















 Информатика
ИнформатикаПохожие презентации:










Ввод данных в SPSS. Обработка данных
1.
МИНОБРНАУКИ РОССИИфедеральное государственное бюджетное
образовательное учреждение
высшего образования
«ЧЕРЕПОВЕЦКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ»
Гуманитарный институт
Кафедра социологии и социальных технологий
Дисциплина Современные методы анализа социологических данных
Ввод данных в SPSS.
Обработка данных.
Череповец
2017 г.
2.
Лист ввода переменныхName (имя
переменной)
Type (тип
переменной)
Имя
NUMERIC
(числовые)
8
(по
умолчанию)
2
Вопрос из
(0 – для
анкеты
номинальных (полностью)
шкал)
Values
(значения)
Missing
(пропуски)
Columns
(ширина)
Align
Measure (тип
(выравниван шкалы
ие)
измерения
переменных)
1 = вариант
ответа
2 = вариант
ответа …
None (Нет) по
умолчанию
Нечаева С. А. ЧГУ.2017г.
Width
(ширина)
8
по
умолчанию
Decimals
(десятичные
значения)
По правому
краю
(по
умолчанию)
Label (метка
переменной)
Scale
(по
умолчанию)
2
3.
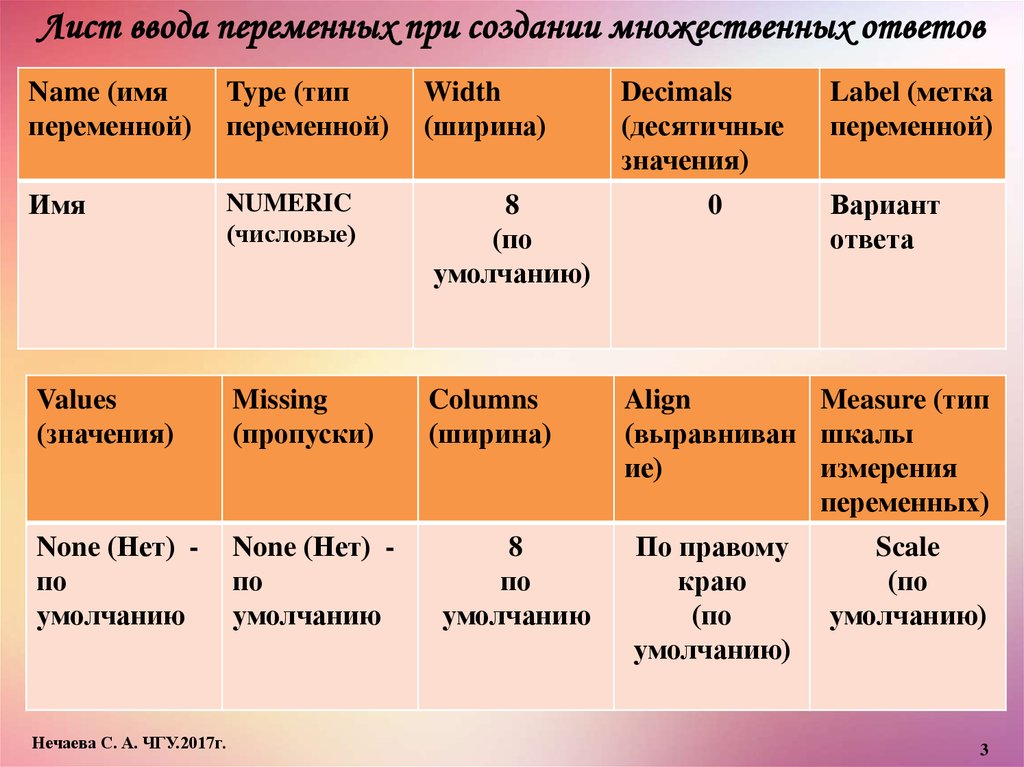
Лист ввода переменных при создании множественных ответовName (имя
переменной)
Type (тип
переменной)
Имя
NUMERIC
(числовые)
8
(по
умолчанию)
Values
(значения)
Missing
(пропуски)
Columns
(ширина)
None (Нет) по
умолчанию
None (Нет) по
умолчанию
Нечаева С. А. ЧГУ.2017г.
