

































































































































 Информатика
Информатика Электроника
ЭлектроникаПохожие презентации:
")


")






Процессоры, память и периферийные устройства ВС, их простейшие модели и разновидности. Лекция 6
1.
Лекция 6: Процессоры, память ипериферийные устройства ВС, их
простейшие модели и разновидности. Конвейерный способ выполнения команд в современных ЭВМ.
Архитектура памяти и систем
хранения информации.
2.
Архитектура вычислительных средствПри описании аппаратных средств вычислительной техники обычно
выделяют собственно вычислительное устройство – процессор;
различные типы и системы организации памяти (кэши, оперативная,
энергонезависимая), контроллеры системных шин и периферийных
устройств, сами эти устройства. Организация связей между ними
может быть различной, соответственно выделяют несколько типов
архитектур вычислительных систем, две из них наиболее известны:
принстонская и гарвардская.
Принстонская архитектура, часто называемая архитектурой фон
Неймана, характеризуется использованием общей оперативной
памяти для хранения программ, данных, а также для организации
стека. Для обращения к этой памяти используется общая системная
шина, по которой в процессор поступают и команды, и данные.
Гарвардская архитектура была разработана Говардом Эйкеном с
целью
увеличить
скорость
вычислительных
операций
и
оптимизировать работу памяти. Она характеризуется физическим
разделением памяти команд (программ) и памяти данных. В ее
оригинальном варианте использовался также отдельный стек для
хранения
содержимого
программного
счетчика,
который
обеспечивал возможности выполнения вложенных подпрограмм.
Каждая память соединяется с процессором отдельной шиной, что
позволяет одновременно с чтением-записью данных при выполнении
текущей команды производить выборку и декодирование следующей
команды.
3.
Гарвардская архитектура4.
Архитектура вычислительных средствАрхитектура
современных
персональных
компьютеров
основана на магистрально-модульном принципе.
Шина – это кабель, состоящий из множества проводников.
Количество проводников, входящих в состав шины, определяет
максимальную разрядность шины.
Системная шина, в свою очередь, представляет собой
совокупность
шины данных, служащей для переноса информации;
шины
адреса,
которая
определяет,
куда
переносить
информацию;
шины управления, которая определяет правила для передачи
информации;
шины питания, подводящей электропитание ко всем узлам
вычислительной машины.
Шины данных и адреса могут объединяться в режиме
мультиплексирования.
Системная шина характеризуется тактовой частотой и
разрядностью. Количество одновременно передаваемых по
шине бит называется разрядностью шины.
Тактовая частота характеризует число элементарных операций
по передаче данных в 1 секунду. Разрядность шины
измеряется в битах, тактовая частота – в мегагерцах.
5.
Архитектура вычислительных средствУстройство управления
(УУ) выполняет функции
управления
вычислительным процессом на основе кодов команд и признаков
результатов предыдущих операций. Современные УУ, как правило,
строятся по принципу микропрограммирования, когда в результате
дешифрации команды и значений ряда регистров запускаются
последовательности
управляющих
сигналов
(микрокоманды)
различным блокам процессора.
УУ формирует адрес команды, которая должна быть выполнена в
данном цикле, и выдает управляющий сигнал на чтение
содержимого соответствующей ячейки запоминающего устройства
(ЗУ). Считанная команда передается в УУ. По информации,
содержащейся в адресных полях команды, УУ формирует адреса
операндов и управляющие сигналы для их чтения из ЗУ и передачи в
арифметико-логическое устройство (АЛУ). После считывания
операндов
устройство
управления
по
коду
операции,
содержащемуся в команде, выдает в АЛУ сигналы на выполнение
операции. Полученный результат записывается в ЗУ по адресу
приемника результата под управлением сигналов записи. Признаки
результата (знак, наличие переполнения, признак нуля и так далее)
поступают в устройство управления, где записываются в специальный
регистр признаков. Эта информация может использоваться при
выполнении следующих команд программы, например команд
условного перехода.
6.
Архитектура вычислительных средствСтруктура гипотетического процессора
7.
Архитектура вычислительных средствРегистр адреса (РА) предназначен для хранения адреса ячейки
основной
памяти
вплоть
до
завершения
операции
(считывание или запись) с этой ячейкой.
Указатель стека (УкС) — это регистр, где хранится адрес
вершины стека. В реальных вычислительных машинах стек
реализуется в виде участка основной памяти обычно
расположенного
в
области
наибольших
адресов.
Заполнение стека происходит в сторону уменьшения
адресов, при этом вершина стека — это ячейка, куда была
произведена последняя по времени запись. Для хранения
адреса такой ячейки и предназначен УкС. При выполнении
операции занесения в стек содержимое УкС сначала
уменьшается на единицу, после чего используется в качестве
адреса, по которому производится запись. Соответствующая
ячейка становится новой вершиной стека. Считывание из
стека происходит из ячейки, на которую указывает текущий
адрес в УкС, после чего содержимое указателя стека
увеличивается на единицу. Таким образом, вершина стека
опускается, а считанное слово считается удаленным из стека.
Хотя физически считанное слово и осталось в ячейке памяти,
при следующей записи в стек оно будет заменено новой
информацией.
8.
Архитектура вычислительных средствСчетчик команд (СК) — неотъемлемый элемент процессора
любой
ЭВМ,
построенной
в
соответствии
с
фоннеймановским принципом программного управления.
Согласно этому принципу соседние команды программы
располагаются в ячейках памяти со следующими по порядку
адресами и выполняются преимущественно в той же
очередности, в какой они размещены в памяти ЭВМ. Перед
началом вычислений в СК заносится адрес ячейки основной
памяти, где хранится команда, которая должна быть
выполнена первой. В процессе выполнения каждой команды
путем увеличения содержимого СК на длину выполняемой
команды в счетчике формируется адрес следующей
подлежащей выполнению команды. По завершении текущей
команды адрес следующей команды программы всегда
берется из счетчика команд. Для изменения естественного
порядка вычислений (перехода в иную точку программы)
достаточно занести в СК адрес точки перехода.
Регистр команды. Чтобы приступить к выполнению команды, ее
необходимо извлечь из памяти и разместить в регистре
команды (РК). Этот этап носит название выборки команды. В
РК команда хранится в течение всего времени ее выполнения.
9.
Архитектура вычислительных средствРегистры общего назначения (РОН), служат для временного
хранения операндов и результатов вычислений. Это самый
быстрый, но и минимальный по емкости тип памяти, который
иногда
объединяют
понятием
сверхоперативное
запоминающее устройство — СОЗУ. Как правило, количество
регистров невелико, хотя в архитектурах с сокращенным
набором команд их число может доходить до нескольких
десятков.
Индексные регистры (ИР) служат для формирования адресов
операндов при реализации циклических участков программ.
Регистр признака результата (РПР) предназначен для фиксации
и
хранения
признака,
характеризующего
результат
последней выполненной арифметической или логической
операции. Такие признаки могут информировать о равенстве
результата нулю, о знаке результата, о возникновении
переноса из старшего разряда, переполнении разрядной
сетки и т. д. Содержимое РПР обычно используется
устройством управления для реализации условных переходов
по результатам операций АЛУ. Под каждый из возможных
признаков отводится один разряд РПР.
10.
Архитектура вычислительных средствАккумулятор (Акк) — это регистр, на который возлагаются
самые
разнообразные
функции.
Так,
в
него
предварительно
загружается
один
из
операндов,
участвующих
в
арифметической
или
логической
операции. В Акк может храниться результат предыдущей
команды и в него же заносится результат очередной
операции. Через Акк зачастую производятся операции
ввода и вывода. Строго говоря, аккумулятор в равной
мере можно отнести как к АЛУ, так и к УУ, а в ЭВМ с
регистровой архитектурфой его можно рассматривать
как один из регистров общего назначения.
Буфер данных призван компенсировать разницу в
быстродействии запоминающих устройств и устройств,
выступающих в роли источников и потребителей хранимой
информации. В буфер данных при чтении заносится
содержимое ячейки ОП, а при записи — помещается
информация, подлежащая сохранению в ячейке ОП.
Буфер адреса. Наличие буфера адреса также позволяет
компенсировать различия в быстродействии оперативной
памяти и других устройств ЭВМ.
11.
Архитектура вычислительных средствСовременные процессоры имеют различные по сложности
наборы команд (RISC и CISC), используют технологии
конвейерной обработки команд, многопоточность и
многоядерность. На кристалле процессора либо рядом, в
конструктиве чипа, размещается кэш-память второго и
третьего уровня.
Если процессоры для серверов, как правило освобождены от
графических задач и работают с сокращёнными системами
команд, то линейки процессоров для ПК имеют графический
процессор
вместе
с
основным
в
одном
чипе.
Соответственно,
архитектура
современных
чипсетов
представлена только микросхемой «южного моста», т.е.
реализует интерфейсы лишь относительно медленных
устройств. Шинами оперативной памяти и видео управляет
центральный процессор.
В мобильных устройствах интеграция идёт ещё дальше,
применяются SoC – системы на чипе (System-on-Chip). На
одном кристалле размещают:
Вычислительные ядра (2-10, с различной группировкой);
Графический ускоритель;
Модем;
Контроллеры Wi-Fi и Bluetooth;
Контроллеры заряда. (технологии быстрой зарядки);
Процессор обработки изображений.
12.
Архитектура вычислительных средствАрхитектура современного АРМ процессора
13.
Архитектура вычислительных средствХарактеристики
смартфона
современного
АРМ
процессора
для
14.
Архитектура параллельных вычисленийОбычно рассматриваются два возможных вида параллелизма:
независимость потоков заданий (команд), существующих в
системе,
и
независимость
(несвязанность)
данных,
обрабатываемых в каждом потоке. С этой тчки зрения
существует четыре основных архитектуры вычислительных
систем:
• одиночный поток команд — одиночный поток данных (ОКОД),
в английском варианте — SingleInstructionSingleData (SISD) —
одиночный поток инструкций — одиночный поток данных;
• одиночный поток команд — множественный поток данных
(ОКМД), или SingleInstructionMultipleData (SIMD) — одиночный
поток инструкций — множественный поток данных;
• множественный поток команд — одиночный поток данных
(МКОД),
или
MultipleInstructionSingleData
(MISD)
—
множественный поток инструкций — одиночный поток данных;
• множественный поток команд — множественный поток
данных (МКМД), или MultipleInstructionMultipleData (MIMD) —
множественный поток инструкций — множественный поток
данных (MIMD).
15.
Архитектура параллельных вычисленийАрхитектура ОКОД охватывает все однопроцессорные и
одномашинные варианты систем, т.е. с одним вычислителем.
Параллелизм вычислений обеспечивается путем совмещения
выполнения операций отдельными блоками АЛУ, а также
параллельной работы устройств ввода-вывода информации
и процессора. Применимо для повышения надёжности
систем за счёт принятия решения по консенсусу или
большинству.
Архитектура ОКМД предполагает создание структур векторной
или матричной обработки. Системы этого типа обычно
строятся как однородные, т.е. процессорные элементы,
входящие в систему, идентичны, и все они управляются одной
и той же последовательностью команд. Однако каждый
процессор обрабатывает свой поток данных. Под эту схему
хорошо подходят задачи обработки матриц или векторов
(массивов), задачи решения систем линейных и нелинейных,
алгебраических и дифференциальных уравнений, задачи
теории поля и др. В структурах данной архитектуры
желательно обеспечивать соединения между процессорами,
соответствующие
реализуемым
математическим
зависимостям. Как правило, эти связи напоминают матрицу, в
которой каждый процессорный элемент связан с соседними.
16.
Архитектура параллельных вычисленийАрхитектура МКОД предполагает построение межпроцессорного
конвейера, в котором результаты обработки передаются от
одного процессора к другому по цепочке. В современных ЭВМ
по этому принципу реализована схема совмещения операций,
в которой параллельно работают различные функциональные
блоки в общем цикле обработки команды.
Конвейер должны образовывать группы процессоров. Очень трудно
выявить регулярный характер в универсальных вычислениях.
Кроме того, на практике нельзя обеспечить и «большую длину»
такого конвейера, при которой достигается наивысший эффект.
Схема нашла применение в скалярных процессорах суперЭВМ, в которых они применяются как специальные процессоры
для поддержки векторной обработки. Пример — сигнальные
процессоры.
Архитектура МКМД предполагает, что все процессоры системы
работают по своим программам с собственным потоком
команд. В простейшем случае они могут быть автономны и
независимы. Такая схема использования ВС часто применяется
на многих крупных вычислительных центрах для увеличения
пропускной способности центра. Больший интерес представляет
возможность согласованной работы ЭВМ (процессоров), когда
каждый элемент делает часть общей задачи. Теоретическая база
такого вида работ практически отсутствует. Такие системы могут
быть многомашинными и многопроцессорными.
17.
Конвейерные вычисленияВыполнение типичной команды ЭВМ можно разделить на этапы:
выборка команды - IF (по адресу, заданному счетчиком
команд, из памяти извлекается команда);
декодирование команды / выборка операндов из регистров - ID;
выполнение операции / вычисление эффективного адреса
памяти - EX;
обращение к памяти - MEM;
запоминание результата - WB.
Можно
представить
схему
простейшего
процессора,
выполняющего указанные выше этапы выполнения команд без
совмещения. Чтобы конвейеризовать эту схему, можно
разбить выполнение команд на этапы, отведя для выполнения
каждого один такт синхронизации, и начинать в каждом такте
выполнение новой команды. Для хранения промежуточных
результатов каждого этапа необходимо использовать
регистровые станции. Хотя общее время выполнения одной
команды в таком конвейере будет составлять пять тактов, в
каждом такте аппаратура будет выполнять в совмещенном
режиме пять различных команд.
Для представления работы конвейера используются временные
диаграммы, на которых обычно изображаются выполняемые
команды, номера тактов и этапы выполнения команд.
18.
Конвейерные вычисленияКонвейеризация увеличивает пропускную способность
процессора, но не сокращает время выполнения
отдельной команды. Она даже несколько увеличивает это
время
из-за
накладных
расходов,
связанных
с
управлением регистровыми станциями.
Кроме ограничений, связанных с задержкой конвейера,
имеются также ограничения, возникающие в результате
несбалансированности задержки на каждой его ступени
и из-за накладных расходов на конвейеризацию. Такт
синхронизации не может быть меньше, чем время,
необходимое для работы наиболее медленной ступени
конвейера.
Накладные
расходы
на
организацию
конвейера возникают из-за задержки сигналов в
конвейерных регистрах (защелках) и из-за перекосов
сигналов синхронизации. Конвейерные регистры к
длительности такта добавляют время установки и задержку
распространения сигналов. В предельном случае
длительность такта можно уменьшить до суммы накладных
расходов и перекоса сигналов синхронизации, однако
при этом в такте не останется времени для выполнения
полезной работы по преобразованию информации.
19.
Конвейерные вычисленияВ качестве примера рассмотрим неконвейерную машину с
пятью этапами выполнения операций, которые имеют
длительность 50, 50, 60, 50 и 50 нс соответственно. Пусть
накладные расходы на организацию конвейерной
обработки составляют 5 нс. Тогда среднее время
выполнения команды в неконвейерной машине будет
равно 260 нс. Если же используется конвейерная
организация, длительность такта будет равна длительности
самого медленного этапа обработки плюс накладные
расходы, т.е. 65 нс. Это время соответствует среднему
времени выполнения команды в конвейере.
Конвейеризация эффективна только тогда, когда загрузка
конвейера близка к полной, а скорость подачи новых
команд и операндов соответствует максимальной
производительности
конвейера.
Если
произойдет
задержка, то параллельно будет выполняться меньше
операций и суммарная производительность снизится.
Такие задержки могут возникать в результате возникновения
конфликтных ситуаций. В следующих разделах будут
рассмотрены различные типы конфликтов, возникающие
при выполнении команд в конвейере, и способы их
разрешения.
20.
Конвейерные вычисленияНомер команды
Номер такта
1 2 3 4
5
6
7
8
9
Команда i
IF ID EX MEM WB
Команда i+1
IF ID EX
MEM WB
Команда i+2
IF ID
EX
MEM WB
Команда i+3
IF
ID
EX
MEM
WB
Команда i+4
IF
ID
EX
MEM WB
Диаграмма работы простейшего конвейера
21.
Конвейерные вычисленияЭффект конвейеризации при выполнении 3-х команд четырехкратное ускорение
22.
Конвейерные вычисленияПри реализации конвейерной обработки возникают ситуации,
которые препятствуют выполнению очередной команды из
потока команд в предназначенном для нее такте. Такие
ситуации называются конфликтами. Существуют три класса
конфликтов:
Структурные конфликты, возникают из-за конфликтов по
ресурсам,
когда
аппаратные
средства
не
могут
поддерживать все возможные комбинации команд в режиме
одновременного выполнения с совмещением.
Конфликты по данным, возникающие в случае, когда
выполнение одной команды зависит от результата выполнения
предыдущей команды.
Конфликты
по
управлению,
которые
возникают
при
конвейеризации команд переходов и других команд, которые
изменяют значение счетчика команд.
Конфликты
в
конвейере
приводят
к
необходимости
приостановки
выполнения
команд
(pipeline
stall).
В
простейших конвейерах, если приостанавливается какаялибо команда, то все следующие за ней команды также
приостанавливаются.
Команды,
предшествующие
приостановленной, могут продолжать выполняться, но во
время приостановки не выбирается ни одна новая команда.
23.
Структурные конфликты и способы их минимизацииСовмещенный режим выполнения команд в общем случае
требует конвейеризации функциональных устройств и
дублирования ресурсов для разрешения всех возможных
комбинаций команд в конвейере. Если какая-нибудь
комбинация команд не может быть принята из-за
конфликта по ресурсам, то говорят, что в машине имеется
структурный конфликт. Примером машин, в которых
возможно появление структурных конфликтов, являются
машины
с
не
полностью
конвейерными
функциональными устройствами. Время работы такого
устройства
может
составлять
несколько
тактов
синхронизации конвейера, последовательные команды не
могут поступать в него в каждом такте.
