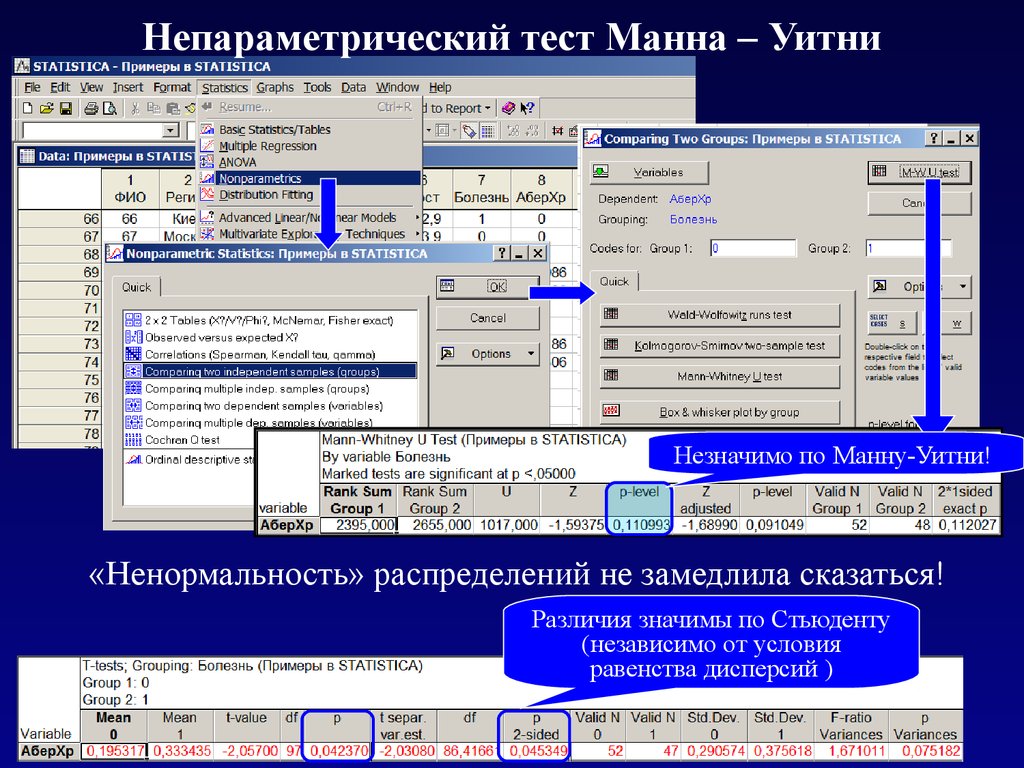
Ранговые критерииДля сравнения 2 независимых выборок используется тест Манна – Уитни,
который основан на вычислении суммы рангов для каждой из выборок
Как всегда Н0: выборки взяты из одной генеральной совокупности.
Но что там с нормальностью?
Упражняемся …
Box & Whisker Plot: АберХр
В нашем файле смотрим сопряженность заболевания с частотой аберраций
Видим различия средних:
0,50
0,45
0,40
АберХр
0,35
0,30
0,25
0,20
0,15
0,10
0
1
Болезнь
Mean
±SE
±1,96*SE
Различия значимы по Стьюденту
(независимо от условия
Проверяем значимость различий по Стьюденту:
равенства дисперсий )
23.
