













 Программирование
ПрограммированиеПохожие презентации:
")









Повышение эффективности работы баз данных. Обработка транзакций OLTP-OLAP системы мониторы транзакций
1. Тема: Повышение эффективности работы баз данных. Обработка транзакций OLTP-OLAP системы мониторы транзакций.
Тема:Повышение эффективности работы баз
данных. Обработка транзакций OLTPOLAP системы мониторы транзакций.
КАБУТОВ ХОДЖИМУРОД
МАХМАДИЕВИЧ
ФТЭС 3-КУРС 2-ГРУППА
2. Индексы в стандарте языка
Индекс – это набор ссылок, упорядоченных поопределенному столбцу таблицы, который в данном случае будет
называться индексированным столбцом . Хотя индекс и связан с
конкретным столбцом (или столбцами ) таблицы, все же он является
самостоятельным объектом базы данных. Индексы обычно
создаются с целью удовлетворения определенных критериев
поиска после того, как таблица уже находилась некоторое время в
работе и увеличилась в размерах. Создание индексов не
предусмотрено стандартом SQL, однако большинство диалектов
поддерживают как минимум следующий оператор:
3. индексы
В СРЕДЕ SQL SERVER РЕАЛИЗОВАНОНЕСКОЛЬКО ТИПОВ ИНДЕКСОВ:
КЛАСТЕРНЫЕ ИНДЕКСЫ ;
НЕКЛАСТЕРНЫЕ ИНДЕКСЫ ;
УНИКАЛЬНЫЕ ИНДЕКСЫ.
4. Некластерный индекс
Некластерные индексы – наиболее типичныепредставители семейства индексов. В отличие от
кластерных, они не перестраивают физическую
структуру таблицы, а лишь организуют ссылки на
соответствующие строки .
Для идентификации нужной строки в таблице
некластерный индекс организует специальные
указатели, включающие в себя:
информацию об идентификационном номере
файла, в котором хранится строка ;
идентификационный номер страницы
соответствующих данных;
номер искомой строки на соответствующей
странице;
содержимое столбца.
5. Кластерный индекс
Кластерный индекс может включать несколькостолбцов. Однако количество таких столбцов
рекомендуется по возможности свести к
минимуму.
Необходимо избегать создания кластерного
индекса для часто изменяемых столбцов,
поскольку сервер должен будет выполнять
физическое перемещение всех данных в
таблице, чтобы они находились в
упорядоченном состоянии, как того требует
кластерный индекс. Для интенсивно
изменяемых столбцов лучше подходит
некластерный индекс.
При создании в таблице первичного ключа (
PRIMARY KEY ) сервер автоматически создает
для него кластерный индекс, если его не
существовало ранее или если при
определении ключа не был явно указан другой
тип индекса.
6. Уникальный индекс
Уникальный индекс являетсясвоеобразной надстройкой и
может быть реализован как для
кластерного, так и для
некластерного индекса . В одной
таблице может существовать
один уникальный кластерный и
множество уникальных
некластерных индексов.
Уникальные индексы следует
определять только тогда, когда
это действительно необходимо.
Для обеспечения целостности
данных в столбце можно
определить ограничение
целостности UNIQUE или PRIMARY
KEY, а не прибегать к уникальным
индексам. Их использование
только для обеспечения
целостности данных является
неоправданной тратой
пространства в базе данных.
Кроме того, на их поддержание
тратится и процессорное время.
7.
OLAP и OLTP системыOLTP –
оперативная транзакционная обработка данных
OLAP –
оперативная аналитическая обработка данных
8.
Характеристики OLTP системыБольшой объем информации
Часто различные БД для разных подразделений
Нормализованная схема, отсутствие
дублирования информации
Интенсивное изменение данных
Транзакционный режим работы
Транзакции затрагивают небольшой объем данных
Обработка текущих данных – мгновенный снимок
Много клиентов
Малое время отклика – несколько секунд
Характеристики OLAP системы
Большой объем информации
Синхронизированная информация из различных БД
с использованием общих
классификаторов
Ненормализованная схема БД с дубликатами
Данные меняются редко, Изменение происходит
через пакетную загрузку
Выполняются сложные нерегламентированные
запросы над большим объемом данных с широким
применением группировок и агрегатных функций.
Анализ временных зависимостей
Небольшое количество работающих
пользователей – аналитики и менеджеры
Большее время отклика (но все равно приемлемое) –
несколько минут
9.