Другая возможность появления структурных конфликтов
связана с недостаточным дублированием некоторых
ресурсов, что препятствует выполнению произвольной
последовательности команд в конвейере без его
приостановки.
Когда
последовательность
команд
наталкивается
на
такой
конфликт,
конвейер
приостанавливает выполнение одной из команд до тех
пор, пока не станет доступным требуемое устройство.
24.
Конвейерные вычисленияСтруктурные конфликты возникают в машинах, в которых
имеется общий конвейер памяти для команд и данных. Если
одна команда содержит обращение к памяти за данными,
оно будет конфликтовать с выборкой более поздней команды
из памяти. Можно приостановить конвейер на один такт, когда
происходит обращение к памяти за данными. Подобная
приостановка часто называются "конвейерным пузырем"
(pipeline bubble).
Разработчики допускают наличие структурных конфликтов для
снижения стоимости и уменьшения задержки устройства.
Конвейеризация всех функциональных устройств может
оказаться слишком дорогой. Машины, допускающие два
обращения к памяти в одном такте, должны иметь удвоенную
пропускную
способность
памяти,
например,
путем
организации раздельных кэшей для команд и данных. Если
структурные конфликты не будут возникать слишком часто, то
может быть и не стоит платить за то, чтобы их обойти. Как
правило, можно разработать неконвейерное, или не
полностью конвейерное устройство, имеющее меньшую
общую задержку, чем полностью конвейерное. Например,
разработчики устройств с плавающей точкой компьютеров
CDC7600 и MIPS R2010 предпочли иметь меньшую задержку
выполнения операций вместо полной их конвейеризации.
25.
Конвейерные вычисленияКонфликты по данным, остановы конвейера и реализация
механизма обходов
Межкомандные
логические
зависимости
ограничивают
потенциальный
параллелизм
смежных
операций,
обеспечиваемый аппаратными средствами обработки.
Степень влияния этих зависимостей определяется как
архитектурой
процессора,
так
и
характеристиками
программ.
Конфликты по данным возникают в том случае, когда
применение конвейерной обработки может изменить
порядок обращений за операндами так, что этот порядок
будет отличаться от порядка, который наблюдается при
последовательном выполнении команд на неконвейерной
машине.
ADD R1,R2,R3
IF ID EX MEM WB
SUB
R4,R1,R5
IF ID EX
MEM WB
AND R6,R1,R7
IF ID
EX
MEM WB
OR
R8,R1,R9
IF
ID
EX
MEM WB
XOR R10,R1,R11
IF ID
EX
MEM WB
Последовательность команд в конвейере и ускоренная
пересылка данных
(data forwarding, data bypassing, short circuiting)
26.
Конвейерные вычисленияADD
R1,R2,R3
SUB
R4,R1,R5
AND
R6,R1,R7
OR
R8,R1,R9
XOR
R10,R1,R11
IF
ID EX MEM
R
IF ID EX
R
IF ID
R
IF
WB
W
MEM
IF
ID
EX
ID
R
WB
W
MEM
EX
EX
R
WB
W
MEM
WB
W
MEM WB
W
Совмещение чтения и записи регистров в одном такте
В этом примере все команды, следующие за командой ADD,
используют результат ее выполнения. Команда ADD записывает
результат в регистр R1, а команда SUB читает это значение. Если не
предпринять никаких мер для того, чтобы предотвратить этот
конфликт, команда SUB прочитает неправильное значение и
попытается его использовать. Если произойдет прерывание между
командами ADD и SUB, то команда ADD завершится, и значение R1 в
этой
точке
будет
соответствовать
результату
ADD.
Такое
непрогнозируемое поведение очевидно неприемлемо.
27.
Конвейерные вычисленияПроблема, поставленная в этом примере, может быть
разрешена с помощью достаточно простой аппаратной
техники,
которая
называется
пересылкой
или
продвижением данных (data forwarding), обходом (data
bypassing), иногда закороткой (short-circuiting). Результат
операции АЛУ с его выходного регистра всегда снова
подается назад на входы АЛУ. Если аппаратура
обнаруживает, что предыдущая операция АЛУ записывает
результат в регистр, соответствующий источнику операнда
для следующей операции АЛУ, то логические схемы
управления выбирают в качестве входа для АЛУ результат,
поступающий по цепи "обхода", а не значение,
прочитанное из регистрового файла.
Эта техника "обходов" может быть обобщена для того, чтобы
включить передачу результата прямо в то функциональное
устройство, которое в нем нуждается: результат с выхода
одного устройства "пересылается" на вход другого, а не с
выхода некоторого устройства только на его вход.
28.
Классификация конфликтов по даннымКонфликт возникает везде, где имеет место зависимость
между командами, и они расположены по отношению
друг к другу достаточно близко так, что совмещение
операций, происходящее при конвейеризации, может
привести к изменению порядка обращения к операндам.
В нашем примере был проиллюстрирован конфликт,
происходящий с регистровыми операндами, но для пары
команд возможно появление зависимостей при записи
или чтении одной и той же ячейки памяти. Если все
обращения к памяти выполняются в строгом порядке, то
появление такого типа конфликтов предотвращается.
Известны три возможных конфликта по данным в зависимости от
порядка операций чтения и записи. Рассмотрим две команды i и
j, при этом i предшествует j. Возможны следующие конфликты:
RAW (чтение после записи) - j пытается прочитать операнд-источник
данных прежде, чем i туда запишет. Таким образом, j может
некорректно получить старое значение. Это наиболее общий тип
конфликтов, способ их преодоления с помощью механизма
"обходов" рассмотрен ранее.
29.
Конвейерные вычисленияWAR (запись после чтения) - j пытается записать результат в
приемник прежде, чем он считывается оттуда командой i,
так что i может некорректно получить новое значение. Этот
тип конфликтов как правило не возникает в системах с
централизованным
управлением
потоком
команд,
обеспечивающих выполнение команд в порядке их
поступления, так как последующая запись всегда
выполняется позже, чем предшествующее считывание.
Особенно часто конфликты такого рода могут возникать в
системах, допускающих выполнение команд не в порядке
их расположения в программном коде.
WAW (запись после записи) - j пытается записать операнд
прежде, чем будет записан результат команды i, т.е.
записи заканчиваются в неверном порядке, оставляя в
приемнике значение, записанное командой i, а не j. Этот
тип конфликтов присутствует только в конвейерах, которые
выполняют запись со многих ступеней (или позволяют
команде выполняться даже в случае, когда предыдущая
приостановлена).
30.
Конвейерные вычисленияКонфликты по данным, приводящие к приостановке конвейера
Не все потенциальные конфликты по данным могут обрабатываться
с помощью механизма "обходов":
Команда
IF
LW R1,32(R6)
ADD R4,R1,R7
SUB R5,R1,R8
AND R6,R1,R7
WB
ID EX MEM
IF ID EX
IF ID
IF
WB
MEM
stall
stall
stall
WB
EX
ID
IF
MEM
EX
ID
WB
MEM
EX
WB
MEM
Последовательность команд с приостановкой конвейера
Этот случай отличается от последовательности подряд идущих
команд АЛУ. Команда загрузки (LW) регистра R1 из памяти имеет
задержку, которая не может быть устранена обычной
"пересылкой". Вместо этого нам нужна дополнительная
аппаратура, называемая аппаратурой внутренних блокировок
конвейера (pipeline interlook), чтобы обеспечить корректное
выполнение примера. Аппаратура приостанавливает конвейер,
начиная с команды, которая хочет использовать данные в то
время, когда предыдущая команда, результат которой является
операндом для нашей, вырабатывает этот результат. Эта
аппаратура вызывает приостановку конвейера или появление
31.
Конвейерные вычисленияДля
устранения конфликтов по данным используется
специальная методика планирования компилятора.
Многие современные компиляторы используют технику
планирования команд для улучшения производительности
конвейера. В простейшем алгоритме компилятор просто
планирует распределение команд в одном и том же
базовом блоке. Базовый блок представляет собой
линейный участок последовательности программного
кода, в котором отсутствуют команды перехода, за
исключением начала и конца участка (переходы внутрь
этого участка тоже должны отсутствовать). Планирование
такой
последовательности
команд
осуществляется
достаточно просто, поскольку компилятор знает, что
каждая команда в блоке будет выполняться, если
выполняется первая из них, и можно просто построить
граф зависимостей этих команд и упорядочить их так,
чтобы минимизировать приостановки конвейера. Для
простых конвейеров стратегия планирования на основе
базовых блоков вполне удовлетворительна. Однако когда
конвейеризация
становится
более
интенсивной
и
действительные задержки конвейера растут, требуются
более сложные алгоритмы планирования.
32.
Конвейерные вычисленияСуществуют аппаратные методы, позволяющие изменить
порядок выполнения команд программы так, чтобы
минимизировать приостановки конвейера. Эти методы
получили общее название методов динамической
оптимизации (в англоязычной литературе в последнее
время часто применяются также термины "out-of-order
execution" - неупорядоченное выполнение и "out-of-order
issue" - неупорядоченная выдача). Основными средствами
динамической оптимизации являются:
Размещение схемы обнаружения конфликтов в возможно
более низкой точке конвейера команд так, чтобы
позволить команде продвигаться по конвейеру до тех пор,
пока ей реально не потребуется операнд, являющийся
также результатом логически более ранней, но еще не
завершившейся команды. Альтернативным подходом
является централизованное обнаружение конфликтов на
одной из ранних ступеней конвейера.
33.
Буферизация команд, ожидающих разрешения конфликта, ивыдача последующих, логически не связанных команд, в "обход"
буфера. В этом случае команды могут выдаваться на
выполнение не в том порядке, в котором они расположены в
программе, однако аппаратура обнаружения и устранения
конфликтов
между
логически
связанными
командами
обеспечивает получение результатов в соответствии с заданной
программой.
Организация коммутирующих магистралей, обеспечивающая
засылку результата операции непосредственно в буфер,
хранящий логически зависимую команду, задержанную из-за
конфликта, или непосредственно на вход функционального
устройства до того, как этот результат будет записан в
регистровый файл или в память (short-circuiting, data forwarding,
data bypassing - методы, которые были рассмотрены ранее).
Метод переименования регистров (register renaming). Получил свое
название от широко применяющегося в компиляторах метода
переименования
метода
размещения
данных,
способствующего сокращению числа зависимостей и тем
самым увеличению производительности при отображении
необходимых исходной программе объектов (например,
переменных) на аппаратные ресурсы (например, ячейки памяти
34.
Технологии виртуализации вычисленийВиртуализацией в ИТ называют процесс логического замещения
аппаратных ресурсов их программными моделями, с которыми
взаимодействует операционная система и прикладные задачи, что
позволяет уменьшить взаимовлияние различных программ друг на
друга через аппаратные средства и в большей степени сбалансировать
загрузку вычислительных мощностей.
На аппаратных ресурсах одного компьютера может быть развёрнуто
несколько виртуальных машин со своими дисками, памятью,
операционными системами и проч. Это упрощает управление
изменениями в системе за счет их локализации в том или ином слое
изолированных с помощью виртуализации ресурсов.
Типы виртуализации Microsoft:
Виртуализация представлений позволяет отделить процесс обработки
информации от графического интерфейса приложения и системы
ввода с клавиатуры и мыши.
Виртуализация приложения позволяет создать изолированную среду для
работы приложения, включающую специфические для приложения
библиотеки, реестр и другие системные элементы.
Виртуализация ПК (машинная виртуализация)
предоставляет
пользователям виртуальные машины: локально — на ПК и
централизованно — на сервере.
35.
Технологии виртуализации вычисленийВиртуализация ПК:
36.
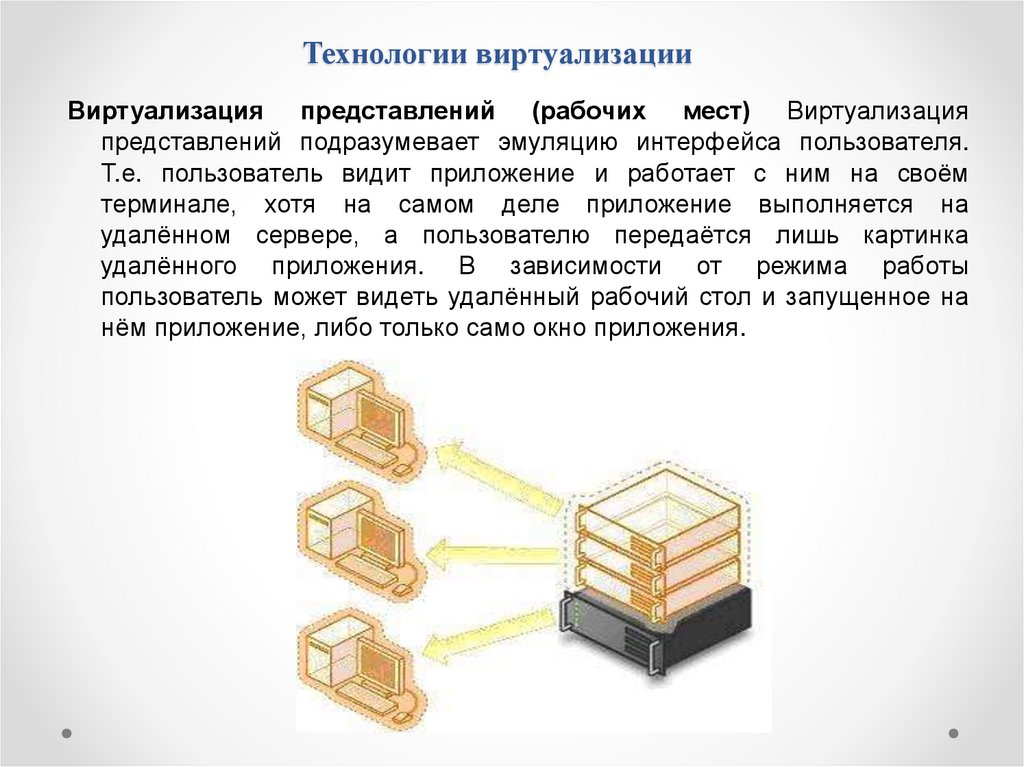
Технологии виртуализацииВиртуализация представлений (рабочих мест) Виртуализация
представлений подразумевает эмуляцию интерфейса пользователя.
Т.е. пользователь видит приложение и работает с ним на своём
терминале, хотя на самом деле приложение выполняется на
удалённом сервере, а пользователю передаётся лишь картинка
удалённого приложения. В зависимости от режима работы
пользователь может видеть удалённый рабочий стол и запущенное на
нём приложение, либо только само окно приложения.
37.
Технологии виртуализации вычисленийВиртуализация серверов:
38.
Blade-серверыПо сравнению с обычными серверами при сравнимой
производительности Blade-серверы занимают в два раза меньше
места, потребляют в три раза меньше энергии и обходятся в
четыре раза дешевле
Blade-сервер - модульная одноплатная компьютерная система,
включающая процессор и память. Лезвия вставляются в
специальное шасси (или полку) с объединительной панелью
(backplane), обеспечивающей им подключение к сети и подачу
электропитания. Это шасси выполнено в конструктиве для
установки в стандартную 19-дюймовую стойку и в зависимости от
модели и производителя, занимает в ней 3U, 6U или 10U (один U unit, или монтажная единица, равен 1,75 дюйма). За счет общего
использования таких компонентов, как источники питания, сетевые
карты и жесткие диски, Blade-серверы обеспечивают более
высокую плотность размещения вычислительной мощности в
стойке по сравнению с обычными тонкими серверами высотой 1U и
2U
39.
Blade-серверы40.
Архитектура памяти вычислительных системВ наиболее развитой иерархии памяти ЭВМ можно выделить
следующие уровни.
Регистровые ЗУ — находятся внутри процессора.
Кэш-память — быстродействующая память, которая может
находиться как внутри, так и вне процессора. Она
предназначена
для
хранения
копий
информации,
находящейся в более медленной основной памяти, програмно
не доступна.
Оперативная память (RAM — Random Access Memory) или
оперативное запоминающее устройство (ОЗУ) — часть
основной памяти ЭВМ, в которой во время работы компьютера
хранится выполняемый машинный код (программы), а также
входные, выходные и промежуточные данные, обрабатываемые
процессором.
Постоянная память (ROM - Read Only Memory) или ПЗУ - вторая
часть основной памяти ЭВМ, предназначенной для хранения
редко изменяемой информации, например, кодов команд,
тестовых программ.
Специализированные виды памяти, например, видеопамять,
предназначенная для хранения информации, отображаемой
на экране дисплея и др.
Внешняя память — магнитные и оптические диски, FLASH-память,
предназначенные
для
хранения
больших
объёмов
информации.
41.
Архитектура сверхоперативной памятиРегистровые ЗУ – размещаются внутри процессора для
обеспечения промежуточного хранения информации в
ходе выполнения команды и её результатов: регистры
адреса и текущей команды, индекса, признаков результата,
счётчик команд, указатель стека, аккумулятор, буферы
адреса и данных, общего назначения. Подробно их
назначение обсуждалось в архитектуре процессора.
В общем пространстве оперативной памяти они не
отображаются,
а
имеют
собственные
номера
и
адресацию. Разрядность регистров в зависимости от
назначения может быть разной: регистр адреса имеет
разрядность адресной шины, регистр команды может
иметь длину самой длинной из принятых в системе команд,
регистры данных обычно имеют разрядность шины данных. В
зависимости
от
версии
ассемблера
могут
быть
программно доступны отдельные байты регистров.
При создании конвейера для каждой его ступени основные
регистры дублируются, и их общее количество может быть
довольно значительным (при конвейере в 21 ступень и 20
регистрах на 1 ступень имеем 420 штук, для 64-разрядной
системы = 3360 байт).
42.
