
















 Маркетинг
МаркетингПохожие презентации:










Маркетинговые исследования. Методы статистического анализа маркетинговой информации
1.
ФГБОУ ВО «Уральский государственный экономический университет»Маркетинговые
исследования
Изакова Наталья Борисовна
Кандидат экономических наук
доцент кафедры маркетинга и международного
менеджмента
+7 (343) 283 10 46
[email protected]
г. Екатеринбург, ФГБОУ ВО «УрГЭУ», ул. 8-е марта 62,
ауд. 755, Кафедра маркетинга и международного
менеджмента
2.
Тема. Методы статистического анализамаркетинговой информации
1. Основные статистические методы, используемые при
проведении маркетингового исследования
.
2. Постановка вопросов в анкете при реализации
статистических методов анализа
3. Применение метода анализа описательных статистик, таблиц сопряженности и сравнения
средних в маркетинговых исследованиях. Преимущества и недостатки.
4. Примеры использования
3.
Цель примененияДать математическое обоснование гипотезам и тенденциям, выявленным в
результате проведения маркетинговых исследований
Методы статистического анализа
Описательные статистики
Таблицы сопряженности
Корреляционный анализ
Регрессионный анализ
Дисперсионный анализ
Факторный анализ
Кластерный анализ
Программные продукты
Excel, IBM SPSS, Statistica, Minitab, Statgraphics и др.
4.
Методы статистического анализа маркетинговойинформации - Описательные статистики
В рамках данного метода оцениваются:
• Показатели центра распределения: средняя, частота, мода, медиана.
• Показатели вариации: дисперсия, стандартное квадратичное отклонение,
размах вариации, максимумы и минимумы значений, стандартная ошибка
выборки.
• Показатели формы распределения: асимметрия, эксцесс.
• Другие показатели: квартиль, процентиль и пр.
Используя метод описательных статистик, можно определить:
количество респондентов, предпочитающих конкретную марку (частотный анализ);
выбрать самую многочисленную группу респондентов, предпочитающих марку А
(мода);
разбить все данные на группы, отвечающие определенным требованиям (квартили,
процентили) и др.
5.
Методы статистического анализа маркетинговойинформации
Самой простой описательной статистикой, многим известной из
практики, является среднее значение.
Среднее - информативная мера "центрального положения" наблюдаемой переменной,
особенно если сообщается ее доверительный интервал. Исследователю нужны такие
статистики, которые позволяют сделать вывод относительно всей генеральной
совокупности (например, всех потребителей). Одной из таких статистик и является
среднее.
Доверительный интервал для среднего представляет интервал значений вокруг оценки,
где с данным уровнем доверия находится среднее генеральной совокупности.
Например, если среднее переменной ВОЗРАСТ РЕСПОНДЕН-ТА равно 40 (лет), а нижняя и
верхняя границы доверительного интервала с уровнем 0.95 равны 20 и 60
соответственно, то с вероятностью 95% интервал с границами 20 и 60 накрывает среднее
генеральной совокупности (потребителей).
6.
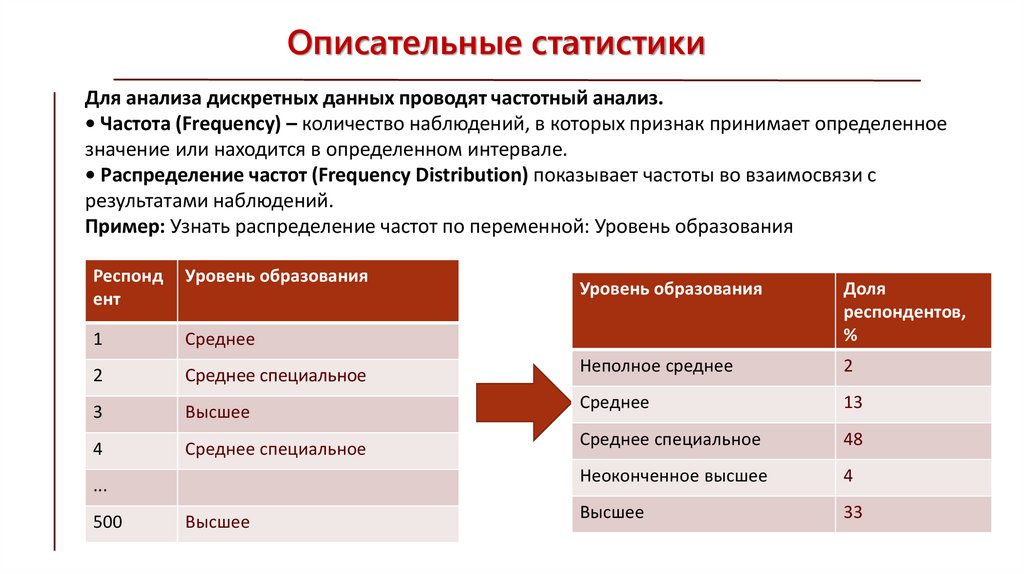
Описательные статистикиДля анализа дискретных данных проводят частотный анализ.
