



























 Информатика
ИнформатикаПохожие презентации:
. Хэш-таблицы (Hash tables)")









Индексы (лекция 6)
1.
Лекция 6Индексы
1
2.
Индексы• Упорядоченные индексы
• Индексы в виде B+-дерева
• Индексы в виде B-дерева
• Хеш-индексы (в следующей лекции)
• Bitmap индексы
2
3.
Основные понятия• Механизмы индексации используются для ускорения доступа к данным
• Например, каталог по авторам в библиотеке
• Ключ поиска – атрибут (или набор атрибутов), используемый для поиска записей
в файле.
• Файл индекса состоит из записей (называемые записями индекса) следующей
формы:
search-key
pointer
• Файлы индекса обычно гораздо меньше оригинального файла
• Два базовых типа индексов:
• Упорядоченные индексы: ключи поиска хранятся в отсортированном
порядке
• Хэш индексы: ключи поиска распределены равномерно по “bucket”, которые
используют хэш функции.
3
4.
Метрики оценки индекса• Какие типы доступа поддерживаются эффективно, например:
• Записи с определенным значением в атрибуте
• Или записи со значениями атрибутов, попадающий в определенный
интервал значений.
• Время доступа
• Время вставки
• Время удаления
• Фрагментация/свободное место
4
5.
Упорядоченные индексы• В упорядоченных индексах записи
отсортированных по ключам поиска
индекса
хранятся
в
порядке,
• Кластерный индекс: в последовательно упорядоченном файле, индекс, ключ
поиска которого определяет последовательный порядок файла.
• Также называется primary index/основной индекс
• Ключ поиска основного индекса обычно, но не обязательно primary
key/основной ключ.
• Вторичный индекс: индекс, чей ключ поиска определен в порядке, который
отличается от последовательного порядка в файле. Также называется
nonclustering index/некластерный индекс
• Файл последовательного индекса: последовательный файл, упорядоченный по
ключу поиска с кластерным индексом по ключу поиска.
5
6.
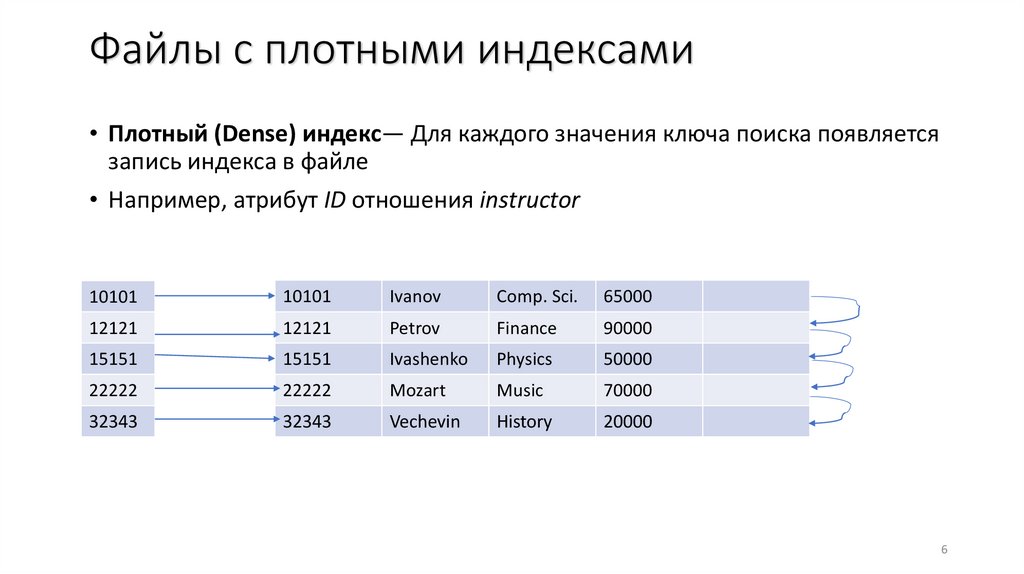
Файлы с плотными индексами• Плотный (Dense) индекс— Для каждого значения ключа поиска появляется
запись индекса в файле
• Например, атрибут ID отношения instructor
10101
10101
Ivanov
Comp. Sci.
65000
12121
12121
Petrov
Finance
90000
15151
15151
Ivashenko
Physics
50000
22222
22222
Mozart
Music
70000
32343
32343
Vechevin
History
20000
6
7.