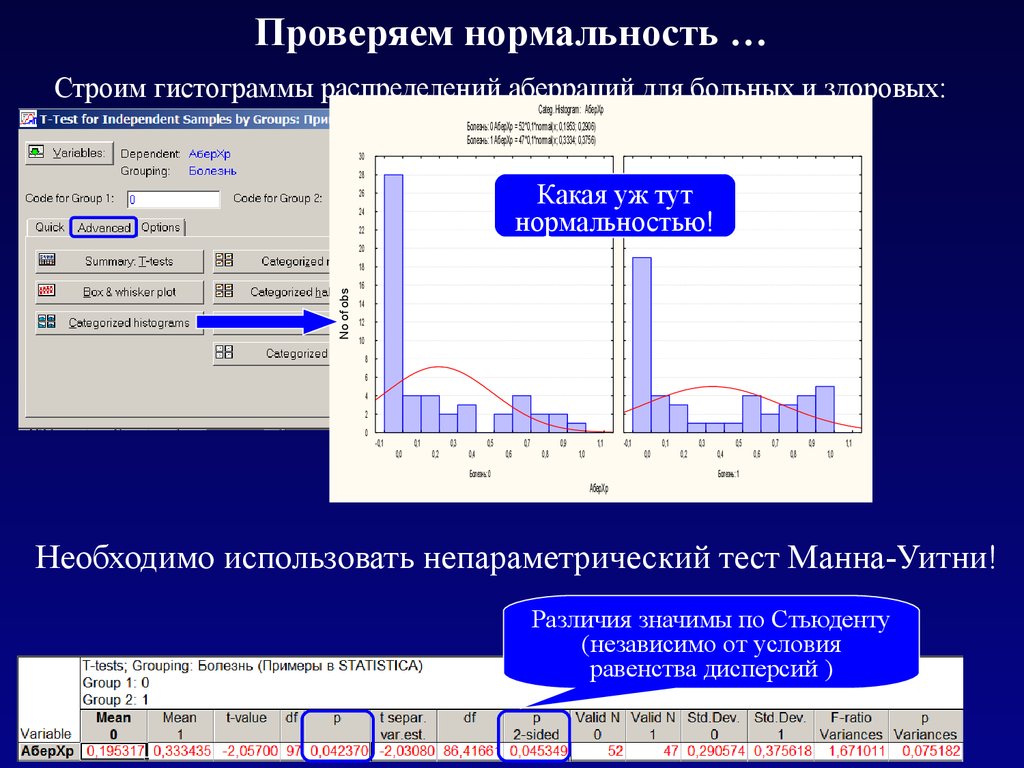
Проверяем нормальность …Строим гистограммы распределений аберраций для больных и здоровых:
Categ. Histogram: АберХр
Болезнь: 0 АберХр = 52*0,1*normal(x; 0,1953; 0,2906)
Болезнь: 1 АберХр = 47*0,1*normal(x; 0,3334; 0,3756)
30
28
Какая уж тут
нормальностью!
26
24
22
20
No of obs
18
16
14
12
10
8
6
4
2
0
-0,1
0,1
0,0
0,3
0,2
0,5
0,4
0,7
0,6
0,9
0,8
1,1
1,0
-0,1
0,1
0,0
Болезнь: 0
0,3
0,2
0,5
0,4
0,7
0,6
0,9
0,8
1,1
1,0
Болезнь: 1
АберХр
Необходимо использовать непараметрический тест Манна-Уитни!
Различия значимы по Стьюденту
(независимо от условия
равенства дисперсий )
24.
Непараметрический тест Манна – УитниНезначимо по Манну-Уитни!
«Ненормальность» распределений не замедлила сказаться!
Различия значимы по Стьюденту
(независимо от условия
равенства дисперсий )
25.
Тест Крускала - УоллисаПараметрически
Непараметрически
1 выборка
Тест Стьюдента
Тест Манна-Уитни
n выборок
Дисперсионный анализ (ANOVA)
Тест Крускала-Уоллиса
Для непараметрических тестов характерна пониженная мощность,
но они безопаснее в смысле ошибки I рода
26.
Что значит «незначимо»?Допустим мы не обнаружили статистическую значимость различий,
о чем с грустью сообщаем в публикации. Достаточно ли этого?
НЕТ! Мы должны продемонстрировать, что объемы наших выборок
достаточны, чтобы обнаружить эффект, если он существует.
Мощность (чувствительность) используемых тестов должна быть
не ниже 80% (тогда упускаем не более 20% открытий)
Только в этом случае незначимые различия можно рассматривать
как отрицательный результат
27.
Что значит «незначимо»?Допустим, что для 2 выборок имеем:
n
Выборка 1
100
x
10
Выборка 1
100
12
SE
SD
1
10
1
10
Тогда по тесту Стьюдента различия незначимы и Р = 0.159
Compare2/ Numerical observations/ Normal distributin/mean value
Проверим мощность данного теста
Compare2/ Power/ Comparison of means
Size A - 100 Size B – 100
DETECT a difference 2
Мощность всего 29%
т.е. доля упущенных открытий более 70% !
О чем мы обязаны сообщить в публикации (правда биологи этого почти никогда
не делают)
Чтобы выйти на мощность 80% объемы выборок должны быть 400 и 400
Compare2/ Sample size/ Means
!
28.
