






 Преобразование некоторых КС-грамматик в автоматные")





 Диаграмма состояний автоматной грамматики")























 КА – распознаватель А-языков")












































 Информатика
ИнформатикаПохожие презентации:

")






")

Лексический анализ (глава 2)
1. Глава 2. Лексический анализ
Цель его работы – выделение лексеми формирование, как правило,
лексической свертки.
2. §2.1. Сканер 2.1.1 Назначение сканера
Сканер представляет собой ту частькомпилятора, которая читает (сканирует)
символы исходной программы и формирует
лексемы:
• идентификаторы,
• числовые, текстовые константы,
• 1- и 2- х символьные разделители,
• знаки операций и т.д.
Одновременно выполняется лексический
контроль.
3. Используются 2 стратегии работы лексического анализа:
1) блок синтаксического анализа обращается ксканеру, как только требуется выделить очередную
лексему , т.е. лексический анализатор По принципу
не выделен отдельным блоком;
«дай лексему»
2) сканер используется блоком лексического анализа,
отделенным от блока синтаксического анализа и
работающим раньше его. Блок лексического анализа
обращается к сканеру для выделения одной текущей
лексемы, размещает её в таблице и последовательно
формирует лексическую свертку, которая поступает
затем на вход синтаксического анализатора.
4. Второй способ считается предпочтительнее.
Доводы в пользу отделениялексического анализа от синтаксического:
1) значительная часть времени
компиляции тратится на сканирование и
анализ символов.
Выделение его, как отдельного процесса,
позволяет запрограммировать его более
эффективно, например на Ассемблере.
5.
2) Синтаксис лексем можно описать врамках простых грамматик (например,
класса 3),
что позволяет создать более
эффективный распознаватель и даже
автоматизировать процесс его
построения, например, в виде КА(см. п.4)
6.
3) Так как сканер формирует лексемывместо отдельных символов, то
синтаксический анализ на каждом шаге
имеет больше информации о структуре
программы.
7. 2.1.2. Автоматные языки и их свойства
Напомним, что автоматные языкипорождаются автоматными
грамматиками (класс 3), правила которых
имеют вид
U -> a,
U -> Va (или aV), где U, V N, a T.
Рассмотрим некоторые свойства
автоматных грамматик и языков.
8. 1) Преобразование некоторых КС-грамматик в автоматные
Отметим, что автоматные грамматикиявляются подмножеством КС-грамматик.
Определение 1.
1) Правило вывода КС-грамматики
будем называть заключительным, если оно имеет
вид
A -> , где A N, T*;
2) правило вывода будем называть праволинейным
(леволинейным), если оно имеет вид
A -> B (A -> B ), где A, B N, T*
( может равняться e);
3) неукорачивающая КС-грамматика называется
праволинейной (леволинейной), если все ее правила
праволинейные (леволинейные) или заключительные.
9.
Обе такие грамматики можно привести кэквивалентной (или почти эквивалентной)
автоматной грамматике.
Теорема 1. По любой праволинейной
(леволинейной) КС-грамматике можно
построить эквивалентную ей автоматную
грамматику. Если КС-грамматика содержит
e-правила, то почти эквивалентную.
10. Доказательство.
Отличие правил праволинейной иавтоматной грамматик только в том,
что в правых частях у праволинейной
грамматики может стоять не один, а
несколько терминальных символов.
Выполним замену этих правил, используя
допустимое преобразование добавление
нетерминала.
U -> a,
U -> aV, где U, V N, a T.
A -> , где A N, T*;
A -> B, где A, B N, T*
11.
Итак, пусть правило КС-грамматикиимеет вид
A -> B, где | | 2, т.е.
A -> a1a2…anB, A,B N, ai T.
Введем n-1 новый нетерминал A1, A2, …,
An-1 N и заменим данное правило группой
правил
A -> a1A1,
A1 -> a2A2,
…,
An-1-> anB.
Если правило заключительное, т.е. имеет вид
A -> , то последнее правило примет вид
An-1 -> an.
12.
- Заменив таким образом всеправолинейные и заключительные
правила, получим эквивалентную
автоматную грамматику.
Если в КС-грамматике были e-правила, то
преобразуем её к почти эквивалентной
неукорачивающей, а затем в автоматную
описанным выше образом.
13.
- Если исходная грамматикалеволинейная, то процедура
преобразования правил
A -> B
и
A ->
аналогична:
A ->A1an,
A1 -> A2an-1,
…,
An-1 -> Ba1.
14. 2) Диаграмма состояний автоматной грамматики
Автоматную грамматику можнопредставить в виде ориентированного
графа.
Граф позволяет не только наглядно увидеть
взаимосвязи между символами и правилами,
но и выполнить по нему анализ цепочек на
принадлежность языку, порожденному этой
грамматикой, по простому правилу.
15. Граф строится таким образом:
1) вершины помечаютсянетерминальными символами;
2) дуги – терминальными;
3) вводится дополнительная вершина I –
вход в граф;
4) каждому правилу вида
A -> a
в соответствие ставится фрагмент графа
a
I
A
16.
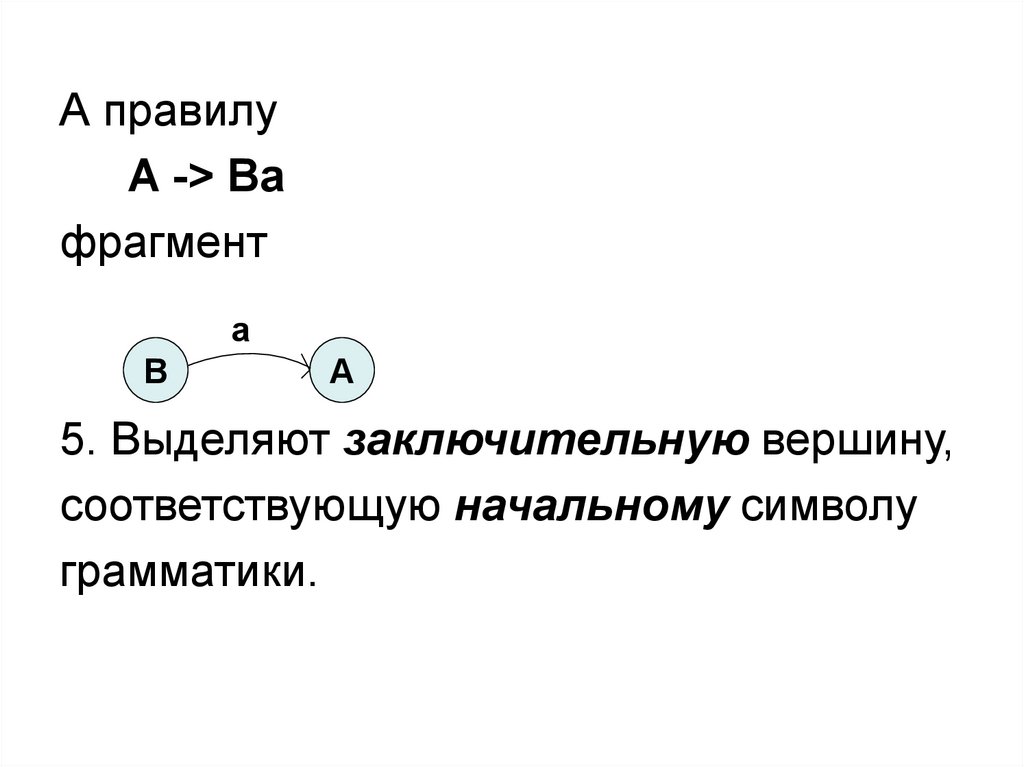
А правилуA -> Ba
фрагмент
a
B
A
5. Выделяют заключительную вершину,
соответствующую начальному символу
грамматики.
17. Пример.
Грамматике идентификатора G(ид):И –> a | b |…| z | Иa | Иb | … | Иz | И0 | И1 |
... | И9
соответствует граф
I
18. Пример.
Грамматике идентификатора G(ид):И –> a | b |…| z | Иa | Иb | … | Иz | И0 | И1 |
... | И9
соответствует граф
a
I
…
z
И
19. Пример.
Грамматике идентификатора G(ид):И –> a | b |…| z | Иa | Иb | … | Иz | И0 | И1 |
... | И9
соответствует граф
a
I
…
z
И
a …z
0 … 9
20. Пример.
Грамматике идентификатора G(ид):И –> a | b |…| z | Иa | Иb | … | Иz | И0 | И1 |
... | И9
соответствует граф
a
I
…
И
a …z
z
И – заключительная вершина.
0 … 9
21. ДС
Граф, представляющий автоматнуюграмматику, чаще называют диаграммой
состояний (ДС):
состояния – вершины,
I – начальное состояние.
Приведем теперь правило анализа
цепочек по ДС.
22. Правило анализа.
Пусть задана автоматная грамматика G,её ДС и цепочка = a1a2…an.
Требуется выяснить,
L(G)?
Встанем в ДС на начальную вершину I, а
в цепочке на первый символ a1.
23. Правило анализа
Найдем дугу, исходящую из I и помеченнуютерминалом a1.
Перейдем по этой дуге в следующую вершину
S’, а в цепочке к следующему символу a2.
Процесс продолжим аналогичным образом.
Если цепочка L(G), то её анализ
завершится в заключительной вершине и вся
цепочка, при этом, будет прочитана. В
противном случае L(G).
