



































 Информатика
ИнформатикаПохожие презентации:








")

Технологии структурирования данных. Табличные данные
1.
Кафедра Прикладной математикиИнститута информационных технологий
РТУ МИРЭА
Дисциплина
«Большие данные»
2023-2024 у.г.
1
2.
Лекция 2. Технологииструктурирования данных.
Табличные данные
2
3.
Часть 1. Обзор и классификациятипов данных. Файлы данных
3
4.
Материал части1. Типы данных в обработке информации
2. Бинарный тип данных.
3. Целые числа (хранение в компьютерных
системах, примеры применения)
4. Вещественные числа (хранение в компьютерных
системах, примеры применения)
5. Строковые данные.
6. BLOB
7. Популярные файлы данных
8. Txt
9. Csv, tsv, prn
10. Json
11. Yaml
12. Excel
4
5.
Типы данныхТип данных — атрибут, определяющий, какого
рода данные могут храниться в объекте: целые
числа, символы, данные денежного типа,
метки времени и даты, двоичные строки и так
далее.
Названия типов данных зачастую различаются
от системы к системе.
В зависимости от характера значений все типы
данных можно разделить на группы:
числовые;
дата и время;
строковые;
бинарные;
5
6.
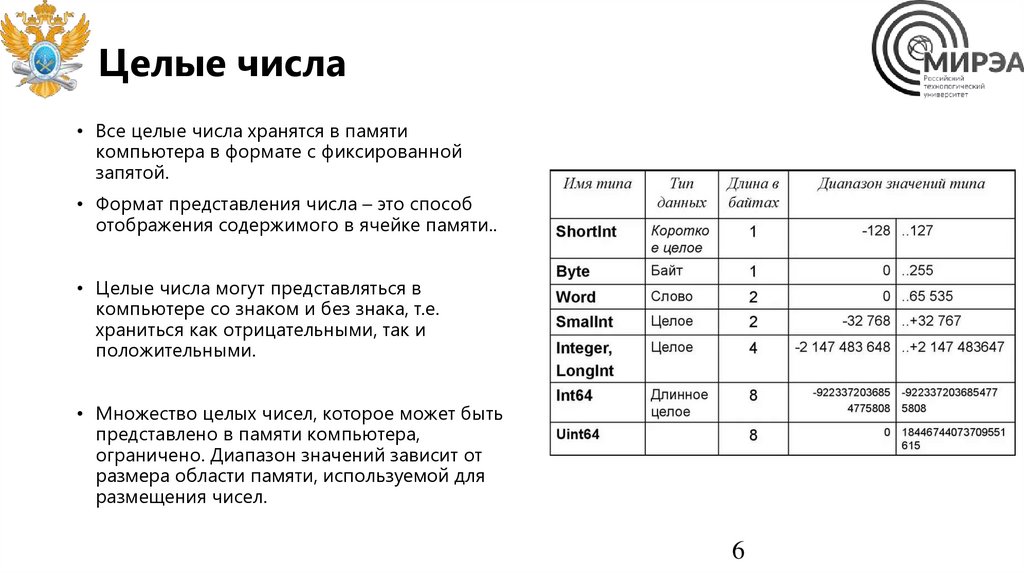
Целые числа• Все целые числа хранятся в памяти
компьютера в формате с фиксированной
запятой.
• Формат представления числа – это способ
отображения содержимого в ячейке памяти..
• Целые числа могут представляться в
компьютере со знаком и без знака, т.е.
храниться как отрицательными, так и
положительными.
• Множество целых чисел, которое может быть
представлено в памяти компьютера,
ограничено. Диапазон значений зависит от
размера области памяти, используемой для
размещения чисел.
6
7.
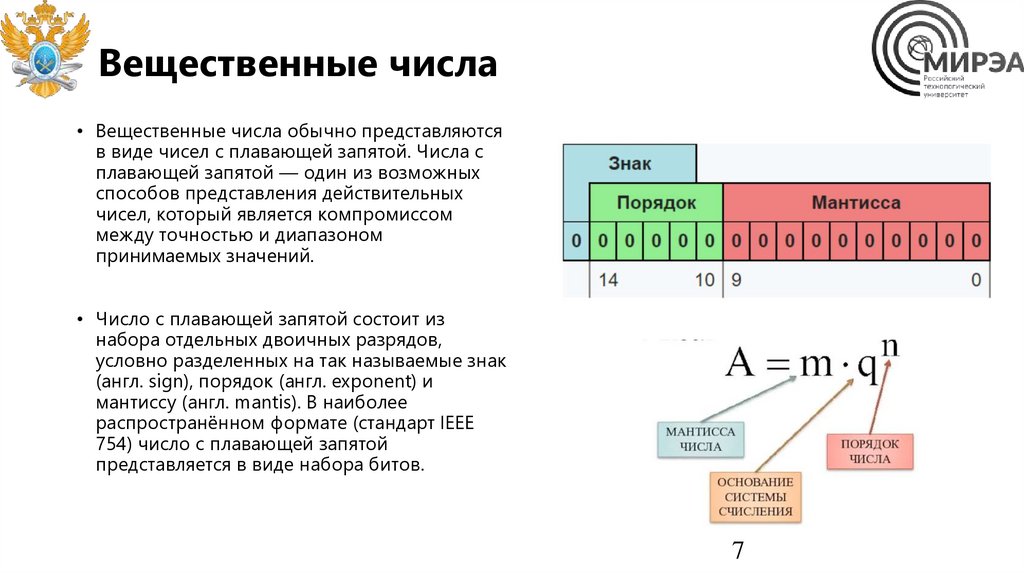
Вещественные числа• Вещественные числа обычно представляются
в виде чисел с плавающей запятой. Числа с
плавающей запятой — один из возможных
способов представления действительных
чисел, который является компромиссом
между точностью и диапазоном
принимаемых значений.
