













































 Программирование
Программирование Базы данных
Базы данныхПохожие презентации:



")

 Access")

")


Прикладное программирование. Часть 2. Приложения для работы с локальными базами данных
1. Прикладное программирование
Часть 2Доцент Литвинов В.Л
2. Приложения для работы с локальными базами данных
Всегда, когда возникает потребность манипулироватьбольшими массивами данных, используются базы данных.
База данных — (мы будем говорить о так называемых
реляционных базах данных) это прежде всего набор
таблиц, хотя, как мы увидим позднее, в базу данных могут
входить также процедуры и ряд других объектов. Таблицу
можно представлять себе как обычную двумерную
таблицу с характеристиками (атрибутами) какого-то
множества объектов. Таблица имеет имя —
идентификатор, по которому на нее можно сослаться. В
табл. 1 приведен пример фрагмента подобной таблицы с
именем Pers, содержащей сведения о сотрудниках
некоторой организации. Эта таблица будет в дальнейшем
использоваться в примерах по работе с базами данных.
3. Таблица 1. Пример таблицы данных о сотрудниках Pers
НомерОтдел
Фамилия
Имя
Отчество
Год
рождения
Пол
Характер
истика
Фотогр
афия
Num
Dep
Fam
Nam
Par
Yearjb
Sex
Charact
Photo
1
Бухгалте
рия
Иванов
Иван
Иванович
1950
м
...
...
2
Цех 1
Петров
Петр
Петрович
1960
м
...
...
3
Цех 2
Сидоров
Сидор
Сидоро-вич
1955
м
...
...
4
Цех 1
Иванова
Ирина
Ивановна
1961
ж
...
...
...
4.
Столбцы таблицы соответствуют тем или иным характеристикамобъектов — полям. Каждое поле характеризуется именем и
типом хранящихся данных. Имя поля — это идентификатор,
который используется в различных программах для
манипуляции данными. Он строится по тем же правилам, как
любой идентификатор, т.е. пишется латинскими буквами,
состоит из одного слова и т.д.
Таким образом, имя — это не то, что отображается на экране
или в отчете в заголовке столбца (это отображение естественно
писать по-русски), а идентификатор, соответствующий этому
заголовку.
Например, для таблицы 1 введем для последующих ссылок
имена полей Num, Dep, Fam, Nam, Par, Year_b, Sex,
Charact, Photo, соответствующие указанным в ней заголовкам
полей.
Тип поля характеризует тип хранящихся в поле данных. Это
могут быть строки, числа, булевы значения, большие тексты
(например, характеристики сотрудников), изображения
(фотографии сотрудников) и т.п.
5.
Каждая строка таблицы соответствует одному изобъектов. Она называется записью и содержит
значения всех полей, характеризующие данный
объект.
При построении таблиц баз данных важно
обеспечивать непротиворечивость информации.
Обычно это делается введением ключевых полей —
обеспечивающих уникальность каждой записи.
Ключевым может быть одно или несколько полей. В
приведенном выше примере можно было бы сделать
ключевыми совокупность полей Fam, Nam и Par. Но
в этом случае нельзя было бы заносить в таблицу
сведения о полных однофамильцах, у которых
совпадают фамилия, имя и отчество. Поэтому в
таблицу введено первое поле Num — номер, которое
можно сделать ключевым, обеспечивающим
уникальность каждой записи.
6.
При работе с таблицей пользователь или программакак бы скользит курсором по записям. В каждый
момент времени есть некоторая текущая запись, с
которой и ведется работа. Записи в таблице базы
данных физически могут располагаться без какоголибо порядка, просто в последовательности их ввода
(появления новых сотрудников). Но когда данные
таблицы предъявляются пользователю, они должны
быть упорядочены. Пользователь может хотеть
просматривать их в алфавитном порядке, или
рассортированными по отделам, или по мере
нарастания года рождения и т.п. Для
упорядочивания данных используется понятие
индекса. Индекс показывает, в какой
последовательности желательно просматривать
таблицу. Он является как бы посредником между
пользователем и таблицей (см. рис. 1).
7.
Курсор скользит по индексу, а индекс указывает нату или иную запись таблицы. Для пользователя
таблица выглядит упорядоченной, причем он может
сменить индекс и последовательность
просматриваемых записей изменится. Но в
действительности это не связано с какой-то
перестройкой самой таблицы и с физическим
перемещением в ней записей. Меняется только
индекс, т.е. последовательность ссылок на записи.
Индексы могут быть первичными и вторичными.
Например, первичным индексом могут служить поля,
отмеченные при создании базы данных как
ключевые. А вторичные индексы могут создаваться
из других полей как в процессе создания самой базы
данных, так и позднее в процессе работы с ней.
Вторичным индексам присваиваются имена —
идентификаторы, по которым их можно
использовать.
8. Рис. 1. Схема перемещения курсора по индексу
9.
Если индекс включает в себя несколькополей, то упорядочивание базы данных
сначала осуществляется по первому полю, а
для записей, имеющих одинаковое значение
первого поля - по второму и т.д.
База данных обычно содержит не одну, а
множество таблиц. Например, база данных о
некоторой организации может содержать
таблицу имеющихся в ней подразделений с
характеристикой каждого из них. Пример
такой таблицы с именем Dep, которая будет
использоваться нами в дальнейшем, приведен
в таблице 2. Имена полей этой таблицы,
которые в дальнейшем мы будем
использовать: Dep и Proisv.
