



 Программирование
ПрограммированиеПохожие презентации:










Local LLM deployment
1.
Local LLM deployment01
02
4 bits QLoRA quantization
8 bits QLoRA quantization
03
04
Code generation
*Tuned Code generation
2.
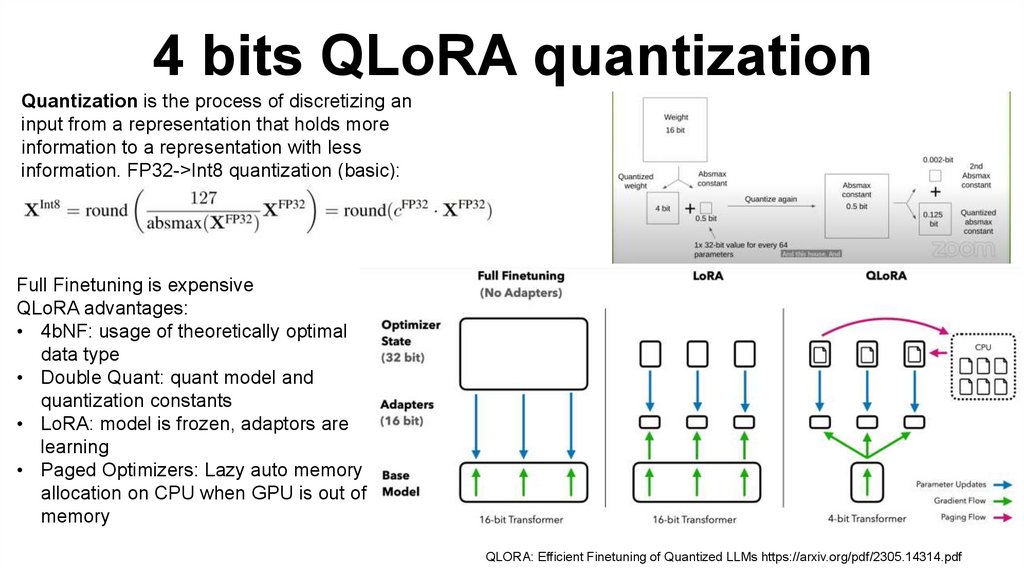
4 bits QLoRA quantizationQuantization is the process of discretizing an
input from a representation that holds more
information to a representation with less
information. FP32->Int8 quantization (basic):
Full Finetuning is expensive
QLoRA advantages:
• 4bNF: usage of theoretically optimal
data type
• Double Quant: quant model and
quantization constants
• LoRA: model is frozen, adaptors are
learning
• Paged Optimizers: Lazy auto memory
allocation on CPU when GPU is out of
memory
QLORA: Efficient Finetuning of Quantized LLMs https://arxiv.org/pdf/2305.14314.pdf
3.
4 bits QLoRA quantizationNo quantization:
4 bits quantization:
4.
8 bits QLoRA quantizationNo quantization:
8 bits quantization:
5.
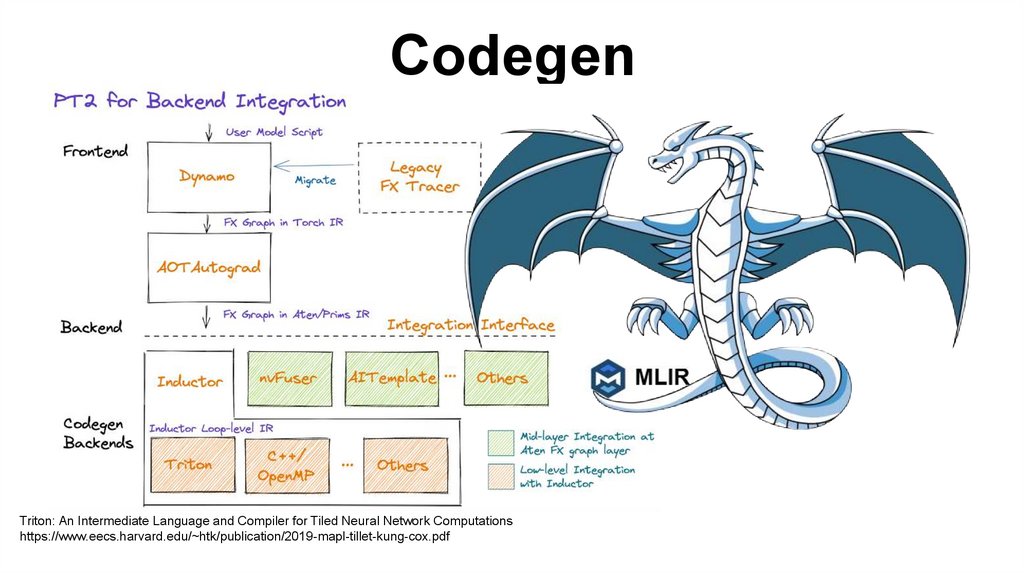
CodegenTriton: An Intermediate Language and Compiler for Tiled Neural Network Computations
https://www.eecs.harvard.edu/~htk/publication/2019-mapl-tillet-kung-cox.pdf
6.
CodegenNo quantization:
Codegen quantization: