




























 Информатика
ИнформатикаПохожие презентации:
")









Чтение по губам с помощью нейронных сетей
1. Чтение по губам
ЧТЕНИЕ ПО ГУБАМС ПОМОЩЬЮ НЕЙРОННЫХ СЕТЕЙ
2. Постановка проблемы
ПОСТАНОВКА ПРОБЛЕМЫЧтение по губам или визуальное распознавание речи – это задача
восстановления речи из движений губ.
Визуальное распознавание речи позволяет переводить видео поток в текст. В
отличии от аудио распознавания речи оно работает в зашумленных ситуациях.
Чтение по губам может является жизненно важной задачей для людей, чье
взаимодействие c обществом затруднено из-за невозможности говорить или
слышать, что может быть при различных медицинских состояниях.
3. Постановка проблемы
ПОСТАНОВКА ПРОБЛЕМЫВопреки распространенному заблуждению чтение по губам не является чем-то чем можно овладеть и
потом пользоваться без особых проблем.
Чтение по губам затруднено:
отсутствием контекста
схожестью многих звуков
различиями в артикуляции различных людей
скоростью речи, “проглатыванием “ звуков
наличием волос на лице или макияжа
и т. д.
Вплоть до того, что задача становится невыполнимой для людей.
4.
Впервые в работе 2009года были получены
результаты, согласно
которым компьютер
справлялся с задачей
чтения по губам
лучше, чем человек.
(высокие результаты в
обоих колонках частично
обусловлены
использованием
упрощенных специально
подготовленных данных)
Comparison of human and machine-based lip-reading
Sarah Hilder, Richard Harvey and Barry-John Theobald
School of Computing Sciences
University of East Anglia, UK
5.
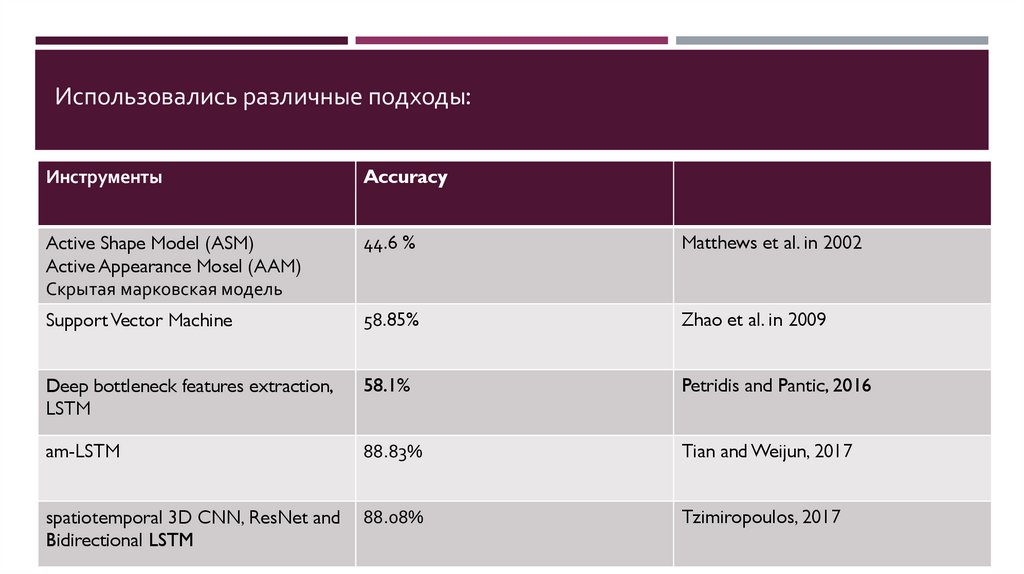
Использовались различные подходы:Инструменты
Accuracy
Active Shape Model (ASM)
Active Appearance Mosel (AAM)
Скрытая марковская модель
44.6 %
Matthews et al. in 2002
Support Vector Machine
58.85%
Zhao et al. in 2009
Deep bottleneck features extraction,
LSTM
58.1%
Petridis and Pantic, 2016
am-LSTM
88.83%
Tian and Weijun, 2017
spatiotemporal 3D CNN, ResNet and
Bidirectional LSTM
88.08%
Tzimiropoulos, 2017
6. Сверточные сети Хана
СВЕРТОЧНЫЕ СЕТИ ХАНА7.
Во всех предыдущих моделях перед проведением классификациипроводилось извлечение признаков, что отрицательно сказывалось
на количестве расчетов и времени их проведения.
