








 Электроника
ЭлектроникаПохожие презентации:










Parameter Efficient Fine-Tuning
1.
Parameter Efficient Fine-Tuning2.
Желаемые свойства:• Результаты, близкие к полноценному FT
• Изменяется малая часть параметров модели
• Набор изменяемых параметров согласован для различных задач
3.
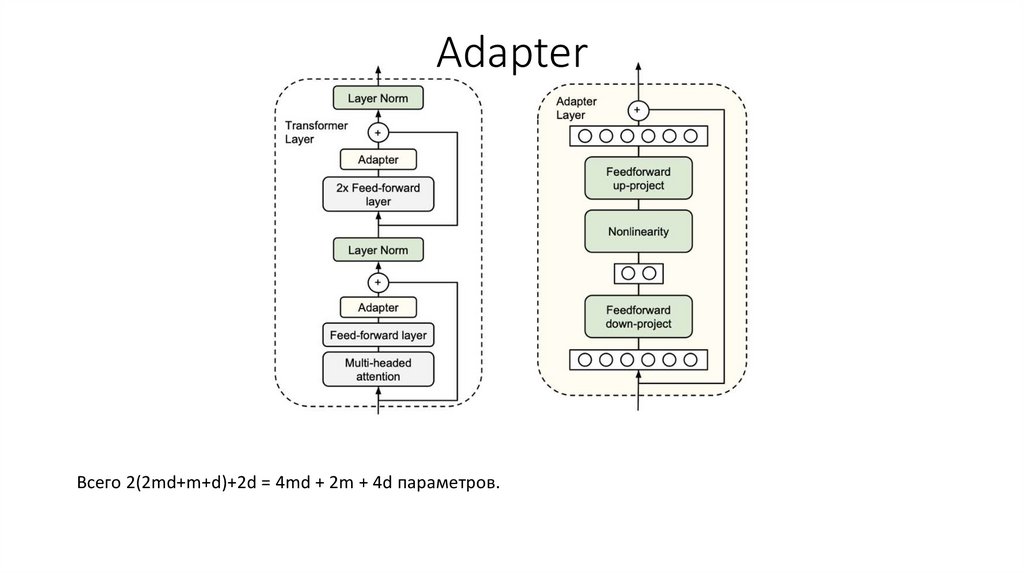