24. Пример анализа
Рассмотрим анализ цепочек aza0, aa+,z9a0 по ДС идентификатора.
a
I
…
z
И
a …z
0 … 9
25. Пример анализа
Рассмотрим анализ цепочек aza0, aa+,z9a0 по ДС идентификатора.
a
I
…
z
И
a …z
0 … 9
26. Пример анализа
Рассмотрим анализ цепочек aza0, aa+,z9a0 по ДС идентификатора.
a
I
…
z
И
a …z
0 … 9
27. Пример анализа
Рассмотрим анализ цепочек aza0, aa+,z9a0 по ДС идентификатора.
a
I
…
z
И
a …z
0 … 9
28. Пример анализа
Рассмотрим анализ цепочек aza0, aa+,z9a0 по ДС идентификатора.
a
I
…
z
И
a …z
0 … 9
29. Пример анализа
Рассмотрим анализ цепочек aza0, aa+,z9a0 по ДС идентификатора.
a
I
…
z
И
a …z
0 … 9
30. Пример анализа
Рассмотрим анализ цепочек aza0, aa+,z9a0 по ДС идентификатора.
a
I
…
z
И
a …z
0 … 9
31. Пример анализа
Рассмотрим анализ цепочек aza0, aa+,z9a0 по ДС идентификатора.
a
I
…
z
И
a …z
0 … 9
32. Пример анализа
Рассмотрим анализ цепочек aza0, aa+,z9a0 по ДС идентификатора.
a
I
…
z
И
a …z
0 … 9
33. Пример анализа
Рассмотрим анализ цепочек aza0, aa+,z9a0 по ДС идентификатора.
a
I
…
z
И
a …z
0 … 9
34. Пример анализа
Рассмотрим анализ цепочек aza0, aa+,z9a0 по ДС идентификатора.
a
I
…
z
И
a …z
0 … 9
35. Пример анализа
Рассмотрим анализ цепочек aza0, aa+,z9a0 по ДС идентификатора.
a
I
…
z
И
a …z
0 … 9
36. Пример анализа
Рассмотрим анализ цепочек aza0, aa+,z9a0 по ДС идентификатора.
a
I
…
z
И
a …z
0 … 9
37.
На практике ДС чаще используют дляпостроения правил грамматики класса 3,
выполняя процедуру, обратную пункту 4
построения ДС.
Рассмотрим для примера построение ДС
и формирование по ней грамматики
класса 3 для лексемы ‘текстовая
константа’ в языке С.
38.
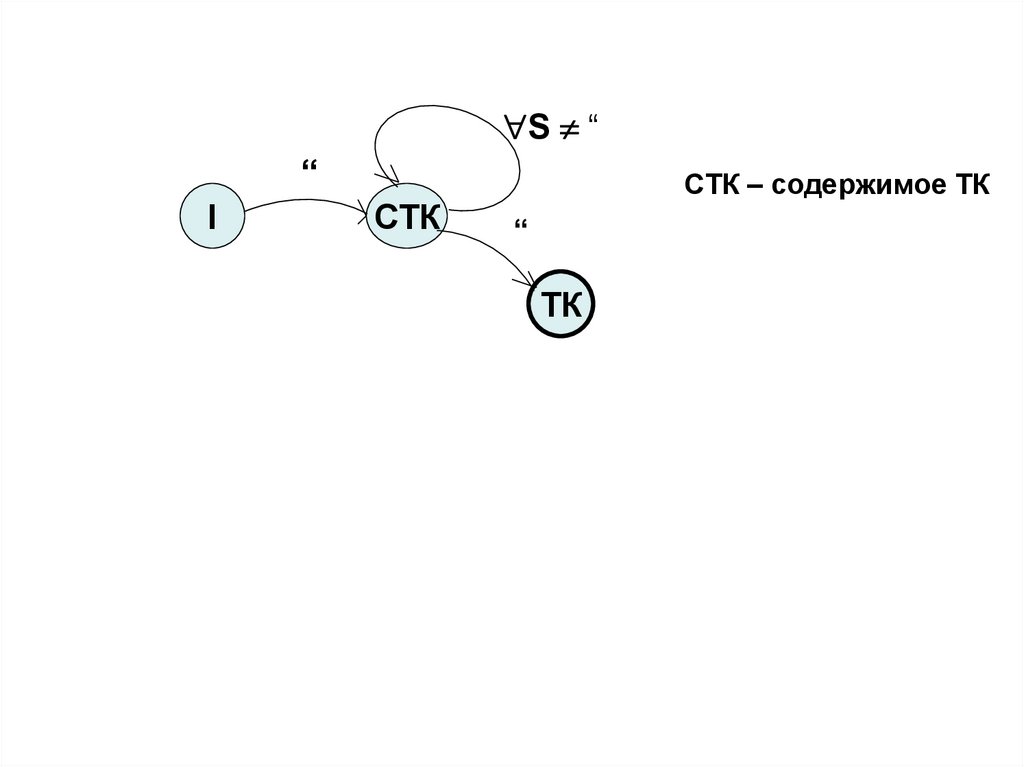
S ““
I
СТК
СТК – содержимое ТК
“
ТК
39.
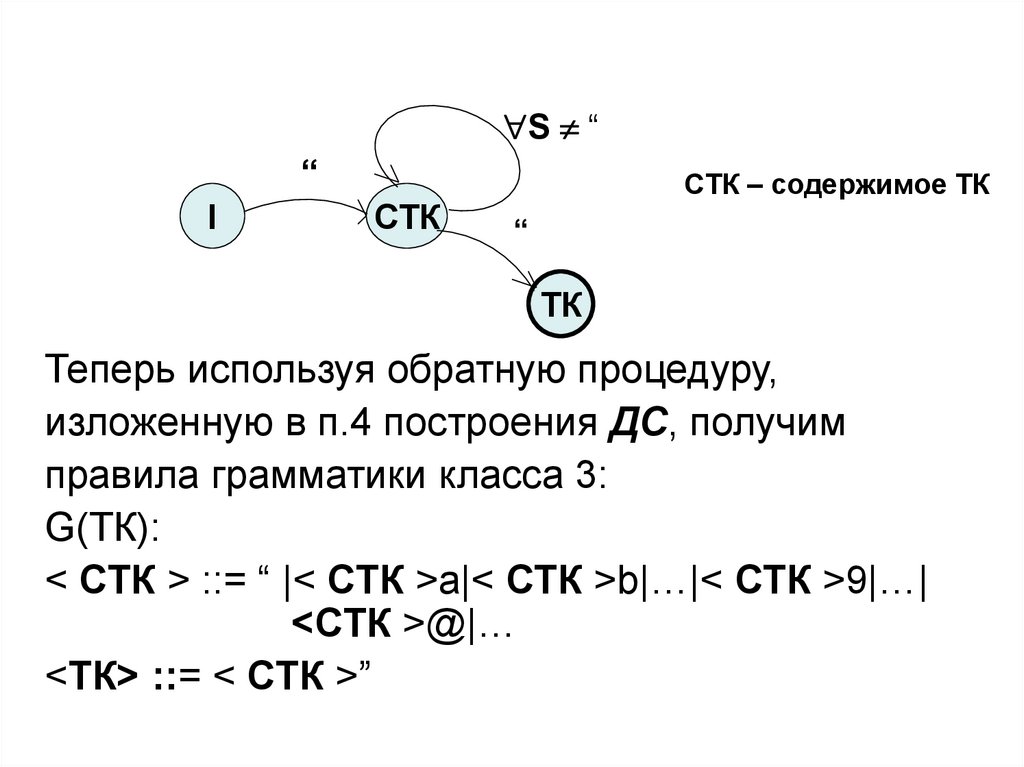
S ““
I
СТК
СТК – содержимое ТК
“
ТК
Теперь используя обратную процедуру,
изложенную в п.4 построения ДС, получим
правила грамматики класса 3:
G(ТК):
< СТК > ::= “ |< СТК >a|< СТК >b|…|< СТК >9|…|
<СТК >@|…
<TК> ::= < СТК >”
40.
По ДС можно увидеть также ряд очевидныхсвойств автоматной грамматики:
• разбор цепочки – это путь от вершины I к
вершине S, цепочка – это метки проходимых
при этом дуг;
• если некоторые символы грамматики
несущественны, то граф несвязный;
• рекурсивной грамматике соответствует граф
с циклами.
Замечание. Символ U грамматики
существенный, если он выводим из начального
символа грамматики и порождает
терминальную цепочку.
S =>*U=>* T*
41. 3) КА – распознаватель А-языков
Диаграмма состояний удобна для выявлениясвойств грамматики на этапе предварительного
анализа. Для построения автоматизированного
распознавателя на практике используется
модель КА, порождающего А-языки. Далее мы
увидим, что ДС и КА – эквивалентные понятия.
42. КА
КА является простейшим распознавателем.Рабочей памяти у него нет, т.е. он
состоит из входной ленты, УУ и головки
чтения-записи, двигающейся по ленте
слева направо.
Входная лента
t1
t2
t3
…
Головка чтения-записи
УУ с конечной памятью
tn
анализируемая
цепочка
43. Определение
Недетерминированный КА – это пятеркаобъектов
КА = {Q, T, , q0, F),
где Q – конечное множество состояний УУ;
T – конечное множество входных символов;
- функция отображения множества Q T
во множество конечных подмножеств
множества Q, её также называют функцией
переходов;
q0 Q – начальное состояние УУ;
F Q - множество заключительных состояний.
44. Работа КА –
это последовательность тактов.Каждый такт определяется
текущим состоянием УУ и текущим
входным символом на ленте.
Они определяют переход в новое
состояние и сдвиг на ленте на 1 символ
вправо.
45. КА может быть задан
а) в виде ДС:q0 соответствует вершине I;
qi - другим вершинам;
F – множеству заключительных вершин;
T – меткам дуг;
б) в виде матрицы переходов(МП):
строки соответствуют состояниям qi,
столбцы – символам из множества T,
на пересечении - множество состояний, в
которые возможен переход для
недетерминированного КА и
одно состояние для детерминированного.
