






















































































 Базы данных
Базы данныхПохожие презентации:


")







Greenplum. Part 1
1.
GreenplumPA R T 1
2.
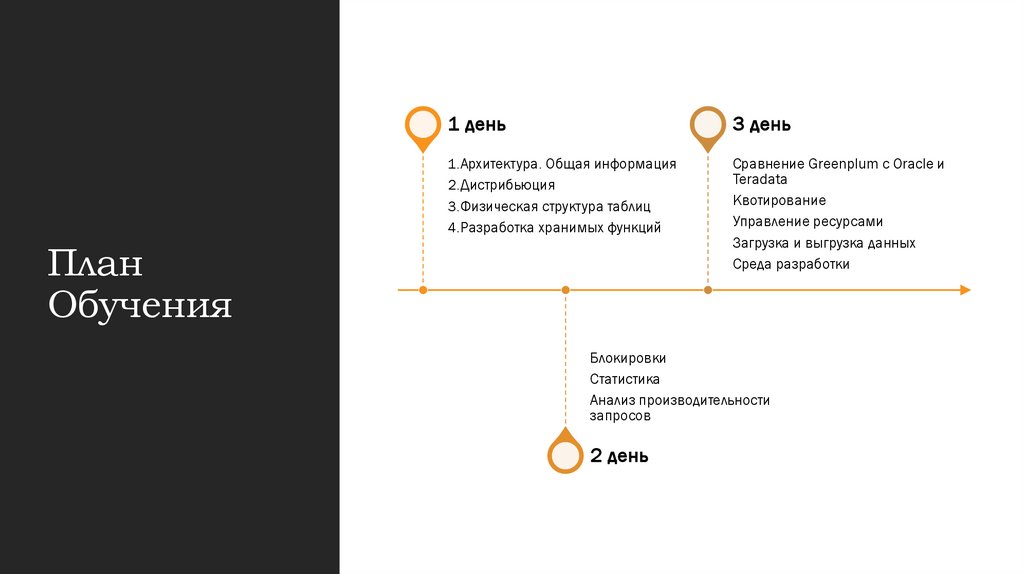
1 день3 день
1.Архитектура. Общая информация
2.Дистрибьюция
3.Физическая структура таблиц
4.Разработка хранимых функций
Сравнение Greenplum с Oracle и
Teradata
Квотирование
Управление ресурсами
Загрузка и выгрузка данных
Среда разработки
План
Обучения
Блокировки
Статистика
Анализ производительности
запросов
2 день
3.
1. Введение.2. Архитектура. Общая информация
3. Дистрибьюция
День 1
4. Физическая структура таблиц
a. Типы таблиц
b. Ориентация данных в таблицах
c. Компрессия
5. Партицирование
6. Общие рекомендации по структуре данных
7. Разработка хранимых функций
4.
1. Введение5.
GreenplumОpen-source MPP ( massively parallel processing,
массивно-параллельные вычисления) СУБД ,
обеспечивающая параллельность выполняемых
запросов с shared nothing (без разделения ресурсов)
архитектурой. В основе лежит Postgres.
Предназначена для хранения и обработки больших
объемов данных – от единиц до сотен терабайт данных.
Хорошо подходит под построение корпоративных
хранилищ данных, аналитику и Machine Learning задач.
6.
ХарактеристикиGreenplum
Параллельная обработка данных
Предназначена для больших
объемов данных
Shared-nothing
Линейная масштабируемость
Отказоустойчивость
ACID
Полиморфное хранение данных
Open source
Не подходит под OLTP нагрузку
Старая версия Postgres (самая
свежая на 2022 год версия
Greenplum (v6) содержит
Postgres v9.4)
7.
2. Архитектура.Общая
информация
8.
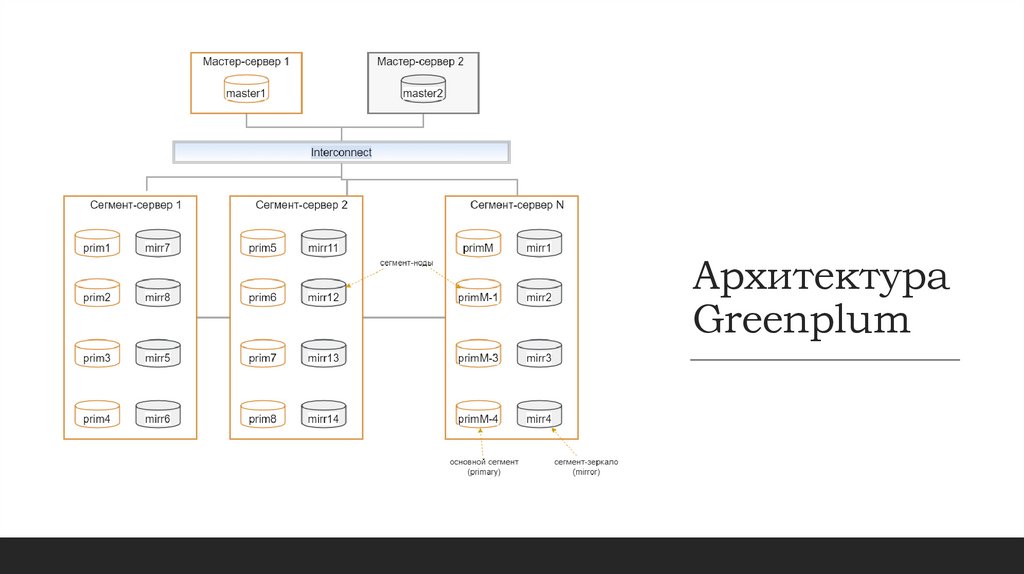
АрхитектураGreenplum
9.
Архитектура GreenplumGreenplum хранит и обрабатывает большие объемы данных, распределяя данные и нагрузку на все сервера в
кластере. Логически база данных Greenplum представляет собой массив отдельных инстансов баз
данных PostgreSQL, расположенных на серверах кластера.
Мастер (инстанс PostgreSQL, расположенный на мастер-сервере) координирует рабочую нагрузку на другие
инстансы (сегменты), расположенные на серверах-сегментах, которые занимаются обработкой и
хранением данных.
Сегменты (сегмент-ноды - инстансы PostgreSQL, расположенные на сегмент-сервере) обмениваются
данными друг с другом и с мастером через интерконнект при помощи одной или нескольких сетей.
Зеркалирование - каждый основной сегмент в кластере может иметь сегмент-зеркало, постоянно
синхронизированный со своим основным сегментом и расположенный на другом сегмент-сервере(сегментхост). Сегмент-зеркало хранит те же самые данные, что и его парный основной, и автоматически
включается в работу в случае, если основной сегмент по какой-то причине работать не может.
Мастер также зеркалируется в виде отдельной бд на выделенном сервере. Но при падении потребуется
ручное переключение
10.
Архитектура
Greenplum
Мастер-нода:
Точка входа для всех пользовательских запросов
Построение плана запроса и координация распределения
данных
Агрегация данных из сегмент-нод
Содержит системные каталоги
Сегмент-ноды:
Хранение данных
Обработка данных
Интерконнект:
Сетевой слой с быстрым соединением (от 10 Gbit)
11.
Как посмотреть конфигурациюкластера?
pg_catalog.gp_segment_configuration
Атрибут
Описание
dbid
Уникальный идентификатор сегмента
content
Идентификтатор содержания сегмента.Праймери и миррор будут иметь одинаковый
content. Для матсетра он всегда равен -1.
role
Текущая роль сегмента (p =primary, m =mirror)
preferred_role
Первоначальная(оригинальная) роль сегмента
mode
Статус синхронизированности с зеркалом. s (Синхронизирован) или n (не
синхронизирован).
status
Статус работоспособности сегмента (u =up, d = down)
hostname
Hostname сегмент-хоста
address
Внутреннее название сервера, используещеся для доступа к сегментам
datadir
Адрес директории сегмент-хоста, в которой находится данные сегмента
12.
Вопросы попройденной теме
1. Когда пользователь обращается к Greenplum с
запросом, на какую компоненту кластера происходит
коннект?
2. В какой компоненте кластера хранятся данные таблиц?