AdapterВсего 2(2md+m+d)+2d = 4md + 2m + 4d параметров.
4.
Инициализация параметровЦель:
- новая модель при инициализации работает, как исходная.
Предлагается инициализировать N(0,10-4).
5.
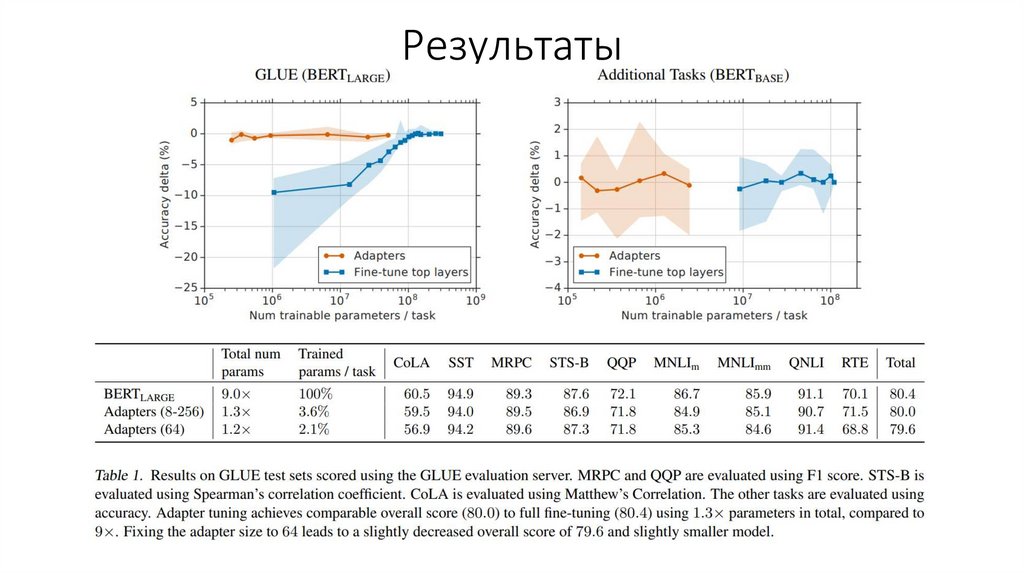
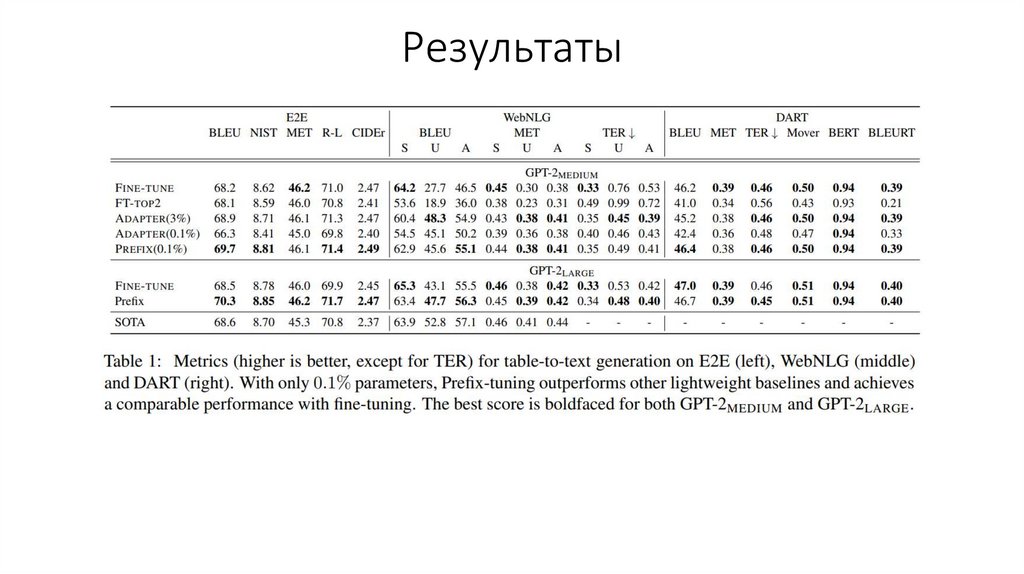
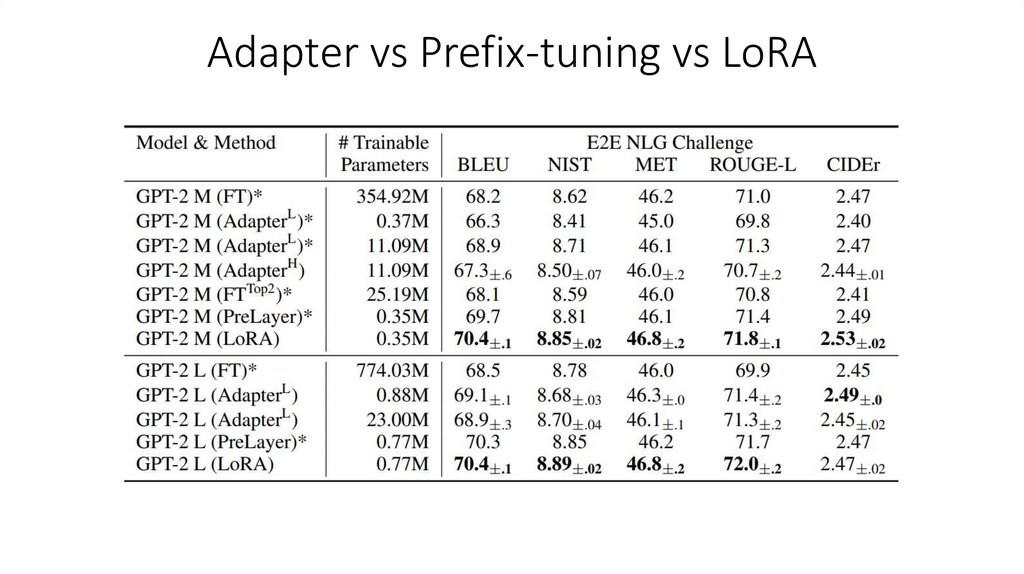
Результаты6.