Для борьбы с этими недостатками была предложена Hahn
Convolutional Neural Networks модель, состоящая из:
Моменты Хана (Hanh moments)
Свёрточные нейронные сети (CNN)
8. 1 слой архитектуры - Hanh moments
1 СЛОЙ АРХИТЕКТУРЫ - HANH MOMENTSИнструмент, позволяющий эффективно выделять наиболее важную
часть изображений с минимумом избыточных данных
Используется на первом слое архитектуры для того, чтобы
извлекать моменты (moments) и скармливать их CNN
Главная цель: уменьшить размерность изображений перед началом
работы с ними
9. Восстановление изображения с помощью моментов хана разных порядков
ВОССТАНОВЛЕНИЕ ИЗОБРАЖЕНИЯ С ПОМОЩЬЮ МОМЕНТОВ ХАНА РАЗНЫХПОРЯДКОВ
Возвращает матрицу моментов размер которой зависит от порядка
10. 2 слой архитектуры – Свёрточная нейронная сеть
2 СЛОЙ АРХИТЕКТУРЫ – СВЁРТОЧНАЯ НЕЙРОННАЯ СЕТЬПринимает на вход матрицу моментов вместо изображения и
применяет операции уже к ней
Слои свертки, активации, нормализации, пулинга обрабатывают
поданные данные и обучаются более сложным паттернам и
признакам
Классификация проводится на последнем полносвязном слое
11.
12. Эксперименты и результаты
ЭКСПЕРИМЕНТЫ И РЕЗУЛЬТАТЫ13. Датасеты
ДАТАСЕТЫ• AVLetters
OuluVS2
BBC LRW
• 780 видео
• 10 человек
• каждый человек выговаривает
26 букв анг. алфавита по 3 раза
• 52 человека
• Последовательности цифр
• Движения рта зафиксировано с
разных углов
• 500 слов
• На каждое 1000 произношений
разными людьми
• 520 изображений для обучения
• 5850 изображений для
обучения
• Разделение по умолчанию
• 260 для теста
• 1800 для теста
• 5000 эпох
• 1000 эпох
• 105 эпох
14.
o Количество данныхувеличивалось
посредством поворота
изображений на
небольшие углы (до 15
градусов) и отражением
изображений по
горизонтали (DA)
o Для каждого датасета по
разному подбиралось
количество кадров на
фрагмент
o Каждый фрагмент
объединялся в одно
изображение на котором
сохранялся
хронологический порядок
15.
Первый сверточный слой – ядро 3x3, 100 фильтровВторой сверточный слой – ядро 3x3, 60 фильтров
Первый пулинг (3х3)
Третий сверточный слой – ядро 3x3, 40 фильтров
Второй пулинг (3х3)
Первый полносвязный слой (300 нейронов)
Второй полносвязный слой (240 нейронов)
Выходной слой (26 классов)
16. Результаты Тестирования
РЕЗУЛЬТАТЫ ТЕСТИРОВАНИЯAVLetters
OuluVS2
17. Результаты Тестирования
РЕЗУЛЬТАТЫ ТЕСТИРОВАНИЯBBC LRW
18. Итоги
ИТОГИПри использовании Сверточных Нейронных Сетей Хана:
Сложность задачи значительно уменьшается.
Результаты классификации: 59,23% на AVLetters, 93,72% на OuluVS2,
58% на BBC LRW.
19. residual networks и LSTM
RESIDUAL NETWORKS ИLSTM
20.
Следующая модель состоит из трех сетей:- внешней, осуществляющей пространственно-временную свертку
- ResNet применяющейся к каждому шагу по времени
- Bi-LSTM (Bidirectional Long Short-Term Memory)
21. База Данных
БАЗА ДАННЫХТренировка и оценка
алгоритма осуществляется
на базе данных LRW
500 целевых слов
Целевые слова
произносятся не отдельно, а
являются частями
высказываний
Напр:
Не ”think”,
А “...point, I think the...”
