



















 Программирование
ПрограммированиеПохожие презентации:










Абстрактный тип данных «Список»
1.
Абстрактный тип данных «Список»Структура, отражающая отношение соседства
между своими элементами, называется линейной.
К линейным структурам можно отнести:
•массивы
•линейные списки
•очереди
•стеки
•деки
.
1
2.
В математике список представляет собой последовательность элементов определенноготипа, который в общем случае обозначим как eltype (тип элемента).
Представим список в виде последовательности элементов, разделенных запятыми:
а1, а2, ..., аn,
где n > 0 и все аi имеют тип eltype.
Количество элементов n будем называть длиной списка.
Если n > 1, то а1 называется первым элементом, аn, — последним элементом списка.
В случае n = 0 имеем пустой список, который не содержит элементов.
Важное свойство списка заключается в том, что его элементы можно линейно
упорядочить в соответствии с их позицией в списке.
Говорят, что элемент аi предшествует ai+1 для i = 1, 2, ..., n — 1 и ai следует за ai-1 для i =
2, 3, ..., n.
Кроме этого говорят, что элемент аi имеет позицию i.
Пусть существует позиция, следующая за последним элементом списка.
2
3.
Функция END(L) будет возвращать позицию, следующую за позицией n в n-элементном списке L.Позиция END(L), рассматриваемая как расстояние от начала списка, может изменяться при
увеличении или уменьшении списка, в то время как другие позиции имеют фиксированное
(неизменное) расстояние от начала списка.
Для формирования абстрактного типа данных на основе математического определения списка
необходимо задать множество операторов, выполняемых над объектами типа LIST (Список).
Необходимо определить операторы, которые должны найти первый элемент списка, перейти к
следующему элементу, осуществить поиск и удаление элементов.
Примем обозначения:
L — список объектов типа eltype,
x — объект этого типа,
р — позиция элемента в списке.
"позиция" имеет другой тип данных, реализация которого может быть различной для разных
реализаций списков.
Обычно позиции понимаются как множество целых положительных чисел, но на практике могут
встречаться и другие представления.
3
4.
1. INSERT(x, р, L). Этот оператор вставляет объект х в позицию р в списке L,перемещая элементы от позиции р и далее в следующую, более высокую позицию.
Если в списке L нет позиции р, то результат выполнения этого оператора не
определен.
2. LOCATE(х, L). Эта функция возвращает позицию объекта х в списке L. Если в
списке объект х встречается несколько раз, то возвращается позиция первого от
начала списка объекта х. Если объекта х нет в списке L, то возвращается END(L).
3. RETRIEVE(р, L). Эта функция возвращает элемент, который стоит в позиции р в
списке L. Результат не определен, если р — END(L) или в списке L нет позиции р.
Элементы должны быть того типа, который в принципе может возвращать функция.
Однако на практике всегда можно изменить эту функцию так, что она будет
возвращать указатель на объект типа eltype.
4. DELETE(p, L). Этот оператор удаляет элемент в позиции р списка L. Результат не
определен, если в списке L нет позиции р или р = END(L).
4
5.
5. NEXT(p, L) и PREVIOUS(р, L). Эти функции возвращают соответственноследующую и предыдущую позиции от позиции р в списке L. Если р — последняя
позиция в списке L, то NEXT(p, L) = END(L). Функция NEXT не определена, когда
р = END(L). Функция PREVIOUS не определена, если р = 1. Обе функции не
определены, если в списке L нет позиции р.
6. MAKENULL(L). Эта функция делает список L пустым и возвращает
позицию END(L).
7. FIRST(L). Эта функция возвращает первую позицию в списке L. Если список
пустой, то возвращается позиция END(L).
8. PRINTLIST(L). Печатает элементы списка L в порядке из расположения.
5
6.
С линейными списками могут выполняться следующие операции(дополнительно):
Объединение в одном списке двух или более линейных списков.
Разбиение линейного списка на два или более списка.
Создание копии линейного списка.
Определение количества узлов в списке.
Сортировка узлов в порядке возрастания значений в определенных полях этих
узлов.
6
7.
Реализация списковСписок — это конечное, возможно пустое множество элементов различной
природы, имеющее определенный смысл для решаемой задачи. В качестве элементов
списка могут выступать любые другие элементы данных, в том числе и сами списки.
Для представления списков можно использовать
массивы (несвязный список) и указатели (связный список).
Каждая их этих реализаций осуществляет определенные операторы, выполняемые
над списками, более эффективно, чем другая.
Связный список — это структура данных, состоящая из узлов, каждый из которых
содержит как собственные данные, так и одну или две ссылки («связки») на следующий
и/или предыдущий узел списка.
Принципиальным преимуществом связных списков перед массивом является
структурная гибкость: порядок элементов связного списка может не совпадать с
порядком расположения элементов данных в памяти компьютера, а порядок обхода
списка всегда явно задаётся его внутренними связями.
7
8.
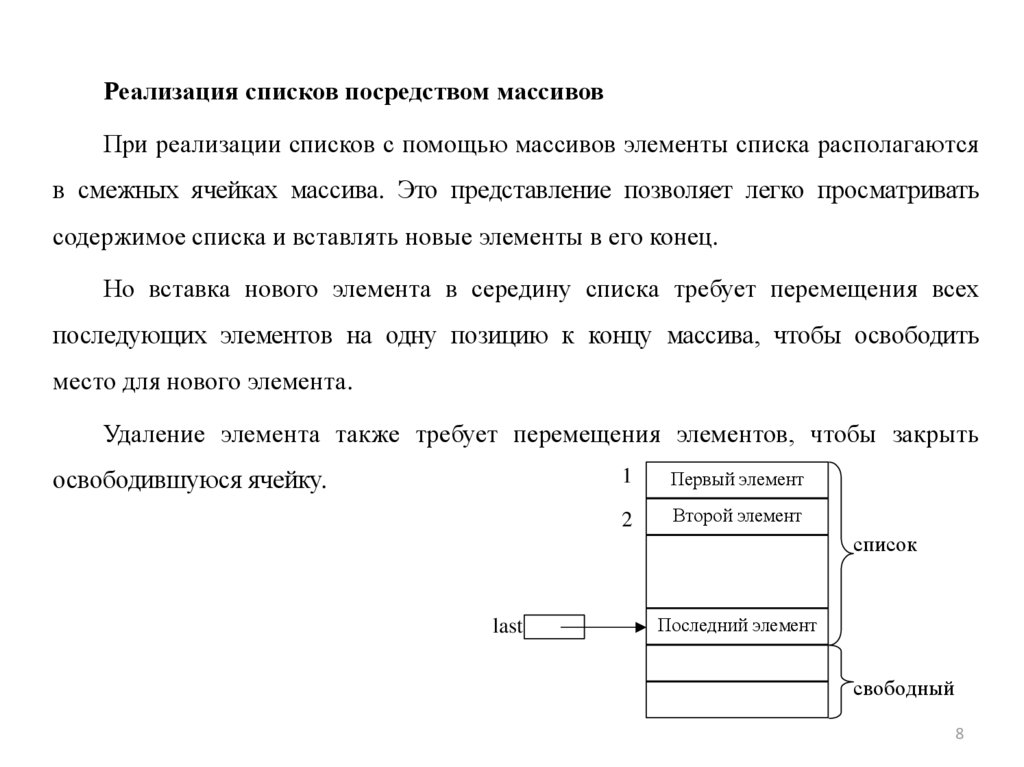
Реализация списков посредством массивовПри реализации списков с помощью массивов элементы списка располагаются
в смежных ячейках массива. Это представление позволяет легко просматривать
содержимое списка и вставлять новые элементы в его конец.