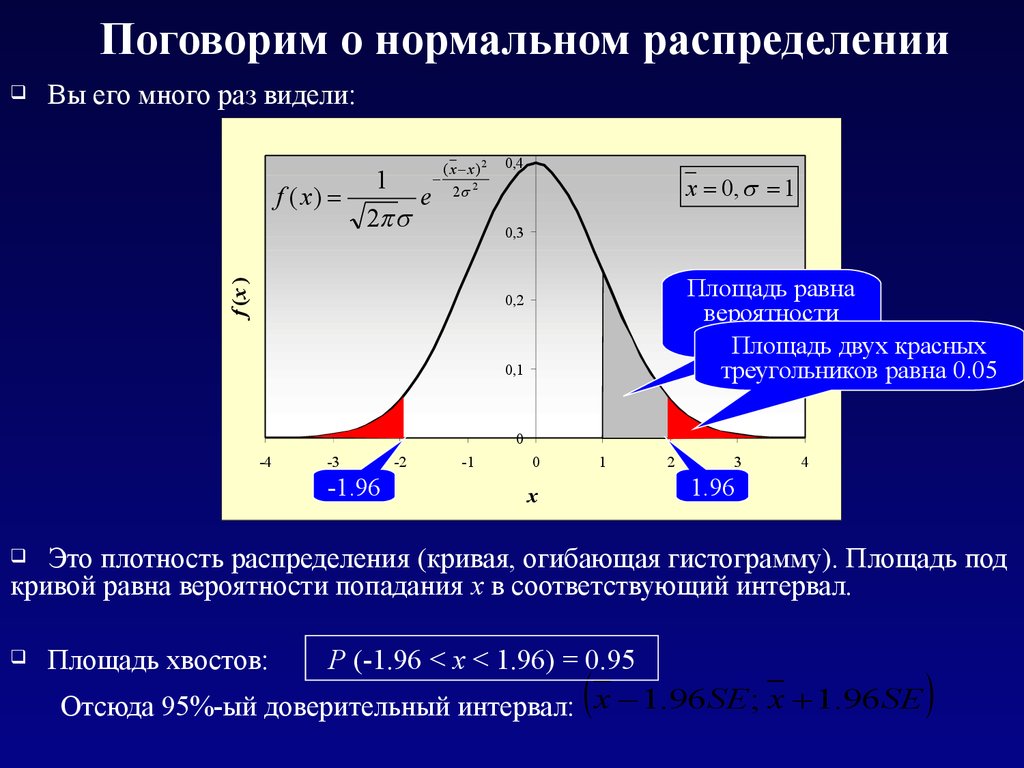
Поговорим о нормальном распределенииВы его много раз видели:
1
e
2
( x x)2
2 2
0,4
x 0, 1
0,3
f (x )
f ( x)
Площадь равна
вероятности
1Площадь
< x < 2 двух красных
треугольников равна 0.05
0,2
0,1
0
-4
-3
-1.96
-2
-1
0
1
2
3
4
1.96
x
Это плотность распределения (кривая, огибающая гистограмму). Площадь под
кривой равна вероятности попадания x в соответствующий интервал.
Площадь хвостов:
Р (-1.96 < x < 1.96) = 0.95
Отсюда 95%-ый доверительный интервал: x 1.96 SE ; x 1.96 SE
29.
Почему нормальное распределениевстречается на каждом шагу?
Нормальное распределение имеет любая величина, которая определяется
суммой большого числа случайных слагаемых (ЦПТ).
Чем больше слагаемых – тем «нормальней»!
Например, биномиальный закон – это вероятность суммарного числа
независимых событий в N испытаниях. Поэтому, если N велико, биномиальное
распределение становится нормальным.
Проверяем ... К 20 годам 80% молодых людей курит. Какова вероятность, что
среди 100 окажется 15 некурящих?
С помощью биномиального распределения: = ЧИСЛКОМБ(100;15)*0,2^15*0,8^85
или
Р(15) = 0.048
= БИНОМРАСП(15; 100; 0,2; 0)
= НОРМРАСПР(15;20;4;0)
С помощью нормального распределения:
Среднее число некурящих Np =100 0.2=20,
дисперсия равна Np(1-p) = 100 0.2(1-0.2) = 16, = 4.
Р(15) = 0.046
30.
Пока мы говорили о сравненияхколичественных признаков
При этом:
Мы припомнили, что такое тест Стьюдента и каких случаях его
можно использовать
Познакомились с дисперсионным анализом – методом
одновременного сравнения нескольких выборок
Узнали, как обрабатывать данные, распределение которых
существенно «ненормально»
Поговорили о том, как следует осмысливать и преподносить
незначимые результаты
31.