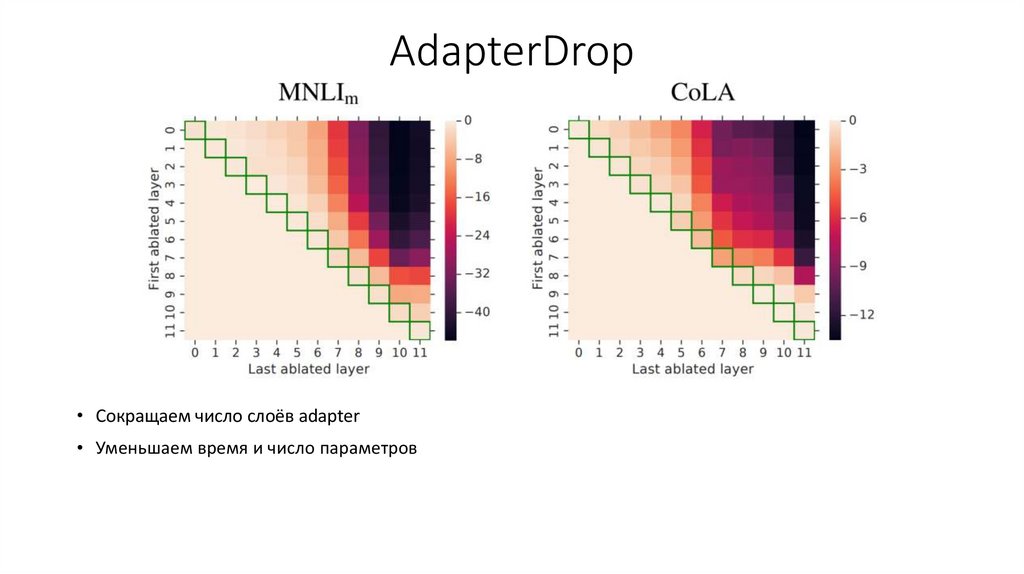
AdapterDrop• Сокращаем число слоёв adapter
• Уменьшаем время и число параметров
7.
Compacter• Полносвязный слой:
• PHM (parameterized hypercomplex multiplication layer):
• LPHM (low-rank PHM):
8.
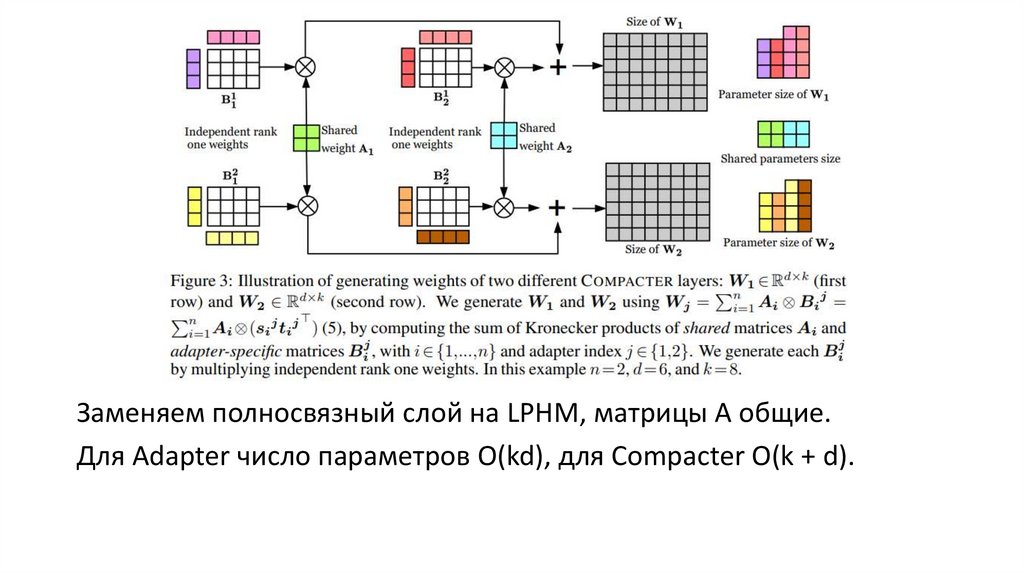
Заменяем полносвязный слой на LPHM, матрицы A общие.Для Adapter число параметров O(kd), для Compacter O(k + d).
