



























 Программное обеспечение
Программное обеспечениеПохожие презентации:


")



")



Корпусные технологии (семинар № 4)
1.
Цифроваяграмотность
(Digital
Literacy)
Корпусные
технологии. Неделя II.
Семинар № 4
Презентация: Бударин Д.Е.
2.
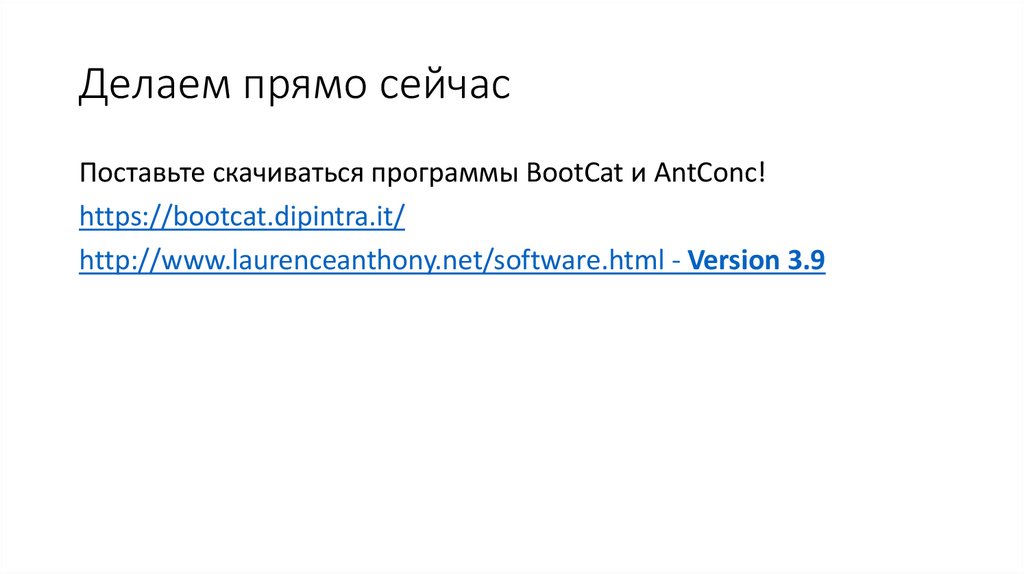
Делаем прямо сейчасПоставьте скачиваться программы BootCat и AntConc!
https://bootcat.dipintra.it/
http://www.laurenceanthony.net/software.html - Version 3.9
3.
Вспоминаем что такое «корпусныетехнологии»?
Лингвистический корпус - что это?
Из чего может состоять лингвистический корпус?
Как классифицируются корпуса?
Какие могут быть свойства у корпуса?
Что можно изучать?
Как мы отсчитываем IPM и для чего?
4.
Почитать про корпусаИсследования на и об НКРЯ
Еще про использование НКРЯ
Что такое корпус и с чем его едят
Национальный корпус русского языка
https://ruscorpora.ru
5.
Юридический аспектВажно проверять, можно ли использовать данные, которые вы
обнаружили.
Пример - НКРЯ и страница “использование корпуса”
6.
Обсудим контрольные точки проекта• выбор темы
1. формулировка цели проекта;
2. поиск литературы;
3. поиск и сбор материалов;
4. обработка найденных материалов, визуализация результатов;
5. представление проекта.
7.
Примерный план проекта23.10 — Определение цели
13.11 — Обзор статей и мнений по теме
20.11 — Сбор материалов
11.12 — Их обработка
22.12 — Выступление о проекте.
Во время зимней сессии
8.
Как придумывать задачи проекта?SMART
Хорошие задачи должны быть:
• Точными и конкретными
«Найти статьи»
«Найти не менее 3 научных статей по нашей теме с хорошим
цитированием»
• Измеримыми
«Узнать мнение посетителей»
«найти 5 заметок в местных СМИ»
• Достижимыми
«Прореферировать 100 научных статей»
«прореферировать по 2 статьи на участника»
9.
