






























 Программное обеспечение
Программное обеспечениеПохожие презентации:










Суперкомпьютер. Понятие информационных технологий и их характерные черты
1.
ПланВопрос 1. Понятие информационных
технологий и их характерные черты.
Вопрос 2. Информатизация общества,
понятие и основные термины.
2.
Введение.Суперкомпьютер — специализированная
вычислительная машина, имеющая высокий
уровень производительности по сравнению с
широко распространёнными ЭВМ.
Используемые в настоящее время
суперкомпьютеры представляют собой большое
число объединенных высокопроизводительных
серверных компьютеров для достижения
максимальной производительности в рамках
подхода распараллеливания вычислительной
задачи.
3.
Производительность суперкомпьютеровизмеряется в операциях с плавающей
запятой в секунду (FLOPS) вместо
миллиона инструкций в секунду (MIPS)
– как это вычисляют для обычных ЭВМ.
В 2017 году был создан суперкомпьютер,
который имеет производительность до
ста квадриллионов (1015) FLOPS.
4.
FLOPS (flops, flop/s) — внесистемнаяединица, показывающая, сколько
операций с плавающей запятой в секунду
выполняет вычислительная система.
Современные компьютеры обладают
высоким уровнем производительности,
производные величины от FLOPS,
образуемые путём использования
приставок СИ
5.
IPS (инструкций в секунду) — мера быстродействия процессоракомпьютера - показывает число определённых инструкций,
выполняемых процессором за одну секунду.
Вместо исходных значений IPS часто принято использовать
результаты синтетических тестов (benchmark).
Производные единицы измерения СИ:
1 kIPS = 103 IPS;
1 MIPS = 106 IPS (million IPS) или 1 MOPS (million operations per second);
1 GIPS = 109 IPS;
1 TIPS = 1012 IPS.
6.
По состоянию на 2020 год все наиболее быстрые суперкомпьютеры вмире работают под управлением операционных систем семейства
Linux.
Основные страны, которые производят суперкомпьютеры:
Китай, США; страны ЕС, Тайвань; Япония.
Суперкомпьютеры применяются при решении задач в области:
- вычислительных наук,
- квантовой механики,
- прогнозирования погоды,
- исследования климата, нефти и газа,
- молекулярного моделирования,
- физического моделирования,
- в области криптоанализа.
7.
Вопрос 1. История суперкомпьютеровВпервые термин "суперкомпьютер" был
использован в Нью-Йорке в 1929 году для
обозначения большого количества упорядоченных
папок(каталогов), который IBM сделала для
Колумбийского университета.
В 1956 году ученые из Манчестерского
университета в Великобритании начали разработку
MUSE — микросекундного двигателя — с целью
возможного создания компьютера, который мог бы
работать со скоростью обработки,
приближающейся к миллиону операций в секунду.
8.
Первый Atlas был официальновведен в эксплуатацию 7
декабря 1962 года, почти за
три года до того, как
суперкомпьютер Cray и
суперкомпьютер CDC 6600
были представлены в качестве
одних из первых
суперкомпьютеров в мире - и
был признан самым мощным
компьютером Англии.
9.
В 1960 году Sperry Corporation решили создать суперкомпьютер. После четырехлет экспериментов Джима Торнтона, Дина Раша и около 30 других инженеров
Сеймур Крэй создал CDC 6600 в 1964 году на кремниевых транзисторах.
CDC 6600 превосходил по мощности все компьютеры того времени примерно в
10 раз и был назван суперкомпьютером.
Все 100 экземпляров были проданы по 8 миллионов долларов каждый.
CDC 6600 имел производительность 500 kFLOPS при стандартных
математических операциях.
10.
В 1968 году Крей создал CDC 7600 – он был в 4 разабыстрее CDC 6600.
Он покинул CDC в 1972 году и через два года
представил Star-100 , который был в три раза быстрее
CDC 7600.
Star-100 стала одной из первых машин, использующих
векторную обработку - идея, появившаяся в 1964 году
после разработки языка программирования APL.
В 1976 году Крэй представил Сrei-1 самый успешный
суперкомпьютер в истории 80 MFLOPS.
Cray-2 (8 процессоров), выпущенный в 1985 году,
имел 4 компьютерных процессора с жидкостным
охлаждением 1,9 GFLOPS.
11.
