




























 Промышленность
Промышленность Базы данных
Базы данныхПохожие презентации:
")
")






")

Агрегатные функции, оконные функции. Лекция 9
1.
Лекция 9:Агрегатные функции,
оконные функции
2.
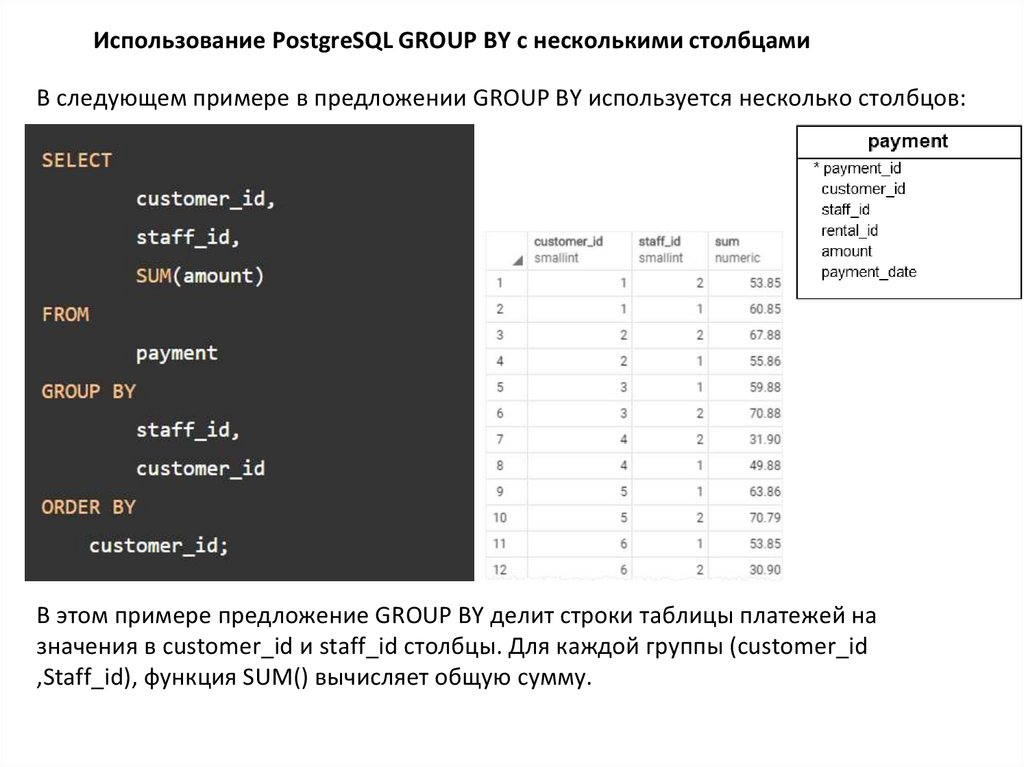
Использование PostgreSQL GROUP BY с несколькими столбцамиВ следующем примере в предложении GROUP BY используется несколько столбцов:
В этом примере предложение GROUP BY делит строки таблицы платежей на
значения в customer_id и staff_id столбцы. Для каждой группы (customer_id
,Staff_id), функция SUM() вычисляет общую сумму.
3.
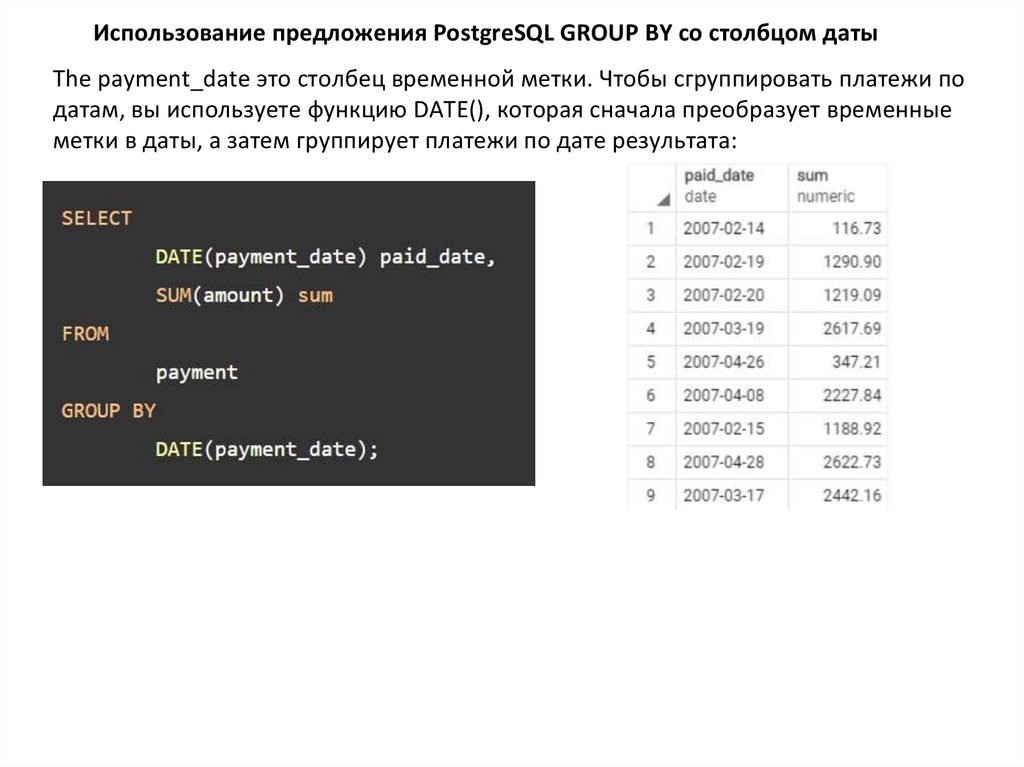
Использование предложения PostgreSQL GROUP BY со столбцом датыThe payment_date это столбец временной метки. Чтобы сгруппировать платежи по
датам, вы используете функцию DATE(), которая сначала преобразует временные
метки в даты, а затем группирует платежи по дате результата:
4.
Функция AVG() — одна из наиболее часто используемых агрегатных функций вPostgreSQL. Функция AVG() позволяет вычислить среднее значение набора.
Синтаксис функции AVG() следующий:
Вы можете использовать функцию AVG() в предложениях SELECT и HAVING.
Давайте рассмотрим несколько примеров использования функции AVG.
5.
Примеры функции PostgreSQLAVG()
Если вы хотите узнать среднюю сумму, которую заплатили клиенты, вы можете
применить функцию AVG к столбцу суммы, выполнив следующий запрос:
Чтобы сделать вывод более читабельным, вы можете использовать оператор
приведения следующим образом:
6.
Функция PostgreSQL AVG() с оператором DISTINCTЧтобы вычислить среднее значение различных значений в наборе, вы используете
опцию Different следующим образом:
Следующий запрос возвращает средний платеж, сделанный клиентами.
Поскольку мы используем DISTINCT, PostgreSQL принимает только уникальные
суммы и вычисляет среднее значение.
7.
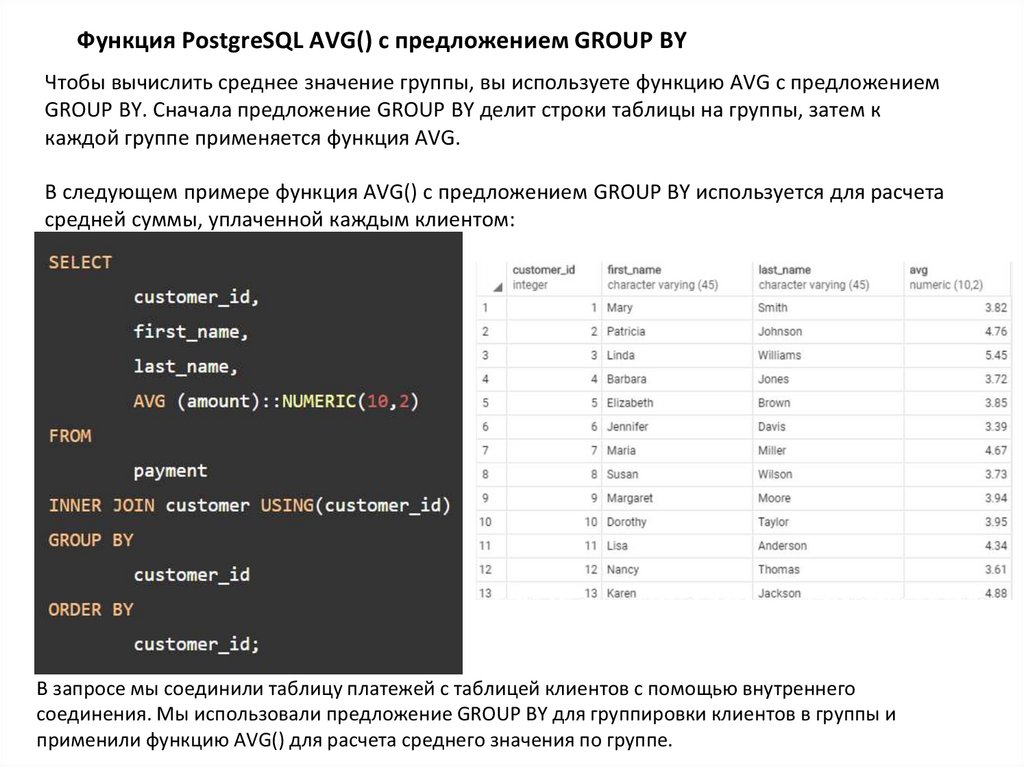
Функция PostgreSQL AVG() с предложением GROUP BYЧтобы вычислить среднее значение группы, вы используете функцию AVG с предложением
GROUP BY. Сначала предложение GROUP BY делит строки таблицы на группы, затем к
каждой группе применяется функция AVG.