46.
Таким образом, на практике автоматныеграмматики используются для разработки
синтаксиса лексем.
При этом обычно действуют по такой
схеме
ДС ->Грамматика кл.3-> КА -> МП.
Причем этап формирования КА можно
пропустить в соответствии с выше
сказанным.
47.
Итак, если сканер построен помодели КА, то анализ лексем прост,
и по своей стратегии представляет собой
восходящий анализ, где основой на
каждом шаге является текущее
состояние и текущий символ программы.
48. Пример
ДС(ид):Анализ цепочки arg1
соответствует
дереву разбора
И
a
I
…
И
a …z
0 … 9
И
z
И
Деревья разбора большинства лексем
выглядят таким образом.
И
arg1
49.
Приведем ещё 2 примера КА.50. Пример 1.
Диаграмме состояний ТК соответствует КАКА(ТК) =
{ {q0 = I,q1 = СТК , q2 = TК }, {“,символы, кроме “}, ,
S “
q0 = I, F= {TК}},
“
( I, “) = < СТК >
I
СТК
“
(< СТК >, символ) = < СТК >
(< СТК >, ”) = <TК>
ТК
МП(ТК): qi tj “
0
1
1
2
2
!
0
-
… 9
- -
a
-
… z
- -
+
-
…
-
1
… 1
1
… 1
1
…
I
СТК
ТК
51. Пример 2.
Недетерминированный КА анализируетцепочки, состоящие из десятичных цифр
1,2, 3. Цепочка верна, если последняя
цифра в ней уже встречалась:
121 – верна,
31312 – нет,
12332 - верна.
52. МП разобрать самостоятельно
tjqi
q0
1
2
3
{q0, q1} {q0, q2} {q0, q3}
q1
{q1, qf}
{q1}
{q1}
121
q2
{q2}
{q2, qf}
{q2}
31312
q3
{q3}
{q3}
{q3, qf}
qf
!
!
!
53. 2.1.3 Программирование сканера
Как было сказано выше, цель работысканера – выделить одну лексему с
текущей позиции программы.
Пусть программа – это цепочка
= a1a2…an .
Итак, сканер представляет собой блок
, i
L, t
Сканер
i
i – текущий указатель , L – лексема, t – её тип
54.
Для примера рассмотрим следующиеосновные типы лексем в языках
программирования
1, идентификатор
2, целая константа
3, верный знак (=+-,….)
t=
4, текстовая константа (“Hello!”)
5, символьная константа (‘*’)
0, ошибочная лексема (@#)
55. Класс символа
На каждом шаге сканер распознает типсимвола.
Зададим вспомогательный блок – Класс
Символа (КС), который определяет тип
текущего символа входной программы - k.
ai
k
КС
56.
Проще, “видя” начальные символы лексем,определить блок Класс Символов таким
образом
1, буква
2, цифра
3, верный знак
k=
4, “
5, ‘
0, недопустимый (ошибочный знак)
Теперь диаграмму состояний сканера для практических
целей можно изобразить следующим образом
57. ДС сканера
Start58. ДС сканера
др/с – другой символStart
б
И
др/с
В1 (t = 1, L)
Вi – i-ый выход
59. ДС сканера
др/с – другой символStart
б
ц
И
ЦК
др/с
др/с
ЦК =>ФТ
В1 (t = 1, L)
В2 (t = 2, L)
Вi – i-ый выход
60. ДС сканера
др/с – другой символStart
б
ц
в/з – верный знак
в/з
И
ЦК
др/с
др/с
ЦК =>ФТ
В1 (t = 1, L)
В2 (t = 2, L)
В3 (t = 3, L)
Вi – i-ый выход
61. ДС сканера
др/с – другой символStart
б
ц
в/з – верный знак
ТК –Текстовая
Константа
И
ЦК
др/с
ЦК =>ФТ
в/з
“
др/с
В1 (t = 1, L)
В2 (t = 2, L)
В3 (t = 3, L)
с - символ
ТК
“
В4 (t = 4, L)
Вi – i-ый выход
62. ДС сканера
др/с – другой символStart
б
И
ц
в/з – верный знак
ТК –Текстовая
Константа
НСК - Начало
Символьной
Константы
ЦК
В1 (t = 1, L)
др/с
ЦК =>ФТ
в/з
В2 (t = 2, L)
В3 (t = 3, L)
с - символ
“
‘
др/с
ТК
“
с ’
НСК
СК
В4 (t = 4, L)
‘
В5 (t = 5, L)
Вi – i-ый выход
63. ДС сканера
др/с – другой символStart
б
И
ц
в/з – верный знак
ТК –Текстовая
Константа
НСК - Начало
Символьной
Константы
ош –
ошибочный
символ
ЦК
В1 (t = 1, L)
др/с
ЦК =>ФТ
в/з
В2 (t = 2, L)
В3 (t = 3, L)
с - символ
“
‘
др/с
ТК
“
с ’
НСК
ош/с
СК
В4 (t = 4, L)
‘
В5 (t = 5, L)
В0 (t = 0, L)
Вi – i-ый выход
64. ДС сканера
StartКС
б
И
ц
ЦК
В1 (t = 1, L)
др/с
ЦК =>ФТ
в/з
В2 (t = 2, L)
В3 (t = 3, L)
“
‘
др/с
ТК
“
с ’
НСК
ош/с
СК
В4 (t = 4, L)
‘
В5 (t = 5, L)
В0 (t = 0, L)
Вi – i-ый выход
65. Замечания к ДС:
1. Сканер выделяет одну самую длинную лексему.(ab – ошибка, если пропустить знак *)
2. После выхода из сканера указатель входной
программы должен стоять на первом символе
следующей лексемы.
3. На каждом шаге сканер обращается к блоку КС для
распознавания класса символа.
4. В некоторых состояниях сканер выполняет
дополнительные действия, например, по
формированию лексемы во внутренней форме
( ЦК => ФТ на ДС) .
5. Кроме того, сканер может выполнять частично
синтаксический контроль – подсчет ( и ), { и } и др.
66. § 2.2. Блок лексического анализа
Цель его работы выделить лексемы впрограмме и заменить их на
лексическую свертку.
Исходная
программа
Лексическая свертка
Лексический анализ
таблицы
Говорят также, что программа переводится
на внутренний язык компилятора
67. Таблицы компилятора
В процессе работы компилятор использует рядтаблиц.
Различают постоянные и временные
таблицы.
• Постоянные таблицы не зависят от
конкретной программы и формируются
компилятором заранее.
Это, например, таблицы служебных слов (ТСС),
таблица основных символов языка (ТОС) и др.
68. Таблицы компилятора
• Временные таблицы зависят отконкретной программы, формируются в
процессе трансляции и удаляются после
работы программы.
Это, например,
• таблица идентификаторов (ТИ),
• таблица числовых констант (ТЧК),
• таблица текстовых констант (ТТК),
• таблица ошибок (ТО).
69.
В процессе работы лексический анализаторпостоянно обращается к сканеру. После того,
как сканер вернет лексему, компилятор
выполняет определенные действия.
В частности, служебное слово сканером
квалифицируется как идентификатор, а
лексический анализатор уточняет его по ТСС.
70.
Лексема в программе заменяется надескриптор вида
тип лексемы
адрес в таблице
Последовательность дескрипторов и
образует лексическую свертку.
Приведем блок-схему работы лексического
анализатора на примере рассмотренных в
п.1 лексем.
71. Блок-схема ЛА
j – номер илиадрес в таблице Исходная программа
ai
Сканер
t
+ L ТСС
j
Занесение
в ТИ
j
k
L
Тип лексемы t =
1 2 3 5 4 0
КС
Формирование
кода ошибки или
Аварийный
выход
Занесение
в ТЧК
j
Определение Занесение
номера по ТОС
в ТТК
j
j
Формирование дескриптора
t, j
Конец
программы?
-
Лексическая свертка +
К синтаксическому анализу
72. § 2.3. КА для анализа вещественной константы
Вещественная константа, пожалуй, самая сложнаялексема. Её общий вид
ц1ц2…цk.д1д2…дme p1p2
Некоторые части могут отсутствовать, но не
все сразу (например, целая часть, или дробная,
или порядок).
Приведенный ниже КА не только выделяет лексему, но
и переводит её во внутреннюю форму с ПТ. Для этого в
некоторых состояниях выполняются вспомогательные
действия, которые назовем подпрограммами пномер.
73. § 2.3. КА для анализа вещественной константы
Вещественная константа, пожалуй, самая сложнаялексема. Её общий вид
ц1ц2…цk.д1д2…дme p1p2
Некоторые части могут отсутствовать, но не
все сразу (например, целая часть, или дробная,
или порядок).
Приведенный ниже КА не только выделяет лексему, но
и переводит её во внутреннюю форму с ПТ. Для этого в
некоторых состояниях выполняются вспомогательные
действия, которые назовем подпрограммами пномер.
74. § 2.3. КА для анализа вещественной константы
Вещественная константа, пожалуй, самая сложнаялексема. Её общий вид
ц1ц2…цk.д1д2…дme p1p2
Некоторые части могут отсутствовать, но не
все сразу (например, целая часть, или дробная,
или порядок).
Приведенный ниже КА не только выделяет лексему, но
и переводит её во внутреннюю форму с ПТ. Для этого в
некоторых состояниях выполняются вспомогательные
действия, которые назовем подпрограммами пномер.
75. § 2.3. КА для анализа вещественной константы
Вещественная константа, пожалуй, самая сложнаялексема. Её общий вид
ц1ц2…цk.д1д2…дme p1p2
Некоторые части могут отсутствовать, но не
все сразу (например, целая часть, или дробная,
или порядок).