• Число с плавающей запятой состоит из
набора отдельных двоичных разрядов,
условно разделенных на так называемые знак
(англ. sign), порядок (англ. exponent) и
мантиссу (англ. mantis). В наиболее
распространённом формате (стандарт IEEE
754) число с плавающей запятой
представляется в виде набора битов.
7
8.
Строковые данные• Строковый тип — тип данных, значениями которого
является произвольная последовательность (строка)
символов некоторого алфавита. Каждая переменная
такого типа может быть представлена
фиксированным количеством байтов либо иметь
произвольную длину.
• В представлении строк в памяти компьютера
существует два разных подхода:
представление массивом символов (char или
varchar);
метод «завершающего байта» — одно из
возможных значений символов алфавита
выбирается в качестве признака конца строки. В
качестве признака конца строки используются
символ 0, байт 0xFF (255) или код символа «$».
8
9.
Дата/время• Формат дата/время хранит информацию о времени
снятия измерения.
• Тип данных DATE используется для величин с
информацией только о дате в формате 'YYYY-MMDD'. При обработке данных допускаются и другие
форматы, которые обычно интерпретируются
разработчиком или аналитиком.
• Тип данных DATETIME используется для величин,
содержащих информацию как о дате, так и о
времени в формате 'YYYY-MM-DD HH:MM:SS'.
Формат также может быть изменён в зависимости от
стандарта хранения.
• Также стоит обратить внимание на стандарт
хранения времени timestamp
timestamp - это последовательность
символов или закодированной
информации, показывающей, когда
произошло определённое событие.
Обычно показывает дату и время (иногда
с точностью до долей секунд).
Формат UNIX timestamp предусматривает
отсчет в секундах от заданной даты.
Применяется во многих задачах обработки
данных.
9
10.
Бинарный тип данныхЭти типы данных используются для
хранения необработанных двоичных
данных длиной до 8,000 байт. Содержимое
файлов изображений (файлы формата
BMP, TIFF, GIF или JPEG), текстовых файлов
и т.д. являются примерами двоичных
данных.
Основные бинарные типы:
• binary (последовательность байтов
фиксированной длины n);
• varbinary (последовательность байтов
переменной длины n).
10
11.
BLOB (Binary Large Object)• BLOB – большой двоичный объект. Он
представляет строку переменной длины,
значение которой составляет до
2,147,483,647 символов.
• При помощи BLOB можно хранить
данные, которые не могут размещаться в
полях иного типа. Сюда относят:
• музыку;
• аудиозаписи;
• картинки;
• анимацию;
• иные компоненты.
11
12.
Популярные расширения файловданных
Среди наиболее популярных расширений для
различных файлов можно выделить
следующие:
• для текстовых данных: txt, csv, json, tsv,
prn, yaml;
• для документов: docx, xlsx, pptx, pdf, odt, ods;
• для архиваторов: rar, zip, tar, 7z, gz;
• для программ: exe, cmd, msi, bin, bat;
• для видео: mp4, avi, webm, mov;
• для аудио: mp3, wav, ogg;
• для изображений: giv, jpeg, png, bmp.
12
13.
Часть 2. Мультимедийнаяинформация, файлы
медиаформата
13
14.
Материал части1. Медиаданные, понятие, определение
2. Субъективное восприятие медиаинформации
3. Текстовые данные
4. Задачи, решающиеся на основе текстовых
данных
5. Аудиоданные
6. Задачи, решающиеся на основе аудиоданных
7. Изображения
8. Задачи обработки и анализа изображений
9. Проблема поиска структуры в
медиаинформации
10. Хранение медиаинформации в различных
популярных форматах
14
15.
Медиаданные• Медиаданные — неструктурированная,
в общем виде, информация,
естественная для человеческого
осознания и осязания.
• Примеры медиаданных:
1. визуализация данных,
2. изображения,
3. видео,
4. аудио
5. текст
6. объемные представления (3D сцены).
• Предназначение данных медиаформата
состоит в передаче и хранении
естественной для человека информации
в цифровой форме.
15
16.
Текстовые данные• Текстовые данные — представление
информации строкового типа (то есть,
последовательности печатных символов) в
вычислительной системе.
Существуют разные способы кодирования
символов:
• кодировка ASCII. При использовании этой
кодировки для представления каждого
символа отводится ровно 8 разрядов (один
байт).
• кодировка Unicode. В этом коде все символы
состоят из 16 битов.
