













 Базы данных
Базы данныхПохожие презентации:







")


SQL
1.
2.
SQL1
SQL
SQL (ˈɛsˈkjuˈɛl; англ. Structured Query Language — «язык структурированных запросов») — универсальный
компьютерный язык, применяемый для создания, модификации и управления данными в реляционных базах
данных.
SQL основывается на реляционной алгебре.
Введение
SQL является, прежде всего, информационно-логическим языком, предназначенным для описания хранимых
данных, для извлечения хранимых данных и для модификации данных. SQL не является языком
программирования. (Вместе с тем стандарт языка спецификацией SQL/PSM предусматривает возможность его
процедурных расширений.)
Изначально, SQL был основным способом работы пользователя с базой данных и представлял собой
небольшую совокупность команд (операторов) допускающих создание таблиц, добавление в таблицы новых
записей, извлечение записей из таблиц (в соответствии с заданным условием), удаление записей и изменение
структур таблиц. В связи с усложнением язык SQL стал более языком прикладного программирования, а
пользователи получили возможность использовать визуальные построители запросов.
Язык SQL представляет собой совокупность операторов.
Операторы SQL делятся на:
операторы определения данных (Data Definition Language, DDL)
операторы манипуляции данными (Data Manipulation Language, DML)
операторы определения доступа к данным (Data Control Language, DCL)
операторы управления транзакциями (Transaction Control Language, TCL)
История
В начале 1970-х годов в одной из исследовательских лабораторий компании IBM была разработана
экспериментальная реляционная СУБД IBM System R, для которой затем был создан специальный язык
SEQUEL, позволявший относительно просто управлять данными в этой СУБД. Аббревиатура SEQUEL
расшифровывалась как Structured English QUEry Language — «структурированный английский язык
запросов». Позже по юридическим соображениям[1] язык SEQUEL был переименован в SQL. Когда в 1986 году
первый стандарт языка SQL был принят ANSI (American National Standards Institute), официальным
произношением стало [,es kju:' el] — эс-кью-эл. Несмотря на это, даже англоязычные специалисты зачастую
продолжают читать SQL как сиквел (по-русски также часто говорят «эс-ку-эль»).
Целью разработки было создание простого непроцедурного языка, которым мог воспользоваться любой
пользователь, даже не имеющий навыков программирования. Собственно разработкой языка запросов
занимались Дональд Чэмбэрлин (Donald D. Chamberlin) и Рэй Бойс (Ray Boyce). Пэт Селинджер (Pat Selinger)
занималась разработкой стоимостного оптимизатора (cost-based optimizer), Рэймонд Лори (Raymond Lorie)
занимался компилятором запросов.
Стоит отметить, что SEQUEL был не единственным языком подобного назначения. В Калифорнийском
Университете Беркли была разработана некоммерческая СУБД Ingres (являвшаяся, между прочим, дальним
прародителем популярной сейчас некоммерческой СУБД PostgreSQL), которая являлась реляционной СУБД,
но использовала свой собственный язык QUEL, который, однако, не выдержал конкуренции по количеству
поддерживающих его СУБД с языком SQL.
3.
SQL2
Первыми СУБД, поддерживающими новый язык, стали в 1979 году Oracle V2 для машин VAX от компании
Relational Software Inc. (впоследствии ставшей компанией Oracle) и System/38 от IBM, основанная на
System/R. Вопреки сложившемуся мнению, первой стала именно СУБД Oracle V2[источник не указан 359 ].
Первый официальный стандарт языка SQL был принят ANSI в 1986 году и ISO (Международной организацией
по стандартизации) в 1987 году (так называемый SQL-86) и несколько уточнён в 1989 году. Дальнейшее
развитие языка поставщиками СУБД потребовало принятия в 1992 году нового расширенного стандарта
(ANSI SQL-92 или просто SQL2). Следующим стандартом стал SQL:1999 (SQL3). В настоящее время
действует стандарт, принятый в 2003 году (SQL:2003) с небольшими модификациями, внесёнными позже.