Архитектура сверхоперативной памятиОсновная идея кэширования: когда нужно обратиться в память для
чтения или записи данных, сначала проверяем, доступна ли их
копия в кэше. В случае успеха операция использует кэш, что
значительно быстрее использования основной памяти.
Данные между кэшем и основной памятью передаются блоками
фиксированного размера - линиями кэша (cache line) или
блоками кэша.
Большинство современных микропроцессоров имеют три
независимых кэша: кэш инструкций для ускорения загрузки
машинного кода, кэш данных для ускорения чтения и записи
данных и буфер ассоциативной трансляции (TLB) для
ускорения трансляции виртуальных (логических) адресов в
физические, как для инструкций, так и для данных. Кэш данных
часто реализуется в виде многоуровневого кэша (L1, L2, L3).
Перед доступом процессора в память производится сравнение
адреса запроса со значениями всех тегов кэша, в которых эти
данные могут храниться. Случай совпадения с тегом какойлибо кэш-линии называется попаданием в кэш (cache hit),
обратный случай - кэш-промах (cache miss). Отношение
количества попаданий в кэш к общему количеству запросов к
памяти называют рейтингом попаданий (hit rate), это мера
эффективности кэша для выбранного алгоритма или
программы.
43.
Размер кэш-линии может различаться в разных процессорах,но для большинства x86-процессоров он составляет 64
байта. Размер кэш-линии обычно больше размера данных,
к которому возможен доступ из одной машинной команды
(типичные размеры от 1 до 16 байт). Каждая группа данных в
памяти размером в 1 кэш-линию имеет порядковый номер.
Для основной памяти этот номер является адресом памяти
с отброшенными 6-ю младшими битами. В кэше каждой
кэш-линии дополнительно ставится в соответствие тег,
который является адресом продублированных в этой кэшлинии данных в основной памяти.
44.
Архитектура сверхоперативной памятиВ случае промаха в кэше выделяется новая запись, в тег которой
записывается адрес текущего запроса, а в саму кэш-линию —
данные из памяти после их прочтения либо данные для записи в
память. Промахи по чтению задерживают исполнение,
поскольку они требуют запроса данных в более медленной
основной памяти. Промахи по записи могут не давать
задержку, поскольку записываемые данные сразу могут быть
сохранены в кэше, а запись их в основную память можно
произвести в фоновом режиме. Кэши инструкций и данных
могут быть разделены для увеличения производительности (в
Гарвардской архитектуре) или объединены для упрощения
аппаратной реализации.
Для добавления данных в кэш после кэш-промаха может
потребоваться вытеснение (evict) ранее записанных данных.
Для выбора замещаемой строки кэша используется политика
замещения (replacement policy). Основной проблемой
является предсказание, какая строка вероятнее всего не
потребуется для последующих операций. Качественные
предсказания сложны, и аппаратные кэши используют простые
правила, такие, как LRU. Пометка некоторых областей памяти
как
некэшируемых
(non
cacheable)
улучшает
производительность за счёт запрета кэширования редко
используемых данных. Промахи для такой памяти не создают
копию данных в кэше.
45.
Архитектура сверхоперативной памятиПри записи данных в кэш должен существовать определенный
момент времени, когда они будут записаны в основную память.
Это время контролируется политикой записи (write policy). Для
кэшей со сквозной записью (write-through) любая запись в кэш
приводит к немедленной записи в память. Другой тип кэшей,
обратная запись write-back (copy-back), откладывает запись на
более позднее время. В таких кэшах отслеживается состояние
кэш-линеек ещё не сброшенных в память (пометка битом
«грязный», dirty). Запись в память производится при вытеснении
подобной строки из кэша. Таким образом, промах в кэше,
использующем политику обратной записи, может потребовать
двух операций доступа в память, один для сброса состояния
старой строки и другой — для чтения новых данных.
Данные в основной памяти могут изменяться не только
процессором, но и периферией, использующей прямой
доступ
к
памяти,
или
другими
процессорами
в
многопроцессорной системе. Изменение данных приводит к
устареванию их копии в кэше (состояние stale). В другой
реализации, когда один процессор изменяет данные в кэше,
копии этих данных в кэшах других процессоров будут
помечены как stale. Для поддержания содержимого нескольких
кэшей в актуальном состоянии используется специальный
протокол кэш когерентности.
46.
Архитектура сверхоперативной памятиТипичная структура записи в кэше:
Блок данных
тег
бит актуальности
Блок данных (кэш-линия) содержит непосредственную копию
данных из основной памяти. Бит актуальности означает, что
данная запись содержит актуальную (самую свежую)
копию. Вместо бита актуальности может использоваться
счётчик возраста строки Строка, к которой обращались в
последнюю очередь, имеет возраст 0, а строка с самым
свежим
обращением
—
возраст,
определяемый
разрядностью счётчика.
Структура адреса:
Тег
индекс
смещение
Адрес памяти разделяется (от старших бит к младшим) на Тег,
индекс и смещение. Длина поля индекса равна
log2(cache\rows) бит и соответствует ряду (строке) кэша,
используемой для записи.
Длина смещения равна log2(data\blocks)
47.
Архитектура сверхоперативной памятиПонятие ассоциативности кэша
Отображение оперативной памяти на кэшпамять может
выполняться по разным правилам. Если любая строка
оперативной памяти может быть записана в любую строку
кэшпамяти, такая кэшпамять называется полностью
ассоциативной (fully associative).
48.
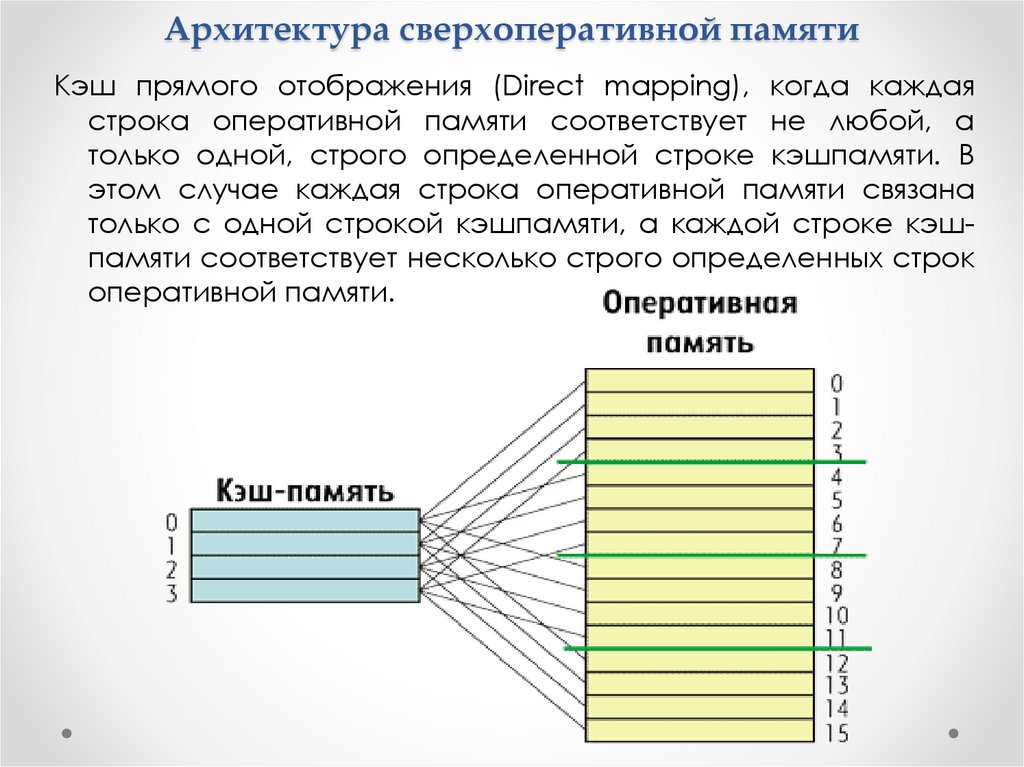
Архитектура сверхоперативной памятиКэш прямого отображения (Direct mapping), когда каждая
строка оперативной памяти соответствует не любой, а
только одной, строго определенной строке кэшпамяти. В
этом случае каждая строка оперативной памяти связана
только с одной строкой кэшпамяти, а каждой строке кэшпамяти соответствует несколько строго определенных строк
оперативной памяти.
49.
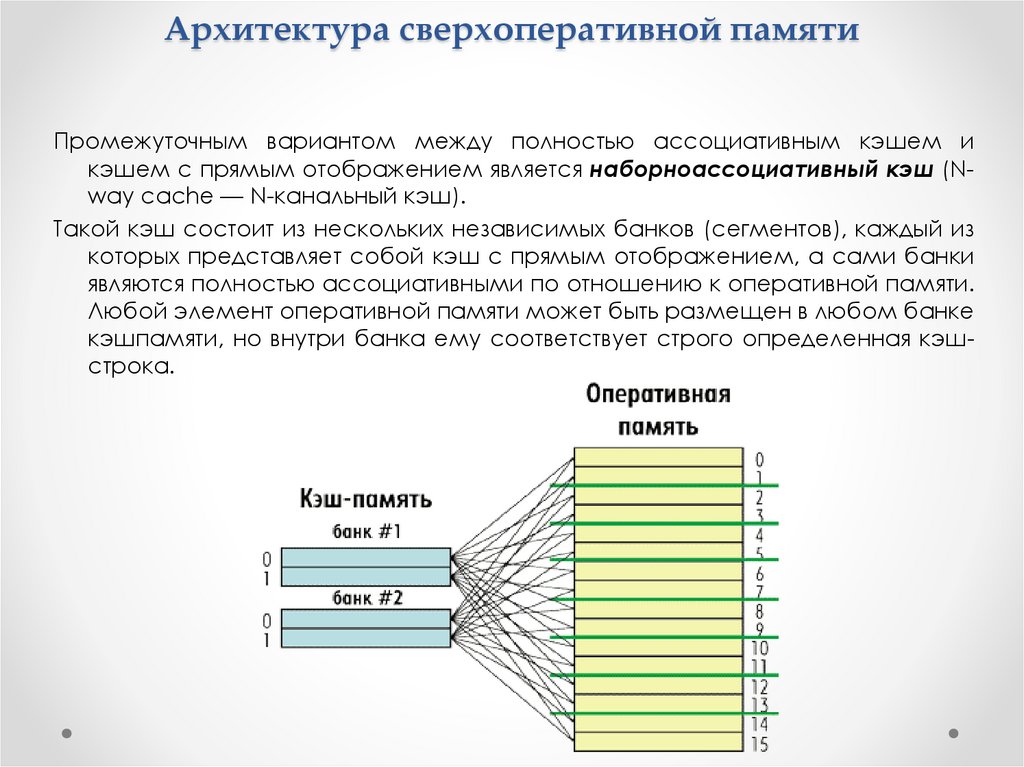
Архитектура сверхоперативной памятиПромежуточным вариантом между полностью ассоциативным кэшем и
кэшем с прямым отображением является наборноассоциативный кэш (Nway cache — N-канальный кэш).
Такой кэш состоит из нескольких независимых банков (сегментов), каждый из
которых представляет собой кэш с прямым отображением, а сами банки
являются полностью ассоциативными по отношению к оперативной памяти.
Любой элемент оперативной памяти может быть размещен в любом банке
кэшпамяти, но внутри банка ему соответствует строго определенная кэшстрока.
50.
Архитектура сверхоперативной памятиАссоциативность
является
компромиссом.
Проверка
большего числа записей требует больше энергии, площади
чипа, и, потенциально, времени. Если бы существовало 10
мест, в которые алгоритм вытеснения мог бы отобразить
место в памяти, тогда проверка наличия этого места в кэше
потребовала бы просмотра 10 записей в кэше. С другой
стороны, кэши с высокой ассоциативностью подвержены
меньшему количеству промахов, и процессор тратит
меньше времени на чтения из медленной основной памяти.
Существует эмпирическое наблюдение, что удвоение
ассоциативности (от прямого отображения к 2-канальной
или от 2- к 4-канальной) имеет примерно такое же влияние
на интенсивность попаданий (hit rate), что и удвоение
размера кэша. Увеличение ассоциативности свыше 4
каналов приносит меньший эффект для уменьшения
количества промахов (miss rate) и обычно производится по
другим
причинам,
например,
из-за
пересечения
виртуальных адресов.
51.
Архитектура сверхоперативной памятиВ порядке ухудшения (увеличения длительности проверки на
попадание)
и
улучшения
(уменьшения
количества
промахов):
кэш прямого отображения (direct mapped cache) —
наилучшее время попадания и, соответственно, лучший
вариант для больших кэшей;
2-канальный множественно-ассоциативный кэш 2-way set
associative cache;
2-канальный skewed ассоциативный кэш (the best tradeoff for
…. caches whose sizes are in the range 4K-8K bytes);
4-канальный множественно-ассоциативный кэш (4-way set
associative cache);
полностью ассоциативный кэш, fully associative cache —
наилучший (самый низкий) процент промахов (miss rate) и
лучший вариант при чрезвычайно высоких затратах при
промахе (miss penalty).
52.
Архитектура сверхоперативной памятиМногоуровневая организация кэша
Все современные процессоры имеют как минимум
двухуровневую структуру кэшпамяти, а большинство
процессоров Intel — трехуровневую кэшпамять. При этом
различают кэш первого уровня (обозначается L1), кэш
второго уровня (L2) и кэш третьего уровня (L3). Чем больше
размер кэша, тем ниже его скорость.
Кроме того, кэши разных уровней в процессоре выполняют
различные задачи. Самый быстрый и маленький кэш
первого уровня L1 всегда делится на кэш данных (L1D) и кэш
команд или инструкций (L1I). Кэш L1 всегда принадлежит
только конкретному ядру процессора.
Кэш второго уровня L2 является унифицированным (содержит
данные и команды). Кэш L2 всегда больше, чем кэш L1, но
медленнее его. В случае многоядерных процессоров кэш
L2 также принадлежит конкретному ядру процессора.
Кэш L3 является самым большим и медленным и разделяется
между всеми ядрами процессора (в архитектуре
процессоров Intel).
53.
Архитектура сверхоперативной памятиВзаимодействие между кэшами разных уровней.
Двухуровневая система кэша строится на базе одной из двух
архитектур: включающей (inclusive), и исключающей (exclusive).
Кэш L2 по включающей архитектуре дублирует содержимое
кэша L1, эффективная емкость кэшпамяти равна емкости
кэша L2.
Кэш L2 по исключающей архитектуре никогда не дублирует кэш
L1, эффективная емкость равна суммарной емкости кэшей L1
и L2.
Включающая архитектура. Если при полностью заполненном
кэше L2 процессор пытается загрузить еще одну кэшстроку, то
обнаружив, что все кэшстроки заняты, кэш L2 избавляется от
наименее ценной из них, стремясь при этом найти линейку,
которая еще не была модифицирована (ее придется
выгружать в оперативную память).
Затем кэш L2 передает полученные из памяти данные кэшу L1.
Если кэш первого уровня также заполнен, ему приходится
избавляться от одной из кэшстрок по тому же сценарию.
Загруженная порция данных присутствует и в кэше L1, и в кэше
L2.
В исключающей архитектуре, кэш L1 никогда не уничтожает кэшстроки при нехватке места, они вытесняются в кэш L2 на то
место, где находилась только что переданная кэшу L1 кэшстрока.
54.
Архитектура сверхоперативной памятиИерархия кэшпамяти в микроархитектуре Intel Core
Кэшпамять первого уровня L1 делится на 8-канальный 32килобайтный кэш данных (L1D) и 4-канальный 32-килобайтный
кэш инструкций (L1I).
Каждое ядро процессора имеет унифицированный (единый для
инструкций и данных) кэш второго уровня (L2) размером 256
Кбайт. Кэш L2 является также 8-канальным, а размер строки
кэша составляет 64 байт.
Кэш третьего уровня (L3) разделяется между всеми ядрами
процессора. Его размер зависит от количества ядер
процессора. Кэш L3 является 16-канальным.
Кэш L3 — включающий по своей архитектуре по отношению к
кэшам L1 и L2, то есть в кэше L3 всегда дублируется
содержимое кэшей L1 и L2. А вот кэши L1 и L2 не являются ни
включающими, ни исключающими по отношению друг к другу,
то есть кэш L2 может содержать, а может и не содержать
копию данных кэша L1.
Применение именно включающего кэша L3 имеет свои
преимущества по сравнению с исключающей архитектурой.
Предположим сначала, что ядро процессора Core 0, обнаружив,
что требуемых ему данных нет ни в кэше L1, ни в кэше L2,
обращается к кэшу L3. Если необходимых данных нет также и в
кэше L3, инициируется обращение к основной памяти.
55.
Архитектура сверхоперативной памятиЕсли же требуемые ядру Core 0 данные обнаруживаются в
кэше L3, то при исключающей архитектуре кэша больше не
нужно выполнять никаких действий, поскольку данная
архитектура гарантирует их отсутствие в кэшах L1 и L2 ядер
Core 1, Core 2 и Core 3.
Однако при включающей архитектуре кэша L3 наличие
требуемых данных в кэше L3 означает, что они также
содержатся в какомнибудь из кэшей ядер Core 1, Core 2 или
Core 3. Но в этом случае не нужна дополнительная
проверка кэшей L1 и L2 всех остальных ядер. Достигается
это тем, что в теге кэшстроки L3-кэша записывается, к
какому из ядер принадлежат данные, поэтому достаточно
лишь прочитать содержимое этого тега.
56.