10. Таблица 2. Пример таблицы данных о подразделениях Dep
ОтделТип
Dep
Proisv
Бухгалтерия
управление
Цех 1
производство
Цех 2
производство
11.
Отдельные таблицы, конечно, полезны, но гораздобольше информации можно извлечь именно из
совокупности таблиц. Например, пользователю
может требоваться узнать общее количество
сотрудников, работающих в производственных цехах.
Но ни одна из приведенных выше таблиц не поможет
ответить на этот вопрос, поскольку в таблице Pers
отсутствуют сведения о типах отделов, а в таблице
Dep — о сотрудниках. Для получения ответов на
подобные запросы необходимо рассмотрение
совокупности связных таблиц.
В связных таблицах обычно одна выступает как
главная, а другая или несколько других — как
вспомогательные, управляемые главной. В этом
случае взаимодействие таблиц иллюстрируется
рисунком 2.
12. Рис. 2. Схема взаимодействия главной и вспомогательной таблицы
13.
Главная и вспомогательная таблицы связываютсядруг с другом ключом. В качестве ключа могут
выступать какое-то поля, присутствующие в обеих
таблицах. Например, в приведенных ранее таблицах
головной может быть таблица Dep, вспомогательной
Pers, а связываться они могут по полю Dep,
присутствующему в обеих таблицах. Курсор скользит
по индексу главной таблицы. Каждой записи в
главной таблице ключ ставит в соответствие в общем
случае множество записей вспомогательной таблицы.
Так в нашем примере каждой записи главной
таблицы Dep соответствуют те записи
вспомогательной таблицы Pers, в которых ключевое
поле Dep с названием отдела совпадает с названием
отдела в текущей записи главной таблицы. Иначе
говоря, если в текущей записи главной таблицы в
поле Dep написано «Бухгалтерия», то во
вспомогательной таблице Pers выделяются все
записи сотрудников бухгалтерии.
14.
Поскольку конкретные свойства баз данных оченьразнообразны, пользователю было бы весьма затруднительно
работать, если бы он должен был указывать в своем
приложении все эти каталоги, файлы, серверы и т.п. Да и
приложение часто пришлось бы переделывать при смене,
например, структуры каталогов и при переходе с одного
компьютера на другой.
Чтобы решить эту проблему, используют псевдонимы баз
данных. Псевдоним (alias) содержит всю информацию,
необходимую для обеспечения доступа к базе данных. Эта
информация сообщается только один раз при создании
псевдонима. А приложение для связи с базой данных
использует псевдоним. В этом случае приложению безразлично,
где физически расположена та или иная база данных, а часто
безразлична и СУБД, создавшая и обслуживающая эту базу
данных.
При смене системы каталогов, сервера и т.п. ничего в
приложении переделывать не надо. Достаточно, чтобы
администратор базы данных ввел соответствующую
информацию в псевдоним.
15.
При работе с базами данных часто используется кэшированиевсех изменений, что означает, что все изменения данных,
вставка новых записей, удаление существующих записей, т.е.
все манипуляции с данными, проводимые пользователем,
сначала делаются не в самой базе данных, а запоминаются в
памяти во временной, виртуальной таблице. И только по особой
команде после всех проверок правильности вносимых в таблицу
данных пользователю предоставляется возможность или
фиксировать все эти изменения в базе данных, или отказаться
от этого и вернуться к тому состоянию, которое было до начала
редактирования.
Фиксация изменений в базе данных осуществляется с помощью
транзакций. Это совокупность команд, изменяющих базу
данных. На протяжении транзакции пользователь может что-то
изменять в данных, но это только видимость. В
действительности все изменения сохраняются в памяти. И
пользователю предоставляется возможность завершить
транзакцию или внесением всех изменения в реальную базу
данных, или отказом от этого с возвратом к тому состоянию,
которое было до начала транзакции.
16. Типы баз данных
Для разных задач целесообразно использоватьразличные модели баз данных, поскольку, конечно,
базу данных сведений о сотрудниках какого-то
небольшого коллектива и базу данных о какомнибудь банке, имеющем филиалы во всех концax
страны, надо строить по-разному.
Процесс определения того, какая база данных более
подходит для конкретного приложения, называется
масштабированием. Это сложная задача, которую мы
нe будем затрагивать. Однако, прежде, чем
двигаться дальше, необходимо иметь представление
о возможных моделях баз данных, поскольку это
влияет на построение приложений в C++Builder.
17.
В следующих разделах коротко рассмотренычетыре модели баз данных:
Автономные
Файл-серверные
Клиент/сервер
Многоярусные
Прежде, чем переходить к рассмотрению
различных моделей баз данных, отметим, что
работа с данными в C++Builder в основном
осуществляется через Borland Database
Engine (BDE) — процессор баз данных фирмы
Borland. Соответствующая программа должна
быть поставлена на компьютере
пользователя во всех моделях баз данных,
кроме многоярусных.
18. Автономные базы данных
Автономные локальные базы данных являются наиболее простыми.Они хранят свои данные в локальной файловой системе на том
компьютере, на котором установлены; система управления и машина
базы данных, осуществляющая к ним доступ, находится на том же
самом компьютере. Сеть не используется. Поэтому разработчику
автономной базы данных не приходится иметь дело с проблемой
параллельного доступа, когда два человека пытаются одновременно
изменить одну и ту же запись, потому что такого никогда не может
быть. Вообще, автономные базы данных не используются для
приложений, требующих значительной вычислительной мощности,
потому что процессорное время будет потрачено на выполнение
манипуляций с данными и в целом будет потеряно для приложения.