SX-3/44R был анонсирован корпорацией NEC в1989 году и через год заработал титул самой
быстрой в мире 4-процессорной модели 0.0256
TFLOPS.
Суперкомпьютер Fujitsu использовал 166
векторных процессоров, занял первое место
среди суперкомпьютеров в 1994 году. Он имел
пиковую скорость 1,7 GFLOPS на процессор.
Hitachi SR2201, 1996 г., производительность 600
GFLOPS с 2048 процессорами, подключенными
через быструю трехмерную сеть.
12.
В те же сроки выпущен Intel Paragonимел от 1000 до 4000 процессоров Intel
i860 и был признан самым быстрым в
мире в 1993 году.
В 2004 году - Earth Simulator,
построенный NEC в Японском агентстве
морской науки и техники, достиг 35,9
TFLOPS, используя 640 узлов, каждый с
восемью собственными векторными
процессорами.
13.
Архитектура суперкомпьютера IBM BlueGene может использовать более 60000
процессоров с 2048 сопроцессорами и
соединяет их через трехмерное торическое
соединение.
После 2014 года данные о суперкомпьютерах
были засекречены, но известно, что уже по
состоянию на 2015 год многие
существующие суперкомпьютеры обладают
большей пропускной способностью
инфраструктуры, чем фактический спрос.
14.
Отечественные суперкомпьютерыВ 1985 году прошел испытания опытный образец
«Электроника СС БИС-1» с одним процессором,
показав производительность в 250 MFLOPS.
В 1991 году состоялись испытания системы с
первой версией операционной системы. Одна из
машин была соединена в двухмашинный
комплекс. Пиковая производительность системы
в двухмашинном варианте составляла 500
MFLOPS.
15.
В 2002 г. в список 500 наиболеепроизводительных компьютеров мира (Тор500)
впервые вошел российский суперкомпьютер
МВС-1000М, заняв 74-е место и имеющий
производительность 735 GFLOPS.
Суперкомпьютер построен на процессорах Alpha,
число процессоров 768. Объем оперативной
памяти системы — 768 Гбайт. Система работает
под управлением операционной системы Red Hat
Linux 6.2, поддерживающей многопроцессорные
системы.
16.
В списке Тор500 2004 года на 210месте новый российский компьютер
МВС-5000БМ производительностью
1,4 TFLOPS, выполненный как
BladeServer на 336 микропроцессорах
PowerPC 1,6 ГГц, коммутирующая
система Myrinet.
17.
В 2008 г. в России построенсуперкомпьютер "СКИФ МГУ". Его
пиковая производительность 60 TFLOPS,
в нем использованы 1250
четырехъядерных процессоров Intel Xeon
E5472. Оперативная память 5,5 Тбайт,
системная - InfiniBand, площадь 96 м2,
потребляемая мощность - 330 кВт.
18.
В 2009 году в МГУ состоялась презентация суперкомпьютераЛомоносов. В 2011мощность суперкомпьютера «Ломоносов» 1,3
PFLOPS – 13 место в международном рейтинге TOP500 по
состоянию на июнь 2011 года.
Пиковая производительность 1,7 PFLOPS
число CPU/Core — 12346/52168
RAM — 92 Tb
HDD — 1,75 Pb
(Xeon X5570/X5670 2.93 GHz, Nvidia 2070 GPU)
Обновление от 06/2012
Xeon X5570/X5670/E5630 2.93/2.53 GHz, Nvidia 2070 GPU,
PowerXCell 8i (Top500)
число ядер : 78660
пиковая производительность: 1700,2 Тфлопс
19.
Вопрос 2. Принципы организациисуперкомпьютеров
Базовая кластерная архитектура
Основополагающим
принципом
создания
суперкомпьютеров
является
построение
масштабируемой кластерной архитектуры на
основе
компонент
широкого
применения
(стандартных микропроцессоров, модулей памяти,
жестких дисков и материнских плат, в том числе с
поддержкой SMP - архитектура многопроцессорных
компьютеров).
20.
Кластерный архитектурный уровень представляет собой тесно связанную сеть(кластер) вычислительных узлов, работающих под управлением операционной
системы.
Для организации параллельного исполнения задач с подобными фрагментами
наиболее адекватна модель потоковых вычислений (data-flow).
Кластерная архитектура является открытой и масштабируемой.
Для организации взаимодействия вычислительных узлов суперкомпьютера в его
составе используются аппаратные и программные сетевые средства, образующие
две системы передачи данных:
1.
