
















 Программирование
ПрограммированиеПохожие презентации:





")




Task and Data Parallelism: Real-World Examples
1.
Task and Data Parallelism:Real-World Examples
Sasha Goldshtein | SELA Group
2.
Why This Talk?• Multicore machines have been a cheap commodity for >10 years
• Adoption of concurrent programming is still slow
• Patterns and best practices are scarce
• We discuss the APIs first…
• …and then turn to examples, best practices, and tips
www.devreach.com
3.
Task Parallel Library Evolution2008
2010
2012
• Incubated
for 3 years
as “Parallel
Extensions
for .NET”
• Released
in full glory
with .NET
4.0
• DataFlow
in .NET 4.5
(NuGet)
• Augmented
with
language
support
(await,
async
methods)
www.devreach.com
The
Future
4.
Tasks• A task is a unit of work
• May be executed in parallel with other tasks by a scheduler (e.g.
Thread Pool)
• Much more than threads, and yet much cheaper
try
//The C# 5.0 version
{
Task<string> t = Task.Factory.StartNew(
var task ()
= Task.Run(DnaSimulation);
=> { return DnaSimulation(…); });
DisplayProgress();
t.ContinueWith(r
=> Show(r.Exception),
Show(await
task);
TaskContinuationOptions.OnlyOnFaulted);
}
t.ContinueWith(r => Show(r.Result),
catch (Exception ex)
TaskContinuationOptions.OnlyOnRanToCompletion);
{
DisplayProgress();
Show(ex);
}
www.devreach.com
5.
Parallel Loops• Ideal for parallelizing work over a collection of data
• Easy porting of for and foreach loops
• Beware of inter-iteration dependencies!
Parallel.For(0, 100, i => {
...
});
Parallel.ForEach(urls, url => {
webClient.Post(url, options, data);
});
www.devreach.com
6.
Parallel LINQ• Mind-bogglingly easy parallelization of LINQ queries
• Can introduce ordering into the pipeline, or preserve order of original
elements
var query = from monster in monsters.AsParallel()
where monster.IsAttacking
let newMonster = SimulateMovement(monster)
orderby newMonster.XP
select newMonster;
query.ForAll(monster => Move(monster));
www.devreach.com
7.
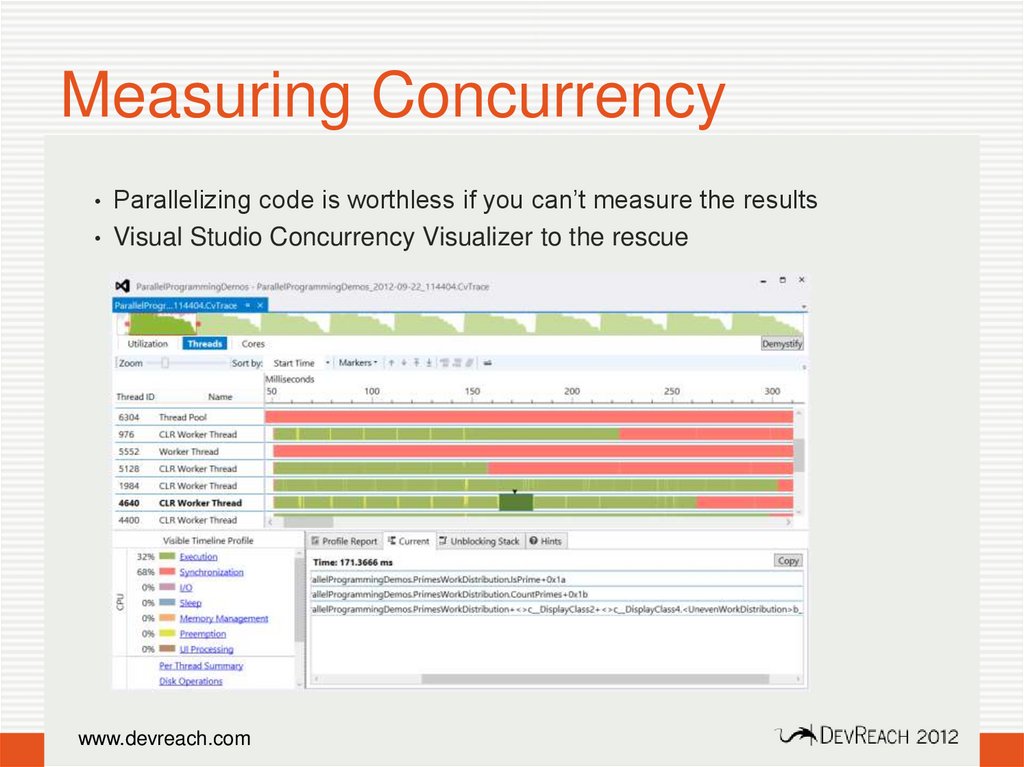
Measuring Concurrency• Parallelizing code is worthless if you can’t measure the results
• Visual Studio Concurrency Visualizer to the rescue
www.devreach.com
8.