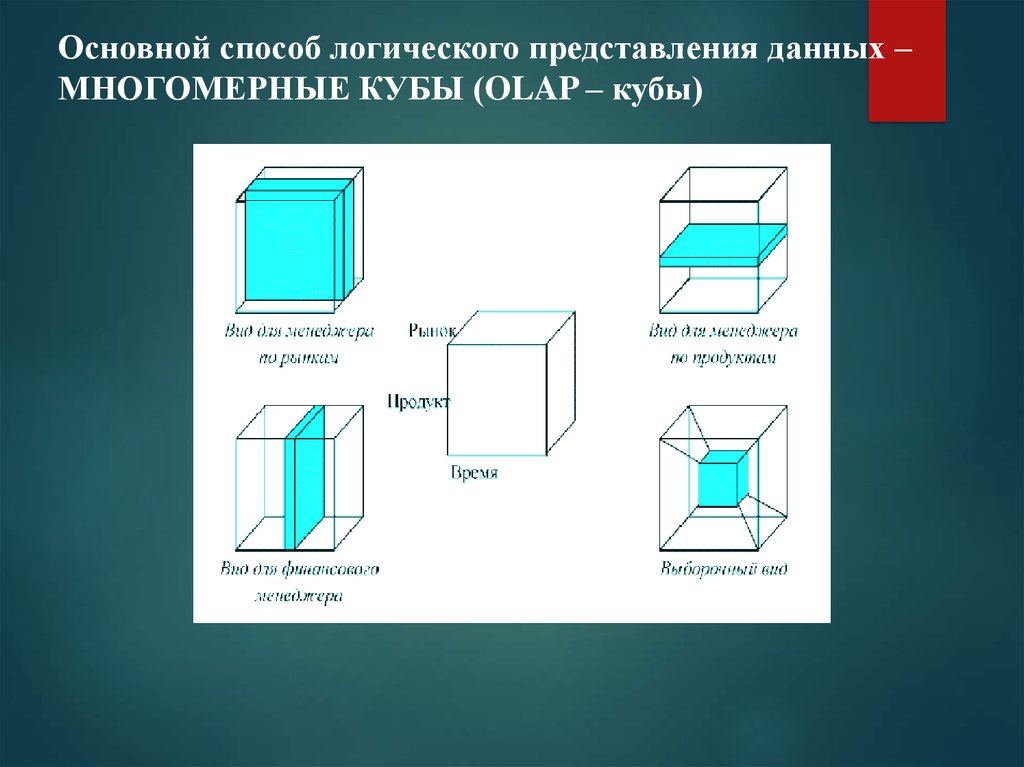
Основной способ логического представления данных –МНОГОМЕРНЫЕ КУБЫ (OLAP – кубы)
10.
OLAP – куб и срезы данных11.
Правила Кодда для реляционных БД1. Правило информации.
2. Правило гарантированного доступа.
3. Правило поддержки недействительных
значений.
4. Правило динамического каталога,
основанного на реляционной модели.
5.Правило исчерпывающего подъязыка
данных.
6. Правило обновления представлений.
7. Правило добавления, обновления и
удаления.
8. Правило независимости физических
данных.
9. Правило независимости логических
данных.
10. Правило независимости условий
целостности.
11. Правило независимости
распространения.
12. Правило единственности.
12.
Правила Кодда для OLAP1. Концептуальное многомерное
представление.
2. Прозрачность.
3. Доступность.
4. Постоянная производительность при
разработке отчетов.
5. Клиент-серверная архитектура.
6. Общая многомерность.
7. Динамическое управление
разреженными матрицами.
8. Многопользовательская поддержка.
9. Неограниченные перекрестные
операции.
10. Интуитивная манипуляция данными.
11. Гибкие возможности получения
отчетов.
12. Неограниченная размерность и число
уровней агрегации.
13.
Реализация OLAPТипы OLAP - серверов
MOLAP (Multidimensional OLAP) - и детальные данные, и
агрегаты хранятся
в
многомерной БД.
ROLAP (Relational OLAP) - детальные данные
храняться в реляционной БД;
агрегаты хранятся в той же БД в
специально
созданных
служебных таблицах.
HOLAP (Hybrid OLAP) - детальные данные храняться
в реляционной БД, а
агрегаты хранятся в многомерной БД.
14.
OLTP схема базы данныхМоделируются оптовые продажи на склад
Объекты
1. Склады
2. Категории товаров (модель)
3. Производители
4. Товары
5. Продавцы
6. Оптовые продажи на склад
15.