В следующем примере функция AVG() с предложением GROUP BY используется для расчета
средней суммы, уплаченной каждым клиентом:
В запросе мы соединили таблицу платежей с таблицей клиентов с помощью внутреннего
соединения. Мы использовали предложение GROUP BY для группировки клиентов в группы и
применили функцию AVG() для расчета среднего значения по группе.
8.
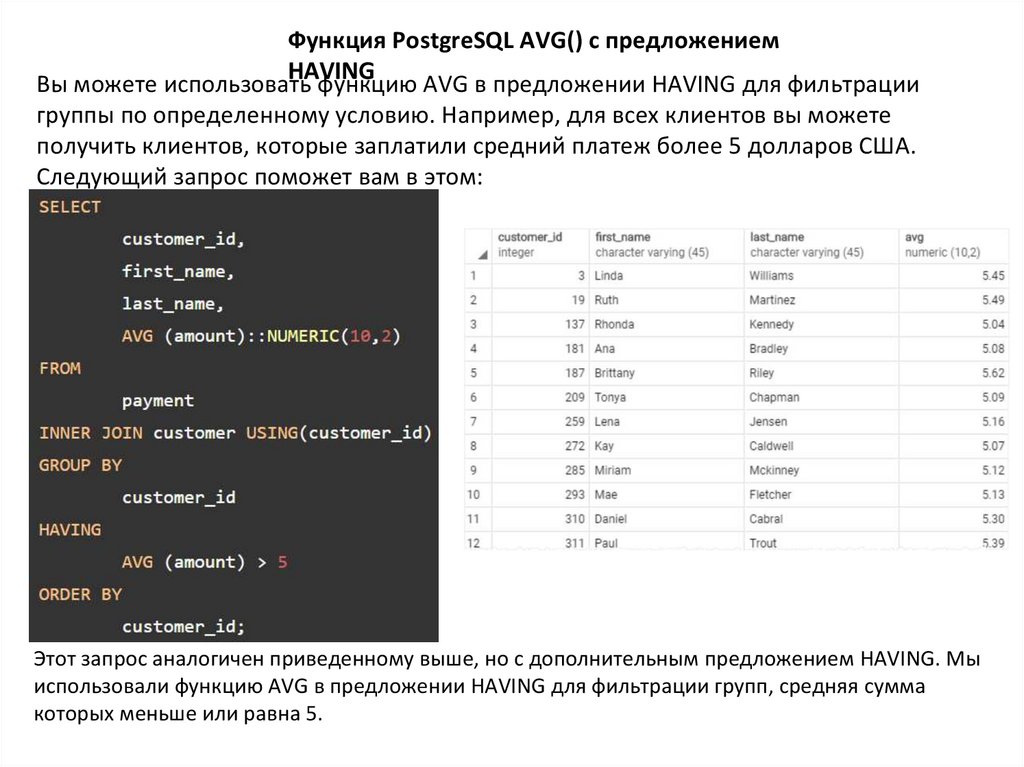
Функция PostgreSQL AVG() с предложениемHAVING
Вы можете использовать
функцию AVG в предложении HAVING для фильтрации
группы по определенному условию. Например, для всех клиентов вы можете
получить клиентов, которые заплатили средний платеж более 5 долларов США.
Следующий запрос поможет вам в этом:
Этот запрос аналогичен приведенному выше, но с дополнительным предложением HAVING. Мы
использовали функцию AVG в предложении HAVING для фильтрации групп, средняя сумма
которых меньше или равна 5.
9.
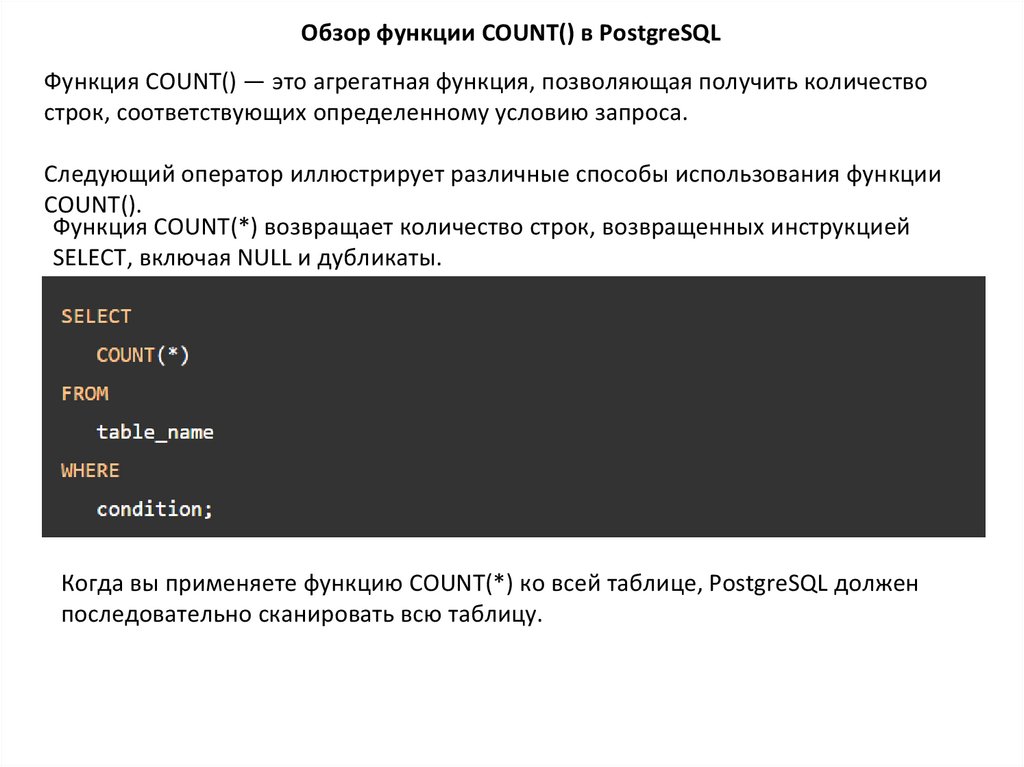
Обзор функции COUNT() в PostgreSQLФункция COUNT() — это агрегатная функция, позволяющая получить количество
строк, соответствующих определенному условию запроса.
Следующий оператор иллюстрирует различные способы использования функции
COUNT().
Функция COUNT(*) возвращает количество строк, возвращенных инструкцией
SELECT, включая NULL и дубликаты.
Когда вы применяете функцию COUNT(*) ко всей таблице, PostgreSQL должен
последовательно сканировать всю таблицу.
10.
Введение в функцию PostgreSQL SUM()PostgreSQL SUM() — это агрегатная функция, которая возвращает сумму значений
или различные значения.
Синтаксис функции СУММ() следующий:
Функция SUM() игнорирует NULL. Это означает, что SUM() не учитывает NULL при
расчете.
Если вы используете опцию DISTINCT, функция SUM() вычисляет сумму различных
значений.
Например, без опции DISTINCT функция SUM() для 1, 1, 8 и 2 вернет 12. Если опция
DISTINCT доступна, функция SUM() для 1, 1, 8 и 2 вернет 11 (1 + 8 + 2). Это
повторяющееся значение (1).
11.