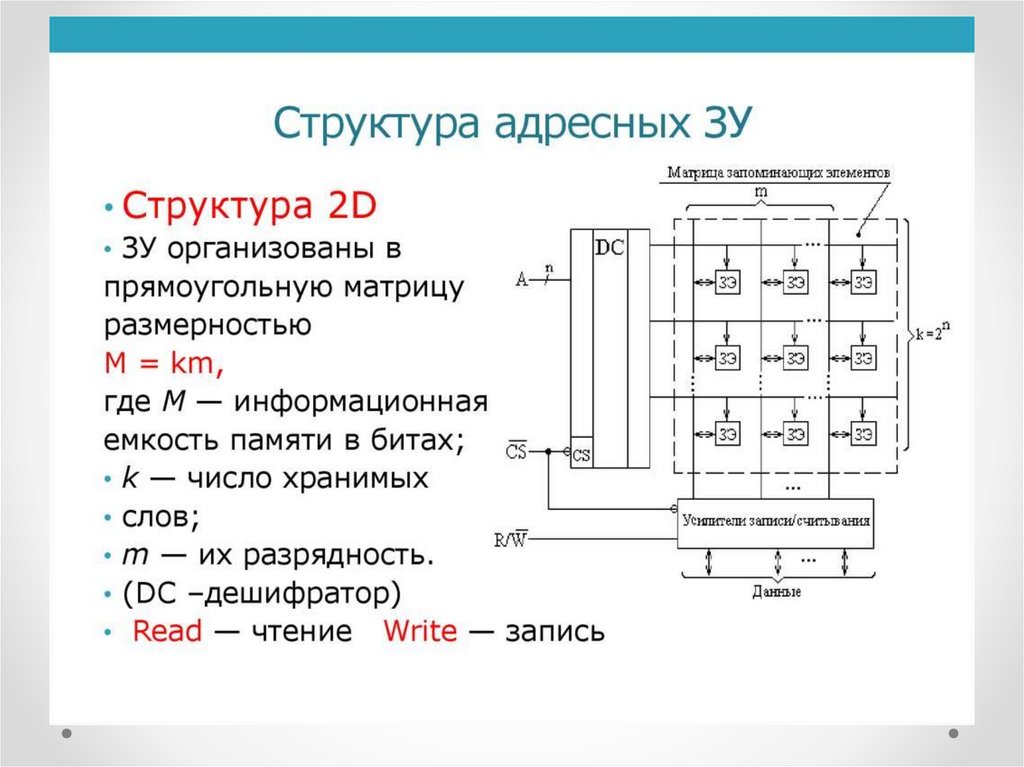
Архитектура оперативной памятиЗУ адресного типа состоят из трёх основных блоков:
- Массив элементов памяти,
- Блок адресной выборки,
- Блок управления.
Варианты ЗУ имеют много общего с точки зрения структурных
схем. Общность структур особенно проявляется для
статических ОЗУ и памяти ROM; для них характерны структуры
2D, 3D и 2DM.
Структура 2D
В ЗУ, с информационной ёмкостью M, запоминающие элементы
организованы в матрицу размерностью k·m:
M = k·m,
где k — количество хранимых слов,
m — их разрядность.
Дешифратор адресного кода имеет k выходов и активизирует
одну из выходных линий, разрешая одновременный доступ ко
всем элементам выбранной строки, хранящей слово.
Элементы каждого из столбцов соединены вертикальными
разрядными линиями и хранят одноимённые биты всех слов.
Таким образом, при наличии разрешающего сигнала CS,
выбранная дешифратором ячейка памяти подключается к
разрядным шинам, по которым производится запись или
считывание адресованного слова.
57.
Архитектура оперативной памяти58.
Архитектура оперативной памятиСтруктура 3D
Структура типа 2D применяется лишь в ЗУ с малой
информационной ёмкостью, т.к. при росте ёмкости
усложняется дешифратор адреса. Например, при коде
разрядностью n=8 дешифратор должен иметь 2n=256 выходов.
В структуре типа 3D выборка одноразрядного элемента памяти из
массива производится по двум координатам. Код адреса
разрядностью n делится на две половины и используются два
дешифратора: по строкам и по столбцам. При этом число
выходов двух дешифраторов равно 2n/2+2n/2=2n/2+1. Если n=8, то
число выходов дешифраторов равно 24+24=32, а количество
элементов памяти равно 2n/2·2n/2=2n=256. В структуре 2D-типа,
как уже было отмечено выше, потребовался бы более сложный
дешифратор на 256 выходов.
Таким образом, с помощью двух дешифраторов, имеющих
небольшое число выходов, осуществляется доступ ко всем
элементам памяти микросхемы.
Структура 3D может применяться в ЗУ с одно- и многоразрядной
организацией, принимая при этом «трёхмерный» характер. В
этом случае несколько матриц управляются от двух
дешифраторов, относительно которых матрицы включены
параллельно.
59.
Архитектура оперативной памяти60.
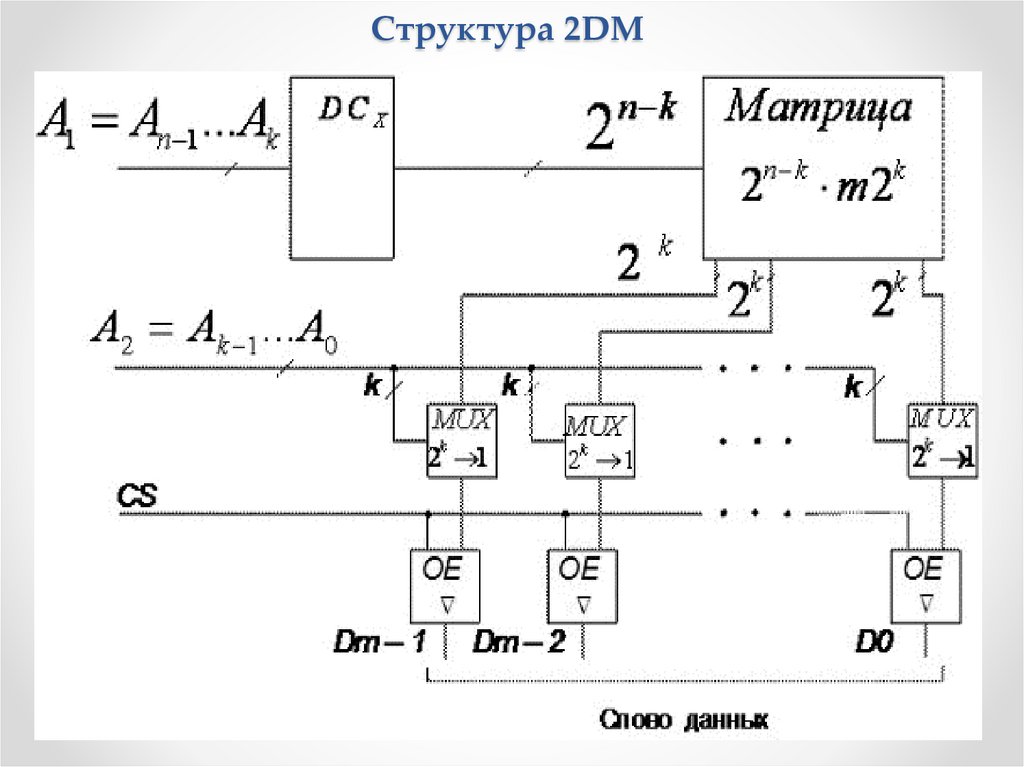
Архитектура оперативной памятиСтруктура 2DM
состоит из дешифратора, который выбирает целую строку.
Однако, в отличие от структуры 2D, длина строки
многократно превышает разрядность хранимых слов. При
этом число строк уменьшается и, следовательно,
уменьшается число выводов дешифратора.
Выбор строк матрицы памяти производится с помощью
старших разрядов адреса An-1…Ak. Остальные k разрядов
используются для выбора необходимого m-разрядного
слова из множества слов, содержащихся в строке.
Это выполняется с помощью мультиплексоров, на адресные
входы которых подаются коды Ak-1…A0. Длина строки равна
m·2k, где m — разрядность слов.
Из каждого отрезка строки, длиной 2k, мультиплексор
выбирает один бит. На выходах m мультиплексоров
формируется выходное m-разрядное слово.
По разрешению сигнала CS, поступающего на входы OE
управляемых буферов с тремя выходными состояниями,
выходное слово передаётся на внешнюю шину.
61.
Структура 2DM62.
Архитектура оперативной памятиОсновные параметры ЗУ
Информационная ёмкость — максимально возможный объём
хранимой информации. Выражается в битах или словах (в
частности, в байтах). Бит хранится запоминающим элементом
(ЗЭ), а слово — запоминающей ячейкой (ЗЯ), т.е. группой ЗЭ, к
которой возможно лишь одновременное обращение.
Быстродействие (производительность) ЗУ оценивают временами
записи, считывания и длительностями циклов записи/чтения.
Время записи — интервал после появления сигнала записи и
установлением ЗЯ в состояние, задаваемое входным словом.
Время считывания — интервал между моментами появления
сигнала чтения и слова на выходе ЗУ. Циклы записи и чтения —
это время между двумя последовательностями записи или
чтения. Длительности циклов могут превышать времена записи
и чтения, так как после этих операций может потребоваться
время для восстановления начального состояния ЗУ.
Кроме
основных
(эксплуатационных
или
измеряемых)
параметров,
ЗУ
характеризуются
рядом
режимных параметров, обеспечение которых необходимо для
нормального функционирования ЗУ. Для управляющих
сигналов задаются не только длительности, но и взаимное
положение во времени.
63.
Архитектура оперативной памятиФункционирование ЗУ во времени регламентируется
изготовителями. Чтобы исключить возможность обращения к
другой ячейке, адрес подаётся раньше, чем другие
сигналы, с опережением на время декодирования и должен
держаться в течение всего цикла обращения к памяти.
Затем следуют сигналы, определяющие направление
передачи данных и, если предполагается запись, то данные,
а также сигнал выборки кристалла. Затем следует
стробирующий сигнал. Всю эту информацию дают
временные диаграммы циклов записи в память и чтения
(считывания) из памяти, приводимые в справочниках.
Самые главные временные параметры:
- время выборки адреса (задержка между изменением
адреса и выдачей данных);
- время выборки микросхемы (задержка выдачи данных по
выставлению сигнала -CS);
- минимальная длительность сигнала записи -WR;
- минимальная длительность сигнала -CS.
Всего же количество временных параметров может достигать
двух-трех десятков, вся подобная информация имеется в
справочниках.
64.
Архитектура оперативной памятиТипичные временные диаграммы записи в память (а) и чтения из
памяти (б)
Для записи информации в память надо выставить код адреса на
адресных входах, выставить код записываемых в этот адрес
данных на входах данных, подать сигнал записи –WR и подать
сигнал выбора микросхемы –CS. Порядок выставления
сигналов бывает различным, он может быть существенным или
несущественным (например, можно выставлять или снимать –
CS раньше или позже выставления или снятия –WR). Собственно
запись обычно производится сигналом -WR или –CS, причем
данные должны удерживаться в течение всего сигнала –WR (или
–CS) и заданное время после его окончания.
65.
Архитектура оперативной памятиВ зависимости от того, в каком порядке может записываться или
читаться информация, существуют две разновидности ЗУ:
ОЗУ с параллельным или произвольным доступом;
ОЗУ с последовательным доступом.
Параллельный или произвольный доступ: можно записывать
информацию в любой адрес ОЗУ и читать информацию из
любого адреса ОЗУ в произвольном порядке. Требует
формирования
сложных
последовательностей
входных
сигналов памяти. Этот режим применяется в компьютерах и
контроллерах, где самыми главными факторами являются
универсальность и гибкость использования памяти.
Последовательный доступ предполагает более простой порядок
общения с памятью. Адрес памяти формируется схемой
автоматически. Для записи информации надо всего лишь
подать код записываемых данных и сопроводить его стробом
записи. Для чтения информации надо подать строб чтения и
получить читаемые данные. Автоматическое задание адреса
осуществляется внутренними счетчиками, меняющими свое
состояние по каждому обращению к памяти. Недостаток
подхода: нет возможности записывать или читать ячейки с
произвольными адресами в любом порядке. Зато упрощается
и ускоряется процедура обмена с памятью (запись и чтение).
66.
Архитектура оперативной памятиМожно выделить три основных типа оперативной памяти с
последовательным доступом:
- память типа "первым вошел - первым вышел" ( FIFO, First In - First
Out);
- память магазинного, стекового типа, работающая по принципу
"последним вошел - первым вышел" (LIFO, Last In - First Out).
- память для хранения массивов данных.
Два
первых
типа
памяти
подразумевают
возможность
чередования операций записи и чтения в памяти. Память с
принципом LIFO используется, в частности, в компьютерах
(стек), где она хранит информацию о параметрах программ
и подпрограмм.
Для памяти FIFO требуется хранение двух кодов адреса (адрес
для записи и адрес для чтения), для памяти LIFO достаточно
одного кода адреса.
Хранение массивов в памяти предполагает, что сначала в память
записывается целиком большой массив данных, а потом этот
же массив целиком читается из памяти. Эта память также
может быть устроена по двум принципам (FIFO и LIFO). В обоих
этих случаях для общения с памятью требуется хранить только
один код адреса памяти.
67.
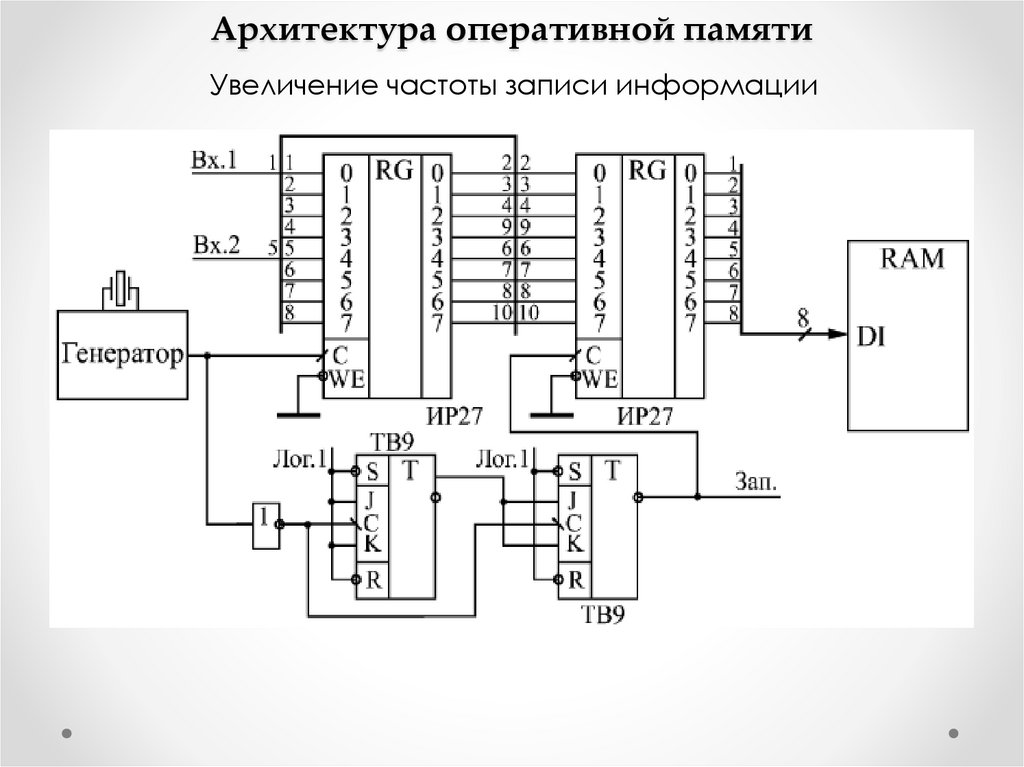
Архитектура оперативной памятиПовышение быстродействия
Самое распространенное и самое простое решение применение сдвиговых регистров. Частота тактовых импульсов
этих регистров может достигать десятков и сотен мегагерц.
Если необходимо в 8 раз увеличить частоту чтения информации из
памяти, то надо соединить нужное количество микросхем
памяти для увеличения разрядности шины данных в 8 раз, а
затем применить на выходах данных схему на основе 8разрядного регистра сдвига. 8-разрядный код, читаемый из
памяти, записывается в сдвиговый регистр, а затем сдвигается
семь раз с частотой, в 8 раз большей, чем частота опроса
памяти. И запись, и сдвиг производятся одним тактовым
сигналом с генератора. Восемь тактовых импульсов
отсчитываются синхронным счетчиком. Для управления работой
регистра сдвига применен элемент 3ИЛИ-НЕ, выдающий
положительный импульс в течение первой 1/8 периода опроса
памяти. Этот же сигнал используется как строб чтения из памяти
(своим задним фронтом он переключает адреса памяти).
Поскольку информация в память записывается не по фронту
сигнала, а по уровню, код с выхода сдвигового регистра
необходимо перед записью в память переписать в
параллельный регистр, где он будет затем храниться в течение
всего периода записи в память.
68.
Архитектура оперативной памятиУвеличение частоты чтения информации
69.
Архитектура оперативной памятиУвеличение частоты записи информации
70.
Архитектура оперативной памяти71.
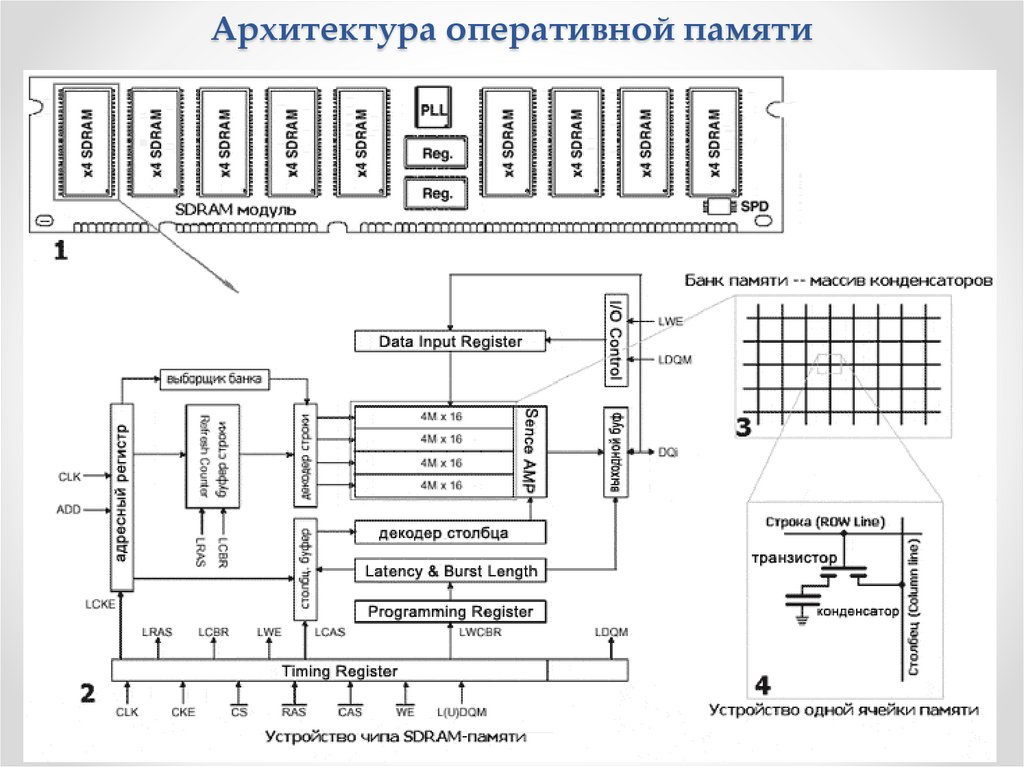
Архитектура оперативной памятиОсновные особенности SDRAM
Все операции синхронизированы с тактовой частотой системной
шины и процессора.