В Unicode каждому коду соответствует
единственный символ, коды не пересекаются
для разных языков.
Рисунок. Анализ статей Хабрахабр и
Geektimes от 2017-02-05
16
17.
Хранение текстовых данных• Хранятся текстовые данные в нескольких
удобных форматах:
1. В таблицах текстовые данные хранятся в
виде записи в столбце показателя
строкового типа данных.
2. В файлах директорий располагают
корпусы документов, статей,
индексированные инструментами
полнотекстового поиска по документам.
3. Для анализа данных текстовая
информация преобразуется и хранится в
виде векторов чисел для каждого слова
или вектором чисел для документа в
зависимости от задачи.
Рисунок. Ruscorpora — Корпус текстов русского языка для
решения задач анализа текстов
17
18.
Обработка текстовых данных• Задачи обработки текста
заключаются в преобразовании
текстовой информации в удобный для
анализа данных вид
структурированной или
векторизованной информации.
Рисунок. Представление документа в виде
структурированного набора данных.
1. Структуризация текстовых данных
2. Векторизация текста
3. Генерация признаков на основе текста
4. Стемминг, лемматизация
5. Очистка текста от ошибок
Рисунок. Векторизация слов и поиск
взаимосвязей Word2Vec.
Рисунок. Стемминг и лемматизация
18
19.
Анализ текстовых данных• Задачи анализа текста:
1. Сбор и классификация отзывов
2. Анализ тональности текста
3. Поиск смысла в тексте
4. Кластеризация документов
5. Генерация текста на заданную тему
6. Автодополнение поисковых запросов
Рисунок. Классификация текста.
7. Поиск именованных сущностей,
ключевых слов
8. Сегментация текста
• Популярные решения:
• GitHub Copilot,
• Яндекс, Mail, DuckDuckGo
• Алиса, Маруся, Салют
Рисунок. Кластеризация текста.
19
20.
Данные формата аудио• Аудиоданные — это разновидности
файлов, предназначенные для хранения
цифровых аудиоданных в компьютерной
системе.
• Аудиофа́йл (файл, содержащий
звукозапись) — компьютерный файл,
состоящий из информации об амплитуде и
частоте звука, сохраненной для
дальнейшего воспроизведения на
компьютере или проигрывателе.
20
21.
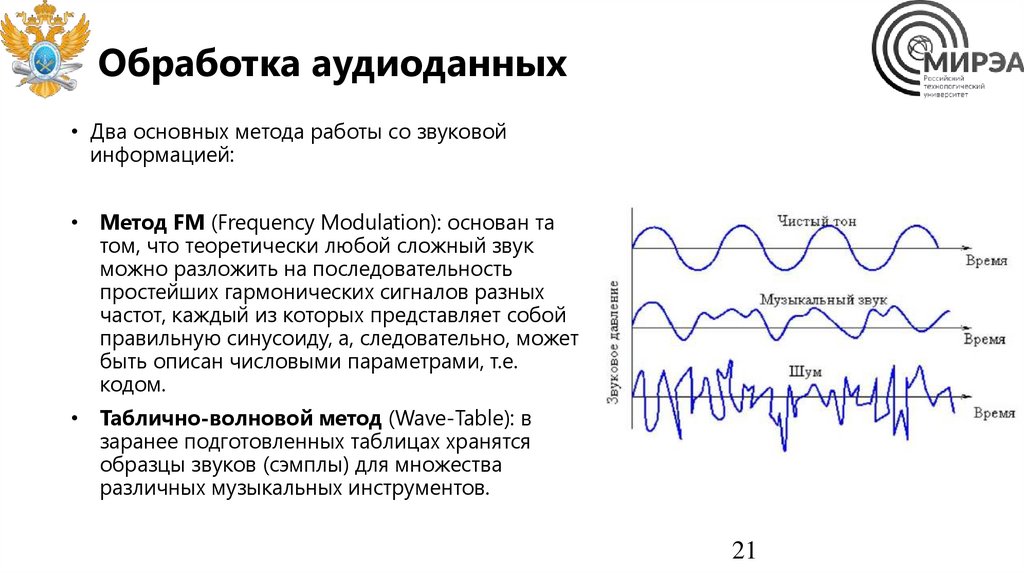
Обработка аудиоданных• Два основных метода работы со звуковой
информацией:
• Метод FM (Frequency Modulation): основан та
том, что теоретически любой сложный звук
можно разложить на последовательность
простейших гармонических сигналов разных
частот, каждый из которых представляет собой
правильную синусоиду, а, следовательно, может
быть описан числовыми параметрами, т.е.
кодом.
• Таблично-волновой метод (Wave-Table): в
заранее подготовленных таблицах хранятся
образцы звуков (сэмплы) для множества
различных музыкальных инструментов.