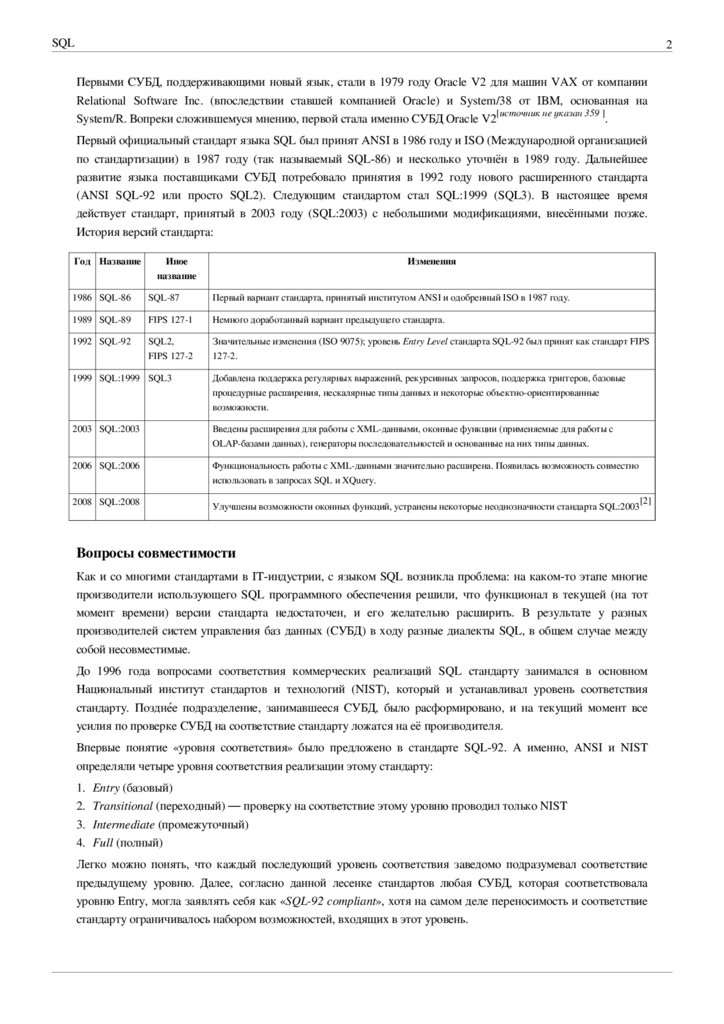
История версий стандарта:
Год Название
Иное
название
Изменения
1986 SQL-86
SQL-87
Первый вариант стандарта, принятый институтом ANSI и одобренный ISO в 1987 году.
1989 SQL-89
FIPS 127-1
Немного доработанный вариант предыдущего стандарта.
1992 SQL-92
SQL2,
FIPS 127-2
Значительные изменения (ISO 9075); уровень Entry Level стандарта SQL-92 был принят как стандарт FIPS
127-2.
1999 SQL:1999 SQL3
Добавлена поддержка регулярных выражений, рекурсивных запросов, поддержка триггеров, базовые
процедурные расширения, нескалярные типы данных и некоторые объектно-ориентированные
возможности.
2003 SQL:2003
Введены расширения для работы с XML-данными, оконные функции (применяемые для работы с
OLAP-базами данных), генераторы последовательностей и основанные на них типы данных.
2006 SQL:2006
Функциональность работы с XML-данными значительно расширена. Появилась возможность совместно
использовать в запросах SQL и XQuery.
2008 SQL:2008
Улучшены возможности оконных функций, устранены некоторые неоднозначности стандарта SQL:2003
[2]
Вопросы совместимости
Как и со многими стандартами в IT-индустрии, с языком SQL возникла проблема: на каком-то этапе многие
производители использующего SQL программного обеспечения решили, что функционал в текущей (на тот
момент времени) версии стандарта недостаточен, и его желательно расширить. В результате у разных
производителей систем управления баз данных (СУБД) в ходу разные диалекты SQL, в общем случае между
собой несовместимые.
До 1996 года вопросами соответствия коммерческих реализаций SQL стандарту занимался в основном
Национальный институт стандартов и технологий (NIST), который и устанавливал уровень соответствия
стандарту. Поздне́е подразделение, занимавшееся СУБД, было расформировано, и на текущий момент все
усилия по проверке СУБД на соответствие стандарту ложатся на её производителя.
Впервые понятие «уровня соответствия» было предложено в стандарте SQL-92. А именно, ANSI и NIST
определяли четыре уровня соответствия реализации этому стандарту:
1. Entry (базовый)
2. Transitional (переходный) — проверку на соответствие этому уровню проводил только NIST
3. Intermediate (промежуточный)
4. Full (полный)
Легко можно понять, что каждый последующий уровень соответствия заведомо подразумевал соответствие
предыдущему уровню. Далее, согласно данной лесенке стандартов любая СУБД, которая соответствовала
уровню Entry, могла заявлять себя как «SQL-92 compliant», хотя на самом деле переносимость и соответствие
стандарту ограничивалось набором возможностей, входящих в этот уровень.
4.
SQL3
Положение изменилось с введением стандарта SQL:1999. Отныне стандарт приобрёл модульную структуру —
основная часть стандарта была вынесена в раздел «SQL/Foundation», все остальные были выведены в
отдельные модули. Соответственно, остался только один уровень совместимости — Core, что означало
поддержку этой основной части. Поддержка остальных возможностей оставлена на усмотрение
производителей СУБД. Аналогичное положение имело место и с последующими версиями стандарта.
