

























")




















 Программирование
Программирование Электроника
ЭлектроникаПохожие презентации:










Параллельное программирование
1. Параллельное программирование
Минязев Ринат Шавкатовичк.т.н., доцент
2. Структура курса
Темы лекций: 32 часа1. Введение: потребность в параллельных
программах, анализ эффективности, законы Амдала
2. Библиотека MPI: введение(ПИ), приемпередача, неблокирующие прием-передача,
топология, групповые операции
3. Библиотека OpenMP: введение, параллельные
циклы, критические секции
4. Программирование GPU: архитектура GPU,
примеры применения
Лабораторные работы: 32 часа
Зачет/Экзамен
2
3. Литература курса
ОсновнаяШпаковский Г.И., Серикова Н.В. Программирование
многопроцессорных систем в стандарте MPI – Минск.: БГУ, 2002.
Антонов А.С. Параллельное программирование с использованием
технологии OpenMP: Учебное пособие.-М.: Изд-во МГУ, 2009.
Сандерс Дж., Кэндрот Э. Технология CUDA в примерах, 2011.
Дополнительная
Воеводин В.В., Воеводин Вл.В. Параллельные вычисления.
СПб.:БХВ-Петербург, 2002
Портал http://www.parallel.ru
Информационный ресурс
Портал http://www.in-education.ru (login: stud428, pass:stud428)
3
4. Параллельное программирование
Лекция №1Введение
5. Спектр задач параллельного программирования
Моделирование газо- и гидро- динамики:- предсказание погоды, конструирование летательных
аппаратов (ansys fluent)
Синтез лекарств, исследование новых химических
веществ, молекулярная динамика (NAMD, VMD)
Crash-тесты автомобилей (ansys mechanicals)
Оптимизационные задачи, общая задача
нахождения экстремума
Обработка изображений и видео:
- анимация, спец.эффекты, распознавание образов
(Blender + менеджер рендер ферм афанасий)
5
6.
Ansys “Fluent”Оптимизация процесса проектно-конструкторской и
технологической подготовки в области вычислительной
динамики жидкостей и газов.
Программный модуль ANSYS FLUENT моделирует течение жидкостей и
газов для промышленных задач с учетом турбулентности,
теплообмена, химических реакций.
Примеры применения FLUENT: задачи обтекания крыла, горение в
печах, течение внутри барботажной колонны, внешнее обтекание
нефтедобывающих платформ, течение в кровеносной системе,
конвективное охлаждение сборки полупроводника, вентиляция в
помещениях, моделирование промышленных стоков.
6
7. Вихревые структуры, возникающие вокруг шасси воздушного судна
http://www.cae-expert.ru/product/ansys-fluent7
8. Моделирование течений в ДВС с использованием ANSYS FLUENT
http://www.cae-expert.ru/product/ansys-fluent8
9.
Ansys “Mechanicals”9
10. Закон Мура
В 1965 году один из основателей компании Intel,Гордон Мур предсказал, что количество
транзисторов на кремниевой подложке будет
удваиваться каждые два года, что повлечет
удвоение производительности и снижение вдое
рыночной стоимости. Сегодня на площади, равное
кончику стержня шариковой ручки, может
поместиться более 10 миллионов транзисторов.
10
11. Динамика развития
1112. Физический предел?
Впервые его поставили под сомнение в начале века, когда процессоры суспехом взяли планку в 1 и 2 ГГц. Однако чипы с частотой выше 3 ГГц
оказались не столь эффективны. Решение было найдено в виде
многоядерных процессоров, которые, кстати, сегодня успешно трудятся на
частотах превышающих 3 ГГц.
Сегодня компании вкладывают миллиарды долларов в производственные
линии, которые затем окупаются за счет массового выпуска относительно
дешевых процессоров. При нормах производства менее 18 нм, цена линий,,
окажется настолько высокой, что они раньше выработают ресурс, чем
окупят себя.
Сегодня за оборудование для техпроцесса 32 нм необходимо выложить 4
миллиарда долларов. Подобные инвестиции имеют смысл только для тех
компаний, которые надеются выручить за чипы не менее 10 миллиардов.
Финансовый предел закону Мура аналитики назначили уже на 2014 год.
Кстати, в 2007 году сам Гордон Мур объявил, что его закон будет справедлив
еще не менее 10 лет. А производители микросхем готовы опровергнуть
выкладки iSuppli прямо сейчас. Toshiba, например, уже ведет разговоры о
внедрении норм 16 нм.