SDRAM-модуль разделен на два или более банков, что позволяет
иметь одновременно две и более открытые страницы. Доступ
чередуется (bank interleaving), что позволяет исключить
задержки, связанные с регенерацией памяти.
Конвейерная
обработка
данных
позволяет
производить
обращение по новому адресу столбца ячейки памяти на
каждом тактовом цикле. Микросхема SDRAM имеет счетчик
потока, который используется для наращивания адресов
столбцов ячеек памяти с целью обеспечения очень быстрого
доступа к ним.
На чипе памяти размещен регистр режимов, который
применяется
для
настройки
основных
параметров
микросхемы, в том числе длины и типа потока.
SDRAM позволяет устанавливать задержку вывода данных,
которые определяется числом тактовых импульсов между
моментом получения адреса столбца и выводом данных.
Значение этого параметра может быть 2 или 3 (латентность).
Теоретической границей, при которой устойчиво функционирует
SDRAM, является частота 125 МГц, хотя технологический запас
может позволить работу и на частоте 133 МГц.
72.
Архитектура оперативной памятиОсновные временные характеристики SDRAM
73.
Архитектура оперативной памятиDDR SDRAM
По сравнению с обычной памятью типа SDR SDRAM, в памяти
SDRAM с удвоенной скоростью передачи данных (double
data rate SDRAM, DDR SDRAM или SDRAM II) была вдвое
увеличена пропускная способность.
У всех предыдущих DRAM были разделены линии адреса,
данных и управления, которые накладывают ограничения на
скорость работы устройств. Для преодоления этого
ограничения ввсе сигналы стали выполняться на одной шине:
технологии DRDRAM и SLDRAM. Стандарт SLDRAM является
открытым и, подобно предыдущей технологии, SLDRAM
использует оба перепада тактового сигнала.
Память DDR SDRAM работает на частотах в 100, 133, 166 и 200
МГц, её время полного доступа — 30 и 22,5 нс, а время
рабочего цикла — 5, 3,75, 3 и 2,5 нс.
Так как частота синхронизации лежит в пределах от 100 до 200
МГц, а данные передаются по 2 бита на один
синхроимпульс, как по фронту, так и по спаду тактового
импульса, то эффективная частота передачи данных лежит
в пределах от 200 до 400 МГц. Такие модули памяти
обозначаются DDR200, DDR266, DDR333, DDR400.
74.
Архитектура оперативной памятиDDR2 SDRAM
Конструктивно новый тип оперативной памяти DDR2 SDRAM был
выпущен в 2004 году. Основываясь на технологии DDR SDRAM,
этот тип памяти за счёт технических изменений показывает
более высокое быстродействие
и предназначен
для
использования на более современных компьютерах. Память
может работать с тактовой частотой шины 200, 266, 333, 337,
400, 533, 575 и 600 МГц. При этом эффективная частота
передачи данных соответственно будет 400, 533, 667, 675, 800,
1066, 1150 и 1200 МГц. Некоторые производители модулей
памяти помимо стандартных частот выпускают и образцы,
работающие на нестандартных (промежуточных) частотах.
Они предназначены для использования в разогнанных
системах, где требуется запас по частоте. Время полного
доступа — 25, 11,25, 9, 7,5 нс и менее. Время рабочего цикла —
от 5 до 1,67 нс.
DDR3 SDRAM
Основан на технологиях DDR2 SDRAM со вдвое увеличенной
частотой передачи данных по шине памяти. Отличается
пониженным
энергопотреблением.
Частота
полосы
пропускания лежит в пределах от 800 до 2400 МГц (рекорд
частоты — более 3000 МГц), что обеспечивает большую
пропускную способность.
75.
Архитектура оперативной памятиDDR4 SDRAM (double-data-rate four synchronous dynamic random
access memory) - развитие предыдущих поколений DDR.
Отличается повышенными частотными характеристиками и
пониженным напряжением питания.
Основное отличие DDR4 заключается в удвоенном до 16 числе
банков (в 2 группах банков). Пропускная способность памяти
DDR4 может достигать 25,6 ГБ/c в случае повышения
максимальной эффективной частоты до 3200 МГц. Повышена
надёжность работы за счёт введения механизма контроля
чётности на шинах адреса и команд.
В массовое производство вышла во 2 квартале 2014 года, вместе
с процессорами Intel Haswell-E/Haswell-EP, требующих DDR4
Для расчёта максимальной пропускной способности памяти
DDR4 необходимо её эффективную частоту умножить на 64
бита (8 байт), то есть размер данных, который может быть
передан за 1 такт работы памяти. Таким образом, для
эффективной частоты:
1600 Мгц пропускная способность составит 1600 × 8 = 12 800 МБ/c
2133 МГц пропускная способность составит 2133 × 8 = 17 064 МБ/c
3200 МГц пропускная способность составит 3200 × 8 = 25 600 МБ/c
Из-за
временных
ограничений
по
взаимодействию
с
микросхемами памяти реальная пропускная способность
меньше на 5—10 %.
76.
Архитектура оперативной памятиОбъём модулей
Объем кристалла DDR4 составляет от 2 до 16 Гбит,
организация модулей памяти - ×4, ×8 или ×16 банков.
Минимальный объём одного модуля DDR4 составляет 4 ГБ,
максимальный — 128 ГБ (кристаллы по 8 Гбит, упаковка 4
кристаллов в чип). Не исключается производство модулей
объёмом в 512 ГБ на базе кристаллов 16 Гбит и упаковке 8
кристаллов в чип.
Размеры модулей
DDR4 имеет 288-контактные DIMM-модули, схожие по
внешнему виду с 240-контактными DIMM DDR-2/DDR-3.
Контакты расположены плотнее (0,85 мм вместо 1,0), чтобы
разместить их на стандартном 5¼-дюймовом (133,35 мм)
слоте DIMM. Высота увеличивается незначительно (31,25 мм
вместо 30,35).
DDR4 модули SO-DIMM имеют 260 контактов[35] (а не 204),
которые расположены ближе друг к другу (0,5 мм, а не 0,6).
Модуль стал на 1,0 мм шире (68,6 мм вместо 67,6), но
сохранил ту же высоту — 30 мм.
77.
Архитектура оперативной памятиУвеличения пропускной способности можно добиться не только с
помощью расширения шины памяти, увеличения её частоты и
количества банков, т.е. на уровне отдельного модуля, но и
организацией многоканальной системы на уровне чипсета.
Многоканальный
режим
(Multi-channel)
использование
нескольких каналов для доступа к объединённому банку
памяти
Двухканальный режим — режим параллельной работы двух
каналов памяти. Позволяет увеличить пропускную способность
до 2 раз по сравнению с одноканальным режимом.
Трёхканальный режим — параллельно работают 3 модуля или три
пары модулей.
Четырёхканальный режим — параллельно работают 4 модуля или
четыре пары модулей. Поддерживается на платформах LGA
2011, LGA 2011v3, TR4, SP3.
Для включения многоканального режима необходимо:
Одинаковая конфигурация модулей DIMM на каждом канале
Одинаковая плотность (128 Мбит, 256 Мбит, и т. п.)
Каналы памяти должны быть идентичны
На большинстве материнских плат должны быть заполнены
симметричные разъемы памяти (разъем 0 или разъем 1)
Желательно, чтобы был один производитель, одинаковые
спецификации
синхронизации,
одинаковая
производительность.
78.
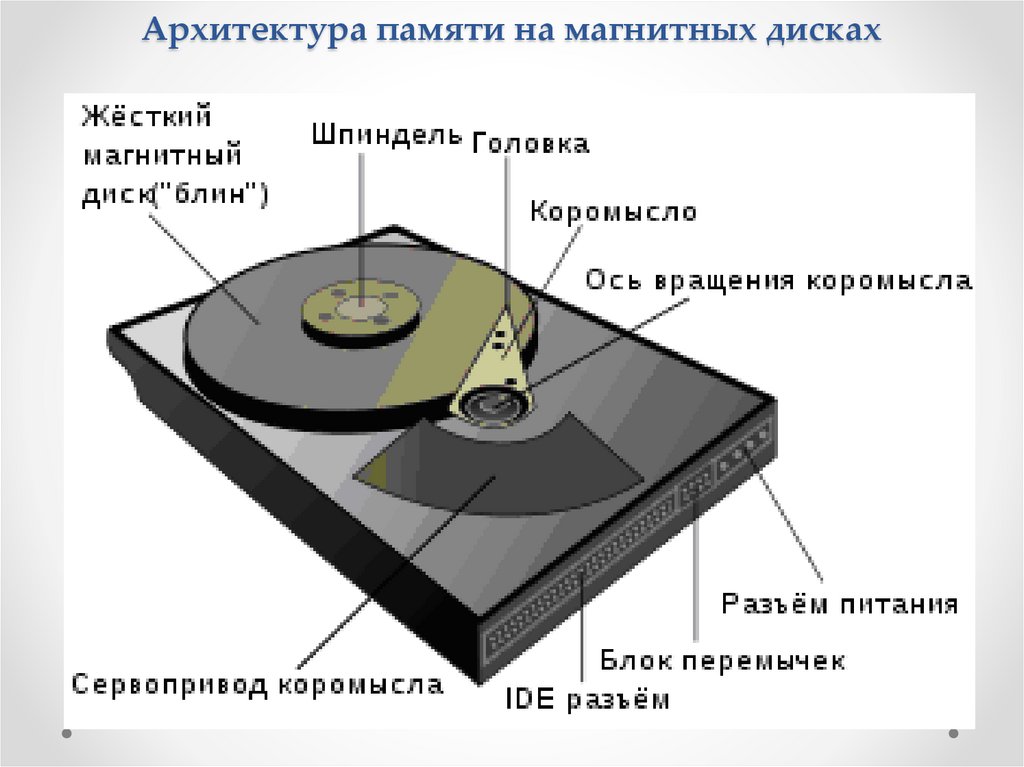
Архитектура памяти на магнитных дискахНакопи́тель на жёстких магни́тных ди́сках или НЖМД (hard
(magnetic) disk drive, HDD, HMDD), жёсткий диск —
запоминающее
устройство
произвольного
доступа,
основанное на принципе магнитной записи. Является
основным
накопителем
данных
в
большинстве
компьютеров.
Информация
в
НЖМД
записывается
на
жёсткие
(алюминиевые или стеклянные) пластины, покрытые слоем
ферромагнитного материала, чаще всего двуокиси
хрома — магнитные диски. В НЖМД используется одна или
несколько пластин на одной оси. Считывающие головки в
рабочем режиме не касаются поверхности пластин
благодаря прослойке набегающего потока воздуха,
образующейся у поверхности при быстром вращении.
Расстояние между головкой и диском составляет несколько
нанометров (в современных дисках около 10 нм), а
отсутствие механического контакта обеспечивает долгий
срок службы устройства. При отсутствии вращения дисков
головки находятся у шпинделя или за пределами диска в
безопасной («парковочной») зоне, где исключён их
нештатный контакт с поверхностью дисков.
79.
Архитектура памяти на магнитных дисках80.
Архитектура памяти на магнитных дискахС середины 1990-х начали применяться головки на основе
эффекта гигантского магнитного сопротивления (ГМС), затем
- головки на основе туннельного магниторезистивного
эффекта (в них изменение магнитного поля приводит к
изменению сопротивления в зависимости от изменения
напряжённости магнитного поля; подобные головки позволяют
увеличить вероятность достоверности считывания информации,
особенно при больших плотностях записи информации). В
2007
году
устройства
на
основе
туннельного
магниторезистивного эффекта с оксидом магния (эффект
открыт в 2005) полностью заменили устройства на основе
эффекта ГМС.
Метод продольной записи. Биты информации записываются с
помощью
маленькой
головки,
которая,
проходя
над
поверхностью
вращающегося
диска,
намагничивает
миллиарды горизонтальных дискретных областей — доменов.
При этом вектор намагниченности домена расположен
продольно, то есть параллельно поверхности диска. Каждая из
этих областей является логическим нулём или единицей, в
зависимости от направления намагниченности. Максимально
достижимая при использовании данного метода плотность
записи составляет около 23 Гбит/см². К 2010 году этот метод
был практически вытеснен методом перпендикулярной записи.
81.
Архитектура памяти на магнитных дискахМетод перпендикулярной записи — технология, при которой биты
информации сохраняются в вертикальных доменах. Это
позволяет использовать более сильные магнитные поля и
снизить площадь материала, необходимую для записи 1 бита.
Плотность записи при этом методе резко подскочила — на
свыше 30 % еще на первых образцах (на 2009 год — 400
Гбит/дюйм² / 62 Гбит/см²). А теоретический предел отодвинулся
на порядки и составляет 1 Тбит на квадратный дюйм. Жёсткие
диски с перпендикулярной записью стали доступны на рынке с
2006 года. Благодаря перпендикулярной записи, винчестеры
продолжают бить рекорды ёмкости, вмещая уже по 8 и даже
10 Терабайт.
Метод черепичной магнитной записи (Shingled Magnetic
Recording, SMR) был реализован в начала 2010-х. В нём
используется тот факт, что ширина области чтения меньше, чем
ширина записывающей головки. Запись дорожек в этом
методе производится с частичным наложением в рамках групп
дорожек (пакетов). Каждая следующая дорожка пакета
частично закрывает предыдущую (подобно черепичной
кровле), оставляя от нее узкую часть, достаточную для
считывающей
головки.
Черепичная
запись
увеличивает
плотность записанной информации, однако осложняет
перезапись - при каждом изменении требуется полностью
перезаписать весь пакет перекрывающихся дорожек.
82.
Архитектура памяти на магнитных дискахМетод тепловой магнитной записи (Heat-assisted magnetic
recording, HAMR) остается перспективным, продолжаются
его доработки и внедрение. При использовании этого
метода используется точечный подогрев диска, который
позволяет головке намагничивать очень мелкие области его
поверхности.
После
того,
как
диск
охлаждается,
намагниченность «закрепляется». На 2009 год были доступны
только экспериментальные образцы, плотность записи
которых составляла 150 Гбит/см². Специалисты Hitachi
называют предел для этой технологии в 2,3−3,1 Тбит/см², а
представители Seagate Technology — 7,75 Тбит/см².
Структурированный (паттернированный) носитель данных
(Bit patterned media), — перспективная технология хранения
данных на магнитном носителе, использующая для записи
данных массив одинаковых магнитных ячеек, каждая из
которых соответствует одному биту информации, в отличие
от современных технологий магнитной записи, в которых бит
информации записывается на нескольких магнитных
доменах.
83.
Характеристики дисковых накопителейИнтерфейс. Современные серийно выпускаемые внутренние
жёсткие диски могут использовать интерфейсы ATA (он же IDE
и PATA), SATA, eSATA, SCSI, SAS, FireWire, SDIO и Fibre Channel.
Ёмкость — количество данных, которые могут храниться
накопителем. С момента создания первых жёстких дисков в
результате непрерывного совершенствования технологии
записи данных их максимально возможная ёмкость
непрерывно увеличивается. Ёмкость современных жёстких
дисков (с форм-фактором 3,5 дюйма) на начало 2015 года
достигает 6000 Гб (6 терабайт). В отличие от принятой в
информатике системы приставок, обозначающих кратную
1024 величину (см.: двоичные приставки), производителями при
обозначении ёмкости жёстких дисков используются величины,
кратные 1000. Так, ёмкость жёсткого диска, маркированного
как «200 ГБ», составляет 186,2 ГиБ.
Физический размер (форм-фактор; dimension) — почти все
накопители 2001—2008 годов для персональных компьютеров и
серверов имеют ширину либо 3,5, либо 2,5 дюйма — под
размер стандартных креплений для них соответственно в
настольных компьютерах и ноутбуках. Также получили
распространение форматы 1,8, 1,3, 1 и 0,85 дюйма.
Прекращено производство накопителей в форм-факторах 8 и
5,25 дюймов.
84.
Характеристики дисковых накопителейВремя произвольного доступа (random access time) —
среднее время, за которое винчестер выполняет операцию
позиционирования головки чтения/записи на произвольный
участок магнитного диска. Диапазон этого параметра — от
2,5 до 16 мс. Как правило, минимальным временем
обладают диски для серверов (например, у Hitachi Ultrastar
15K147 — это 3,7 мс), самым большим из актуальных —
диски для портативных устройств (Seagate Momentus
5400.3 — 12,5 мс). Для сравнения, у SSD-накопителей этот
параметр меньше 1 мс.
Скорость вращения шпинделя (spindle speed) — количество
оборотов шпинделя в минуту. От этого параметра в
значительной степени зависят время доступа и средняя
скорость передачи данных. В настоящее время выпускаются
винчестеры со следующими стандартными скоростями
вращения: 4200, 5400 и 7200 (ноутбуки); 5400, 5700, 5900, 7200
и 10 000 (персональные компьютеры); 10 000 и 15 000 об/мин
(серверы и высокопроизводительные рабочие станции).