21
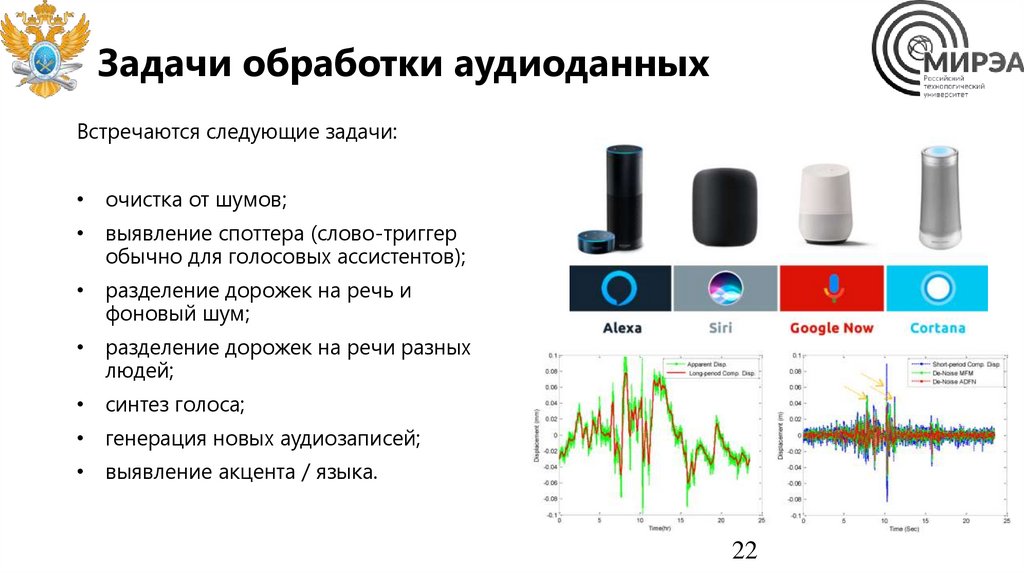
22.
Задачи обработки аудиоданныхВстречаются следующие задачи:
• очистка от шумов;
• выявление споттера (слово-триггер
обычно для голосовых ассистентов);
• разделение дорожек на речь и
фоновый шум;
• разделение дорожек на речи разных
людей;
• синтез голоса;
• генерация новых аудиозаписей;
• выявление акцента / языка.
22
23.
Данные изображений и видео23
24.
Задачи для данных изображений ивидео
• • Бинаризация: преобразует изображение
в серых тонах в бинарное (белые и
черные пиксели);
Сегментация: используется для поиска
и/или подсчета деталей;
Чтение штрихкодов: декодирование 1D и
2D кодов, разработанных для считывания
или сканирования машинами;
Оптическое распознавание символов:
автоматизированное чтение текста,
например, серийных номеров;
Обнаружение краев: поиск краев
объектов
Сопоставление шаблонов: поиск,
подбор, и/или подсчет конкретных
моделей.
24
25.
Часть 3. Проблема нарастающегообъема данных
25
26.
Умные устройства• Миллионы абонентов умных устройств в
фоновом режиме отправляют на сервер
разработчика диагностические данные о
состоянии, ошибках, и т.д.
Устройства объединяются в сети и
интегрируются у отдельных абонентов в
различных конфигурациях, что приводит
к конфликтным ситуациям, которые
помогает решить анализ данных.
Предпочтения пользователя
анализируются для большей
клиентоориентированности.
26
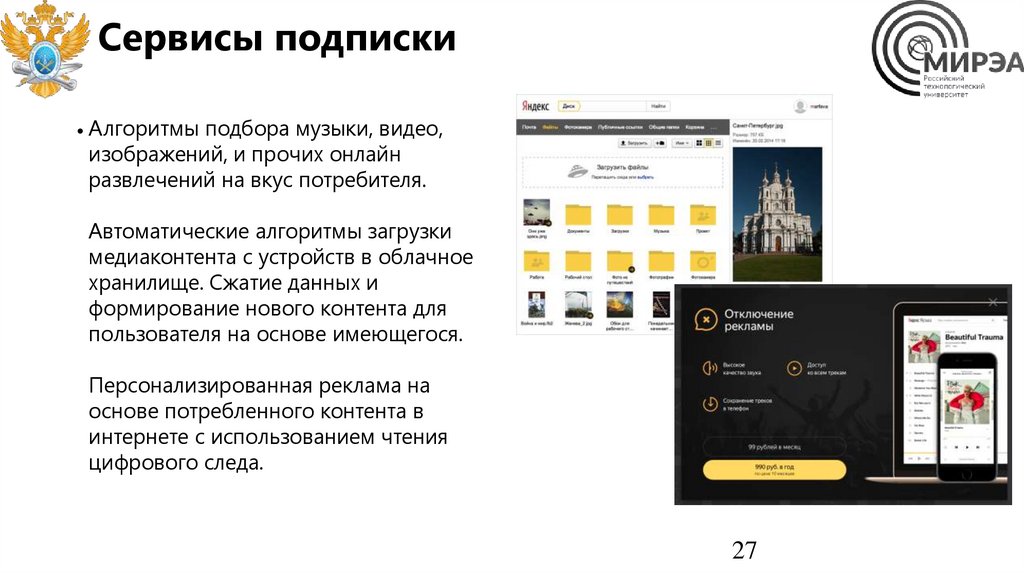
27.
Сервисы подписки• Алгоритмы подбора музыки, видео,
изображений, и прочих онлайн
развлечений на вкус потребителя.
Автоматические алгоритмы загрузки
медиаконтента с устройств в облачное
хранилище. Сжатие данных и
формирование нового контента для
пользователя на основе имеющегося.
