














 Программное обеспечение
Программное обеспечениеПохожие презентации:

")








Системы искусственного интеллекта
1.
СИСТЕМЫИСКУССТВЕННОГО
ИНТЕЛЛЕКТА
Москат Н.А.
Лекция 2
2.
Scikit Learn:Обучение с учителем.Линейные модели
3.
Построение модели k-ближайшихсоседей (k-NN) с помощью Scikit-learn
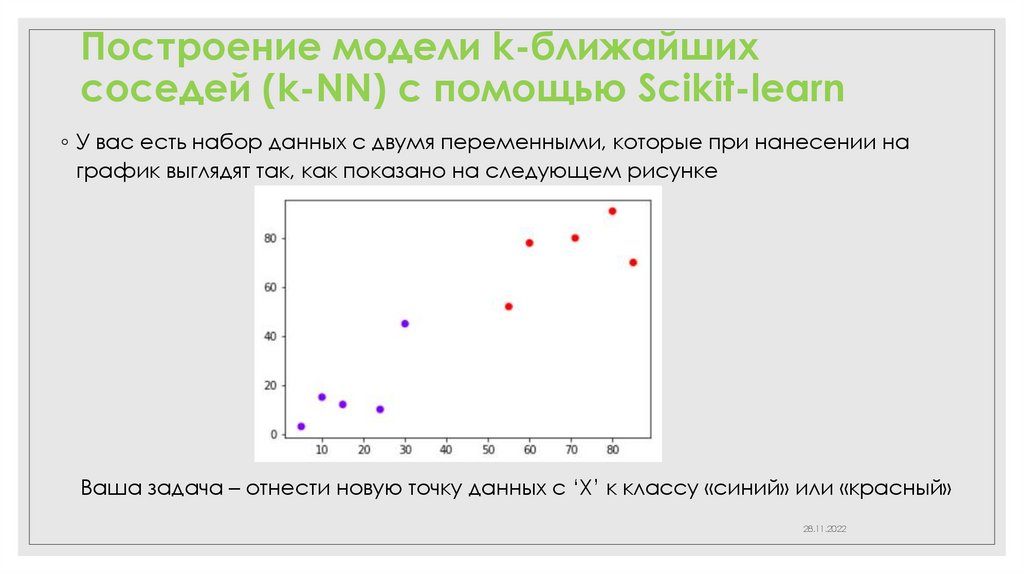
◦ У вас есть набор данных с двумя переменными, которые при нанесении на
график выглядят так, как показано на следующем рисунке
Ваша задача – отнести новую точку данных с ‘X’ к классу «синий» или «красный»
28.11.2022
4.
◦ Предположим, значение K равно 3. Алгоритм KNN начинается с вычисления расстоянияточки X от всех точек. Затем он находит 3 ближайшие точки с наименьшим расстоянием
до точки X. Это показано на рисунке ниже. Обведены три ближайшие точки
◦ Последним шагом алгоритма KNN является присвоение новой точки классу, которому
принадлежит большинство из трех ближайших точек. Из рисунка выше видно, что две из
трех ближайших точек относятся к классу «Красный», а одна – к классу «Синий». Поэтому
новая точка данных будет классифицирована как «красная».
28.11.2022
5.
◦ Плюсы1. Простая реализация.
2. Это алгоритм ленивого обучения, поэтому он не требует обучения перед тем, как
делать прогнозы в реальном времени. Это делает алгоритм KNN намного быстрее, чем
другие алгоритмы, требующие обучения, например SVM, линейная регрессия и т.д.
3. Поскольку алгоритм не требует обучения перед выполнением прогнозов, новые данные
можно добавлять без проблем.
4. Для реализации KNN требуются только два параметра, то есть значение K и функция
расстояния (например, евклидова или манхэттенская и т.д.)
◦ Минусы
1. Алгоритм KNN плохо работает с данными большого размера, потому что при большом
количестве измерений алгоритму становится сложно вычислять расстояние в каждом
измерении.