Автономные базы данных полезны для развития тех приложений,
которые распространены среди многих пользователей, каждый из
которых поддерживает отдельную базу данных. Это, например,
приложения, обрабатывающие документацию небольшого офиса,
кадровый состав небольшого предприятия, бухгалтерские документы
небольшой бухгалтерии. Каждый пользователь такого приложения
манипулирует своими собственными данными на своем компьютере.
Пользователю нет необходимости иметь доступ к данным любого
другого пользователя, так что отдельная база данных здесь вполне
приемлема.
19. Файл-серверные базы данных
Файл-серверные базы данных отличаются от автономных тем,что они могут быть доступны многим клиентам через сеть. Это
очень удобно, так как изменения в таких базах данных видят
все пользователи. Например, базу данных сотрудников крупного
учреждения целесообразно делать именно такой, чтобы
администраторы отдельных подразделений обращались к ней, а
не заводили у себя локальные базы данных (при этом можно
сделать так, чтобы каждый администратор видел только ту
информацию, которая относится к его подразделению).
Сама база данных хранится на сетевом файл-сервере в
единственном экземпляре. Для каждого клиента во время
работы создается локальная копия данных, с которой он
манипулирует. При этом возникают (и решаются) проблемы,
связанные с возможным одновременным доступом нескольких
пользователей к одной и той же информации. Например, при
проектировании приложений, работающих с подобными базами
данных, должны быть решены такие проблемы: что делать,
если пользователь прочел некоторую запись и, пока он ее
просматривает и собирается изменить, другой пользователь
меняет или удаляет эту запись.
20.
Одним из недостатков баз данных файл-серверявляется непроизводительная загрузка сети. При
каждом запросе клиента данные в его локальной
копии полностью обновляются из базы данных на
сервере. Даже если запрос относится всего к одной
записи, обновляются все записи данных. Если
записей в базе данных много, то даже при
небольшом числе клиентов сеть будет загружена
очень основательно, что серьезно скажется на
скорости выполнения запросов.
Другой недостаток связан с тем, что забота о
целостности данных при такой организации работы
возлагается на программы клиентов. Если они
недостаточно тщательно продуманы, в базу данных
легко занести ошибки, которые могут отразиться на
всех пользователях.
21. Базы данных клиент/сервер
Для больших баз данных с множеством пользователей частоиспользуются базы данных на платформе клиент/сервер. В этом
случае доступ к базе данных для клиентов выполняется
специальным компьютером — сервером. Клиент дает задание
серверу выполнить те или иные операции поиска или
обновления базы данных. И мощный сервер, ориентированный
на операции с запросами самым оптимальным способом,
выполняет их и сообщает клиенту результаты своей работы.
Подобная организация работы повышает эффективность
выполнения приложений за счет использования мощности
сервера, разгружает сеть, обеспечивает хороший контроль
целостности данных.
В базах данных клиент/сервер возникает дополнительная
проблема — спроектировать приложение так, чтобы оно
максимально использовало возможности сервера и минимально
нагружало сеть, передавая через нее только минимум инфорции.
22. Многоярусные базы данных
Это новый путь обработки данных в сети. Наиболее распространентрехярусный вариант:
На нижнем уровне на компьютерах пользователя расположены приложения
клиентов, обеспечивающие пользовательский интерфейс.
На втором уровне расположен сервер приложений, обеспечивающий обмен
данными между пользователями и распределенными базами данных.
Сервер
приложений размещается в узле сети, доступном всем клиентам.
На третьем уровне расположен удаленный сервер баз данных,
принимающий
информацию от серверов приложений и управляющий ими.
Подобную концепцию обработки данных пропагандируют, в частности,
фирмы Oracle и Sun.
Первый, элементарный уровень состоит из «тонких клиентов», то есть
несложных терминалов, предназначенных, в основном, для ввода —
вывода.
Второй, средний (middleware) уровень — это рабочие станции и серверы
приложений, то есть значительно более серьезные машины, на которых
выполняются программы, критичные к загрузке процессора.
Третий и последний уровень — мощные специализированные серверы баз
данных.
Отметим одну особенность многоярусных распределенных баз данных: в
них на нижнем уровне — на компьютерах пользователя не требуется
установка Borland Database Engine (BDE). В этом заключается одно из
преимуществ такой организации баз данных.
23. Организация связи с базами данных в C++Builder
Основой работы C++Builder с базами данныхявляется Borland Database Engine (BDE) — процессор
баз данных фирмы Borland. BDE служит посредником
между приложением и базами данных. Он
предоставляет пользователю единый интерфейс для
работы, развязывающий пользователя от конкретной
реализации базы данных. Благодаря этому не надо
менять приложение при смене реализации базы
данных. Приложение C++Builder никогда не
обращается непосредственно к данных, а только к
BDE.
24.
Приложение C++Builder, когда ему нужно связаться сбазой данных, обращается к BDE и сообщает обычно
псевдоним базы данных и необходимую таблицу в
ней. Этот механизм реализован в виде динамически
присоединяемых библиотек DLL. Они, как и любые
библиотеки, снабжены API (Application Program
Interface — интерфейсом прикладных программ),
названным IDAPI Integrated Database Application
Program Interface). Это список процедур и функций
работы с базами данных, которым и пользуются
приложения.
ВDЕ по псевдониму находит подходящий для
указанной базы данных драйвер. Драйвер — это
вспомогательная программа, которая понимает, как
общаться с базами данных определенного типа. Если
в BDE имеется собственный драйвер
соответствующей СУБД, то BDE связывается через
него с базой данных и с нужной таблицей в ней,
обрабатывает запрос пользователя и возвращает в
приложение результаты обработки. BDE
поддерживает естественный доступ к таким базам
данных, как Microsoft Access, FoxPro, Paradox, dBase.
25.
Если собственного драйвера нужной СУБД в BDE нет,то используется драйвер ODBC. ODBC (Open Database
Connectivity) — это DLL, аналогичная по функциям
BDE, но разработанная фирмой Microsoft. Она
хранится в файле ODBC.DLL. Поскольку Microsoft
включила поддержку ODBC в свои офисные продукты
и для ODBC созданы Драйверы практически к любым
СУБД, фирма Borland включила в BDE драйвер,
позволяющий использовать ODBC. Правда, работа
через ODBC осуществляется несколько медленнее,
чем через собственные драйверы СУБД, включенные
в BDE. Но благодаря связи с ODBC масштабируемость
C++Builder существенно увеличилась и сейчас из
C++Builder можно работать с любой сколько-нибудь
значительной СУБД.
26.
BDE поддерживает SQL — стандартизованный языкзапросов, позволяющий обмениваться данными с
SQL-серверами, такими, как Sybase, Microsoft SQL,
Oracle, Interbase. Эта возможность используется
особенно широко при работе на платформе
клиент/сервер и в распределенных базах данных.
В C++Builder 5 введена другая альтернативная
возможность работы с базами данных, минуя BDE.
Это разработанная в Microsoft технология ActiveX
Data Objects (ADO). ADO - это пользовательский
интерфейс к любым типам данных, включая
реляционные и не реляционные базы данных,
электронную почту, системные, текстовые и
графические файлы. Связь с данными
осуществляется посредством так называемой
технологии OLE DB.
27.
Использование ADO обеспечивает болееэффективную работу с данными. Однако, надо
сказать, что возможности ADO в C++Builder пока в
некоторых отношениях ниже, чем возможности BDE.
Поэтому в дальнейшем мы в основном
сосредоточимся на работе с BDE.
Еще один альтернативный доступ к базам данных
Interbase введен в C++Builder 5 на основе
технологии InterBase Express (IBX). В библиотеке
компонентов C++Builder 5 имеется страница
InterBase, содержащая компоненты для работы с
InterBase, минуя BDE. Эти компоненты обеспечивают
повышенную производительность и позволяют
использовать новые возможности сервера InterBase,
недоступные обычным компонентам BDE.
28. Создание баз данных с помощью Database Desktop
Прежде, чем начать строить приложения,работающие с базами данных, надо иметь сами базы
данных. C++Builder поставляется с примерами,
имеющими немало баз данных, которыми можно
воспользоваться для обучения. Но можно и самим
создать необходимые базы данных. Причем не
обязательно для этого использовать стандартные
СУБД. Вместе с BDE и C++Builder поставляется
программа Database Desktop (файл DBD.EXE для 16разрядных приложений, файл DBD32.EXE для 32разрядных приложений, файл DBDLOCAL.EXE — файл
конфигурирования), которая позволяет создавать
таблицы
29.
Для каждого поля создаваемой таблицыпрежде всего указывается имя FieldName) — идентификатор поля. Он
может включать до 25 символов и не
может начинаться с пробела (но внутри
пробелы допускаются). Затем надо
выбрать тип данных для этого поля.
30.
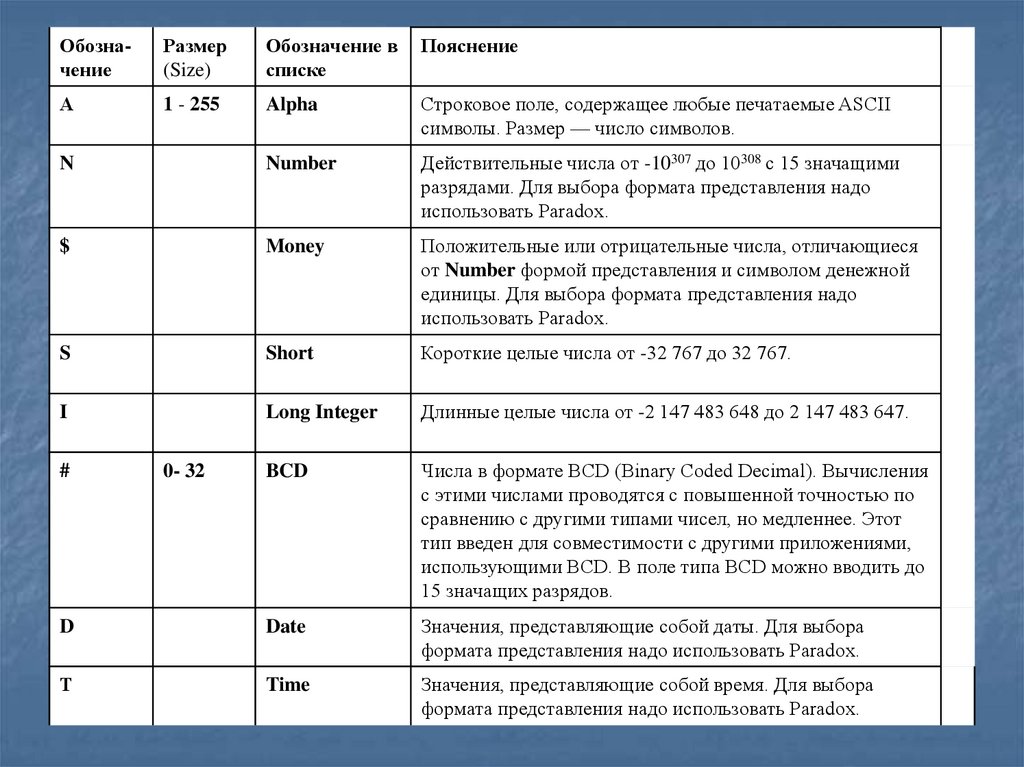
ОбозначениеРазмер
(Size)
Обозначение в
списке
Пояснение
А
1 - 255
Alpha
Строковое поле, содержащее любые печатаемые ASCII
символы. Размер — число символов.