3. В чем отличие сегмент-сервера от сегмент-ноды?
4. Как участвует в работе кластера второй мастер?
13.
Задание 1Зайти в базу, посмотреть:
1. Количество хостов в кластере
2. Количество сегмент-хостов
Практика
3. Количество сегмент-нод
4. Есть ли ноды, которые сейчас "лежат"(не
в рабочем состоянии)?
5. На сколько частей будут распределены
данные, хранящиеся в текущем
кластере?
14.
1) количество хостов в кластереselect count(distinct hostname) from gp_segment_configuration
-- 3
2) количество сегмент-хостов
select count(distinct hostname) from gp_segment_configuration
where content >= 0
--2
3) количество сегмент -нод
Ответы
select count(dbid) from gp_segment_configuration
where content >= 0
-- 12
4) количество нод, которые сейчас "лежат"(не в рабочем состоянии)?
select count(dbid) from gp_segment_configuration
where status = 'd
--6
5) на сколько частей будут распределены данные, хранящиеся в текущем кластере?
select count(dbid) from gp_segment_configuration
where content >= 0
and role = 'p’
--6
15.
3. Дистрибьюция16.
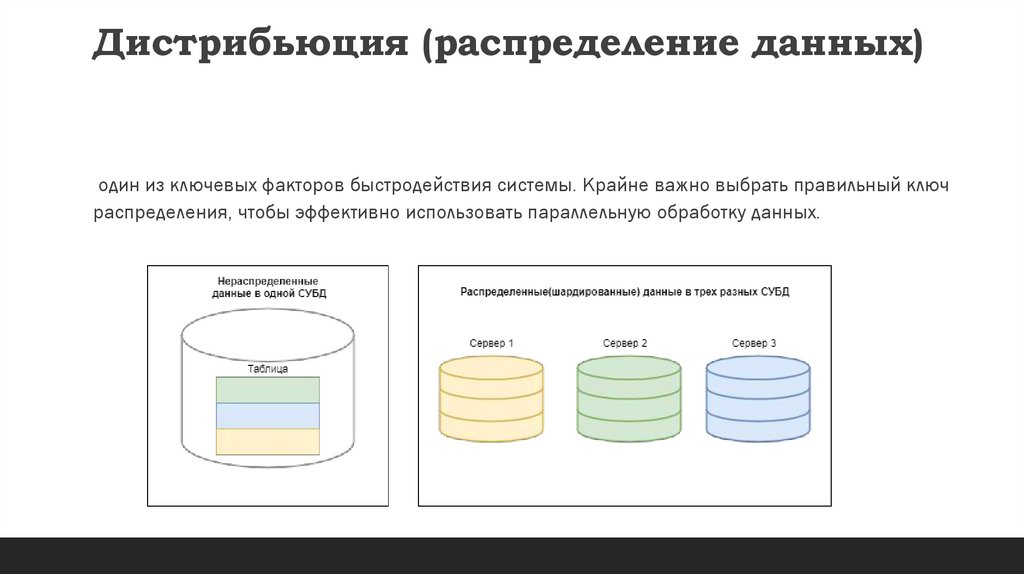
Дистрибьюция (распределение данных)один из ключевых факторов быстродействия системы. Крайне важно выбрать правильный ключ
распределения, чтобы эффективно использовать параллельную обработку данных.
17.
DISTRIBUTED BY (column)Предпочтительный вид дистрибьюции. Для распределения по сегментнодам используется хэш над заданным полем
Виды
дистрибьюции
DISTRIBUTED REPLICATED
Содержимое таблицы тиражируется на каждую сегмент-ноду.
Используется для небольших таблиц-словарей
DISTRIBUTED RANDOMLY
Приблизительно равномерно распределяет данные между сегментами
(по принципу round-robin), но исключает локальность джойнов в
дальнейшем. Используется в редких случаях для таблиц, где не подходит
никакой ключ распределения или ключ состоял бы из всех полей таблиц
18.
Равномерное распределение данных междусегментами
Greenplum работает со скоростью самого
медленного сегмента, поэтому важно свести к
минимуму перекосы (skew) в количестве данных
между сегментами
На что влияет
ключ
распределения
Локальность операций
Если операции выполняются локально на
сегментах (операции над таблицами с равным
ключом распределения), то получаем
существенное ускорение их исполнения, так как
каждый сегмент самостоятельно исполняет
запрос и не происходит пересылки данных по
сети
19.
Правила при выбореключа дистрибьюции
Факторы, влияющие на равномерное распределение данных
Выбирать атрибут с хорошей селективностью (большое количество
уникальных значений - как правило, это id)
Если селективность низкая, то велика вероятность неравномерного
распределения данных – одинаковые значения будут лежать на одном
сегменте
В ключе не должно быть null или значений по умолчанию
Иначе все null (или другие дефолтные значения) будут попадать на один
сегмент
20.
Правила при выбореключа дистрибьюции
Факторы, влияющие на локальность обработки
Ключи распределения используется в условиях join , group by, window
partition. В данном случае операции будут выполняться на каждом
сегменте локально.
Минимальное количество полей (лучше всегда один) в ключе
распределения. Если ключ состоит из нескольких полей, то локальные
операции по таблице будут при участии всех полей, входящих в ключ, и
ровно в таком же их порядке. Что, в свою очередь, минимизирует
вероятность локальных операций. Хэширование множества атрибутов
также замедляет процесс загрузки
Одинаковый тип данных у полей из ключа распределения в случае
соединения нескольких таблиц. Различные типы данных приводят к
различным хэш значениям => теряется локальность операций
21.
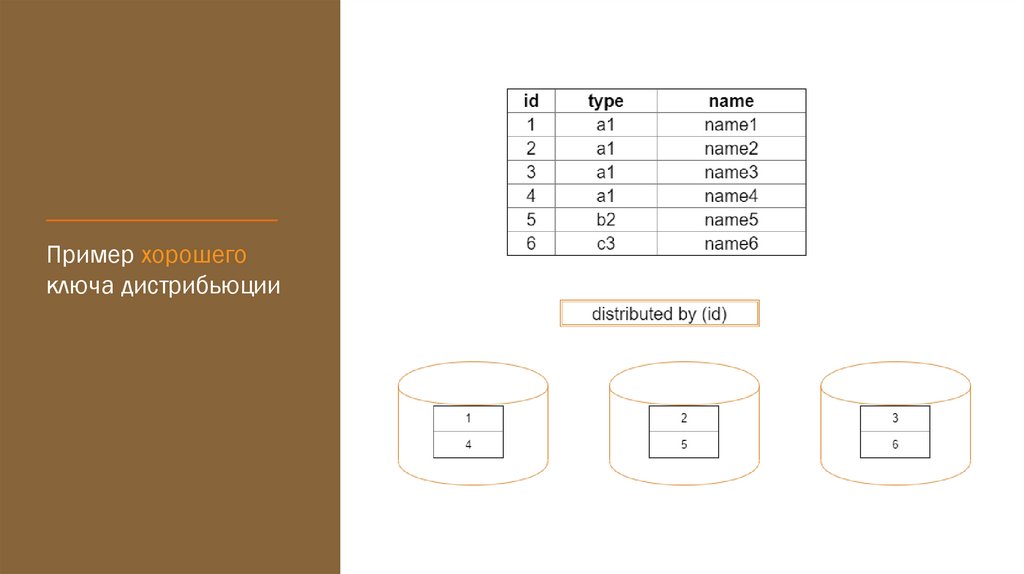
Пример хорошегоключа дистрибьюции
22.