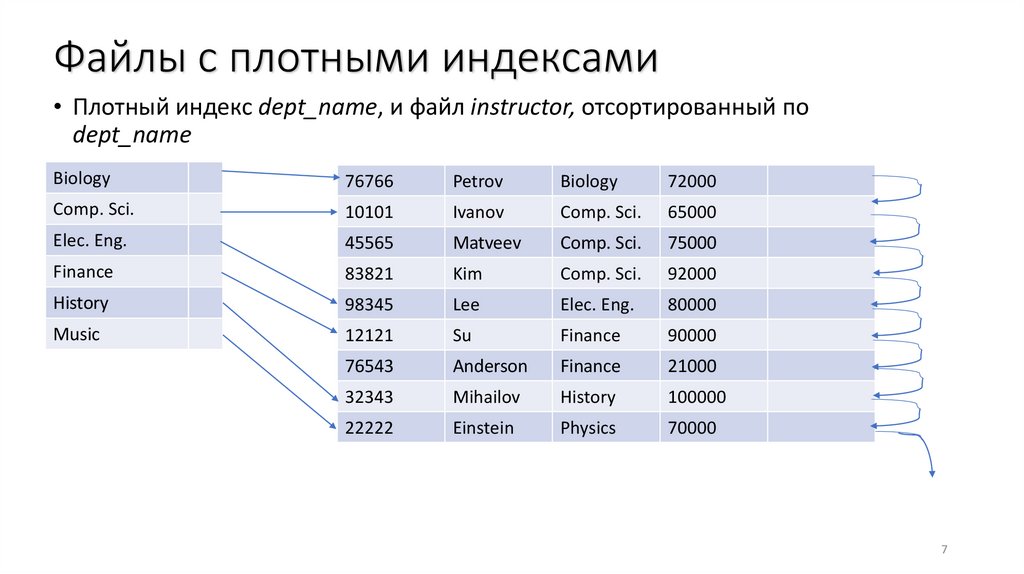
Файлы с плотными индексами• Плотный индекс dept_name, и файл instructor, отсортированный по
dept_name
Biology
76766
Petrov
Biology
72000
Comp. Sci.
10101
Ivanov
Comp. Sci.
65000
Elec. Eng.
45565
Matveev
Comp. Sci.
75000
Finance
83821
Kim
Comp. Sci.
92000
History
98345
Lee
Elec. Eng.
80000
Music
12121
Su
Finance
90000
76543
Anderson
Finance
21000
32343
Mihailov
History
100000
22222
Einstein
Physics
70000
7
8.
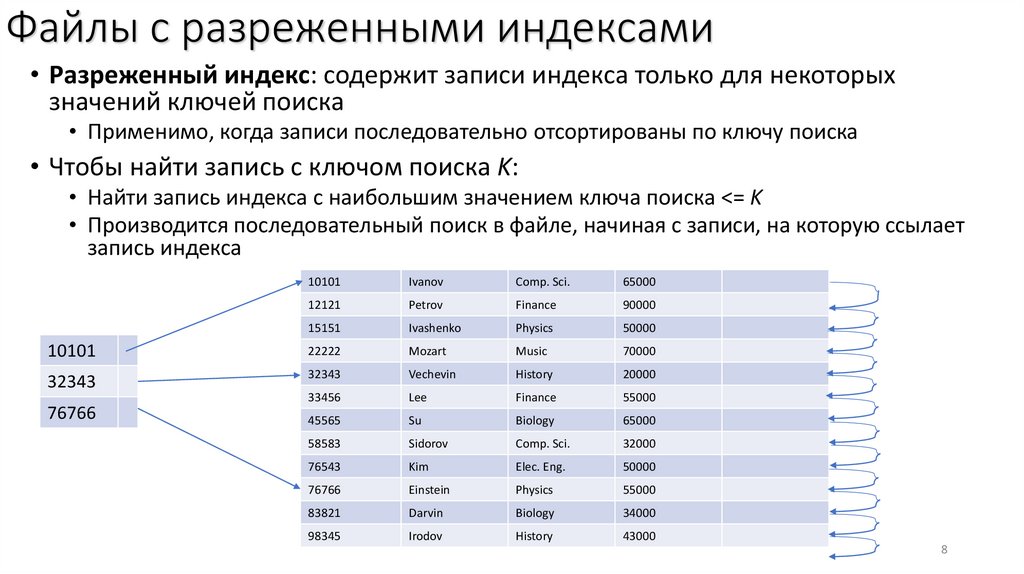
Файлы с разреженными индексами• Разреженный индекс: содержит записи индекса только для некоторых
значений ключей поиска
• Применимо, когда записи последовательно отсортированы по ключу поиска
• Чтобы найти запись с ключом поиска K:
• Найти запись индекса с наибольшим значением ключа поиска <= K
• Производится последовательный поиск в файле, начиная с записи, на которую ссылает
запись индекса
10101
Ivanov
Comp. Sci.
65000
12121
Petrov
Finance
90000
15151
Ivashenko
Physics
50000
10101
22222
Mozart
Music
70000
32343
32343
Vechevin
History
20000
33456
Lee
Finance
55000
45565
Su
Biology
65000
58583
Sidorov
Comp. Sci.
32000
76543
Kim
Elec. Eng.
50000
76766
Einstein
Physics
55000
83821
Darvin
Biology
34000
98345
Irodov
History
43000
76766
8
9.
Файлы с разреженными индексами• Сравнивая с плотными индексам:
• Меньший размер и меньше накладных расходов для вставок и удалений
• Обычно медленней, чем плотный индекс для поиска записей
• Компромисс:
• Для кластерных индексов: разреженный индекс с
записью в индексе для каждого блока в файле,
который ссылается на наименьший ключ поиска в
блоке
• Для некластерных индексов: разреженный индекс
над плотным индексом (мультиуровневый индекс)
9
10.