2. Алгоритм KNN имеет высокую стоимость прогнозирования для больших наборов
данных. Это связано с тем, что в больших наборах данных стоимость вычисления
расстояния между новой точкой и каждой существующей точкой становится выше.
3. Алгоритм KNN плохо работает с категориальными признаками, поскольку трудно найти
расстояние между измерениями с категориальными признаками
28.11.2022
6.
Набор данных растений ириса◦ Характеристики набора данных:
◦ Количество экземпляров: 150 (по 50 в каждом из трех классов)
◦ Количество атрибутов: 4 числовых, 3 прогнозных атрибута и класс
◦ Информация об атрибутах
◦ длина чашелистика в см
◦ ширина чашелистика в см
◦ длина лепестка в см
◦ ширина лепестка в см
◦ класс:
◦ Ирис-Сетоса
◦ Ирис-разноцветный
◦ Ирис-Вирджиния
◦ Отсутствующие значения атрибутов: Нет
◦ Распределение классов: 33,3% за каждый из 3 классов.
◦ Создатель: Р. А. Фишер
◦ Дата: Июль: 1988 г.
28.11.2022
7.
Реализация алгоритма KNN◦ Набор данных состоит из четырех атрибутов: ширина чашелистика, длина
чашелистика, ширина лепестка и длина лепестка. Это атрибуты конкретных видов
ириса. Задача – предсказать, к какому классу принадлежат эти растения. В наборе
данных три класса: Iris-setosa, Iris-versicolor и Iris-virginica
◦ Импорт библиотек, импорт набора данных
28.11.2022
8.
◦ Чтобы увидеть, как на самом деле выглядит набор данных, выполните следующуюкоманду:
28.11.2022
9.
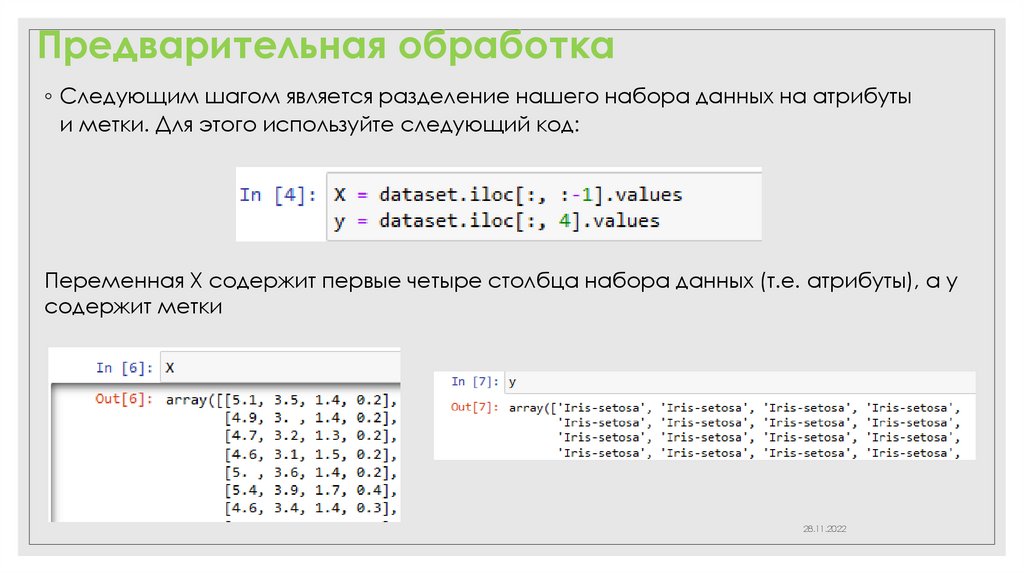
Предварительная обработка◦ Следующим шагом является разделение нашего набора данных на атрибуты
и метки. Для этого используйте следующий код:
Переменная X содержит первые четыре столбца набора данных (т.е. атрибуты), а y
содержит метки
28.11.2022
10.