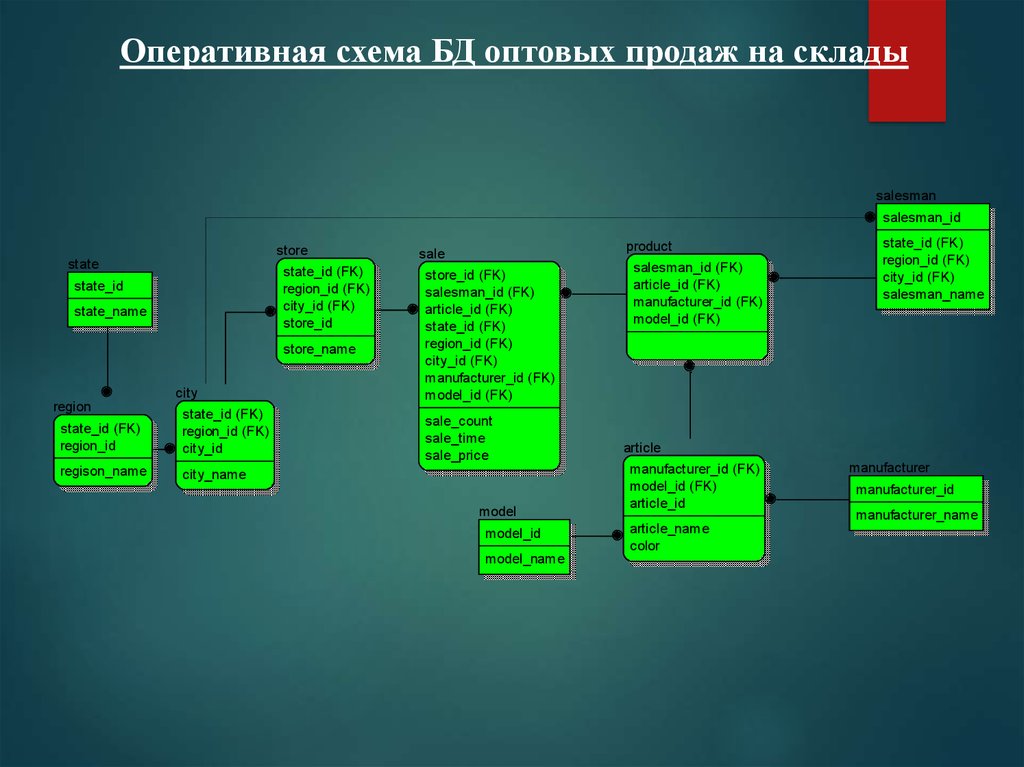
Оперативная схема БД оптовых продаж на складыsalesman
salesman_id
store
state
state_id (FK)
region_id (FK)
city_id (FK)
store_id
state_id
state_name
store_name
city
region
state_id (FK)
region_id
state_id (FK)
region_id (FK)
city_id
regison_name
city_name
product
sale
store_id (FK)
salesman_id (FK)
article_id (FK)
state_id (FK)
region_id (FK)
city_id (FK)
manufacturer_id (FK)
model_id (FK)
sale_count
sale_time
sale_price
model
model_id
model_name
salesman_id (FK)
article_id (FK)
manufacturer_id (FK)
model_id (FK)
state_id (FK)
region_id (FK)
city_id (FK)
salesman_name
article
manufacturer_id (FK)
model_id (FK)
article_id
article_name
color
manufacturer
manufacturer_id
manufacturer_name
16.
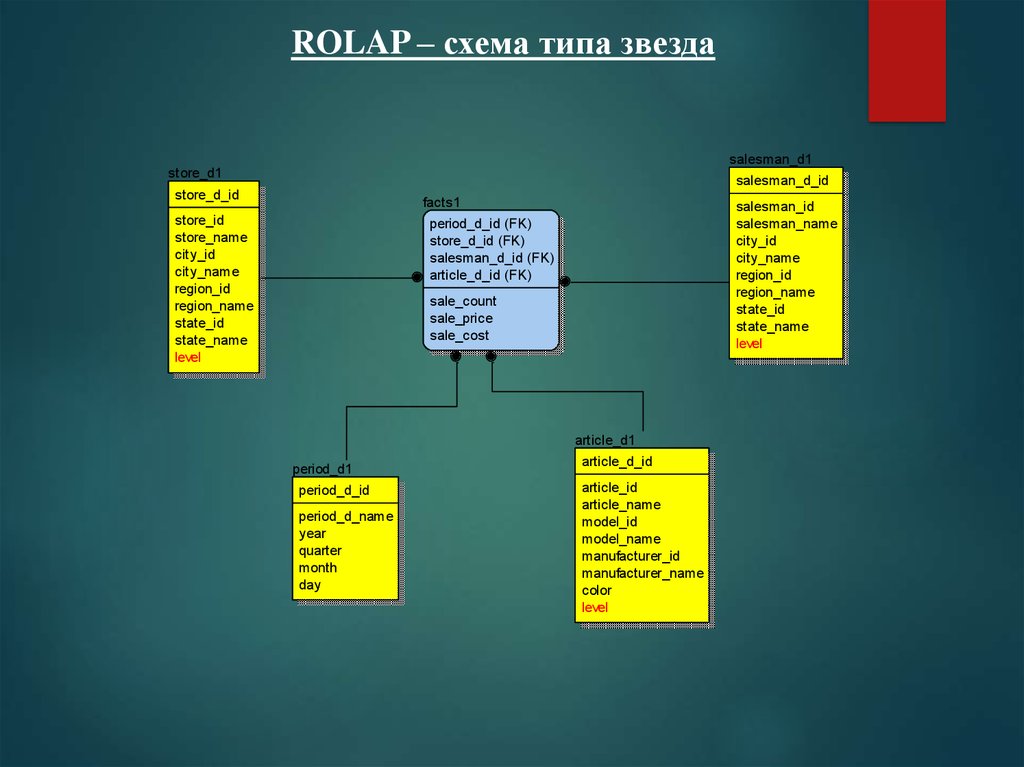
ROLAP – схема типа звездаsalesman_d1
store_d1
salesman_d_id
store_d_id
facts1
store_id
store_name
city_id
city_name
region_id
region_name
state_id
state_name
level
salesman_id
salesman_name
city_id
city_name
region_id
region_name
state_id
state_name
level
period_d_id (FK)
store_d_id (FK)
salesman_d_id (FK)
article_d_id (FK)
sale_count
sale_price
sale_cost
article_d1
period_d1
period_d_id
period_d_name
year
quarter
month
day
article_d_id
article_id
article_name
model_id
model_name
manufacturer_id
manufacturer_name
color
level
17.