Приведенный ниже КА не только выделяет лексему, но
и переводит её во внутреннюю форму с ПТ. Для этого в
некоторых состояниях выполняются вспомогательные
действия, которые назовем подпрограммами пномер.
76. § 2.3. КА для анализа вещественной константы
Вещественная константа, пожалуй, самая сложнаялексема. Её общий вид
ц1ц2…цk.д1д2…дme p1p2
Некоторые части могут отсутствовать, но не
все сразу (например, целая часть, или дробная,
или порядок).
Приведенный ниже КА не только выделяет лексему, но
и переводит её во внутреннюю форму с ПТ. Для этого в
некоторых состояниях выполняются вспомогательные
действия, которые назовем подпрограммами пномер.
77.
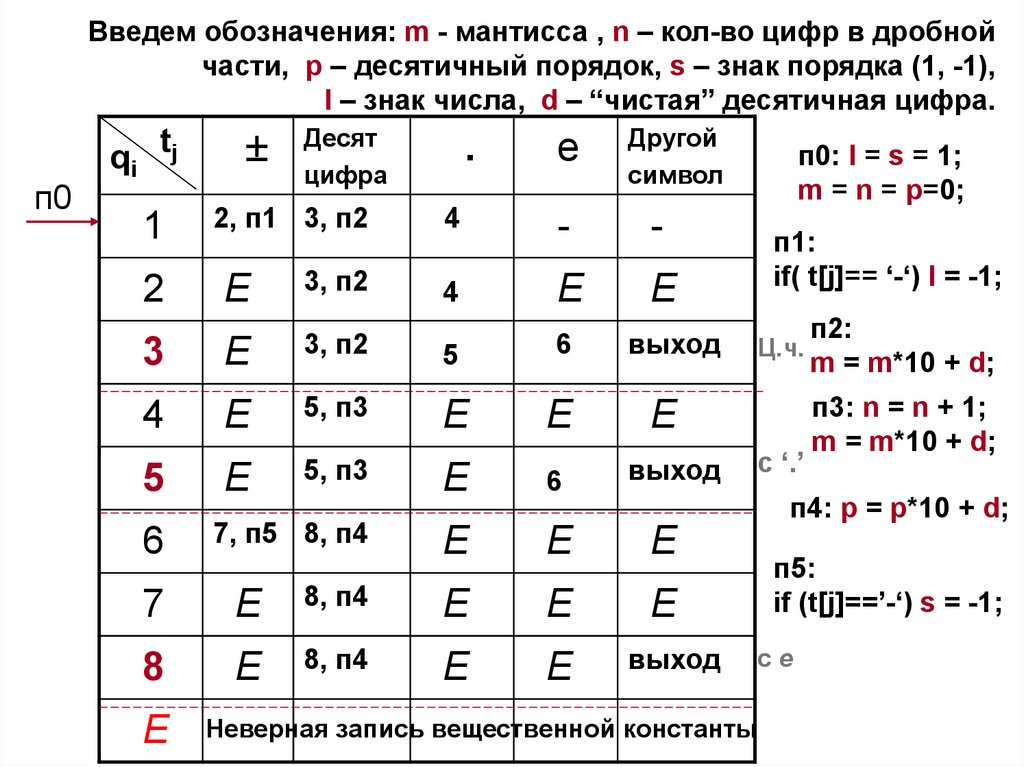
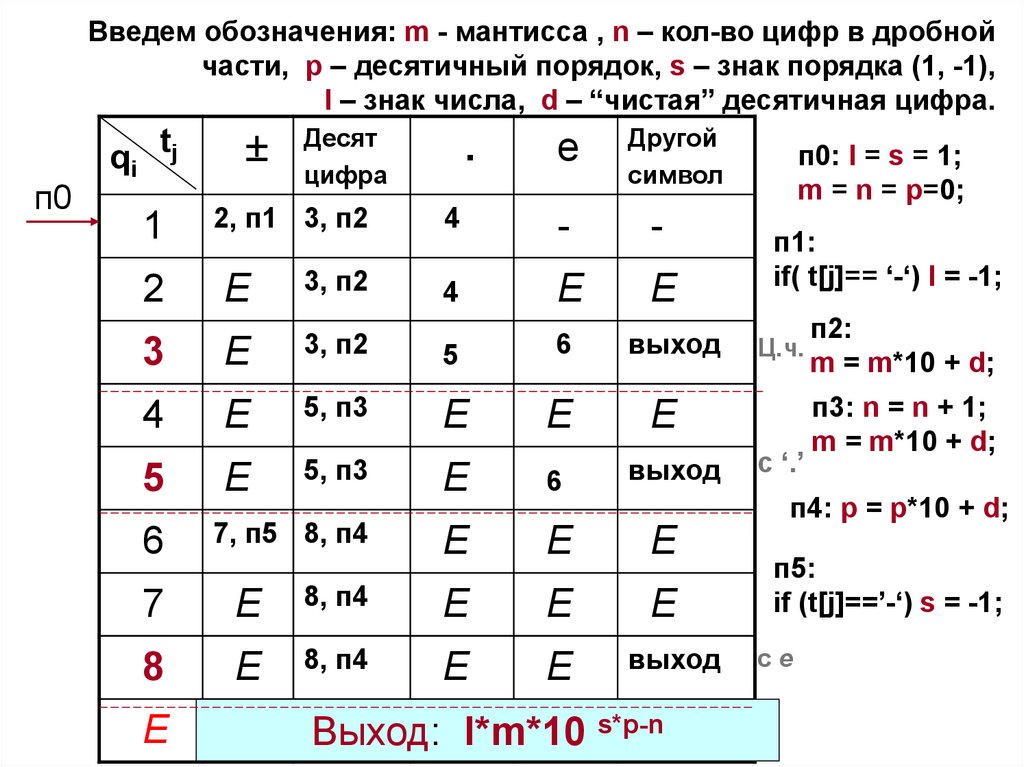
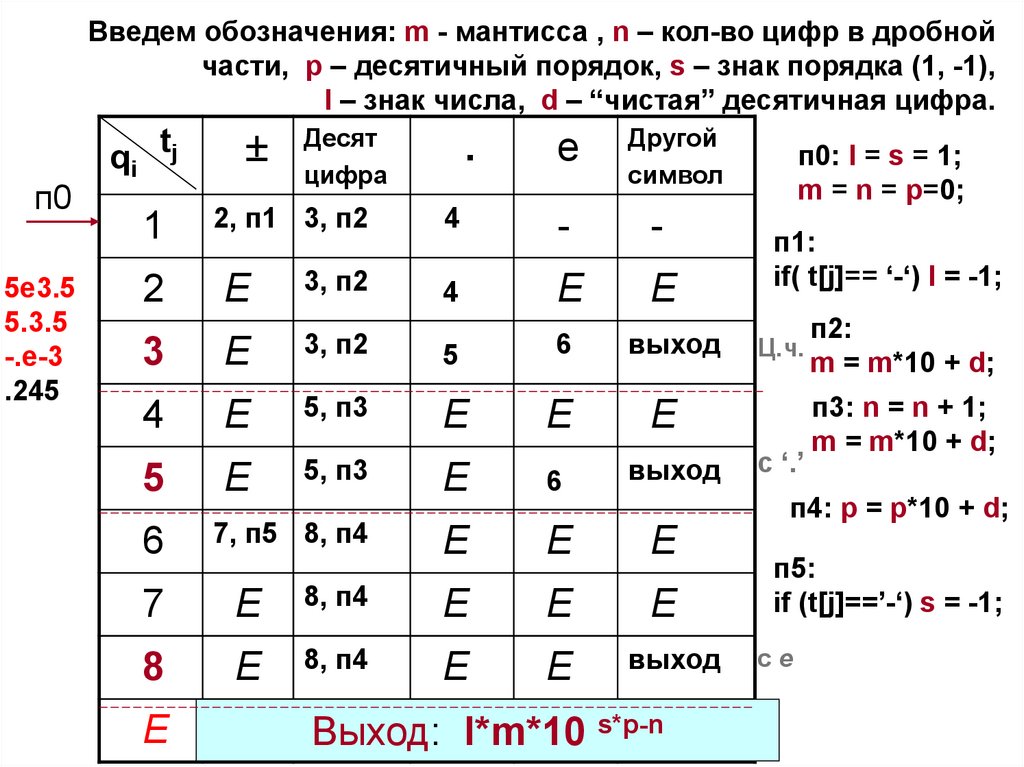
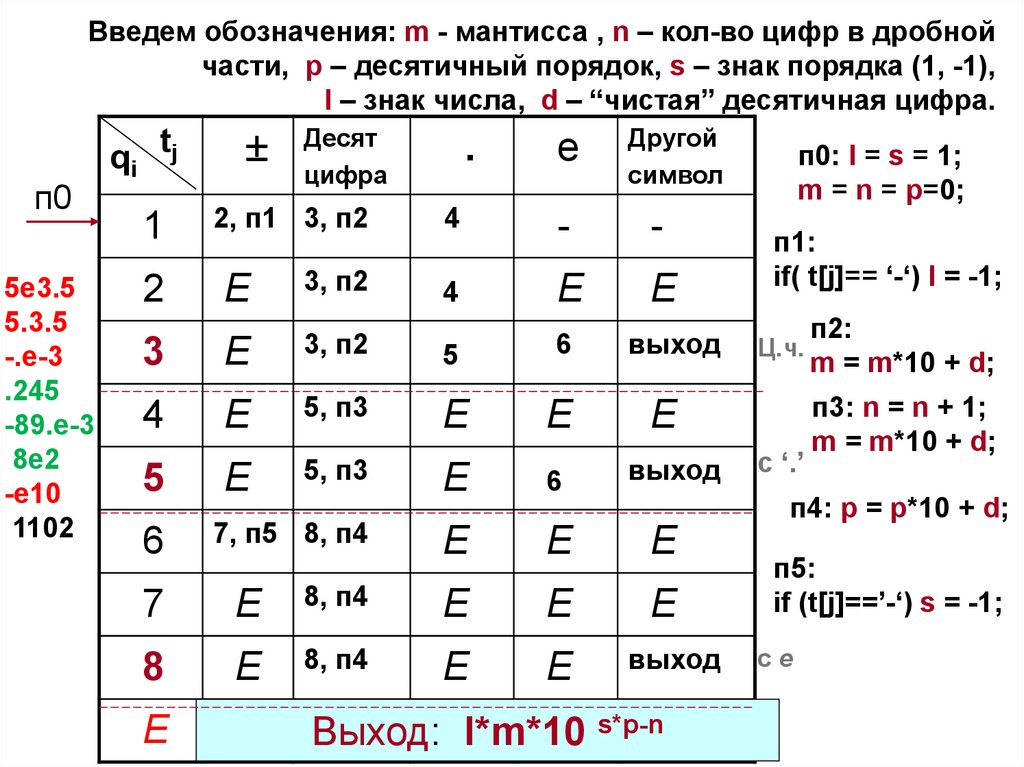
Введем обозначения: m - мантисса , n – кол-во цифр в дробнойчасти, p – десятичный порядок, s – знак порядка (1, -1),
l – знак числа, d – “чистая” десятичная цифра.