Тестовый сплит◦ Разделим наш набор данных на обучающие и тестовые части, что даст нам лучшее
представление о том, как наш алгоритм работал на этапе тестирования. Таким образом,
наш алгоритм тестируется на невидимых данных
◦ В Scikit-learn есть функция, которую мы можем использовать, называемая train_test_split,
которая позволяет легко разделить наш набор данных на данные обучения и тестирования.
◦ Чтобы создать тренировочные и тестовые сплиты, выполните следующий скрипт:
◦ ‘Train_test_split’ принимает 3 параметра. Первые два параметра - это входные и целевые
данные, которые мы разделили ранее. Далее мы установим «test_size» равным 0,2. Это
означает, что 20% всех данных будут использоваться для тестирования, что оставляет 80%
данных в качестве обучающих данных для модели для изучения.
◦ В нашем датасете из 150 записей, обучающий набор будет содержать 120 записей, а
тестовый набор – 30 из этих записей.
28.11.2022
11.
Масштабирование функций◦ Перед тем, как делать какие-либо фактические прогнозы, всегда рекомендуется
масштабировать функции, чтобы все они могли быть оценены единообразно
Поскольку диапазон значений необработанных данных сильно различается, в
некоторых алгоритмах машинного обучения целевые функции не будут работать
должным образом без нормализации.
◦ Диапазон всех функций должен быть нормализован так, чтобы каждая функция
вносила вклад приблизительно пропорционально конечному расстоянию
Следующий скрипт выполняет масштабирование функций
28.11.2022
12.
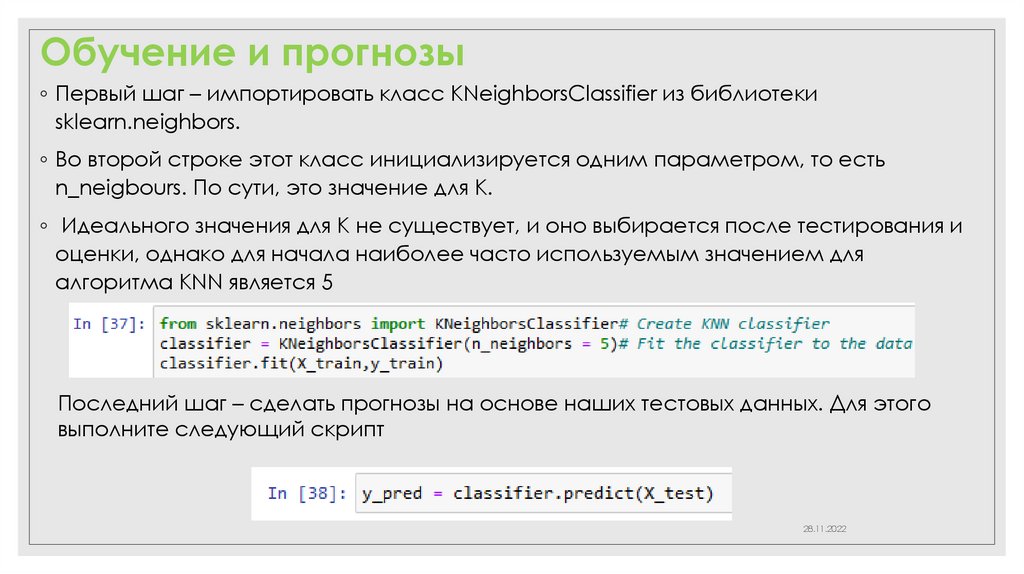
Обучение и прогнозы◦ Первый шаг – импортировать класс KNeighborsClassifier из библиотеки
sklearn.neighbors.
◦ Во второй строке этот класс инициализируется одним параметром, то есть
n_neigbours. По сути, это значение для K.
◦ Идеального значения для K не существует, и оно выбирается после тестирования и
оценки, однако для начала наиболее часто используемым значением для
алгоритма KNN является 5
Последний шаг – сделать прогнозы на основе наших тестовых данных. Для этого
выполните следующий скрипт
28.11.2022
13.