Особенности ROLAP – схемы типа звезда1. Одна таблица фактов, которая сильно денормализована
2. Несколько таблиц измерений, которые также
денормализованы
3. Первичный ключ таблицы фактов является составным
и имеет по одному столбцу на каждое измерение
4. Агрегированные данные храняться совместно с
исходными
Недостатки
Если агрегаты храняться совместно с исходными данными,
то в измерениях необходимо использовать дополнительный
параметр – уровень иерархии
18.
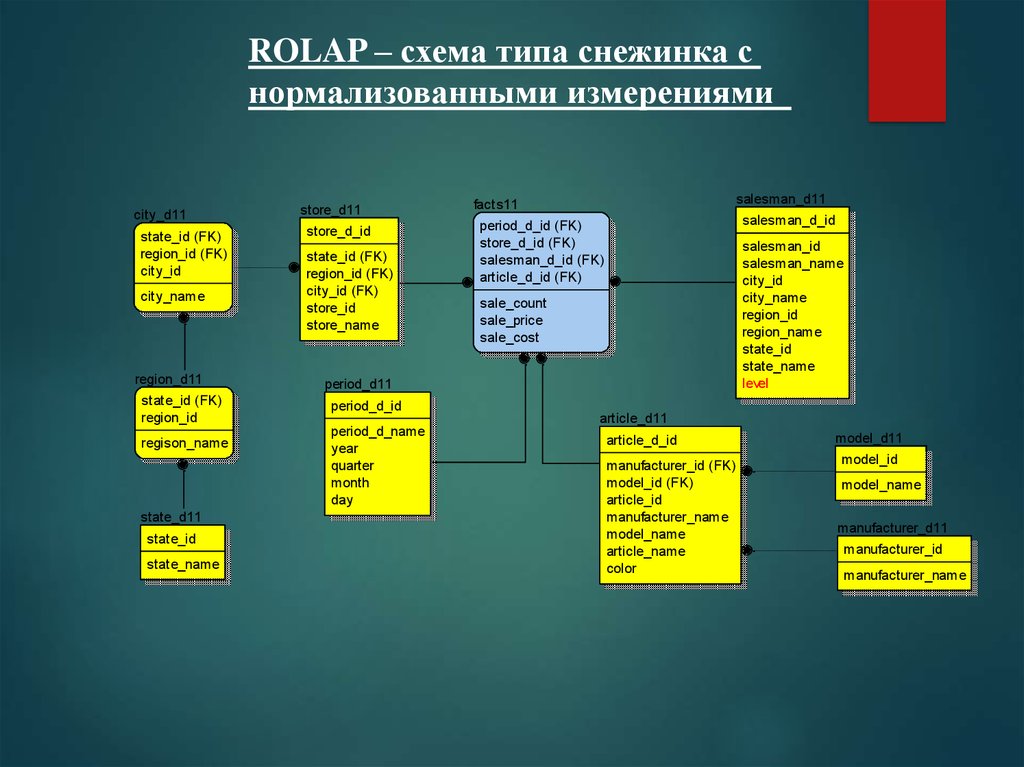
ROLAP – схема типа снежинка снормализованными измерениями
city_d11
state_id (FK)
region_id (FK)
city_id
store_d11
store_d_id
city_name
state_id (FK)
region_id (FK)
city_id (FK)
store_id
store_name
region_d11
period_d11
state_id (FK)
region_id
regison_name
state_d11
state_id
state_name
period_d_id
period_d_name
year
quarter
month
day
salesman_d11
facts11
salesman_d_id
period_d_id (FK)
store_d_id (FK)
salesman_d_id (FK)
article_d_id (FK)
salesman_id
salesman_name
city_id
city_name
region_id
region_name
state_id
state_name
level
sale_count
sale_price
sale_cost
article_d11
article_d_id
manufacturer_id (FK)
model_id (FK)
article_id
manufacturer_name
model_name
article_name
color
model_d11
model_id
model_name
manufacturer_d11
manufacturer_id
manufacturer_name
19.