Персонализированная реклама на
основе потребленного контента в
интернете с использованием чтения
цифрового следа.
27
28.
Сельское хозяйство• • Подсчет продукции
• Распознавание растений
• Мониторинг животных
• Автоматизация ферм
• Контроль условий в зоне посадок.
• Обнаружение поврежденной
продукции
28
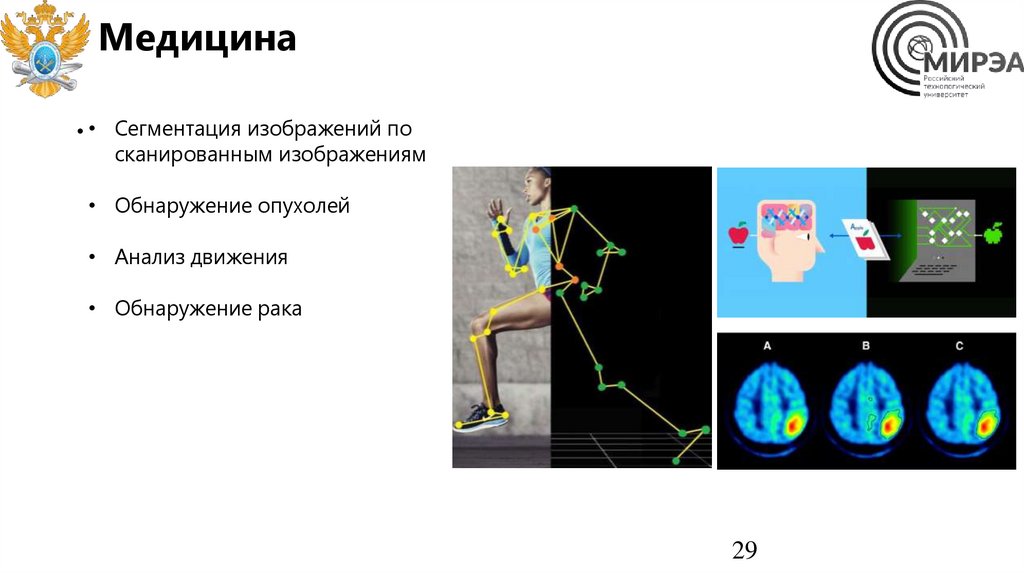
29.
Медицина• • Сегментация изображений по
сканированным изображениям
• Обнаружение опухолей
• Анализ движения
• Обнаружение рака
29
30.
Розничная торговля• • Предсказание повторного
визита клиента
• Анализ профилей клиентов
• Анализ продуктовой корзины
• Логистика
• Современные тренды в
обществе
• Создание новых брендов
30
31.
Часть 4. Скорость обработкибольших объёмов данных
31
32.
Материал части1. Проблема скорости последовательной
обработки данных
2. Пример задачи последовательной записи
данных
3. Решение задачи с помощью параллельной
обработки данных
32
33.
Скорость обработки данныхВсе вычислительные задачи, решаемые на
компьютерных системах, опираются на
процессорные вычисления и локальные
хранилища данных.
Однопроцессорные вычисления способны
обработать значительное число информации
за короткое время в масштабах локальных
персональных исследований (гигабайты
данных).
Для обработки современных больших данных
(петабайты) каждый день этого недостаточно.
Требуется внедрять вычисления на нескольких
процессорах и запись на несколько дисков.
33
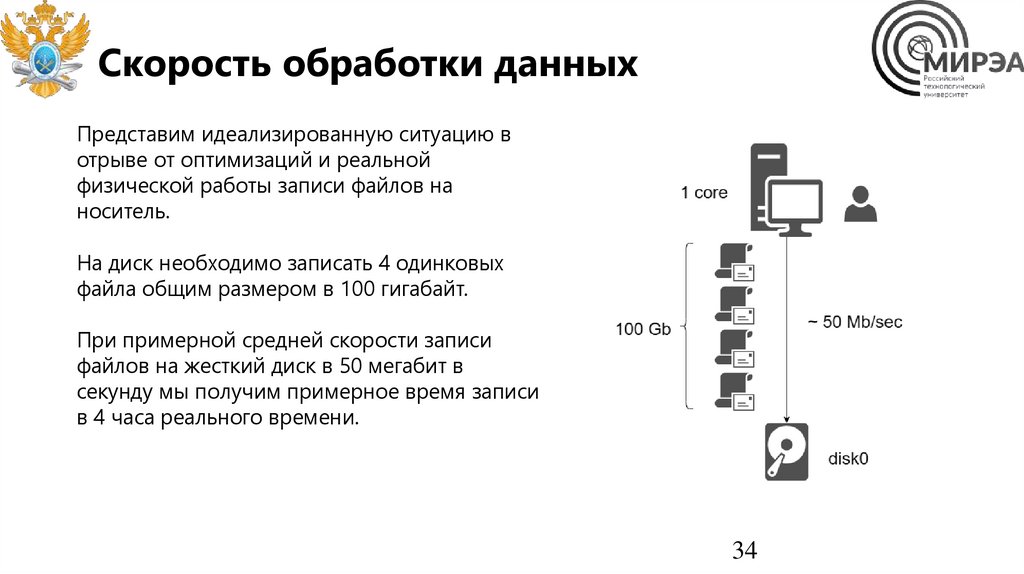
34.