• Частота (Frequency) – количество наблюдений, в которых признак принимает определенное
значение или находится в определенном интервале.
• Распределение частот (Frequency Distribution) показывает частоты во взаимосвязи с
результатами наблюдений.
Пример: Узнать распределение частот по переменной: Уровень образования
Респонд
ент
Уровень образования
1
Среднее
2
Среднее специальное
3
Высшее
4
Среднее специальное
...
500
Высшее
Уровень образования
Доля
респондентов,
%
Неполное среднее
2
Среднее
13
Среднее специальное
48
Неоконченное высшее
4
Высшее
33
7.
Описательные статистики. Частотные таблицыК методам описательной статистики относится построение частотных таблиц.
Таблицы частот представляют собой простейший метод анализа категориальных
(номинальных) переменных. Часто их используют как одну из процедур разведочного
анализа, чтобы просмотреть, каким образом различные группы данных распределены в
выборке.
Например, если в анкете, предназначенной для выявления покупательских предпочтений,
встречается вопрос о количестве детей у респондента, то из частотной таблицы исследователь
может выяснить, что 419 опрошенных или 27,6% не имеют детей, 255 (16,8%) имеют одного
ребенка и т.д.
Кроме того, в таблице приводятся такие показатели, как значимый процент (данные с учетом
тех опросных листов, где на этот вопрос даны ошибочные ответы, которые исследователь не
может интерпретировать и помечает при проведении расчетов как так называемые
"пропущенные" значения), а также кумулятивный (накопленный) процент.
8.
МЕДИАНА• Значение, которое делит распределение пополам: половина
значений больше медианы, половина – меньше. «Середина»
распределения.
• Имеет смысл для ранговых и количественных переменных, но не
для качественных.
Количество чисел (значений) в ряду
Нечетное
Четное
Пример:
Пример:
Возраст 5 опрошенных:
Возраст 6 опрошенных:
18 22 27 31 44
18 22 27 31 44 55
(27+31):2 = 29
9.
ДИСПЕРСИЯ (VARIANCE)• Дисперсия – это среднее арифметическое квадратов разностей полученных значений
переменной и ее средним значением.
• Измеряется в единицах переменной, возведённых в квадрат (не всегда удобно).
• Показывает разброс значений признака относительно своего среднего арифметического
значения, то есть насколько плотно значения признака группируются вокруг среднего
• Чем больше разброс, тем сильнее варьируются ответы респондентов в данной группе, тем
больше индивидуальные различия между респондентами.
• Используется скорее в различных статистических методах, а не в описательной статистике.
Где, а1, а2, а3 … аn – данные, S – среднее арифметическое n – количество чисел в ряду
10.
Описательные статистикиСреднеквадратическое или стандартное отклонение – мера разброса
значений признака около среднего арифметического значения.
•На практике вместо оценки дисперсии чаще используют
производную от нее – стандартное отклонение (корень из
дисперсии).
•Более наглядно, т.к. его размерность соответствует размерности
измеряемой величины (измеряется в тех же единицах, что и
переменная!)
Коэффициент вариации (CV) – отношение стандартного s отклонения к среднему
арифметическому, выраженное в %. CV - это относительная мера разброса значений признака
X.
Стандартная ошибка (S.E. Mean) – определяется как стандартное отклонение, деленное на
квадратный корень из объема выборки. Используется для оценки того, насколько выборка
отражает тенденции, наблюдаемые в генеральной совокупности.