Заметим,
что на вход КА
поступают
символы
78.
Введем обозначения: m - мантисса , n – кол-во цифр в дробнойчасти, p – десятичный порядок, s – знак порядка (1, -1),
l – знак числа, d – “чистая” десятичная цифра.
п0
qi tj
Десят
цифра
.
e
Другой
символ
1
2, п1 3, п2
4
-
-
2
E
3, п2
4
E
E
3
E
3, п2
5
6
выход
4
E
5, п3
E
E
E
5
E
5, п3
E
6
выход
6
7, п5 8, п4
E
E
E
п1:
if( t[j]== ‘-‘) l = -1;
Ц.ч.
с ‘.’
п2:
m = m*10 + d;
п3: n = n + 1;
m = m*10 + d;
п4: p = p*10 + d;
7
E
8, п4
E
E
E
8
E
8, п4
E
E
выход
E
п0: l = s = 1;
m = n = p=0;
п5:
if (t[j]==’-‘) s = -1;
сe
Неверная запись вещественной константы
79.
Введем обозначения: m - мантисса , n – кол-во цифр в дробнойчасти, p – десятичный порядок, s – знак порядка (1, -1),
l – знак числа, d – “чистая” десятичная цифра.
п0
qi tj
Десят
цифра
.
e
Другой
символ
1
2, п1 3, п2
4
-
-
2
E
3, п2
4
E
E
3
E
3, п2
5
6
выход
4
E
5, п3
E
E
E
5
E
5, п3
E
6
выход
6
7, п5 8, п4
E
E
E
п1:
if( t[j]== ‘-‘) l = -1;
Ц.ч.
с ‘.’
п2:
m = m*10 + d;
п3: n = n + 1;
m = m*10 + d;
п4: p = p*10 + d;
7
E
8, п4
E
E
E
8
E
8, п4
E
E
выход
E
п0: l = s = 1;
m = n = p=0;
п5:
if (t[j]==’-‘) s = -1;
сe
Неверная
запись вещественной
константы
Выход:
l*m*10 s*p-n
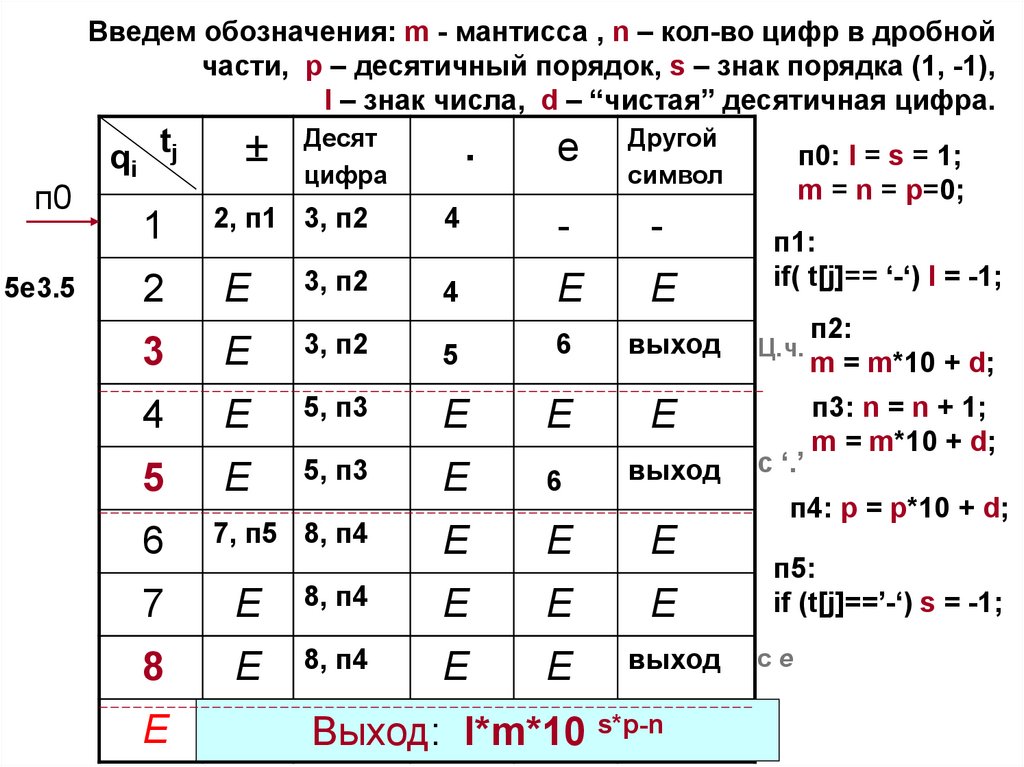
80.
Введем обозначения: m - мантисса , n – кол-во цифр в дробнойчасти, p – десятичный порядок, s – знак порядка (1, -1),
l – знак числа, d – “чистая” десятичная цифра.
п0
5e3.5
qi tj
Десят
цифра
.
e
Другой
символ
1
2, п1 3, п2
4
-
-
2
E
3, п2
4
E
E
3
E
3, п2
5
6
выход
4
E
5, п3
E
E
E
5
E
5, п3
E
6
выход
6
7, п5 8, п4
E
E
E
п1:
if( t[j]== ‘-‘) l = -1;
Ц.ч.
с ‘.’
п2:
m = m*10 + d;
п3: n = n + 1;
m = m*10 + d;
п4: p = p*10 + d;
7
E
8, п4
E
E
E
8
E
8, п4
E
E
выход
E
п0: l = s = 1;
m = n = p=0;
п5:
if (t[j]==’-‘) s = -1;
сe
Неверная
запись вещественной
константы
Выход:
l*m*10 s*p-n
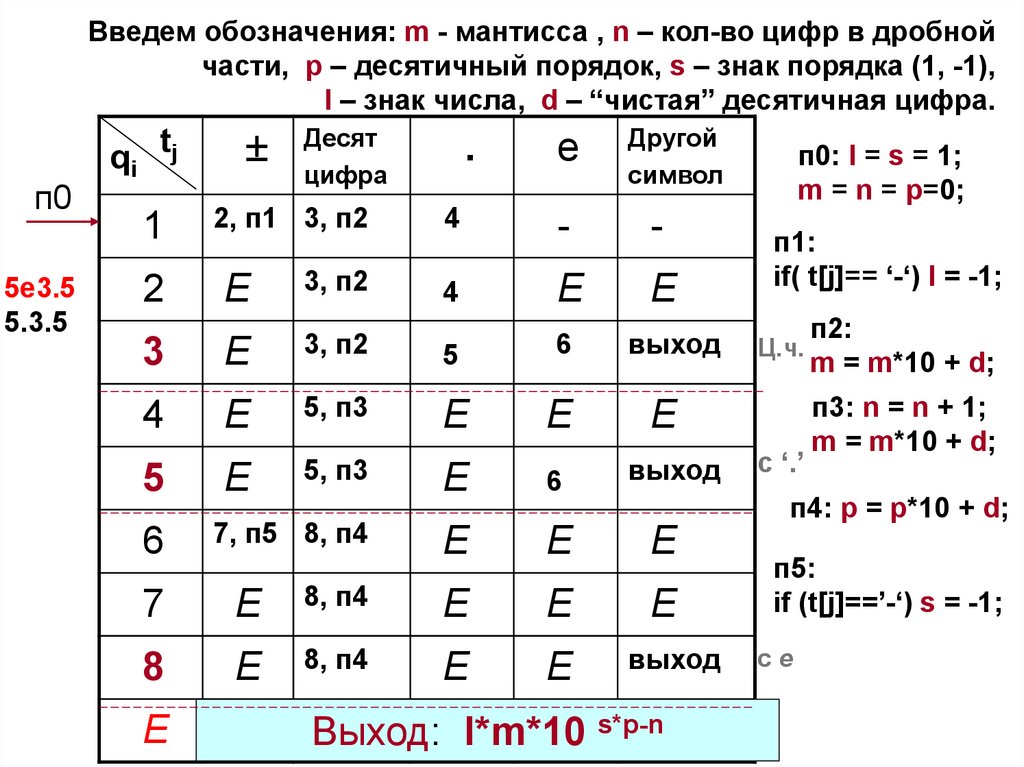
81.