Преимущества и недостатки
Преимущества
Независимость от конкретной СУБД
Несмотря на наличие диалектов и различий в синтаксисе, в большинстве своём тексты SQL-запросов,
содержащие DDL и DML, могут быть достаточно легко перенесены из одной СУБД в другую. Существуют
системы, разработчики которых изначально ориентировались на применение по меньшей мере нескольких
СУБД (например: система электронного документооборота Documentum может работать как с Oracle, так и с
Microsoft SQL Server и IBM DB2). Естественно, что при применении некоторых специфичных для реализации
возможностей такой переносимости добиться уже очень трудно.
Наличие стандартов
Наличие стандартов и набора тестов для выявления совместимости и соответствия конкретной реализации
SQL общепринятому стандарту только способствует «стабилизации» языка. Правда, стоит обратить внимание,
что сам по себе стандарт местами чересчур формализован и раздут в размерах (например, Core-часть стандарта
SQL:2003 представляет собой более 1300 страниц текста).
Декларативность
С помощью SQL программист описывает только то, какие данные нужно извлечь или модифицировать. То,
каким образом это сделать, решает СУБД непосредственно при обработке SQL-запроса. Однако не стоит
думать, что это полностью универсальный принцип — программист описывает набор данных для выборки или
модификации, однако ему при этом полезно представлять, как СУБД будет разбирать текст его запроса. Чем
сложнее сконструирован запрос, тем больше он допускает вариантов написания, различных по скорости
выполнения, но одинаковых по итоговому набору данных.
Недостатки
Несоответствие реляционной модели данных
Создатели реляционной модели данных Эдгар Кодд, Кристофер Дейт и их сторонники указывают на то, что
SQL не является истинно реляционным языком. В частности, они указывают на следующие проблемы SQL[3] :
Повторяющиеся строки
Неопределённые значения (nulls)
Явное указание порядка колонок слева направо
Колонки без имени и дублирующиеся имена колонок
Отсутствие поддержки свойства «=»
Использование указателей
Высокая избыточность
В опубликованном Кристофером Дейтом и Хью Дарвеном Третьем Манифесте[4] они излагают принципы
СУБД следующего поколения и предлагают язык Tutorial D, который является подлинно реляционным.
5.
SQL4
Сложность
Хотя SQL и задумывался как средство работы конечного пользователя, в конце концов он стал настолько
сложным, что превратился в инструмент программиста.
Отступления от стандартов
Несмотря на наличие международного стандарта ANSI SQL-92, многие компании, занимающиеся разработкой
СУБД (например, Oracle, Sybase, Microsoft, MySQL AB), вносят изменения в язык SQL, применяемый в
разрабатываемой СУБД, тем самым отступая от стандарта. Таким образом, появляются специфичные для
каждой конкретной СУБД диалекты языка SQL.
Сложность работы с иерархическими структурами
Ранее диалекты SQL большинства СУБД не предлагали способа манипуляции древовидными структурами.
Некоторые поставщики СУБД предлагали свои решения (например, Oracle использует выражение CONNECT
BY). В настоящее время в ANSI стандартизована рекурсивная конструкция WITH из диалекта SQL DB2. В
MS SQL Server рекурсивные запросы появились лишь в версии MS SQL Server 2005. В версии MS SQL Server
2008 появился новый тип данных — hierarchyid, упрощающий манипуляцию древовидными
структурами.[источник не указан 121 ].
Расширения
Процедурные расширения
Поскольку SQL не является языком программирования (то есть не предоставляет средств для автоматизации
операций с данными), вводимые разными производителями расширения касались в первую очередь
процедурных расширений. Это хранимые процедуры (stored procedures) и процедурные языки-«надстройки».
Практически в каждой СУБД применяется свой процедурный язык. Стандарт для процедурных расширений
представлен спецификацией SQL/PSM. Перечень процедурных расширений для самых популярных СУБД
приведён в следующей таблице:
СУБД
Краткое
название
Расшифровка
InterBase/Firebird
PSQL
IBM DB2
SQL PL (англ.)
SQL Procedural Language (расширяет SQL/PSM); также в DB2 хранимые процедуры могут писаться на
обычных языках программирования: Си, Java и т. д.
MS SQL Server/
Sybase ASE
Transact-SQL
Transact-SQL
MySQL
SQL/PSM
SQL/Persistent Stored Module (соответствует стандарту SQL:2003[источник не указан 359 ])
Oracle
PL/SQL
Procedural Language/SQL (основан на языке Ada)
PostgreSQL
PL/pgSQL
Procedural Language/PostgreSQL Structured Query Language (очень похож на Oracle PL/SQL)
Procedural SQL
6.
SQL5
См. также
QBE
SQL-дескриптор
Внедрение SQL-кода
Хранимая процедура
SQLCA
Ссылки
Текст стандарта SQL-92 [5](англ.)
Форум по СУБД и SQL [6](рус.)
Упражнения по SQL. Самоучитель по SQL DML [7](рус.)(англ.)