Конечно же, у миниатюризации транзисторов, из которых состоит современный
процессор, есть и физический предел, но пока мы его не достигли.
12
13. Модели параллельных программ Классификация Флинна
Основными понятиями классификации являются "поток команд" и "потокданных".
Поток команд - последовательность команд одной программы.
Поток данных - последовательность данных, обрабатываемых одной программой.
Согласно этой классификации имеется четыре больших класса ЭВМ:
SISD (Single Instruction − Single Data) - выполняется единственная программа, т. е. имеется
только один счетчик команд.
SIMD (Single Instruction – Multiple Data). В таких ЭВМ выполняется единственная программа, но
каждая команда обрабатывает массив данных. Соответствует векторной форме параллелизма.
MISD (Multiple Instruction − Single Data). Подразумевается, что в данном классе несколько команд
одновременно работает с одним элементом данных, однако эта позиция классификации
Флинна на практике не нашла применения.
MIMD (Multiple Instruction − Multiple Data). В таких ЭВМ одновременно и независимо друг от друга
выполняется несколько программных ветвей, в определенные промежутки времени
обменивающихся данными. Такие системы обычно называют многопроцессорными.
13
14. Параллельные аппаратные архитектуры
1. Векторно-конвейерные компьютеры. Конвейерные функциональные устройства и наборвекторных команд - это две особенности таких машин. В отличие от традиционного
подхода, векторные команды оперируют целыми массивами независимых данных, что
позволяет эффективно загружать доступные конвейеры, т.е. команда вида A=B+C
может означать сложение двух массивов, а не двух чисел. Характерным
представителем данного направления является семейство векторно-конвейерных
компьютеров CRAY куда входят, например, CRAY EL, CRAY J90, CRAY T90 (в марте 2000
года американская компания TERA перекупила подразделение CRAY у компании Silicon
Graphics, Inc.).
2. Массивно-параллельные компьютеры с распределенной памятью (ВЫЧИСЛИТЕЛЬНЫЕ
КЛАСТЕРА). Идея построения компьютеров этого класса тривиальна: возьмем
серийные микропроцессоры, снабдим каждый своей локальной памятью, соединим
посредством некоторой коммуникационной среды - вот и все. Достоинств у такой
архитектуры масса: если нужна высокая производительность, то можно добавить еще
процессоров, если ограничены финансы или заранее известна требуемая
вычислительная мощность, то легко подобрать оптимальную конфигурацию и т.п.
14
15.
Однако есть и решающий "минус", сводящий многие "плюсы" на нет. Дело в том, чтомежпроцессорное взаимодействие в компьютерах этого класса идет намного медленнее, чем
происходит локальная обработка данных самими процессорами. Именно поэтому написать
эффективную программу для таких компьютеров очень сложно, а для некоторых алгоритмов иногда просто
невозможно. К данному классу можно отнести компьютеры Intel Paragon, IBM SP1, Parsytec, в какой-то
степени IBM SP2 и CRAY T3D/T3E, хотя в этих компьютерах влияние указанного минуса значительно
ослаблено. К этому же классу можно отнести и сети компьютеров, которые все чаще рассматривают как
дешевую альтернативу крайне дорогим суперкомпьютерам.
3. Параллельные компьютеры с общей памятью. (МНОГОЯДЕРНЫЕ ПЛАФТОРМЫ) Вся оперативная память таких
компьютеров разделяется несколькими одинаковыми процессорами. Это снимает проблемы предыдущего
класса, но добавляет новые - число процессоров, имеющих доступ к общей памяти, по чисто техническим
причинам нельзя сделать большим. В данное направление входят многие современные многопроцессорные
SMP-компьютеры или, например, отдельные узлы компьютеров HP Exemplar и Sun StarFire.
4. Последнее направление, строго говоря, не является самостоятельным, а скорее представляет собой
комбинации предыдущих трех. Из нескольких процессоров (традиционных или векторно-конвейерных) и
общей для них памяти сформируем вычислительный узел. Если полученной вычислительной мощности не
достаточно, то объединим несколько узлов высокоскоростными каналами. Подобную архитектуру называют
кластерной, и по такому принципу построены CRAY SV1, HP Exemplar, Sun StarFire, NEC SX-5, последние
модели IBM SP2 и другие.
По каким же направлениям идет развитие высокопроизводительной вычислительной техники в настоящее
время? – ГИБРИДНЫЕ СИСТЕМЫ, КВАНТОВЫЕ КОМПЬЮТЕРЫ
15
16.