Как придумывать задачи проекта?SMART
Хорошие задачи должны быть:
• Релевантными
«Нарисовать логотип нашему проекту»
• Имеющими сроки
«Сделать до дедлайна»
«Сделать до 18 ноября, чтобы успеть показать остальным, и сдать
работу к 20-у»
10.
Обсудим тему, задачи и источники данных-
*выступление на 2 минуты от каждой команды
Изменилась ли ваша тема за прошедшую неделю?
Какие задачи стоят перед вашей командой?
Какие источники данных вы будете привлекать для сбора корпуса?
(в случае, если вы выполняете корпусное исследование)
11.
Оцениваемое задание: Определение целипроекта
Срок сдачи: суббота, 23 октября 2022, 23:59
1.
создана общая папка, к которой предоставлены права комментатора
по ссылке.
2.
внутри папки создан текстовый файл «Отчёт “название
команды/проекта”» с названием проекта, списком команды, темой
проекта, целью проекта, задачами проекта.
3.
внутри папки создан файл «Обратная связь проекта», куда
скопированы комментарии из форума выбора темы и указаны
выводы, которые команда по обратной связи сделала.
12.
Откуда взять данные?Bootstrap Corpora And Terms from the Web (BooTCaT)
● Бесплатный инструмент для автоматического построения
корпуса, основанного на материалах веб-страниц.
● Создание специального корпуса по конкретной проблематике
для составления терминологических списков, технических
переводов, машинного обучения и т.д.
13.
Этапы работы в BooTCaT1. Создание списка seeds, т.е. ключевых слов (или сочетаний), которые
определяют исследуемую сферу.
2. Сочетание этих слов в случайные группы (tuple) (последовательности
из n слов).
3. Запросы в поисковую систему для нахождения web-страниц,
содержащих сгенерированные группы.
4. Загрузка подходящих web-страниц, удаление лишнего HTML-кода и,
наконец, формирование корпуса.
14.
Задаем название корпуса, выбираем язык.Можно подключить черный список
15.
Выбираем метод сбора корпуса и источники16.
Создаем список ключевых слов17.
Генерируем случайные группы из ключевыхслов
18.
Отправляем запрос для нахождения страниц,содержащих необходимые слова
19.
Открываем найденные страницы, сохраняем впапку BootCaT Corpora\Мой корпус\queries
20.
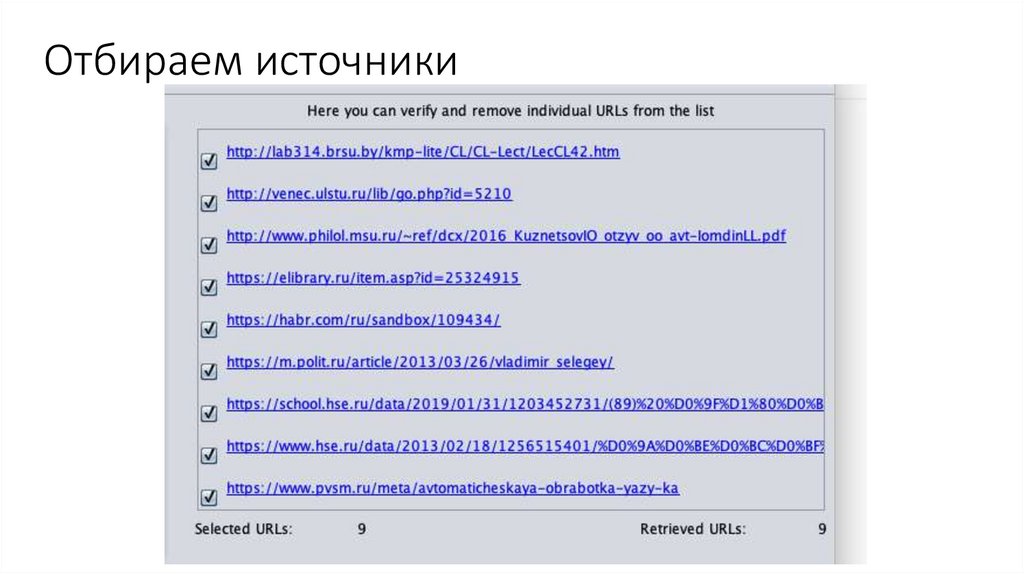
Отбираем источники21.