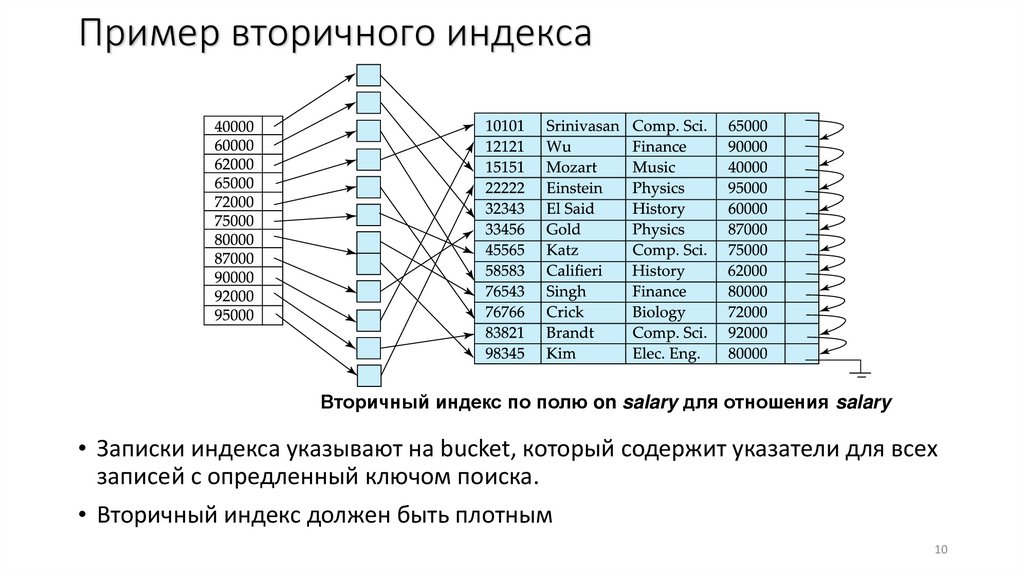
Пример вторичного индексаВторичный индекс по полю on salary для отношения salary
• Записки индекса указывают на bucket, который содержит указатели для всех
записей с опредленный ключом поиска.
• Вторичный индекс должен быть плотным
10
11.
Кластерные и некластерные индексы• Индексы предоставляют существенные преимущества, когда осуществляется
поиск для записей.
• НО: Индексы дают накладные расходы при изменении базы данных
• когда запись вставлена или удалена, каждый индекс в отношении
должен быть обновлен
• при обновлении записи любой индекс по обновленному атрибуту
должен быть обновлен.
• Последовательное сканирование при использовании кластерного индекса
довольно эффективно, но последовательное сканирование вторичного
(некластерного) индекса довольно дорогая операция на магнитном диске
• Каждый доступ к записи может осуществлять забор нового блока из
диска
• Каждый забор блока с диска занимает 5-10 мс
11
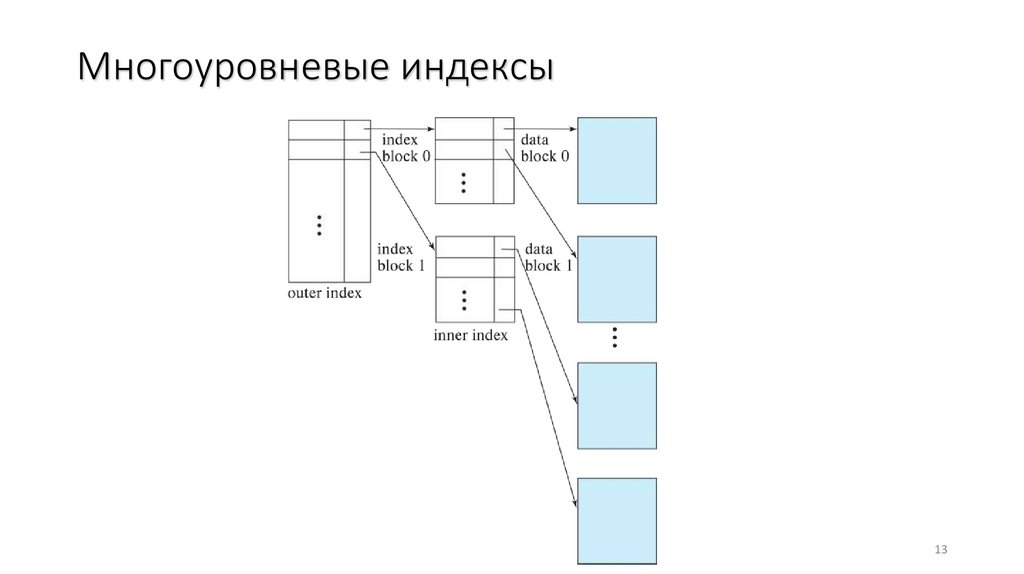
12.
Многоуровневые индексы• Если индекс перестает умещаться в памяти, доступ к нему становится довольно
затратной операцией
• Решение: рассмотреть индекс, содержащийся на диске, как последовательный
файл и построить плотный индекс на нем.
• Внешний индекс – плотный индекс базового индекса
• Внутренний индекс – основной файл индекса
• Даже если внешний индекс слишком большой, чтобы попасти в основную
память, можно создать еще один уровень и т.д.
• Индексы на всех уровнях должны быть обновляемым при вставке или
удалении файла.
12
13.
Многоуровневые индексы13
14.