17. Варианты параллельных систем
Mainframe (SMP системы) –симметричные мультипроцессоры
Clusters (MPP системы) – массивно
параллельные системы
17
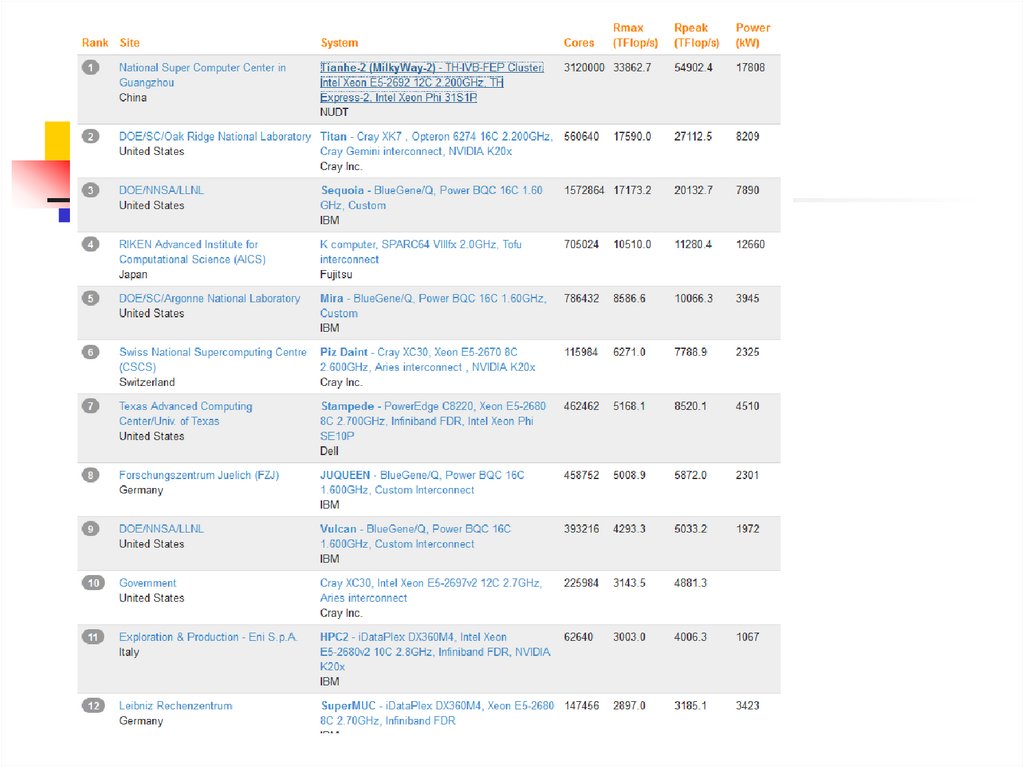
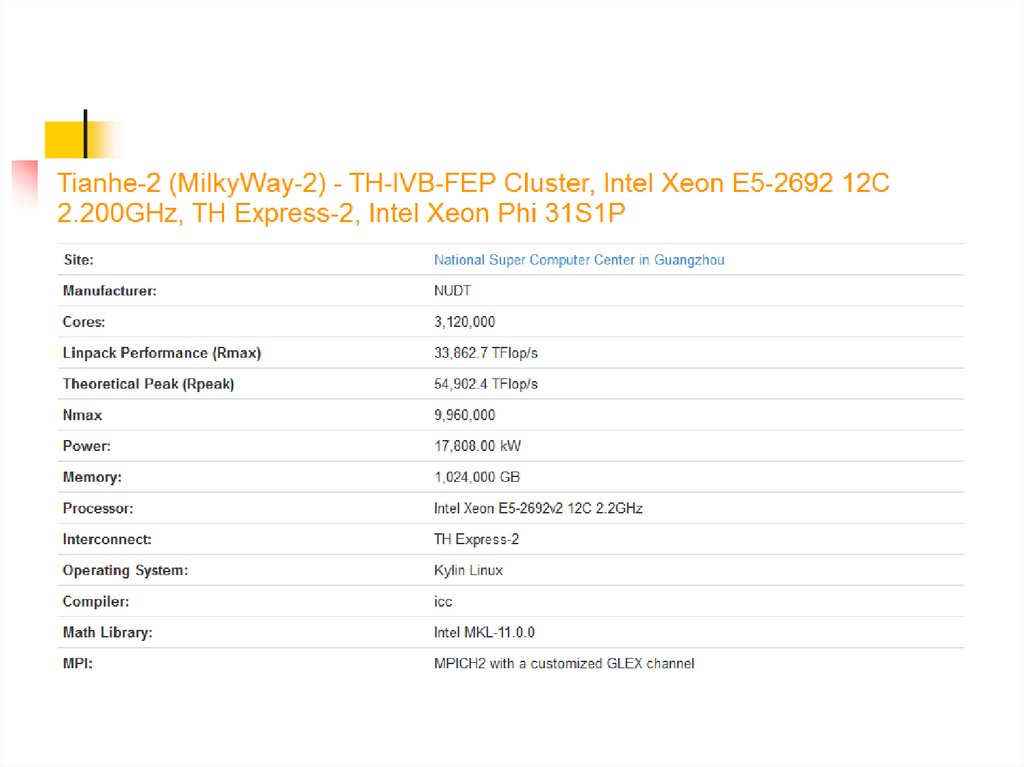
18. TOP500
TOP500 — проект по составлению рейтинга и описаний 500 самыхмощных общественно известных компьютерных систем мира.