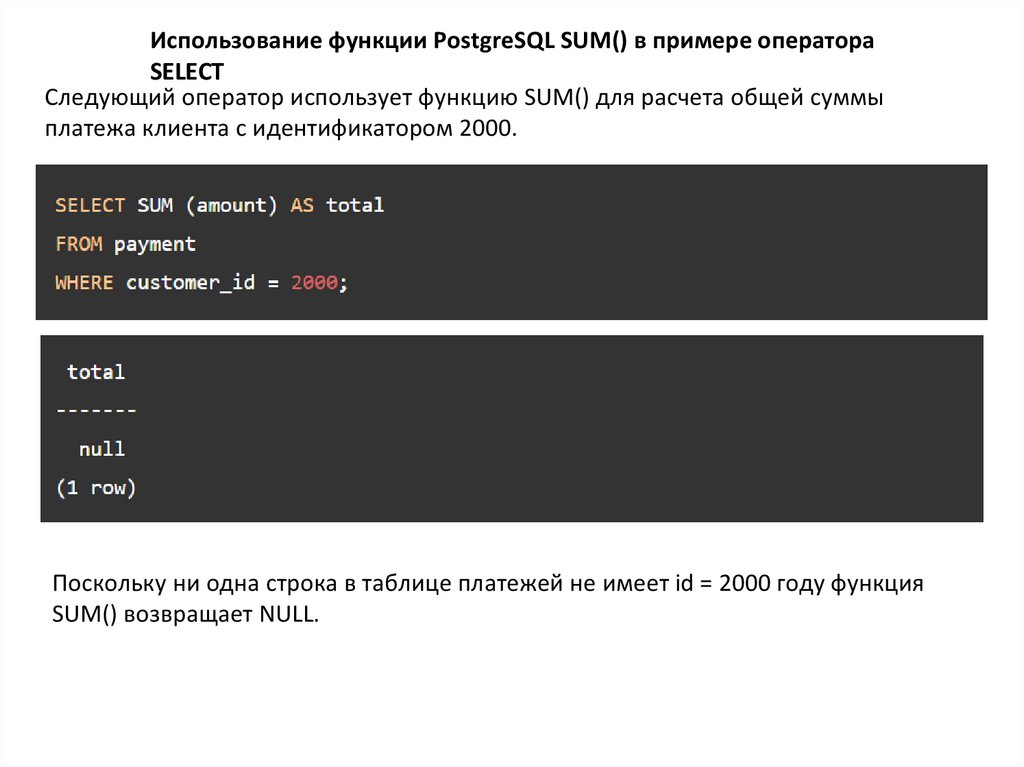
Использование функции PostgreSQL SUM() в примере оператораSELECT
Следующий оператор использует функцию SUM() для расчета общей суммы
платежа клиента с идентификатором 2000.
Поскольку ни одна строка в таблице платежей не имеет id = 2000 году функция
SUM() возвращает NULL.
12.
Введение в функцию PostgreSQL MAXФункция PostgreSQL MAX — это агрегатная функция, которая возвращает
максимальное значение в наборе значений. Функция MAX полезна во многих
случаях. Например, вы можете использовать функцию MAX, чтобы найти
сотрудников с самой высокой зарплатой или найти самые дорогие продукты и т. д.
Синтаксис функции МАКС следующий:
Вы можете использовать функцию MAX не только в предложении SELECT, но также
в предложениях WHERE и HAVING.
13.
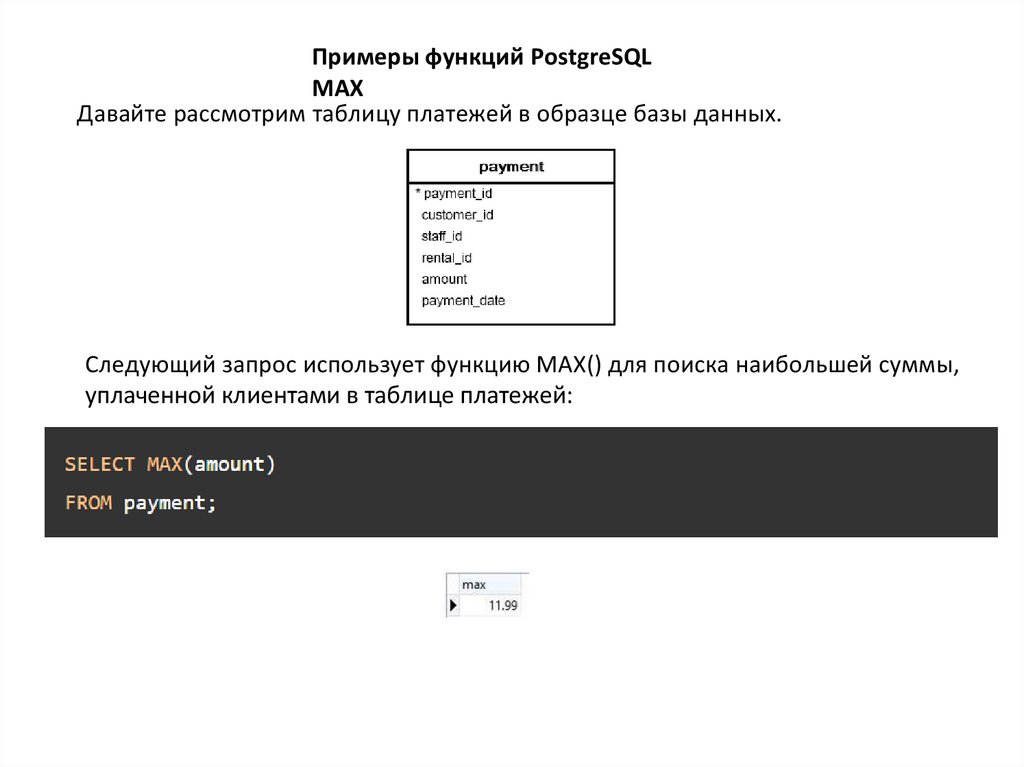
Примеры функций PostgreSQLMAX
Давайте рассмотрим таблицу платежей в образце базы данных.
Следующий запрос использует функцию MAX() для поиска наибольшей суммы,
уплаченной клиентами в таблице платежей:
14.
Введение в функцию PostgreSQL MINФункция PostgreSQL MIN() — агрегатная функция, возвращающая минимальное
значение из набора значений.
Чтобы найти минимальное значение в столбце таблицы, вы передаете имя столбца
функции MIN(). Тип данных столбца может быть числом, строкой или любым
сопоставимым типом.
Синтаксис функции МИН() следующий:
В отличие от функций AVG(), COUNT() и SUM(), опция DISTINCT не оказывает
никакого влияния на функцию MIN().
15.
Использование функции PostgreSQL MIN впредложении SELECT
В следующем примере используется функция MIN(), чтобы получить самую
низкую ставку аренды изарендная платастолбец таблицы фильмов:
16.
Введение в подзапрос PostgreSQLНачнем с простого примера.
Предположим, мы хотим найти фильмы, ставка проката которых выше средней
ставки проката. Мы можем сделать это в два этапа:
– Найдите среднюю арендную ставку, используя оператор SELECT и функцию
среднего значения (AVG).
- Используйте результат первого запроса во втором операторе SELECT, чтобы найти
нужные нам фильмы.
Следующий запрос позволяет получить среднюю ставку аренды:
17.
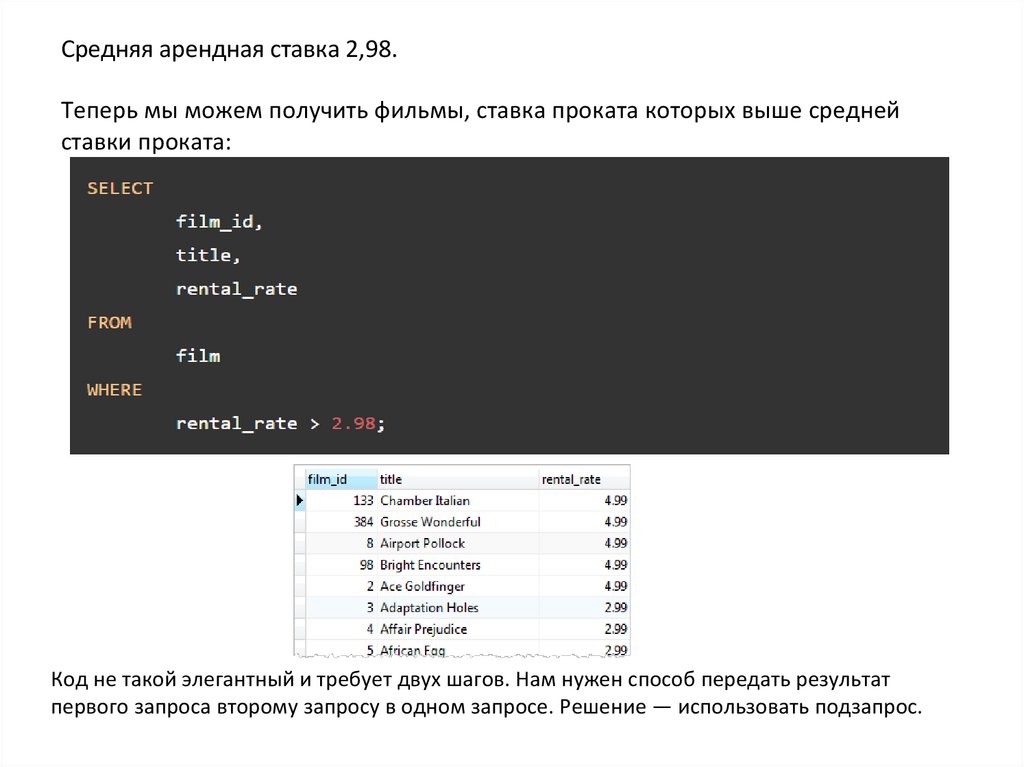
Средняя арендная ставка 2,98.Теперь мы можем получить фильмы, ставка проката которых выше средней
ставки проката:
Код не такой элегантный и требует двух шагов. Нам нужен способ передать результат
первого запроса второму запросу в одном запросе. Решение — использовать подзапрос.