Качественные признакиБудет правильно, если вы скажите – мы этим уже занимались! Сравнение частот,
таблицы 2х2, точный тест Фишера и все такое.
Но то было сравнение 2 частот. А как сравнивать несколько пар частот?
Например, распределения генотипов при различных вариантах скрещиваний –
наблюдаемые и ожидаемые исходя из законов Менделя?
Или как сравнить в целом видовой состав в двух регионах? Или частоты
встречаемости блондинов, брюнетов, шатенов и т.д. для 2 этносов
Во всех этих случаях речь идет либо о сравнении двух выборочных дискретных
распределений, либо о сравнении наблюдаемого распределения с теоретически
ожидаемым
Для решении этих задач разработаны тесты, называемые критериями согласия
32.
Критерий 2Соответствие наблюдаемых численностей ожидаемым частотам
Класс
Наблюдаемая
численность
Ожидаемая
численность
1
n1
p1 N
2
n2
p2 N
…
…
…
k
nk
pk N
Всего N
N
Вычисляется сумма
2
(
Н
О
)
2
О
2
(
n
p
N
)
2
i
i
т.е.
pi N
i 1
k
В 1900 г. Карл (Charles) Пирсон вычислил распределение этой величины:
Оказалось, что 2 распределен как сумма
2
2
2
2
...
~
1
2
k
1
квадратов независимых случайных величин:
где все i - нормальны
k -1– число степеней свободы
Если величина 2 достаточно велика, то гипотеза о совпадении
наблюдаемых и ожидаемых численностях отвергается.
Насколько велика скажет Excel:
0.05 =ХИ2РАСП(3.84;1)
33.
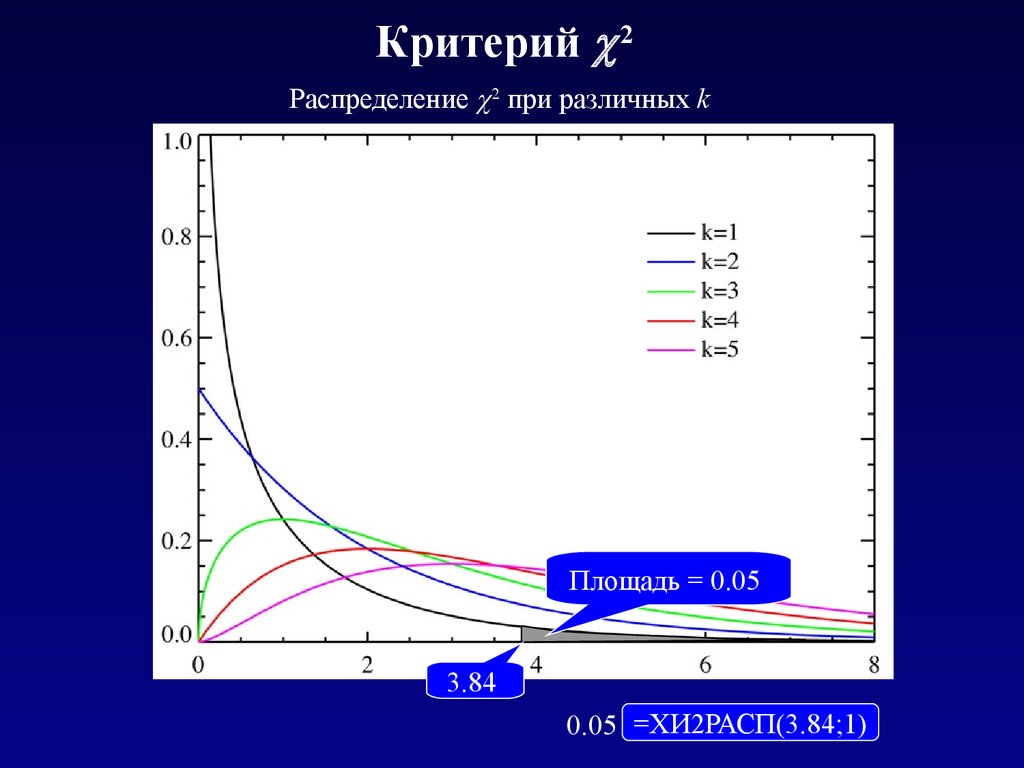
Критерий 2Распределение 2 при различных k
Площадь = 0.05
3.84
0.05 =ХИ2РАСП(3.84;1)
34.
Упражняемся …В выборке 100 человек имеем 44 мужчины и 56 женщин. Есть ли
значимое отклонение от 1:1 ?