SQL. Введение и руководство [8]
Краткий курс SQL [9]
Интерактивный учебник по SQL с примерами и задачами [10]
Наиболее интересные новшества в стандарте SQL:2003 [11]
Литература
• Бен Форта. Освой самостоятельно язык запросов SQL / Пер. с англ. — 3-е изд. — М.: Диалектика, 2005. —
288 с.
• Пол Уилтон, Джон Колби. Язык запросов SQL для начинающих / Пер. с англ. — М.: Диалектика, 2005. —
496 с.
• К. Дж. Дейт. Введение в системы баз данных / Пер. с англ. — 8-е изд. — М.: Вильямс, 2005. — 1328 с.
• Кевин Клайн. SQL. Справочник [12]. — М.: Кудиц-Образ, 2006. — 832 с.
Сноски
[1] Andy Oppel. Databases Demystified (http:/ / www. mhprofessional. com/ product. php?cat=112& isbn=0072253649). — San Francisco, CA:
McGraw-Hill Osborne Media. — С. 90—91. — ISBN 0-07-225364-9 — «„SEQUEL“ был торговой маркой британской авиастроительной
группы компаний Hawker Siddeley»
[2] http:/ / archives. postgresql. org/ pgsql-hackers/ 2008-09/ msg00071. php
[3] O’Reilly Network (http:/ / www. oreillynet. com/ lpt/ a/ 6060) An Interview with Chris Date
[4] The Third Manifesto (http:/ / www. thethirdmanifesto. com/ )
[5] http:/ / www. contrib. andrew. cmu. edu/ ~shadow/ sql/ sql1992. txt
[6] http:/ / www. sql. ru/
[7] http:/ / www. sql-ex. ru/
[8] http:/ / aam. ugpl. de/ ?q=sql_vvedenie/ select
[9] http:/ / gsbelarus. com/ gs/ wiki/ index. php/ Краткий_курс_SQL
[10] http:/ / www. sql-tutorial. ru/
[11] http:/ / citforum. ru/ database/ sql/ sql2003/
[12] http:/ / mea. dn. ua/ category/ sql20002008/ sql_spravochnik. html
7.
Select (SQL)Select (SQL)
SELECT — оператор DML языка SQL, возвращающий набор данных (выборку) из базы данных,
удовлетворяющих заданному условию.
В большинстве случаев, выборка осуществляется из одной или нескольких таблиц. В последнем случае говорят
об операции слияния (англ. join). В тех СУБД, где реализованы представления и хранимые процедуры, также
возможно получение соответствующих наборов данных.
При формировании запроса SELECT пользователь описывает ожидаемый набор данных: его вид (набор
столбцов) и его содержимое (критерий попадания записи в набор, группировка значений, порядок вывода
записей и т.п.).
Запрос выполняется следующим образом: сначала извлекаются все записи из таблицы, а, затем, для каждой
записи набора проверяется её соответствие заданному критерию. Если осуществляется слияние из нескольких
таблиц, то сначала составляется произведение таблиц, а уже затем из полученного набора отбираются
требуемые записи.
Особую роль играет обработка NULL-значений, когда при слиянии, например, двух таблиц — главной (англ.
master) и подчинённой (англ. detail) — имеются или отсутствуют соответствия между записями таблиц,
участвующих в слиянии. Для решения этой задачи используются механизмы внутреннего (англ. inner) и
внешнего (англ. outer) слияния.
Один и тот же набор данных может быть получен при выполнении различных запросов. Поиск оптимального
плана выполнения данного запроса является задачей оптимизатора.
Структура оператора
Оператор SELECT имеет следующую структуру:
SELECT [DISTINCT | DISTINCTROW | ALL] select_expression,... [FROM table_references [WHERE
where_definition] [GROUP BY {unsigned_integer | col_name | formula} [ASC | DESC], ...] [HAVING
where_definition] [ORDER BY {unsigned_integer | col_name | formula} [ASC | DESC], ...]
Формат запроса с использованием данного оператора:
SELECT список полей FROM список таблиц WHERE условия…
Основные ключевые слова, относящиеся к запросу SELECT:
• WHERE — используется для определения, какие строки должны быть выбраны или включены в GROUP
BY.
• GROUP BY — используется для объединения строк с общими значениями в элементы меньшего набора
строк.
• HAVING — используется для определения, какие строки после GROUP BY должны быть выбраны.
• ORDER BY — используется для определения, какие столбцы используются для сортировки
результирующего набора данных.
Примеры
1
8.
Select (SQL)2
Таблица
«T»
Запрос
Результат
SELECT * FROM T;
C1 C2
C1 C2
1
a
1
a
2
b
2
b
SELECT C1 FROM T;
C1 C2
C1
1
a
1
2
b
2
SELECT * FROM T WHERE C1 = 1;
C1 C2
C1 C2
1
a
1
2
b
a
SELECT * FROM T ORDER BY C1 DESC;
C1 C2
C1 C2
1
a
2
b
2
b
1
a
Для таблицы T запрос
SELECT * FROM T;
вернёт все столбцы всех строк данной таблицы.