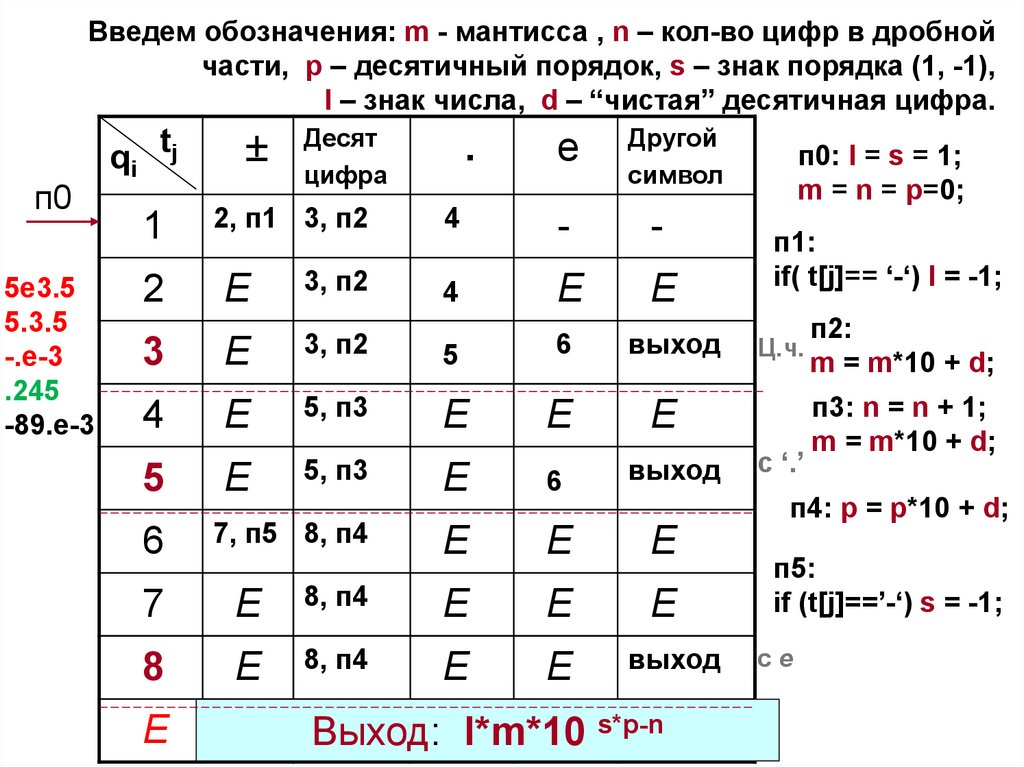
Введем обозначения: m - мантисса , n – кол-во цифр в дробнойчасти, p – десятичный порядок, s – знак порядка (1, -1),
l – знак числа, d – “чистая” десятичная цифра.
п0
5e3.5
5.3.5
qi tj
Десят
цифра
.
e
Другой
символ
1
2, п1 3, п2
4
-
-
2
E
3, п2
4
E
E
3
E
3, п2
5
6
выход
4
E
5, п3
E
E
E
5
E
5, п3
E
6
выход
6
7, п5 8, п4
E
E
E
п1:
if( t[j]== ‘-‘) l = -1;
Ц.ч.
с ‘.’
п2:
m = m*10 + d;
п3: n = n + 1;
m = m*10 + d;
п4: p = p*10 + d;
7
E
8, п4
E
E
E
8
E
8, п4
E
E
выход
E
п0: l = s = 1;
m = n = p=0;
п5:
if (t[j]==’-‘) s = -1;
сe
Неверная
запись вещественной
константы
Выход:
l*m*10 s*p-n
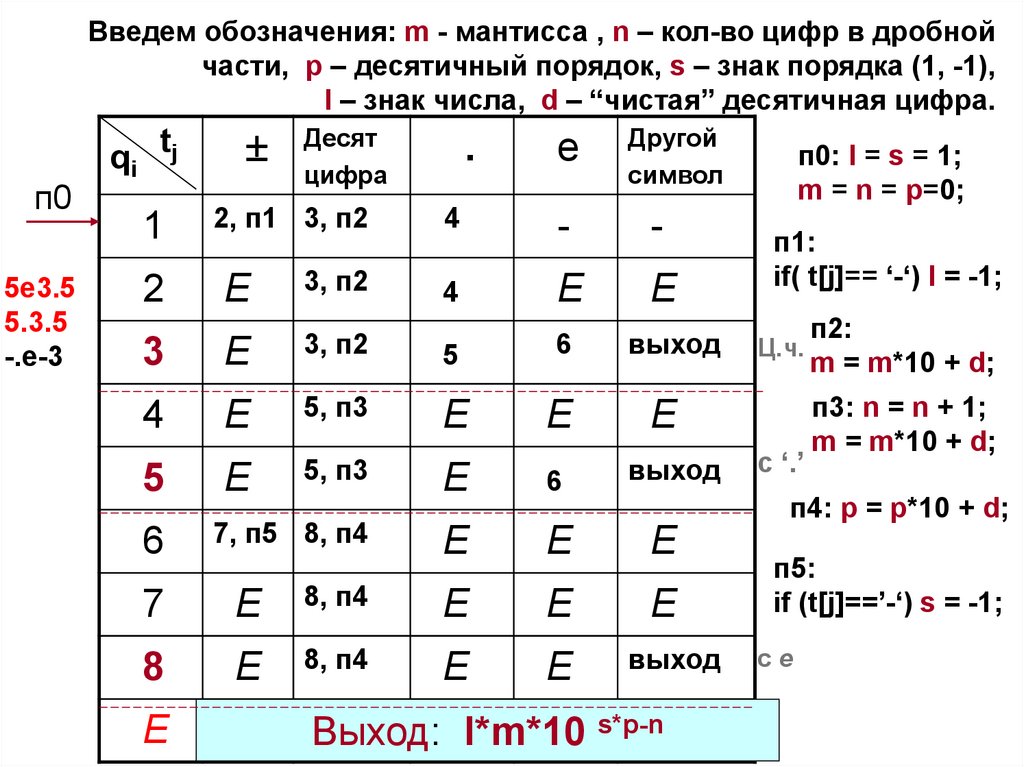
82.
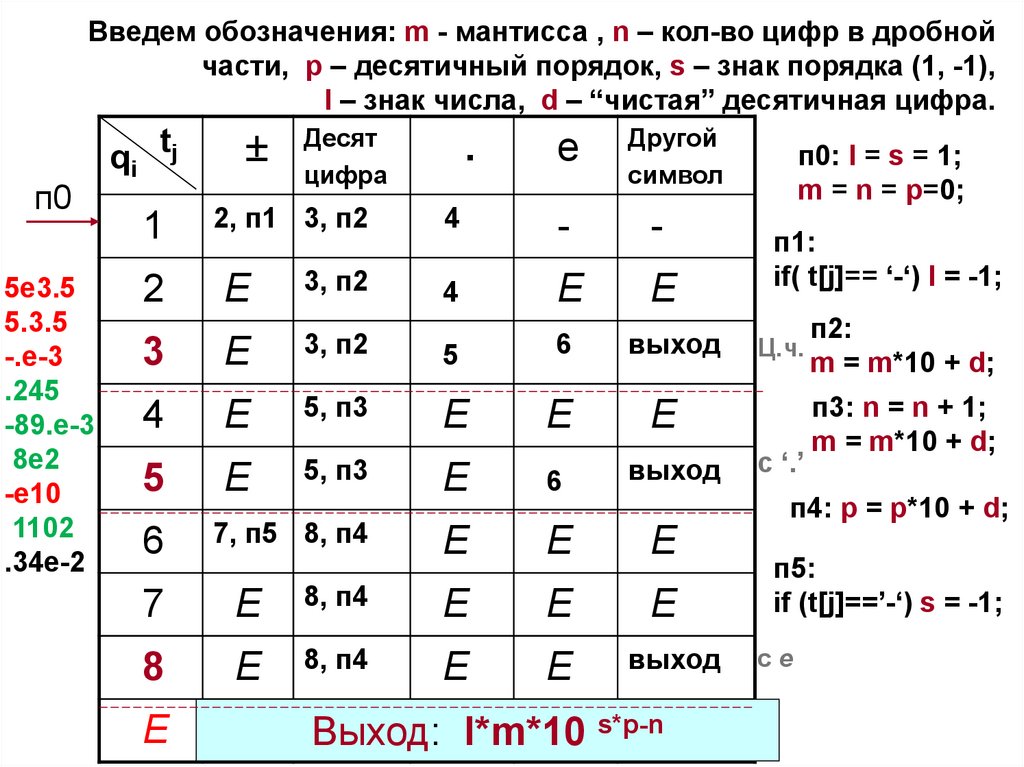
Введем обозначения: m - мантисса , n – кол-во цифр в дробнойчасти, p – десятичный порядок, s – знак порядка (1, -1),
l – знак числа, d – “чистая” десятичная цифра.
п0
5e3.5
5.3.5
-.e-3
qi tj
Десят
цифра
.
e
Другой
символ
1
2, п1 3, п2
4
-
-
2
E
3, п2
4
E
E
3
E
3, п2
5
6
выход
4
E
5, п3
E
E
E
5
E
5, п3
E
6
выход
6
7, п5 8, п4
E
E
E
п1:
if( t[j]== ‘-‘) l = -1;
Ц.ч.
с ‘.’
п2:
m = m*10 + d;
п3: n = n + 1;
m = m*10 + d;
п4: p = p*10 + d;
7
E
8, п4
E
E
E
8
E
8, п4
E
E
выход
E
п0: l = s = 1;
m = n = p=0;
п5:
if (t[j]==’-‘) s = -1;
сe
Неверная
запись вещественной
константы
Выход:
l*m*10 s*p-n
83.