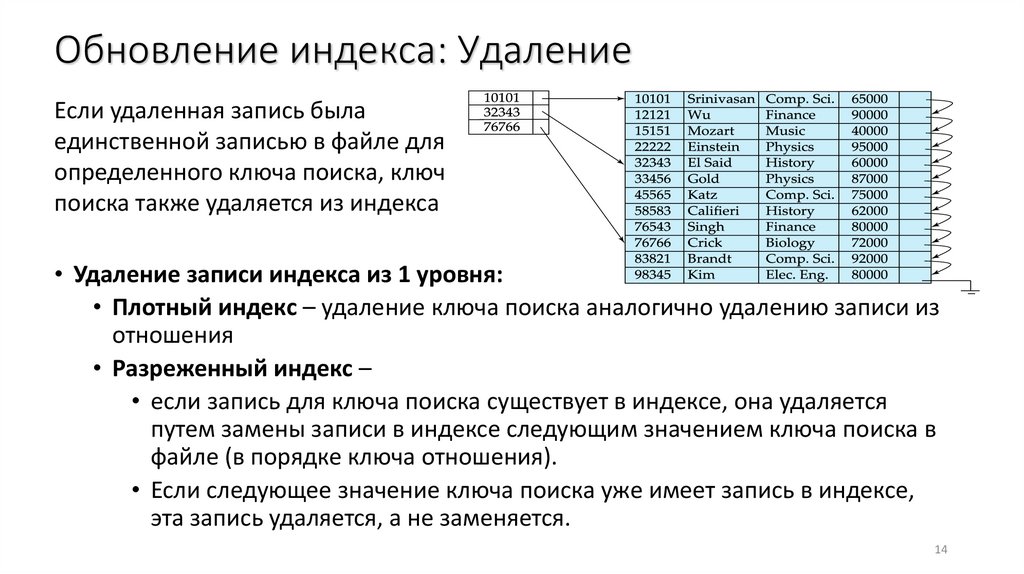
Обновление индекса: УдалениеЕсли удаленная запись была
единственной записью в файле для
определенного ключа поиска, ключ
поиска также удаляется из индекса
• Удаление записи индекса из 1 уровня:
• Плотный индекс – удаление ключа поиска аналогично удалению записи из
отношения
• Разреженный индекс –
• если запись для ключа поиска существует в индексе, она удаляется
путем замены записи в индексе следующим значением ключа поиска в
файле (в порядке ключа отношения).
• Если следующее значение ключа поиска уже имеет запись в индексе,
эта запись удаляется, а не заменяется.
14
15.
Обновление индекса: Вставка• Вставка индекса одного уровня:
• Осуществляется поиск по индексу для ключа вставки.
• Плотные индексы – если значение ключа поиска отсутствует в индексе,
осуществляется вставка
• Индексы поддерживаются в виде последовательных файлов
• Требуется создание места для новой записи, возможно, потребуются
overflow блоки.
• Разреженные индексы – если в индексе хранится запись для каждого блока
файла, в индекс не нужно вносить никаких изменений, если только не создан
новый блок.
• Если создается новый блок, первое значение ключа поиска,
появляющееся в новом блоке, вставляется в индекс.
• Многоуровневые индексы. Вставка и удаление. Алгоритмы являются
расширением упрощенного случая
15
16.
Индексы по составным ключам• Составной поисковый ключ
• Например, индекс по отношению instructor по атрибутам (name, ID)
• Значения хранятся лексикографически
• Например, (John, 12121) < (John, 13514)
и (John, 13514) < (Peter, 11223)
• Могут быть запрос по name, или по (name, ID)
16
17.
Файл индекса в виде B+-дерева• Недостатки последовательных файлов индекса:
• Производительность ухудшается при росте файла, так как могут быть созданы
overflow блоки.
• Требуется периодическая реорганизация всего файла
• Преимущество файла в виде B+-дерева:
• Автоматически реорганизуется при небольших, локальных изменениях при
вставках и удалениях
• Реорганизация всего файла не требуется для управления
производительностью.
• (Небольшой) недостаток B+-дерева:
• Дополнительные издержки на вставку и удаление, есть накладные расходы
для места
• Обычно преимущества B+-деревьев превышают недостатки
17
• B+-деревья часто используются на данный момент
18.
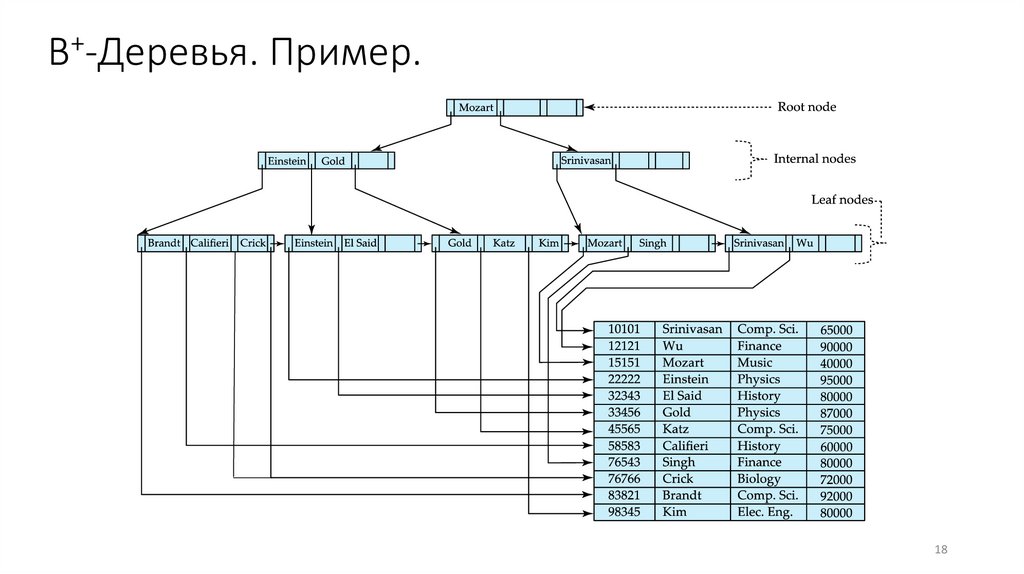
B+-Деревья. Пример.18
19.