Для той же таблицы запрос
SELECT C1 FROM T;
вернёт значения столбца C1 всех строк таблицы— в терминах реляционной алгебры можно сказать, что была
выполнена проекция.
Для той же таблицы запрос
SELECT * FROM T WHERE C1 = 1;
вернёт значения всех столбцов всех строк таблицы, у которых значение поля C1 равно '1'— в терминах
реляционной алгебры можно сказать, что была выполнена выборка, так как присутствует ключевое слово
WHERE.
Последний запрос
SELECT * FROM T ORDER BY C1 DESC;
вернёт те же строки, что и первый, однако результат будет отсортирован в обратном порядке (Z-A) из-за
использования ключевого слова ORDER BY с полем C1 в качестве поля сортировки. Этот запрос не содержит
ключевого слова WHERE, поэтому он вернёт всё, что есть в таблице. Несколько элементов ORDER BY могут
быть указаны разделённые запятыми [напр. ORDER BY C1 ASC, C2 DESC] для более точной сортировки.
Отбирает все строки где поле column_name равен одному из перечисленных значений value1,value2,...
9.
Select (SQL)SELECT *
FROM table_name
WHERE column_name IN (value1,value2,...)
Ограничение возвращаемых строк
Согласно ISO SQL:2003 возвращаемый набор данных может быть ограничен с помощью:
• курсоров, или
• введением оконных функций в оператор SELECT
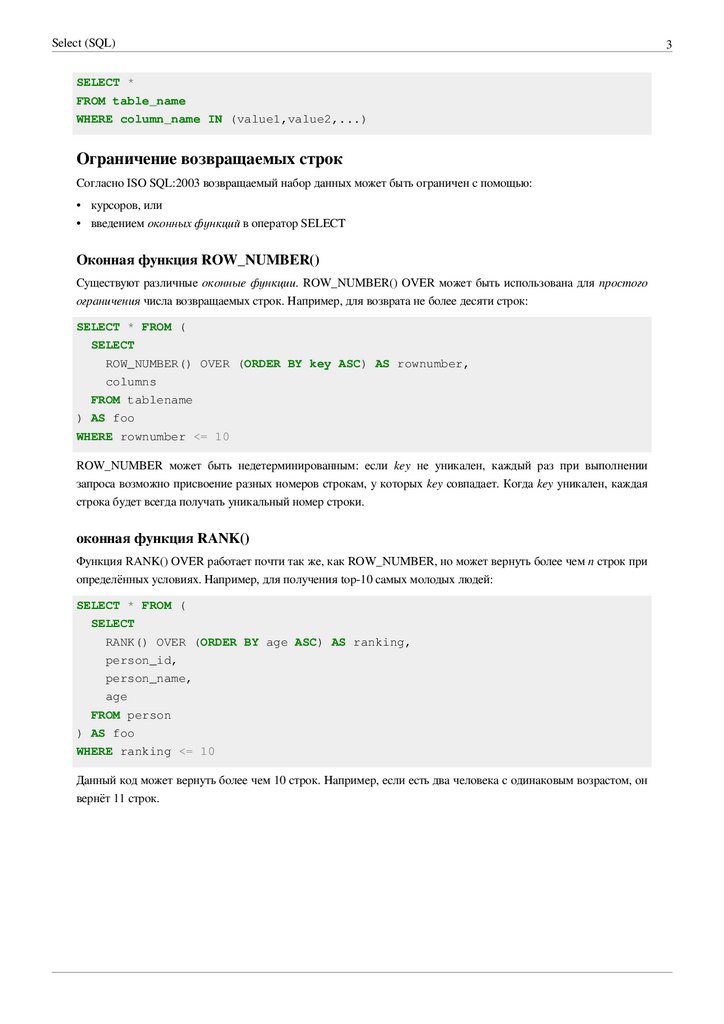
Оконная функция ROW_NUMBER()
Существуют различные оконные функции. ROW_NUMBER() OVER может быть использована для простого
ограничения числа возвращаемых строк. Например, для возврата не более десяти строк:
SELECT * FROM (
SELECT
ROW_NUMBER() OVER (ORDER BY key ASC) AS rownumber,
columns
FROM tablename
) AS foo
WHERE rownumber <= 10
ROW_NUMBER может быть недетерминированным: если key не уникален, каждый раз при выполнении
запроса возможно присвоение разных номеров строкам, у которых key совпадает. Когда key уникален, каждая
строка будет всегда получать уникальный номер строки.