Размах (Range) – разница между наибольшим и наименьшим значениями в распределении
(между мин и макс). Используется для порядковых переменных. Пример: размах цен.
11.
Пример применения описательных статистикНа основе собранной информации о ценах на товар А в 100 торговых точках города:
Показатели
Значения
1. Среднее
29,61
2. Медиана
29.40
3. Мода
24,04
4. Размах
14,7
5. Максимум
22,9
6. Минимум
37,7
Интерпретация результатов:
1. Средняя цена на товар А – 29 руб. 61 коп.
2. Половина всех товаров на рынке представлено по цене ниже/выше 29 руб. 40 коп.
3. Наиболее часто встречающаяся цена на рынке – 24 руб.04 коп.
4. Разница между ценами на товар Ана рынке составляет 14 руб. 70 коп.
5. Минимальная цена на товар А – 22 руб. 90 коп.
6. Максимальная цена на товар А – 37 руб 70 коп.
12.
АНАЛИЗ ДВУМЕРНОЙ ЗАВИСИМОСТИ.ТАБЛИЦЫ СОПРЯЖЕННОСТИ.
Анализ маркетинговой информации - это прежде всего исследование взаимосвязей, выявление
зависимости между несколькими признаками.
• Изучение взаимозависимостей начинается с выдвижения гипотез, которые содержат
предположения о наличии взаимосвязи между исследуемыми явлениями или данными.
Для их проверки применяются статистические методы.
• В простейшем случае каузальную зависимость можно описать следующим образом: X
определяет Y (где X – причина, а Y — следствие).
Например: юноши (Х-пол) чаще приобретают компьютерные игры (Y-частота приобретения),
чем девушки(Х-пол). Или частота приобретения компьютерных игр (Y) зависит от пола
покупателя (Х).
Это означает существование следующих отношений:
1. X влияет на Y (X → Y)
2. Если X не существует, то не существует и Y
3. Необходимое условие анализа каузальных зависимостей – требование ”при прочих равных
условиях“ (т.е. все остальные факторы никак не влияют на X и Y).
К сожалению, в маркетинговых исследованиях эти условия, как правило, не выполняются.
13.
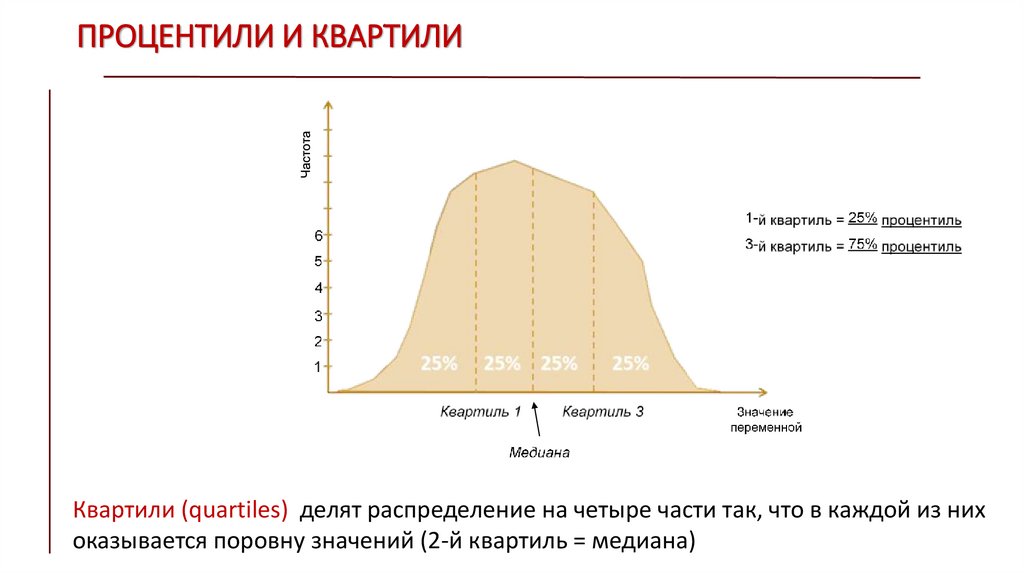
ПРОЦЕНТИЛИ И КВАРТИЛИКвартили (quartiles) делят распределение на четыре части так, что в каждой из них
оказывается поровну значений (2-й квартиль = медиана)
14.
