



























































































































 Информатика
ИнформатикаПохожие презентации:










Техологии обработки больших объемов данных: вычисления
1.
Большие данныеЮрченков Иван Александрович
Старший преподаватель кафедры прикладной математики ИИТ
yurchenkov@mirea.ru
2.
Тема 4. Техологии обработки большихобъемов данных: вычисления
3.
Тема 4. Техологии обработки большихобъемов данных: вычисления
Операции обработки структурированных табличных данных
4.
Тема 4. Техологии обработки большихобъемов данных: вычисления
Операции обработки структурированных табличных данных
Шкалы данных. Обработка шкал данных
5.
Тема 4. Техологии обработки большихобъемов данных: вычисления
Операции обработки структурированных табличных данных
Шкалы данных. Обработка шкал данных
Очистка данных
6.
Тема 4. Техологии обработки большихобъемов данных: вычисления
Операции обработки структурированных табличных данных
Шкалы данных. Обработка шкал данных
Очистка данных
Фильтрация и сортировка данных
7.
Тема 4. Техологии обработки большихобъемов данных: вычисления
Операции обработки структурированных табличных данных
Шкалы данных. Обработка шкал данных
Очистка данных
Фильтрация и сортировка данных
Агрегация данных
8.
Трансформация данных9.
Трансформация данныхТрансформация данных - это выполнение различных
преобразований данных с целью их подготовки к
анализу или моделированию
10.
Трансформация данных11.
Трансформация данныхВыборка данных (выборка столбцов или атрибутов)
12.
Трансформация данныхВыборка данных (выборка столбцов или атрибутов)
Сортировка данных
13.
Трансформация данныхВыборка данных (выборка столбцов или атрибутов)
Сортировка данных
Фильтрация данных
14.
Трансформация данныхВыборка данных (выборка столбцов или атрибутов)
Сортировка данных
Фильтрация данных
Вычисления столбцов
15.
Трансформация данныхВыборка данных (выборка столбцов или атрибутов)
Сортировка данных
Фильтрация данных
Вычисления столбцов
Агрегация данных (группировка)
16.
Трансформация данныхВыборка данных (выборка столбцов или атрибутов)
Сортировка данных
Фильтрация данных
Вычисления столбцов
Агрегация данных (группировка)
Обогащение данных
17.
Трансформация данныхВыборка данных (выборка столбцов или атрибутов)
Сортировка данных
Фильтрация данных
Вычисления столбцов
Агрегация данных (группировка)
Обогащение данных
Транспонирование данных
18.
Задачи трансформации19.
Задачи трансформацииВ OLTP системах (системы оперативной обработки данных):
• обеспечение поддержки корректности форматов и типов данных
• оптимизация процессов доступа к данным и выгрузки данных
20.
Задачи трансформацииНа этапе ETL-процесса:
• приведение данных в соответствие с моделью, которая
используется в хранилище
• обеспечение процесса консолидации и согласованности данных
для их загрузки в хранилище
21.
Задачи трансформацииВ аналитическом приложении:
• подготовка данных к анализу
• объединение и выделение наиболее ценной информации
• обеспечение корректной работы аналитических алгоритмов
22.
Задачи трансформации23.
Задачи трансформацииСтадии трансформации данных:
очистка и подготовка данных перед загрузкой в хранилище данных
24.
Задачи трансформацииСтадии трансформации данных:
очистка и подготовка данных перед загрузкой в хранилище данных
организация витрин данных на стадии подготовки схем витрин данных для
разных отделов разработки
25.
Задачи трансформацииСтадии трансформации данных:
очистка и подготовка данных перед загрузкой в хранилище данных
организация витрин данных на стадии подготовки схем витрин данных для
разных отделов разработки
оптимизация данных для моделирования
26.
Задачи трансформацииСтадии трансформации данных:
очистка и подготовка данных перед загрузкой в хранилище данных
организация витрин данных на стадии подготовки схем витрин данных для
разных отделов разработки
оптимизация данных для моделирования
организация подведения аналитических отчетностей
27.