Но вставка нового элемента в середину списка требует перемещения всех
последующих элементов на одну позицию к концу массива, чтобы освободить
место для нового элемента.
Удаление элемента также требует перемещения элементов, чтобы закрыть
освободившуюся ячейку.
1
Первый элемент
2
Второй элемент
список
last
Последний элемент
свободный
8
9.
При использовании массива мы определяем тип LIST как запись, имеющую дваполя.
Первое поле elements (элементы) — это элементы массива, чей размер считается
достаточным для хранения списков любой длины, встречающихся в данной
реализации или программе.
Второе поле целочисленного типа last (последний) указывает на позицию
последнего элемента списка в массиве.
Как видно из рисунка, приведенного выше, i-й элемент списка, если 1 < i < last,
находится в i-й ячейке массива.
Позиции элементов в списке представлены в виде целых чисел, таким образом, i-я
позиция — это просто целое число i.
Функция END(L) возвращает значение last + 1.
9
10.
Реализация списков с помощью указателейДля реализации однонаправленных списков могут использоваться указатели, связывающие
последовательные элементы списка.
Эта реализация позволяет не использовать непрерывную область памяти для хранения списка
и, следовательно, нет необходимости перемещать элементы списка при вставке или удалении
элементов.
Однако ценой за это удобство становится дополнительная память для хранения указателей.
В этой реализации список состоит из ячеек, каждая из которых содержит элемент списка и
указатель на следующую ячейку списка.
Если список состоит из элементов а1, а2, ..., аn, то для i = 1, 2, ..., n-1 ячейка, содержащая
элемент аi, имеет также указатель на ячейку, содержащую элемент ai+1.
Можно ввести ячейку header (заголовок), которая указывает на ячейку, содержащую а1. Ячейка
header не содержит элементов списка.
В случае пустого списка заголовок имеет указатель nil, не указывающий ни на какую ячейку.
10
11.
Сравнение реализацийРеализация списков с помощью массивов требует указания максимального размера
списка до начала выполнения программ. Если мы не можем заранее ограничить
сверху длину обрабатываемых списков, то, очевидно, более рациональным
выбором будет реализация списков с помощью указателей.
Выполнение некоторых операторов в одной реализации требует больших
вычислительных затрат, чем в другой.
Например, процедуры INSERT и DELETE выполняются за постоянное число шагов
в
случае
связанных
списков
любого
размера,
но
требуют
времени,
пропорционального числу элементов, следующих за вставляемым (или удаляемым)
элементом, при использовании массивов.
И наоборот, время выполнения функций PREVIOUS и END постоянно при
реализации списков посредством массивов, но это же время пропорционально
длине списка в случае реализации, построенной с помощью указателей.
11
12.
Сравнение реализацийРеализация списков с помощью массивов расточительна в отношении
компьютерной памяти, резервируется объем памяти, достаточный для
максимально возможного размера списка независимо от его реального размера
в конкретный момент времени.
Реализация с помощью указателей использует столько памяти, сколько
необходимо для хранения текущего списка, но требует дополнительную
память для указателя каждой ячейки.
Таким образом, в разных ситуациях по критерию используемой памяти могут
быть выгодны разные реализации.
12
13.
Реализация списков с помощью указателей:• Однонаправленный (односвязный) список
• Двунаправленный (двусвязный) список
• Кольцевой связный список
13
14.
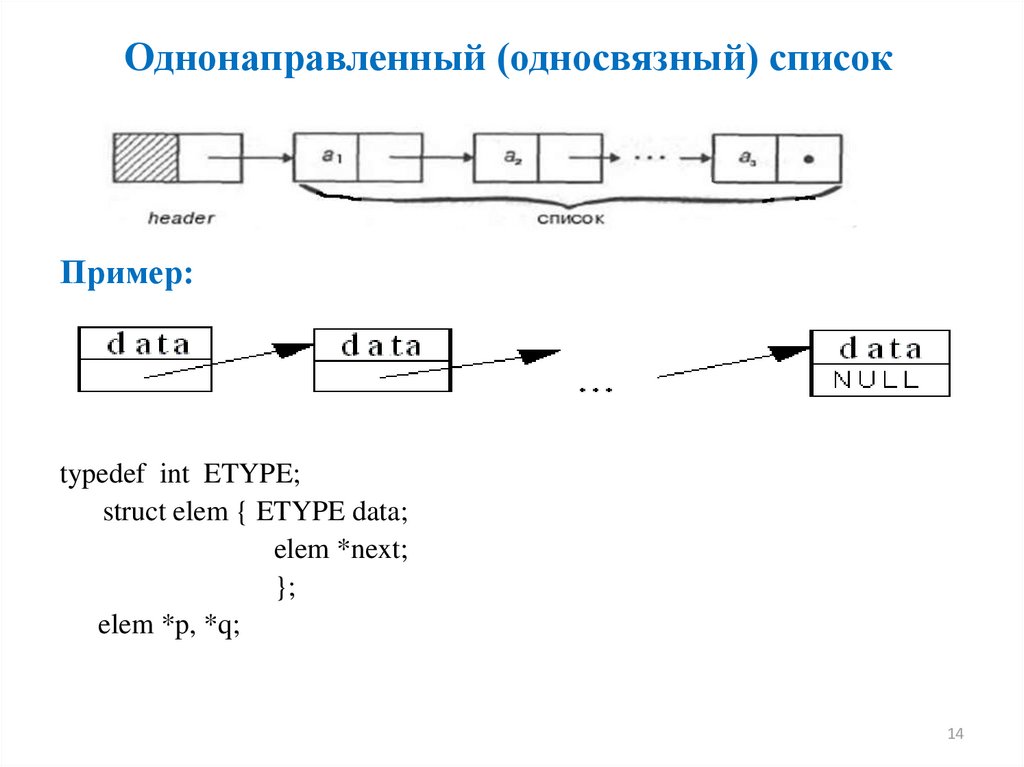
Однонаправленный (односвязный) списокПример:
typedef int ETYPE;
struct elem { ETYPE data;
elem *next;
};
elem *p, *q;
14
15.
Однонаправленная структура данных иногда называется цепочкой.Объекты типа elem из этого списка называют элементами списка или звеньями.