Увеличению скорости вращения шпинделя в винчестерах
для ноутбуков препятствует гироскопический эффект,
влияние которого пренебрежимо мало в неподвижных
компьютерах.
85.
Характеристики дисковых накопителейНадёжность (reliability) — определяется как среднее время
наработки на отказ (MTBF). Подавляющее большинство
современных дисков поддерживают технологию S.M.A.R.T.
Количество операций ввода-вывода в секунду (IOPS) — у
современных дисков это около 50 оп./с при произвольном
доступе
к
накопителю
и
около
100
оп./сек
при
последовательном доступе.
Потребление энергии.
Сопротивляемость ударам (G-shock rating) — измеряется в
единицах
допустимой
перегрузки
во
включённом
и
выключенном состоянии.
Скорость передачи данных (Transfer Rate) при последовательном
доступе:
внутренняя зона диска: от 44,2 до 74,5 Мб/с;
внешняя зона диска: от 60,0 до 111,4 Мб/с.
Объём буфера — буфером называется промежуточная память,
предназначенная
для
сглаживания
различий
скорости
чтения/записи и передачи по интерфейсу. В современных
дисках он обычно варьируется от 8 до 128 Мб.
Уровень шума — шум, который производит механика накопителя
при его работе. Указывается в децибелах. Тихими
накопителями считаются устройства с уровнем шума около 26
дБ и ниже.
86.
Управление дисковым накопителемВ ранних жёстких дисках управляющая логика была вынесена на
MFM- или RLL-контроллер компьютера, а плата электроники
содержала только модули аналоговой обработки и управления
шпиндельным двигателем, позиционером и коммутатором
головок. Увеличение скоростей передачи данных вынудило
разработчиков уменьшить до предела длину аналогового
тракта, и в современных жёстких дисках блок электроники
обычно содержит:
управляющий блок,
постоянное запоминающее устройство (ПЗУ),
буферную память,
интерфейсный блок и
блок цифровой обработки сигнала.
Интерфейсный блок обеспечивает сопряжение электроники
жёсткого диска с остальной системой.
Блок ПЗУ хранит управляющие программы для блоков управления
и цифровой обработки сигнала, а также служебную
информацию винчестера.
Буферная память сглаживает разницу скоростей интерфейсной
части
и
накопителя
(используется
быстродействующая
статическая память). Увеличение размера буферной памяти в
некоторых случаях позволяет увеличить скорость работы
87.
Управление дисковым накопителемБлок управления представляет собой систему управления,
принимающую электрические сигналы позиционирования
головок, и вырабатывающую управляющие воздействия
приводом
типа
«звуковая
катушка»,
коммутации
информационных потоков с различных головок, управления
работой всех остальных узлов (к примеру, управление
скоростью вращения шпинделя), приёма и обработки
сигналов с датчиков устройства (система датчиков может
включать в себя одноосный акселерометр, используемый в
качестве
датчика
удара,
трёхосный
акселерометр,
используемый в качестве датчика свободного падения, датчик
давления, датчик угловых ускорений, датчик температуры).
Блок цифровой обработки сигнала осуществляет очистку
считанного аналогового сигнала и его декодирование
(извлечение
цифровой
информации).
Для
цифровой
обработки применяются различные методы, например, метод
PRML (Partial Response Maximum Likelihood — максимальное
правдоподобие при неполном отклике). Осуществляется
сравнение принятого сигнала с образцами. При этом
выбирается образец, наиболее похожий по форме и
временным характеристикам с декодируемым сигналом.
88.
Структура данных на дисковом накопителеНа заключительном этапе сборки устройства поверхности
пластин форматируются — на них формируются дорожки и
секторы. Конкретный способ определяется производителем
и/или стандартом, но, как минимум, на каждую дорожку
наносится магнитная метка, обозначающая её начало.
Существуют утилиты, способные тестировать физические
секторы диска и ограниченно просматривать и править его
служебные данные.
С целью адресации пространства поверхности пластин диска
делятся на дорожки — концентрические кольцевые области.
Каждая дорожка делится на равные отрезки — секторы.
Адресация CHS (цилинр-голвка-сектор) предполагает, что все
дорожки в заданной зоне диска имеют одинаковое число
секторов.
Цилиндр — совокупность дорожек, равноотстоящих от центра, на
всех рабочих поверхностях пластин жёсткого диска. Номер
головки задает используемую рабочую поверхность, а номер
сектора — конкретный сектор на дорожке.
Чтобы использовать адресацию CHS, необходимо знать
геометрию
используемого
диска:
общее
количество
цилиндров, головок и секторов в нём. Первоначально эту
информацию требовалось задавать вручную; в стандарте ATA1 была введена функция автоопределения геометрии
(команда Identify Drive).
89.
Структура данных на дисковом накопителе90.
Структура данных на дисковом накопителеОсобенности HDD со встроенными контроллерами
Зонирование
На
пластинах
современных
«винчестеров»
дорожки
сгруппированы в несколько зон (Zoned Recording). Все дорожки
одной зоны имеют одинаковое количество секторов. Однако на
дорожках внешних зон секторов больше, чем на дорожках
внутренних (определяется максимально доступной плотностью
записи). Это позволяет, используя бо́льшую длину внешних
дорожек, добиться более равномерной плотности записи,
увеличивая ёмкость пластины при той же технологии
производства.
Резервные секторы
Для увеличения срока службы диска на каждой дорожке могут
присутствовать дополнительные резервные секторы. Если в
каком-либо секторе возникает неисправимая ошибка, то этот
сектор может быть подменён резервным (remapping). Данные,
хранившиеся в нём, при этом могут быть потеряны или
восстановлены при помощи ECC, а ёмкость диска останется
прежней. Существует две таблицы переназначения: одна
заполняется на заводе, другая — в процессе эксплуатации.
Границы зон, количество секторов на дорожку для каждой зоны
и таблицы переназначения секторов хранятся в ППЗУ блока
электроники.
91.
Структура данных на дисковом накопителеПо мере роста ёмкости дисков их физическая геометрия
перестала вписываться в ограничения, накладываемые
программными и аппаратными интерфейсами. В результате
контроллеры дисков стали сообщать не реальную, а
логическую геометрию. Так, максимальные номера секторов
и головок для большинства моделей берутся 63 и 255
(максимально возможные значения в функциях прерывания
BIOS INT 13h), а число цилиндров подбирается соответственно
ёмкости диска, хотя физически головок гораздо меньше, а
цилиндров и секторов - больше.
Адресация данных
Минимальной адресуемой областью данных на жёстком диске
является сектор. Размер сектора традиционно был равен 512
байт. В 2006 году IDEMA объявила о переходе на размер
сектора 4096 байт, который завершили к 2010 году. Новая
технология форматирования названа Advanced Format. Перед
использованием накопителя с технологией Advanced Format
для работы в Windows XP необходимо выполнить процедуру
выравнивания с помощью специальной утилиты. Если разделы
на диске создаются Windows Vista, Windows 7+ и Mac OS,
выравнивание не требуется. В Windows Vista, Windows 7,
Windows Server 2008 и Windows Server 2008 R2 поддержка дисков
с увеличенным размером сектора ограничена.
92.
Структура данных на дисковом накопителеВозможны 2 основных способа адресации секторов на диске:
цилиндр-головка-сектор (cylinder-head-sector, CHS) и линейная
(логическая) адресация блоков (linear block addressing, LBA).
CHS. Сектор адресуется по его физическому положению на
диске 3 координатами — номером цилиндра, номером
головки и номером сектора. В дисках объёмом больше
528 482 304 байт (504 Мб) со встроенными контроллерами эти
координаты уже не соответствуют физическому положению
сектора на диске и являются «логическими координатами».
LBA. Адрес блоков данных на носителе задаётся с помощью
логического линейного адреса. LBA-адресация начала
внедряться и использоваться в 1994 году совместно со
стандартом EIDE (Extended IDE). Необходимость LBA была
вызвана, в частности, появлением дисков больших объёмов,
которые нельзя было полностью использовать с помощью
старых схем адресации.
LBA = ((cylinder х N of heads + heads) x head/track) + sector – 1
Метод LBA соответствует Sector Mapping для SCSI. BIOS SCSIконтроллера выполняет эти задачи автоматически, то есть для
SCSI-интерфейса
метод
логической
адресации
был
характерен изначально.
93.
Структура данных на дисковом накопителеОригинальная спецификация АТА предусматривала 28-битный
режим адресации. Это позволяло адресовать 228 (268 435 456)
секторов по 512 байт каждый, что давало максимальную
ёмкость в 137 Гб (128 ГБ). В стандартных PC BIOS поддерживал
до 7,88 ГБ (8,46 Гб), допуская максимум 1024 цилиндра, 256
головок и 63 сектора. Это ограничение на число
цилиндров/головок/секторов CHS (Cyllinder-Head-Sector) в
сочетании со стандартом IDE привело к ограничению
адресуемого пространства в 504 МБ (528 Мб). Для
преодоления этого ограничения и была введена схема
адресации LBA, что позволило адресовать до 7,88 ГиБ. Со
временем и это ограничение было снято, что позволило
адресовать сначала 32 ГиБ, а затем и все 128 ГиБ, используя
все 28 разрядов (в АТА-4) для адресации сектора. Запись 28битного числа организована путём записи его частей в
соответствующие регистры накопителя (с 1 по 8 бит в 4-й
регистр, 9-16 в 5-й, 17-24 в 6-й и 25-28 в 7-й).
Адресация регистров организована при помощи трёх адресных
линий DA0-DA2. Первый регистр с адресом 0 является 16разрядным и используется для передачи данных между диском
и контроллером. Остальные регистры 8-битные и используются
для управления. Новейшие спецификации ATA предполагают
48-битную адресацию, расширяя таким образом возможный
предел до 128 ПиБ (144 петабайт).
94.
Кэш память на дисковом накопителеМетоды кэширования Write Through и Write Back применяются
и для кэширования информации, а жестких дисках. Данные
передаются блоками определенной длины, причем MS-DOS
использует при этом специальные буферы для файлов
(команда BUFFERS), центральный процессор работает с
диском не напрямую, а через эти буферы.
Кэш-память диска заполняется данными требуемого сектора
и секторами, непосредственно следующими за ним, так
как в большинстве случаев взаимосвязанные данные
хранятся в соседних секторах. Это метод Read Ahead "чтение вперед". Выполнение процесса оптимизации
жесткого диска оказывает влияние на эффективность его
кэширования,
поскольку
при
выполнении
полной
оптимизации различные части файлов могут находиться в
соседних секторах.
Если кэш-память полностью заполнена данными, алгоритм
кширования заменит именно ту информацию, к которой
производился минимум обращений. Если в кэше хранить
таблицу FAT и дерево каталогов, то поиск файлов может
происходить достаточно эффективно даже для винчестеров
большой емкости.
95.
Кэш память на дисковом накопителеАрхитектура
кэш-памяти
современных
винчестеров
использует полностью ассоциативное отображение, и кэш
может быть использован для работы с любым количеством
страниц. Такая организация кэша возможна, так как
оперативная
память
и
микропроцессор
работают
существенно быстрее, чем жесткий диск.
На плате кэш-контроллера для жестких дисков находятся
собственная кэш-память, выполненная обычно на 30контактных SIMM-модулях, и собственный процессор (i80286
или Motorola 68000). Размер установленной памяти может
достигать 16 Мбайт.
В процессе кэширования осуществляется непрерывное
считывание данных с поверхности диска до момента
заполнения буфера, а оно происходит и после того, как
найдены требуемые данные. Такая работа с опережением
создает избыточный запас данных, которые могут быть
востребованы позднее. Скорость считывания данных из кэшбуфера выше, чем с поверхности диска. При кэшировании
записи происходит обратная процедура: в буфере
накапливаются данные, предназначенные для размещения
на диске, что обеспечивает непрерывность процесса с
максимальной скоростью.
96.
Кэш память на дисковом накопителеПри работе с многозадачными системами выгодно иметь
винчестер с мультисегменгной кэш-памятью, которая для
каждой из задач отводит свою часть кэша (сегмент). В
адаптивной мультисегментной кэш-памяти для повышения
производительности число и параметры сегментов могут
изменяться.
Особое место в увеличении надежности жестких дисков
занимает технология SMART (self-monitoring, analysis and
reporting technology — технология самоконтроля, анализа и
отчётности). Ее смысл заключается в осуществлении
винчестером самодиагностики технического состояния с
выдачей пользователю соответствующей информации.
Технология S.M.A.R.T. является частью протокола ATA (ныне
распространенного в интерфейсе SATA). В общем случае
состояние
накопителя
оценивается
по
нескольким
параметрам, критичным для его нормальной эксплуатации,
которые называются атрибутами надежности. Каждому
атрибуту
соответствует
определенный
параметр,
способный характеризовать его естественный износ и
предаварийное состояние. Все SMART-параметры хранятся
в энергонезависимой памяти жесткого диска.
97.
Технология S.M.A.R.TСтандарт S.M.A.R.T. I предусматривал мониторинг основных
параметров и запускался только после команды.
В разработке S.M.A.R.T. II участвовала Hitachi, предложившая
методику полной самодиагностики накопителя (extended selftest), также появилась функция журналирования ошибок.
В S.M.A.R.T. III появилась функция обнаружения дефектов
поверхности и возможность их восстановления «прозрачно» для
пользователя.
Характеристики можно разбить на две группы:
параметры, отражающие процесс естественного старения
жёсткого
диска
(число
оборотов
шпинделя,
число
перемещений
головок,
количество
циклов
включениявыключения);
текущие
параметры
накопителя
(высота
головок
над
поверхностью диска, число переназначенных секторов, время
поиска дорожки и количество ошибок поиска).
Полный набор атрибутов содержит несколько десятков позиций.
Данные хранятся в шестнадцатеричном виде, называемом raw
value («сырые значения»), а затем пересчитываются в value —
значение надёжности относительно некоторого эталонного
значения. Обычно value располагается в диапазоне от 0 до 100.
Высокая оценка говорит об отсутствии изменений данного
параметра или медленном его ухудшении. Низкая — о
возможном скором сбое.
98.
Технология S.M.A.R.TЖёсткие диски с поддержкой SMART версии 2 и старше,
предлагают ряд различных тестов:
Короткий (Short) - проверяет электрические и механические
параметры, а также производительность на чтение. Тест, как
правило, длится около двух минут.
Длинный/расширенный (Long/extended) - проверяет всю
поверхность диска и не имеет ограничения по времени. В
среднем занимает около двух-трёх часов.
Тест транспортировки (Conveyance) - быстрый тест,
предназначенный для оценки состояния диска после
транспортировки диска от производителя к поставщику.
Выборочный (Selective) - некоторые диски позволяют
проверить определённую часть поверхности.
Журнал тестов SMART может содержать результаты только 21
последнего теста и доступен только для чтения. Иными
словами, сбросить его штатными средствами невозможно.
Журнал представляет собой таблицу из следующих
колонок: порядковый номер теста, тип теста, результат
теста, сколько процентов осталось до завершения, время
жизни диска, LBA.
99.
Интерфейс дискового накопителяПервоначально контроллер привода выполнялся в виде отдельной
платы расширения (стандарт ST-506 и интерфейсы SCSI и ST412). С ростом емкости дисков и интенсивности обмена по
аналоговой части канала контроллеры стали размещать в
корпусе диска (IDE\d, Integrated Drive Electronics —
«электроника, встроенная в привод»). Это позволило улучшить
характеристики накопителей (за счёт меньшего расстояния до
контроллера), упростить управление им (так как контроллер
канала IDE абстрагировался от деталей работы привода) и
удешевить производство (контроллер привода мог быть
рассчитан только на «свой» привод, а не на все возможные;
контроллер канала же вообще становился стандартным).
Контроллер канала IDE, размещённый на материнской плате
или на отдельной плате расширения, правильнее называть
хост-адаптером, поскольку он перешёл от прямого
управления приводом к обмену данными с ним по протоколу.
В стандарте АТА определён интерфейс между контроллером и
накопителем, а также передаваемые по нему команды.
Интерфейс имеет 8 регистров, занимающих 8 адресов в
пространстве ввода-вывода, и два регистра для управления.
Ширина шины данных составляет 16 бит.
100.
Интерфейс дискового накопителяВ IBM PC AT коммуникация с HDD выполняется через три группы
регистров в области ввода-вывода:
16-битный регистр данных ввода-вывода (1F0h);
семь "Task File"-регистров (1F1h...1F7h);
два регистра управления и состояния (3F6h...3F7h).
Регистры 1F0h...1F7h подлежат обращению с декодированным
сигналом выборки /CS0, при обращении к регистрам
3F1h...3F7h должен быть активен /СS1. Выборка отдельных
регистров выполняется адресными линиями А0...А2. Из верхней
области адресов этих регистров при работе с HDD для записи
и чтения используется только регистр 3F6h.
Адреса 3F2h...3F5h находятся в распоряжении контроллера
накопителей FDD. Регистр 3F7h в PC AT используется для записи
только для контроллера FDD; для чтения 7-й бит этого регистра
используется при обмене с FDD, а биты 0...6 информируют о
текущем состоянии HDD.
Регистр данных 1F0h. Ввод и вывод записываемых и читаемых
данных. Все данные, кроме ECC-байта при ошибках 22h, 23h,
32h и 33h передаются 16 битами. Данные имеют силу, если в
регистре состояния установлен DRQ-бит.
Биты ошибки 1F1h (чтение). Отдельные биты дают разъяснение о
виде произошедшей ошибки.
101.
Интерфейс дискового накопителяПрекомпенсация записи 1F1h (запись). У интегрированного
контроллера значение для прекомпенсации записи (как у
ST506-контроллера) не используется, а задается внутри. Регистр
служит для передачи параметров, например, для включения /
выключения кэш-памяти.
Счетчик секторов 1F2h. Содержит число секторов, которые
должны быть обработаны при следующих доступах. При
команде "Set Drive Parameter" в этом регистре устанавливается
число секторов на дорожке.
Hачальный сектор 1F3h. Hачальный сектор для следующего
доступа.