Проект был запущен в 1993 году и публикует обновлённый список
суперкомпьютеров дважды в год(1-Июнь,2-Ноябрь). Этот проект
направлен на обеспечение надёжной основы для выявления и
отслеживания тенденций в области высокопроизводительных
вычислений. Россия по данным на ноябрь 2009 года занимает 8-10
место по числу установленных систем наряду с Австрией и Новой
Зеландией. Лидируют по этому показателю США.
18
19.
20.
21.
22. Jaguar
«Ягуар» (Jaguar) — суперкомпьютер класса массивно-параллельных систем,размещен в Национальном Центре компьютерных исследований в Окридже,
штат Теннеси (National Center for Computational Sciences (NCCS)).
Суперкомпьютер имеет массово-параллельную архитектуру, то есть состоит из
множества автономных ячеек (англ. nodes). Все ячейки делятся на 2
раздела (англ. partitions): XT5 и XT4 моделей Cray XT5 и XT4,
соответственно.
Раздел XT5 содержит 18’688 вычислительных ячеек, а также вспомогательные
ячейки для входа пользователей и обслуживания. Каждая вычислительная
ячейка содержит 2 четырехъядерных процессора AMD Opteron 2356
(Barcelona) с внутренней частотой 2.3 ГГц, 16 ГБ памяти DDR2-800, и
роутер SeaStar 2+. Всего раздел содержит 149’504 вычислительных ядер,
более 300 ТБ памяти, более 6 ПБ дискового пространства и пиковую
производительность 1.38 PFLOPS.
22
23. Jaguar
2324. Roadrunner
Roadrunner — суперкомпьютер в Лос-Аламосской национальной лаборатории вНью-Мексико, США. Разработан в расчёте на пиковую производительность в
1,026 петафлопа (достигнута в июне 2008 года) и 1,105 петафлопа (ноябрь
2008 года). Был самым производительным суперкомпьютером в мире и в 2009
году. IBM построила этот компьютер для Министерства энергетики США по
гибридной схеме из 6480 двухъядерных процессоров AMD Opteron и 12 960
процессоров IBM Cell 8i в специальных стойках TriBlade, соединённых с
помощью Infiniband.
Roadrunner работает под управлением Red Hat Enterprise Linux совместно с Fedora
и управляется по xCAT. Он занимает приблизительно 12 000 кв.футов (1100
м²) и весит 226 тонн. Энергопотребление — 3,9 МВт. Вступил в строй в июне
2008 года. Стоимость IBM Roadrunner составила 133 миллиона долларов.
Министерство энергетики планирует использовать RoadRunner для расчёта
старения ядерных материалов и анализа безопасности и надёжности ядерного
арсенала США. Также планируется использование для научных, финансовых,
транспортных и аэрокосмических расчётов.
24
25. Roadrunner
2526. Виды параллелизма
Общая памятьРаспределенная
память
26
27. Виды параллелизма
Распределеннаяпамять
Взаимодействие
Быстрое
Низкое
между
через общую
через передачу
процессорами память/переменные сообщений по сети
Параметр
Общая память
Расширяемость
архитектур
Низкая
Высокая
не более 64
процессоров
тысячи
процессоров
27
28. Средства параллельного программирования
Общаяпамять
Распределенная
память
Системные
средства
threads
sockets
Специальные
библиотеки и
пакеты
OpenMP,
CUDA
MPI
PVM
28
29. Кластер (наиболее актуально)
Вычислительный Кластер – это группа компьютеров, объединенных локальной сетью и способных работать в качестве единоговычислительного ресурса.