Файл индекса в виде B+-дереваB+-дерево – корневое дерево со следующими свойствами:
• Все пути от корня до листа одинакового размера
• Каждая вершина, которая ни корень, ни лист имеет от n/2 до n детей.
• Лист содержит от (n–1)/2 до n–1 значений
• Специальные случаи:
• Если корень не лист, у него есть как минимум, 2 ребенка.
• Если корень является листом, то у него от 0 до (n–1) значений.
19
20.
Структура вершин B+-Дерева• Формат вершины
• Ki – ключи поиска
• Pi – указатели на детей (для не листовых вершин) или указатели на
записи или buckets записей (для листовых вершин).
• Ключи поиска в вершине отсортированы
K1 < K2 < K3 < . . . < Kn–1
(Предположение: отсутствуют ключи дубликаты)
20
21.
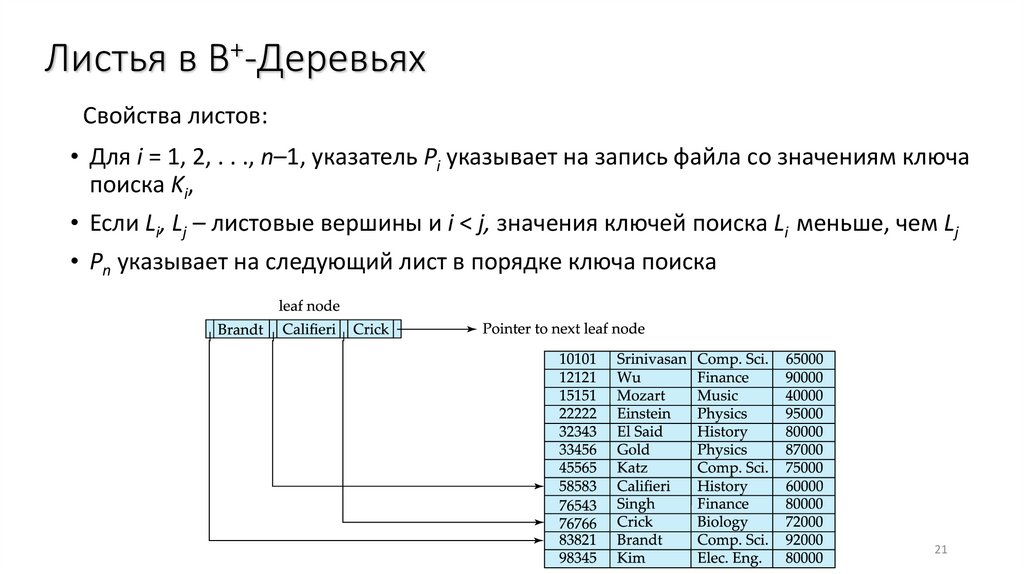
Листья в B+-ДеревьяхСвойства листов:
• Для i = 1, 2, . . ., n–1, указатель Pi указывает на запись файла со значениям ключа
поиска Ki,
• Если Li, Lj – листовые вершины и i < j, значения ключей поиска Li меньше, чем Lj
• Pn указывает на следующий лист в порядке ключа поиска
21
22.
Не листовые вершины в B+-деревьях• Не листовые узлы формируют многоуровневый разреженный индекс на
конечных узлах. Для не листовой вершине с m указателями:
• Все ключи поиска в поддереве, на который указывает P1 меньше, чем K1
• Для 2 i n – 1, все ключи поиска в поддереве, на который указывают Pi
имеют значения больше или равно, чем Ki–1 и меньше, чем Ki
• Все ключи поиска в поддереве, на который указывает Pn , имеют
значения больше или равные, чем Kn–1
22
23.
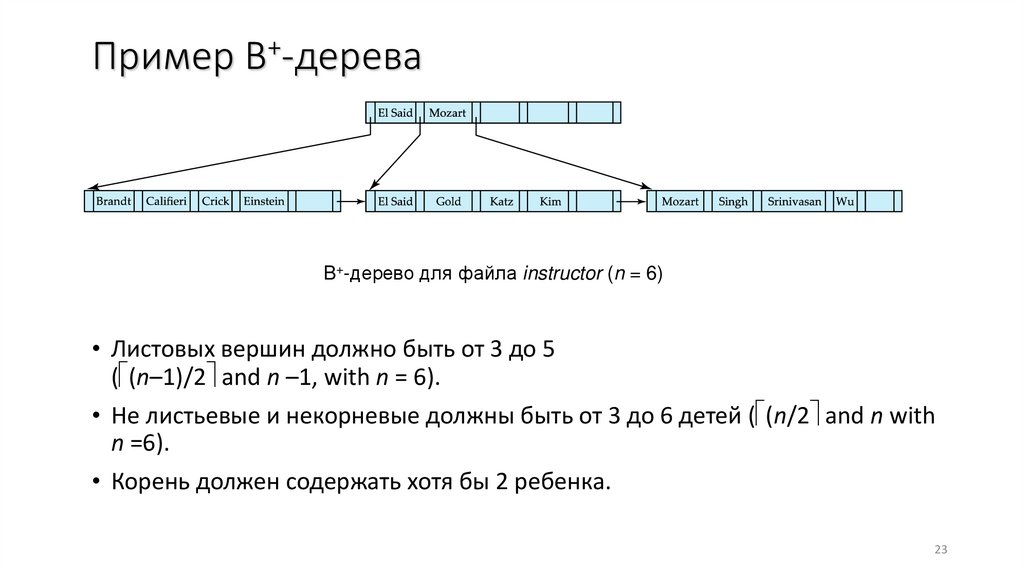
Пример B+-дереваB+-дерево для файла instructor (n = 6)
• Листовых вершин должно быть от 3 до 5
( (n–1)/2 and n –1, with n = 6).