АСИММЕТРИЯ. ЭКСЦЕССКоэффициент асимметрии А (skewness) – характеризует скошенность
распределения в сторону больших или меньших значений признака.
Это мера отклонения распределения частоты от симметричного
(нормального) распределения, то есть такого, у которого на
одинаковом удалении от среднего значения по обе стороны
выборки данных располагается одинаковое количество значений
Коэффициент асимметрии изменяется от минус до плюс
бесконечности, для нормальных распределений A=0
Если вершина асимметричного распределения сдвинута к меньшим значениям, то говорят о
положительной асимметрии (А>0), в противоположном случае — об отрицательной (А<0).
Коэффициент эксцесса Е (kurtosis) - характеризует степень
островершинности распределения. Коэффициент указывает, является
ли распределение пологим (при большом значении коэффициента)
или крутым.
Для нормального распределения Е=0
Для островершинного Е>0
Для плосковершинного Е<0
15.
ТАБЛИЦЫ СОПРЯЖЕННОСТИПозволяют исследовать взаимосвязи, выявлять отношения между
несколькими признаками - каузальную зависимость.
Каузальную зависимость можно описать следующим образом:
X определяет Y (где X – причина, а Y — следствие).
Это означает существование следующих отношений:
1. X влияет на Y (X → Y)
2. 2. Если X не существует, то не существует и Y
Например: Удовлетворенность доходом (X) и жилищными условиями (Y)
ведет к удовлетворенности условиями жизни в целом (Z)
Для применения метода таблиц сопряженности исследуемые признаки должны
измеряться в номинальной или порядковой шкале, возможны комбинации
значений обеих переменных, при этом значения одной переменной образуют
строки, а значения другой — столбцы таблицы.
16.
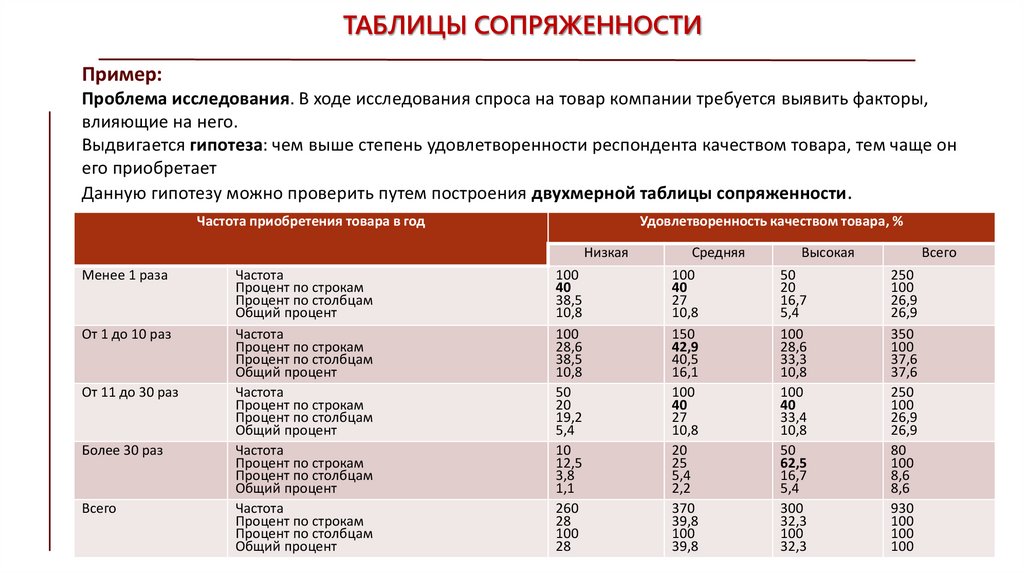
ТАБЛИЦЫ СОПРЯЖЕННОСТИПример:
Проблема исследования. В ходе исследования спроса на товар компании требуется выявить факторы,
влияющие на него.
Выдвигается гипотеза: чем выше степень удовлетворенности респондента качеством товара, тем чаще он
его приобретает
Данную гипотезу можно проверить путем построения двухмерной таблицы сопряженности.