Width
(ширина)
8
по
умолчанию
Decimals
(десятичные
значения)
0
Label (метка
переменной)
Вариант
ответа
Align
Measure (тип
(выравниван шкалы
ие)
измерения
переменных)
По правому
краю
(по
умолчанию)
Scale
(по
умолчанию)
3
4.
Обработка данныхДанные – результат регистрации
социальных явлений, отношений, фактов
поведения людей.
Обработка данных - необходимая
табличная и графическая форма
представления и анализа совокупной
социологической информации.
Обработка данных включает:
1.Одномерный анализ, который осуществляется,
если целью является описание одной
характеристики выборки в определенный
момент времени.
2.Многомерный анализ – позволяет
одновременно исследовать взаимоотношения
двух и более переменных, в той или иной форме
проверять гипотезы о причинных связях между
ними.
Нечаева С. А. ЧГУ.2017г.
4
5.
Одномерный анализ. Виды:1.Группировка – обобщение первичной
социологической информации в соответствии с
выбранным признаком (признаками)
группировки.
2.Линейное (одномерное) распределение –
распределение числа голосов респондентов,
отданных каждому варианту ответа.
3.Определение средних
показателей.
4.Определение характеристик
разброса.
5.Интервальное оценивание.
6.Ранжирование.
Нечаева С. А. ЧГУ.2017г.
5
6.
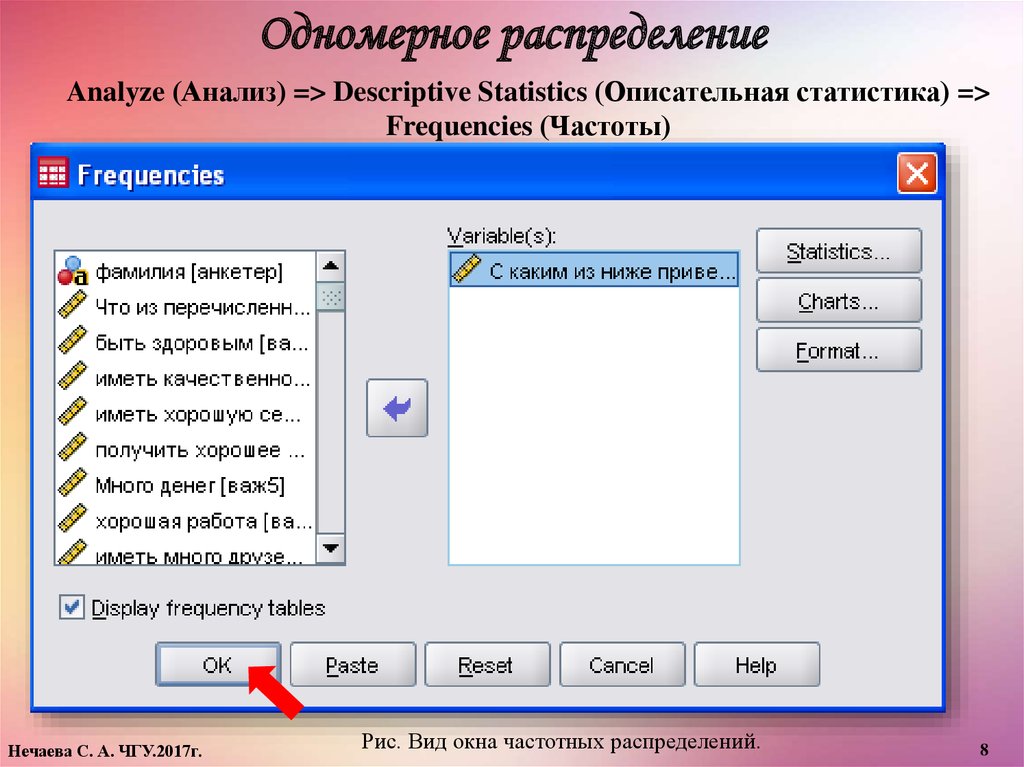
Одномерное распределениеAnalyze (Анализ) => Descriptive Statistics (Описательная статистика) =>
Frequencies (Частоты)
Нечаева С. А. ЧГУ.2017г.