18.
Подзапрос — это запрос, вложенный в другой запрос, например SELECT, INSERT,DELETE и UPDATE. В этом уроке мы сосредоточимся только на операторе SELECT.
Чтобы создать подзапрос, мы заключаем второй запрос в скобки и используем его в
предложении WHERE как выражение:
Запрос внутри скобок
называется подзапросом или
внутренним запросом.
Запрос, содержащий
подзапрос, называется
внешним запросом.
PostgreSQL выполняет
запрос, содержащий
подзапрос, в следующей
последовательности:
- Сначала выполняет
подзапрос.
- Во-вторых, получает
результат и передает его
внешнему запросу.
- В-третьих, выполняет
внешний запрос.
19.
Подзапросы можно использовать с операторами SELECT, INSERT, UPDATE и DELETE,а также с такими операторами, как =, <, >, >=, <=, IN и т. д.
Есть несколько правил, которым должны следовать подзапросы:
- Подзапросы должны быть заключены в круглые скобки.
- Подзапрос может иметь только один столбец в предложении SELECT, если только
в основном запросе для подзапроса не содержится несколько столбцов для
сравнения выбранных столбцов.
— ORDER BY нельзя использовать в подзапросе, хотя в основном запросе можно
использовать ORDER BY. GROUP BY можно использовать для выполнения той же
функции, что и ORDER BY в подзапросе.
— Оператор BETWEEN нельзя использовать с подзапросом; однако BETWEEN
можно использовать внутри подзапроса.
20.
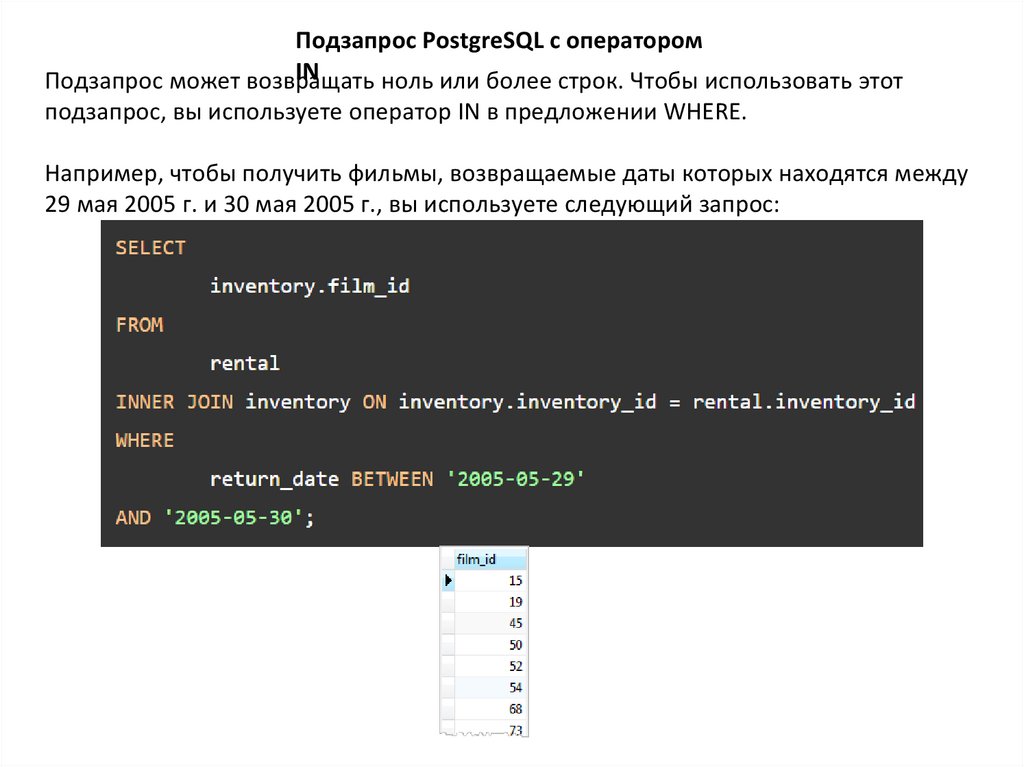
Подзапрос PostgreSQL с операторомIN
Подзапрос может возвращать
ноль или более строк. Чтобы использовать этот
подзапрос, вы используете оператор IN в предложении WHERE.
Например, чтобы получить фильмы, возвращаемые даты которых находятся между
29 мая 2005 г. и 30 мая 2005 г., вы используете следующий запрос:
21.
Он возвращает несколько строк, поэтому мы можем использовать этот запрос вкачестве подзапроса в предложении WHERE запроса следующим образом:
SELECT
film_id,
title
FROM
film
WHERE
film_id IN (
SELECT
inventory.film_id
FROM
rental
INNER JOIN inventory ON inventory.inventory_id = rental.inventory_id
WHERE
return_date BETWEEN '2005-05-29’ AND '2005-05-30'
);
22.
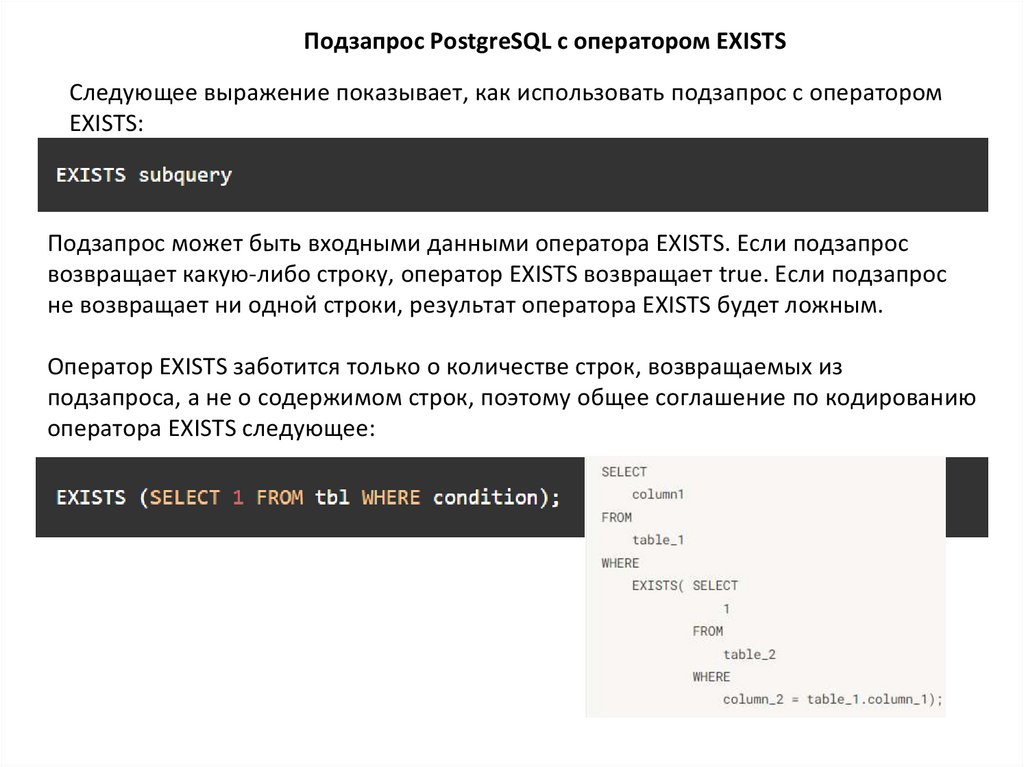
Подзапрос PostgreSQL с оператором EXISTSСледующее выражение показывает, как использовать подзапрос с оператором
EXISTS:
Подзапрос может быть входными данными оператора EXISTS. Если подзапрос
возвращает какую-либо строку, оператор EXISTS возвращает true. Если подзапрос
не возвращает ни одной строки, результат оператора EXISTS будет ложным.
Оператор EXISTS заботится только о количестве строк, возвращаемых из
подзапроса, а не о содержимом строк, поэтому общее соглашение по кодированию
оператора EXISTS следующее:
23.
EXISTS принимает аргумент,
который является
подзапросом.
Если подзапрос возвращает
хотя бы одну строку, результат
EXISTS будет истинным. Если
подзапрос не возвращает ни
одной строки, результат EXISTS
будет ложным.