Структура системного программного обеспечения:
система управления и мониторинга ресурсами кластера:
Gangulia, Nagios;
cистема управления очередью заданий: Torgue;
средства параллельного программирования:
Message Passing Interface (MPI),
Parallel Virtual Machine (PVM),
OpenMP
29
30. Высокопроизводительные кластеры
High performance cluster (HPC) позволяют увеличить скорость расчетов,разбивая задание на параллельно выполняющиеся потоки.
Область применения — научные исследования.
Одна из типичных конфигураций — набор серверов с установленной на них
операционной системой Linux (кластер Beowulf).
Для HPC создается специальное ПО, способное эффективно распределять
задачу между узлами.
31. «Селектел» — хостинг-провайдер
«Селектел» — хостингпровайдер32. «Ицва» дата-центр «ВК» в деревне Новосергиевка под Санкт-Петербургом,
33.
34.
35. Схема Beowulf кластера
Группа идентичных РС (Client node) под управлением ОС Lunix(Server node), объединенных в небольшую TCP/IP LAN
36. Типовая архитектура вычислительного кластера
ПользователиСеть управления
Упр.
Узел
Узел 1
Узел 2
Узел N
Вычислительная сеть
Вычислительный кластер
36
37. Типовая архитектура вычислительного кластера
ПользователиGigabit Ethernet
Упр.
Узел
Узел 1
Узел 2
Узел N
InfiniBand, Myrinet, SCI
Вычислительный кластер
37
38. Средства коммутации
ТехнологияEthernet
FastEthernet
GigabitEthernet
Скорость
1 Мбит/сек
100 Мбит/сек
1 Гбит/сек
10GigabitEthernet 10 Гбит/сек
Myrinet
InfiniBand
SCI
Латентность
100 мксек
50 мксек
~ 10 мксек
~ 5 мксек
2 Гбит/сек
2 мксек
20-40 Гбит/сек 1.2 мксек
10 Гбайт/сек 0.2 мксек
38
39. Grid-системы
Грид (англ. grid — решетка, сеть) — согласованная, открытая истандартизованная компьютерная среда, которая обеспечивает гибкое,
безопасное, скоординированное разделение вычислительных ресурсов и
ресурсов хранения информации, которые являются частью этой среды, в
рамках одной виртуальной организации.
Грид является географически распределенной инфраструктурой,
объединяющей множество ресурсов разных типов (процессоры,
долговременная и оперативная память, хранилища и базы данных, сети),
доступ к которым пользователь может получить из любой точки, независимо
от места их расположения.
40. Схема Grid-системы
Центральный узел (Control Server) распределяет задачипо узлам грида (Grid Node) и контролирует результат
41. Grid вычисления
SETI@homeFolding@home
Climate Prediction
LHC@home
…
42. Аппаратные ресурсы КАИ
Вычислительный HPC кластер (фирма SUN):Вычислительных узлов
Управляющих узлов
Количество процессоров:
Объем оперативной памяти:
Объем внешней памяти
Вычислительная сеть
Дополнительная сеть
Пиковая производительность
Операционная система
Система управления
22
1
22 x 2 Xeon (4 Core)
22 x 32GB
4 TB
InfiniBand
GigabitEthernet
≈1.3 Tflops
SLES 10
Ganglia
42
43. Аппаратные ресурсы КАИ
Вычислительный GPU кластер (фирма Niagara) :Вычислительных узлов
Управляющих узлов
Количество GPU карт:
Объем оперативной памяти:
Объем накопителей (HDD)
Вычислительная сеть
Пиковая производительность
6
1
6 x 2 (Tesla C-2075, 448 ядер)
6 x 128 GB
6 x 4 TB (RAID 10)
GigabitEthernet
≈6x2 Tflops
Операционная система
Система управления
Windows Server 2012 (CentOS)
(?)
43
44. Кластеры КНИТУ-КАИ
4445. Закон Амдала
Предположим, что необходимо решить некоторую вычислительнуюзадачу. Предположим, что её алгоритм таков, что доля α от общего
объёма вычислений может быть получена только
последовательными расчётами (ввод/вывод, менеджмент потоков,
точки синхронизации и т.п. ), а соответственно, доля 1 − α
может быть распараллелена идеально (то есть время вычисления
будет обратно пропорционально числу задействованных узлов p).