9.
Битва адаптеровBitfit – меняем только biases.
PHM-Adapter – заменяем
полносвязный слой на PHM.
Compacter++ - оставляем в
каждом блоке один слой
адаптера.
10.
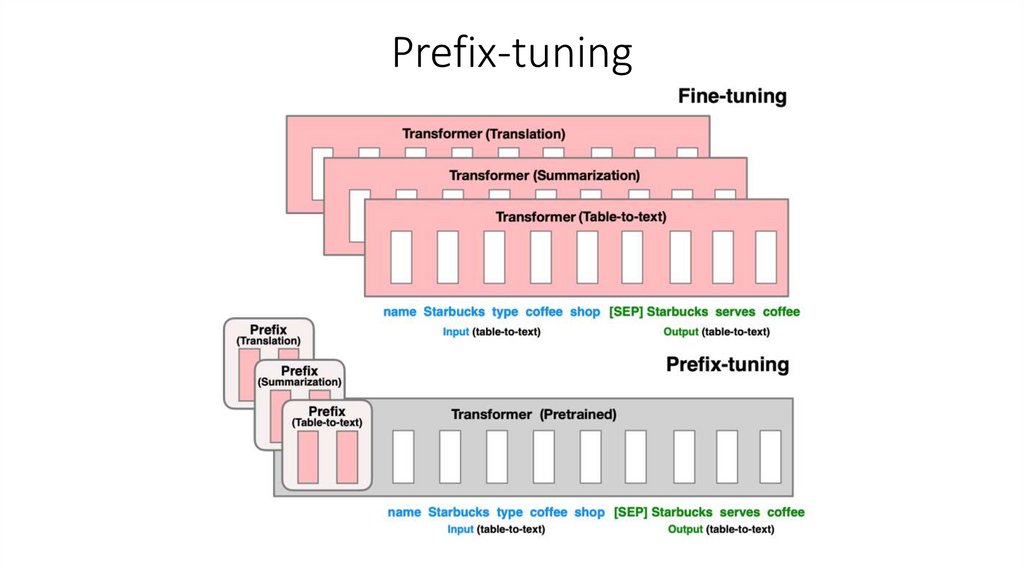
Prefix-tuning11.
Случай классического FTОбозначим
Активацией на шагу
назовём
, где
это выход j-го блока трансформера на шагу i. Вычисляется она в
авторегрессионной модели, как
. Тогда задача
классического FT
12.
13.
В случае Prefix-tuning:На практике прямая оптимизация матрицы
работает плохо,
потому её репараметризуют более маленькой матрицой
14.
Результаты15.