Системная сеть кластера (СС) или System Area Network (SAN)
объединяет узлы данного уровня в кластер. Системная сеть кластера строится на
основе программной поддержки на уровне ОС Linux и систем организации
параллельных вычислений (Т-систем, MPI);
2.
Вспомогательная сеть суперкомпьютера (ВС) с протоколом TCP/IP
объединяет узлы кластерного уровня в обычную (TCP/IP) локальную сеть
(TCP/IP LAN). Вспомогательная сеть предназначена для управления системой,
подключения рабочих мест пользователей, интеграции суперкомпьютера в
локальную сеть предприятия и/или в глобальные сети.
21.
Операционная системаРанние операционные системы были
специально адаптированы к каждому
суперкомпьютеру для увеличения скорости.
Современная тенденция заключается в
переходе к Linux.
Современные массивно-параллельных
суперкомпьютеры, как правило, оснащены
различными операционными системами на
разных узлах.
22.
Каждый производитель имеет своюсобственную производную Linux.
23.
Уровнями распараллеливания вычислительной задачиРаспараллелить решение задачи можно на нескольких уровнях. Приведем
несколько уровней распараллеливания.
Распараллеливание на уровне задач
Часто распараллеливание на этом уровне является самым простым и при этом
самым эффективным.
Такое распараллеливание возможно в тех случаях, когда решаемая задача
состоит из независимых подзадач, каждую из которых можно решить отдельно.
24.
Распараллеливание на уровне задачосуществляет операционная система, запуская на
многоядерной машине программы на разных
ядрах.
Но если компьютер решает однородную задачу данный вид распараллеливания не применим
(операционная система не может ускорить
программу, использующую только одно ядро,
сколько бы ядер ни было бы при этом доступно).
Что бы распараллелить однородные задачи,
нужно спуститься на уровень ниже.
25.
Уровень параллелизма данныхМодель «параллелизма данных» заключается в возможности применения одной и той же
операции к множеству элементов данных.
Например - архиватор, использующий для упаковки изображения несколько ядер
процессора (данные разбиваются на блоки, которые единообразным образом
обрабатываются (упаковываются) на разных узлах).
Данный вид параллелизма широко используется при решении задач численного
моделирования (ГЕОМЕТРИЧЕСКИЙ ПАРАЛЛЕЛИЗМ)
26.
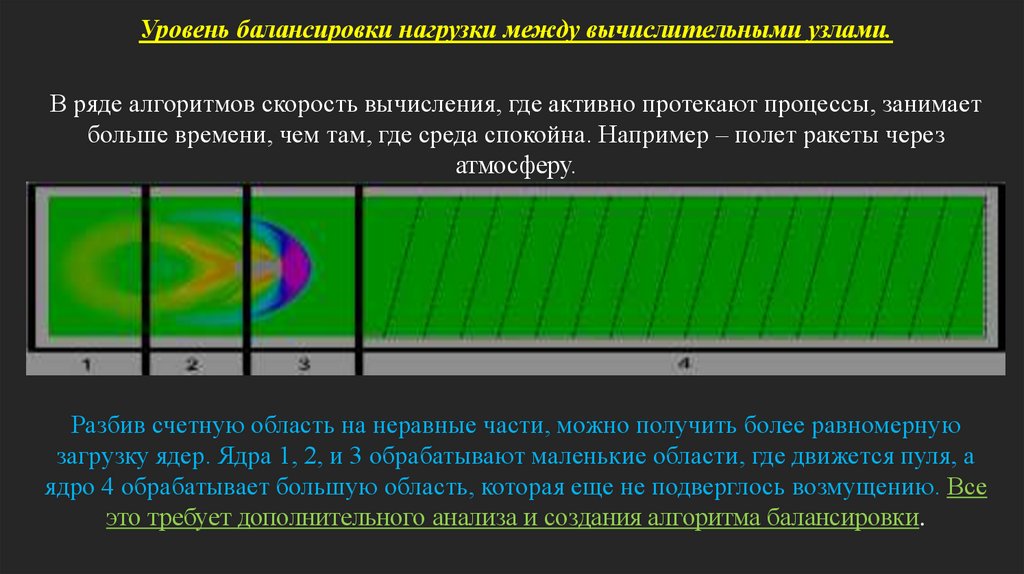
Уровень балансировки нагрузки между вычислительными узлами.В ряде алгоритмов скорость вычисления, где активно протекают процессы, занимает
больше времени, чем там, где среда спокойна. Например – полет ракеты через
атмосферу.