Тогда ускорение, которое может быть получено на вычислительной
системе из p процессоров, по сравнению с однопроцессорным
решением не будет превышать величины
45
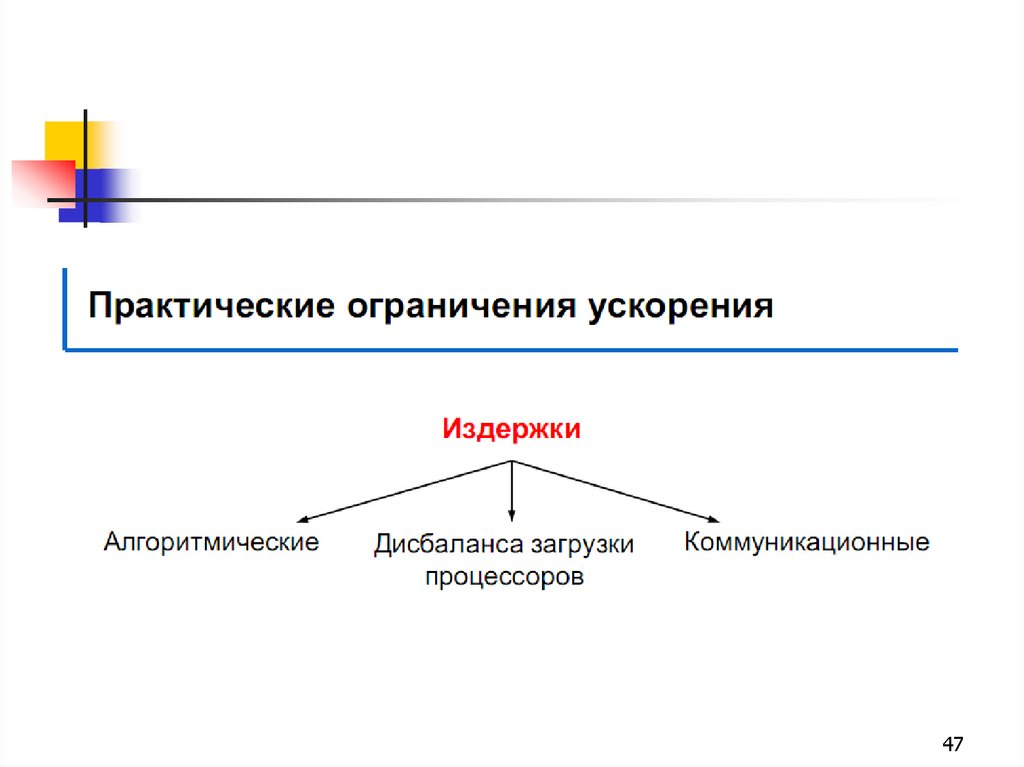
46. Ограничение производительности
Таблица показывает, во сколько раз быстрее выполнится программа с долейпоследовательных вычислений α при использовании p процессоров.
Из таблицы видно, что только алгоритм, вовсе не содержащий последовательных
вычислений (α = 0), позволяет получить линейный прирост производительности с
ростом количества вычислителей в системе. Если доля последовательных вычислений
в алгоритме равна 25 %, то увеличение числа процессоров до 10 дает ускорение в
3,077 раза (эффективность 30,77 %), а увеличение числа процессоров до 1000 даст
ускорение в 3,988 раза (эффективность 0,4 %).
Отсюда же очевидно, что при доле последовательных вычислений α общий прирост
производительности не может превысить 1 / α. Так, если половина кода —
последовательная, то общий прирост никогда не превысит двух.
46
47.
4748. Законы Амдала
N – количествопроцессоров
16,00
14,00
12,00
10,00
Ускорение
Фактор F, который
указывает, какая
часть программы не
может быть распараллелена (часть
программы, которая
последовательна по
своей природе)
8,00
6,00
4,00
2,00
0,00
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
Число процессоров
48
49. Законы Амдала
N – количествопроцессоров
16,00
F=0
Идеальный
случай
14,00
12,00
10,00
Ускорение
Фактор F, который
указывает, какая
часть системы не
может быть распараллелена (часть
программы, которая
последовательна по
своей природе)
8,00
6,00
4,00
2,00
0,00
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
Число процессоров
49
50. Законы Амдала
N – количествопроцессоров
16,00
14,00
12,00
10,00
Ускорение
Фактор F, который
указывает, какая
часть системы не
может быть распараллелена (часть
программы, которая
последовательна по
своей природе)
8,00
6,00
4,00
2,00
0,00
Наихудший
случай
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
Число процессоров
F=1
50