Скорость обработки данныхПредставим идеализированную ситуацию в
отрыве от оптимизаций и реальной
физической работы записи файлов на
носитель.
На диск необходимо записать 4 одинковых
файла общим размером в 100 гигабайт.
При примерной средней скорости записи
файлов на жесткий диск в 50 мегабит в
секунду мы получим примерное время записи
в 4 часа реального времени.
34
35.
Последовательная и параллельнаяобработка данных
• Последовательная: один процессор
выполняет одну задачу в заданное время, а
другие задачи ждут в очереди. В
операционной системе может быть запущено
несколько программ, и каждая программа
имеет несколько запущенных задач. В этом
случае все задачи разных программ
передаются процессору через регистры и
обрабатываются последовательно.
Параллельная: несколько задач выполняются
одновременно разными исполнителями.
Операционная система, работающая на
многоядерном процессоре, является примером
параллельной операционной системы.
35
36.
Параллельная обработки данныхПредоставим нашему тестовому стенду общее
хранилище с 4-мя физическими носителями.
Предположим, что наша программная система
умеет записывать разные файлы с
использованием разных ядер на разные
устройства хранения.
На диск необходимо записать 4 одинаковых
файла общим размером в 100 гигабайт.
При примерной средней скорости записи
файлов на жесткий диск в 50 мегабит в
секунду мы получим примерное время записи
в 1 час реального времени.
36
37.
Последовательная, параллельная,распределенная обработка данных
Распределённая обработка данных - методика выполнения прикладных программ группой
систем (узлов, компьютеров, устройств).
Пользователь получает возможность работать с сетевыми службами и прикладными
процессами, расположенными в нескольких взаимосвязанных системах.
Тип
Последовательная
Параллельная
Распределенная
Процессоров
1
1
Больше 1
Синхронизация
Нет
Процессов
Данных и
процессов
Масштабируемость
Замена процессора
Замена процессора
Добавление узлов в
распределенную
систему, замена
процессора
37
38.
Распределенная обработка данных38
39.
Распределенная обработка данных39
40.
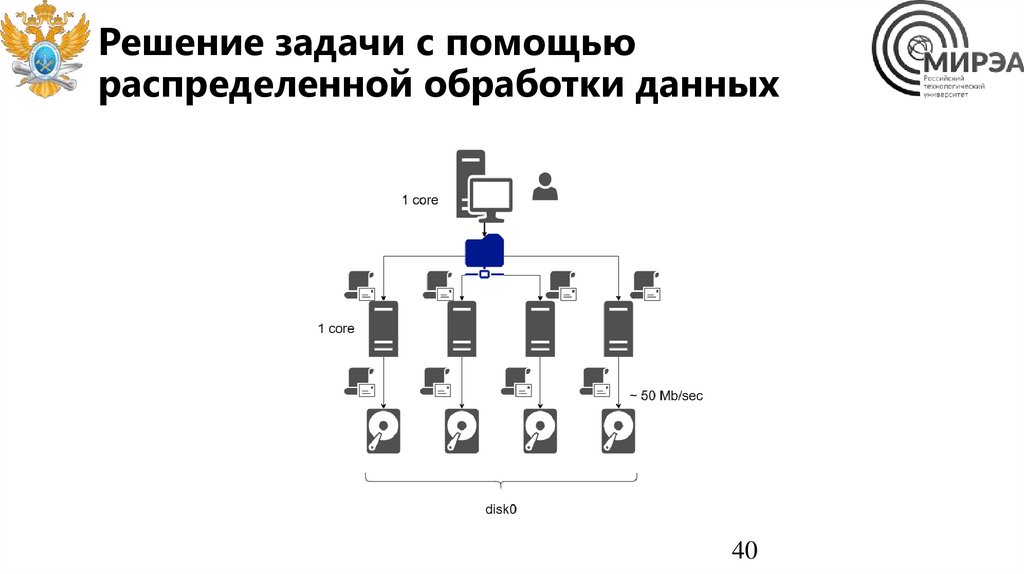
Решение задачи с помощьюраспределенной обработки данных
40
41.