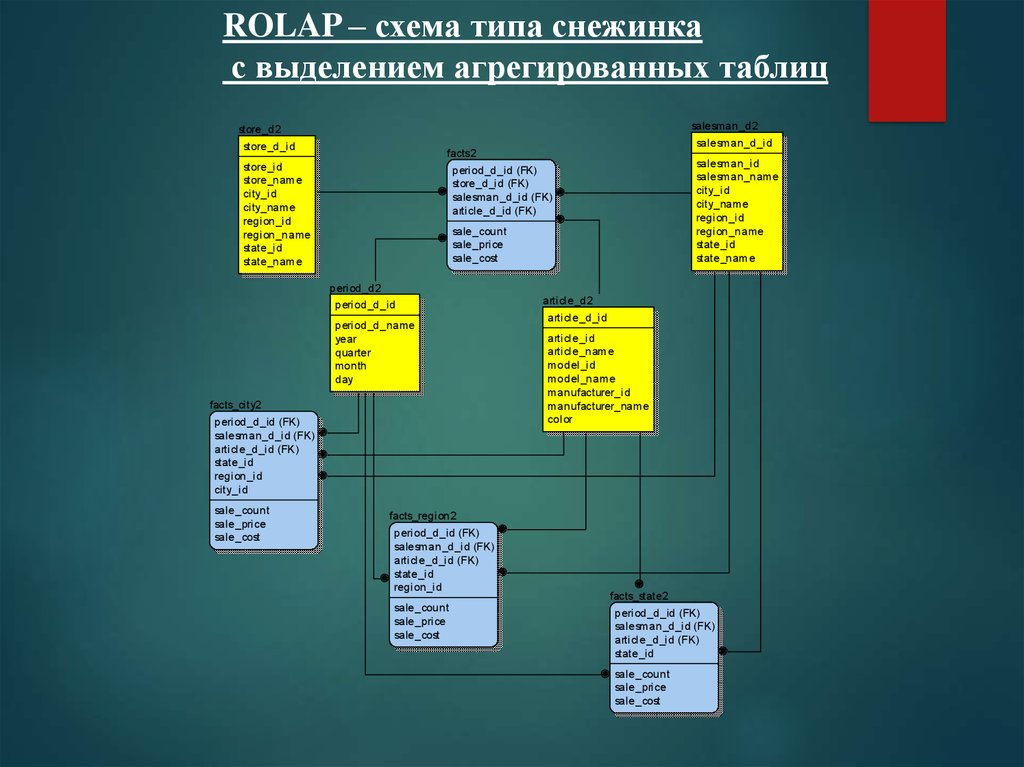
ROLAP – схема типа снежинкас выделением агрегированных таблиц
salesman_d2
store_d2
store_d_id
salesman_d_id
facts2
store_id
store_name
city_id
city_name
region_id
region_name
state_id
state_name
salesman_id
salesman_name
city_id
city_name
region_id
region_name
state_id
state_name
period_d_id (FK)
store_d_id (FK)
salesman_d_id (FK)
article_d_id (FK)
sale_count
sale_price
sale_cost
period_d2
period_d_id
period_d_name
year
quarter
month
day
facts_city2
period_d_id (FK)
salesman_d_id (FK)
article_d_id (FK)
state_id
region_id
city_id
sale_count
sale_price
sale_cost
article_d2
article_d_id
article_id
article_name
model_id
model_name
manufacturer_id
manufacturer_name
color
facts_region2
period_d_id (FK)
salesman_d_id (FK)
article_d_id (FK)
state_id
region_id
sale_count
sale_price
sale_cost
facts_state2
period_d_id (FK)
salesman_d_id (FK)
article_d_id (FK)
state_id
sale_count
sale_price
sale_cost
20.
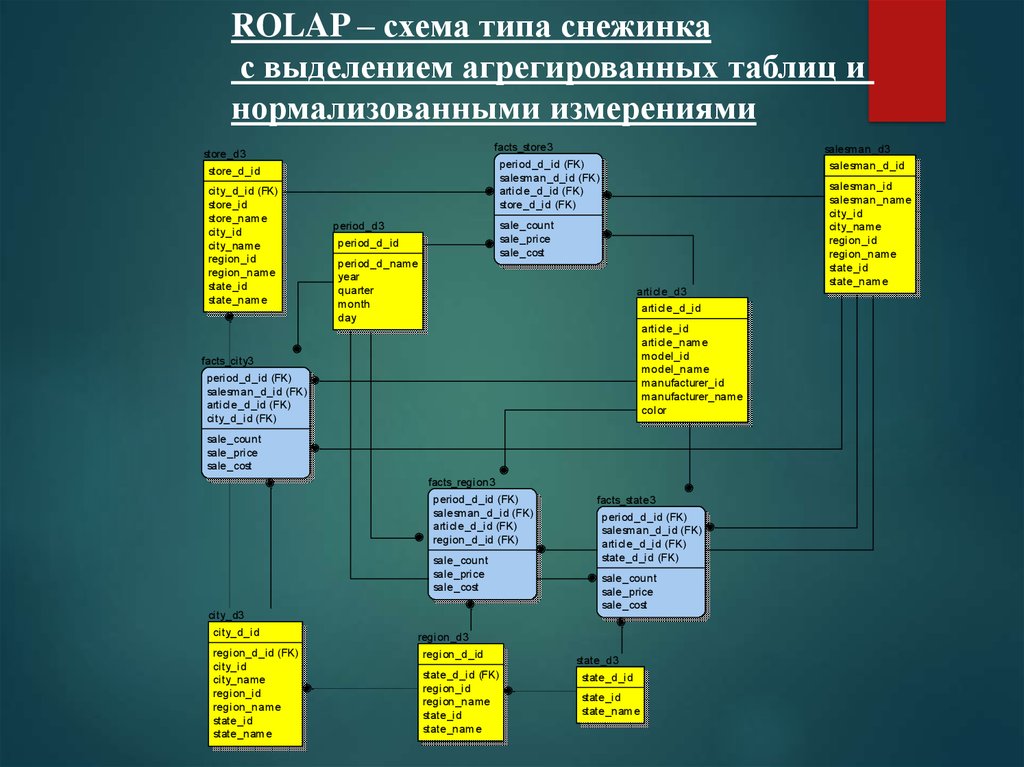
ROLAP – схема типа снежинкас выделением агрегированных таблиц и
нормализованными измерениями
facts_store3
store_d3
city_d_id (FK)
store_id
store_name
city_id
city_name
region_id
region_name
state_id
state_name
salesman_d3
period_d_id (FK)
salesman_d_id (FK)
article_d_id (FK)
store_d_id (FK)
store_d_id
salesman_d_id
sale_count
sale_price
sale_cost
period_d3
period_d_id
period_d_name
year
quarter
month
day
article_d3
article_d_id
article_id
article_name
model_id
model_name
manufacturer_id
manufacturer_name
color
facts_city3
period_d_id (FK)
salesman_d_id (FK)