N
Number
Действительные числа от -10307 до 10308 с 15 значащими
разрядами. Для выбора формата представления надо
использовать Paradox.
$
Money
Положительные или отрицательные числа, отличающиеся
от Number формой представления и символом денежной
единицы. Для выбора формата представления надо
использовать Paradox.
S
Short
Короткие целые числа от -32 767 до 32 767.
I
Long Integer
Длинные целые числа от -2 147 483 648 до 2 147 483 647.
BCD
Числа в формате BCD (Binary Coded Decimal). Вычисления
с этими числами проводятся с повышенной точностью по
сравнению с другими типами чисел, но медленнее. Этот
тип введен для совместимости с другими приложениями,
использующими BCD. В поле типа BCD можно вводить до
15 значащих разрядов.
D
Date
Значения, представляющие собой даты. Для выбора
формата представления надо использовать Paradox.
Т
Time
Значения, представляющие собой время. Для выбора
формата представления надо использовать Paradox.
#
0- 32
31.
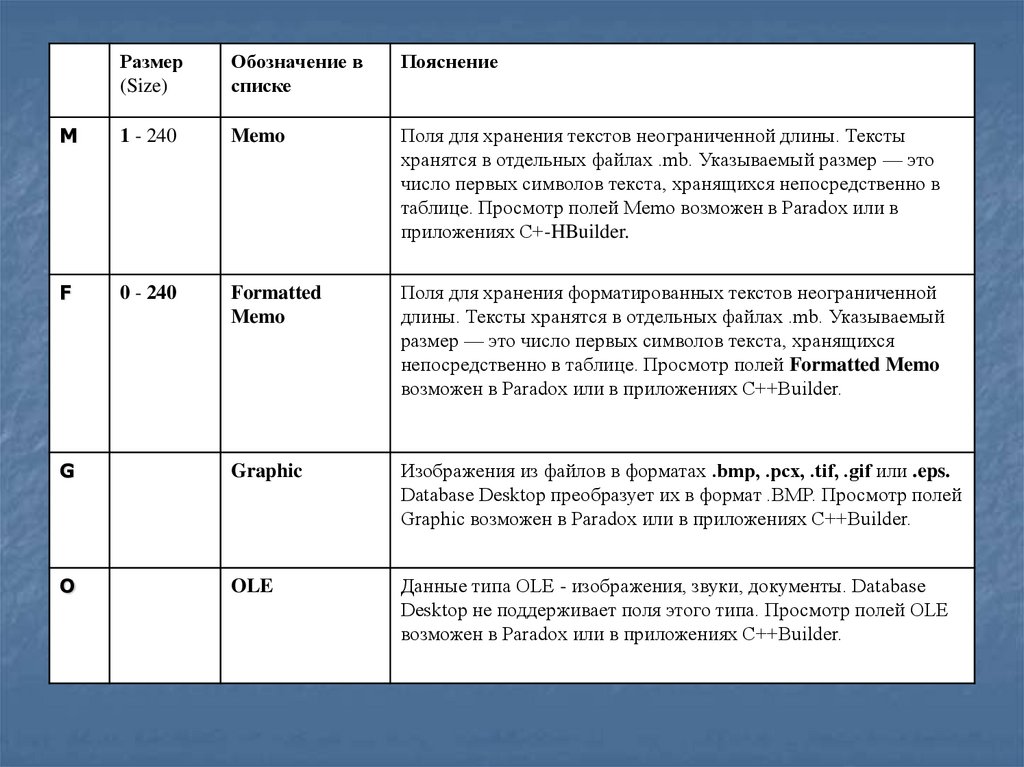
Размер(Size)
Обозначение в
списке
Пояснение
M
1 - 240
Memo
Поля для хранения текстов неограниченной длины. Тексты
хранятся в отдельных файлах .mb. Указываемый размер — это
число первых символов текста, хранящихся непосредственно в
таблице. Просмотр полей Memo возможен в Paradox или в
приложениях С+-HBuilder.
F
0 - 240
Formatted
Memo
Поля для хранения форматированных текстов неограниченной
длины. Тексты хранятся в отдельных файлах .mb. Указываемый
размер — это число первых символов текста, хранящихся
непосредственно в таблице. Просмотр полей Formatted Memo
возможен в Paradox или в приложениях C++Builder.
G
Graphic
Изображения из файлов в форматах .bmp, .рсх, .tif, .gif или .eps.
Database Desktop преобразует их в формат .BMP. Просмотр полей
Graphic возможен в Paradox или в приложениях C++Builder.