• Не листьевые и некорневые должны быть от 3 до 6 детей ( (n/2 and n with
n =6).
• Корень должен содержать хотя бы 2 ребенка.
23
24.
Наблюдения о B+-деревьях• Так как межузловые связи происходят через указатели, то “ логически ”
близкие блоки не должны быть “физически” близкими.
• Не листьевые вершины B+-дерева формируют иерархию разреженных
индексов.
• B+-дерево содержит относительно небольшое количество уровней
• Уровни ниже корня имеют хотя бы 2* n/2 значений
• Следующий уровень содержит в себе 2* n/2 * n/2 значений
• .. т.д.
• Если в файле значений ключей поиска K, высота дерева не более, чем
log n/2 (K)
• Таким образом, поиск был эффективным
• Вставки и удаления для основного файла могут быть эффективно
обработаны, так как индекс реконструируется за логарифмическое время
24
25.
Файлы индексов в виде B-дерева• Похоже на B+-деревья, но B-деревья позволяют ключам поиска возникать
только один раз; исключает избыточное хранение ключей поиска.
• Ключи поиска в не листовых атрибутах нигде больше не возникают; требуется
доп. указатель для каждого не ключевой вершины
• Обобщенная вершина листа B-дерева
25
26.
Файлы индексов в виде B-дерева• Преимущества индексов в виде B-Дерева:
• Может быть меньшее число вершин, чем в B+-Дереве.
• Иногда можно найти ключ поиска до листа.
• Недостатки индексов в виде B-Дерева:
• Только небольшое число ключей поиска находится до листа
• Неключевые узлы больше, так что уменьшаются разветвления. Поэтому у BДеревьев высота больше, чем у B+-Деревьев
• Вставка и удаление более сложна, чем в B+-Деревьях
• Реализация сложнее, чем B+-Деревья.
• Обычно преимущества B-Деревьев не превышают недостатки
26
27.
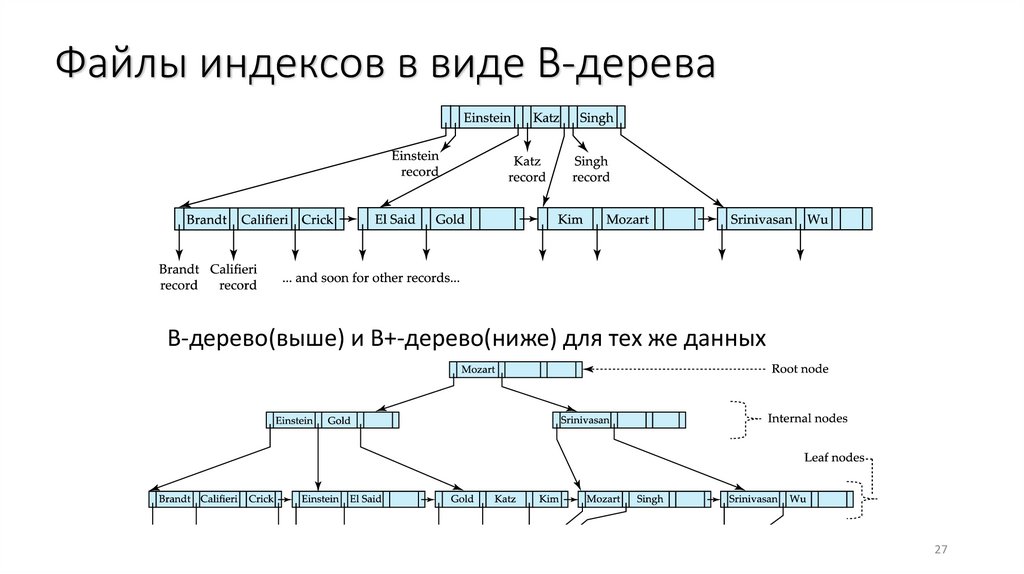
Файлы индексов в виде B-дереваB-дерево(выше) и B+-дерево(ниже) для тех же данных
27
28.
Хеширование28
29.
Статический хэш• Bucket (бакет, корзина, сегмент) – единица хранения, содержащая одну или
более записей (сегмент обычно блок диска).
• Мы получаем значение сегмента для записи из значения ключа поиска,
используя хеш функцию
• Хеш функция h – это функция из множества всех ключей поиска K во
множество всех сегментов адресов B.
• Хеш функция используется для поиска записей для вставки, доступа и
удаления.