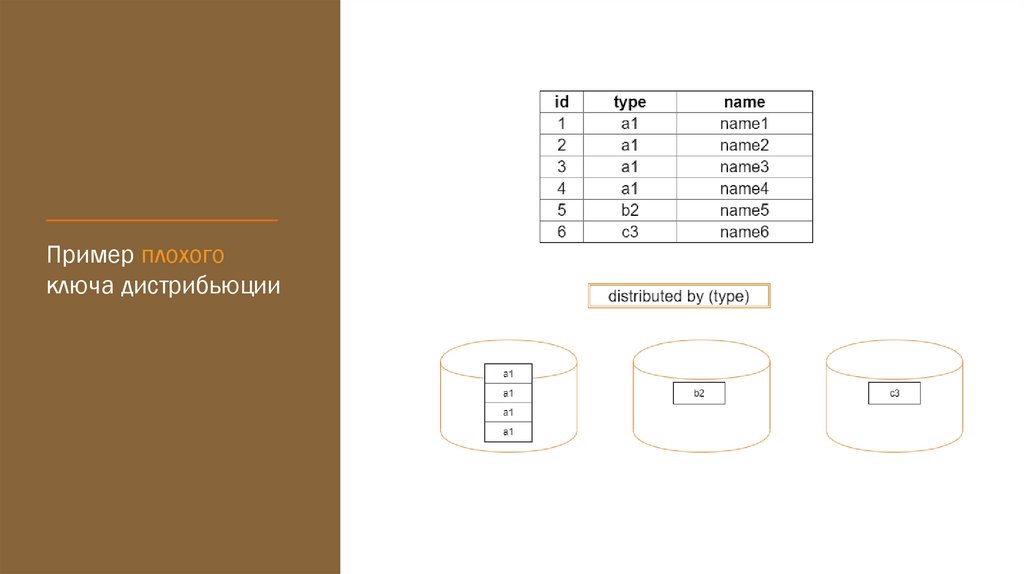
Пример плохогоключа дистрибьюции
23.
Советы привыборе ключа
дистрибьюции
24.
Советы при выборе ключадистрибьюции (1\2)
1.
Поля встречающиеся в where – плохой кандидат на
ключ распределения. Т.к. при фильтрации по ключу
дистрибьюции будут участвовать только часть сегментов
2.
Всегда явно указывать в DDL способ распределения,
иначе по умолчанию ключом дистрибьюции
назначается первый атрибут таблицы (или PK при его
существовании)
3.
Не забывать указывать способ распределения для
временных/промежуточных таблиц
25.
Советы при выборе ключадистрибьюции (2\2)
4.
Integer лучше чем String для ключа дистрибьюции – так как
хэш для integer вычисляется быстрее
5.
Date, timestamp- плохие кандидаты, так как по ним чаще
идет фильтрация. И хэш также вычисляется медленнее
6.
Небольшие(например, до 1000 строк) таблицысправочники прекрасно подходят для replicated
дистрибьюции
7.
При отсутствии полей с хорошим распределением (либо,
как правило, когда больше 2-3х полей в ключе) допустимо у
небольших таблиц выбирать randomly распределение.
Таким образом, будет как минимум
26.
Примеры создания таблиц с дистрибьюцией по ключу-- пример классического создания таблицы
create table test.test3_1 (
customer_id bigint,
customer_w4_sid character varying(100)
)
distributed by (customer_id);
-- пример создания таблицы через create as select
create table test.test3_2 as
select * from dds.transaction where proc_dt = '2019-10-01'
distributed by (transaction_id);
-- пример создания таблицы c дистрибьюцией по нескольким полям
create table test.test3_3
as
select * from dds.transaction where proc_dt = '2019-10-01'
distributed by (transaction_id, customer_id);
27.
Примеры создания таблиц с replicated и random дистрибьюцией-- пример создания таблицы с replicated дистрибьюцией
create table test.test_3_replicated (
operation_id int,
operation_name character varying(100)
)
distributed replicated;
-- пример создания таблицы с random дистрибьюцией
create table test.test_3_random (
operation_id int,
operation_name character varying(100)
)
distributed randomly;
28.
Выбирать атрибут с хорошей селективностью (большоеколичество уникальных значений - как правило, это id)
Атрибуты ключа распределения используются в join ,
group by, window partition
Один, максимум два атрибута в ключе распределения
В итоге:
В ключе не должно быть null или значений по
умолчанию
Для таблиц-справочников выбирать replicated
распределение
Стараться избегать randomly распределение
Всегда явно указывать способ распределения в DDL
Не забывать указывать способ распределения для
временных таблиц
Одинаковый тип данных в ключе распределения для
таблиц, участвующих в соединениях
29.
Как посмотреть ключдистрибьюции?
Функция pg_get_table_distributedby(oid)
select pg_get_table_distributedby(oid)
from pg_class
where relname = 'my_table'
select pg_get_table_distributedby('schema.my_table'::regclass::oid)
30.
Вопросы попройденной теме (1\2)
1. Какие 2 главные цели мы преследуем при выборе ключа
дистрибьюции?
2. Что лучше выбрать для ключа дистрибьюции, поле по которому
происходит джойн или по которому происходит партицирование?
3. Является ли номер строки хорошим
дистрибьюции, почему?
4.
претендентом для
Есть три подходящих на роль ПК поля с идентификатором, один
с типом string, другой c integer, третий – bigint. Какой лучше
выбрать в качестве ключа дыистрибьюции?
5. Как выбрать ключ дистрибьюции для незнакомой таблицы?
Зная ее DDL (create table)
31.
Вопросы попройденной теме (2\2)
7.
Таблица А: distributed by (a,b) , таблица С: distributed by
(b,a).
Будет ли локальной операция джойна
(on A.a=C.a and A.b=C.b)?
8. Таблица А: distributed by (a,b), таблица С: distributed by (a).
Будет ли локальной операция джойна (on A.a=C.a)?
9. Таблица А: distributed by (a), таблица С: distributed by (a).
Будет ли локальной операция джойна
(on A.a=C.a and A.b=C.b)?
32.
Задание 21. Какой ключ дистрибьюции у таблицы
public.test_distribution_2_1?
Практика
2. Создайте таблицу card_2_2, указав
дистрибьюцию. какой ключ
дистрибьюции выберете?
create table <your_schema>.card_2_2(/*
уникальные : card_id, card_hash, rownum – каждый
по отдельности является уникальным полем */
rownum bigint,
card_id bigint,
client_id varchar(10),
card_hash varchar(64),
card_type varchar(20),
status_cd varchar(10)
)
33.
Задание 23. Создайте таблицу card_2_3, не указав
дистрибьюцию. Что произойдет, будет ли
у таблицы ключ дистрибьюции ?
Практика
4. Создайте таблицу card_2_4 как
результат выборки ниже.Какой ключ
дистрибьюции выберете?
Select current_user as usr, card_id, status_cd
from card_2_2
34.
7. Таблица А: distributed by (a,b) , таблица С: distributed by (b,a).Будет ли локальной операция джойна
(on A.a=C.a and A.b=C.b)?
Нет, так как порядок у ключей разный
8. Таблица А: distributed by (a,b), таблица С: distributed by (a).
Будет ли локальной операция джойна (on A.a=C.a)?
Ответы
Нет, так как дистрибьюция по двум параметрам a,b не равна
дистрибьюции по одному
9. Таблица А: distributed by (a), таблица С: distributed by (a).
Будет ли локальной операция джойна
(on A.a=C.a and A.b=C.b)?
Да, дистрибьюция совпадает, а доп условие на равенство будет
проверяться уже локально
35.
1.Какой ключ дистрибьюции у таблицы public.test_distribution_2_1?
Select
pg_get_table_distributedby('public.test_distribution_2_1'::regcla
ss::oid)
--nspname
2.
Создайте таблицу card_2_2, указав дистрибьюцию. какой ключ дистрибьюции
выберете?
card_id
так как card_id лучше по типу данных(числовой) и по нему более вероятны джойны
Ответы
3.
Создайте таблицу card_2_3, не указав дистрибьюцию. Что произойдет, будет ли у
таблицы ключ дистрибьюции ?
автоматически выберется первая колонка rownum в качестве ключа
дистрибьюции (либо ПК при его физическом существовании) Если таблица будет
создана как create as select – то будет рандомная дистрибьюция
4.
Создайте таблицу card_2_4 как результат выборки ниже.Какой ключ
дистрибьюции выберете?
card_id – так как уже используется в оригинал таблице, логика
выбора такая же, как и в 2 пунке
36.
Какие ключи дистрибьюции выбрать?create table public.client_card(-- PK:
size
card_id bigint,
card_id (подходит также и client_card_hash),
400 GB
client_id varchar(10),
client_card_hash varchar(16),
client_card_type varchar(20),
status_cd varchar(10))
create table public.client( -- PK: client_id (подходит также client_passport_no), 200 GB size
client_id varchar(10),
client_passport_no bigint,
client_type bigint,
client_status_cd varchar(10));
create table public.transact( -- PK: transact_id, 20 TB size
transact_id bigint,
client_id varchar(10),
card_id bigint,
transact_amnt numeric(18,2),
client_card_hash varchar(16),
proc_dt date);
create table public.client_type( -- PK:
client_type bigint,
client_type_descr varchar(1000));
client_type,
1 MB size
37.