Каждый элемент цепочки, кроме последнего, содержит указатель на
следующий за ним элемент.
Признаком того, что элемент является последним в списке, служит то, что член
типа elem* этого звена равен NULL.
Вместе с каждым списком рассматривается переменная, значением которой
является указатель на первый элемент списка (header).
Если список не имеет ни одного элемента, т.е. пуст, значением этой переменной
должен быть NULL.
Рассмотрим методы работы с такими списками.
Пусть переменные p, q имеют тип elem*:
elem *p, *q;
15
16.
Построим список из двух элементов, содержащих числа 12 и -8.Значением переменной p всегда будет указатель на первый элемент уже
построенной части списка.
Переменная q будет использоваться для выделения с помощью new места в памяти
под размещение новых элементов списка.
Выполнение оператора p = NULL;
приводит к созданию пустого списка.
После выполнения операторов:
q = new elem;
q->data = -8;
q->next = p;
p = q;
получили список, он состоит из одного элемента, содержит в
информационной части число -8.
Переменные p, q указывают на этот элемент.
16
17.
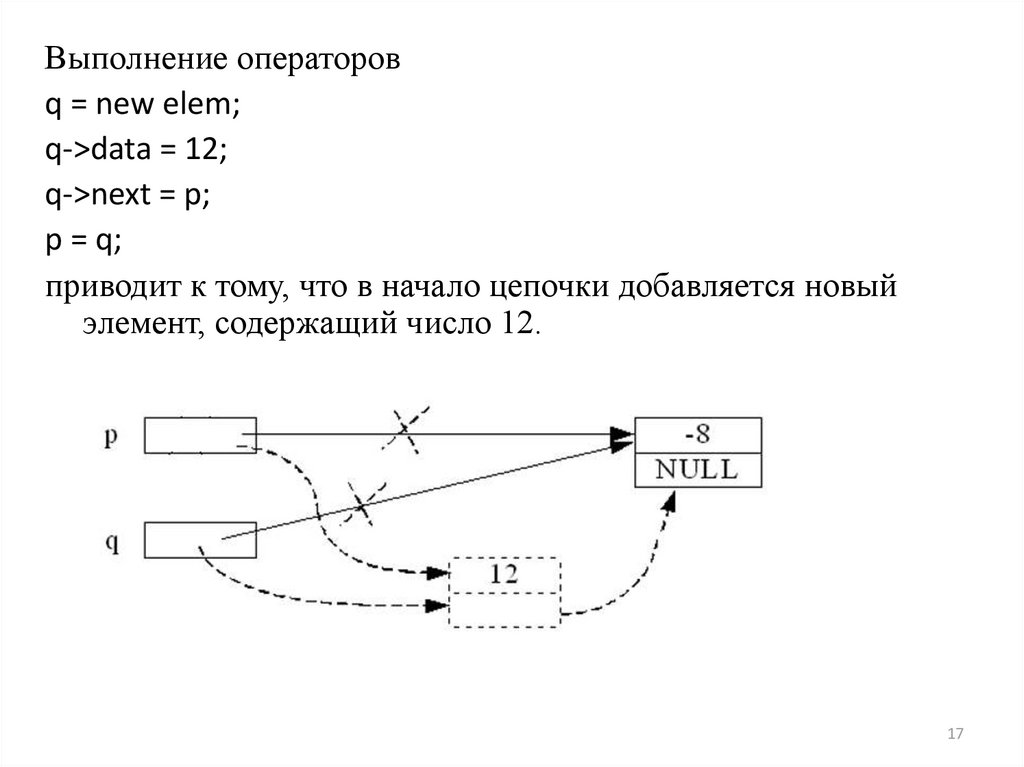
Выполнение операторовq = new elem;
q->data = 12;
q->next = p;
p = q;
приводит к тому, что в начало цепочки добавляется новый
элемент, содержащий число 12.
17
18.
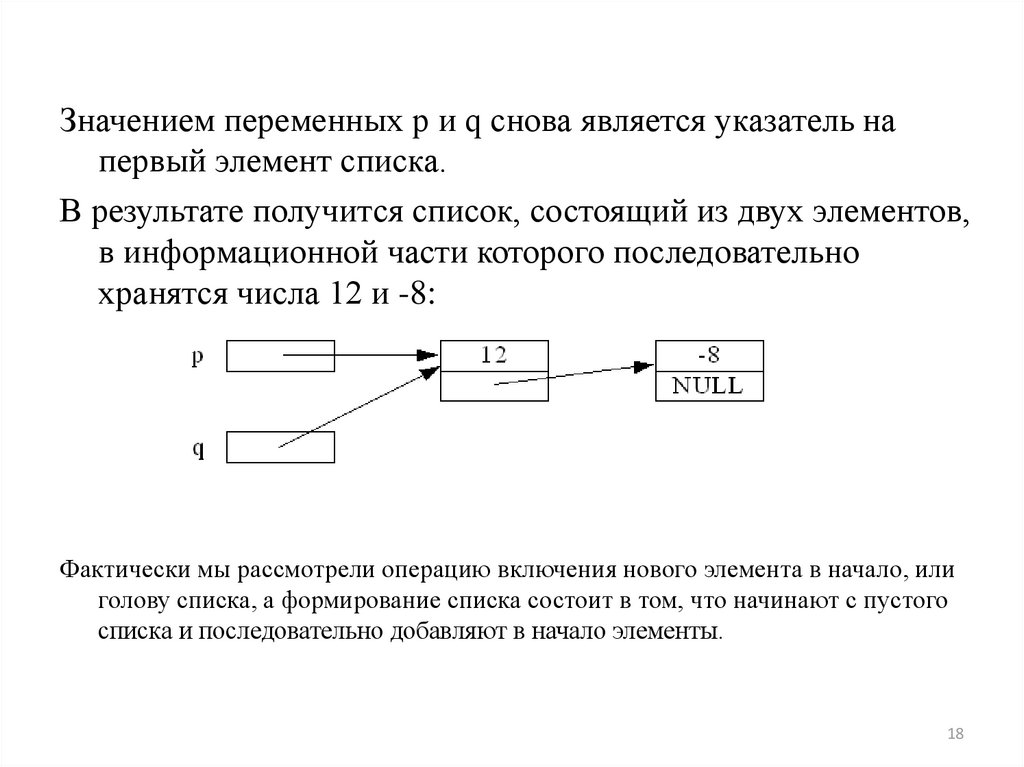
Значением переменных p и q снова является указатель напервый элемент списка.
В результате получится список, состоящий из двух элементов,
в информационной части которого последовательно
хранятся числа 12 и -8:
Фактически мы рассмотрели операцию включения нового элемента в начало, или
голову списка, а формирование списка состоит в том, что начинают с пустого
списка и последовательно добавляют в начало элементы.
18
19.
Построим список, элементы которого содержат целые числа1, 2, 3, . . ., n.
p = NULL;
while ( n > 0 )
{ q = new elem;
q->data = n;
q->next = p;
p=q;
n - -;}
При включении элемента в голову списка порядок
элементов в списке обратный по отношению к порядку их
включения.
