



























 Информатика
ИнформатикаПохожие презентации:










Кодирование текстовой информации
1.
Михаилиди И.М.КОДИРОВАНИЕ ТЕКСТОВОЙ
ИНФОРМАЦИИ
2.
КОДИРОВАНИЕ ТЕКСТАТак как информация в компьютере может храниться только в
цифровом виде, то для кодирования текстовой информации
нужно перевести ее в числовое представление, или иначе
закодировать в виде чисел, которые затем представить в
двоичной системе счисления для хранения и обработки в
компьютере.
Существуют разные системы кодирования текста для
представления в компьютере:
Пример:
а (латинская) -
1100001 ASCII
а (латинская) - 00000000 01100001
UNICODE
3.
КОДИРОВАНИЕ ТЕКСТАСистема кодирования текстовой (символьной) информации
основана на присваивании каждому символу уникального
целого положительного числа, называемого кодом символа.
Например, это может быть порядковый этого символа в
используемом алфавите.
Количество символов, которое можно закодировать таким
образом зависит от длины используемого кода.
Для кодирования 256 (28) различных символов достаточно
восьми двоичных разрядов (при использовании кодов
одинаковой длины).
4.
КОДИРОВАНИЕ ТЕКСТАДля кодирования текстовой информации разработаны разные
стандарты кодирования
Примеры кодов символов в кодировке ASCII
СИМВОЛ
ДЕСЯТИЧНЫЙ
КОД
ДВОИЧНЫЙ
КОД
ШЕСТНАДЦАТИ
РИЧНЫЙ КОД
Заглавная
латинская Н
072
01001000
48
Строчная
латинская k
107
01101011
6B
Заглавная
русская Н
205
11001101
СD
Строчная русская 234
к
11101010
EA
00111111
3F
?
63
Буквы,
имеющие
одинаковое
начертание в
разных
алфавитах ,
имеют разные
коды!
5.
СИСТЕМА КОДИРОВАНИЯ ASCIIВ1963 году Институт стандартизации США (ANSI –
American National Standard Institute) ввел в действие одну
из первых систем кодирования текста (стандарт) ASCII
(American Standard Code for Information Interchange —
стандартный код информационного обмена США).
Cистема ASCII разбита на две таблицы кодирования:
базовую и расширенную.
В ASCII используются 8-значные коды
В базовой таблице представлены значения кодов
от 0 (двоичный код 00000000)
до 127 (двоичный код 011111111) .
В расширенной таблице представлены значения кодов со
значениями
от 128 (двоичный код 10000000)
до 255 (двоичный код 111111111)
6.
СИСТЕМА КОДИРОВАНИЯ ASCIIПервые 32 кода базовой таблицы, начиная с нулевого, - это
управляющие коды.
Символы с этими кодами, не выводятся на экран или на
печать, но служат для управления выводом текста или
других данных на различные устройства (например,
перевод строки, табуляции и др.)
В базовую таблицу также входят буквы латинского
алфавита, цифры, простые знаки препинания, знаки
арифметических операций скобки и некоторые другие
часто употребляемые символы.
Остальные 128 кодов, начиная со 128 (двоичный код
10000000) и кончая 255 (11111111), используются для
кодировки букв национальных алфавитов, символов
псевдографики и некоторых научных символов.
7.