4. Физическаяструктура
таблиц
38.
4.1 Типытаблиц
39.
Таблицы пофизической
организации
Heap
стандартная физическая структура из postgres со
строковой ориентацией
Append-optimized tables (aot)
таблицы со специальной структурой, более компактные,
обладающие рядом спец. возможностей
40.
Возможности aot:appendoptimized
tables (aot)
•доступна колоночная структура
•доступна компрессия
•менее ресурсоемкие для больших
таблиц в обслуживании(сбор статистики
проходит заметно быстрее, занимают
меньше пространства)
Ограничения aot:
•не подходят для часто изменяемых
данных
•не подходят для единичных строковых
операций
41.
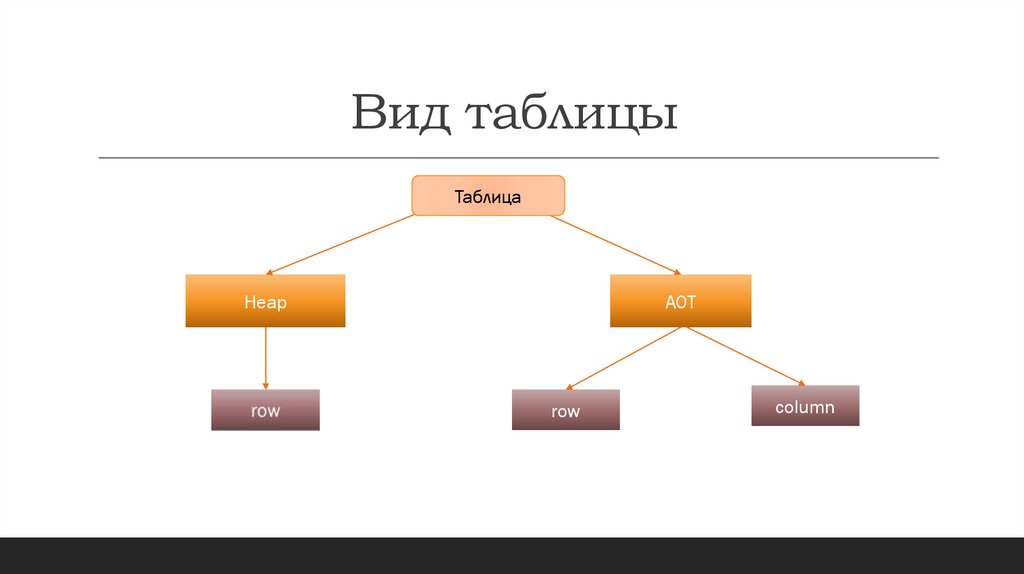
Вид таблицыТаблица
Heap
AOT
row
column
42.
Когда выбираем heap1.
Небольшой объем данных (зависит от кластера.
Например, менее 1 млн. строк или до 1Гб)
2.
Предполагаются частые изменения данных (update,
delete)
3.
Предполагаются построковые вставки, удаления и
обновления
43.
Когда выбираем АОТAot + row:
1.
Много данных (например, более 1 млн строк или >1 Гб)
2.
Создается однажды, далее превалируют операции выборки (select) и
добавления (insert) данных батчами
Aot + column:
1.
2.
3.
4.
Широкая таблица с множеством столбцов,при выборке используются
не все столбцы
Выполняются агрегирующие операции над небольшим количеством
столбцов
Имеются единичные столбцы, которые часто обновляются без
изменения остальных значений в строке
Хотим получить максимальную компрессию данных
При создании ad-hoc таблиц рекомендуется использовать append-optimized структуру
44.
Примеры создания aot таблиц-- пример классического создания aot таблицы
create table test.test4_1_1 (
customer_id bigint,
customer_w4_sid character varying(100)
) WITH (APPENDONLY=true )
distributed by (customer_id);
-- пример создания aot таблицы через create as select
create table test.test4_1_2 WITH (APPENDONLY=true ) as
select * from dds.transaction where proc_dt = '2019-10-01'
distributed by (transaction_id);
45.
Примеры создания heap таблиц-- пример классического создания heap таблицы
create table test.test4_1_3 (
customer_id bigint,
customer_w4_sid character varying(100)
) WITH (APPENDONLY = false )
distributed by (customer_id);
-- пример создания heap таблицы через create as select
create table test.test4_1_4 WITH (APPENDONLY = false ) as
select * from dds.transaction where proc_dt = '2019-10-01'
distributed by (transaction_id);
46.
Temporary таблицыВременные таблицы автоматически удаляются в
конце сессии или транзакции. При создании не
указываем схему – автоматически выбирается спец
пространство для временных таблиц
47.
Примеры-- пример удаления таблицы(drop) по окончанию сессии (поведение по умолчанию)
create temp table test4_1_5 (
customer_id bigint,
customer_w4_sid character varying(100)
) with (appendonly = true )
distributed by (customer_id);
-- пример удаления всей таблицы(drop) по окончанию транзакции
create temp table test4_1_6 (
customer_id bigint,
customer_w4_sid character varying(100)
) with (appendonly = true ) on commit drop
distributed by (customer_id);
-- пример удаления данных (delete) по окончанию транзакции
create temp table test4_1_7 (
customer_id bigint,
customer_w4_sid character varying(100)
) with (appendonly = true ) on commit delete rows
distributed by (customer_id);
48.
Unlogged таблицыНелогируемые таблицы быстрее обычных за счет
отказа записи операций в WAL(write ahead log).
Используются только в случаях, когда
сохранность(durability) не требуется. Например,
для промежуточных вычислений
49.
Пример-- пример unlogged таблицы, которая не будет удалена по окончанию сессии
create unlogged table test_4_1_unlogged (
customer_id bigint,
customer_w4_sid character varying(100)
) with (appendonly = true )
distributed by (customer_id);
50.
4.2Ориентация
данных в
таблицах
51.
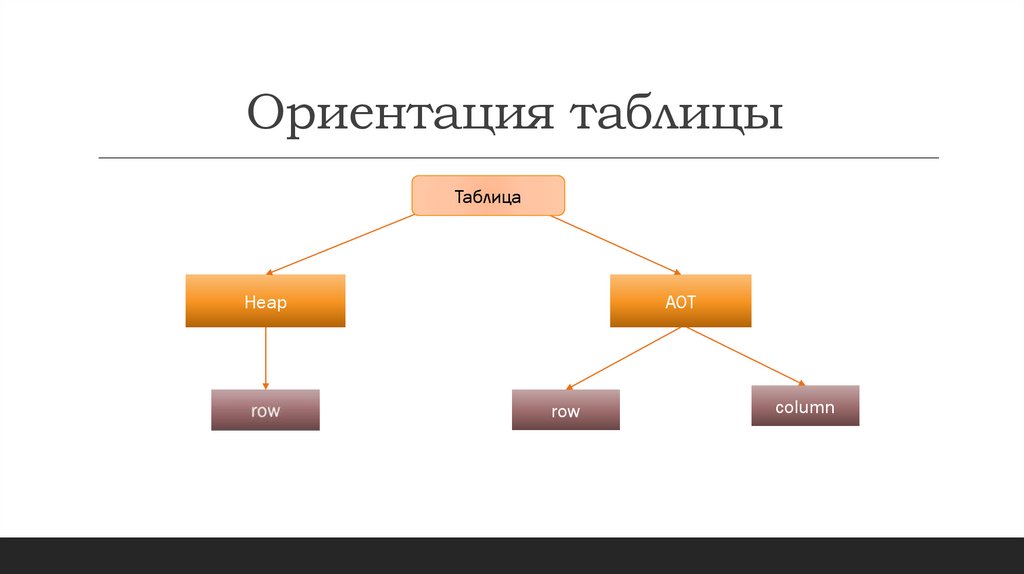
Ориентация таблицыТаблица
Heap
AOT
row
column
52.
Строковая структураРекомендуется :
При использование множества/большинства атрибутов таблицы
Для небольших таблиц
При частых обновлениях и вставках
Особенности:
Выгрузки, как правило, эффективнее делать из строковых таблиц
Доступны не все алгоритмы сжатия (не доступен RLE_TYPE). Применимо
только к AOT таблицам
Данные таблиц хранятся на сегменте в одном файле
53.