O
OLE
Данные типа OLE - изображения, звуки, документы. Database
Desktop не поддерживает поля этого типа. Просмотр полей OLE
возможен в Paradox или в приложениях C++Builder.
32.
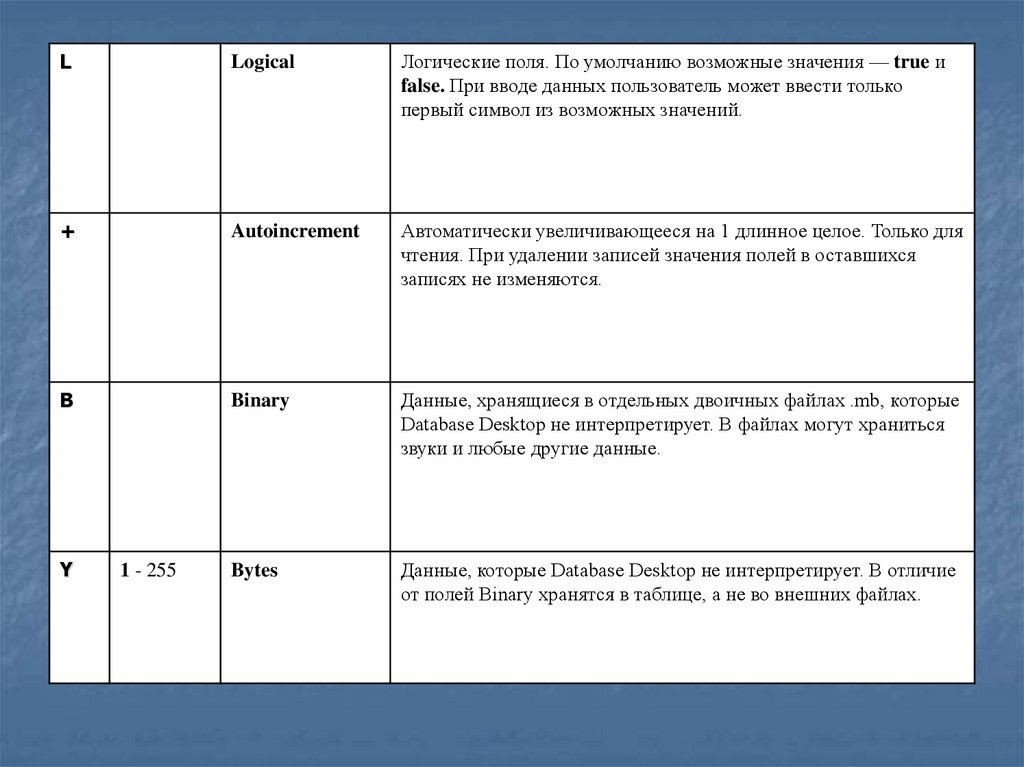
LLogical
Логические поля. По умолчанию возможные значения — true и
false. При вводе данных пользователь может ввести только
первый символ из возможных значений.
+
Autoincrement
Автоматически увеличивающееся на 1 длинное целое. Только для
чтения. При удалении записей значения полей в оставшихся
записях не изменяются.
B
Binary
Данные, хранящиеся в отдельных двоичных файлах .mb, которые
Database Desktop не интерпретирует. В файлах могут храниться
звуки и любые другие данные.
Bytes
Данные, которые Database Desktop не интерпретирует. В отличие
от полей Binary хранятся в таблице, а не во внешних файлах.
Y
1 - 255
33.
В нашем примере таблицы Pers (см.таблицу 1) для поля Num
целесообразно выбрать тип
Autoincrement, обеспечивающий
уникальность каждой записи. Для полей
Dep, Fam, Nam и Par необходимо
задать тип Alpha, для поля Yearjb —
тип Short, для поля Sex — Logical, для
поля Charact — Memo, для поля Photo
— Graphic. В таблице Dep (см. таблицу
2) для поля Dep надо задать тип Alpha,
а для поля Proisv — Logical.
34.
Ключевые поля должны быть отмеченысимволом «*» в последней колонке. Для
того, чтобы поставить или удалить этот
символ, надо или сделать двойной
щелчок в соответствующей графе
информации о поле, или выделить эту
графу и нажать клавишу пробела. Если
имеется несколько ключевых полей, то
в таблицах Paradox они должны быть
первыми. В нашем примере для
таблицы Pers ключевым является поле
Num, а для таблицы Dep — поле Dep.
35. Задание свойств таблицы
Теперь обратите внимание на правуючасть окна. В нем задаются свойства
таблицы (Table properties). Вверху
имеется выпадающий список с рядом
разделов свойств таблицы.
Начнем с первого из них: Validity
Checks — проверка правильности
значений. Вы можете задать следующие
характеристики поля:
36.
Required Field Этим индикатором отмечаются те поля,значения которых обязательно должны содержаться в каждой
записи. Для нашего примера такими полями, вероятно, должны
быть поля Fam, Nam и Par
Minimum
Минимальное значение. Это свойство полезно
задавать для числовых полей. В нашем примере надо задать
минимальное значение для поля Year_b
Maximum
Максимально значение. Это свойство полезно
задавать для числовых полей. В нашем примере надо задать
максимальное значение для поля Year_b
Default
Значение по умолчанию. Это свойство полезно
задавать для числовых и логических полей. В нашем примере
полезно задать значение по умолчанию для поля Year_b и
обязательно надо задать значение по умолчанию для поля Sex
(иначе у пользователя могут возникнуть проблемы при вводе
информации)
Picture
Шаблон для ввода данных. Например, можно
задать шаблон номера телефона «###-##-##» и др.
