













 Программирование
ПрограммированиеПохожие презентации:







")


Построение модели для прогнозирования стоимости квартиры
1.
Программа Повышения КвалификацииАналитик данных: Python и SQL в Big Data
Итоговый проект
Построение модели для прогнозирования
стоимости квартиры
Выполнил: Рослякова Дарья Сергеевна
Номер потока: АДЦ-801
Преподаватель: Туманян Симон
Рафаэлович
2.
Постановка задачи:Построить модель для прогнозирования стоимости квартиры в соответствии со
следующими требованиями:
Программа реализована на языке программирования Python.
Выполнена загрузка и чтение данных из файлов.
Выполнена предварительная обработка данных (очистка и форматирование данных).
Применены методы математической статистики для обработки данных.
Выполнен поиск закономерностей в данных.
Выполнена визуализация данных.
Составлена гипотеза о данных и выполнена проверка соответствующей гипотезы.
Полученные результаты интерпретированы в соответствии с поставленной бизнес-задачей.
3.
Исходные данные:Имеется выборка данных о продаже квартир.
airports_nearest
balcony
ceiling_height
cityCenters_nearest
floor
floors_total
is_apartment
kitchen_area
last_price
living_area
open_plan
parks_around3000
parks_nearest
ponds_around3000
ponds_nearest
rooms
studio
total_area
расстояние до ближайшего аэропорта в метрах (м)
число балконов
высота потолков (м)
расстояние до центра города (м)
этаж
всего этажей в доме
апартаменты (булев тип)
площадь кухни в квадратных метрах (м²)
цена на момент снятия с публикации
жилая площадь в квадратных метрах(м²)
свободная планировка (булев тип)
число парков в радиусе 3 км
расстояние до ближайшего парка (м)
число водоёмов в радиусе 3 км
расстояние до ближайшего водоёма (м)
число комнат
квартира-студия (булев тип)
площадь квартиры в квадратных метрах (м²)
4.
Предобработка данных#Импортируем все необходимые библиотеки
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sb
import scipy.stats as st
#Читаем файл с данными
df = pd.read_csv('home_price.csv')
#Выводим информацию о датасете
print(df.info())
5.
Предобработка данных#Подсчет дублирующихся строк и вывод их количества на экран
print("Количество повторяющихся строк:", df.duplicated().sum())
#В данном датасете найдена одна задвоенная строка, удалим ее
df=df.drop_duplicates()
#Теперь проверим, есть ли в используемом наборе данных пропущенные значения
for col in df.columns:
pct_missing = np.mean(df[col].isna())
print(f'{col} - {round(pct_missing * 100)}%')
#Видим, что есть столбцы с большим количеством пропусков, пока держим эту
информацию в уме и посмотрим на отклонения показателей c помощью гистограмм
6.
Предобработка данныхdf_hist=df.hist(figsize=(15, 20));
#Для удобства просмотра сохраняем гистограммы в файл.png
plt.savefig('Гистограмма.png')
plt.close()
#В полученных гистограммам можем отследить аномальные
значения по каждому показателю. Например, видим, что
высота потолков достигает 100 м.
7.
Предобработка данных#Просмотрев гистограммы, видим, что есть выброс по высоте потолков (до 100 м), ограничим данный
показатель от 2,4 м до 4 м.
#Находим медиану для высоты потолков
median_ceiling_height = float(df['ceiling_height'].median())
print("Медиана высоты потолков:", median_ceiling_height)
#Заменяем значения высоты потолков больше 4 метров на медиану
df['ceiling_height'] = np.where(df['ceiling_height'] > 4, median_ceiling_height, df['ceiling_height'])
#Заменяем значения высоты потолков меньше 2,4 метра на медиану
df['ceiling_height'] = np.where(df['ceiling_height'] < 2.4, median_ceiling_height, df['ceiling_height'])
#Заменяем пустые значения высоты потолков на медиану
df['ceiling_height'] = df['ceiling_height'].fillna(median_ceiling_height)
#Далее уберем пропуски в столбце "всего этажей в доме".
#Находим медиану для этажности домов
median_floors_total = float(df['floors_total'].median())
print("Медиана этажности домов:", median_floors_total)
#Заменяем пустые значения этажности домов на медиану и переводим весь столбец к типу данных "int"
df['floors_total'] = df['floors_total'].fillna(median_floors_total).astype('int')
8.