Частота приобретения товара в год
Удовлетворенность качеством товара, %
Низкая
Менее 1 раза
От 1 до 10 раз
От 11 до 30 раз
Более 30 раз
Всего
Частота
Процент по строкам
Процент по столбцам
Общий процент
Частота
Процент по строкам
Процент по столбцам
Общий процент
Частота
Процент по строкам
Процент по столбцам
Общий процент
Частота
Процент по строкам
Процент по столбцам
Общий процент
Частота
Процент по строкам
Процент по столбцам
Общий процент
100
40
38,5
10,8
100
28,6
38,5
10,8
50
20
19,2
5,4
10
12,5
3,8
1,1
260
28
100
28
Средняя
100
40
27
10,8
150
42,9
40,5
16,1
100
40
27
10,8
20
25
5,4
2,2
370
39,8
100
39,8
Высокая
50
20
16,7
5,4
100
28,6
33,3
10,8
100
40
33,4
10,8
50
62,5
16,7
5,4
300
32,3
100
32,3
Всего
250
100
26,9
26,9
350
100
37,6
37,6
250
100
26,9
26,9
80
100
8,6
8,6
930
100
100
100
17.
Таблицы сопряжённости, логика анализаПодразделяя переменные на зависимую и независимую, рекомендуется
следовать следующему правилу:
• Если независимая переменная строковая, выбирайте строковые проценты
• Если независимая переменная столбцовая, выбирайте столбцовые.
Это соответствует логике анализа ”от причины к следствию“.
В нашем примере зависимая переменная – Частота приобретения товара в год – размещаем в строки
Независимая - Удовлетворенность качеством товара, % - размещаем в столбцы.
Анализируя полученную таблицу делаем выводы:
1. «Реже 1 раза в год» приобретают товар большинство респондентов с низким и средним уровнем
удовлетворенности: 40% и 40%.
2. «От 1 до 10 раз в год» - наибольшее количество респондентов со средним уровнем
удовлетворенности 42,9 %
3. От 11 до 30 раз в год покупают товар респонденты со средним и высоким уровнем
удовлетворенности – по 40% соответственно
4. Большинство респондентов с высоким уровнем удовлетворенности приобретают товар чаще 30
раз в год 62,5 %
Общий вывод: гипотеза подтверждается, удовлетворенность потребителей качеством товара влияет
на частоту его приобретения.
18.
Статистическая проверка наличия взаимосвязи между переменнымиИспользуется показатель:
Критерий ХИ-квадрат Пирсона – это показатель, фиксирующий степень расхождения реальных и
ожидаемых частот.
Как делаем вывод?
• если значимость ХИ-квадрат = 0, значит признаки независимы (меньше 0,05)
• если значимость ХИ-квадрат от 0,05 до 0,1 – трудно сказать
• если значимость ХИ-квадрат больше 0,1 значит признаки зависимы
• чем значимость ХИ-квадрат меньше, тем меньше различия между реальными и
ожидаемыми частотами, и наоборот
При построении таблиц сопряженности обязательно проверять существование связи через
хи-квадрат!!! Можно не приводить в таблице, но указать в сноске, что коэффициенты значимы.
Критерии хи-квадрат
Хи-квадрат Пирсона
Отношения правдоподобия
Линейно-линейная связь
Количество допустимых
наблюдений
Асимптотическ
ая значимость
Значение
ст.св. (2-сторонняя)
a
605,473
484
,000
559,252
484
,010
2,979
1
,084
500
Критерии хи-квадрат
Хи-квадрат Пирсона
Отношения
правдоподобия
Линейно-линейная связь
Количество допустимых
наблюдений
Значение
8,490a
Асимптотическа
я значимость
ст.св.
(2-сторонняя)
11
,669
8,525
11
,666
,371
1
,542
500
19.