6
7.
Одномерное распределениеAnalyze (Анализ) => Descriptive Statistics (Описательная статистика) =>
Frequencies (Частоты)
Нечаева С. А. ЧГУ.2017г.
Рис. Вид окна частотных распределений.
7
8.
Одномерное распределениеAnalyze (Анализ) => Descriptive Statistics (Описательная статистика) =>
Frequencies (Частоты)
Нечаева С. А. ЧГУ.2017г.
Рис. Вид окна частотных распределений.
8
9.
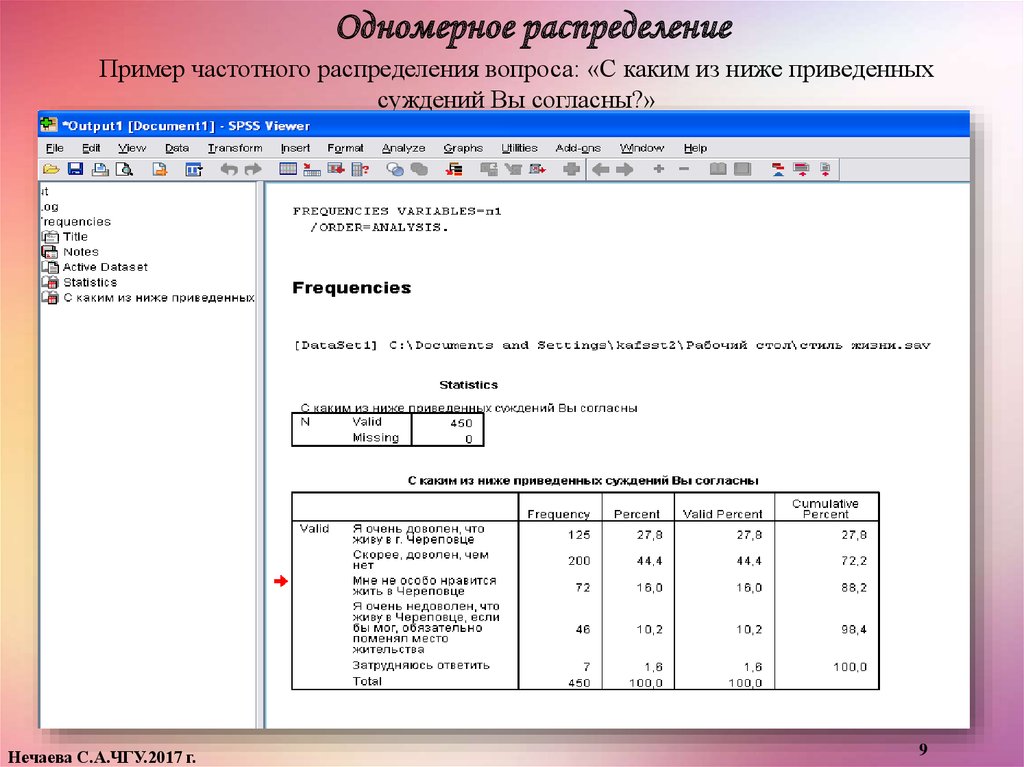
Одномерное распределениеПример частотного распределения вопроса: «С каким из ниже приведенных
суждений Вы согласны?»
Нечаева С.А.ЧГУ.2017 г.
9
10.
Одномерное распределениеТермины, используемые программой в окне вывода данных:
Frequency (Частота) – число объектов, соответствующих каждой
категории (градации) переменной (число респондентов, выбравших
соответствующий вариант ответа)
Percent (Процент) – процент от общей численности (с учетом пропусков).
Если в файле есть пропущенные значения, то их процент указан в
предпоследней строке Missing System.
Total (Итого) – итоговые значения.
Valid percent (Валидный процент) –
процент значений для каждой
категории за вычетом пропущенных
значений.
Cumulative percent (Кумулятивный
процент) – накопленный процент
величины Valid percent.
Valid (Валидные значения) – список
градаций (значений) переменной.