Задачи трансформации28.
Шкалы данных29.
Шкалы данныхШкала измерения в статистике — это способ представления
переменных и их группировки в различные категории
Она определяет характер значений, присвоенных переменным в
наборе данных.
30.
Шкалы данных31.
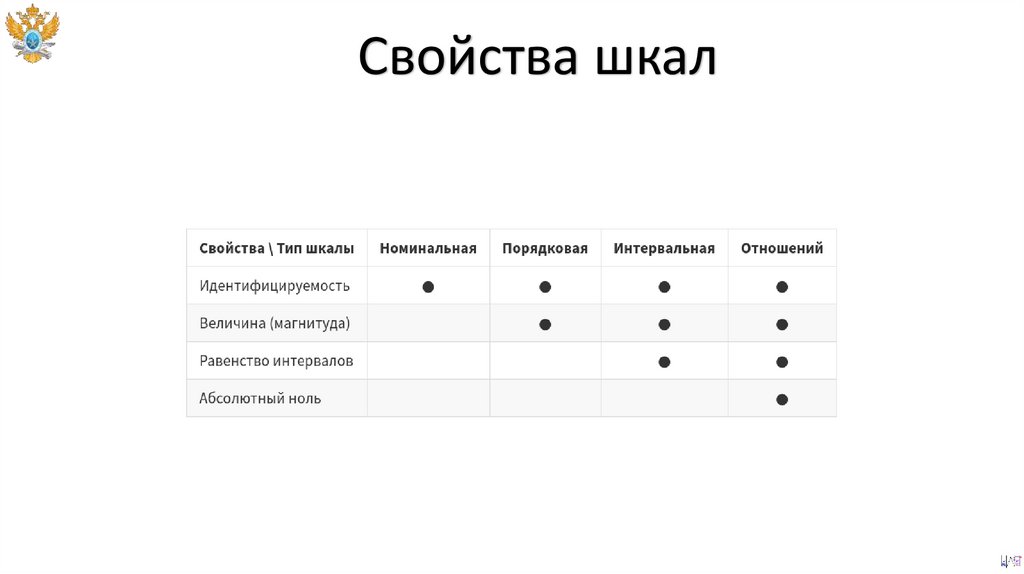
Свойства шкалОсновными свойствами шкал измерений
являются:
32.
Свойства шкалОсновными свойствами шкал измерений
являются:
Идентифицируемость
33.
Свойства шкалОсновными свойствами шкал измерений
являются:
Идентифицируемость
Величина
34.
Свойства шкалОсновными свойствами шкал измерений
являются:
Идентифицируемость
Величина
Равенство интервалов
35.
Свойства шкалОсновными свойствами шкал измерений
являются:
Идентифицируемость
Величина
Равенство интервалов
Абсолютный ноль
36.
Номинальная шкалаНоминальная шкала: описание групп статистик, подписи
визуализации.
37.
Порядковая шкалаПорядковая шкала: то же, что и номинальная шкала, плюс расчет
квантилей, исследование градации.
38.
Интервальная шкала39.
Шкала отношений40.
Свойства шкал41.
Дискретные данные42.
Дискретные данныеДискретные данные являются значениями признака,
общее число которых конечной или бесконечно, но
может быть подсчитано при помощи натуральных чисел.
43.
Непрерывные данныеНепрерывные данные – это данные, которые могут принимать любые значения в
некотором интервале.
Тип данных
Числовой
Строковый
Логический
Дата/время
Вид данных
Непрерывный
Дискретный
+
+
+
+
+
+
44.
Очистка данных45.
Грязные данные46.
Грязные данныеГрязные данные - это неверные, недостаточные, не несущие
никакой пользы. К таковым относится информация, представленная
в некорректном формате или несоответствующая критериям. Они
появились вместе с системой ввода данных.
47.
Грязные данныеПричины появления грязных данных:
• ошибка во время ввода
48.
Грязные данныеПричины появления грязных данных:
• ошибка во время ввода
• противоречие критериям
49.
Грязные данныеПричины появления грязных данных:
• ошибка во время ввода
• противоречие критериям
• отсутствие оперативного обновления
50.
Грязные данныеПричины появления грязных данных:
• ошибка во время ввода
• противоречие критериям
• отсутствие оперативного обновления
• неправильное обновление копий данных
51.