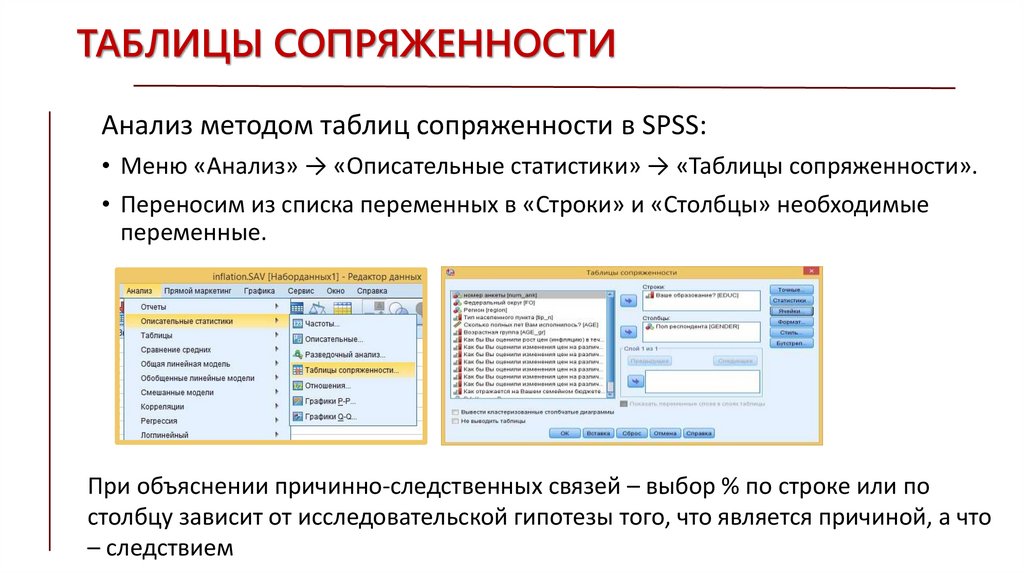
ТАБЛИЦЫ СОПРЯЖЕННОСТИАнализ методом таблиц сопряженности в SPSS:
• Меню «Анализ» → «Описательные статистики» → «Таблицы сопряженности».
• Переносим из списка переменных в «Строки» и «Столбцы» необходимые
переменные.
При объяснении причинно-следственных связей – выбор % по строке или по
столбцу зависит от исследовательской гипотезы того, что является причиной, а что
– следствием
20.
Методы статистического анализа маркетинговойинформации
Описательные статистики
количество респондентов,
предпочитающих конкретную марку;
выбор самой многочисленной группы
респондентов;
разделение данных на группы,
отвечающих определенным требованиям
Корреляционный анализ
Оценки взаимосвязи между двумя
количественными величинами:
• объемами продаж и затратами на
рекламу;
• объемами продаж и ценой продукции;
• Уровнем удовлетворенности и средним
чеком потребителя
Дисперсионный анализ
Регрессионный анализ
Оценка влияния номинальной (качественной
величины) на количественную:
• влияют ли характеристики товара на
сумму, которую респондент готов
потратить на его приобретение;
• влияет ли уровень дохода на размер
среднего чека респондента
Построение модели зависимости между
показателями:
• объясняются ли различия в объемах
продаж различием расходов на
продвижение;
• какие объемы продаж можно ожидать
при заданных ценах
Факторный анализ
Кластерный анализ
Обобщение данных, группировка в
группы по общим признакам
сегментирование рынка;
определение предпочтений
потребителей
выявление особенностей восприятия
потребителем рекламного продукта
Определение целевых групп
потребителей
сегментирование на основе отношения к
различным характеристикам товара;
Сегментирование на основе
особенностей потребительского
поведения
21.
Список рекомендуемой литературы1.
2.
3.
Изакова Н. Б.. Маркетинговые исследования с применением пакета SPSS
[Электронный ресурс]:учебное пособие. - Екатеринбург: [2018]. Режим доступа:
http://meu.usue.ru/lessons/index.html
Солосиченко Т. Ж.. Маркетинговые исследования [Электронный ресурс]:учебное
пособие. - Екатеринбург: [Издательство УрГЭУ], 2017. - 121 с. Режим доступа:
http://lib.usue.ru/resource/limit/ump/17/p488707.pdf
Басовский Л. Е., Басовская Е. Н.. Маркетинг [Электронный ресурс]:учебное пособие
для студентов вузов, обучающихся по направлению 38.03.02 "Менеджмент". Москва: ИНФРА-М, 2016. - 300 с. – Режим доступа:
http://znanium.com/go.php?id=544241