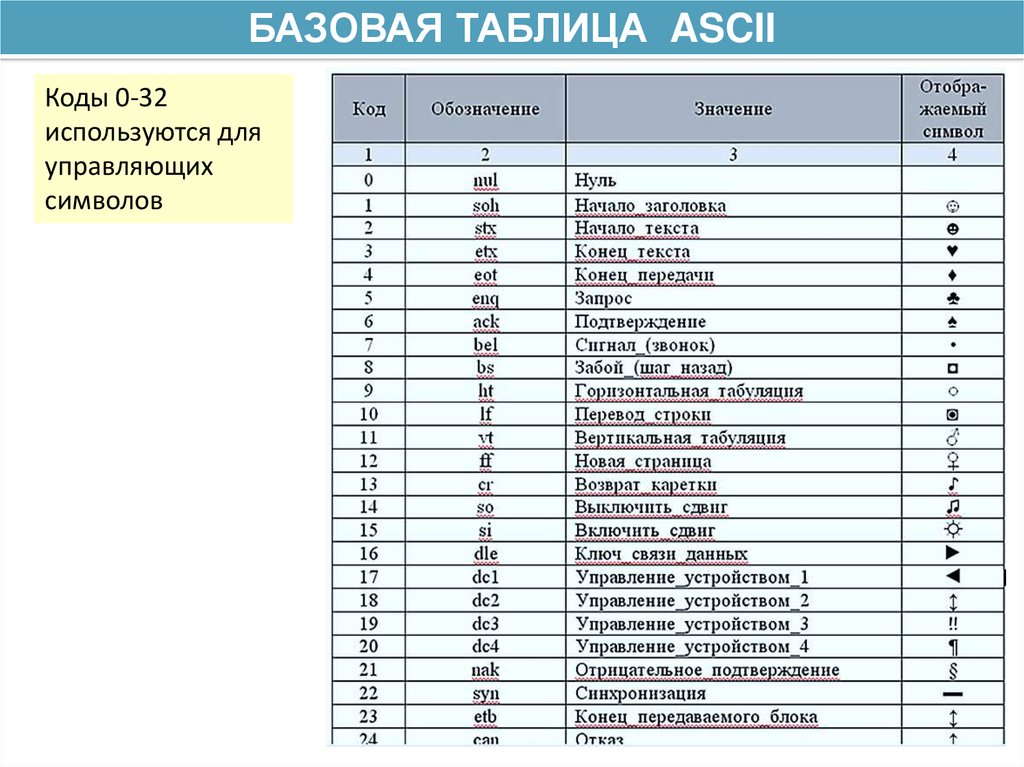
СИСТЕМАКОДИРОВАНИЯ
ASCII
БАЗОВАЯ
ТАБЛИЦА ASCII
Коды 0-32
используются для
управляющих
символов
8.
БАЗОВАЯ ТАБЛИЦА ASCIIС кода 33 начинаются текстовые символы
Здесь таблица представлена в 3 колонки:
символ, его код в 10-й системе счисления
и в двоичной системе счисления
9.
РАСШИРЕННАЯ ТАБЛИЦА ASCIIС кода 128
начинается
расширенная
таблица,
включающая коды
для национальных
алфавитов
Эта
Длярасширенная
русского языка
таблица
эта таблица,
называется
используемая для
кодовой
страницей
ОС WINDOWS
,
и
для разных
называется
языков
CP 1251содержит
и содержит
разные
символысимволы
кириллицы и
некоторые
специальные знаки
10.
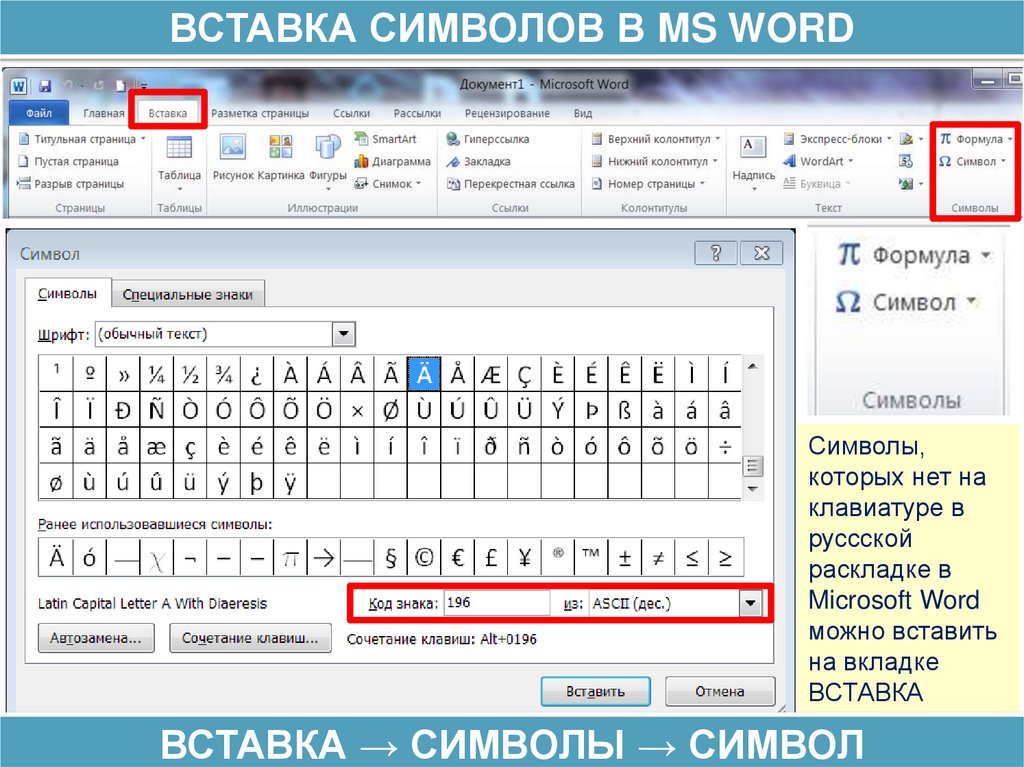
ВСТАВКА СИМВОЛОВ В MS WORDСимволы,
которых нет на
клавиатуре в
руссской
раскладке в
Microsoft Word
можно вставить
на вкладке
ВСТАВКА
ВСТАВКА → СИМВОЛЫ → СИМВОЛ
11.