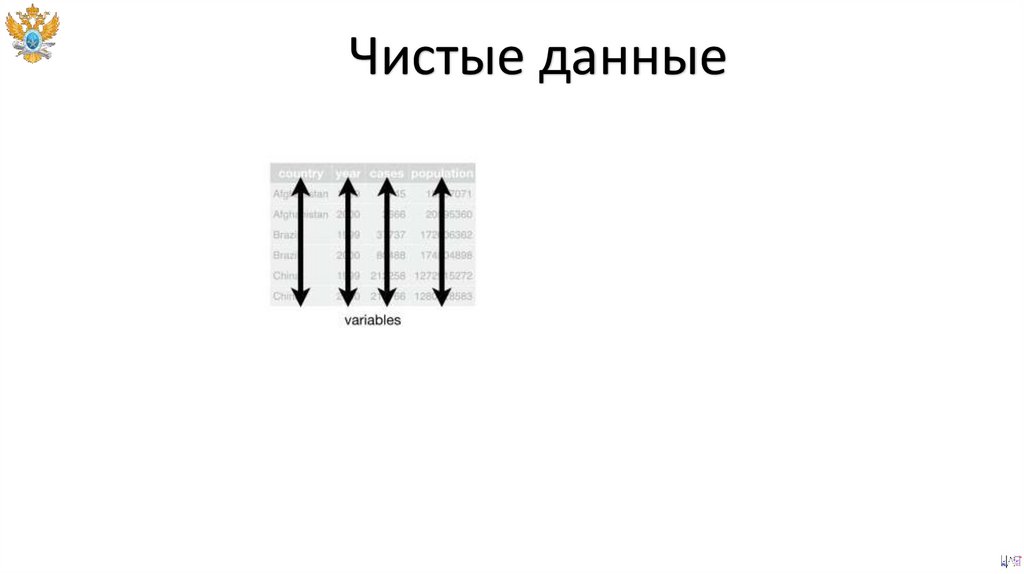
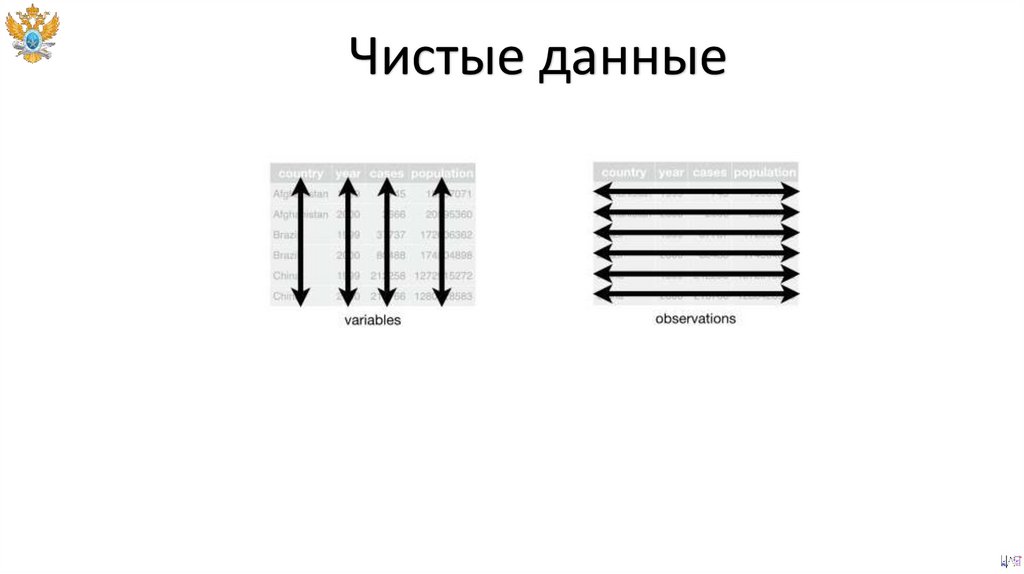
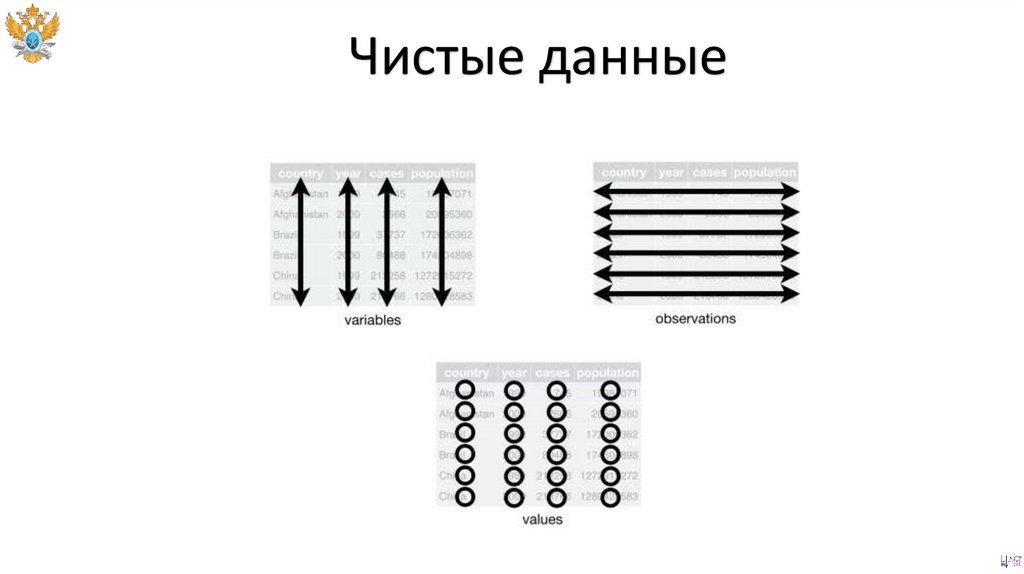
Чистые данныеЧистые данные представляют собой табличный набор
наблюдений в котором каждой строке данных
соответствует
полный
перечень
атрибутов
c
адекватными значениями.
52.
Чистые данные53.
Чистые данные54.
Чистые данные55.
Чистые данные56.
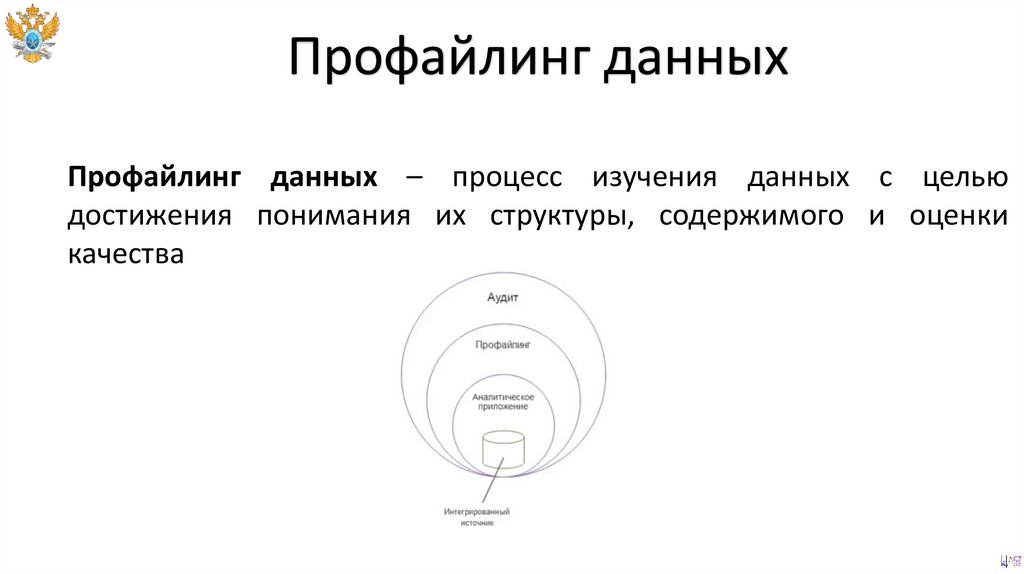
Профайлинг данныхПрофайлинг данных – процесс изучения данных с целью
достижения понимания их структуры, содержимого и оценки
качества
57.
Профайлинг данныхПрофайлинг данных включает в себя следующие этапы:
• Подведение общих описательных статистик по выборке.
58.
Профайлинг данныхПрофайлинг данных включает в себя следующие этапы:
• Подведение общих описательных статистик по выборке.
• Обнаружение пропусков.
59.