19
20.
Проход по спискуПредположим, что с каждым информационным элементом
звена нужно выполнить некоторую операцию, которая
реализуется функцией
void FUN (ETYPE).
Пусть p указывает на начало списка.
Тогда проход по списку осуществляется так:
q = p;
while (q) {
FUN ( q->data );
q = q->next;
}
20
21.
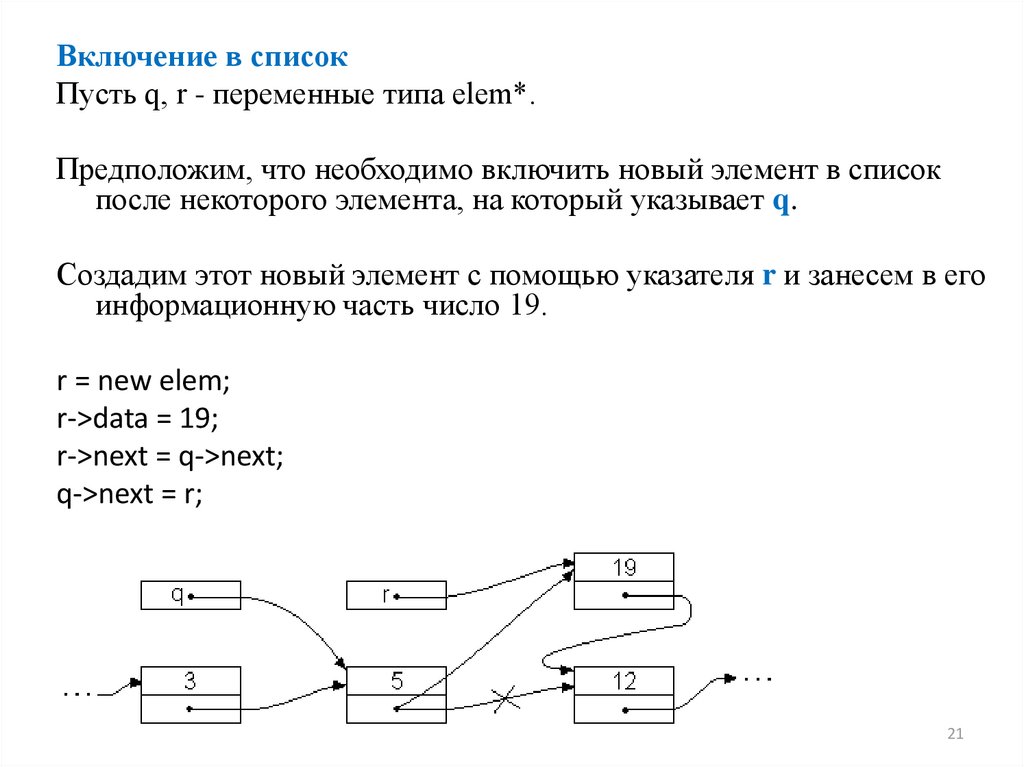
Включение в списокПусть q, r - переменные типа elem*.
Предположим, что необходимо включить новый элемент в список
после некоторого элемента, на который указывает q.
Создадим этот новый элемент с помощью указателя r и занесем в его
информационную часть число 19.
r = new elem;
r->data = 19;
r->next = q->next;
q->next = r;
21
22.
Исключение из списка.Пусть теперь значением переменной q является указатель на некоторый, не
последний, элемент списка
и требуется исключить из списка элемент, следующий за ним.
r = q->next;
q->next = q->next->next;
r->next = NULL;
Второе из приведенных присваиваний - это собственно исключение из списка, а
первое выполняется для того, чтобы сохранить указатель на исключенный элемент,
т.е. чтобы после исключения из списка он оставался доступным и с ним можно
было бы выполнять некоторые действия.
Например, вставить его на другое место или освободить занимаемую им память с
помощью операции delete r.
Третье
присваивание
выполняется
для
того,
чтобы сделать
исключение
окончательным, т.е. чтобы из исключенного элемента нельзя было бы попасть в
список, из которого он исключен.
22
23.
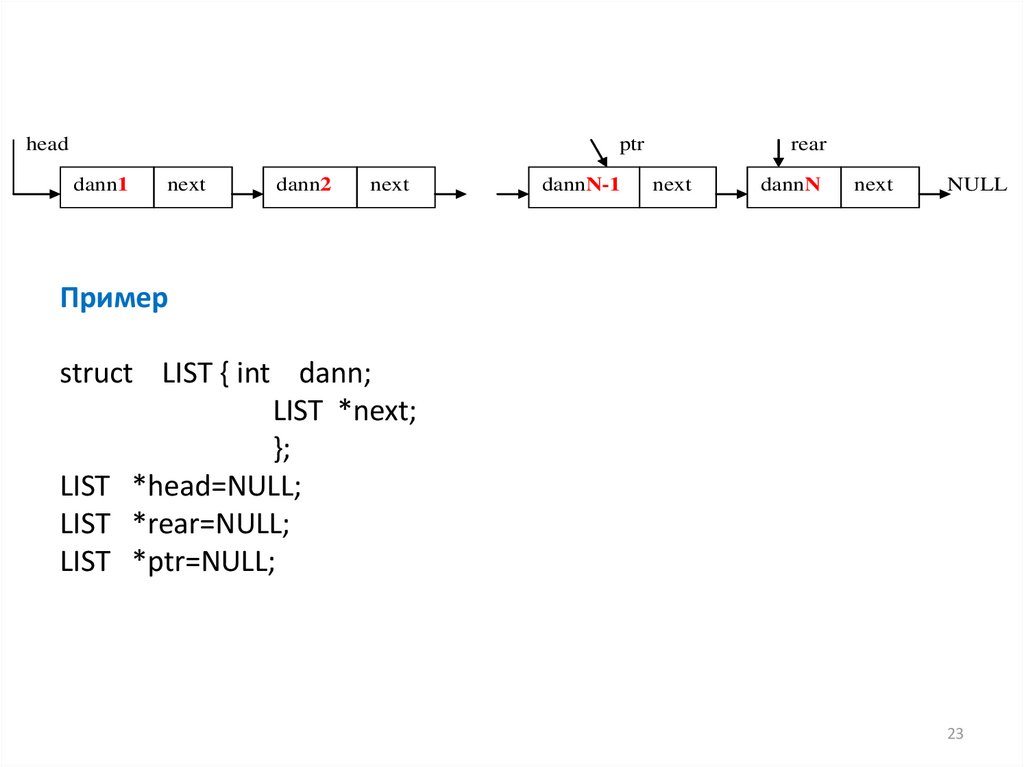
headptr
dann1
next
dann2
next
dannN-1
rear
next
dannN
next
NULL
Пример
struct LIST { int dann;
LIST *next;
};
LIST *head=NULL;
LIST *rear=NULL;
LIST *ptr=NULL;
23
24.