Оператор EXISTS часто
используется с
коррелированным
подзапросом.
Результат оператора EXISTS
зависит от того, возвращена
ли подзапросом какая-либо
строка, а не от ее
содержимого. Таким образом,
столбцы, которые появляются
в предложении SELECT
подзапроса, не важны.
24.
Оператор NOT отменяет
результат оператора EXISTS. НЕ
СУЩЕСТВУЕТ противоположно
СУЩЕСТВУЕТ. Это означает, что
если подзапрос не возвращает
ни одной строки, NOT EXISTS
возвращает true. Если
подзапрос возвращает одну
или несколько строк, NOT
EXISTS возвращает false.
В следующем примере
возвращается информация о
том, что клиенты не произвели
ни одного платежа,
превышающего 11.
25.
Подзапросы с оператором INSERTПодзапросы также можно использовать с операторами INSERT. Инструкция INSERT
использует данные, возвращенные из подзапроса, для вставки в другую таблицу.
Выбранные данные в подзапросе можно изменить с помощью любой символьной,
датовой или числовой функции.
Основной синтаксис следующий:
Пример
Рассмотрим таблицу COMPANY_BKP со структурой, аналогичной таблице COMPANY,
и ее можно создать с помощью того же CREATE TABLE, используя COMPANY_BKP в
качестве имени таблицы. Теперь, чтобы скопировать полную таблицу COMPANY в
COMPANY_BKP, используйте следующий синтаксис:
26.
Подзапросы с оператором UPDATEПодзапрос можно использовать вместе с оператором UPDATE. При использовании
подзапроса с оператором UPDATE можно обновить один или несколько столбцов в
таблице.
Основной синтаксис следующий:
Пример
Предположим, у нас есть таблица COMPANY_BKP, которая является резервной
копией таблицы COMPANY.
В следующем примере SALARY обновляется в 0,50 раза в таблице COMPANY для
всех клиентов, возраст которых больше или равен 27:
27.
Подзапросы с оператором DELETEПодзапрос можно использовать вместе с оператором DELETE, как и с любыми
другими операторами, упомянутыми выше.
Основной синтаксис следующий:
Пример
Предположим, у нас есть таблица COMPANY_BKP, которая является резервной
копией таблицы COMPANY.
В следующем примере удаляются записи из таблицы COMPANY для всех клиентов,
возраст которых больше или равен 27:
28.
Оконные функцииPostgreSQL
Оконная функция выполняет вычисления для набора строк таблицы, которые
каким-то образом связаны с текущей строкой. Это сравнимо с типом
вычислений, которые можно выполнить с помощью агрегатной функции. Но в
отличие от обычных агрегатных функций, использование оконной функции не
приводит к группировке строк в одну выходную строку — строки сохраняют свои
отдельные идентификаторы. За кулисами оконная функция может получить
доступ не только к текущей строке результата запроса.
Возьмем для примера таблицу:
29.
Предположим, вы хотите найти самого высокооплачиваемого человека в каждомотделе. Есть вероятность, что вы могли бы сделать это, создав сложную хранимую
процедуру или, может быть, даже очень сложный SQL. Большинство
разработчиков даже предпочли бы вернуть данные обратно на предпочитаемый
ими язык, а затем выполнить циклический анализ результатов. С оконными
функциями это становится намного проще.
Сначала мы можем ранжировать каждого человека по определенной группе:
30.
Надеюсь, отсюда станет понятно, как мы можем фильтровать и находить толькосамых высокооплачиваемых сотрудников в каждом отделе:
Самое приятное то, что Postgres оптимизирует запрос за вас, а не анализирует весь
набор результатов, если вы сделаете это самостоятельно.plpgsqlили в коде вашего
приложения.
31.
Введение в оконные функции PostgreSQLСамый простой способ понять оконные функции — начать с рассмотрения
агрегатных функций. Агрегатная функция объединяет данные из набора строк в
одну строку.
В следующем примере агрегатная функция AVG() используется для расчета
средней цены всех продуктов в таблице продуктов.
Чтобы применить агрегатную функцию к подмножествам строк, вы используете
предложение GROUP BY. В следующем примере возвращается средняя цена для
каждой группы продуктов.
32.
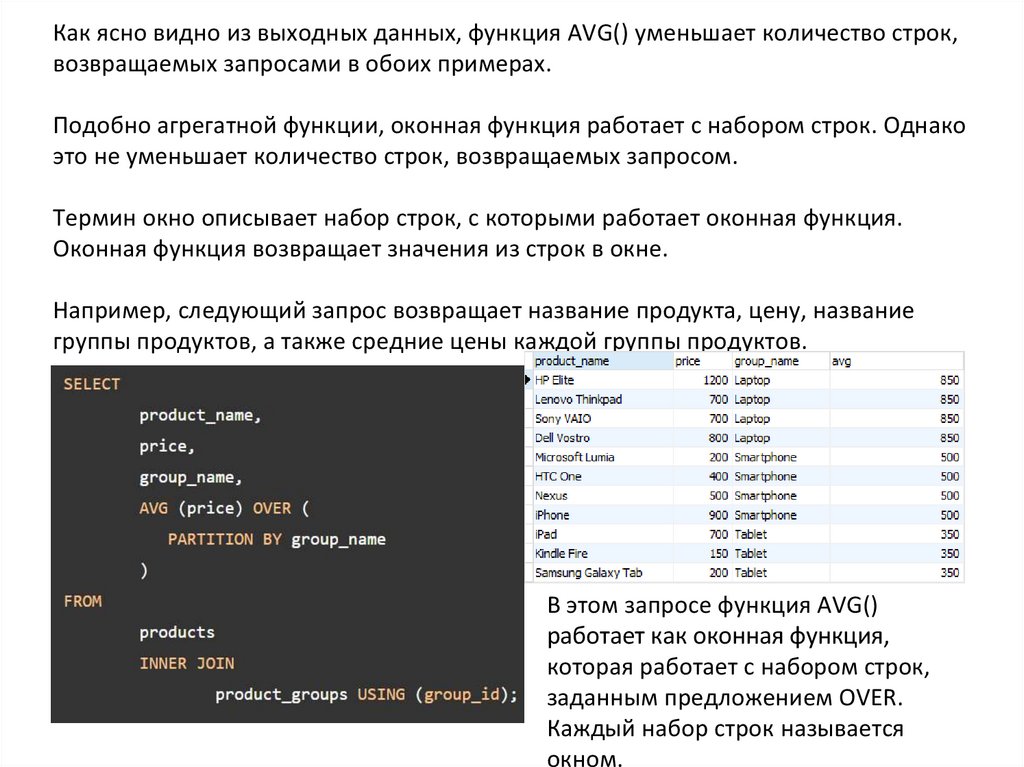
Как ясно видно из выходных данных, функция AVG() уменьшает количество строк,возвращаемых запросами в обоих примерах.
Подобно агрегатной функции, оконная функция работает с набором строк. Однако
это не уменьшает количество строк, возвращаемых запросом.
Термин окно описывает набор строк, с которыми работает оконная функция.
Оконная функция возвращает значения из строк в окне.
Например, следующий запрос возвращает название продукта, цену, название
группы продуктов, а также средние цены каждой группы продуктов.
В этом запросе функция AVG()
работает как оконная функция,
которая работает с набором строк,
заданным предложением OVER.
Каждый набор строк называется
окном.
33.
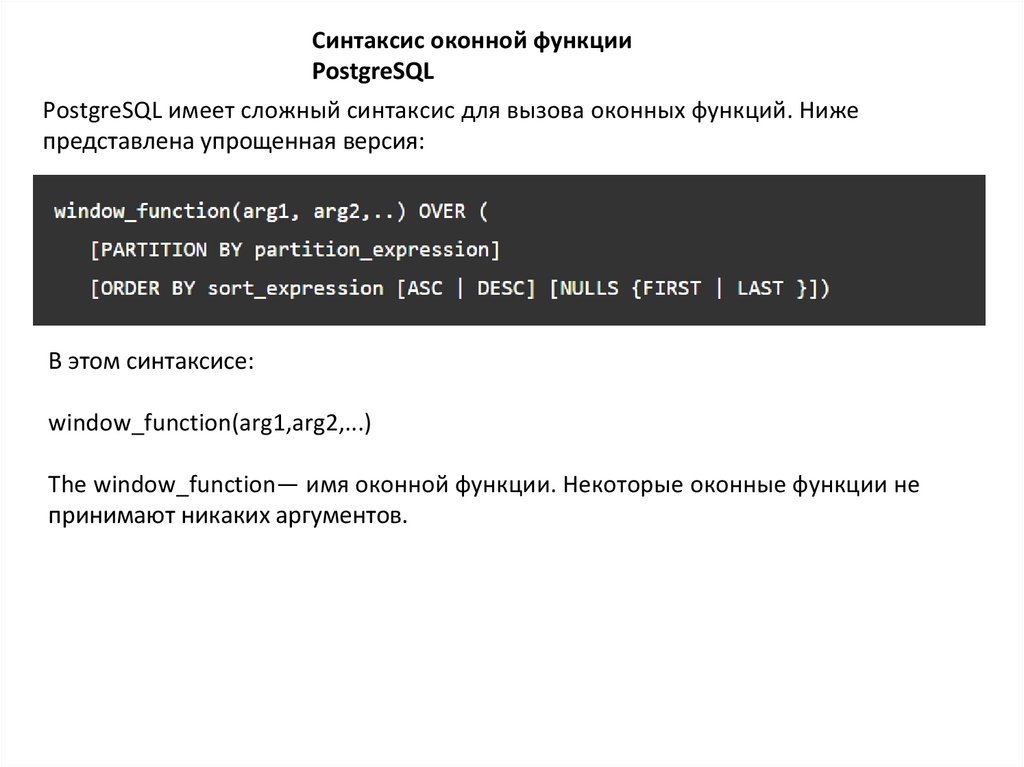
Синтаксис оконной функцииPostgreSQL
PostgreSQL имеет сложный синтаксис для вызова оконных функций. Ниже
представлена упрощенная версия:
В этом синтаксисе:
window_function(arg1,arg2,...)