ВСТАВКА СИМВОЛОВ В MS WORDВСТАВКА → СИМВОЛЫ → СИМВОЛ
12.
ВСТАВКА СИМВОЛОВ В MS WORDВСТАВКА –> СИМВОЛЫ -> СИМВОЛ
13.
ВСТАВКА СИМВОЛОВ В MS WORDВСТАВКА –> СИМВОЛЫ -> СИМВОЛ
14.
ВСТАВКА СИМВОЛОВ В MS WORDВСТАВКА –> СИМВОЛЫ -> СИМВОЛ
15.
СИСТЕМЫ КОДИРОВАНИЯ В РОССИИВ СССР, и позже в России, применялось несколько систем
кодирования текста для кириллицы:
• Система кодирования КОИ-7 (код обмена
информацией, семизначный);
• Система кодирования КОИ-8 (код обмена
информацией, восьмизначный).
• Для кодирования букв русского языка использовалась
кодировка КОИ8-Р.
Для кодирования букв украинского языка использовалась
кодировка КОИ8-У.
16.
СИСТЕМЫ КОДИРОВАНИЯ В РОССИИКодировка КОИ8-Р имела широкое распространение на
территории России :
• в Unix-совместимых операционных системах;
• в компьютерных сетях и в некоторых службах
российского сектора Интернета.
В частности, в России КОИ8-Р являлась стандартной в
сообщениях электронной почты и телеконференций.
Начиная c 2010 года, постепенно вышла из употребления
17.
СИСТЕМЫ КОДИРОВАНИЯ В РОССИИКодировка кириллицы для русского языка Windows-1251
была введена компанией Microsoft. Она представляет
собой кодовую страницу для кириллицы в системе ASCII.
Эта кодировка используется на большинстве компьютеров,
работающих на платформе Windows. Она стала также
стандартном в российском секторе World Wide Web.
Система кодирования ISO 8859 разработана
Международным институтом стандартизации (International
Standard Organization ) для UNIX-подобных операционных
cистем.
Кодовая страница для кириллицы: ISO 8859-5. Совместима
с ASCII.
В настоящее время эта кодировка используется редко.
18.
Пример текста в разных системах кодированияТексты созданные в одной кодировке будут неправильно отображаться в
другой кодировке
Windows 1251
КОИ8-Р
Если текст имеет кодировку Windows 1251, а его попытаются прочитать в
браузере с установленной по умолчанию кодировкой КОИ8-Р, то получится
вот такая абракадабра
19.
СТАНДАРТ UNICODEТрудности, связанные с созданием единой
системы кодирования текстовых данных
вызваны ограниченным набором кодов
(256) в использовавшихся ранее
системах кодирования
Но, если кодировать символы не восьмиразрядными
двоичными числами, а числами с бóльшим количеством
разрядов, то и диапазон возможных значений кодов
станет намного больше.
В 1991 году был разработан, новый стандарт
кодирования, основанный на 16-разрядных кодах (2
байта на 1 символ). Он получил название UNICODE
(«универсальный код»).
20.
СТАНДАРТ UNICODEЧисло кодов в первом стандарте UNICODE было равно
216 = 65536. Этого вполне достаточно для размещения
в одной кодовой таблице алфавитных символов
большинства языков планеты.