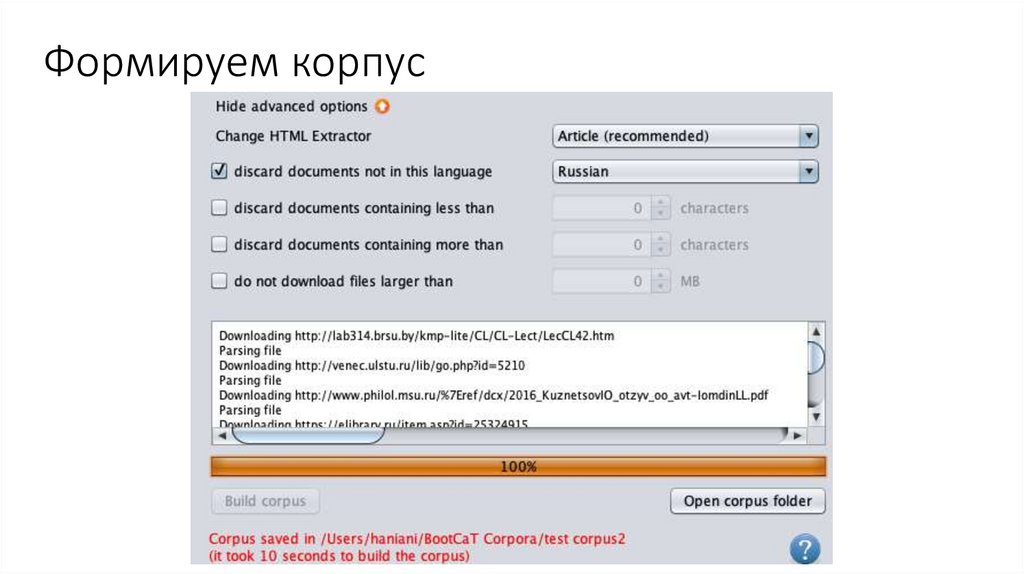
Формируем корпус22.
Плюсы и минусы➕
Простота использования
Быстрота и результативность
Удобный инструмент для подготовки
корпусов и использовании в разных
задачах вместе с другими
инструментами, например:
○
○
BootCaT -> MyStem -> AntConc
BootCaT -> Python
➖
Нельзя предсказать, какие документы
найдет поисковик
Нет метаданных
Возможно нахождение дубликатов и
мусорных текстов
23.
AntConchttp://www.laurenceanthony.net/software.html
С помощью данной программы можно производить поиск и подсчет
различных элементов текста, анализировать частотность и контекст
употребления словоформ, словосочетаний и морфем, сравнивать
употребительность словоформ в разных текстах.
Программа может быть использована для получения привязанных к
заданной предметной области словарных минимумов, списков
устойчивых сочетаний (в том числе терминологических), выборок к
тематическим группам слов.
24.
1. Открываем во второй сверху строке меню кнопку «Word List» (втораясправа) и нажимаем кнопку «Start» (внизу ближе к левому краю).
Программа выстроит все словоформы текста в порядке частотности
2. Можно сортировать и по другим критериям. Если вместо «Sort by
Freq» (в самом низу) выбрать «Sort by Word», произойдет сортировка по
алфавиту, если выбрать «Sort by Word End», сортировка пойдет по концу
слов.
3. Если к тому же поставим галочку между фразами «Sort by» и «Invert
Order», то сортировка пойдет в обратном порядке — от редких слов к
частым или от я до а .