The window_function— имя оконной функции. Некоторые оконные функции не
принимают никаких аргументов.
34.
Предложение PARTITION BYПредложение PARTITION BY делит строки на несколько групп или разделов, к
которым применяется оконная функция. Как и в приведенном выше примере, мы
использовали группу продуктов, чтобы разделить продукты на группы (или
разделы).
Предложение PARTITION BY является необязательным. Если вы пропустите
предложение PARTITION BY, оконная функция будет обрабатывать весь набор
результатов как один раздел.
Предложение ORDER BY
Предложение ORDER BY определяет порядок строк в каждом разделе, к которому
применяется оконная функция.
Предложение ORDER BY использует опцию NULLS FIRST или NULLS LAST, чтобы
указать, будет ли обнуляемый значения должны быть первыми или последними в
наборе результатов. По умолчанию используется опция NULLS LAST.
35.
Если вы используете в запросе несколько оконных функций:вы можете использовать предложение WINDOW, чтобы сократить запрос, как
показано в следующем запросе:
Предложение WINDOW также можно использовать, даже если в запросе вы
вызываете одну оконную функцию:
36.
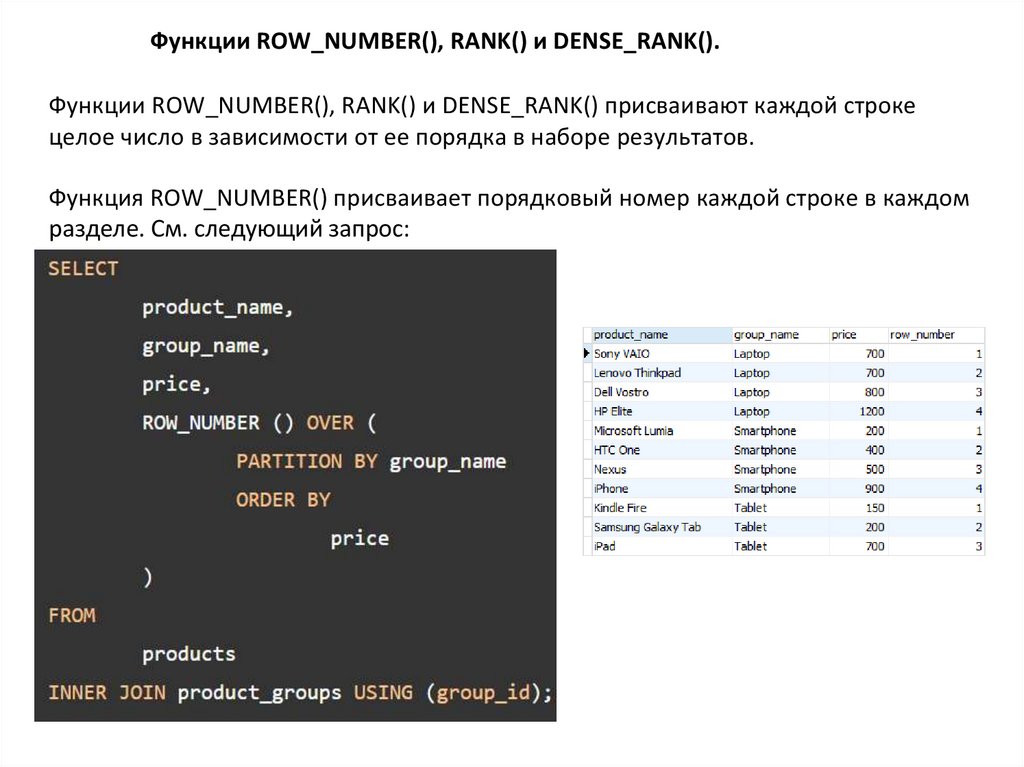
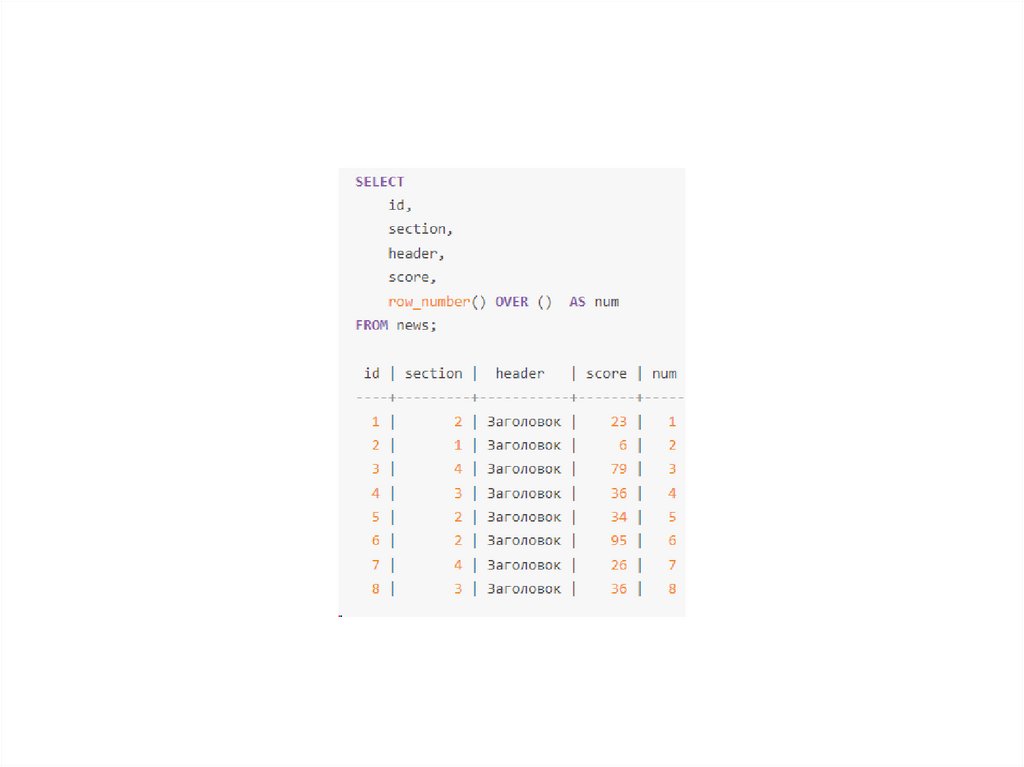
Функции ROW_NUMBER(), RANK() и DENSE_RANK().Функции ROW_NUMBER(), RANK() и DENSE_RANK() присваивают каждой строке
целое число в зависимости от ее порядка в наборе результатов.
Функция ROW_NUMBER() присваивает порядковый номер каждой строке в каждом
разделе. См. следующий запрос:
37.
Функция RANK() присваивает ранг внутри упорядоченного раздела. Если строкиимеют одинаковые значения, функция РАНГ() присваивает один и тот же ранг, при
этом следующий ранг пропускается.
См. следующий запрос:
В группе продуктов для ноутбуков
продукты Dell Vostro и Sony VAIO
имеют одинаковую цену, поэтому им
присваивается один и тот же ранг 1.
Следующей строкой в группе
является HP Elite, которая получает
ранг 3, поскольку ранг 2
пропускается.
38.