Сеть должна еще и научится
выделять целевые слова
22. Подготовка данных
ПОДГОТОВКА ДАННЫХПрежде всего с помощью специальных алгоритмов происходит подготовка
данных:
на лица говорящих помещаются лицевые ориентиры
изображения обрезаются до важной части (области рта)
приводятся к одному размеру
переводятся в оттенки серого
нормализуются
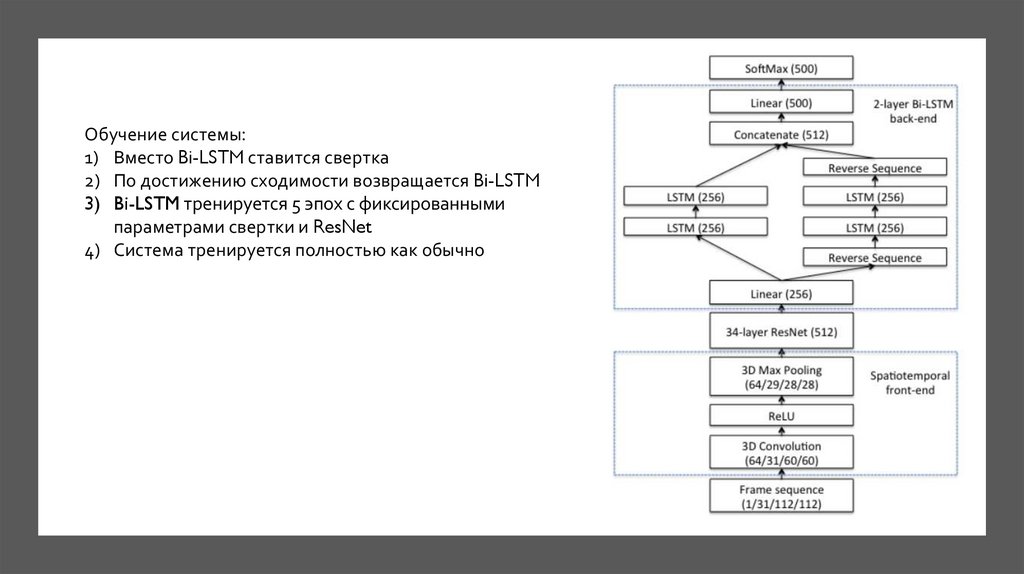
23. I Spatiotemporal front-end
I SPATIOTEMPORAL FRONT-ENDПространственно-временные сверточные слои фиксируют кратковременную
динамику области рта.
Состоят из:
- Сверточный слой с 64 ядрами 5 x 7 x 7 (время, ширина, высота)
- Пакетной нормализации (batch-normalization)
- ReLU
24. II RESNET
…Полученные карты признаков проходят через
готовый 34-слойный ResNet, изначально
разработанный для ImageNet.
ResNet уменьшает пространственную размерность
данных до одномерного тензора на временной шаг.
25. III Bi-LSTM
III BI-LSTMLSTM является рекурсивной сетью, то есть
содержит обратные связи. Ее основным
преимуществом перед большинством других
рекурсивных сетей является устойчивость к
проблеме затухающих градиентов. Bi-LSTM это ее
двухнаправленный вариант.
26.
Обучение системы:1) Вместо Bi-LSTM ставится свертка
2) По достижению сходимости возвращается Bi-LSTM
3) Bi-LSTM тренируется 5 эпох с фиксированными
параметрами свертки и ResNet
4) Система тренируется полностью как обычно
27. Итог
ИТОГN1 – 2D свертка, ResNet, свертка вместе LSTM
N2 – 3D свертка, ResNet, свертка вместе LSTM
N3 – 3D свертка, Deep Neural Network, свертка
вместе LSTM
N4 – 3D свертка, ResNet, однослойный Bi-LSTM
(без обучения)
N5 – 3D свертка, ResNet, двухслойный Bi-LSTM
(без обучения)
28. Результаты
РЕЗУЛЬТАТЫПомимо работы с
словами из базы данных
вариации данной
архитектуры также
неплохо справляются с
распознаванием и
незнакомых слов.
29. Итог
ИТОГВ заключение можно сказать, что системы визуального распознавание речи уже
давно превосходят человека и на данный момент могут показывать очень
высокие результаты и при этом продолжают совершенствоваться.
Их использование, особенно вкупе с аудио-распознаванием речи способно
облегчить жизни как и обычных людей, так и повысить доступность окружающей
среды для людей чье взаимодействие с обществом затруднено.
30. Источники
ИСТОЧНИКИLip Reading with Hahn Convolutional Neural Networks
T. Stafylakis, G. Tzimiropoulos, Deep word embeddings for visual speech recognition 2017, In CoRR,
abs/1710.11201.
T. Stafylakis and G. Tzimiropoulos, “Combining Residual Networks with LSTMs for Lipreading,” in Inter-speech,
2017.
31. Спасибо за внимание
СПАСИБО ЗАВНИМАНИЕ