Предобработка данных#Теперь займемся показателем жилая площадь, в данном столбце около 2000 пропусков. Арифметически из тех
данных, что у нас есть, вычислить значения не получится. Построим тепловую карту из возможных связанных
колонок
#Создадим переменную для выбранных колонок из df
columns = df[["living_area", "total_area","kitchen_area","rooms","last_price"]]
#Создадим переменную для корреляции признаков
corr_matrix = columns.corr()
#Создадим тепловую карту, укажем переменную, где была просчитана корреляция
sb.heatmap(corr_matrix, annot=True, cmap='coolwarm')
plt.savefig('Тепловая карта.png')
plt.close()
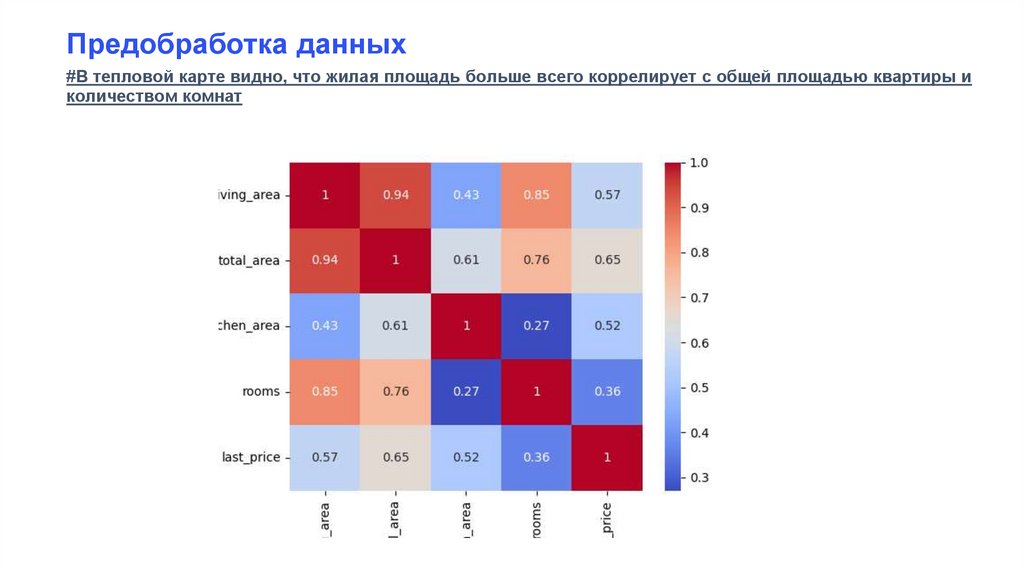
9.
Предобработка данных#В тепловой карте видно, что жилая площадь больше всего коррелирует с общей площадью квартиры и
количеством комнат
10.
Предобработка данных#Идея для нахождения жилой площади состоит в том, чтобы найти усредненное значение одной комнаты и
умножить его на количество комнат
#В колонке с количеством комнат нет пропусков, но есть нулевые значения.Найдем среднюю общую площадь
квартиры,где количество комнат равно нулю
total_area_zero_room=df.loc[df['rooms'] == 0, 'total_area'].mode()
print('Мода квартир с нулевым значением по количеству комнат:',total_area_zero_room)
#Так как мода квартир с нулевым значением по количеству комнат равна 25, то можно заменить нулевые
значения на 1
df['rooms'] = df['rooms'].replace(0,1)
#Посчитаем усредненное значение жилой площади одной комнаты
df1 = round(df.pivot_table(index='rooms', values='living_area', aggfunc='mean')).reset_index()
mean_room_area=round(df1.living_area.sum() / df1.rooms.sum())
print("Средняя площадь одной комнаты:", mean_room_area)
#Для получения жилой площади умножим среднюю площадь комнаты на количество комнат и данной величиной
заменим только пустые значения
living_area=mean_room_area*df['rooms']
df['living_area'] = df['living_area'].fillna(living_area)
#Заменим пустые значения в признаке того, что жилье-аппартаменты на False
df.is_apartment = df.is_apartment.fillna(False)
#Заменяем тип данных на "bool"
df.is_apartment = df.is_apartment.astype(bool)
11.
Предобработка данных#Вычислить пустые значения по площади кухни не представляется возможным, поэтому заменим их на 0
df.kitchen_area = df.kitchen_area.fillna(0)
#Тоже самое сделаем с балконами
df.balcony = df.balcony.fillna(0).astype('int')
#Остальные колонки оставляем без изменений
#Добавим столбец цена за квадратный метр
df['price_per_square_meter'] = df['last_price']/df['total_area']
#Посмотрим информацию о нашем новом столбце с помощью метода describe
describe_ppsm=df['price_per_square_meter'].describe()
print(describe_ppsm.round(3))
#Видим что у нас получились непохожие на реальность максимальное и минимальное значения цены за
квадратный метр. Ограничим эти показатели диапазоном от 50 000 рублей до 500 000 рублей
df = df[(df['price_per_square_meter'] > 50000) & (df['price_per_square_meter'] < 500000)]
12.
Исследовательский анализ данных:#Для более удобного отбражения на графике переведем удаленность от центра из метров в километры
df['cityCenters_nearest']=df['cityCenters_nearest']/1000
#Теперь посмотрим как несколько переменных влияют на цену за квадратный метр, возьмем к примеру
удаленность от центра, количество комнат и общую площадь квартиры
pivot = df.pivot_table(index='price_per_square_meter', values=['total_area','rooms','cityCenters_nearest'])
pivot=pivot.head(500)
sb.scatterplot(data=pivot)
plt.xlabel('Цена за квадратный метр')
plt.ylabel('Удалённость от центра\n Число комнат\n Площадь')
plt.savefig('График зависимости цены за квадратный метр от площади, числа комнат, удалённости от центра.png')
13.
Результаты и выводы:14.
Результаты и выводы:#И напоследок выдвенем нулевую гипотезу, что площадь кухни не зависит от всей площади квартиры
A = df['kitchen_area']
B = df['total_area']
t_stat, p_value = st.ttest_ind(A,B)
print("Т-статистика:", t_stat)
print("р-значения:", p_value)
if p_value > 0.05:
print('Площадь кухни не зависит от всей площади квартиры')
else:
print('Площадь кухни зависит от всей площади квартиры')
15.
Спасибоза внимание!