В дальнейшем (в 1996 г.) кодовое пространство
стандарта UNICODE было значительно расширено (до 6
байт на 1 символ, хотя реально используется до 4 байт
на символ), что позволило включить в стандартный
набор символов:
• знаки вымерших форм письменности,
• редкие китайские иероглифы,
• больше пиктограмм,
• музыкальные и редкие математические символы
21.
МИР UNICODEПри использовании четырехбайтной кодировки в Unicode можно закодировать
231 символов (первый бит не используется) это более двух миллиардов кодов
231=2 147 483 648!
Но в реальности было решено использовать только 1 112 064 кодов для
совместимости с кодировкой UTF-16. Этого более чем достаточно , чтобы
охватить все формы письменности всех существующих и вымерших языков.
22.
СИСТЕМA КОДИРОВАНИЯ UNICODEСтандарт UNICODE состоит из двух основных
разделов: универсальный набор символов (UCS, universal
character set) и семейство кодировок (UTF, Unicode
transformation format).
Универсальный набор символов содержит числовые коды
для каждого символа любой формы письменности, а также
коды специальных симолов и пиктограмм.
Семейство кодировок определяет машинное
представление кодов UCS (например однобайтный или
двубайтный код, коды переменной или постоянной длины).
Код символа в UNICODE записывается как U+xxxx, где xxxx –
это число в 16-ричной системе счисления.
Например: строчная латинская буква а имеет код U+0061
А строчная кириллическая буква а имеет код U+0430
23.
СИСТЕМA КОДИРОВАНИЯ UNICODE• Для символов кириллицы в системе UNICODE
отведено два диапазона кодов:
с 0400 по 04FF ( в 16-ричной системе счисления )базовая кириллица и
с 0500 по 052F - расширенная кириллица.
• Для кодирования формул в систему UNICODE
был введен набор математических символов
• для нотных записей - набор музыкальных
символов.
• Кроме того, в систему UNICODE также был
включен расширенный набор пиктограмм.
24.
ПЛОСКОСТИ UNICODEКодовое пространство UNICODE разбито на 17
подмножеств (плоскостей), пронумерованных от 0 до 16
и содержащих по 216 кодов в каждом.
25.
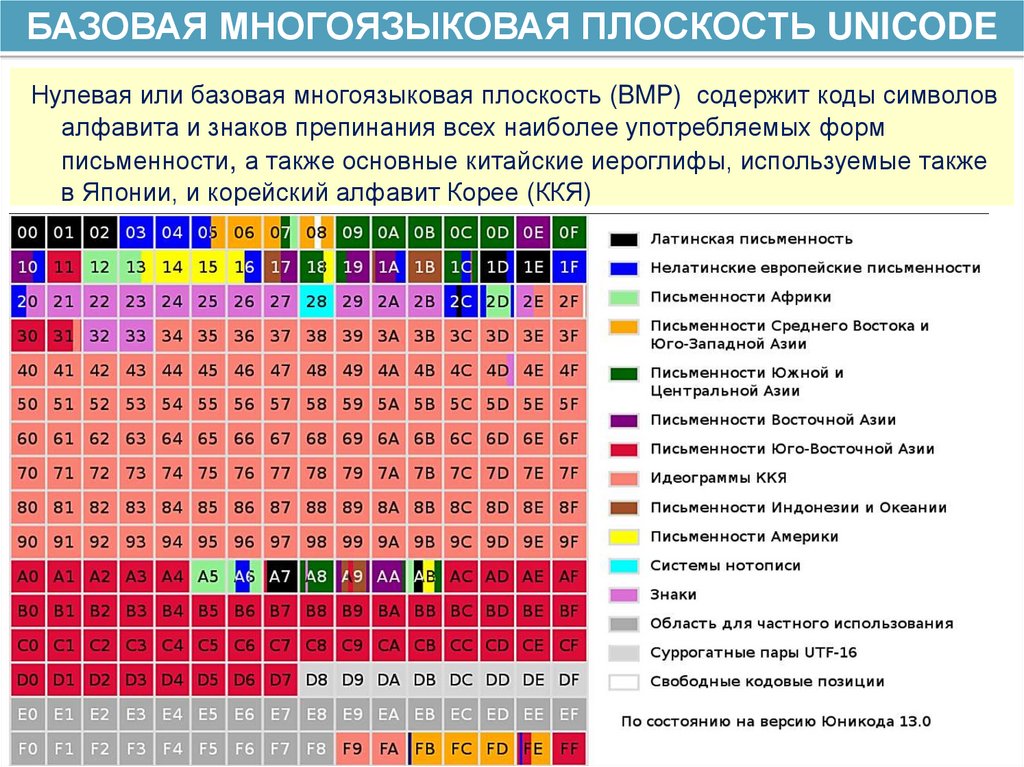
БАЗОВАЯ МНОГОЯЗЫКОВАЯ ПЛОСКОСТЬ UNICODEНулевая или базовая многоязыковая плоскость (BMP) содержит коды символов
алфавита и знаков препинания всех наиболее употребляемых форм
письменности, а также основные китайские иероглифы, используемые также
в Японии, и корейский алфавит Корее (ККЯ)
26.