Введем обозначения: m - мантисса , n – кол-во цифр в дробнойчасти, p – десятичный порядок, s – знак порядка (1, -1),
l – знак числа, d – “чистая” десятичная цифра.
п0
5e3.5
5.3.5
-.e-3
.245
qi tj
Десят
цифра
.
e
Другой
символ
1
2, п1 3, п2
4
-
-
2
E
3, п2
4
E
E
3
E
3, п2
5
6
выход
4
E
5, п3
E
E
E
5
E
5, п3
E
6
выход
6
7, п5 8, п4
E
E
E
п1:
if( t[j]== ‘-‘) l = -1;
Ц.ч.
с ‘.’
п2:
m = m*10 + d;
п3: n = n + 1;
m = m*10 + d;
п4: p = p*10 + d;
7
E
8, п4
E
E
E
8
E
8, п4
E
E
выход
E
п0: l = s = 1;
m = n = p=0;
п5:
if (t[j]==’-‘) s = -1;
сe
Неверная
запись вещественной
константы
Выход:
l*m*10 s*p-n
84.
Введем обозначения: m - мантисса , n – кол-во цифр в дробнойчасти, p – десятичный порядок, s – знак порядка (1, -1),
l – знак числа, d – “чистая” десятичная цифра.
п0
5e3.5
5.3.5
-.e-3
.245
-89.e-3
qi tj
Десят
цифра
.
e
Другой
символ
1
2, п1 3, п2
4
-
-
2
E
3, п2
4
E
E
3
E
3, п2
5
6
выход
4
E
5, п3
E
E
E
5
E
5, п3
E
6
выход
6
7, п5 8, п4
E
E
E
п1:
if( t[j]== ‘-‘) l = -1;
Ц.ч.
с ‘.’
п2:
m = m*10 + d;
п3: n = n + 1;
m = m*10 + d;
п4: p = p*10 + d;
7
E
8, п4
E
E
E
8
E
8, п4
E
E
выход
E
п0: l = s = 1;
m = n = p=0;
п5:
if (t[j]==’-‘) s = -1;
сe
Неверная
запись вещественной
константы
Выход:
l*m*10 s*p-n
85.
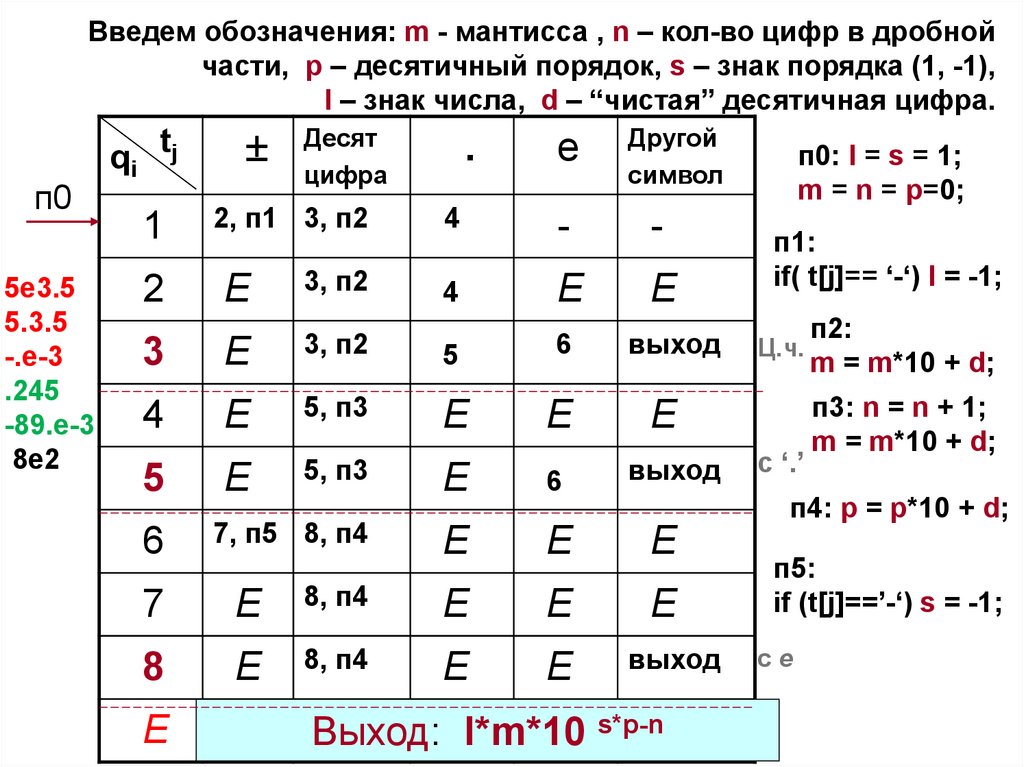
Введем обозначения: m - мантисса , n – кол-во цифр в дробнойчасти, p – десятичный порядок, s – знак порядка (1, -1),
l – знак числа, d – “чистая” десятичная цифра.
п0
5e3.5
5.3.5
-.e-3
.245
-89.e-3
8e2
qi tj
Десят
цифра
.
e
Другой
символ
1
2, п1 3, п2
4
-
-
2
E
3, п2
4
E
E
3
E
3, п2
5
6
выход
4
E
5, п3
E
E
E
5
E
5, п3
E
6
выход
6
7, п5 8, п4
E
E
E
п1:
if( t[j]== ‘-‘) l = -1;
Ц.ч.
с ‘.’
п2:
m = m*10 + d;
п3: n = n + 1;
m = m*10 + d;
п4: p = p*10 + d;
7
E
8, п4
E
E
E
8
E
8, п4
E
E
выход
E
п0: l = s = 1;
m = n = p=0;
п5:
if (t[j]==’-‘) s = -1;
сe
Неверная
запись вещественной
константы
Выход:
l*m*10 s*p-n
86.
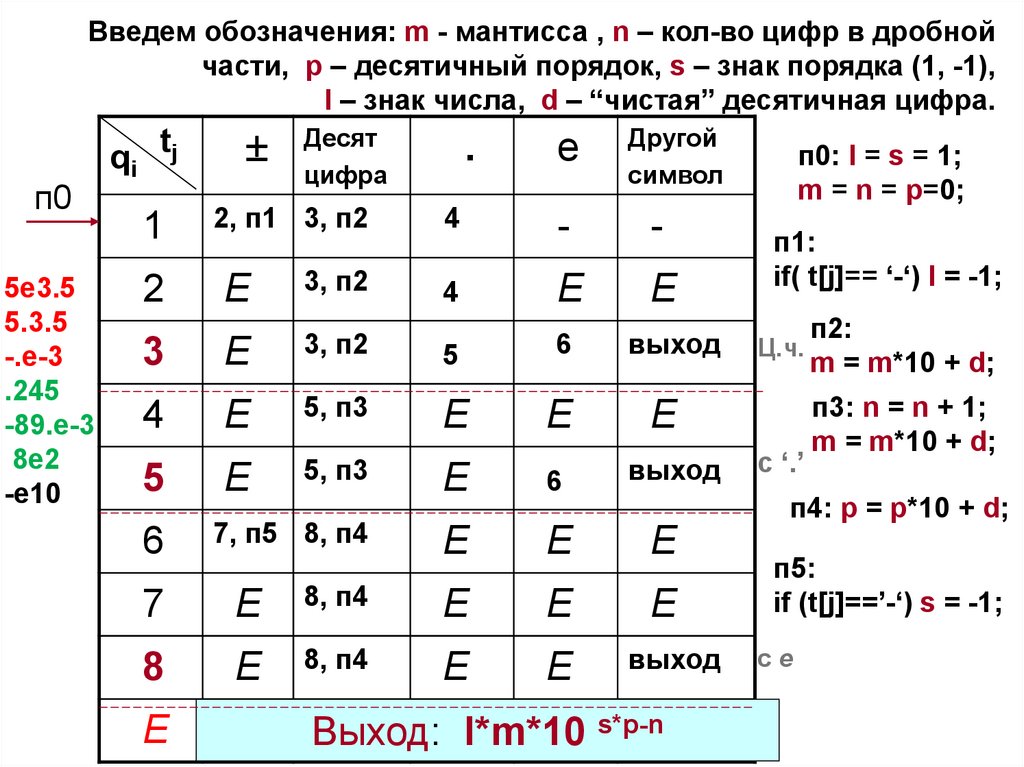
Введем обозначения: m - мантисса , n – кол-во цифр в дробнойчасти, p – десятичный порядок, s – знак порядка (1, -1),
l – знак числа, d – “чистая” десятичная цифра.
п0
5e3.5
5.3.5
-.e-3
.245
-89.e-3
8e2
-e10
qi tj
Десят
цифра
.
e
Другой
символ
1
2, п1 3, п2
4
-
-
2
E
3, п2
4
E
E
3
E
3, п2
5
6
выход
4
E
5, п3
E
E
E
5
E
5, п3
E
6
выход
6
7, п5 8, п4
E
E
E
п1:
if( t[j]== ‘-‘) l = -1;
Ц.ч.
с ‘.’
п2:
m = m*10 + d;
п3: n = n + 1;
m = m*10 + d;
п4: p = p*10 + d;
7
E
8, п4
E
E
E
8
E
8, п4
E
E
выход
E
п0: l = s = 1;
m = n = p=0;
п5:
if (t[j]==’-‘) s = -1;
сe
Неверная
запись вещественной
константы
Выход:
l*m*10 s*p-n
87.
Введем обозначения: m - мантисса , n – кол-во цифр в дробнойчасти, p – десятичный порядок, s – знак порядка (1, -1),
l – знак числа, d – “чистая” десятичная цифра.