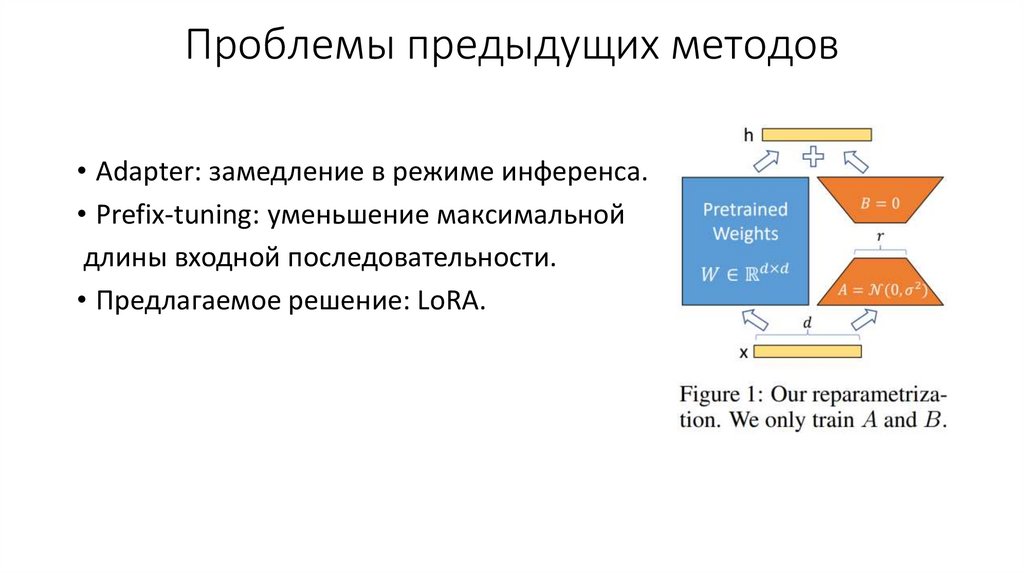
Проблемы предыдущих методов• Adapter: замедление в режиме инференса.
• Prefix-tuning: уменьшение максимальной
длины входной последовательности.
• Предлагаемое решение: LoRA.
16.
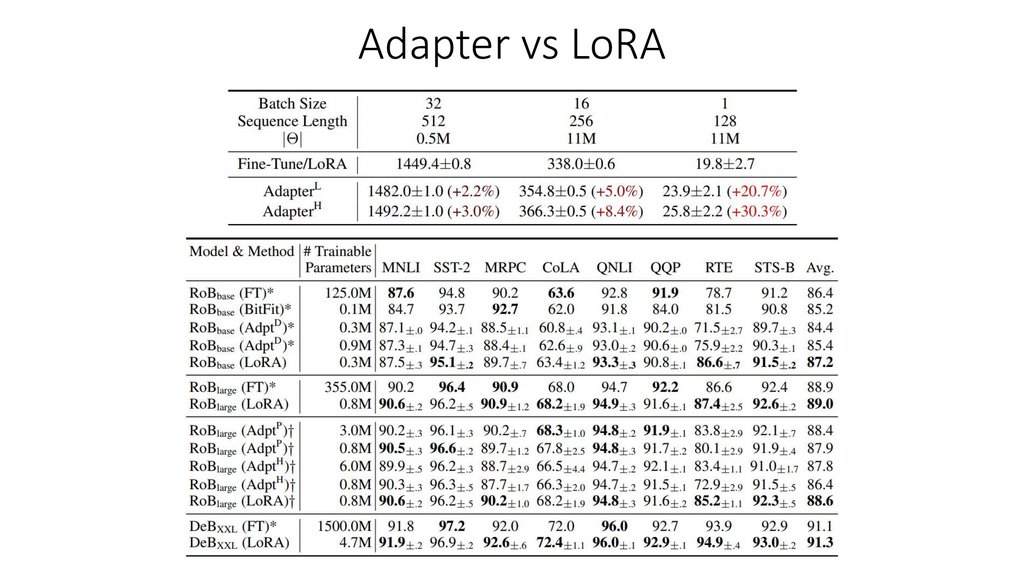
LoRA(Low Rank Adaptation)Общая задача параметризации:
Реализация в LoRA:
Матрицы A и B малоранговы, что заметно уменьшает число параметров.
Обновляем таким способом веса слоёв attention.