



















 Информатика
ИнформатикаПохожие презентации:





. Типы статистических данных и способы их первичной обработки")




Исследовательский анализ данных. Нормализация
1.
Лабораторная работа 1: «Исследовательский анализданных. Нормализация»
2.
Гистограмма — это график, который показывает, как часто в наборе данных встречается то или иноезначение. Гистограмма объединяет числовые значения по диапазонам, то есть считает частоту значений в
пределах каждого интервала. Её построение подобно работе знакомого вам метода value_counts(),
подсчитывающего количество уникальных значений в списке. value_counts() группирует строго одинаковые
величины и хорош для подсчёта частоты в списках с категориальными переменными.
3.
4.
5.
6.
Параметр figsize позволяет подобрать наиболее оптимальный размергистограмм, если переменная data содержит несколько колонок
7.
8.
9.
10.
11.
Описывая распределение, аналитики рассчитывают среднее арифметическое или медиануОднако, помимо медианы и среднего, важно знать характерный разброс — то, какие значения
оказались вдали от среднего и насколько их много.
Самое простое, что можно посчитать для оценки разброса, — это минимальное и максимальное
значения. Такое описание не всегда точно, подвержено влиянию выбросов. Гораздо более устойчивая
оценка — межквартильный размах.
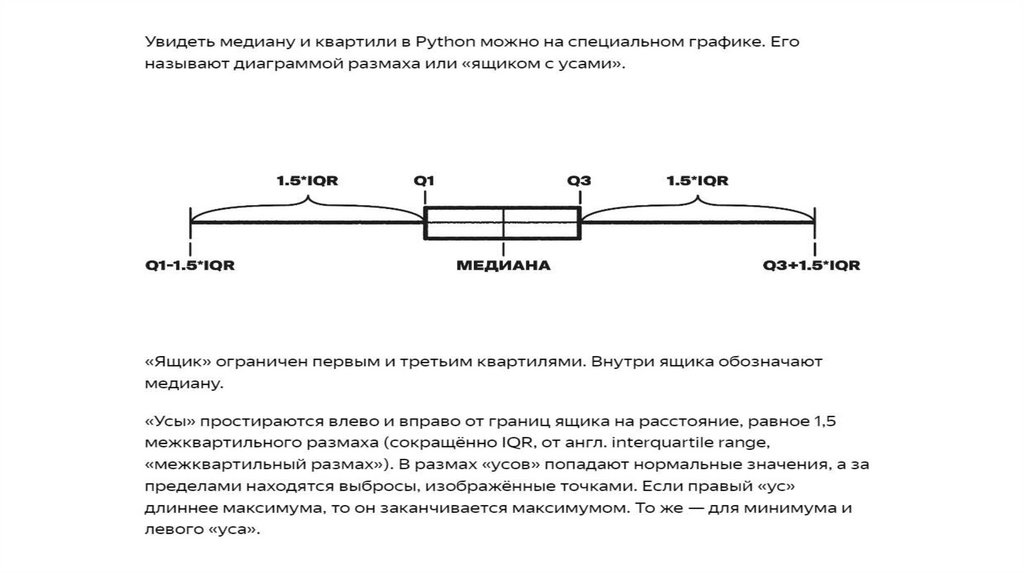
Квартили (от лат. quartus — «четвёртый») разбивают упорядоченный набор данных на четыре части.
Первый квартиль Q1 — число, отделяющее первую четверть выборки: 25% элементов меньше, а 75% —
больше него. Медиана — второй квартиль Q2, половина элементов больше и половина меньше неё.
Третий квартиль Q3 — это отсечка трёх четвертей: 75% элементов меньше и 25% элементов больше него.
Межквартильный размах — это расстояние между Q1 и Q3.
12.
13.
14.
15.
16.
Стандартизация данныхС логарифмированием данных приходится сталкиваться постоянно, независимо от конечной цели: и при построении
регрессии, и при корреляционном и кластерном анализах и при попытках предсказать будущее на временных
данных
Представим, что у нас есть база данных со свежими, только что собранными количественными переменными Y X1 X2
X3. Мы хотим построить линейную множественную регрессию, и стандартно Y выступает как зависимая переменная,
а X1, X2, X3 – как независимые переменные. Но прежде чем переходить к непосредственному построению,
проводится взятие натурального логарифма:
Y -> ln(Y), X1 -> ln(X1), X2 -> ln(X2), X3 -> ln(X3)
Теперь мы строим регрессию с уже новыми показателями ln(Y) на ln(X1) ln(X2) ln(X3)
В каких случаях нам придется прологарифмировать данные?
Собранные переменные имеют разные единицы измерения. Например, Х1 измеряется в тоннах, Х2 – в штуках, Х3 – в
процентах, а зависимая переменная – вообще в рублях. При логарифмировании они стандартизируются в единицы
Даже если переменные имеют одни и те же единицы измерения, они могут быть несимметричны. Внутри одной
переменной есть значения 100000 и 235, либо в Х1 – только большие значения, а в Х3 – в сравнении с Х1 – какие-то
совсем маленькие. Например, населения разных стран, измеряются в одних единицах, но населения Китая и
Люксембурга – несопоставимы
Переменные имеют разные виды распределения, после логарифмирования распределения будут стремиться к
нормальному. А с нормальным распределением всегда работать приятнее
17.
for values in data_log:data[values].apply(lambda x: np.log(x)) # логарифмирование при помощи лямбда функции
18.
19.
20.
21.
Обзор данных.1. Импортируйте библиотеку pandas
2. Импортируйте библиотеку matplotlib.pyplot as plt
3. Импортируйте библиотеку Numpy
4. Прочитайте файл и сохраните его в любой переменной
5. Выведите на экран первые 10 строк таблицы
6. Одной командой выведите информацию о таблице
7. Выведите типы данных по датасету одной командой
8. Выведите количество строк и колонок одной командой
9. Выведите на экран название колонок.
10. С помощью isna посмотрите есть ли пропущенные значения, выведите количество по каждой колонке
11. Проверьте данные на наличие дубликатов. Если есть дубликаты, удалите их.
Какой тип данных доминирует в датасете? Есть ли пропущенные значения и если да, то в каких колонках?
Предобработка и визуализация данных
1. Постройте диаграмму размаха для переменной data, подберите оптимальные параметры figsize. Наблюдаете ли Вы
какие-то аномалии?
2. Нарисуйте гистограмму для переменной data. Подберите оптимальные значения параметров bins и figsize. Выедите
гистограмму с помощью команды plt.show.
3. С помощью команды data.select_dtypes выберите все данные которые относятся к числовым (обращение к
технической документации)
4. С помощью лямбда функции проведите логарифмирование числовых данных, при логорифмировании прибавьте
единицу.
5. C помощью конструкции
for values in data_log:
data.boxplot(column=values)….постройте диаграммы размаха и гистограммы для отлогарифмированных значений.