• Могут быть записи с разными ключами поиска, но одним bucket; поэтому
весь сегмент необходимо последовательно просматривать для поиска
записи
• В хеш индексе, сегмент хранит записи с указателями на записи файлов
• В хеш файлах сегменты хранят записи
29
30.
Управление переполнением сегментов• Переполнение сегментов может возникнуть из-за
• Недостаточного числа сегментов
• Смещении в распределении записей
• Много записей имеют одно и то же значение ключа поиска
• Выбранная хэш функция создает неравномерное распределение
значений ключа
• Хотя вероятность переполнения корзины может быть уменьшена, ее нельзя
устранить; это обрабатывается с помощью сегментов переполнения (overflow
buckets).
30
31.
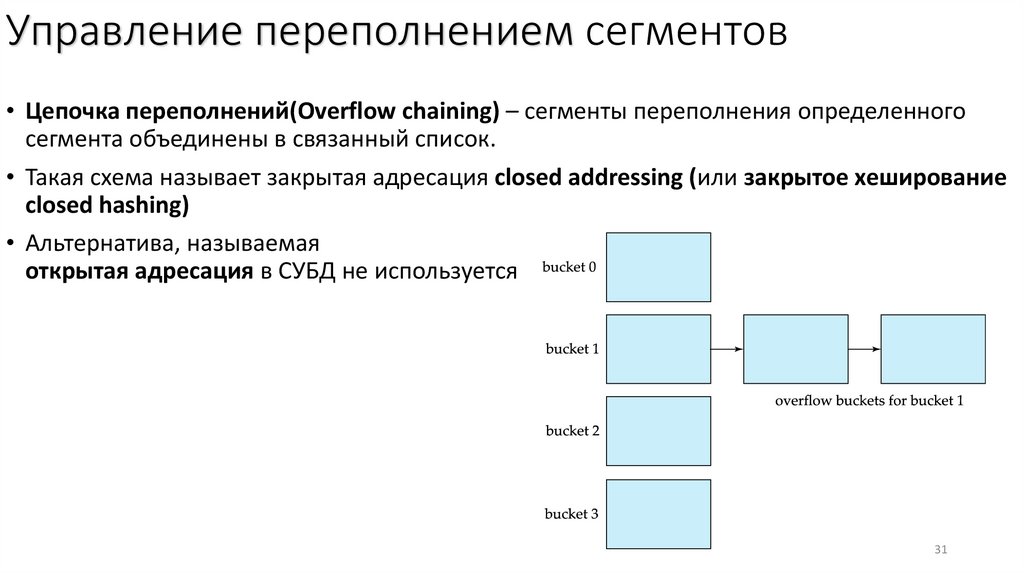
Управление переполнением сегментов• Цепочка переполнений(Overflow chaining) – сегменты переполнения определенного
сегмента объединены в связанный список.
• Такая схема называет закрытая адресация closed addressing (или закрытое хеширование
closed hashing)
• Альтернатива, называемая
открытая адресация в СУБД не используется
31
32.
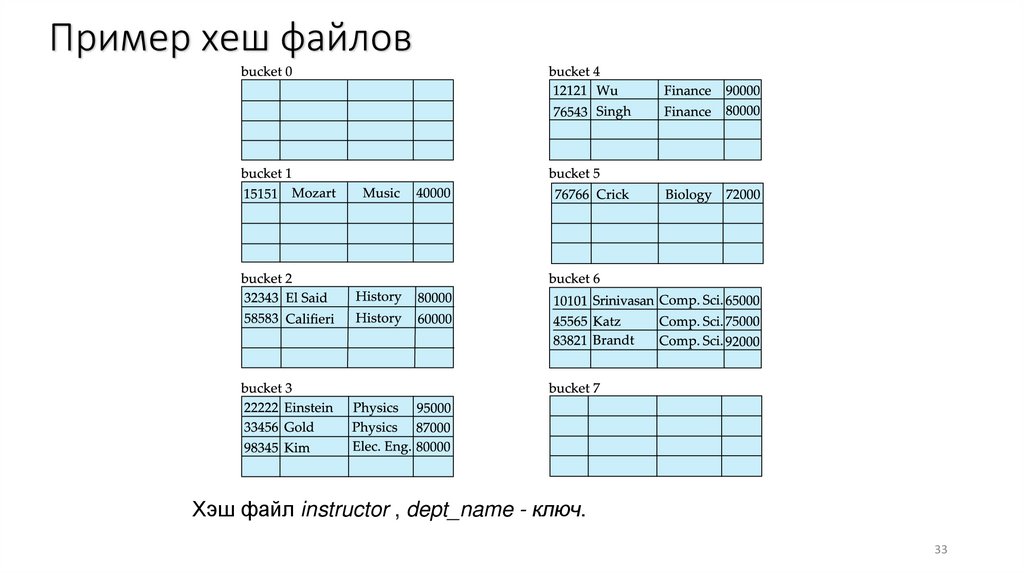
Пример хеш файловОрганизация файла в виде хешей instructor file, используя
dept_name как ключ
• Всего 10 сегментов,
• Бинарное представление i-го символа предполагается целым числом i.
• Хеш функция возвращает сумму бинарных представлений символов по
модулю 10. Например,
• h(Music) = 1
• h(History) = 2
• h(Physics) = 3
• h(Elec. Eng.) = 3
32
33.