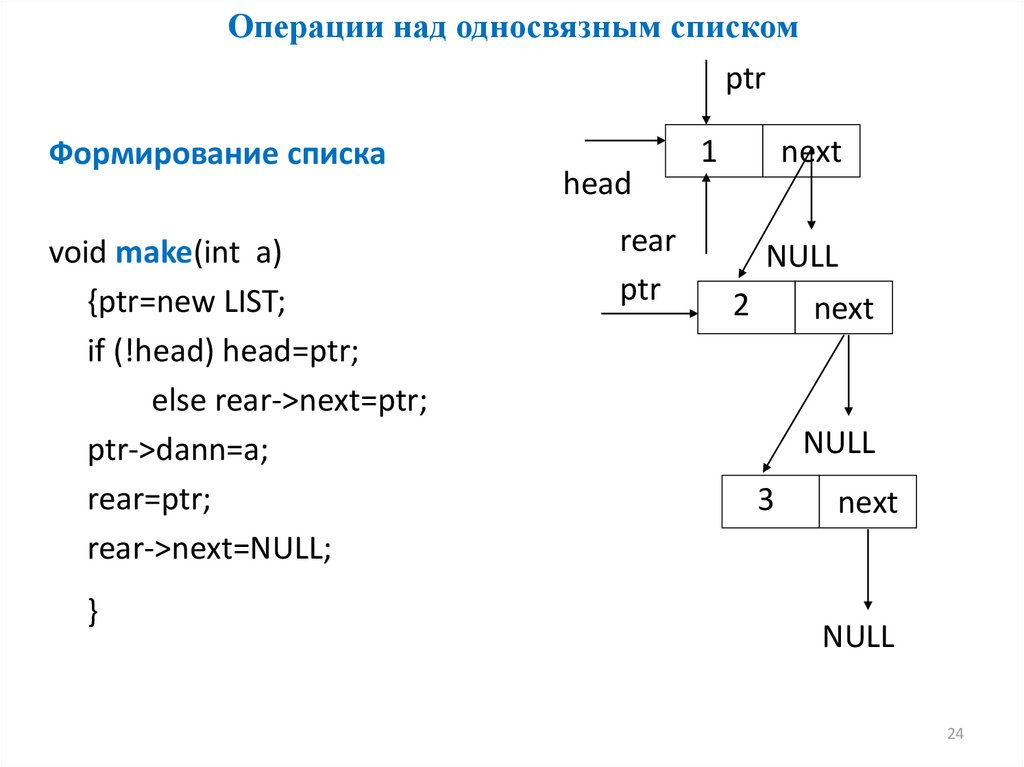
Операции над односвязным спискомptr
Формирование списка
void make(int a)
{ptr=new LIST;
if (!head) head=ptr;
else rear->next=ptr;
ptr->dann=a;
rear=ptr;
rear->next=NULL;
}
head
rear
ptr
1
next
NULL
2
next
NULL
3
next
NULL
24
25.
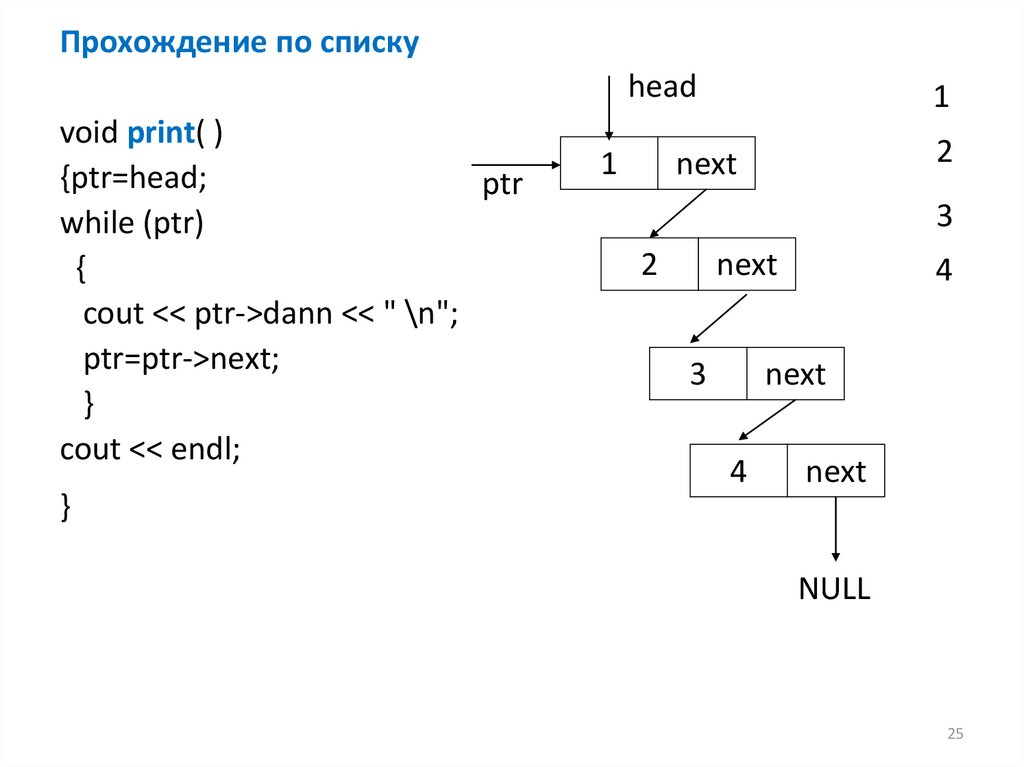
Прохождение по спискуhead
void print( )
{ptr=head;
ptr
while (ptr)
{
cout << ptr->dann << " \n";
ptr=ptr->next;
}
cout << endl;
1
1
2
next
3
2
next
3
4
next
4
next
}
NULL
25
26.