Нечаева С.А.ЧГУ.2017 г.
10
11.
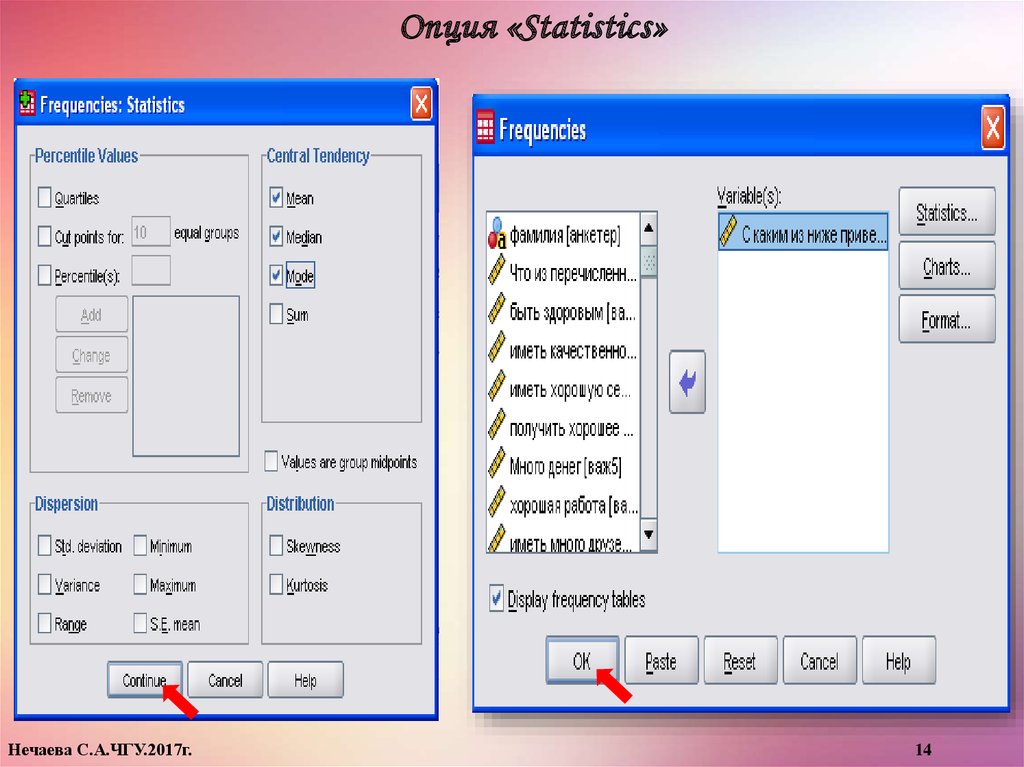
Опция «Statistics»Нечаева С.А.ЧГУ.2017г.
Рис.Вид опции «Statistics»
11
12.
Опция «Statistics»Первая группа – меры центральной тенденции, вокруг которых
«группируются» данные: среднее значение, медиана, мода.
Вторая группа характеризует изменчивость значений
переменной относительно среднего: среднее отклонение и
дисперсия.
Диапазон изменчивости
характеризуется минимумом,
максимумом и размахом.
Ассиметрия и эксцесс
представляют меру отклонения
формы распределения от
нормального вида.
Нечаева С.А.ЧГУ.2017г.
12
13.
Меры центральной тенденцииМеры центральной тенденции
– характеристики,
предназначенные для описания
центра распределения.
Среднее арифметическое значение (mean) равно сумме всех
значений распределения, деленной на их количество.
Медиана (median) – значение, находящееся в середине
распределения, полученного из исходного путем
упорядочивания по возрастанию.
Мода (mode) равна наиболее часто встречающемуся
значению.
Нечаева С.А.ЧГУ.2017г.
13
14.
Опция «Statistics»Нечаева С.А.ЧГУ.2017г.
14
15.
Опция «Statistics»Нечаева С.А.ЧГУ.2017г.
Рис. Пример
15
16.