Пример хеш файловХэш файл instructor , dept_name - ключ.
33
34.
Недостатки статического хеширования• При статическом хешировании функция h отображает значения
ключа поиска в фиксированный набор B адресов сегментов. Базы
данных растут или уменьшаются со временем.
• Если начальное количество сегментов слишком мало, а размер
файла увеличивается, производительность будет снижаться из-за
слишком большого количества переполнений.
34
35.
Недостатки статического хеширования• Одно из решений: периодическая реорганизация файла с новой
хэш-функцией
• Дорого, нарушает нормальную работу
• Более правильное решение: разрешить динамическое изменение
количества сегментов.
35
36.
Динамическое хеширование• Периодическое рехеширование
• Если количество записей в хеш-таблице становится (скажем) в 1,5 раза
больше хеш-таблицы,
• создать новую хеш-таблицу размером (скажем) в 2 раза больше
предыдущей хеш-таблицы
• Рехешировать все записи в новую таблицу
• Линейное хеширование
• Рехешировать инкрементально
• Расширяемое хеширование
• Предназначен для хэширования на основе диска, с сегментами,
совместно используемыми несколькими хэш-значениями
• Удвоение количества записей в хэш-таблице без удвоения количества
блоков
36
37.
Сравнение упорядоченного индексирования ихеширования
• Стоимость периодической реорганизации
• Относительная частота вставок и удалений
• Желательно ли оптимизировать среднее время доступа за счет наихудшего
времени доступа?
• Ожидаемый тип запросов:
• Хеширование обычно лучше при извлечении записей, имеющих
указанное значение ключа.
• Если запросы распространены с диапазонами, упорядоченные индексы
должны быть предпочтительными
37
38.
Сравнение упорядоченного индексирования ихеширования
• На практике:
• PostgreSQL поддерживает хеш-индексы, но не рекомендует использовать
его из-за низкой производительности
• Oracle поддерживает статическую хеш-организацию, но не хеш-индексы
• SQLServer поддерживает только B + -дерево
38
39.
Bitmap индексы• Bitmap индексы – специальный тип индексов, разработанный специально для
эффективных запросов по нескольким ключам
• Записи в отношении предполагаются пронумерованными последовательно от,
например, 0
• Имея номер n довольно просто получить запись n
• Особенно, если записи фикс. длины
• Применимо, если атрибуты содержат в себе малое число уникальных
значений
• Например, пол, город, страна
• Или уровень дохода (0-9999, 10000-19999, 20000-50000, 50000бесконечность)
• Bitmap (битовая карта) – это просто массив битов
39
40.
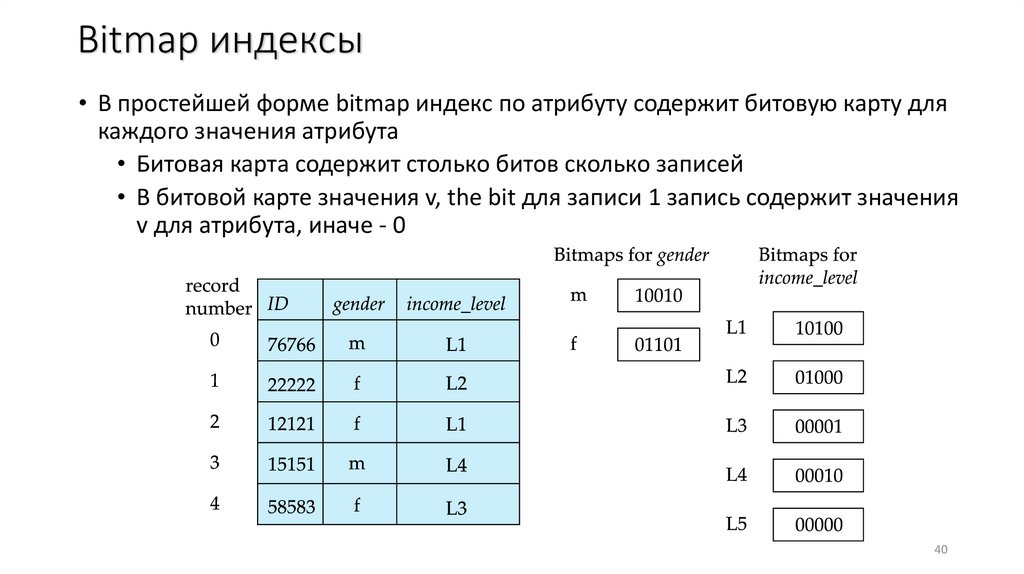
Bitmap индексы• В простейшей форме bitmap индекс по атрибуту содержит битовую карту для
каждого значения атрибута
• Битовая карта содержит столько битов сколько записей
• В битовой карте значения v, the bit для записи 1 запись содержит значения
v для атрибута, иначе - 0
40
41.
Bitmap индексы• Bitmap индексы полезны для запросов по нескольким атрибутам
• не всегда полезны для запросов с одним атрибутом
• Запросы работают с
• Пересечением (and)
• Объединением (or)
• Каждая операция берет две битовые карты того же размера и применяет
битовые операции
• Пример. 100110 AND 110011 = 100010
100110 OR 110011 = 110111
NOT 100110 = 011001
• Мужчины с уровнем дохода L1:10010 AND 10100 = 10000
• Затем можно получить необходимые кортежи
• Подсчет количества очень быстрый
41