Цилиндр MSB 1F5h. Биты 0 и 1 являются битами 8 и 9 адреса
цилиндра. Чтение регистра состояния гасит IRQ14.
Регистр команд 1F7h (запись). Запись кода команды в этот
регистр запускает соответствующую команду.
2-й регистр состояния 3F6h (чтение). Как и регистр состояния
1F7h, но не изменяется состояние IRQ14.
Количество каналов в системе может быть больше 2. Главное,
чтобы адреса каналов не пересекались с адресами других
устройств ввода-вывода. К каждому каналу можно подключить 2
устройства (master и slave), но в каждый момент времени
может работать лишь одно устройство.
102.
Архитектура дисковых массивовУровни спецификации RAID:
RAID 1 — зеркальный дисковый массив;
RAID 2 — массивы, которые применяют код Хемминга;
RAID 3 и 4 — с чередованием и выделенным диском чётности;
RAID 5 — с чередованием и отсутствием выделенного диска
чётности.
В
современных
RAID-контроллерах
предоставлены
дополнительные уровни спецификации RAID:
RAID 0 — массив повышенной производительности с
чередованием, без отказоустойчивости. Строго говоря, RAIDмассивом не является, поскольку избыточность (redundancy) в
нём отсутствует;
RAID 6 — массив с чередованием, использующий две
контрольные суммы, вычисляемые двумя независимыми
способами;
RAID 10 — массив RAID 0, построенный из массивов RAID 1;
RAID 01 — массив RAID 1, построенный из массивов RAID 0;
RAID 50 — массив RAID 0, построенный из массивов RAID 5;
RAID 05 — массив RAID 5, построенный из массивов RAID 0;
RAID 60 — массив RAID 0, построенный из массивов RAID 6;
RAID 06 — массив RAID 6, построенный из массивов RAID 0.
103.
Архитектура дисковых массивовУровни спецификации RAID:
104.
Архитектура дисковых массивовMatrix RAID — технология Intel в южных мостах чипсетов, начиная с
ICH6R. Она не является новым уровнем RAID (и её аналог
существует в аппаратных RAID-контроллерах высокого уровня),
но позволяет, используя небольшое количество дисков,
организовать на разных разделах этих дисков одновременно
несколько массивов уровня RAID 1, RAID 0 и RAID 5. Это
позволяет за сравнительно небольшие деньги обеспечить для
одних данных повышенную надёжность, а для других — высокую
производительность. Сейчас это Intel Rapid Storage Technology
(Intel RST).
Для реализации RAID можно применять полностью программные
компоненты (драйверы). Например, в системах на ядре Linux
существуют специальные модули ядра, а управлять RAIDустройствами
можно
с
помощью
утилиты
mdadm.
Программный RAID имеет свои достоинства и недостатки. С
одной стороны, он ничего не стоит, с другой стороны,
программный
RAID
использует
ресурсы
центрального
процессора, и в моменты пиковой нагрузки на дисковую
систему процессор может значительную часть мощности
тратить на обслуживание RAID-устройств.
105.
Архитектура дисковых массивовЯдро Linux 2.6.28 поддерживает программные RAID следующих
уровней: 0, 1, 4, 5, 6, 10. Можно создавать RAID на отдельных
разделах дисков, как в Matrix RAID. Есть загрузка с RAID.
ОС семейства Windows поддерживают программный RAID 0, RAID
1 и RAID 5 (Dynamic Disk). Windows XP Pro поддерживает RAID 0.
Поддержка RAID 1 и RAID 5 заблокирована разработчиками,
Windows 7 поддерживает программный RAID 0 и RAID 1,
Windows Server 2003 — 0, 1 и 5. Windows XP Home не
поддерживает RAID.
В ОС FreeBSD, начиная с версии 5.0, дисковая подсистема
управляется встроенным в ядро механизмом GEOM: gstripe
(RAID 0), gmirror (RAID 1), graid3 (RAID 3), gconcat (объединение
нескольких дисков в единый раздел). Существуют и
устаревшие классы ccd (RAID 0, RAID 1) и gvinum (менеджер
логических томов vinum). Начиная с FreeBSD 7.2 используется
файловая система ZFS, где есть RAID: 0, 1, 5, 6, а также
комбинируемые.
OpenSolaris и Solaris 10 используют Solaris Volume Manager,
который поддерживает RAID-0, RAID-1, RAID-5 и любые их
комбинации как 1+0. Поддержка RAID-6 осуществляется в
файловой системе ZFS.
106.
DAS, SAN и NAS системыСервер к хранилищу данных можно подключить несколькими
способами.
Самый простой — DAS, Direct Attached Storage (прямое
подключение),
даёт
большой
объём
дискового
пространства со сравнительно быстрым доступом, и при
использовании RAID-массива — достаточную надежность.
Обычно делают или по RAID 1+0 на каждую дисковую полку с
FC дисками, оставляя 1 запасной диск (Hot Spare) и
нарезают из этого куска LUN-ы под задачи, или делают RAID5
из медленных дисков, опять же оставляя 1 диск на замену.
Устройство
DAS
может
разделяться
несколькими
компьютерами, если оно предоставляет несколько
интерфейсов (портов), позволяющих параллельный прямой
доступ. Такой способ используется в кластерах. В
реальности большинство устройств хранения SAN или NAS
могут использоваться как устройства DAS — для этого нужно
отсоединить их порты от сети данных и присоединить один
или более портов прямо к компьютеру («простым»
кабелем).
107.
DAS, SAN и NAS системыИспользование дискового пространства в DAS не оптимально
— на одном сервере место кончается, на другом его еще
много. Решение этой проблемы — NAS, Network Attached
Storage (хранилище, подключенное по сети). Однако при
всех преимуществах этого решения — гибкости и
централизованного управления — есть существенный
недостаток — скорость доступа, еще не во всех
организациях внедрена
сеть 10
гигабит. Поэтому
используются сети хранения данных.
Главное отличие SAN от NAS — то, каким образом видятся
подключаемые ресурсы на сервере. Если в NAS ресурсы
подключаются протоколам NFS или SMB, в SAN мы получаем
подключение к диску, с которым можем работать на уровне
операций блочного ввода-вывода, что гораздо быстрее
сетевого подключения (плюс контроллер массива с
большим кэшем добавляет скорости на многих операциях).
108.
DAS, SAN и NAS системыСеть хранения данных, или Storage Area Network — это система,
состоящая из собственно устройств хранения данных —
дисковых, или RAID — массивов, ленточных библиотек и
прочего, среды передачи данных и подключенных к ней
серверов. Это система, позволяющая раздавать серверам
надежные быстрые диски изменяемой емкости с разных
устройств хранения данных.
Используя SAN, мы сочетаем преимущества DAS — скорость и
простоту, и NAS — гибкость и управляемость. Плюс
возможность
масштабирования
систем
хранения
и
дополнительные преимущества:
* снимаются ограничения на дальность подключения устройств,
* уменьшается время резервного копирования,
* возможность загрузки с SAN,
* в случае отказа от NAS разгружается локальная сеть,
* большая скорость ввода-вывода за счет оптимизации на
стороне системы хранения,
* возможность подключать несколько серверов к одному ресурсу
и использовать сервисы VMWare — например VMotion
(миграцию виртуальной машины между физическими).
109.
DAS, SAN и NAS системыСистемы хранения данных обычно состоят из жестких дисков
и контроллеров, как правило с резервированием — по 2
контроллера, по 2 пути к каждому диску, по 2 интерфейса,
по 2 блока питания. Производители систе: HP, IBM, EMC и
Hitachi.
Среда передачи данных. Обычно SAN строят на оптике, это
дает скорость в 4, местами в 8 гигабит на канал. Используют
свитчи Qlogic, Brocade, McData и Cisco. Кабели
одномодовые и многомодовые.
Внутри используется FCP — Fibre Channel Protocol,
транспортный протокол, внутри него классический SCSI, а
FCP обеспечивает адресацию и доставку. Есть вариант с
подключением по обычной сети и iSCSI, но он сильно
нагружает локальную, а не выделенную под передачу
данных сеть, и требует адаптеров с поддержкой iSCSI.
Топологии: точка-точка (point to point); управляемая петля (FCAL), устройства замкнуты в кольцо; коммутируемая
структура (Fabric), она создается с помощью свитчей.
Основной принцип построения — все пути и связи
дублируются.
110.
DAS, SAN и NAS системыСерверы подключают к СХД через HBA - Host Bus Adapter. По
аналогии с сетевыми картами существуют одно-, двух-,
четырехпортовые адаптеры. Рекомендуют ставить по 2
адаптера на сервер, это позволяет как осуществлять
балансировку нагрузки, так и обеспечивает надежность.
Далее на системах хранения нарезаются ресурсы, (диски
LUN) для каждого сервера и оставляется место в запас.
Обычно при создании SAN заказывают массивы с
несколькими
типами
дисков:
FC
для
скоростных
приложений, и SATA или SAS для не очень быстрых. Таким
образом, получаются 2 дисковые группы с различной
стоимостью мегабайта — дорогая и быстрая, и медленная
и дешевая. На быструю устанавливают базы данных и
прочие приложения с активным и быстрым вводом-выводом,
на медленную — файловые ресурсы и все остальное.
111.
Архитектура SSD накопителейФлеш-память (flash memory) — разновидность полупроводниковой
технологии электрически перепрограммируемой памяти
(EEPROM). Благодаря компактности, дешевизне, механической
прочности, большому объёму, скорости работы и низкому
энергопотреблению, флеш-память широко используется в
цифровых портативных устройствах и носителях информации.
Недостаток - ограниченный срок эксплуатации носителей, а
также чувствительность к электростатическому разряду.
Предшественниками
можно
считать
ультрафиолетово
стираемые ПЗУ (EPROM) и электрически стираемые ПЗУ
(EEPROM). Эти приборы имели матрицу транзисторов с
плавающим затвором, в которых инжекция электронов в
плавающий затвор («запись») осуществлялась созданием
большой напряженности электрического поля в тонком
диэлектрике. Однако площадь разводки компонентов в
матрице резко увеличивалась, если требовалось создать поле
обратной напряжённости для снятия электронов с плавающего
затвора («стирания»). Возникло два класса устройств: в одном
случае жертвовали цепями стирания, получая память высокой
плотности с однократной записью, а в другом делали
полнофункциональное устройство с меньшей ёмкостью.
112.
Архитектура SSD накопителей113.
Архитектура SSD накопителейNOR- и NAND-приборы различаются методом соединения
ячеек в массив и алгоритмами чтения-записи. Конструкция
NOR использует классическую двумерную матрицу
проводников, в которой на пересечении строк и столбцов
установлено по одной ячейке. При этом проводник строк
подключался к стоку транзистора, а столбцов — ко второму
затвору. Исток подключался к общей для всех подложке. В
такой
конструкции
было
легко
считать
состояние
конкретного
транзистора,
подав
положительное
напряжение на один столбец и одну строку.
Конструкция NAND — трёхмерный массив. В основе та же
самая матрица, что и в NOR, но вместо одного транзистора
в каждом пересечении устанавливается столбец из
последовательно включенных ячеек. В такой конструкции
получается много затворных цепей в одном пересечении.
Плотность компоновки можно резко увеличить (ведь к одной
ячейке в столбце подходит только один проводник затвора),
однако алгоритм доступа к ячейкам для чтения и записи
заметно усложняется.
114.
Архитектура SSD накопителейСхемотехника NAND оказалась удобна для построения
вертикальной компоновки блока ячеек на кристалле. На
кристалл послойно напыляют проводящие и изолирующие
слои, которые образуют проводники затворов и сами
затворы. Затем в этих слоях формируют множество
отверстий на всю глубину слоев. На стенки отверстий
наносят структуру полевых транзисторов — изоляторы и
плавающие затворы. Таким образом формируют столбец
кольцеобразных полевых транзисторов с плавающими
затворами.
Такая вертикальная структура оказалась очень удачна и
обеспечила качественный рывок плотности флеш-памяти.
Некоторые компании продвигают технологию под своими
торговыми марками, например V-NAND, BiCS. Количество
слоёв по мере развития технологии наращивается: так, на
2016 год количество слоёв ряда изделий достигло 64, а в 2018
году освоено производство 96-слойной памяти.
Для экономии места в одну микросхему флеш-памяти может
упаковываться несколько полупроводниковых пластин
(кристаллов), до 16 штук.
115.
Архитектура SSD накопителейРазличают приборы, в которых элементарная ячейка хранит
один бит информации и несколько бит. В однобитовых
ячейках различают только два уровня заряда на плавающем
затворе. Такие ячейки называют одноуровневыми (singlelevel cell, SLC). В многобитовых ячейках различают больше
уровней заряда; их называют многоуровневыми (multi-level
cell, MLC). MLC-приборы дешевле и более ёмки, чем SLCприборы, однако имеют более высокое время доступа и
примерно на порядок меньшее максимальное количество
перезаписей.
Обычно под MLC понимают память с 4 уровнями заряда (2
бита) на каждую ячейку. Более дешевую в пересчете на
объём память с 8 уровнями (3 бита) чаще называют TLC
(Triple Level Cell) или 3bit MLC (MLC-3). Существуют
экспериментальные устройства с 16 уровнями на ячейку (4
бита), 16LC или QLC, однако с уменьшением техпроцесса
их массовое производство маловероятно из-за чрезвычайно
низкой надежности хранения. Часто в одну микросхему
флеш-памяти упаковывается несколько полупроводниковых
пластин (кристаллов), до 8—16 штук.
116.
Архитектура SSD накопителей117.
Изменение заряда сопряжено с накоплением необратимыхизменений в структуре и потому количество циклов записи
для ячейки флеш-памяти ограничено (обычно до 10 тыс. раз
для MLC-устройств и до 100 тыс. раз для SLC-устройств).
Одна из причин деградации — невозможность индивидуально
контролировать заряд плавающего затвора в каждой
ячейке. Запись и стирание производятся над множеством
ячеек одновременно. Автомат записи контролирует
достаточность инжекции заряда по референсной ячейке
или по средней величине. Постепенно характеристики
отдельных ячеек меняются и выходят за границы, которые
может скомпенсировать инжекцией автомат записи и
воспринять устройство чтения.
Другая причина — взаимная диффузия атомов изолирующих
и проводящих областей полупроводниковой структуры,
ускоренная градиентом электрического поля в области
кармана и периодическими электрическими пробоями
изолятора при записи и стирании. Это приводит к
размыванию границ и ухудшению качества изолятора,
уменьшению времени хранения заряда.
Идут исследования технологии восстановления ячейки флешпамяти путём локального нагрева изолятора затвора до
800°С в течение нескольких миллисекунд.
118.
Архитектура SSD накопителейИзоляция кармана, хранящего заряд, неидеальна, заряд
постепенно изменяется. Срок хранения заряда, заявляемый
большинством производителей для бытовых изделий, не
превышает 10—20 лет, хотя гарантия на носители дается не
более, чем на 5 лет. При этом память MLC имеет меньшие
сроки, чем SLC.
Специфические внешние условия, например, повышенные
температуры или радиационное облучение (гаммарадиация
и
частицы
высоких
энергий),
могут
катастрофически сократить срок хранения данных.
У современных микросхем NAND при чтении возможно
повреждение данных на соседних страницах в пределах
блока. Осуществление большого числа (сотни тысяч и
более) операций чтения без перезаписи может ускорить
возникновение ошибки.
По данным Dell, длительность хранения данных на SSD,
отключенных от питания, сильно зависит от количества
прошедших циклов перезаписи (P/E) и от типа флешпамяти и в худших случаях может составлять 3—6 месяцев.
119.
Архитектура SSD накопителейСтирание, запись и чтение флеш-памяти всегда происходит
относительно крупными блоками разного размера, при этом
размер блока стирания всегда больше, чем блок записи, а
размер блока записи не меньше, чем размер блока чтения.
Как следствие — все микросхемы флеш-памяти имеют ярко
выраженную иерархическую структуру. Память разбивается
на блоки, блоки состоят из секторов, секторы из страниц. В
зависимости от назначения конкретной микросхемы глубина
иерархии и размер элементов может меняться. Например,
NAND-микросхема может иметь размер стираемого блока в
сотни кбайт, размер страницы записи и чтения — 4 кбайт. Для
NOR-микросхем размер стираемого блока варьируется от
единиц до сотен кбайт, размер сектора записи — до сотен
байт, страницы чтения — единицы—десятки байт.
Скорость чтения и записи
Скорость стирания варьируется от единиц до сотен миллисекунд
в зависимости от размера стираемого блока. Скорость
записи — десятки-сотни микросекунд.
Обычно скорость чтения для NOR-микросхем нормируется в
десятки наносекунд. Для NAND-микросхем скорость чтения
составляет десятки микросекунд.
120.
Архитектура SSD накопителейСтремление достичь предельных значений ёмкости для NANDустройств привело к «стандартизации брака» — праву
выпускать и продавать микросхемы с некоторым
процентом бракованных ячеек и без гарантии непоявления
новых «bad-блоков» в процессе эксплуатации.
Чтобы минимизировать потери данных, каждая страница
памяти снабжается небольшим дополнительным блоком, в
котором записывается контрольная сумма, информация
для восстановления при одиночных битовых ошибках,
информация о сбойных элементах на этой странице и
количестве записей на эту страницу.
Сложность алгоритмов чтения и допустимость наличия
некоторого количества бракованных ячеек вынудило
разработчиков
оснастить
NAND-микросхемы
памяти
специфическим командным интерфейсом. Это означает,
что нужно сначала подать специальную команду переноса
указанной страницы памяти в специальный буфер внутри
микросхемы, дождаться окончания этой операции, считать
буфер,
проверить
целостность
данных
и,
при
необходимости, попытаться восстановить их.
121.
Архитектура SSD накопителейNAND-контроллеры
Для упрощения применения микросхем флеш-памяти NANDтипа они используются совместно со специальными
микросхемами — NAND-контроллерами. Эти контроллеры
должны выполнять всю черновую работу по обслуживанию
NAND-памяти: преобразование интерфейсов и протоколов,
виртуализация адресации (с целью обхода сбойных ячеек),
проверка и восстановление данных при чтении, забота о
разном размере блоков стирания и записи, забота о
периодическом обновлении записанных блоков (есть и такое
требование), равномерное распределение нагрузки на
секторы при записи (Wear leveling).