2
2
(
44
50
)
(
56
50
)
2
1.44
Вычисляем величину
50
50
0.23 =ХИ2РАСП(1.44;1)
Вывод: нулевая гипотеза не отвергается. Мужчины и женщины представлены в
этой выборке в соотношении 1:1. Вероятность наблюдать такие и еще более
сильные отклонения равна 0.23
Подобное мы уже считали : 0.135 =БИНОМРАСП(44;100;0,5;1)
Соответствие распределению Харди–Вайнберга – не обходится без 2
35.
Соответствие распределениюХарди - Вайнберга
Как правило для популяционных частот генотипов АА, аА, аа
соблюдается соотношение Харди–Вайнберга (а2также
и 2многих других).
pq Кастла
2 p 2q
Закон настолько прост, что его открывали для себя многие, но стеснялись
публиковать.
Я запишу это соотношение в виде:
PaA 2 Paa PAA
и то же самое для численностей:
naA 2 naa n AA
Т.е. не бывает: [100, 100, 100] , а лишь, например, [50, 100, 50]
Класс
Наблюдаемая
численность
Ожидаемая
частота
АА
nАА
р2
аА
nаА
2pq
аа
nаа
q2
Всего
N
1
где
p
1
1
naa naA
n Aa
2
2
q
,
N
N
p q 1
n AA
36.
Упражняемся …Для учебного файла определим частоты генотипов по локусу GSTP1
37.
Упражняемся …Важное условиеприменимости 2 :
Для учебного файла определим частоты генотипов
локусу GSTP1
всепо
ожидаемые
>5
(Н-О)2/О
Класс
Наблюдаемая
численность
Ожидаемая
численность
АА
47
0.68 100 = 46.24
аА
42
2 0.68 0.32 = 43.52
аа
11
0.322 100 = 10.24
0. 1220
100
0.727 =ХИ2РАСП(0,122; 1)
Всего
100
1
p 47 42 / 100 0.68
2
1
q 11 42 / 100 0.32
2
2
0.0125
0.0531
0.0564
Число степеней свободы 1,
а не 2. Это потому, что мы
вычисляли ожидаемые
Вывод: нулевая гипотеза не отвергается. Частотычерез
генотипов
соответствует
наблюдаемые
распределению Харди-Вайнберга. Вероятность наблюдать такие и еще более
сильные отклонения равна 0.73 (при условии равновесия Х-В)
38.
Что означают серьезные отклоненияот Харди – Вайнберга?
Основная причина выполнения закона Харди-Вайнберга – панмиксия
(случайность скрещиваний). Например, существенные отклонения от ХВ
возможны в популяциях растений с частичным самоопылением
В принципе причинами отклонений от ХВ могут быть
- близкородственные скрещивания
- подразделенность популяции
- генетический дрейф
- отбор
Но самая реальная причина – ошибки генотипирования
Проверяйте ХВ, чтобы убедиться в том, что ваши праймеры
работают правильно
39.
Критерий 2 и таблицы сопряженностиТест 2 можно использовать для проверки независимости качественных
признаков. Например бинарных (да - нет)
Вероятности независимых событий перемножаются.
Поэтому, если признак А не сопряжен (не связан) с признаком В, то таблица
сопряженности этих признаков принимает вид:
Признак А Признака А нет
есть
A
B
B
_
A
_
p A pB
p A_ pB
p A pB_
p A_ pB_
Это и есть ожидаемые частоты
при условии, что признаки А и В никак не связаны
Теперь их можно сравнить с реально наблюдаемым распределением, используя 2
40.
Критерий 2 и таблицы сопряженностиКак это делается практически?
B
B
_
A
A
50
30
20
Наблюдаемые
Вычисляем:
_
100
A
B
B
_
5600
8400
A
_
10400
15600
Делим на 200 (сумма по 4 клеткам)
_
A
A
Ожидаемые
B
28
52
_
B
42
78
В 2общем случае: 2
2
2
(
50
28
)
(
30
52
)
(
20
42
)
(100 78)
строк-1)
2
(число столбцов-1)(число
44.3
28
52
42
78
А что скажет по этому поводу
точный тест Фишера?
2,8 10-11
2,5 10-9
=ХИ2РАСП(44,3; 1)
41.