п0
5e3.5
5.3.5
-.e-3
.245
-89.e-3
8e2
-e10
1102
qi tj
Десят
цифра
.
e
Другой
символ
1
2, п1 3, п2
4
-
-
2
E
3, п2
4
E
E
3
E
3, п2
5
6
выход
4
E
5, п3
E
E
E
5
E
5, п3
E
6
выход
6
7, п5 8, п4
E
E
E
п1:
if( t[j]== ‘-‘) l = -1;
Ц.ч.
с ‘.’
п2:
m = m*10 + d;
п3: n = n + 1;
m = m*10 + d;
п4: p = p*10 + d;
7
E
8, п4
E
E
E
8
E
8, п4
E
E
выход
E
п0: l = s = 1;
m = n = p=0;
п5:
if (t[j]==’-‘) s = -1;
сe
Неверная
запись вещественной
константы
Выход:
l*m*10 s*p-n
88.
Введем обозначения: m - мантисса , n – кол-во цифр в дробнойчасти, p – десятичный порядок, s – знак порядка (1, -1),
l – знак числа, d – “чистая” десятичная цифра.
п0
5e3.5
5.3.5
-.e-3
.245
-89.e-3
8e2
-e10
1102
.34e-2
qi tj
Десят
цифра
.
e
Другой
символ
1
2, п1 3, п2
4
-
-
2
E
3, п2
4
E
E
3
E
3, п2
5
6
выход
4
E
5, п3
E
E
E
5
E
5, п3
E
6
выход
6
7, п5 8, п4
E
E
E
п1:
if( t[j]== ‘-‘) l = -1;
Ц.ч.
с ‘.’
п2:
m = m*10 + d;
п3: n = n + 1;
m = m*10 + d;
п4: p = p*10 + d;
7
E
8, п4
E
E
E
8
E
8, п4
E
E
выход
E
п0: l = s = 1;
m = n = p=0;
п5:
if (t[j]==’-‘) s = -1;
сe
Неверная
запись вещественной
константы
Выход:
l*m*10 s*p-n
89.
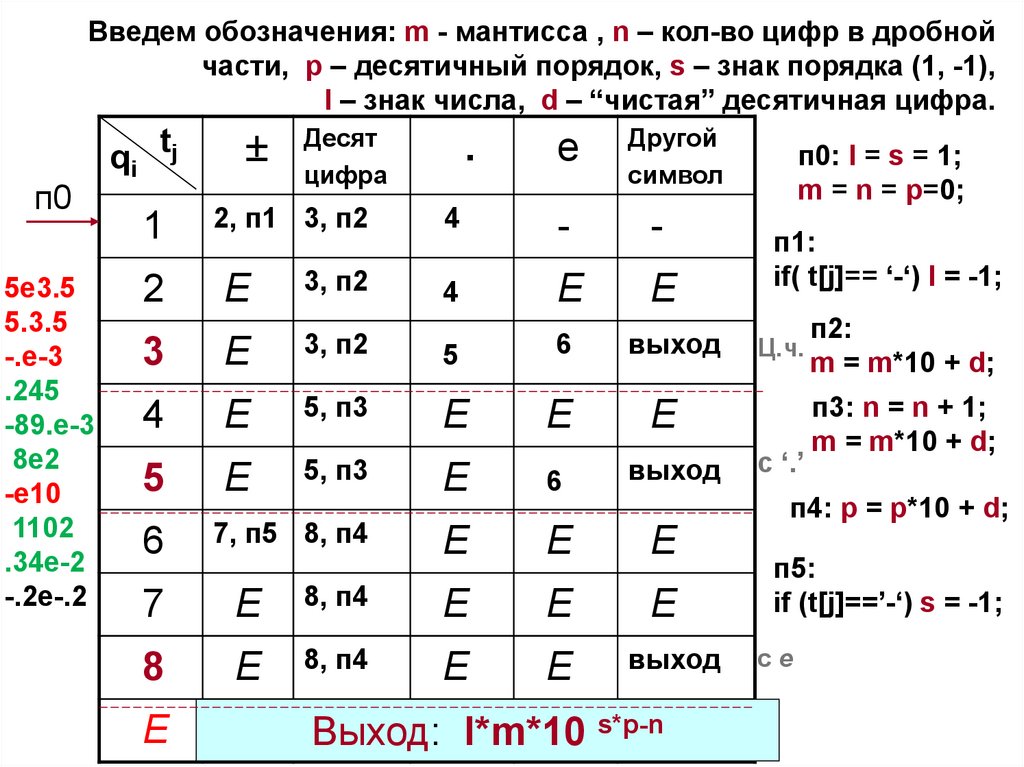
Введем обозначения: m - мантисса , n – кол-во цифр в дробнойчасти, p – десятичный порядок, s – знак порядка (1, -1),
l – знак числа, d – “чистая” десятичная цифра.
п0
5e3.5
5.3.5
-.e-3
.245
-89.e-3
8e2
-e10
1102
.34e-2
-.2e-.2
qi tj
Десят
цифра
.
e
Другой
символ
1
2, п1 3, п2
4
-
-
2
E
3, п2
4
E
E
3
E
3, п2
5
6
выход
4
E
5, п3
E
E
E
5
E
5, п3
E
6
выход
6
7, п5 8, п4
E
E
E
п1:
if( t[j]== ‘-‘) l = -1;
Ц.ч.
с ‘.’
п2:
m = m*10 + d;
п3: n = n + 1;
m = m*10 + d;
п4: p = p*10 + d;
7
E
8, п4
E
E
E
8
E
8, п4
E
E
выход
E
п0: l = s = 1;
m = n = p=0;
п5:
if (t[j]==’-‘) s = -1;
сe
Неверная
запись вещественной
константы
Выход:
l*m*10 s*p-n
90.
Введем обозначения: m - мантисса , n – кол-во цифр в дробнойчасти, p – десятичный порядок, s – знак порядка (1, -1),
l – знак числа, d – “чистая” десятичная цифра.
п0
5e3.5
5.3.5
-.e-3
.245
-89.e-3
8e2
-e10
1102
.34e-2
-.2e-.2
qi tj
Десят
цифра
.
e
Другой
символ
1
2, п1 3, п2
4
-
-
2
E
3, п2
4
E
E
3
E
3, п2
5
6
выход
4
E
5, п3
E
E
E
5
E
5, п3
E
6
выход
6
7, п5 8, п4
E
E
E
п1:
if( t[j]== ‘-‘) l = -1;
Ц.ч.
с ‘.’
п2:
m = m*10 + d;
п3: n = n + 1;
m = m*10 + d;
п4: p = p*10 + d;
7
E
8, п4
E
E
E
8
E
8, п4
E
E
выход
E
п0: l = s = 1;
m = n = p=0;
п5:
if (t[j]==’-‘) s = -1;
сe
Неверная
запись вещественной
константы
Выход:
l*m*10 s*p-n
91. § 2.4. Конструирование сканера
Если алгоритм сканера строить помодели КА, то можно автоматизировать
процесс построения КА, т.е. создать такую
программу конструктор
Грамматика G
в форме БНФ
Матрица
Конструктор
переходов
Для этого, как видно из схемы, надо на вход подать
грамматику G класса 3 в некоторой стандартной форме (БНФ),
на выходе будет сформирована Матрица Переходов МП.
Заметим, что синтаксис лексем определяется
детерминированным КА.
92.
Таким образом, для построения КА требуетсяопределить:
• Q – множество состояний,
• T – множество входных символов,
• q0 – начальное состояние,
• F – множество заключительных состояний.
Все это определяется в результате анализа
правил грамматики.
Правила грамматики класса 3 имеют вид
U -> a
Правила формируются
U -> Va, a T; U, V N
по ДС(1.2 п.2)
93. Определяем КА
КА = { Q = { I + нетерминалы}, T= {терминалы},, I, F = { нетерминалы, соответствующие
лексемам} }
Функция перехода определяется правилами
грамматики. А именно:
При формировании МП состоянию I
соответствует первая строка(и правила вида
U->a), остальным состояниям – другие строки
(и правила вида U->Va).
На пересечении - новое состояние U.
94.
В общем случае КА сканера будетпредставлять собой множество
подавтоматов.
Каждый подавтомат соответствует одной
лексеме.
Переход на подавтомат осуществляется
по первой строке и символу, с которым
происходит вход в МП(см. ДС сканера).
95. Пример
Построить МП для лексемы «Целаяконстанта +со знаком или без знака».
ДС:
ц - цифра
З
I
ЦК
ц
Знак числа
Правила грамматики:
<З>::=+|<ЦК>::= 0|1|2|3|4|5|6|7|8|9|<З>0|<З>1|<З>2|…|<З>9|<ЦК>0|<ЦК>1|<ЦК>2|… |<ЦК>9
КА = { {I, З, ЦК}, {+, -, 0, 1, .., 9}, , I, { ЦК }}
96. МП
+-
0
1
…
9
I
З
З
ЦК
ЦК
…
ЦК
З
error
error
ЦК
ЦК
…
ЦК
ЦК error
error
ЦК
ЦК
…
ЦК
tj
qi
97. Самостоятельно
1. Определить КА и МП дляграмматики
- идентификатора;
2. Определить ДС и МП символьной
константы языка С.
98. Вопросы для повторения
Задача сканера.2 стратегии лексического анализа.
Какая стратегия лучше и почему?
Какие КС-грамматики можно привести к
автоматной?
5. Как построить ДС по грамматике класса 3?
6. Правила анализа по ДС, какая это стратегия.
7. Какой дополнительный блок использует сканер?
8. Таблицы лексического анализатора.
9. Что такое дескриптор?
10. Что такое конструктор?
11. Как формируется грамматика по ДС?
12. Как формируется МП?
1.
2.
3.
4.