Ограничения распределеннойобработки данных
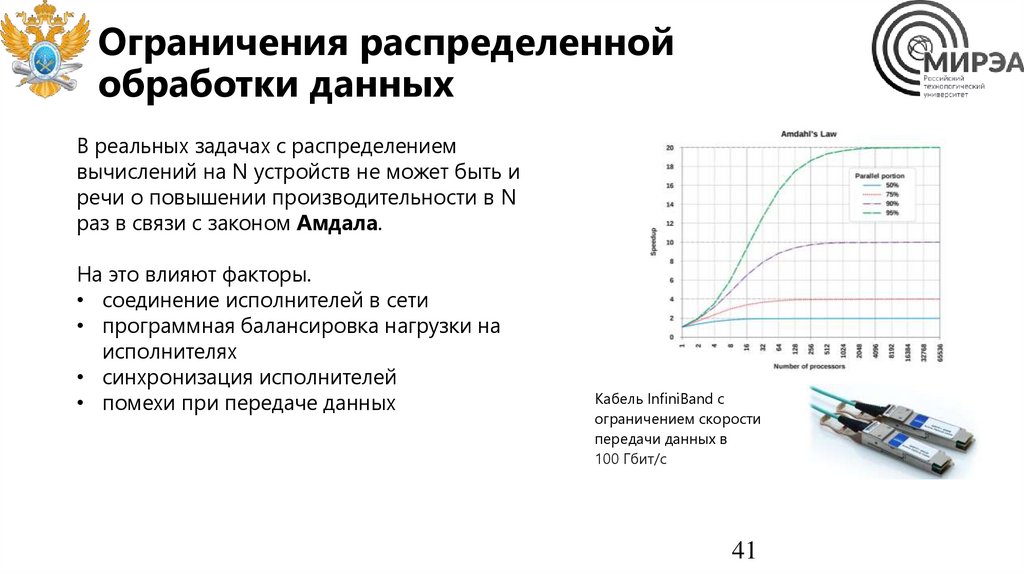
В реальных задачах с распределением
вычислений на N устройств не может быть и
речи о повышении производительности в N
раз в связи с законом Амдала.
На это влияют факторы.
• соединение исполнителей в сети
• программная балансировка нагрузки на
исполнителях
• синхронизация исполнителей
• помехи при передаче данных
Кабель InfiniBand с
ограничением скорости
передачи данных в
100 Гбит/с
41
42.
Часть 5. Масштабируемость системхранения и обработки данных
42
43.
Материал части1. Масштабируемость по аппаратным ресурсам
2. Масштабируемость по программным ресурсам
3. Экстенсивное масштабирование
4. Эффективное масштабирование
43
44.
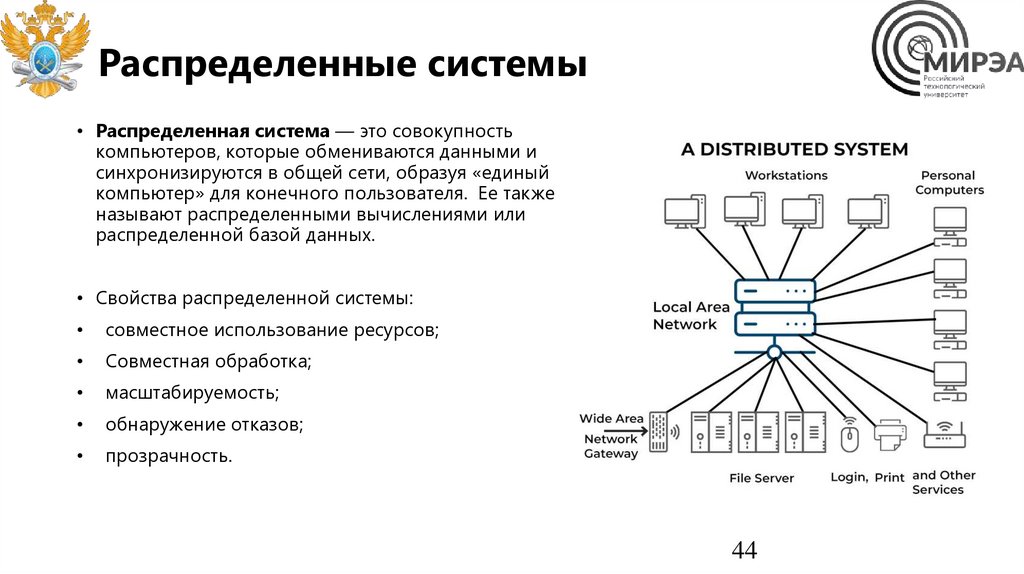
Распределенные системы• Распределенная система — это совокупность
компьютеров, которые обмениваются данными и
синхронизируются в общей сети, образуя «единый
компьютер» для конечного пользователя. Ее также
называют распределенными вычислениями или
распределенной базой данных.
• Свойства распределенной системы:
совместное использование ресурсов;
Совместная обработка;
масштабируемость;
обнаружение отказов;
прозрачность.
44
45.
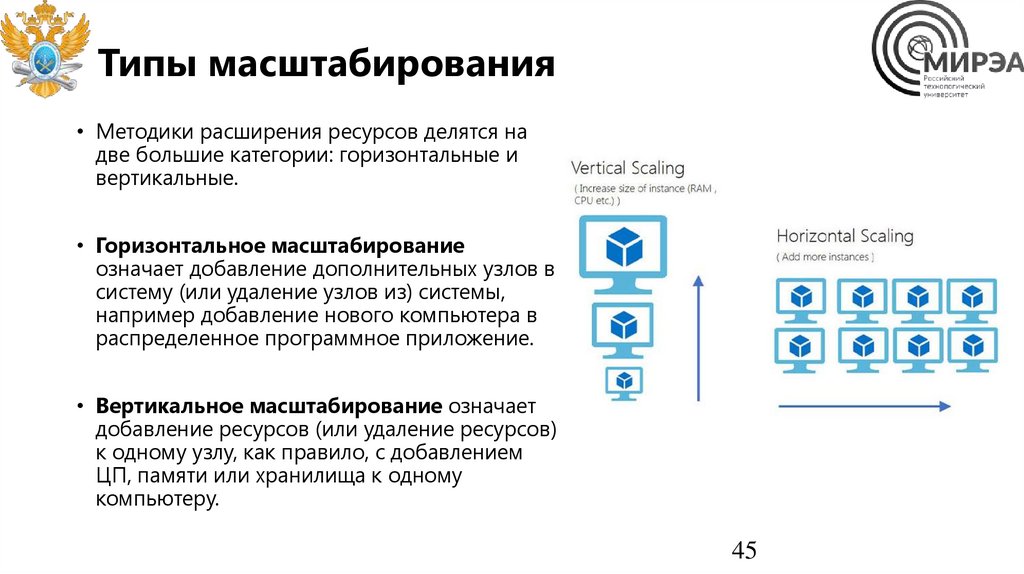
Типы масштабирования• Методики расширения ресурсов делятся на
две большие категории: горизонтальные и
вертикальные.