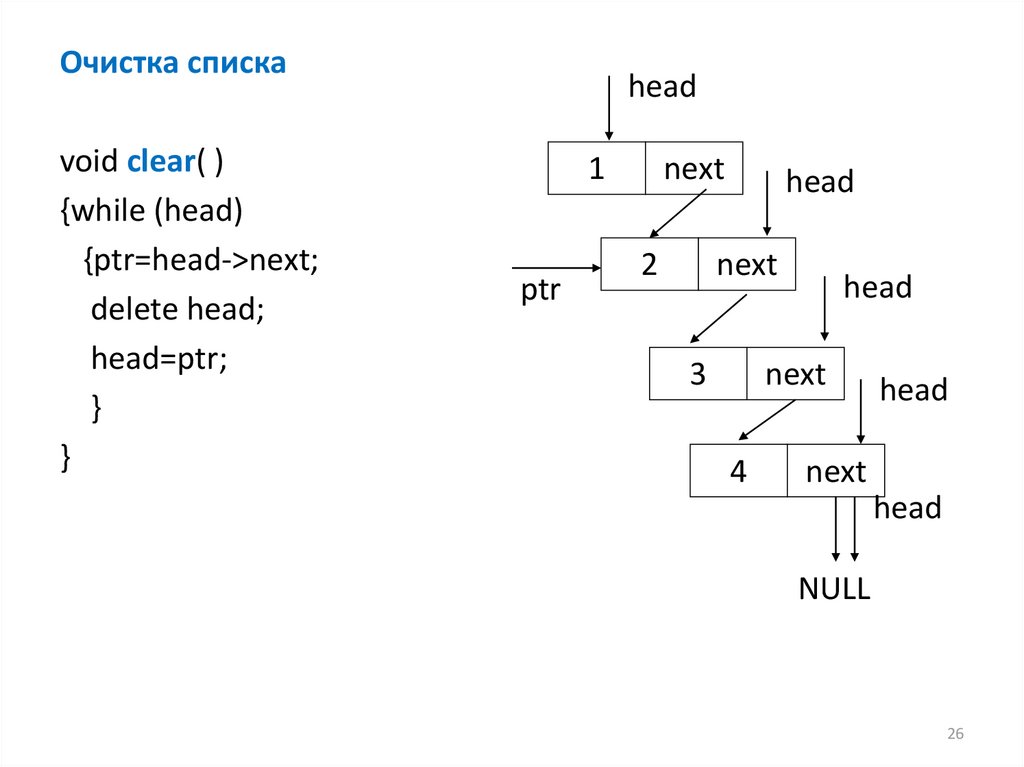
Очистка спискаvoid clear( )
{while (head)
{ptr=head->next;
delete head;
head=ptr;
}
}
head
1
ptr
next
2
head
next
3
head
next
4
head
next
head
NULL
26
27.
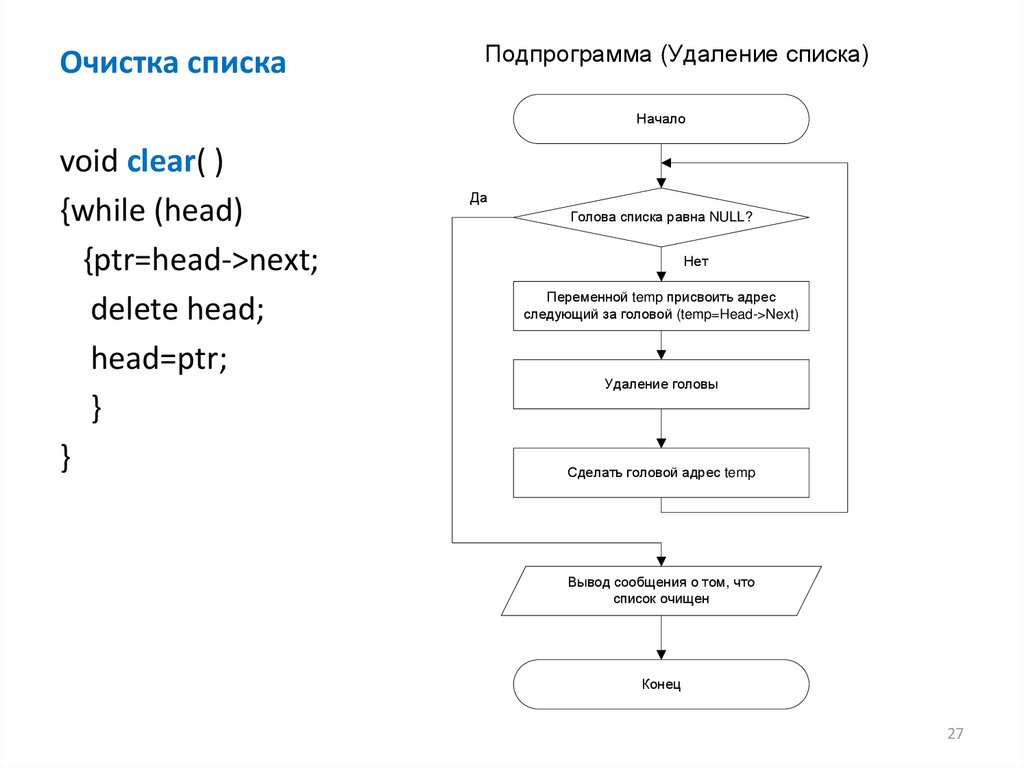
Очистка спискаПодпрограмма (Удаление списка)
Начало
void clear( )
{while (head)
{ptr=head->next;
delete head;
head=ptr;
}
}
Да
Голова списка равна NULL?
Нет
Переменной temp присвоить адрес
следующий за головой (temp=Head->Next)
Удаление головы
Сделать головой адрес temp
Вывод сообщения о том, что
список очищен
Конец
27
28.
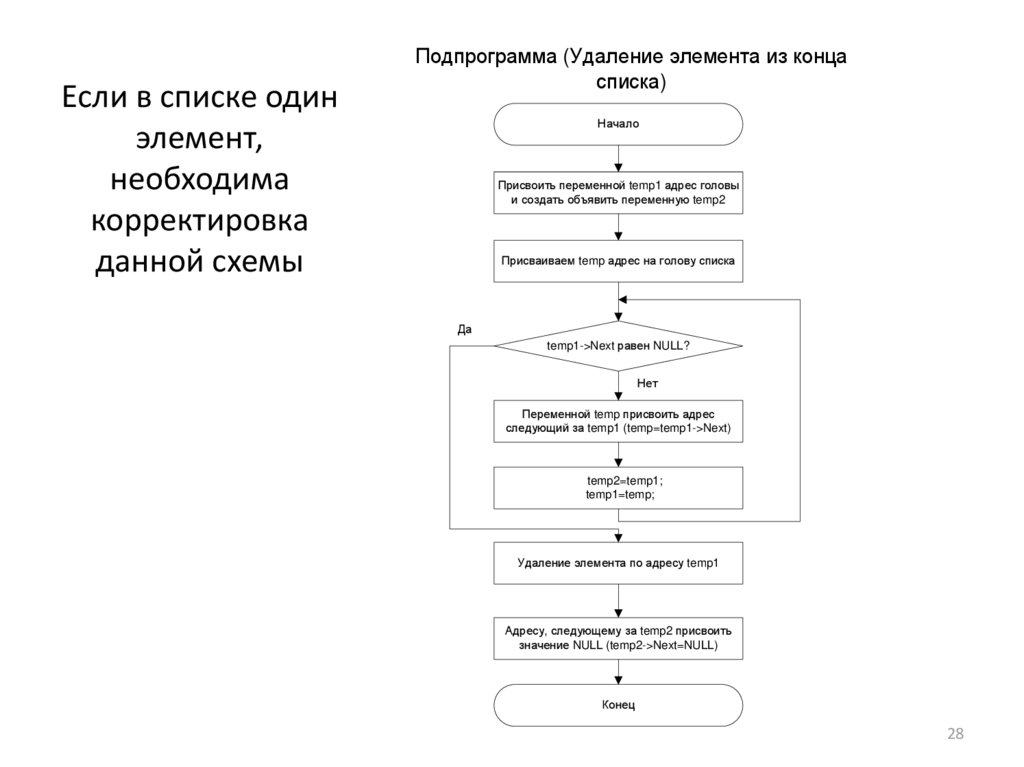
Если в списке одинэлемент,
необходима
корректировка
данной схемы
Подпрограмма (Удаление элемента из конца
списка)
Начало
Присвоить переменной temp1 адрес головы
и создать объявить переменную temp2
Присваиваем temp адрес на голову списка
Да
temp1->Next равен NULL?