article_d_id (FK)
city_d_id (FK)
sale_count
sale_price
sale_cost
facts_region3
period_d_id (FK)
salesman_d_id (FK)
article_d_id (FK)
region_d_id (FK)
sale_count
sale_price
sale_cost
city_d3
city_d_id
region_d_id (FK)
city_id
city_name
region_id
region_name
state_id
state_name
facts_state3
period_d_id (FK)
salesman_d_id (FK)
article_d_id (FK)
state_d_id (FK)
sale_count
sale_price
sale_cost
region_d3
region_d_id
state_d_id (FK)
region_id
region_name
state_id
state_name
state_d3
state_d_id
state_id
state_name
salesman_id
salesman_name
city_id
city_name
region_id
region_name
state_id
state_name
21.
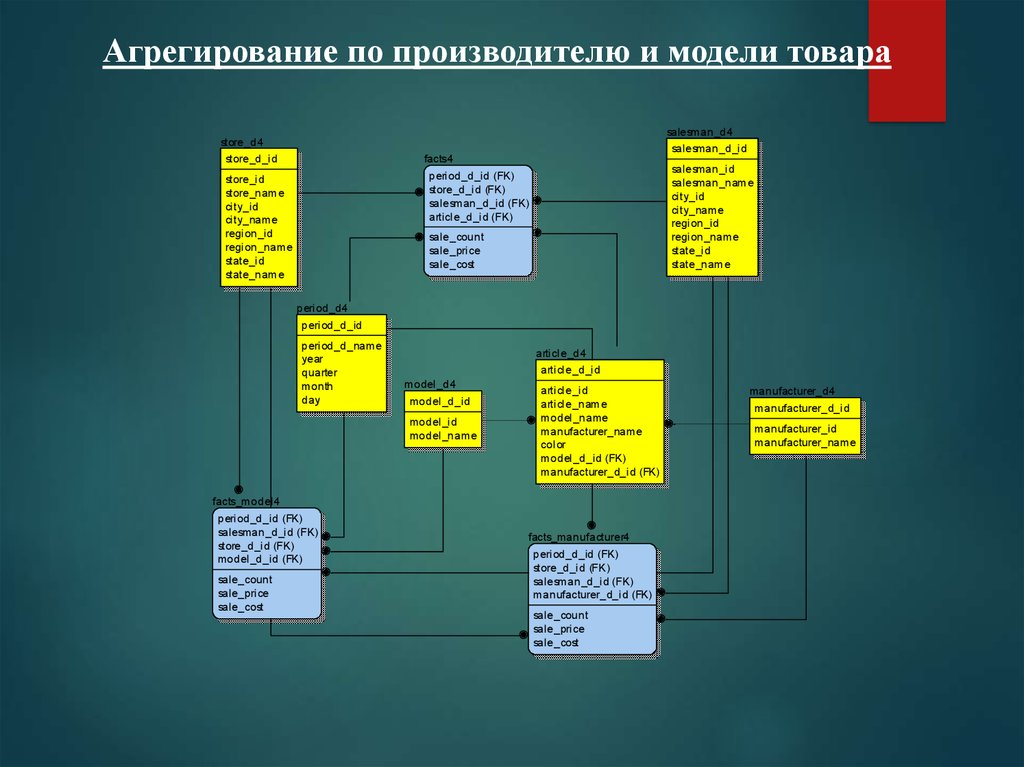
Агрегирование по производителю и модели товараsalesman_d4
store_d4
store_d_id
salesman_d_id
facts4
salesman_id
salesman_name
city_id
city_name
region_id
region_name
state_id
state_name
period_d_id (FK)
store_d_id (FK)
salesman_d_id (FK)
article_d_id (FK)
store_id
store_name
city_id
city_name
region_id
region_name
state_id
state_name
sale_count
sale_price
sale_cost
period_d4
period_d_id
period_d_name
year
quarter
month
day
article_d4
article_d_id
model_d4
model_d_id
model_id
model_name
article_id
article_name
model_name
manufacturer_name
color
model_d_id (FK)
manufacturer_d_id (FK)
facts_model4
period_d_id (FK)
salesman_d_id (FK)
store_d_id (FK)
model_d_id (FK)
sale_count
sale_price
sale_cost
facts_manufacturer4
period_d_id (FK)
store_d_id (FK)
salesman_d_id (FK)
manufacturer_d_id (FK)
sale_count
sale_price
sale_cost
manufacturer_d4
manufacturer_d_id
manufacturer_id
manufacturer_name
22.