Recursive Parallelism Extraction• Divide-and-conquer algorithms are often parallelized through the
recursive call
• Need to be careful with parallelization threshold and watch out for
dependencies
void FFT(float[] src, float[] dst, int n, int r, int s) {
if (n == 1) {
dst[r] = src[r];
} else {
Parallel.Invoke(
FFT(src, n/2, r,
s*2);
() => FFT(src, n/2, r, s*2),
() => FFT(src, n/2, r+s, s*2)
FFT(src, n/2, r+s, s*2);
); O(n) time
//Combine the two halves in
}
}
www.devreach.com
DEMO
9.
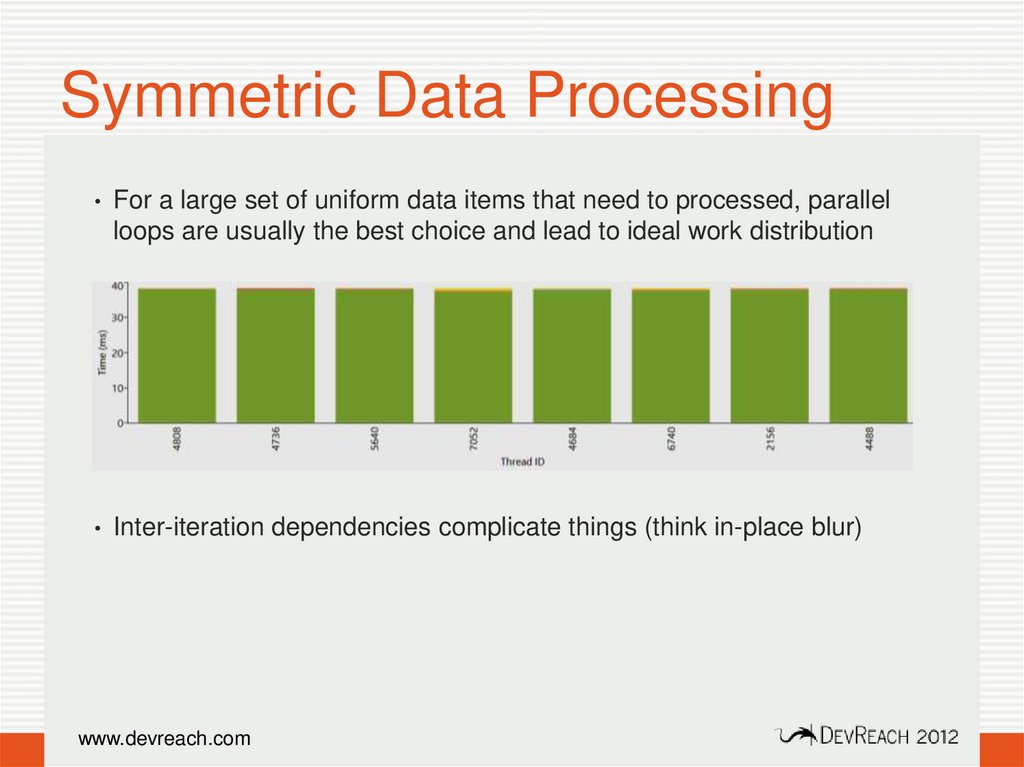
Symmetric Data Processing• For a large set of uniform data items that need to processed, parallel
loops are usually the best choice and lead to ideal work distribution
Parallel.For(0, image.Rows, i => {
for (int j = 0; j < image.Cols; ++j) {
destImage.SetPixel(i, j, PixelBlur(image, i, j));
}
});
• Inter-iteration dependencies complicate things (think in-place blur)
www.devreach.com
10.
Uneven Work Distribution• With non-uniform data items, use custom partitioning or manual
distribution
• Checking primality: 7 is easier to check than 10,320,647
• Not ideal (and complicated!):
var work = Enumerable.Range(0, Environment.ProcessorCount)
.Select(n => Task.Run(() =>
CountPrimes(start+chunk*n, start+chunk*(n+1))));
Task.WaitAll(work.ToArray());
• Faster (and simpler!):
Parallel.ForEach(Partitioner.Create(Start, End, chunkSize),
chunk => CountPrimes(chunk.Item1, chunk.Item2)
);
www.devreach.com
DEMO
11.