Нет
Переменной temp присвоить адрес
следующий за temp1 (temp=temp1->Next)
temp2=temp1;
temp1=temp;
Удаление элемента по адресу temp1
Адресу, следующему за temp2 присвоить
значение NULL (temp2->Next=NULL)
Конец
28
29.
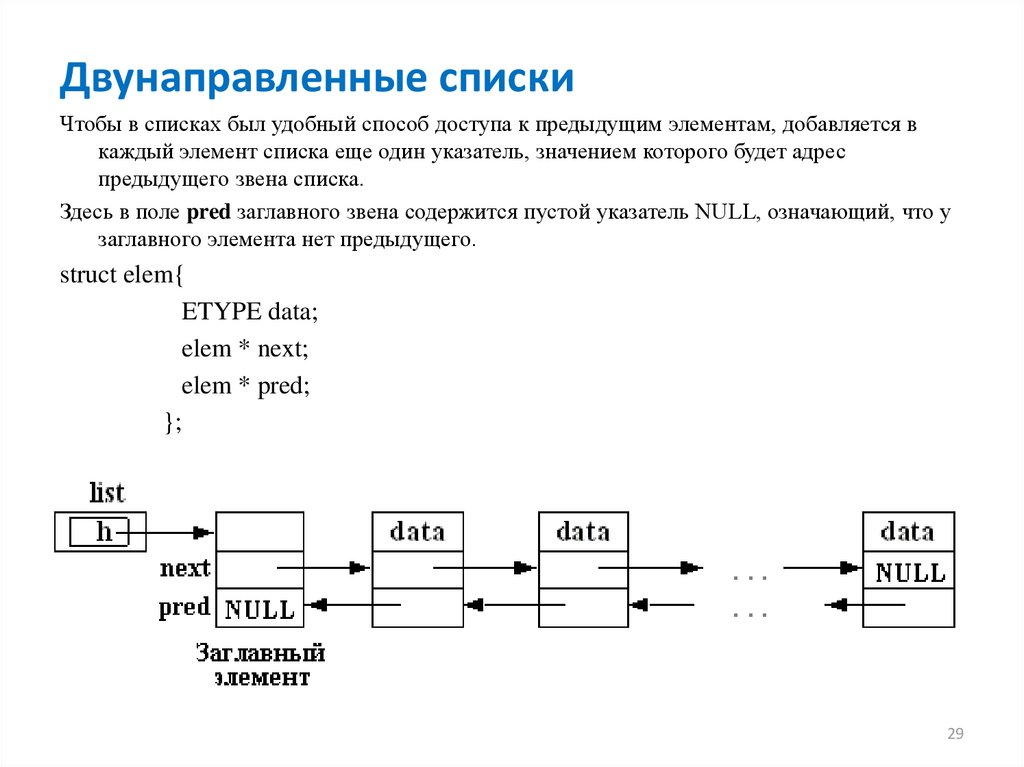
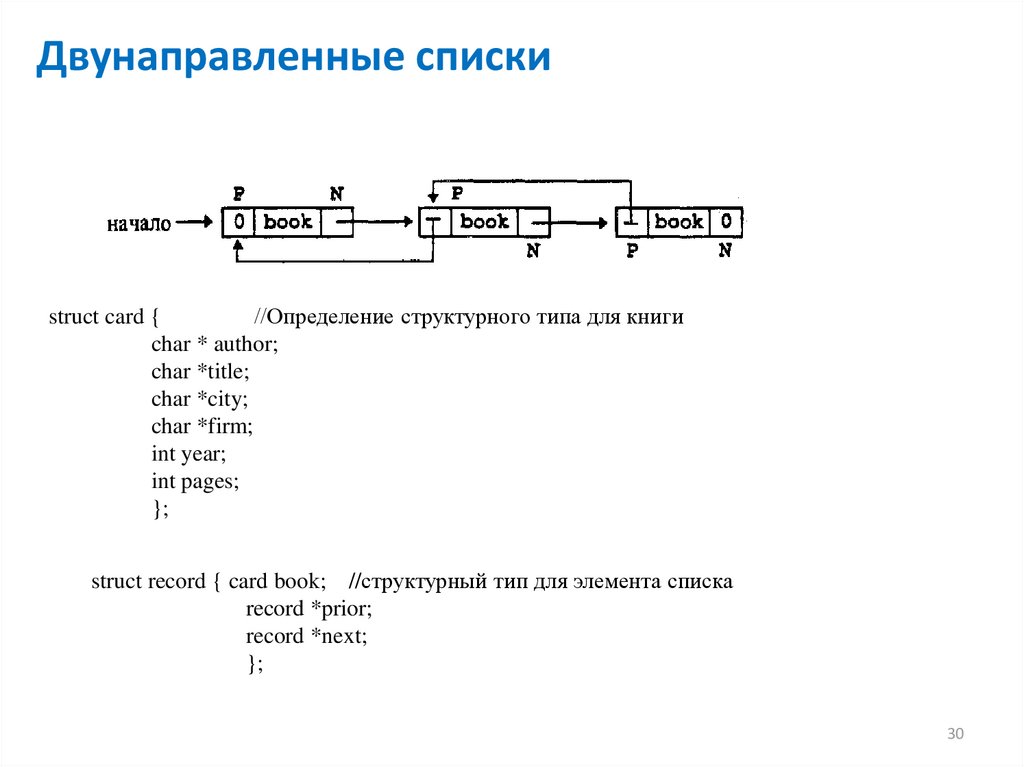
Двунаправленные спискиЧтобы в списках был удобный способ доступа к предыдущим элементам, добавляется в
каждый элемент списка еще один указатель, значением которого будет адрес
предыдущего звена списка.
Здесь в поле pred заглавного звена содержится пустой указатель NULL, означающий, что у
заглавного элемента нет предыдущего.
struct elem{
ETYPE data;
elem * next;
elem * pred;
};
29
30.
Двунаправленные спискиstruct card {
//Определение структурного типа для книги
char * author;
char *title;
char *city;
char *firm;
int year;
int pages;
};
struct record { card book; //структурный тип для элемента списка
record *prior;
record *next;
};
30
31.