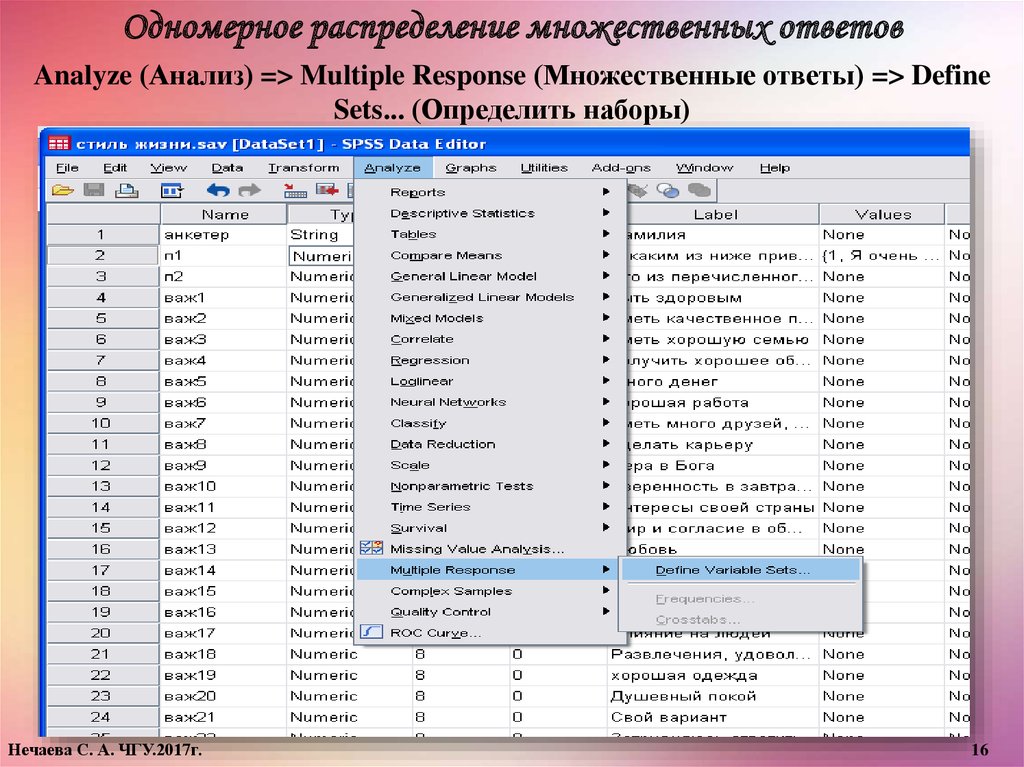
Одномерное распределение множественных ответовAnalyze (Анализ) => Multiple Response (Множественные ответы) => Define
Sets... (Определить наборы)
Нечаева С. А. ЧГУ.2017г.
16
17.
Одномерное распределение множественных ответовAnalyze (Анализ) => Multiple Response (Множественные ответы) => Define
Sets... (Определить наборы). => Откроется диалоговое окно Define Multiple
Response Sets (Определение наборов ответов)
Нечаева С. А. ЧГУ.2017г.
17
18.
Одномерное распределение множественных ответовНечаева С. А. ЧГУ.2017г.
18
19.
Одномерное распределение множественных ответовНечаева С. А. ЧГУ.2017г.
19
20.