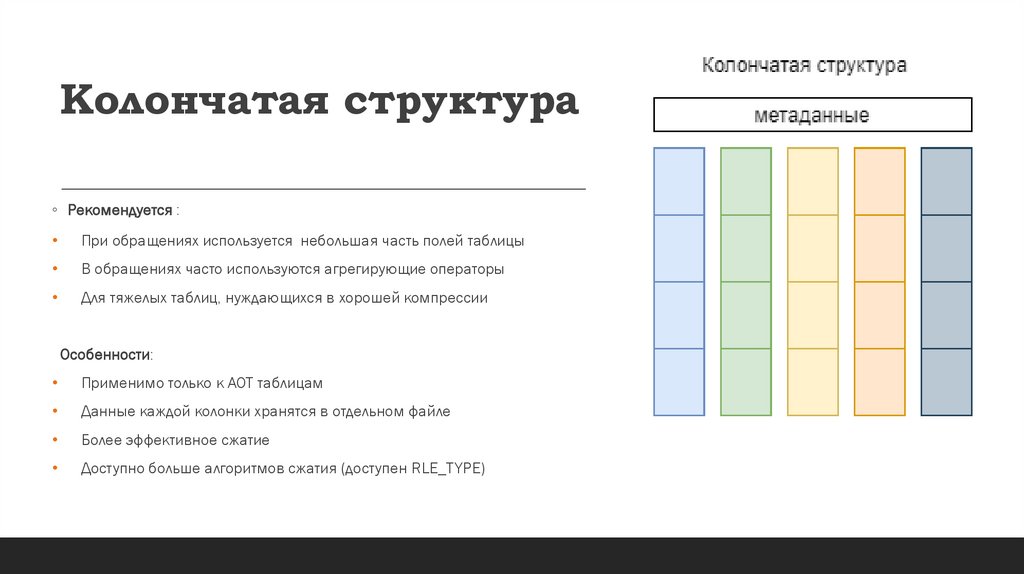
Колончатая структура◦ Рекомендуется :
При обращениях используется небольшая часть полей таблицы
В обращениях часто используются агрегирующие операторы
Для тяжелых таблиц, нуждающихся в хорошей компрессии
Особенности:
Применимо только к AOT таблицам
Данные каждой колонки хранятся в отдельном файле
Более эффективное сжатие
Доступно больше алгоритмов сжатия (доступен RLE_TYPE)
54.
Примеры создания row иcolumn таблиц
-- пример создания row таблицы
create table test.test4_2_1 (
customer_id bigint,
customer_w4_sid character varying(100)
) WITH (appendonly=true , orientation=row )
distributed by (customer_id);
-- пример создания column таблицы через create as select
create table test.test4_2_2 WITH (appendonly=true , orientation=column )
select * from dds.transaction where proc_dt = '2019-10-01'
distributed by (transaction_id);
as
55.
Как посмотреть тип таблицы?pg_catalog.pg_class
Атрибут
Описание
relname
Название таблицы/партиции
relnamespace
oid схемы (pg_namespace.oid )
relstorage
Тип физ. строения таблицы:
a= append-optimized,
c= column-oriented,
h = heap
relpersistence
Тип «долговечности» таблицы:
p = heap или append-optimized таблица,
u = unlogged таблица,
t = temporary таблица
56.
4.3Компрессия
57.
Плюсы:Меньше занимает дискового пространства
Быстрее чтение с диска
Минусы:
Компрессия
Требует дополнительно ресурсы CPU при обработке
Особенности:
Применимо только к AOT таблицам
Доступны различные типы: ZSTD, Quicklz, ZLIB, RLE
Можно управлять степенью сжатия
Возможна компрессия всей таблицы или выделенных
колонок
На разные колонки можно применять свои типы
компрессии
58.
Типы компрессииТип
компрессии
Особенности
Допустимый уровень
сжатия
QuickLZ
Быстрее работает, меньше CPU использует,
хуже уровень сжатия
1
ZLIB
Лучше сжимает, но ниже скорость, выше
утилизация CPU
1-9
При определенных условиях(низкая
кардинальность) лучше сжимает
1-4
Золотая середина – хорошо и быстро сжимает
1-19
RLE_TYPE
ZSTD
59.
Примеры таблиц с компрессиейzlib, quicklz
-- ZLIB
create table test.tab_4_3_zlib (
customer_id bigint,
customer_w4_sid character varying(100)
) WITH (appendonly=true , compresstype = zlib, compresslevel=5 )
distributed by
(customer_id);
-- QUICKLZ
create table test.tab_4_3_quicklz (
customer_id bigint,
customer_w4_sid character varying(100)
) WITH (appendonly=true , compresstype = quicklz)
distributed by
(customer_id);
60.
Примеры таблиц с компрессиейzstd, rle_type
-- RLE_TYPE
create table test.tab_4_3_rle (
customer_id bigint,
customer_w4_sid character varying(100)
) WITH (appendonly=true ,orientation=column,
distributed by
compresstype = rle_type, compresslevel = 1 )
(customer_id);
-- ZSTD
create table test.tab_4_3_quicklz (
customer_id bigint,
customer_w4_sid character varying(100)
) WITH (appendonly=true , compresstype = zstd, compresslevel = 1 )
distributed by
(customer_id);
61.
Примеры таблиц с компрессией поколонкам
--для колончатых таблиц возможно добавлять разный тип компрессии для колонок
create table test.tab_4_3_column_compress (
customer_id
bigint encoding (compresstype = zstd) ,
customer_type_id bigint encoding (compresstype = rle_type , compresslevel = 2 ) ,
customer_w4_sid character varying(100)
) WITH (appendonly=true , orientation=column)
distributed by
(customer_id);
62.
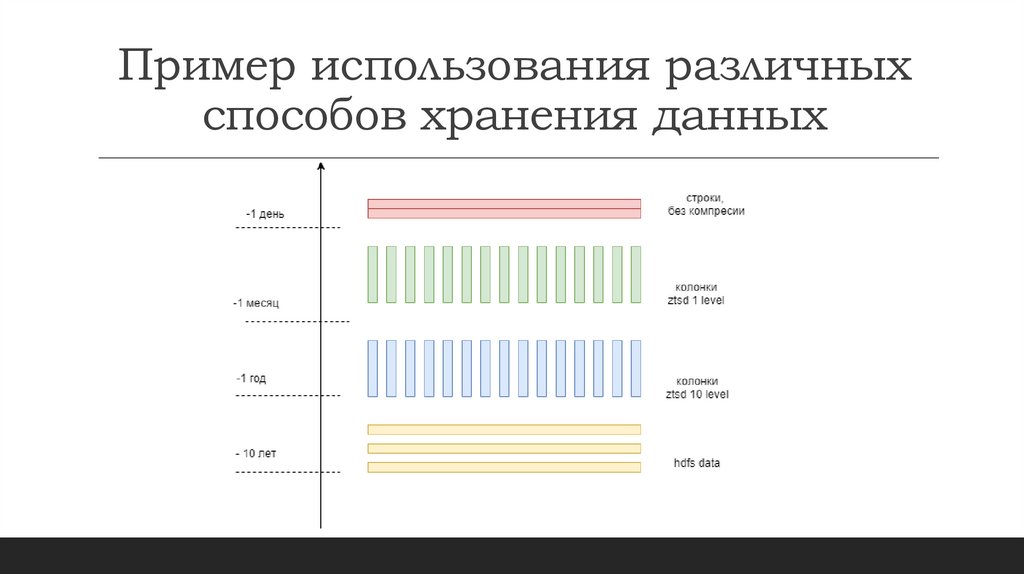
Пример использования различныхспособов хранения данных
63.
Как посмотреть компрессиютаблицы?
pg_catalog.pg_appendonly
Атрибут
Описание
relid
oid таблицы(pg_class.oid)
compresslevel
Уровень компрессии (1-19)
compresstype
Тип компрессии:
none (без компресии)
rle_type (run-length encoding компрессия)
zlib (gzip компрессия)
zstd (Zstandard компрессия)
quicklz
64.
Вопросы попройденной теме (1\2)
1.
Какую физ структуру (aot\heap) выбрать для тяжелой таблицы фактов?
2.
Какой тип компрессии можно использовать по умолчанию в большинстве
задач?
3.
Какую физ структуру (aot\heap) выбрать для небольшой таблицы в 100 строк?
4.
Если создать unlogged table, будет ли доступна данная таблица в новой
сессии?
5.