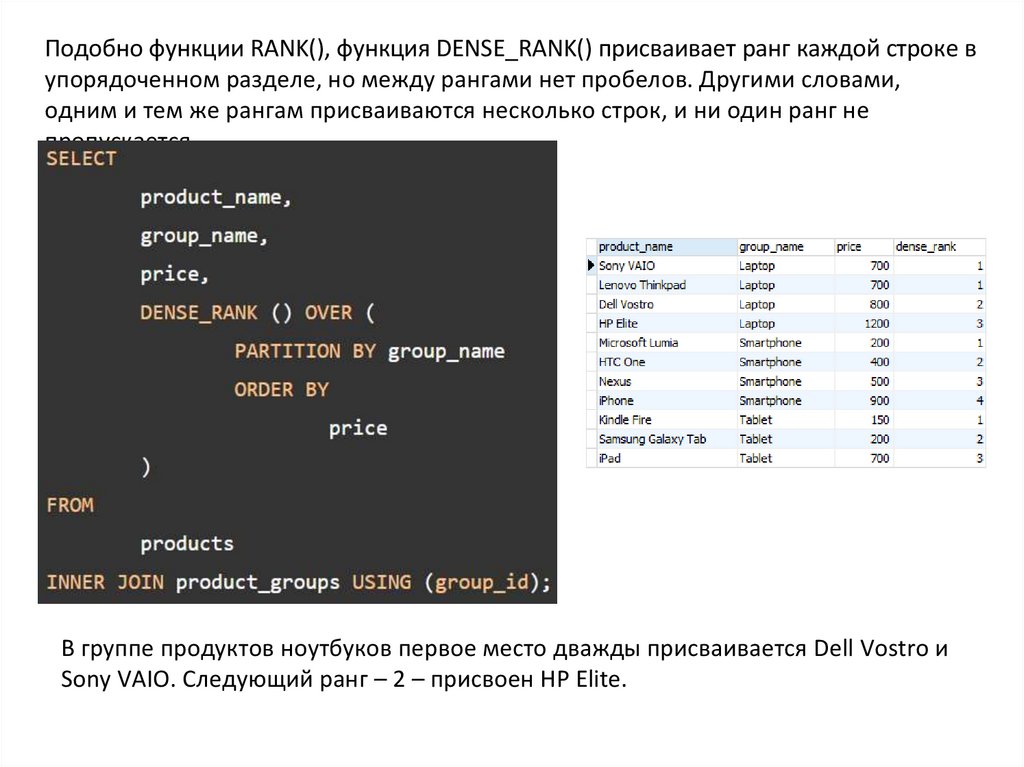
Подобно функции RANK(), функция DENSE_RANK() присваивает ранг каждой строке вупорядоченном разделе, но между рангами нет пробелов. Другими словами,
одним и тем же рангам присваиваются несколько строк, и ни один ранг не
пропускается.
В группе продуктов ноутбуков первое место дважды присваивается Dell Vostro и
Sony VAIO. Следующий ранг – 2 – присвоен HP Elite.
39.
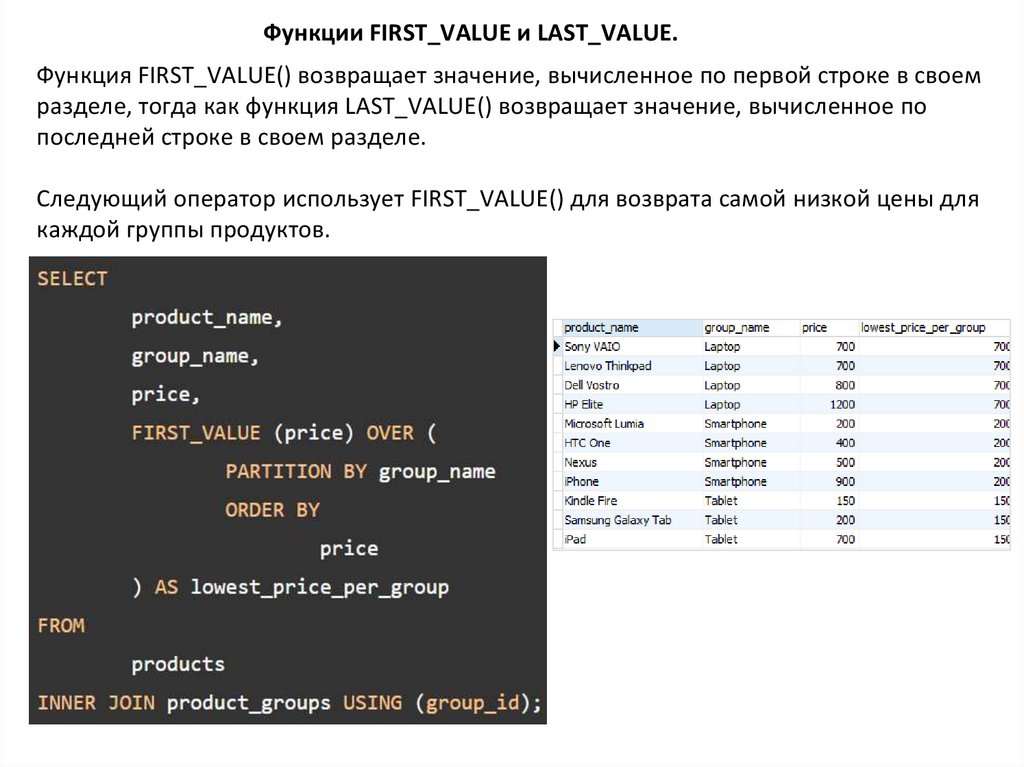
Функции FIRST_VALUE и LAST_VALUE.Функция FIRST_VALUE() возвращает значение, вычисленное по первой строке в своем
разделе, тогда как функция LAST_VALUE() возвращает значение, вычисленное по
последней строке в своем разделе.
Следующий оператор использует FIRST_VALUE() для возврата самой низкой цены для
каждой группы продуктов.
40.
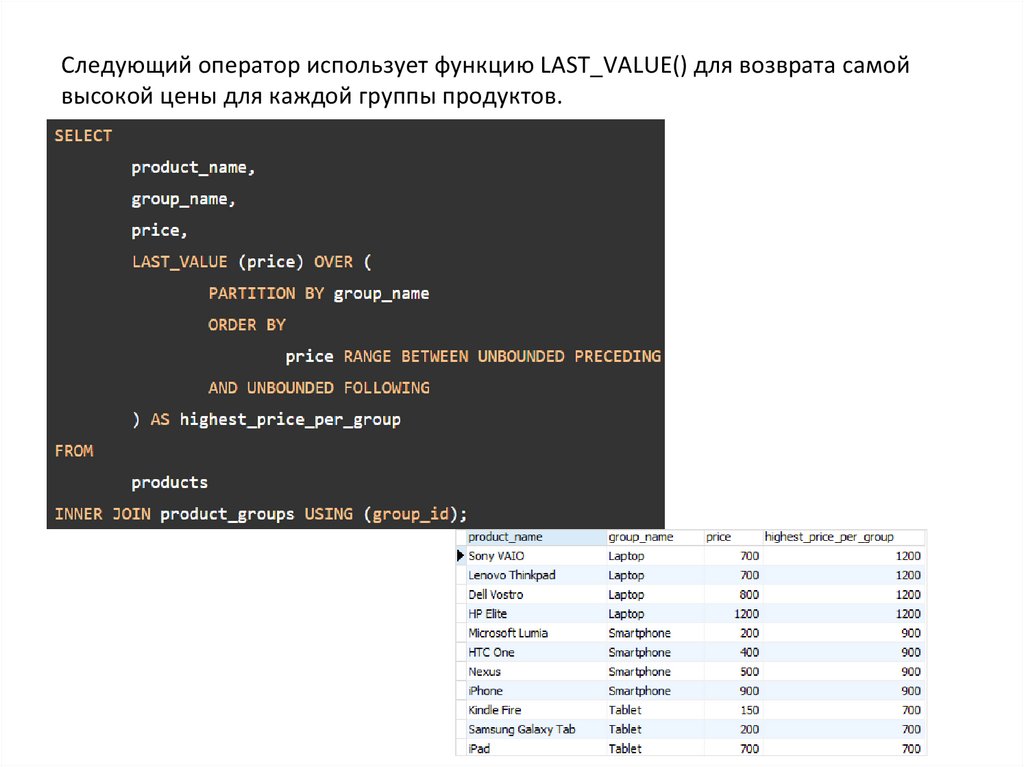
Следующий оператор использует функцию LAST_VALUE() для возврата самойвысокой цены для каждой группы продуктов.
41.