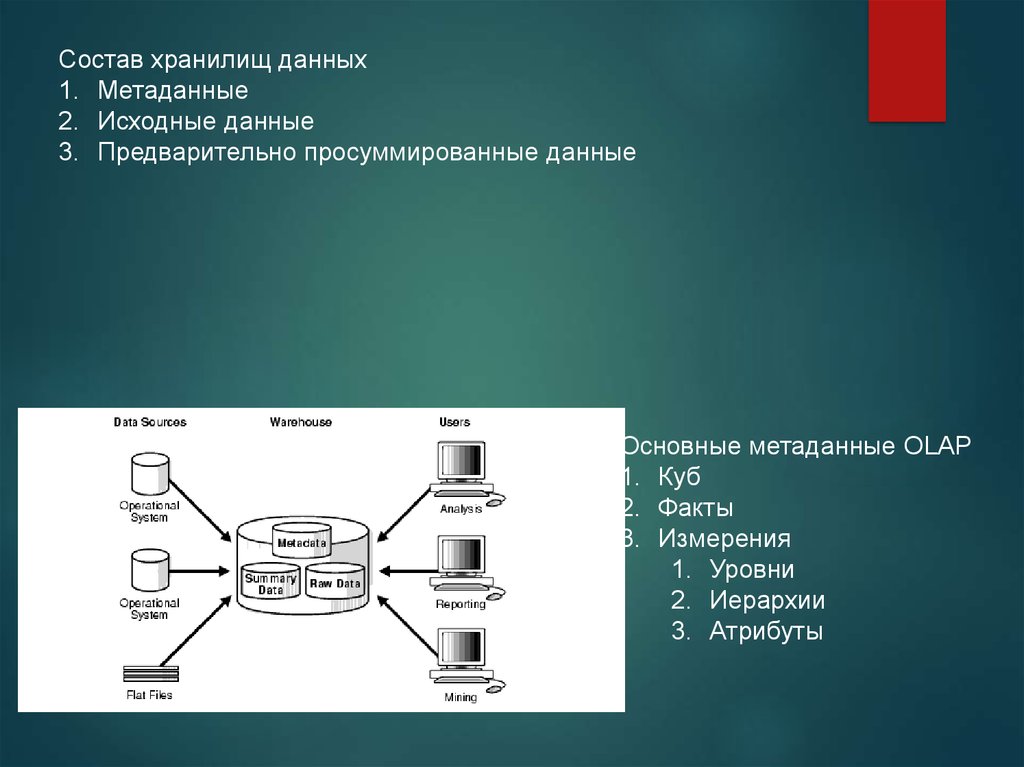
Состав хранилищ данных1. Метаданные
2. Исходные данные
3. Предварительно просуммированные данные
Основные метаданные OLAP
1. Куб
2. Факты
3. Измерения
1. Уровни
2. Иерархии
3. Атрибуты
23.