Подробнее о составлении шаблонов вы можете узнать во
встроенной справке Database Desktop
Assist
Эта кнопка вызывает диалоговое окно,
помогающее создать шаблон Picture и занести его в список, из
которого в дальнейшем его можно брать при создании новых
таблиц
37.
Следующий раздел в выпадающем списке свойствтаблицы в правом верхнем углу экрана - Table Lookup
— таблица просмотра. Этот раздел позволяет связать
с полем данной таблицы какое-то поле другой,
просматриваемой таблицы, из которого будут
браться допустимые значения. При выборе Table
Lookup на экране появляется кнопка Define —
определить. При ее нажатии открывается диалоговое
окно. В нем вы можете для данного поля задать
таблицу просмотра (Lookup table). При этом вы
можете воспользоваться выпадающим списком
драйверов или псевдонимов (Drive or Alias) и кнопкой
просмотра (Browse). A кнопкой со стрелкой занести
поле просматриваемой таблицы, из которого будут
выбираться допустимые значения.
После того, как создана таблица Dep, полезно
вернуться к таблице Pers и для поля Dep задать
таблицу Dep как просматриваемую и ее поле Dep как
множество возможных значений. Это запретит
ошибочное появление в таблице Pers каких-то
значений подразделений, не содержащихся в
таблице Dep.
38.
Следующий раздел в выпадающемсписке свойств таблицы - Secondary
Indexes — вторичные индексы. Этот
раздел позволяет создать необходимые
для дальнейшей работы вторичные
индексы (первичный индекс создается
по ключевым полям). Например, для
дальнейшего использования нашей
таблицы Pers полезны будут следующие
индексы:
39.
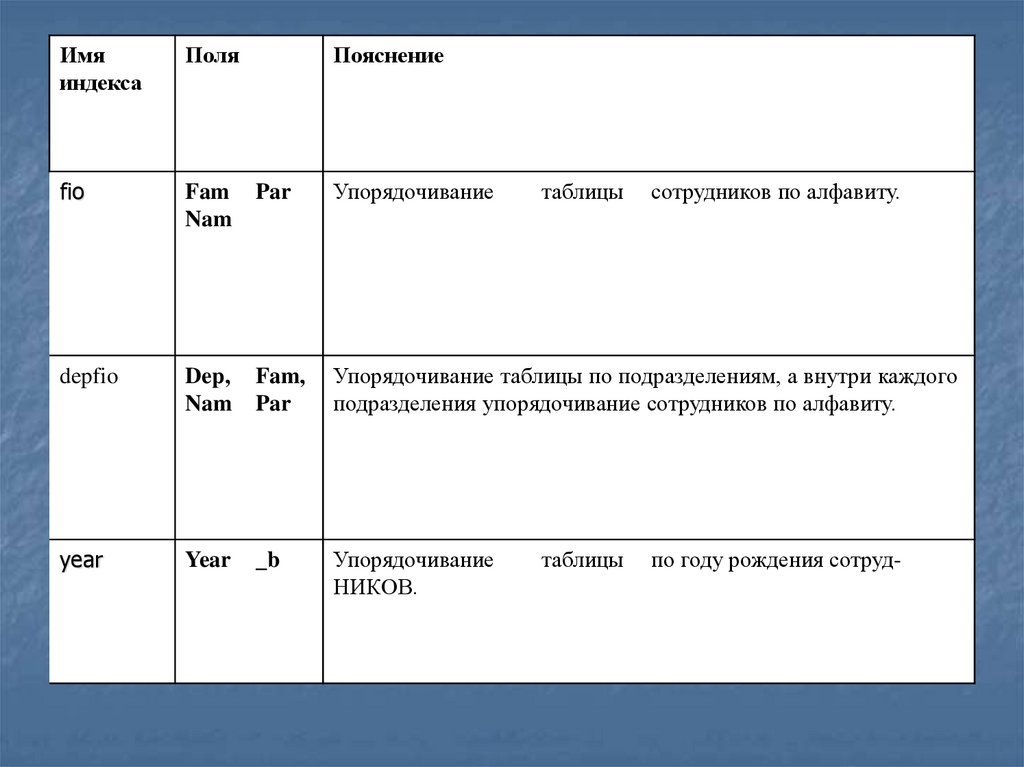
Имяиндекса
Поля
Пояснение
fio
Fam
Nam
Par
Упорядочивание
depfio
Dep,
Nam
Fam,
Par
Упорядочивание таблицы по подразделениям, а внутри каждого
подразделения упорядочивание сотрудников по алфавиту.
year
Year
_b
Упорядочивание
НИКОВ.
таблицы
таблицы
сотрудников по алфавиту.
по году рождения сотруд-
40.
Чтобы создать новый вторичный индекс,нажмите кнопку Define. Откроется диалоговое
окно. В его левом окне – Fields - содержится
список доступных полей, в правом окне
Indexed fields вы можете брать и упорядочить
список полей, включаемых в индекс. Для
переноса поля из левого окна в правое надо
выделить интересующее вас поле или группу
полей и нажать кнопку со стрелкой вправо.
Стрелками Change order (изменить
последованость) можно изменить порядок
следования полей в индексе. Панель
радиокнопок Index Options (опции индекса)
позволяют установить следующие
характеристики:
41.