Разбив счетную область на неравные части, можно получить более равномерную
загрузку ядер. Ядра 1, 2, и 3 обрабатывают маленькие области, где движется пуля, а
ядро 4 обрабатывает большую область, которая еще не подверглось возмущению. Все
это требует дополнительного анализа и создания алгоритма балансировки.
27.
Уровень распараллеливания процедур и алгоритмовНа этом уровне используют технологию параллельного программирования,
например OpenMP.
OpenMP — это набор директив компилятора, библиотечных процедур и
переменных окружения, которые предназначены для программирования
многопоточных приложений на многопроцессорных системах.
В OpenMP используется модель параллельного выполнения «ветвлениеслияние»:
1. Программа начинает работу, как единственный поток выполнения начальный поток.
2. Если поток встречает параллельную конструкцию, он создает новую группу
потоков, состоящую из себя и некоторого числа дополнительных потоков.
3. В конце параллельной конструкции имеется неявный барьер.
4. После параллельной конструкции выполнение пользовательского кода
продолжает только главный поток.
Существует достаточно большое количество библиотек параллельных
алгоритмов, позволяющих строить программы как из кубиков, не вдаваясь в
устройство реализаций параллельной обработки данных.
28.
Уровень инструкций (битов)Уровень инструкция - наиболее низкий уровень параллелизма, осуществляемый на уровне
параллельной обработки процессором нескольких инструкций.
На этом же уровне находится пакетная обработка нескольких элементов данных одной командой
процессора (MMX, SSE, SSE2 и так далее).
Иногда выделяют в еще более глубокий уровень распараллеливания – параллелизм на уровне битов.
Программа представляет собой поток инструкций, выполняемых процессором, в котором:
- можно изменить порядок этих инструкций;
- распределить их по группам, которые будут выполняться параллельно, без изменения результата
работы всей программы.
Для реализации данного вида параллелизма в микропроцессорах используются:
- несколько конвейеров команд;
- технология предсказание команд;
- технология переименование регистров.
Данный уровень параллели выполняется не программистом, а компилятором или интерпретатором.
29.
Для суперкомпьютеров есть свои подходы к выполнению параллельныхвычислений.
Конъюнктурный подход
Оппортунистические суперкомпьютеры — это форма сетевых grid-вычислений (форма
распределённых вычислений, в которой «виртуальный суперкомпьютер» представлен в виде
кластеров) при которой "супер-виртуальный компьютер" в системе нескольких слабо
связанных вычислительных машин выполняет масштабные вычислительные задачи.
Самыми быстрыми системами grid-вычислений является:
- проект распределенных вычислений Folding@home (F@h) - 101 PFLOPS процессорной
мощности x86 (из них более 100 PFlop-операций выполняются клиентами, работающими на
различных графических процессорах, а остальные — на различных системах);
- платформа Berkeley Open Infrastructure for Network Computing (BOINC) - вычислительную
мощность более 166 петафлопс через более 762 тысяч активных компьютеров (хостов) в сети;
- Great Internet Mersenne Prime Search's (GIMPS) представил проект вычислений при помощи
простого числа Мерсенна, поиск с использованием которой достиг около 0,313 PFLOPS более
чем на 1,3 миллиона компьютеров.
30.
Квази-конъюнктурный подходКвази-конъюнктурный подход - форма распределенных вычислений, в
которой:
- "супервиртуальный компьютер"
- в сети нескольких объединенных компьютеров, удаленных физически
друг от друга,
- выполняет вычислительные задачи, которые требуют огромной
вычислительной мощности.
Подобный вычислительный метод призван обеспечить более высокое
качество обслуживания, чем оппортунистические grid-вычисления за
счет:
- достижения большего контроля над назначением задач на
распределенные ресурсы;
- использования информации о доступности и надежности отдельных
систем внутри суперкомпьютерной сети.
31.
HPC в облаке32.
Распределение по количеству суперкомпьютеров в разных странах мира:Китай — 206
США — 124
Япония — 36
Великобритания — 22
Германия — 21
Франция — 18
Нидерланды - 9
Ю.Корея - 7
Ирландия - 7
Канада - 6
другие страны — 44 (включая Россию - 4, пик количества
суперкомпьютерных систем в России пришелся на июнь 2011 года - 12
шт.).