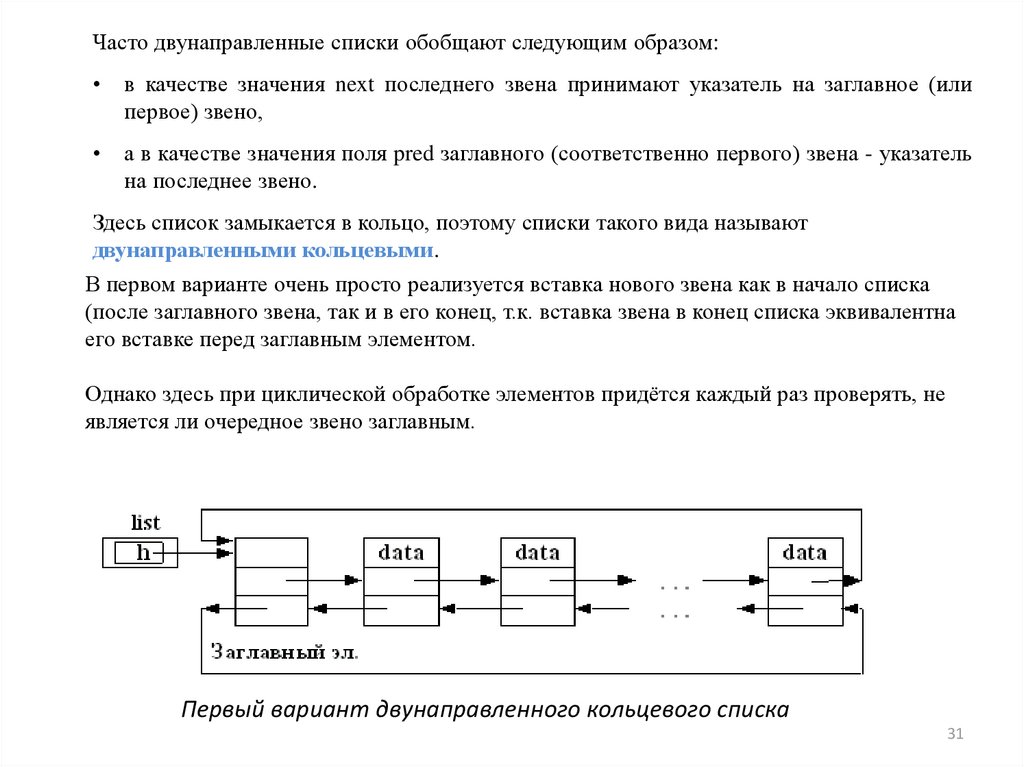
Часто двунаправленные списки обобщают следующим образом:в качестве значения next последнего звена принимают указатель на заглавное (или
первое) звено,
а в качестве значения поля pred заглавного (соответственно первого) звена - указатель
на последнее звено.
Здесь список замыкается в кольцо, поэтому списки такого вида называют
двунаправленными кольцевыми.
В первом варианте очень просто реализуется вставка нового звена как в начало списка
(после заглавного звена, так и в его конец, т.к. вставка звена в конец списка эквивалентна
его вставке перед заглавным элементом.
Однако здесь при циклической обработке элементов придётся каждый раз проверять, не
является ли очередное звено заглавным.
Первый вариант двунаправленного кольцевого списка
31
32.
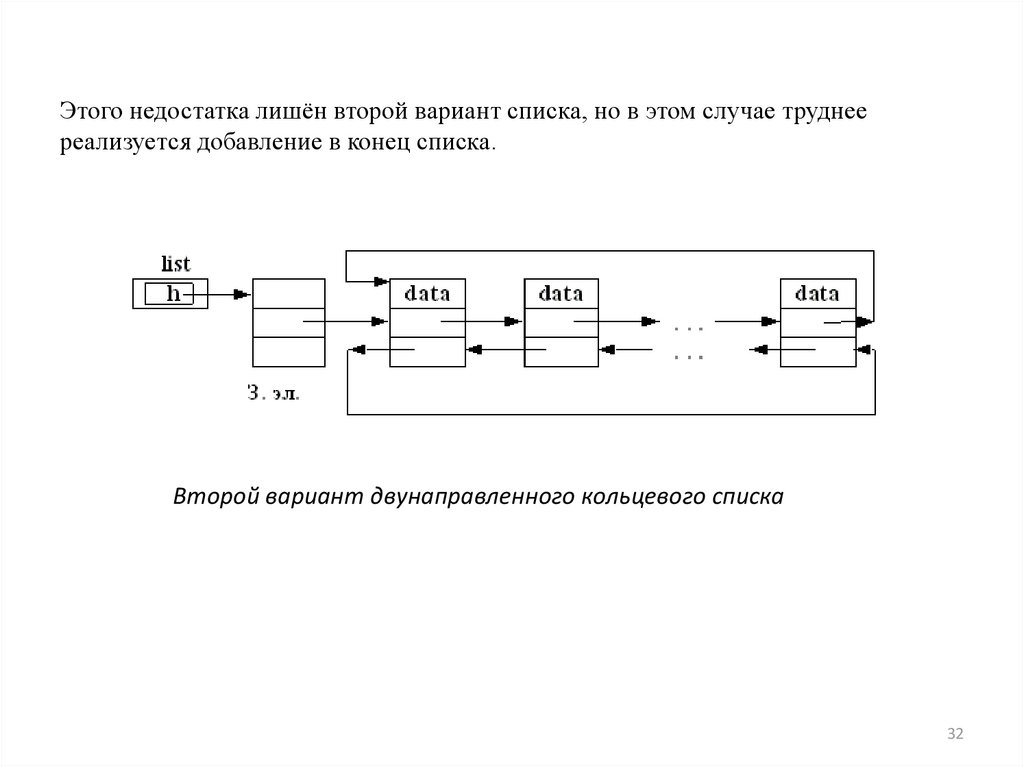
Этого недостатка лишён второй вариант списка, но в этом случае труднеереализуется добавление в конец списка.
Второй вариант двунаправленного кольцевого списка
32
33.
ОперацииВставка элемента
Пусть h, p, q - переменные типа elem*,
k - переменная типа int, значение которой должно содержаться в
информационной части элемента, который должен быть
вставлен после звена, на которое указывает указатель p.
q = new elem;
q->data =k;
q->next= p->next;
q->pred =p;
p->next->pred=q;
p->next=q; // В таком порядке!
Для вставки нового элемента в начало списка достаточно, чтобы
указатель p принял значение адреса заглавного элемента списка: p=h;
33
34.
ОперацииУдаление элемента
Возможность двигаться по указателям в любом направлении
позволяет задавать исключаемое звено
указателем p непосредственно на само это звено:
p->next->pred = p->pred;
p->pred->next = p->next;
delete p;
34
35.
Поиск элементаПусть h - указатель на заглавный элемент списка;
r - указатель, который будет указывать на найденное звено,
содержащее k;
p, q - переменные типа elem*;
b - типа int.
Поиск элемента, содержащего число k:
b=1;
h->data = k+1; // В информационную часть заглавного звена
// заведомо занесём число, отличное от k.
p=h->next;
// Сначала p указывает на первое звено.
r=NULL;
q=p;
// q указывает на первое звено
do { if (p->data= =k)
{ b=0;
r=p;
}
p=p->next;
} while ((p!=q) && b);
35