• Горизонтальное масштабирование
означает добавление дополнительных узлов в
систему (или удаление узлов из) системы,
например добавление нового компьютера в
распределенное программное приложение.
• Вертикальное масштабирование означает
добавление ресурсов (или удаление ресурсов)
к одному узлу, как правило, с добавлением
ЦП, памяти или хранилища к одному
компьютеру.
45
46.
Масштабируемость по аппаратнымресурсам
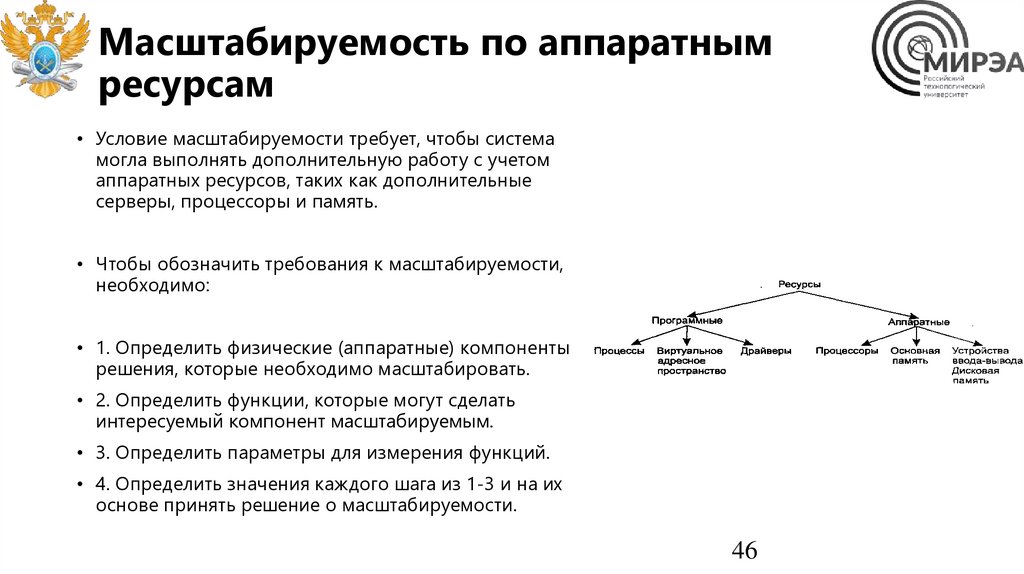
• Условие масштабируемости требует, чтобы система
могла выполнять дополнительную работу с учетом
аппаратных ресурсов, таких как дополнительные
серверы, процессоры и память.
• Чтобы обозначить требования к масштабируемости,
необходимо:
• 1. Определить физические (аппаратные) компоненты
решения, которые необходимо масштабировать.
• 2. Определить функции, которые могут сделать
интересуемый компонент масштабируемым.
• 3. Определить параметры для измерения функций.
• 4. Определить значения каждого шага из 1-3 и на их
основе принять решение о масштабируемости.
46
47.
Масштабируемость по программнымресурсам
• Масштабируемость можно оценить через
отношение прироста производительности
системы к приросту используемых ей
ресурсов. Чем ближе это отношение к
единице, тем масштабируемость лучше.
• При определении программной
масштабируемости учитываются:
• функциональность системы с учетом
простоты использования обновлений;
• выбор базы данных;
• грамотно написанный код.
47
48.
Экстенсивное масштабированиеЭкстенсивное развитие подразумевает собой
уменьшение расходов для платформ и/или
продуктов по средствам, времени и качеству
решения задачи.
Для реализации такого масштабирования можно:
прибегнуть к использованию дешевого
трафика (если это онлайн-платформа);
поэкспериментировать с готовыми
платформами, программным обеспечением;
провести аналитику с целью выявления редких
событий со значительными последствиями;
установление лидерских позиций на
небольшом сегменте рынка.
48
49.
Эффективное масштабирование• Указания по проведению эффективного
масштабирования включают в себя:
распределение трафика с
балансировкой нагрузки (добавление
дополнительного сервера для
поддержания пропускной способности);
определение размера базы данных
(увеличение емкости базы данных,
оптимизация запросов, добавление
процессоров и/или памяти, репликация
и/или разделение базы данных,
добавление новых баз данных);
мониторинг производительности
компонентов системы.
49