Какую физ. структуру выбрать для версионной таблицы со справочником
курсов валют?
6.
Можно ли создать колончатую heap таблицу?
7.
Можно ли для разных партиций одной таблицы выбирать свою физ. структуру?
65.
Вопросы попройденной теме (2\2)
8. Какую физ. структуру (aot\heap\
column\row\compression_type) следует выбрать для
таблицы размером 100 Гб, создающейся как
промежуточное приземление перед агрегацией?
9. Какую физ. структуру выбрать для таблицы со 100
атрибутами и размером в 5 Гб?
10.Стоит ли использовать RLE_TYPE компрессию для
колоночной таблицы в 200гб, если только 1 атрибут имеет
низкую селективность, а остальные 9 атрибутов близки к
уникальным?
66.
Задание 31. Создать row aot таблицу aot_3_1 c с таким
же атрибутным составом, как и у таблицы
card_2_2
2. Создать сolumn таблицу col_3_2 как селект
из таблицы aot_3_1
Практика
3. Создать heap таблицу heap_3_3 как дубль
таблицы pg_class
4. Cоздать temp таблицу temp_3_4
5. Cоздать unlogged таблицу unlog_3_5(такую
же как temp_3_4)
6. Cоздать обычную таблицу regular_3_6(такую
же как temp_3_4)
7. Создать таблицу с компрессией zstd
67.
Задание 3Практика
9. Создайте таблицу без указания физ
структуры, какие параметры физ
структуры у нее окажутся
(aot/heap/column/compression/level)?
68.
Ответы1.
Какую физ структуру (aot\heap) выбрать для тяжелой таблицы фактов?
Aot
2.
Какой тип компрессии можно использовать по умолчанию в
большинстве задач?
zstd 1 левел - так как это лучшее соотношение скорости и
эффективности
3.
Какую физ структуру (aot\heap) выбрать для небольшой таблицы в 100
строк?
Heap
4.
Если создать unlogged table, будет ли доступна данная таблица в новой
сессии?
Да, таблица сохранится до тех пор, пока не упадет сегмент или
произойдет остановка кластера
5.
Какую физ. структуру выбрать для версионной таблицы со
справочником курсов валют?
Можно ли создать колончатую heap таблицу? таблица часто изменяется
и небольшая - значит Heap
6.
Можно ли создать колончатую heap таблицу?
Нет
7.
Можно ли для разных партиций одной таблицы выбирать свою физ.
структуру?
Можно, так как каждая партиция по сути является отдельной таблицей
69.
9.Создайте таблицу без указания физ структуры, какие
параметры физ структуры у нее
будут(aot/heap/column/compression/level)?
Для базы можно задать ее дефотное состояние физ
структуры через настройку gp_default_storage_options
Ответы
select * from pg_settings where name =
'gp_default_storage_options’
appendonly=false,blocksize=32768,compressty
pe=none,checksum=true,orientation=row
select c.relname, case c.relstorage
when 'a' then 'aot'
when 'c' then 'column'
when 'h' then 'heap'
else c.relstorage::varchar end,
coalesce(a.compresstype, null, '') as compession_type, c.relpersistence
from pg_namespace n
left join pg_class c
on (n.oid = c.relnamespace and c.relname like 'test4_1_2%')
left join pg_appendonly a
on a.relid = c.oid
where n.nspname = 'test'
70.
5. Партиции71.
ПартицированиеБлагодаря MPP-архитектуре операция full scan в Greenplum выполняется наиболее эффективно,
соответственно можно использовать партиции бóльшего размера по сравнению с SMP базами.
Следует избегать создания большого количества партиций (до 1000)
Многоуровневое партицирование увеличивает кол-во итоговых сущностей (партиции*субпартиции) и
усложняет обработку , поэтому лучше его не использовать там, где это можно избежать
Размер партиции – от сотен мегабайт до десятков гигабайт (в зависимости от размера кластера)
Партиции автоматически не создаются для новых периодов
К партиции можно обращаться как к отдельной таблице и выполнять аналогичные операции.
Информация по партициям хранится в таблице pg_partitions
72.
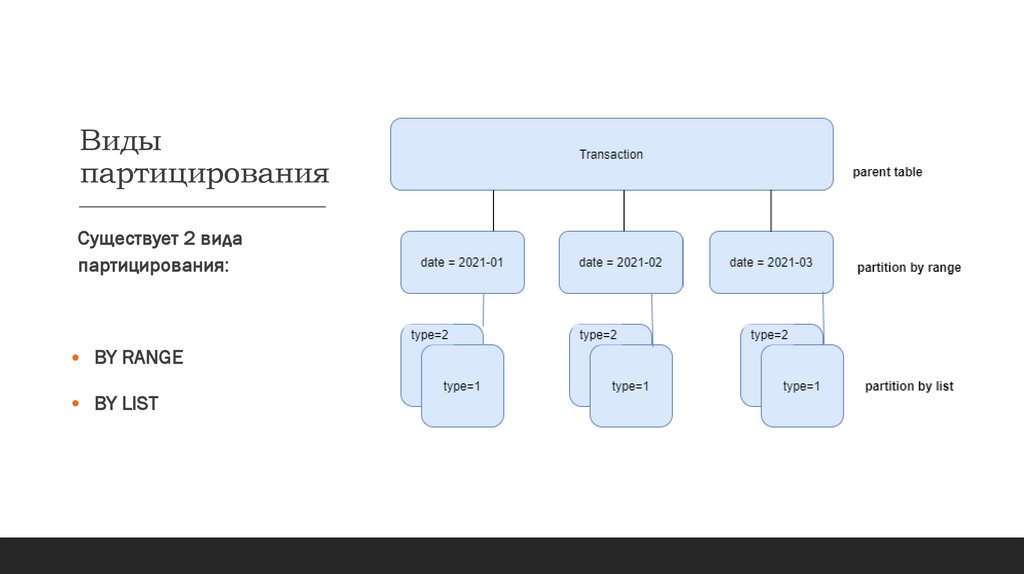
Видыпартицирования
Существует 2 вида
партицирования:
• BY RANGE
• BY LIST
73.
Пример создания rangeпартиций
-- PARTITION BY RANGE
create table test.test5_1
(
customer_id bigint,
registration_dt date
)
distributed by (customer_id)
PARTITION BY RANGE(registration_dt)
(
PARTITION do_2010_01_01 START (‘2000-01-01'::date) END ('2010-01-01'::date)
WITH (appendonly=true, orientation=column, compresstype=zstd)
START ('2010-01-01'::date) END ('2022-01-01'::date) EVERY ('1 day'::interval)
WITH (appendonly=true, orientation=column, compresstype= zstd)
);
74.
Пример создания list партиций-- PARTITION BY LIST
create table test.test_5_2_partition_by_list
(
schema_nm character varying(100)
table_nm character varying(100)
)
distributed by (report_from_dttm)
PARTITION BY LIST(table_nm)
(
PARTITION ts_tab1_prt_1 VALUES('table1'),
PARTITION ts_tab2_prt_2 VALUES('table2'),
PARTITION ts_tab3_prt_3 VALUES('table3'),
PARTITION ts_tab4_prt_4 VALUES('table4'),
DEFAULT PARTITION others
)
;
75.
Пример создания numeric rangeпартиций
-- partition by numeric range
CREATE TABLE test.test_5_3_partition_by_rank
(
id bigint,
year int
)
DISTRIBUTED BY (id)
PARTITION BY RANGE (year) (
START (2006) END (2016) EVERY (1),
DEFAULT PARTITION extra );
76.
Пример изменения партицийALTER TABLE sales ADD PARTITION
START (date '2017-02-01')
END (date '2017-03-01’);
ALTER TABLE sales DROP partition for ('2021-02-28'::date)
77.
Как посмотреть партицирование?pg_catalog.pg_partitions
Атрибут
Описание
schemaname
Схема таблицы
tablename
Название таблицы
partitionschemaname
Схема партиции
partitiontablename
Название партиции
parentpartitiontablename
Название родительской партиии, если она есть
partitiontype
Тип партиции (range или list)
partitionlevel
Уровень партиции
partitionrank
Для range партиций показывает последовательность внутри одного уровня
partitionrangestart
Для range партиций нижняя граница партиции
partitionrangeend
Для range партиций верхняя граница партиции
partitionisdefault
T если партиция дефолтная, иначе F.
78.