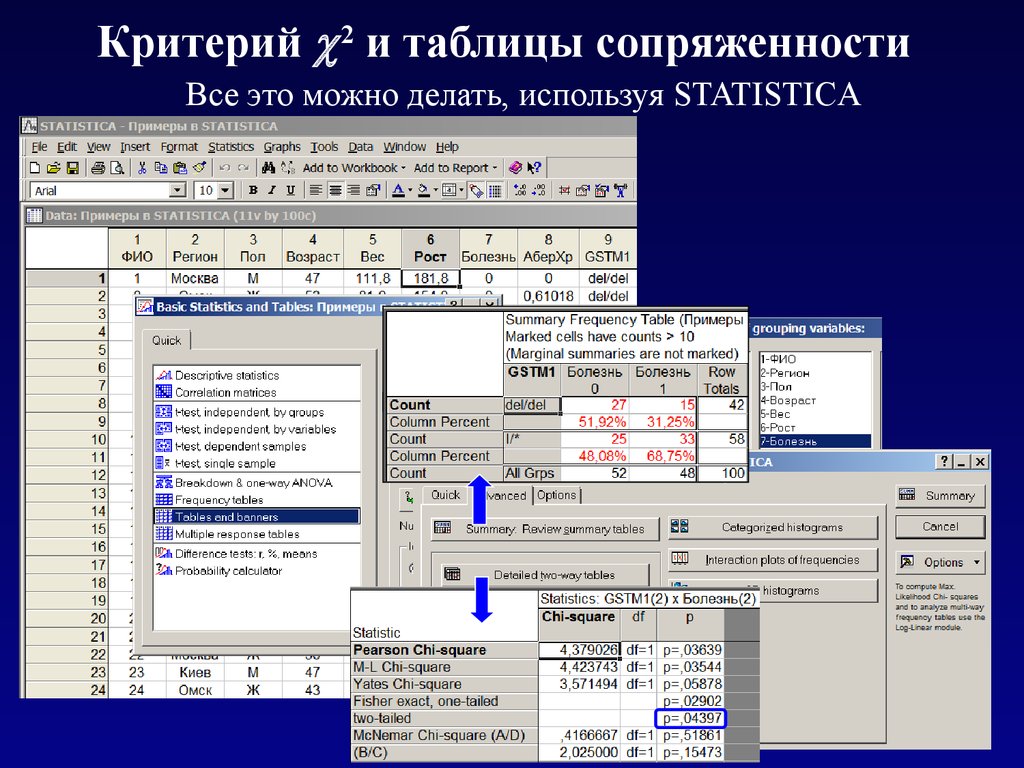
Критерий 2 и таблицы сопряженностиВсе это можно делать, используя STATISTICA
42.
Критерий 2 и таблицы сопряженностиНапомню:
во всех
Это все были таблицы
2х2.
численности
Для признаков с более, чем 2 клетках
значениями,
все тоже самое
должны быть > 5
Наблюдаемые:
n23
n*3
n2*
n*3 n2*
N
Ожидаемые:
2
(
Н
О
)
2
О
Число степеней свободы = (число столбцов-1)(число строк-1)
=ХИ2РАСП( 2; Число ст. свободы)
Кстати точный тест Фишера считается только для 2х2,
и поэтому только и остается, что использовать 2
43.
Критерий 2 и таблицы сопряженностиТаблица сопряженности 2х3: ассоциация заболевания
с полиморфизмом гена GSTP1
GSTP1 A313G
90
A/A
Relative frequency (%)
80
A/G
70
G/G
60
50
40
30
20
10
0
0
1
Болезнь
44.
Критерий 2: проверка однородности данныхВ практике экспериментатора постоянно возникает вопрос о
возможности объедания выборок
Данные мониторинга популяций, полученные в различные годы
Данные по частотам генов в нескольких выборках в пределах
одно локальности
Сравнение частот аберраций для экспонированных и
контрольных популяций: можно ли объединять данные для
различных особей
Объединие выборок возможно лишь при условии
однородности данных. В случае таблиц сопряженности на
однородность указывает низкий 2 (соответствующее р > 0.1)
При работе с неоднородными данными возникают
невероятные ситуации!
45.
На сегодня это всеНапоследок хочу посоветовать:
Проверяйте характер распределения
сравниваемых величин. Или хотя бы стройте
гистограммы распределений – для себя.
При сравнении средних всегда пробуйте все тесты –
параметрические и непараметрические.
Оценивайте мощность теста в случае получения незначимых
результатов
Прикиньте с помощью 2 – соотношение мальчиков и девочек в
вашей группе отличается значимо от 1:1 ?