оконная функция RANK()
Функция RANK() OVER работает почти так же, как ROW_NUMBER, но может вернуть более чем n строк при
определённых условиях. Например, для получения top-10 самых молодых людей:
SELECT * FROM (
SELECT
RANK() OVER (ORDER BY age ASC) AS ranking,
person_id,
person_name,
age
FROM person
) AS foo
WHERE ranking <= 10
Данный код может вернуть более чем 10 строк. Например, если есть два человека с одинаковым возрастом, он
вернёт 11 строк.
3
10.
Select (SQL)4
Нестандартный синтаксис
Не все СУБД поддерживают вышеуказанные оконные функции. При этом многие имеют нестандартный
синтаксис для решения тех же задач. Ниже представлены варианты простого ограничения выборки для
различных СУБД:
Производитель/СУБД
Синтаксис ограничения
DB2
(Поддерживает стандарт, начиная с DB2 Version 6)
Firebird
SELECT FIRST 10 * FROM T
Informix
SELECT FIRST 10 * FROM T
Interbase
SELECT * FROM T ROWS 10
Microsoft
(Поддерживает стандарт, начиная с SQL Server 2005)
Также SELECT TOP 10 [PERCENT] * FROM T ORDER BY col
MySQL
SELECT * FROM T LIMIT 10
SQLite
SELECT * FROM T LIMIT 10
PostgreSQL
(Поддерживает стандарт, начиная с PostgreSQL 8.4)
SELECT * FROM T LIMIT 10
Oracle
(Поддерживает стандарт, начиная с Oracle8i)
Также SELECT * from T WHERE ROWNUM <= 10
См. также
11.
Join (SQL)Join (SQL)
JOIN - оператор языка SQL, позволяющий включить данные из нескольких таблиц. Входит в оператор FROM
и отдельно от него не используется.
Описание оператора
select field [,... n]
from MainTable
{inner | {left | right | full} outer | cross } join JoinTable on <condition>
В большинстве СУБД при указании слов left, right, full слово outer можно опустить. Слово INNER также в
большинстве СУБД можно опустить.
В общем случае СУБД проверяет условие condition, на соответствие в соединяемой таблице (JoinTable). Для
cross join условие не указывается.
Для cross join'a в некоторых реализациях SQL используется такой вид оператора:
select field [,... n]
from MainTable, JoinTable
или
select field [,... n]
from MainTable
from JoinTable
Виды оператора JOIN
Оператор JOIN может использоваться с различными опциями:
• inner join (по умолчанию)
• outer join
• left outer join
• right outer join
• full outer join
• cross join
Для пояснений будут использоваться следующие таблицы:
Люди, проживающие в городах (таблица Person)
1
12.
Join (SQL)2
Name
CityId
Андрей
1
Леонид
2
Сергей
1
Григорий 4
Города (таблица City)
Id
Name
1
Москва
2
Санкт-Петербург
3
Казань
INNER JOIN
Объединяет две таблицы, где каждая строка обеих таблиц в точности соответствует условию. Если для строки
одной таблицы не найдено соответствия в другой таблице, строка не включается в набор.
select *
from Person
inner join City on Person.CityId = City.Id
Person.Name Person.CityId City.Id
City.Name
Андрей
1
1
Москва
Леонид
2
2
Санкт-Петербург
Сергей
1
1
Москва
Выбор по первичному ключу и индексу положительно сказывается на скорости выборки.
OUTER JOIN
Присоединение таблицы с необязательным присутствием записи в таблице. Также как и в случае с inner join,
условие по индексированным полям и первичному ключу ускоряет все виды outer join'ов.
LEFT OUTER JOIN
К левой таблице присоединяются все записи из правой, соответствующие условию (по правилам inner join),
плюс все не вошедшие записи из левой таблицы, поля правой таблицы заполняются значениями NULL.
select *
from Person
left outer join City on Person.CityId = City.Id
13.