Вопросы попройденной теме
1. Какие типы партиций существуют?
2. Какое количество партиций считаем в среднем
максимумом для таблицы?
3. Если таблица весит 240 Гб, колоночная, 20 атрибутов,
12 партиций. Какой средний размер одного файла будет
храниться на сегменте (например, кластер состоит из 5
сегмент-серверов по 8 primary сегментов)?
4. Что произойдет, если в таблицу попробовать вставить
данные, для которых нет подходящей партиции?
79.
Задание 45. Какой тип партиции у таблицы
public.test_partition ?
Практика
6. На сколько частей(файлов) разделена
таблица ... (не забудь учесть кол-во
сегментов в кластере)
7. Создай таблицу part_4_4 с дневными
партициями на весь январь 2021 года
8. Добавь в part_4_4 партиции до конца
февраля 2021 года
80.
1. Какие типы партиций существуют?range, list
2. Какое количество партиций считаем в среднем
максимумом для таблицы?
1000
Ответы
3. Если таблица весит 240 Гб, колоночная, 20 атрибутов,
12 партиций. Какой средний размер одного файла будет
храниться на сегменте?
240*1024/20/12/(8*5) = 25 mb
4. Что произойдет, если в таблицу попробовать вставить
данные, для которых нет подходящей партиции?
запрос упадет (если нет партиции по умолчанию)
81.
5.Какой тип партиции у таблицы public.test_partition ?
select distinct partitiontype from
pg_catalog.pg_partitions where tablename =
'test_partition’
--range
6.
На сколько частей(файлов) разделена таблица ... (не
забудь учесть кол-во сегментов в кластере)
кол сегментов = 6, кол-во партиций = 144, таблица
строковая. получается 144*6 = 864
7.
Создай таблицу part_4_4 с дневными партициями на
весь январь 2021 года
Ответы
8.
create table part_4_4(id bigint, param text, dt date)
with (appendonly=true)
distributed by (id)
partition by range (dt)
( start ('2021-01-01'::date) end ('2021-02-01') every ('1 day'::interval)
);
Добавь в part_4_4 партиции до конца февраля 2021
года
alter table part_4_4
add partition start ('2021-02-01'::date) end ('2021-03-01')
82.
6. Общиерекомендации
по структуре
данных
83.
Факты/тяжелые таблицы храним в aot структуреИзмерения – в heap
Общие
рекомендации
по структуре
данных
Для тяжелых таблиц-измерений можно использовать
комбинированную структуру – редкоизменяемые
партиции в aot структуре, остальные - в heap
Широкие витрины лучше хранить в колончатой
структуре
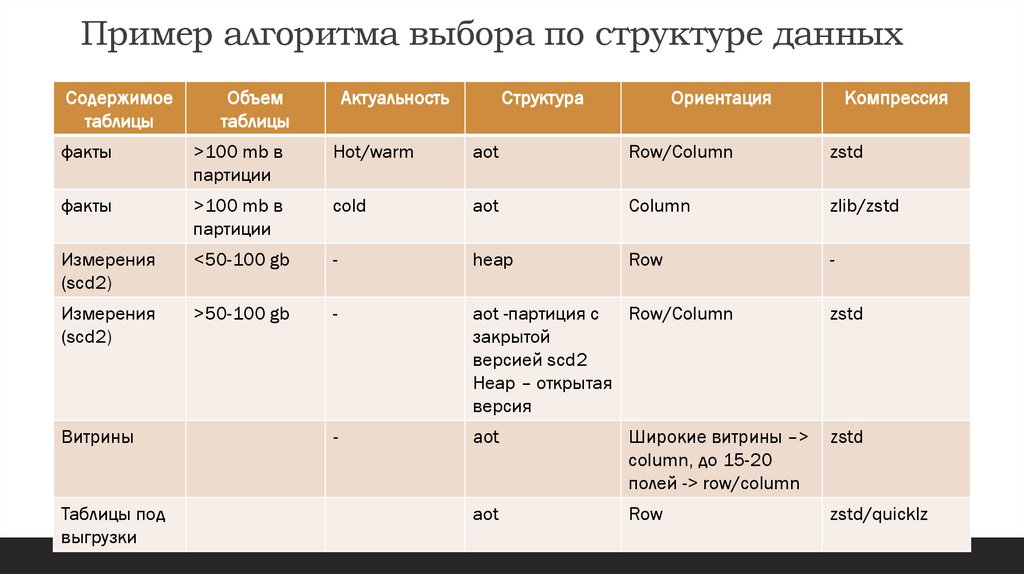
Таблицы, предназначенные для выгрузок – в
строковых
84.
Пример алгоритма выбора по структуре данныхСодержимое
таблицы
Объем
таблицы
Актуальность
Структура
Ориентация
Компрессия
факты
>100 mb в
партиции
Hot/warm
aot
Row/Column
zstd
факты
>100 mb в
партиции
cold
aot
Column
zlib/zstd
Измерения
(scd2)
<50-100 gb
-
heap
Row
-
Измерения
(scd2)
>50-100 gb
-
aot -партиция с
Row/Column
закрытой
версией scd2
Heap – открытая
версия
zstd
-
aot
Широкие витрины –>
сolumn, до 15-20
полей -> row/сolumn
zstd
aot
Row
zstd/quicklz
Витрины
Таблицы под
выгрузки
85.
7. Разработкахранимых
процедур
86.
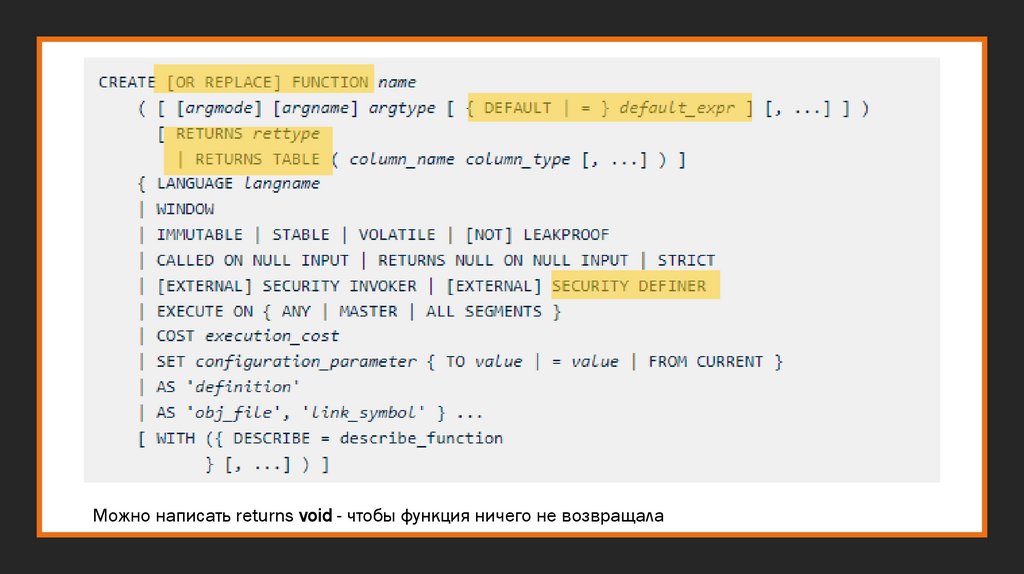
В Greenplum есть только функции, нет процедур(но функция может возвращать void)
Особенности
функций
Greenplum
Доступно обращение к параметрам как по
имени, так и позиционно : $1- первый параметр,
$2 –второй и тд
Существует несколько видов функций, с
различными языками. Язык (language) задается
при создании : sql, plpgsql, plpythonu и тд
Нет внутреннего коммита* (rollback, savepoint,
begin, commit). Все, что происходит в функции
является единой транзакцией.
87.
Можно написать returns void - чтобы функция ничего не возвращала88.
SQL функции-- создание «процедуры»
create or replace function public.clean_data()
returns void
as 'delete from test.test5_1 where registration_dt < current_date; '
language sql;
-- вызов «процедуры»
select public.clean_data();
create or replace function public.last_day(dt date)
returns date
language sql
immutable
as $$
select (date_trunc('month', $1::date) + interval '1 month' - interval '1 day')::date;
$$
;
89.
SQL функции, возвращающиеsets
-- создание функции
create or replace function public.get_data()
returns setof test.test5_1
as
$$
select * from test.test5_1 where registration_dt >= current_date;
$$
language sql;
-- вызов функции
select * from public.get_data()
name
|dt
|
--------|----------|
name1234|2020-02-02|
90.