В самых дешевых изделиях могут устанавливаться наиболее
простые контроллеры без распределения нагрузки. Такие
флеш-карты памяти быстро выйдут из строя при частой
перезаписи, или при использовании файловой системы,
отличной от той, на которую рассчитан контроллер. При
необходимости очень частой записи данных на флешки
предпочтительно не изменять штатную файловую систему и
использовать дорогие изделия с более износостойкой памятью
(MLC вместо TLC, SLC вместо MLC) и качественными
контроллерами.
122.
Архитектура SSD накопителейНа дорогие NAND-контроллеры также может возлагаться задача
«ускорения» микросхем флеш-памяти путем распределения
данных одного файла по нескольким микросхемам, как в
ОЗУ. Время записи и чтения файла при этом сильно
уменьшается.
Специальные файловые системы
Зачастую во встраиваемых применениях флеш-память может
подключаться к устройству напрямую — без контроллера. В
этом
случае
задачи
контроллера
должен
выполнять
программный NAND-драйвер в операционной системе. Чтобы
не
выполнять
избыточную
работу
по
равномерному
распределению
записи
по
страницам,
стараются
эксплуатировать такие носители со специальными файловыми
системами: JFFS2 и YAFFS для Linux и др., реализующими
команды TRIM (to trim — подрезать) — команда интерфейса
ATA,
позволяющая
операционной
системе
уведомить
твердотельный накопитель о том, какие блоки данных уже не
содержатся в файловой системе и могут быть использованы
накопителем для физического удаления. TRIM входит в
спецификацию интерфейса ATA, стандартизацией которого
занимается группа T13 в составе INCITS
123.
Архитектура SSD накопителейПрименение NOR-флеш - устройства энергонезависимой
памяти относительно небольшого объёма, требующие
быстрого доступа по случайным адресам и с гарантией
отсутствия сбойных элементов:
Встраиваемая
память
программ
однокристальных
микроконтроллеров. Типовые объёмы — от 1 кбайта до 1
Мбайта.
- Стандартные микросхемы ПЗУ произвольного доступа для
работы вместе с микропроцессором.
- Специализированные микросхемы начальной загрузки
компьютеров (POST и BIOS), процессоров ЦОС и
программируемой логики. Типовые объёмы — единицы и
десятки мегабайт.
- Микросхемы хранения среднего размера данных,
например, DataFlash. Обычно снабжаются интерфейсом
SPI и упаковываются в миниатюрные корпуса. Типовые
объёмы — от сотен кбайт до технологического максимума.
Максимальное значение объёмов микросхем NOR — до 256
Мбайт.
124.
Архитектура SSD накопителейNAND флеш-память применяется в мобильных носителях данных
и устройствах, требующих больших объёмов хранения.
NAND
позволила
миниатюризировать
и
удешевить
вычислительные
платформы
на
базе
стандартных
операционных
систем
с
развитым
программным
обеспечением. Их стали встраивать во множество бытовых
приборов: сотовые телефоны и телевизоры, сетевые
маршрутизаторы и точки доступа, медиаплееры и игровые
приставки, фоторамки и навигаторы.
Высокая скорость чтения делает NAND-память привлекательной
для кэширования винчестеров. При этом часто используемые
данные операционная система хранит на относительно
небольшом твердотельном устройстве, а данные общего
назначения записывает на дисковый накопитель большого
объёма. Также возможно объединение флеш-буфера на 4—8
ГБ и магнитного диска в едином устройстве, гибридном
жёстком диске (SSHD, Solid-state hybrid drive).
Благодаря большой скорости, объёму и компактным размерам,
NAND-память активно вытесняет из обращения носители других
типов. Магнитные носители практически полностью вытеснены
из мобильных и медиаприменений.
125.
Архитектура SSD накопителейНебольшие твердотельные накопители могут встраиваться в один
корпус с магнитными жёсткими дисками, образуя гибридные
жёсткие диски (SSHD, Solid-state hybrid drive). Флеш-память в
них может использоваться либо в качестве буфера (кэша)
небольшого объёма (4—8 ГБ), либо, реже, быть доступной как
отдельный накопитель (Dual-drive hybrid systems). Подобное
объединение позволяет воспользоваться частью преимуществ
флеш-памяти (быстрый произвольный доступ) при сохранении
небольшой стоимости хранения больших объёмов данных.
Начиная с Windows 7 используется оптимизация работы с
твердотельными накопителями. При наличии SSD-накопителей
эта операционная система работает с ними иначе, чем с
обычными HDD-дисками. Windows 7 не применяет к SSDнакопителю дефрагментацию, технологии SuperFetch и
ReadyBoost
и
другие
техники
упреждающего
чтения,
ускоряющие загрузку приложений с обычных HDD-дисков.
Mac OS X начиная с версии 10.7 (Lion) и Linux начиная с версии
ядра 2.6.33 полностью осуществляют TRIM-поддержку для
установленной в системе твердотельной памяти.
126.
Архитектура ленточных накопителейЛенточные накопители - относительно медленные системы с
последовательным доступом. Это отдельно стоящие приводы
магнитных лент, библиотеки магнитных лент и достаточно редко
используемые
RAIT
системы.
Обладают
наибольшим
временем доступа, наибольшей емкостью и наименьшей
удельной стоимостью хранения данных. Используются также в
системах иерархического хранения данных.
Две основные технологии: линейная запись (запись с
неподвижной магнитной головкой) и наклонно-строчная запись.
Оба метода пришли из аналоговой магнитной записи.
В линейной технологии используется достаточно широкая лента с
большим числом расположенных по всей длине ленты
параллельных дорожек и многоканальная магнитная головка.
Лента протягивается лентопротяжным механизмом мимо
головки. При этом считывается часть (группа) дорожек. При
достижении окончания ленты головка перепозиционируется на
следующую группу дорожек, лентопротяжный механизм
реверсирует движение ленты, и так повторяется, пока не будут
считаны или записаны все дорожки. Такой метод записи
называют серпантиновым.
127.
Архитектура ленточных накопителей128.
Архитектура ленточных накопителейЧтобы обеспечить необходимую плотность записи лента
должна двигаться мимо магнитной головки со скоростью
порядка 160 дюймов/с (70 см/с). Чем быстрее достигается
рабочая скорость движения ленты, тем меньше задержек
при неизбежном старт-стопном движении ленты. Поэтому,
чем более быстродействующий лентопротяжный механизм,
тем больше механическая нагрузка на ленту и применение
современных тонких лент AME в этом случае недопустимо.
При движении ленты неизбежна некоторая девиация
положения магнитной дорожки по высоте. Причина в
неизбежном перемещении ленты в вертикальной плоскости
при движении из-за некоторого люфта направляющих стоек
или роликов и не абсолютная параллельность краев самой
ленты. Это не критично при невысоких плотностях цифровой
записи, но при увеличении количества дорожек (плотность
расположения) и использовании более прогрессивных
методов магнитной записи (RLL, PRML) для увеличения
количества дорожек на ленте требуется специальная
система слежения и коррекция положения головки.
129.
Архитектура ленточных накопителейТехнология DDS. Формат DDS (Digital Data Storage) был
разработан в 1989 году компаниями Hewlett-Packard и Sony на
базе формата DAT (Digital Audio Tape). Носитель четырёхмиллиметровая магнитная лента в пластиковом
корпусе 73 мм × 54 мм × 10,5 мм. Используется 16-битная
импульсно-кодовая модуляция (PCM) без сжатия, как у CD, а
частота дискретизации может быть как больше, чем у CD (44,1
кГц), так и меньше, а именно: 48, 44,1 или 32 кГц. Запись
производится без потери качества исходного сигнала, в отличие
от более поздних форматов DCC (Digital Compact Cassette) и
MD (MiniDisc). Накопители DDS используют технику записи,
основанную на перемещении носителя в горизонтальном
направлении и головок — в вертикальном.
Технология QIC. Поддерживалось аппаратное сжатие данных.
Накопители этих стандартов устанавливались в стандартный 5дюймовый отсек и подключались к интерфейсу контроллера
флоппи-дисков. Появилось большое количество сходных
стандартов под торговыми марками QIC и Travan,
определяющих носители ёмкостью до 10 Гбайт.
130.
Архитектура ленточных накопителейТехнология DLT использует ленту шириной 0,5 дюйма и
однокатушечный картридж (приемный барабан несъемный и
находится в самом устройстве). Лента закреплена одним
концом в подающем барабане в картридже, а на другом
конце находится специальная петля, лидер, за которую ЛПМ
(лентопротяжный механизм) вытаскивает ленту из картриджа и
заправляет в приемный барабан. Таким образом, весь объем
картриджа заполнен лентой, но сам привод магнитных лент
получается
несколько
больших
размеров.
Технология
используется в системах среднего и более высокого уровня.
Устройства SuperDLT принадлежат к новому поколению, где
используется другая, более совершенная лента, другие
магнитные гоовки (CMR, кластер магниторезистивных головок),
оптическая система позиционирования дорожек и др.
Технология Value DLT (DLT VS) является боковым ответвлением DLT,
разработчик — Quantum. Стандарт создавался с целью
составить конкуренцию DAT и захватить часть соответствующего
рынка, первые устройства DLT VS80 (3/6 Mb/s, 40/80 GB),
появились в начале 2000 года. Носитель — картридж DLT IV,
однако формат чтения/записи не совместим с DLT80 и SDLT.
131.
Архитектура ленточных накопителейПриводы SLR используют лету шириной 1/4 дюйма. Полностью
закрытый картридж с массивным металлическим основанием
имеет
двухкатушечную
конструкцию.
Оба
барабана
приводятся в движение специальным ремнем, размещенным
внутри картриджа. Картридж имеет лишь небольшое окошко
для контакта головки чтения/записи с лентой и ролик, который
сообщается с приводным ремнем внутри картриджа и с
тонвалом привода. ЛПМ имеет минимальное количество
движущихся частей (головка и тонвал).
Многоканальная головка подвешена при помощи магнитной
катушки. На ленте при изготовлении нанесены специальные
синхро-дорожки, которые всегда считываются при движении
ленты (как при чтении, так и при записи), а сервосистема на
основе считанного синхросигнала постоянно корректирует
положение магнитной головки по высоте. Кроме того, головка
чтения-записи имеет дополнительный рабочий зазор, который
позволяет
считывать
только
что
сделанную
запись.
Использование такой сервосистемы позволяет существенно
увеличить количество дорожек на ленте. Приводы SLR имеют
несколько меньшую стоимость, чем DLT.
132.
Архитектура ленточных накопителейОткрытый формат LTO (Linear Tape Open format) основан на
технологии серпантиновой записи на ленту шириной 0,5
дюйма. Два типа устройств:
1. Устройства Accelis, ориентированные на минимальное время
доступа
и
максимальную
скорость.
Для
получения
минимального времени доступа исходное положение ленты в
картридже - не начало, а середина ленты (спецификация не
используется).
2. Устройства Ultrium, ориентированные на максимальную
емкость. Конструкция картриджа и привода напоминает DLT.
Особенности технологии LTO:
Поддержка большого количества параллельных каналов на ленте
Высокая плотность записи информации на ленту
Улучшенный алгоритм сжатия информации - распознает сжатые
данные и отключает компрессию.
Динамическое перемещение данных из испорченных областей
на ленте, при поломке сервомеханизма или одной из головок
чтения-записи.
LTO-CM (LTO Cartridge Memory) - чип для хранения информации о
размещении данных на носителе. Использует бесконтактный
радио интерфейс для передачи данных
133.
Архитектура ленточных накопителейЗакрытый стандарт IBM 3592 (Jaguar). К линейке IBM 3592 относятся
модели стримеров 3592 (1 поколение), TS1120 (2 поколение),
TS1130 (3 поколение) и TS1140, а также ленточные библиотеки на
их основе. Картриджи имеют физическую ёмкость до 4 Тбайт.
Будучи ориентирован не только на архивацию и резервное
копирование, но и на произвольный доступ к данным, стандарт
IBM 3592 обеспечивает более жёсткие требования по
количеству перезаписей носителя, использован ряд решений
для оптимизации производительности в старт-стопном режиме
записи (глубокое кеширование данных и многоскоростное
движение ленты). Используется линейный метод записи.
Отличительной особенностью стандарта IBM 3592 является
заложенная в него возможность переформатирования
магнитных носителей старого поколения под формат более
новых
устройств
с
соответствующим
повышением
информационной ёмкости (в отличие от других современных
стандартов, обеспечивающих совместимость новых устройств
со старыми носителями только в старом формате).
134.
Архитектура ленточных накопителейТехнология наклонно-строчной записи AIT (Advanced Intelligent
Tape). Формат разработан Sony на базе технологии helicanscan, использует систему трекинга (ATF) для более плотной
записи дорожек. Особенности AIT:
Специальный механизм охлаждения накопителя.
MIC (Memory in cassette) Перезаписываемый чип на носителе для
хранения информации о содержимом ленты - увеличение
надежности, среднее время доступа к уменьшилось в 2 раза.
Active Head Cleaner - встроенный механизм для отчистки головок
накопителя, активизируемый устройством при появлении
большого количества ошибок при работе с лентой.
AME (Advanced Metal Evaporated). Ленты AME c вакуумным
напылением 100% кобальта, позволяют получить в 2-е большую
плотность записи, чем на обычной (MP) ленте. Сама лента при
этом значительно меньше подвергается износу, благодаря
покрытию из алмазоподобного углерода, а головка устройства
практически не засоряется, поскольку не соприкасается
непосредственно с магнитным слоем.
Алгоритм сжатия позволяющий добиться компрессии 2.6:1
135.
Архитектура ленточных накопителейФормат VXA объединил дискретный пакетный формат DPF
(Discrete Packet Format), работу на разных скоростях VSO
(Variable Speed Operation) и многократное сканирование OSO
(Over Scan Operation).
Перед записью данные разбиваются на пакеты по 64 байт
данных,
маркера
синхронизации,
информации
об
уникальном адресе, избыточного циклического кода CRC
(Cyclic Redundancy Check) и кода исправления ошибок ECC.
Поддержка переменной скорости (VSO) позволяет менять
скорость ленты в соответствии с изменением скорости
передачи данных. В отличие от обычного накопителя, VXAустройство просто останавливается, ожидает поступления
очередной порции данных и продолжает запись с места, где
ранее произошла остановка.
Многократное
сканирование
(OSO)
—
избавляет
от
необходимости четкого согласования направлений движения
ленты и записывающих головок. OSO позволяет неоднократно
считывать ленту с физическими повреждениями, такими, как
нарушение угла наклона дорожки или дефект носителя.
136.
Архитектура ленточных накопителейНа базе формата AIT в 2001 году специалисты Sony
разработали формат S-AIT (Super Advanced Intelligent
Tape). В отличие от AIT (3,5”), кассета и дисковод имеют
форм фактор 5,25”. В кассете используется один ролик, а
ширина ленты составляет 0.5 дюйма. AIT и S-AIT
изготавливаются по одинаковой технологии, однако емкость
кассеты S-AIT в 5 раз больше (500 Гб без сжатия) за счет
увеличения общей площади ленты. В S-AIT используются все
передовые технологии- AME, MIC, Helical Scan и др. S-AIT
предлагает также сверхвысокую для ленточных накопителей
скорость передачи данных- 30 Mб/сек.
Вторая версия SAIT-2; в ней емкость увеличена в два раза, до 1
Тбайт (2,6 Тбайт с компрессией) при скорости обмена 60
Мбайт/с (156 Мбайт/с с компрессией). В каждом из двух
следующих поколений SAIT-3 и SAIT-4 характеристики
последовательно удваиваются. Для SAIT-3 емкость составит 2
Тбайт (5,2 Тбайт с компрессией) при скорости обмена 120
Мбайт/с (312 Мбайт/с с компрессией), для SAIT-4 — 4 Тбайт
(10,4 Тбайт с компрессией).
137.
Архитектура ленточных накопителейКритерии выбора ленточного накопителя
Стоимость хранения (отношение стоимости носителя к его
емкости) – при больших объемах данных и длительном
использовании, определяет львиную долю стоимости
владения.
Среднее время доступа к файлам – может существенно
влиять на скорость восстановления данных. По этому
показателю устройства с наклонно-строчной записью
превосходят устройства с линейной записью, а лидером
является технология AIT(SAIT), благодаря наличию MIC памяти.
Скорость передачи данных. У систем с наклонно-строчной
записью за счет малой линейной скорости ленты стартстопный режим работы мало влияет на производительность,
а лучше всего в этом отношении приводы VXA, где не
тратится время даже на обратный откат ленты перед
возобновлением записи.
Среднее время безотказной работы (MTBF) и рабочий цикл
(Duty Cycle) вместе характеризуют надежность устройства,
и являются важными критериями при выборе устройства
резервного копирования.
138.
Архитектура ленточных накопителейНакопитель,
поддерживающий
работу
одновременно
с
несколькими лентами, называется ленточной библиотекой.
Роботизированные ленточные библиотеки могут содержать
хранилища с тысячами магнитных лент, из которых робот
автоматически достаёт требуемые ленты и устанавливает в
одно или несколько устройств чтения-записи. С программной
точки зрения такая библиотека выглядит, как один накопитель с
огромной ёмкостью и значительным временем произвольного
доступа. Кассеты в ленточной библиотеке идентифицируются
специальными
наклейками
со
штрих-кодом,
который
считывает робот. Коммерчески доступны модели ленточных
библиотек с ёмкостью до 70 петабайт при использовании 70
000 кассет.
ЛБ имеет преимущества перед дисковым массивом по
стоимости и энергопотреблению при больших объёмах
хранимых
данных.
Недостатком
ЛБ
является
время
произвольного доступа к данным, которое в нормальном
режиме функционирования может достигать нескольких
минут, и падение производительности на порядки при
увеличении количества одновременных запросов более числа
наличествующих устройств чтения-записи (когда кассеты
оказываются стоящими в очереди на чтение/запись).