Join (SQL)3
Person.Name Person.CityId City.Id
City.Name
Андрей
1
1
Москва
Леонид
2
2
Санкт-Петербург
Сергей
1
1
Москва
Григорий
4
NULL
NULL
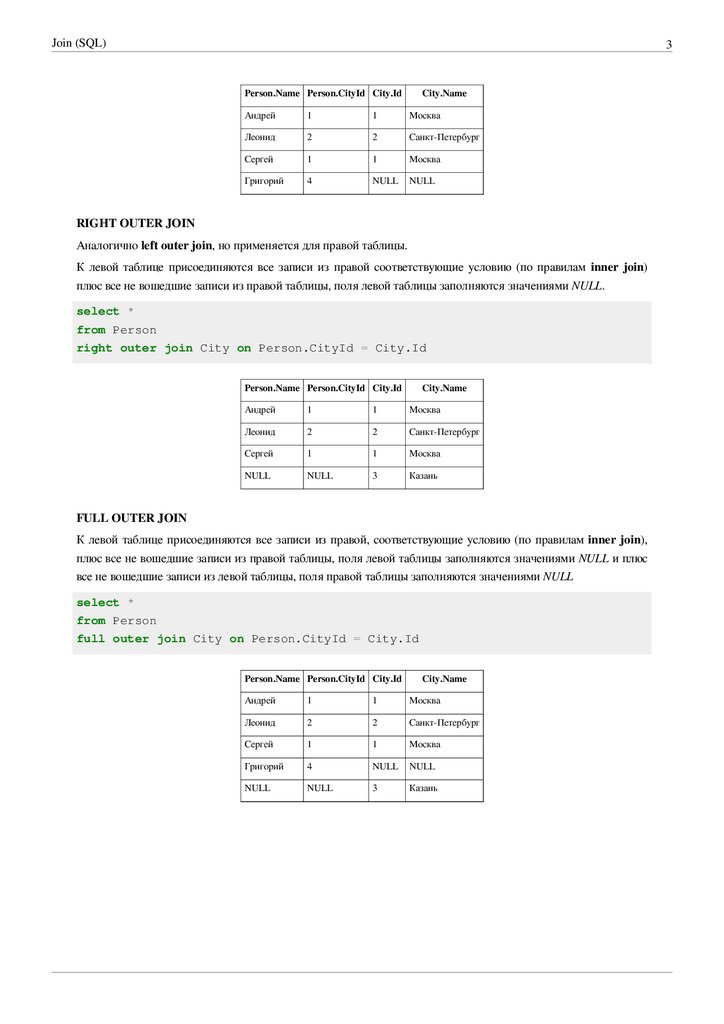
RIGHT OUTER JOIN
Аналогично left outer join, но применяется для правой таблицы.
К левой таблице присоединяются все записи из правой соответствующие условию (по правилам inner join)
плюс все не вошедшие записи из правой таблицы, поля левой таблицы заполняются значениями NULL.
select *
from Person
right outer join City on Person.CityId = City.Id
Person.Name Person.CityId City.Id
City.Name
Андрей
1
1
Москва
Леонид
2
2
Санкт-Петербург
Сергей
1
1
Москва
NULL
NULL
3
Казань
FULL OUTER JOIN
К левой таблице присоединяются все записи из правой, соответствующие условию (по правилам inner join),
плюс все не вошедшие записи из правой таблицы, поля левой таблицы заполняются значениями NULL и плюс
все не вошедшие записи из левой таблицы, поля правой таблицы заполняются значениями NULL
select *
from Person
full outer join City on Person.CityId = City.Id
Person.Name Person.CityId City.Id
City.Name
Андрей
1
1
Москва
Леонид
2
2
Санкт-Петербург
Сергей
1
1
Москва
Григорий
4
NULL
NULL
NULL
NULL
3
Казань
14.
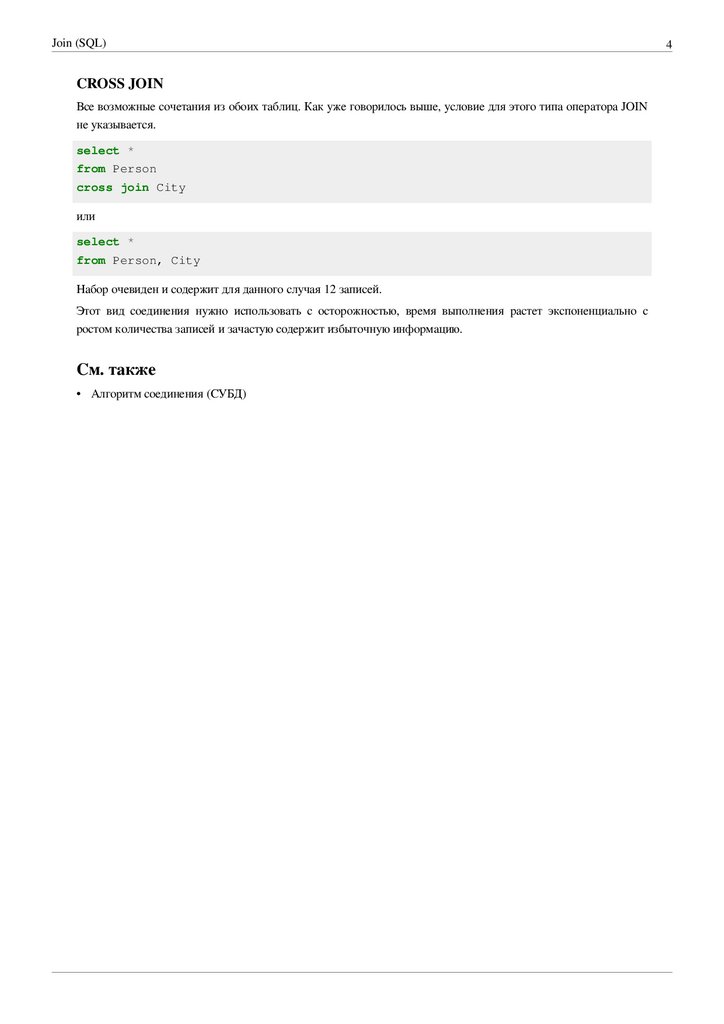
Join (SQL)CROSS JOIN
Все возможные сочетания из обоих таблиц. Как уже говорилось выше, условие для этого типа оператора JOIN
не указывается.
select *
from Person
cross join City
или
select *
from Person, City
Набор очевиден и содержит для данного случая 12 записей.