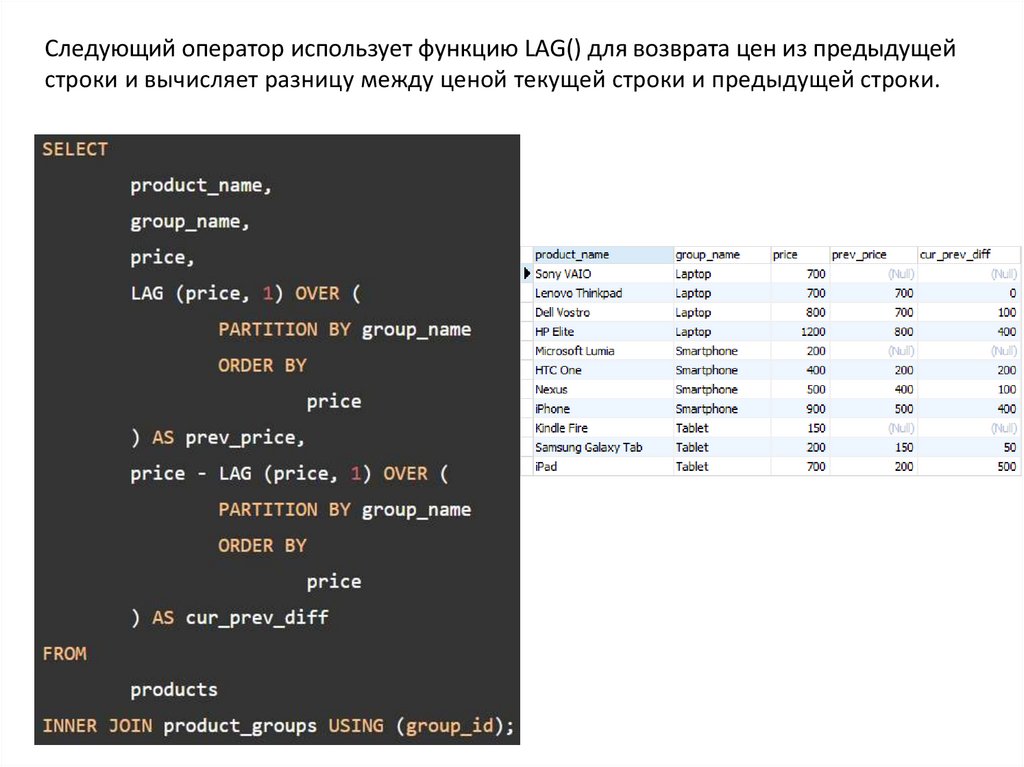
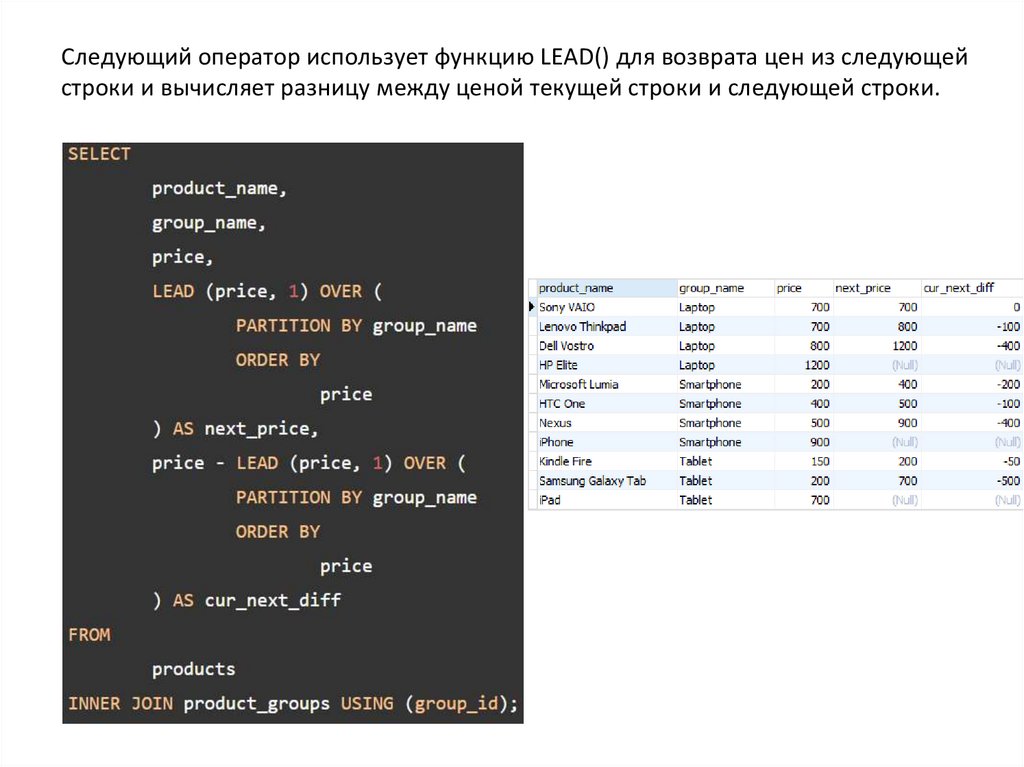
Функции LAG и LEADФункция LAG() имеет возможность доступа к данным из предыдущей строки, а
функция LEAD() — к данным из следующей строки.
Функции LAG() и LEAD() имеют одинаковый синтаксис:
В этом синтаксисе:
- выражение – столбец или выражение для вычисления возвращаемого значения.
- offset – количество строк, предшествующих (LAG)/следующих (LEAD) текущей
строке. По умолчанию установлено значение 1.
- default – возвращаемое значение по умолчанию, если смещение выходит за
пределы окна. По умолчанию установлено значение NULL, если вы его пропустите.
42.
Следующий оператор использует функцию LAG() для возврата цен из предыдущейстроки и вычисляет разницу между ценой текущей строки и предыдущей строки.
43.
Следующий оператор использует функцию LEAD() для возврата цен из следующейстроки и вычисляет разницу между ценой текущей строки и следующей строки.
44.
45.
В оконное выражение можно добавитьORDER BY, тогда можно изменить порядок
обработки
Обратите внимание,
что добавлено еще и
в конце всего запоса
ORDER BY id, при
этом рейтинг
посчитан все равно
верно. Т.е. посгрес
просто отсортировал
результат вместе с
результатом работы
оконной функции,
один order ничуть не
мешает другому
46.
Дальше — больше. В оконное выражение можно добавитьслово PARTITION BY [expression],
например row_number() OVER (PARTITION BY section), тогда
подсчет будет идти в каждой группе отдельно:
Если не указывать
партицию, то партицией
является весь запрос.
47.
48.
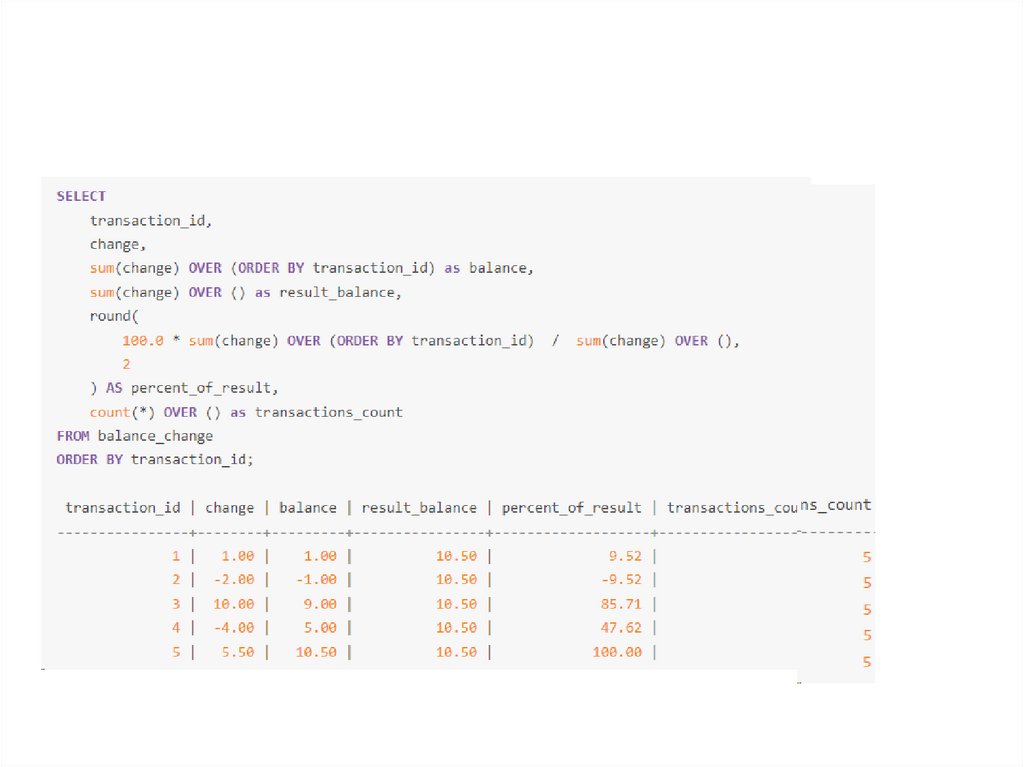
Если же мы для агрегатной фунции sum не будем
использовать ORDER BY в окне, тогда мы просто посчитаем
общую сумму и покажем её во всех строках. Т.е. фреймом для
каждой из строк будет весь набор строк от начала до конца
партиции.