Plpgsql функцииPlpgsql функции позволяют реализовывать внутри себя процедурные конструкции.
Становятся доступны:
• циклы
create or replace function test_func()
• вычислительные блоки begin end
returns <data_type>
• работа с динамическим кодом
as
• все доступные типы данных и пр.
$$
declare -- необязательный блок
…
begin
…
end
$$
language 'plpgsql';
91.
Анонимный блокdo $$
declare
r record;
l_view text;
begin
for r in select cl.relname,
n.nspname
from pg_class cl
inner join pg_namespace n
on n.oid = cl.relnamespace
where cl.relkind = 'v'
and n.nspname = 'public'
loop
l_view := r. nspname || '.' || r.relname ;
raise notice 'granted view: %', l_view ;
execute 'grant select on ' || l_view || ' to user123';
end loop;
end $$;
92.
Вызов динамического кодаdeclare
l_param int := 0;
begin
execute 'insert into table1(a) values (%)' using l_param;
end;
declare
l_param int := 0;
l_script text;
begin
l_script := 'insert into table1(a) values (' || l_param ||')' ;
execute l_script;
end;
93.
Perform и ExecuteЕсли функция ничего не возвращает (void) и у нее нет никаких динамических параметров – то
вызов можно сделать через perform
perform 'create table foo as (select 1)’;
Иначе – только execute
EXECUTE 'create table ' || some_var || '(a int)';
94.
Обработка исключений(Exceptions)
declare
begin
…
exception
when <condition> [ or <condition> ... ] then
<handler_statements>
[ when <condition> [ or <condition> ... ] then
<handler_statements> ... ]
end;
<condition> - может быть именованной ошибкой или ‘others’
<handler_statements> - одна или несколько инструкций
Список всех доступных кодов исключений здесь:
https://www.postgresql.org/docs/9.4/errcodes-appendix.html
95.
Пример обработки исключений идинамического вызова в функциях
do $$
declare
l_script text;
param1 int := 1;
param2 int := 0;
out_res int;
begin
l_script := 'select '||param1||'/'||param2;
execute l_script into out_res;
raise notice '%',out_res;
exception
when division_by_zero then
raise notice 'division_by_zero while executing l_script_join_results';--raise warning\error
when others then
raise notice 'error in executing l_script_join_results with errcode = %',sqlerrm ;
/*execute 'insert into test.logs_table ( d_schema_nm ,d_table_nm ,status_dttm)
values(
'''||data_f_source.schema_name||''',
'''||data_f_source.table_name||''',
timeofday()::timestamp);';*/
end;
$$
96.
Тип функцийТип Функции
Описание
Пример
immutable
Неизменяемая, для одних и тех Функция сложения:
же входных параметров всегда 2+2=4
тот же результат.
stable
В рамках sql стейтмента для
одних и тех же входных
параметров тот же результат
Volatile
(используется по умолчанию
при создании plpgsql функции)
Единственный тип, где
• Set_val()
возможно изменение данных в • Random()
БД. Результат при этом может
• Пользовательские функции
измениться внутри одного sql
над данными
блока
Current_timestamp()
97.
Примеры различных типовфункций
select id,
date_part('milliseconds', now()) as now, --stable
date_part('milliseconds',current_timestamp) as current_timestamp, --stable
date_part('milliseconds', timeofday()::timestamp ) as timeofday, --volatile
date_part('milliseconds', clock_timestamp()) as clock_timestamp --volatile
from generate_series(1,5) as id;
stable
volatile
Не изменяется
Изменяется
98.
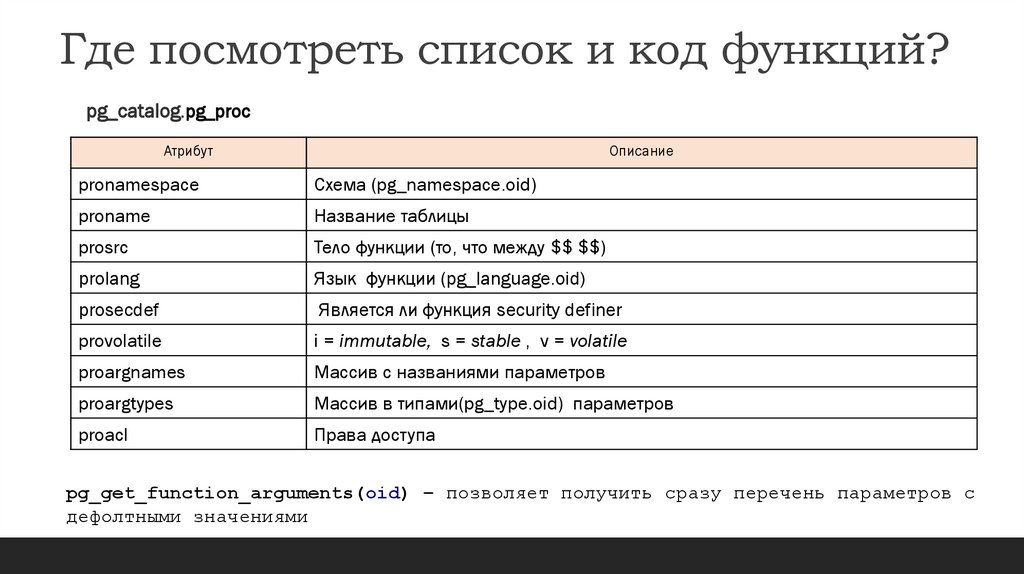
Где посмотреть список и код функций?pg_catalog.pg_proc
Атрибут
Описание
pronamespace
Схема (pg_namespace.oid)
proname
Название таблицы
prosrc
Тело функции (то, что между $$ $$)
prolang
Язык функции (pg_language.oid)
prosecdef
Является ли функция security definer
provolatile
i = immutable, s = stable , v = volatile
proargnames
Массив с названиями параметров
proargtypes
Массив в типами(pg_type.oid) параметров
proacl
Права доступа
pg_get_function_arguments(oid) – позволяет получить сразу перечень параметров с
дефолтными значениями
99.
Вопросы попройденной теме
1. В какой таблице можно посмотреть ddl функций?
2. Можно ли создать функцию, которая ничего не будет
возвращать?
3. Если требуется в логах записывать время операции
внутри транзакции(т е мы хотим получить разные
значения внутри транзакции), то какую функцию следует
использовать в данном случае?
100.
Задание 51. Создайте функцию proc_5_1, которая бы
вернула количество всех функций в
схеме public
Практика
2. Создайте функцию proc_5_2, которая
создаст таблицу tab_5_2, содержащую 2
атрибута: название схемы и текущее
время.Поместите туда все схемы(таким
образом, количество строк будет равно
кол-ву схем в текущей БД).
3. Создайте функцию proc_5_3, которая
будет возвращать результат деления
100 на входной параметр.
101.
1. В какой таблице можно посмотреть ddl функций?Pg_proc
2 Можно ли создать функцию, которая ничего не будет
возвращать?
Да, через void
Ответы
3. Если требуется в логах записывать время операции
внутри транзакции(т е мы хотим получить разные
значения внутри транзакции), то какую функцию следует
использовать в данном случае?
clock_timestamp (она volatile)
102.
1. Создайте функцию proc_5_1, которая бы вернула количество всех функций в схеме publiccreate function proc_5_1() returns bigint
as 'select count(1) from pg_proc where pronamespace = 2200'
language sql
2. Создайте функцию proc_5_2, которая создаст таблицу tab_5_2, содержащую 2 атрибута: название схемы
и текущее время.Поместите туда все схемы(таким образом, количество строк будет равно кол-ву схем в
текущей БД).
Ответы
create or replace function proc_5_2()
returns void
as $$
declare
begin
execute 'drop table if exists tab_5_2; create table tab_5_2 as select n.nspname ,
clock_timestamp()::timestamp(0) from pg_catalog.pg_namespace n';
end;
$$
language plpgsql
3. Создайте функцию proc_5_3, которая будет возвращать результат деления 100 на входной параметр.
create or replace function proc_5_3(in_param numeric)
returns numeric
as $$
declare
l_res numeric;
begin
l_res:= 100 / in_param;
return l_res;
exception
when others then
raise exception 'невозможно же делить на 0 !!';
--return 0;
end;
$$
language plpgsql