Оценка алгоритма◦ Для оценки алгоритма наиболее часто используемыми метриками являются
матрица неточностей, точность, отзывчивость и оценка f1. Для вычисления этих
показателей можно использовать методы confusion_matrix и classification_report из
sklearn.metrics.
Результаты показывают, что наш алгоритм KNN смог классифицировать все 30 записей
в тестовом наборе со 100% точностью, что превосходно
14.
Сравнение частоты ошибок созначением K
◦ В разделе обучения и прогнозирования мы сказали, что невозможно заранее узнать,
какое значение K дает наилучшие результаты с первого раза.
◦ Мы случайно выбрали 5 в качестве значения K, и это дает 100% точность. Один из
способов помочь вам найти наилучшее значение K – построить график значения K и
соответствующего коэффициента ошибок для набора данных
28.11.2022
15.
◦ построим график средней ошибки для предсказанных значений тестовогонабора для всех значений K от 1 до 40
Для этого давайте сначала вычислим среднее значение ошибки для всех
прогнозируемых значений, где K находится в диапазоне от 1 до 40
Сценарий выполняет цикл от 1 до 40. На каждой итерации вычисляется средняя
ошибка для предсказанных значений тестового набора, и результат добавляется в
список ошибок.
28.11.2022
16.
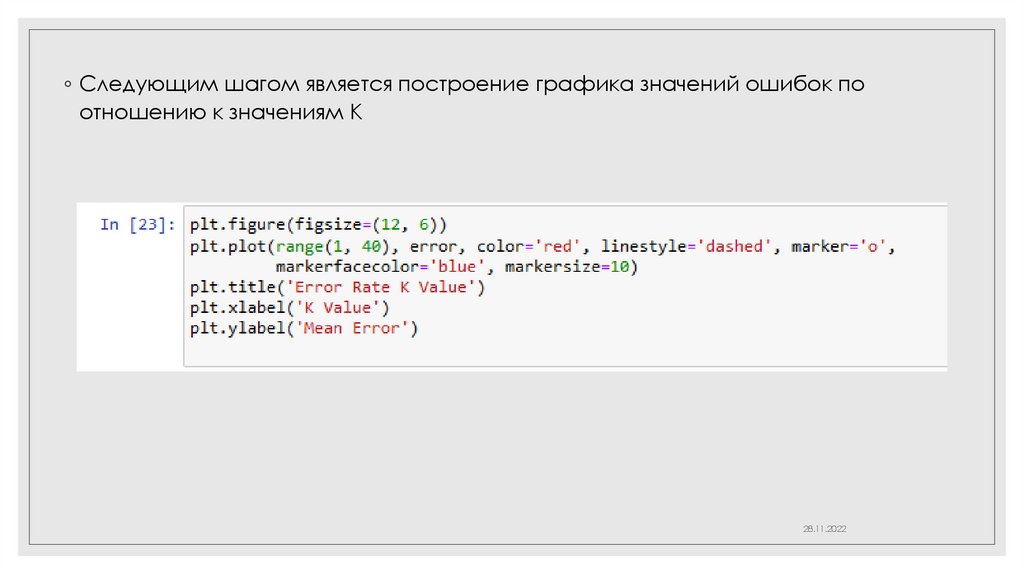
◦ Следующим шагом является построение графика значений ошибок поотношению к значениям K
28.11.2022
17.
◦ Выходной график выглядит так:Из выходных данных мы видим, что средняя ошибка равна нулю, когда значение K находится в
диапазоне от 5 до 18.
Совет ! поработать со значением K, чтобы увидеть, как оно влияет на точность прогнозов
28.11.2022
18.
Заключение◦ KNN – это простой, но мощный алгоритм классификации. Он не требует обучения
для прогнозирования, что обычно является одной из самых сложных частей
алгоритма машинного обучения.
◦ Задание! реализовать алгоритм KNN для другого набора данных классификации.
Измените размер теста и обучения вместе со значением K, чтобы увидеть, как
различаются ваши результаты и как вы можете повысить точность своего алгоритма
28.11.2022