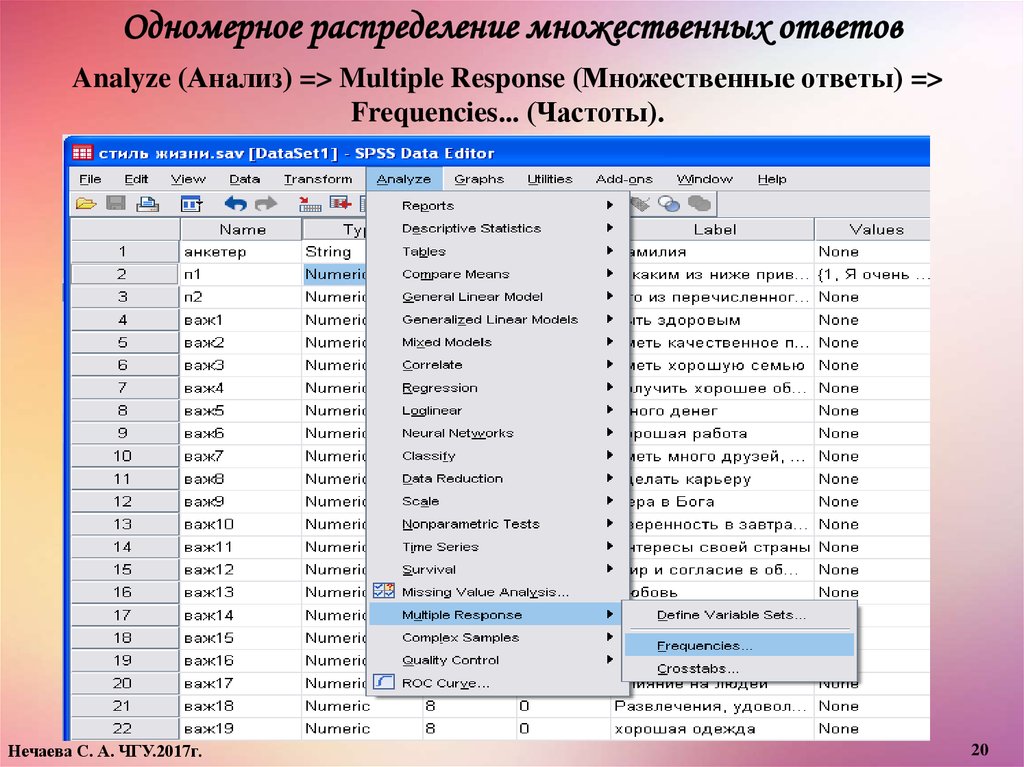
Одномерное распределение множественных ответовAnalyze (Анализ) => Multiple Response (Множественные ответы) =>
Frequencies... (Частоты).
Нечаева С. А. ЧГУ.2017г.
20
21.
Одномерное распределение множественных ответовAnalyze (Анализ) => Multiple Response (Множественные ответы) =>
Frequencies... (Частоты).
=>
Нечаева С. А. ЧГУ.2017г.
21
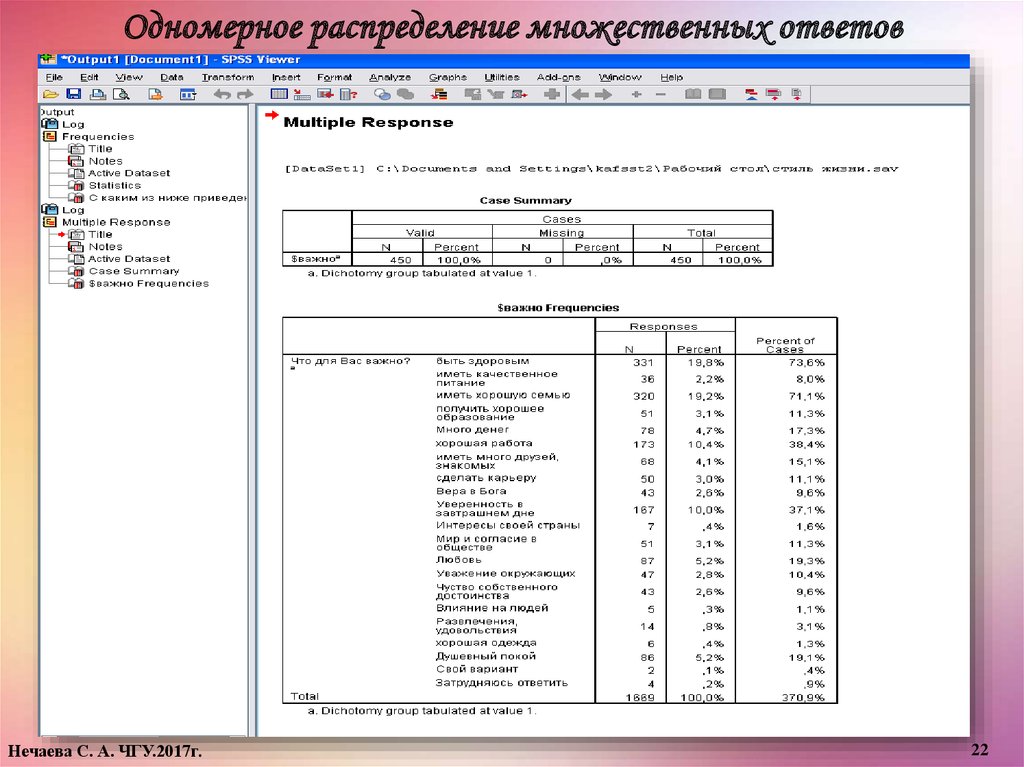
22.