UniqueУстановка этой опции не позволяет
индексировать таблицу, если в ней находятся
дубликаты совокупности включенных в индекс полей.
Например, установка этой опции для индекса fio не
допустила бы наличия в таблице сотрудников с
совпадающими фамилией, именем и отчеством
Descending
При установке этой опции таблица
будет упорядочиваться по степени убывания
значений (по умолчанию упорядочивание
производится по степени нарастания значений)
Case Sensitive При установке этой опции будет
приниматься во внимание регистр, в котором
введены символы
Maintained
Если эта опция установлена, то
индекс обновляется при каждом изменении в
таблице. В противном случае индекс обновляется
только в момент связывания с таблицей или
передачи в нее запроса. Это несколько замедляет
обработку запросов. Поэтому полезно включать эту
опцию для обновляемых таблиц. Если таблица
используется только для чтения, эту опцию лучше не
включать
42.
Следующий раздел в выпадающем списке свойствтаблицы в правом верхнем углу экрана - Referential
Integrity — целостность на уровне ссылок. Речь идет
о способах, позволяющих обеспечить постоянные
связи между данными отдельных таблиц. Если
устанавливается целостность на уровне ссылок
между двумя таблицами, одна из которых — головная
(родительская), а другая — вспомогательная
(дочерняя), то во вспомогательной таблице
указывается поле или группа полей, которые могут
брать свои значения только из ключевого поля (или
полей) головной таблицы. Подобные связи
допустимы не для всех типов таблиц, но в Paradox
они предусмотрены. Прежде, чем создавать
Referential Integrity, надо иметь обе связываемые
таблицы — родительскую и дочернюю. Если бы мы
уже имели в нашем примере обе таблицы — Pers и
Dep, мы могли бы задать целостность, связав поле
Dep таблиц Pers с ключевым полем Dep головной
таблицы Dep. Чтобы ввести подобную связь, надо
сначала установить в качестве рабочего каталог,
содержащий обе таблицы (это делается командой File
| Working Directory).
43.
Следующий раздел в выпадающем спискесвойств таблицы в правом верхнем - Password
Security — пароли доступа. Paradox позволяет
задать для таблицы пароли и для каждого из
них определить разрешенные операции как
для таблицы в целом, так и для отдельных ее
полей. Щелчок на копке Define откроет вам
окно, в нем вы можете ввести главный
пароль (окно Master password), подтвердить
его (окно Verify master password), после чего
щелчком на копке Auxiliary Passwords
(вспомогательные пароли) открыть новое
диалоговое окно, позволяющее ввести
вспомогательные пароли и определить
правила доступа по ним.
44.
АllДопускаются любые операции,
вплоть до изменения ее структуры, удаления
таблицы, изменения и удаления паролей
Insert & Delete
Допускаются любые операции с
записями (редактирование, вставка, удаление), но не
разрешается изменение структуры таблицы и ее
удаление
Data Entry
Допускается редактирование данных
и вставка записей, но запрещено удаление записей и
не разрешается изменение структуры таблицы и ее
удаление
Update
Допускается только просмотр
таблицы и изменение неключевых полей
Read Only
Допускается только просмотр
таблицы
45.
В окне Field Rights (права доступа кполю) вы можете определить
дополнительные права доступа к
каждому полю, но не превышающие
заданный уровень доступа к таблице.
46. Table Language — язык таблицы
Этот раздел в выпадающем списке TableProperties позволяет задать (если он не
задан) или переопределить (кнопкой
Modify) язык таблицы, установленный
по умолчанию в драйвере данной СУБД
с помощью программы BDE
Administrator. Правильный выбор языка
определяет, будут ли нормально
читаться в таблице русские тексты.
47. Dependent Tables — зависимые таблицы
Этот последний раздел в выпадающемсписке Table Properties позволяет
просматривать список зависимых
таблиц, связанных с данной
целостностью на уровне
Referential Integrity.
48. Завершение создания таблицы
После того, как все необходимые данные о структуретаблицы внесены, щелкните нп кнопке Save as
(сохранить как) и перед вами откроется окно,
начинающее обычный диалог сохранения в файле.
От обычного это окно отличается выпадающим
списком Alias. Этот список содержит псевдонимы
различных баз (о них пойдет речь позднее), из
которого вы можете выбрать базу данных, в которую
будете сохранять свою таблицу. Если вам не надо
сохранять таблицу в существующих базах данных, то
вы можете воспользоваться обычным списком
Сохранить в в верхней части окна. При этом вы с
помощью обычной быстрой кнопки можете создать
новую папку (каталог). Вспомните, что для Paradox
база данных — это каталог, в котором сохраняется
таблица.
49.
Внизу окна имеются еще две опции. Перваяиз них — Display Table обеспечивает
немедленное автоматическое открытие
таблицы после ее сохранения. Вторая опция
— Add Data to New Table доступна в случае,
если производилось не создание таблицы, а
изменение ее структуры. Эта опция
обеспечивает, что в измененную структуру из
прежней таблицы перенесутся все данные,
которые вписываются в новую структуру.
Мы рассмотрели создание таблицы Paradox.
Для других СУБД диалоги отличаются от
рассмотренного и учитывают возможности
различных СУБД. Однако эти отличия
касаются только отдельных деталей и
рассматривать их мы не будем.
50. Создание и редактирование псевдонимов баз данных, каталогов, драйверов
Имеется три альтернативных путипросмотра, создания и редактирования
псевдонимов с помощью трех
различных программ: Database Desktop,
BDE Administrator и Database Explorer.