25.
4. Можно кликнуть из списка любое слово, начнется его автоматическийпоиск в окне Concordance.
Конкорданс – это список всех употреблений заданного языкового
выражения (например, слова) в контексте со ссылками на источник.
5. Если открыто окно Concordance, искомое слово можно ввести в
окошко, находящееся между кнопкой «Start» и фразой «Search Term» и
нажать «Start». Будет происходить поиск данного слова в контекстах.
В НКРЯ нечто похожее было тогда, когда мы выводили в KWIC.
26.
6. Если убрать галочку над тем же окошком между словами «SearchTerm» и «Words», можно будет искать не только конкретную форму
слова, но и похожие формы напр. пишем пукт — выйдет пукта, пуктіс,
пукты и т. п.
График конкорданса. В этом инструменте все адреса для каждого
элемента поиска представлены в виде “штрих-кода”, указывающего на
место в файле, где находится элемент. График позволяет увидеть, какие
файлы включают искомый элемент. Он также может быть использован
для определения, где сталкиваются искомый элемент и кластер.
27.
Кластеры. Инструмент кластеры используется для созданияупорядоченного списка кластеров, которые появляются вокруг поиска в
целевом файле, перечисленные в левой части главного окна.
Коллокации. Коллокацией называется словосочетание, имеющее
признаки синтаксически и семантически целостной единицы, в котором
выбор одного из компонентов осуществляется по смыслу, а выбор
второго зависит от выбора первого.
Список слов. Данный инструмент подсчитывает все слова в корпусе и
представляет их в упорядоченном списке. Это позволяет быстро найти,
какие слова употребляются наиболее часто в корпусе.
28.
Список ключевых слов. В дополнение к созданию списка слов, спомощью AntConc можно сравнить слова в целевом файле со словами,
которые появляются в «базисном корпусе», чтобы создать список
"Ключевых слов", которые являются наиболее частыми (или редкими) в
целевых файлах.
29.
Задание: BootCat, AntConc1. Соберите корпус БутКетом из 10*N статей минимум
N – число участников
2. Откройте его в AntConc, посмотрите самые частотные слова.
3. Добавьте список стоп-слов, снова проверьте частотые слова.
4. Кликнув на 3 ключевых, по вашему мнению, (или других интересных)
слова, посмотрите их конкордансы.
5. Постройте частотный список двух-, трех- и т.д. -словных словосочетаний
(вкладка Cluster/N-Grams, поставьте галочку на N-Grams, укажите, сколько
слов в ngram-е вы хотите видеть, например, Min:3, Max:3, установите порог
вхождений в корпусе, например, 10). Кликнув на n-грам, вы также можете
попасть в его конкорданс.
30.
Форма сдачи задания● Задание сдается на странице SmartLMS по ссылке внутри.
Срок сдачи – 26.10.2022, до 23:59.
1. Создайте облачный документ или документ MS Word.
2. Напишите тему, которой будет посвящен Ваш корпус.
3. Укажите список ключевых слов по которым проводили сбор
корпуса.
4. Запишите результаты и прикрепите скриншоты по итогу
выполнения каждого задания (№ 3 – 5) из слайда «Задание по
BootCat, AntConc».
5. При работе с ключевыми словами/конкордансами/n-gram’ами
обратите внимание на их электронные источники. Укажите
источники с самым частым употреблением выбранных
слов/конкордансов (не более 3-х)
31.
Вы можете выбрать тему из предложенныхили придумать собственную.
● Древняя Русь, язычество, крещение, 988, традиции;
● Вильгельм Завоеватель, Гарольд Годвинсон, 14 октября 1066,
Англия, Гастингс;
● Гуманитарные науки, историческое исследование, методология,
высшее образование, периодизация (осторожно, требуется тщательная
фильтрация);
● Воинская слава, героизм, история, подвиг, храбрость;
Или
● Попробуйте придумать свою тему с уникальным набором
поисковых слов*