Complex DependencyManagement
• With dependent work units, parallelization is no longer automatic and
simple
• Must extract all dependencies and incorporate them into the algorithm
• Typical scenarios: 1D loops, dynamic algorithms
• Levenshtein string edit distance: each task depends on two
predecessors, computation proceeds as a wavefront
C = x[i-1] == y[i-1] ? 0 : 1;
D[i, j] = min(
D[i-1, j] + 1,
D[i, j-1] + 1,
D[i-1, j-1] + C);
www.devreach.com
0,0
DEMO
m,n
12.
Synchronization => Aggregation• Excessive synchronization brings parallel code to its knees
• Try to avoid shared state, or minimize access to it
• Aggregate thread- or task-local state and merge later
Parallel.ForEach(
Partitioner.Create(Start, End, ChunkSize),
() => new List<int>(),
//initial local state
(range, pls, localPrimes) => {
//aggregator
for (int i = range.Item1; i < range.Item2; ++i)
if (IsPrime(i)) localPrimes.Add(i);
return localPrimes;
},
localPrimes => { lock (primes)
//combiner
primes.AddRange(localPrimes);
});
www.devreach.com
DEMO
13.
Creative Synchronization• We implement a collection of stock prices, initialized with 105 name/price
pairs
• Access rate: 107 reads/s, 106 “update” writes/s, 103 “add” writes/day
• Many reader threads, many writer threads
• Store the data in two dictionaries: safe and unsafe
GET(key):
if safe contains key then return safe[key]
lock { return unsafe[key] }
PUT(key, value):
if safe contains key then safe[key] = value
lock { unsafe[key] = value }
www.devreach.com
14.
Lock-Free Patterns (1)• Try to void Windows synchronization and use hardware synchronization
• Primitive operations such as Interlocked.Increment,
Interlocked.Add, Interlocked.CompareExchange
• Retry pattern with Interlocked.CompareExchange enables arbitrary
lock-free algorithms, ConcurrentQueue<T> and ConcurrentStack<T>
www.devreach.com
Comparand
New Value
int InterlockedMultiply(ref int x, int y) {
int t, r;
do {
t = x;
r = t * y;
}
while (Interlocked.CompareExchange(ref x, r, t) != t);
return r;
}
15.
Lock-Free Patterns (2)• User-mode spinlocks (SpinLock class) can replace locks you acquire
very often, which protect tiny computations
//Sample implementation of SpinLock
class __DontUseMe__SpinLock {
private volatile int _lck;
public void Enter() {
while (Interlocked.CompareExchange(ref _lck, 1, 0) != 0);
}
public void Exit() {
Thread.MemoryBarrier();
_lck = 0;
}
}
www.devreach.com
16.
Miscellaneous Tips (1)• Don’t mix several concurrency frameworks in the same process
• Some parallel work is best organized in pipelines – TPL DataFlow
BroadcastBlock
<Uri>
TransformBlock
<Uri, byte[]>
TransformBlock
<byte[],
string>
ActionBlock
<string>
• Some parallel work can be offloaded to the GPU – C++ AMP
void vadd_exp(float* x, float* y, float* z, int n) {
array_view<const float,1> avX(n, x), avY(n, y);
array_view<float,1>
avZ(n, z); avZ.discard_data();
parallel_for_each(avZ.extent, [=](index<1> i) ... {
avZ[i] = avX[i] + fast_math::exp(avY[i]);
});
avZ.synchronize();
}
www.devreach.com
17.
Miscellaneous Tips (2)• Invest in SIMD parallelization of heavy math or data-parallel algorithms
START:
movups xmm0, [esi+4*ecx]
addps xmm0, [edi+4*ecx]
movups [ebx+4*ecx], xmm0
sub
ecx, 4
jns START
• Make sure to take cache effects into account, especially on MP systems
A’s cache
CL
state = S
www.devreach.com
B’s cache
RFO
Set CL as I
CL
state = S
Thread does
CL[0] = 15
18.
Conclusions• Avoid shared state and synchronization
• Parallelize judiciously and apply thresholds
• Measure and understand performance gains or losses
• Concurrency and parallelism are still hard
• A body of best practices, tips, patterns, examples is being built:
Microsoft Parallel Computing Center: http://msdn.microsoft.com/concurrency
Concurrent Programming on Windows (Joe Duffy): http://s.sashag.net/SLwEhI
Parallel Programming with .NET: http://parallelpatterns.codeplex.com/
www.devreach.com
19.
Two free Pro .NET Performance eBooks!Send an email to sashag@sela.co.il with an answer to
the following question:
Thank You!
Which class can be used to generate markers in the
Visual Studio Concurrency Visualizer reports?
@goldshtn
blog.sashag.net
www.linkedin.com/in/goldshtn
Sasha Goldshtein | SELA Group