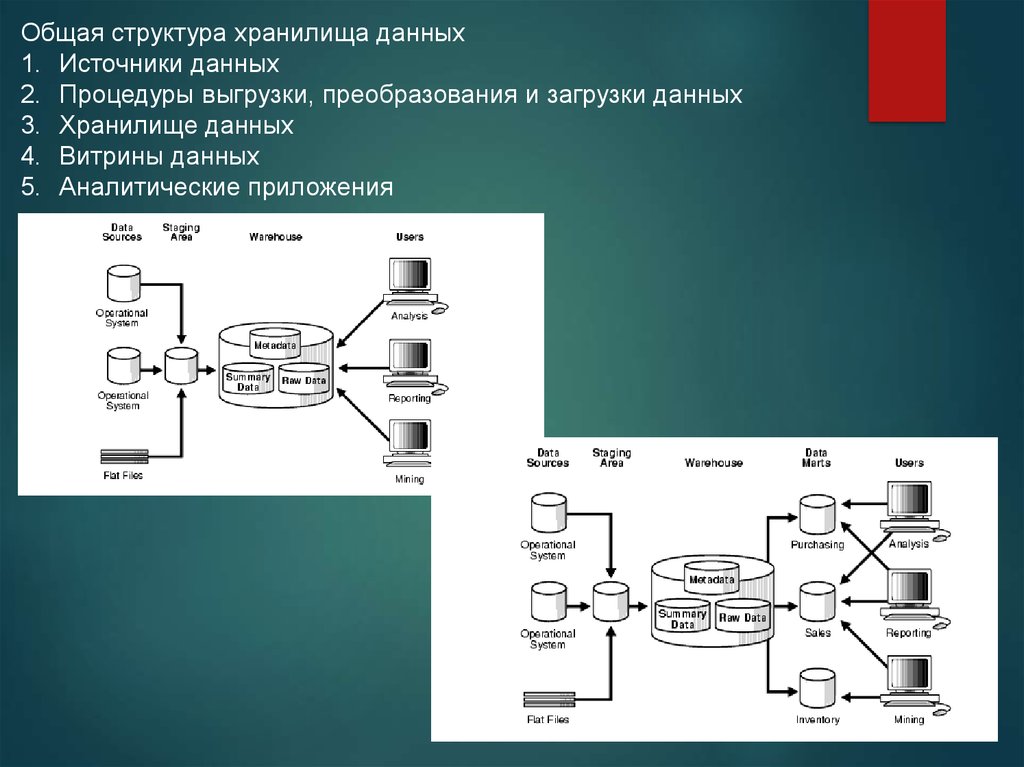
Общая структура хранилища данных1. Источники данных
2. Процедуры выгрузки, преобразования и загрузки данных
3. Хранилище данных
4. Витрины данных
5. Аналитические приложения
24.
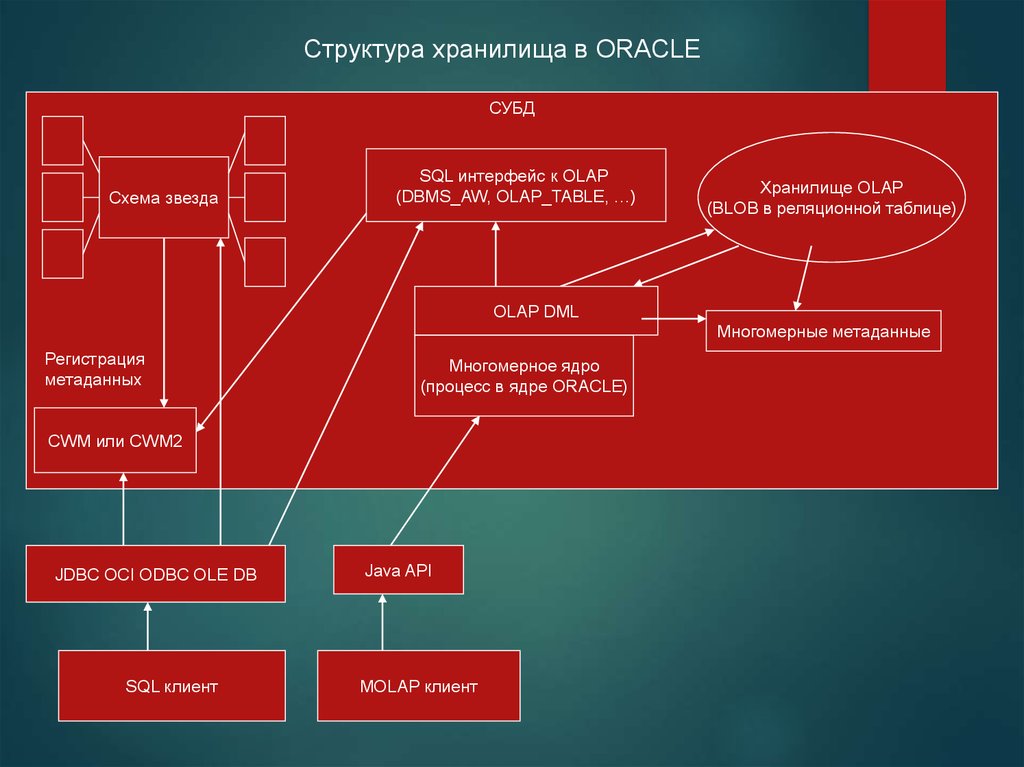
Структура хранилища в ORACLEСУБД
Схема звезда
SQL интерфейс к OLAP
(DBMS_AW, OLAP_TABLE, …)
Хранилище OLAP
(BLOB в реляционной таблице)
OLAP DML
Многомерные метаданные
Регистрация
метаданных
Многомерное ядро
(процесс в ядре ORACLE)
CWM или CWM2
JDBC OCI ODBC OLE DB
SQL клиент
Java API
MOLAP клиент