Одномерное распределение множественных ответовНечаева С. А. ЧГУ.2017г.
22
23.
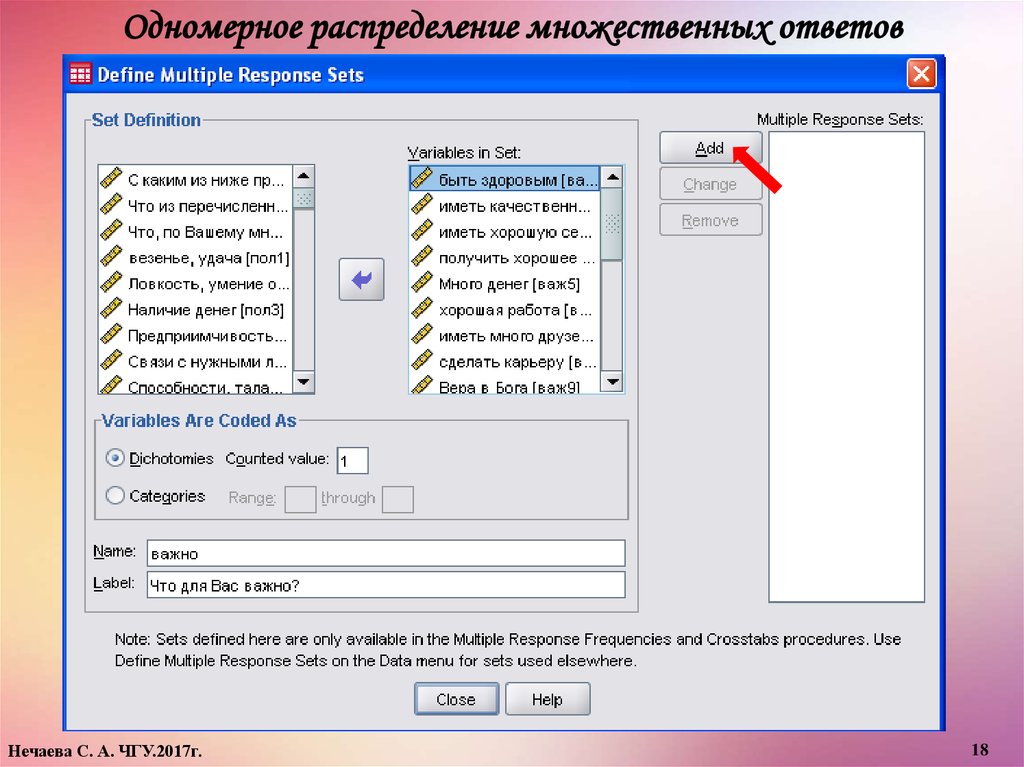
Одномерное распределение множественных ответов1.Выделить в списке исходных переменных нужные переменные и
перенести их в список Variables in Set (Переменные в наборе).
2.Задать дихотомическую кодировку переменных (опция Dichotomies в
группе Variables Are Coded As). Настройка выбирается по умолчанию.
3.В поле Counted Value (Учитываемое значение) ввести "1".
4.Присвоить набору «имя» и метку, соответствующую полной
формулировке вопроса.
5.Щелкнуть на кнопке Add (Добавить), и созданный набор будет внесен в
список наборов множественных ответов (Mult Response Sets). SPSS начинает
имена наборов переменных со знака доллара.
6.Щелкнуть по кнопке Close (Закрыть), чтобы закончить процесс
определения набора.
Analyze (Анализ) => Multiple Response (Множественные ответы) =>
Frequencies... (Частоты).
Нечаева С. А. ЧГУ.2017г.
23