Этот вид соединения нужно использовать с осторожностью, время выполнения растет экспоненциально с
ростом количества записей и зачастую содержит избыточную информацию.
См. также
• Алгоритм соединения (СУБД)
4
15.
Insert (SQL)Insert (SQL)
INSERT — оператор языка SQL который позволяет добавить строки в таблицу, заполняя их значениями.
Значения можно вставлять перечислением с помощью слова values и перечислив их в круглых скобках через
запятую или оператором select.
Примеры использования
Используя перечисление значений, с указанием столбцов:
insert into <название таблицы> ([<Имя столбца>, ... ]) values (<Значение>,...)
Используя перечисление значений, без указания столбцов:
insert into <название таблицы> values (<Значение>,...)
Используя select:
insert into <название таблицы> select <имя столбца>,... from <название таблицы>
В последнем случае, в таблицу может вставиться более одной записи. Если в таблице есть другие поля
требующие заполнения, но не указанные в операторе insert, для них будет установлено значение по
умолчанию, либо null, если значение по умолчанию не указано.
Особенности
Во время выполнения оператора могут возникнуть ошибки:
• если при создании таблицы для поля был указан параметр not null и не было определено значение по
умолчанию (см. create), то при отсутствии для него вставляемого значения возникнет ошибка. Решение
очевидно:
• либо убрать параметр not null
• либо указать значение по умолчанию
• либо вставить значение
• если произойдет попытка вставки в поле с типом identity (автоинкремент), то также произойдет ошибка.
Решить проблему можно двумя способами:
• не вставлять значение в это поле
• указать опцию identity_insert on после чего вставить уникальное значение для этого столбца
Опция identity_insert
Включить опцию:
set identity_insert on
После включения этой опции можно вставлять значения в поля определенные как identity. Нужно учесть, что
значение должно быть уникальным. Включать эту опцию не рекомендуется, её следует использовать в записях
в которых нужно сменить некоторые столбцы, не поменяв её identity столбец (например если по этому столбцу
подцепляется другая таблица)
1
16.
Insert (SQL)См. также
• Инъекция SQL
• UPDATE
2
17.
Update (SQL)Update (SQL)
UPDATE — оператор языка SQL, позволяющий обновить значения в заданных столбцах таблицы.
Общий вид команды:
update [top(x)] <объект>
set <присваивание1 [, присваивание2, ...]>
[where <условие>]
[option <хинт1 [, хинт2, ...]>]
• top(x) — команда выполнится только х раз
• <объект> — объект, над которым выполняется действие (таблица или представление(views))
• <присваивание> — присваивание, которое будет выполняться при каждом выполнении условия <условие>,
или для каждой записи, если отсутствует раздел where
• <условие> — условие выполнения команды
• <хинт> — инструкция программе как исполнить запрос
Пример:
update top(10) tbl_books set price = 0 where quantity = 0
option (force group, hash join, force order)
UPDATE Persons SET Address='Nissestien 67', City='Sandnes'
WHERE LastName='Tjessem' AND FirstName='Jakob'
См. также
• Инъекция SQL
• INSERT
1
18.
Delete (SQL)Delete (SQL)
Delete — в языках, подобных SQL, DML-операция удаления записей из таблицы. Критерий отбора записей
для удаления определяется выражением where. В случае, если критерий отбора не определён, выполняется
удаление всех записей.
• В СУБД, поддерживающих триггеры, операция Delete может вызывать их срабатывание;
• При наличии на таблице внешних ключей все дочерние к удаляемым записи в подчинённых таблицах также
должны быть удалены для обеспечения ссылочной целостности;
• В СУБД, поддерживающих транзакции, выполнение операции Delete должно быть подтверждено
(COMMIT), либо опровергнуто (ROLLBACK) вызовом соответствующих операций.
Синтаксис
Общий синтаксис команды:
DELETE FROM <Имя Таблицы> WHERE <Условие отбора записей>
Последствием выполнения такой команды будет удаление тех строк из таблицы <Имя Таблицы>, которые
соответствуют условию <Условие отбора записей>. При этом никакого результата команда не
возвращает и, следовательно, не может быть использована в качестве параметра в команде SELECT.
Связанные команды
Удаление всех записей из таблицы при наличии внешних ключей и механизме транзакций может занять
продолжительное время. Для полной очистки таблицы может быть использована операция TRUNCATE.
1