ДОПОЛНИТЕЛЬНАЯ МНОГОЯЗЫКОВАЯПЛОСКОСТЬ UNICODE
1-я или дополнительная многоязыковая плоскость содержит коды
символов алфавита вымерших языков, но включает также коды
математических и музыкальных символы
27.
ДОПОЛНИТЕЛЬНАЯ ИДЕОГРАФИЧЕСКАЯПЛОСКОСТЬ UNICODE
2-я или дополнительная идеографическая плоскость Unicode содержит
редкие китайские иероглифы
Иллюстрации к Слайдам 2426 – источник Википедия
28.
КОДИРОВКА UTF- 8Для того чтобы решить проблему увеличения длины
закодированных текстов была разработана кодировка
UTF-8 (Unicode Transformation Format) – одно из
представлений Unicode.
Эта кодировка имеет нефиксированную длину кодов от 8
до 32 бит. При этом коды символов с номером меньше
128, совпадают по значению с кодами ASCII (базовая
латиница и др.) и записываются как 8-разрядные, то
есть занимают 1 байт. Остальные символы из
универсального набора символов UNICODE (UCS)
изображаются кодами длиной 16, 24 и 32 разряда, то
есть занимают от 2-х до 4-х байт, соответственно
UTF-8 в настоящее время является самой
распространённой практической реализацией
UNICODE, как самая экономичная.
29.
КОДИРОВКА UTF-830.
Таблица символов WindowsДля того чтобы узнать код символа и определить, в какой
диапазон он попадает, можно использовать:
Например, сайт https://unicode-table.com/ru/044B/
Или таблицу символов Windows
Эту таблицу можно вызвать так:
• начать набирать в строке поиска: Таблица символов и в
списке программ появится программа «Таблица
символов»
• нажать комбинацию клавиш Win-R и в открывшемся
окне вызова программ ввести: charmap.exe
31.
Таблица символов WindowsКод выбранного
символа в системе
кодирования Unicode
показан в нижней строке
Далее нужно
посмотреть, в какой
диапазон этот код
попадает при
использовании
кодировки UTF-8
В примере код буквы Ä
00С4 > 0080, значит в
UTF-8 этот символ
кодируется в 2 байта
32.
КОДИРОВКА UTF- 6Кодировка UTF-16 (Unicode Transformation Format) –
создана для совместимости с первой версией Unicode
(1991-1995 год).
В этй кодировке коды символов записываются в 2 или 4
байта, то есть имеют длину 16 или 32 бита.
При этом коды символов, имеющих номера в базовой
мультиязычной плоскости, за исключением дапазона
для суррогатных пар, записываются как 16-разрядные,
то есть занимают 2 байта. Остальные символы из
универсального набора символов UNICODE (UCS)
изображаются кодами длиной 32 разряда и занимают
4 байта.
33.
КОНТРОЛЬНЫЕ ВОПРОСЫ1. Сколько разрядов используется для кодирования в
системе ASCII?
2. Какие две таблицы закреплены в системе ASCII?
3. Какие группы кодов размещены в базовой таблице
системы ASCII?
4. Какие группы кодов размещены в расширенной
таблице системы ASCII?
5. Какие системы кодирования текстовой информации вы
знаете?
6. Что представляет собой стандарт кодирования
UNICODE?
7. Что такое плоскости Unicode?
8. Представлены ли в Unicode китайские иероглифы?
9. Как кодируется текстовая информация в UTF-8?
10.Как кодируется текстовая информация в UTF-16?