Профайлинг данныхПрофайлинг данных включает в себя следующие этапы:
• Подведение общих описательных статистик по выборке.
• Обнаружение пропусков.
• Обнаружение выбросов и экстремальных значений.
60.
Профайлинг данныхПрофайлинг данных включает в себя следующие этапы:
• Подведение общих описательных статистик по выборке.
• Обнаружение пропусков.
• Обнаружение выбросов и экстремальных значений.
• Обнаружение дубликатов и противоречий.
61.
Профайлинг данныхПрофайлинг данных включает в себя следующие этапы:
• Подведение общих описательных статистик по выборке.
• Обнаружение пропусков.
• Обнаружение выбросов и экстремальных значений.
• Обнаружение дубликатов и противоречий.
• Сложные проверки.
62.
Профайлинг данных63.
Пропуски данных64.
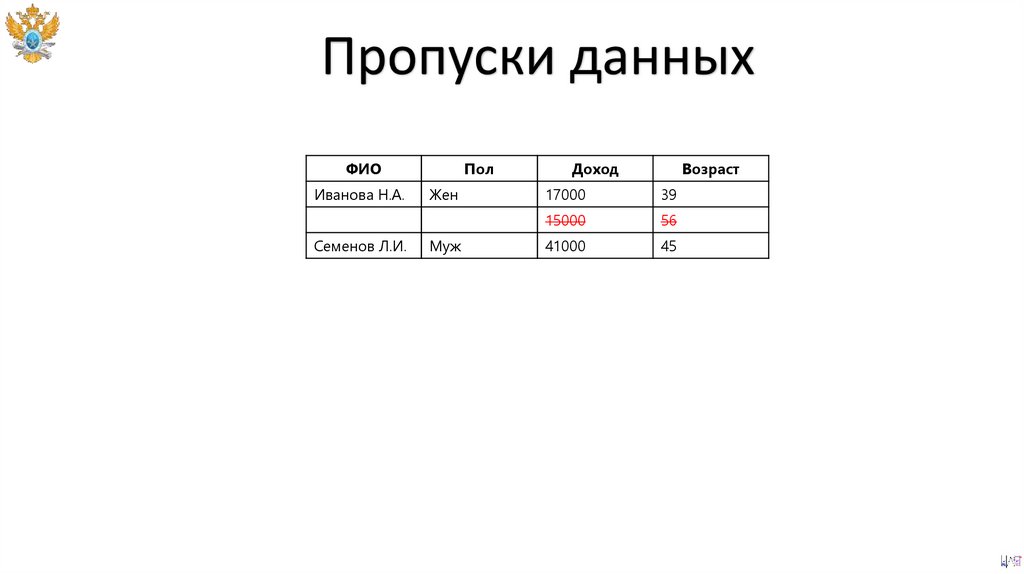
Пропуски данныхФИО
Иванова Н.А.
Семенов Л.И.
Пол
Жен
Муж
Доход
Возраст
17000
39
15000
56
41000
45
65.
Пропуски данныхФИО
Иванова Н.А.
Семенов Л.И.
Пол
Жен
Муж
Доход
Возраст
17000
39
15000
56
41000
45
66.
Стратегии борьбы с пропусками67.
Стратегии борьбы с пропускамиЧисло пропусков:
• Очень малое (до 0.5 - 1%) – можно удалить примеры
68.
Стратегии борьбы с пропускамиЧисло пропусков:
• Очень малое (до 0.5 - 1%) – можно удалить примеры
• Незначительное (1 - 1.5%) – рекомендуется восстановление пропусков
69.
Стратегии борьбы с пропускамиЧисло пропусков:
• Очень малое (до 0.5 - 1%) – можно удалить примеры
• Незначительное (1 - 1.5%) – рекомендуется восстановление пропусков
• Среднее (1.5-30%) и большое (30-50%) – пропуски необходимо восстановить,
результаты могут быть неадекватны
70.
Стратегии борьбы с пропускамиЧисло пропусков:
• Очень малое (до 0.5 - 1%) – можно удалить примеры
• Незначительное (1 - 1.5%) – рекомендуется восстановление пропусков
• Среднее (15-30%) и большое (30-50%) – пропуски необходимо восстановить,
результаты могут быть неадекватны
• Очень большое (50% и выше) – лучше отказаться от анализа набора данных
71.
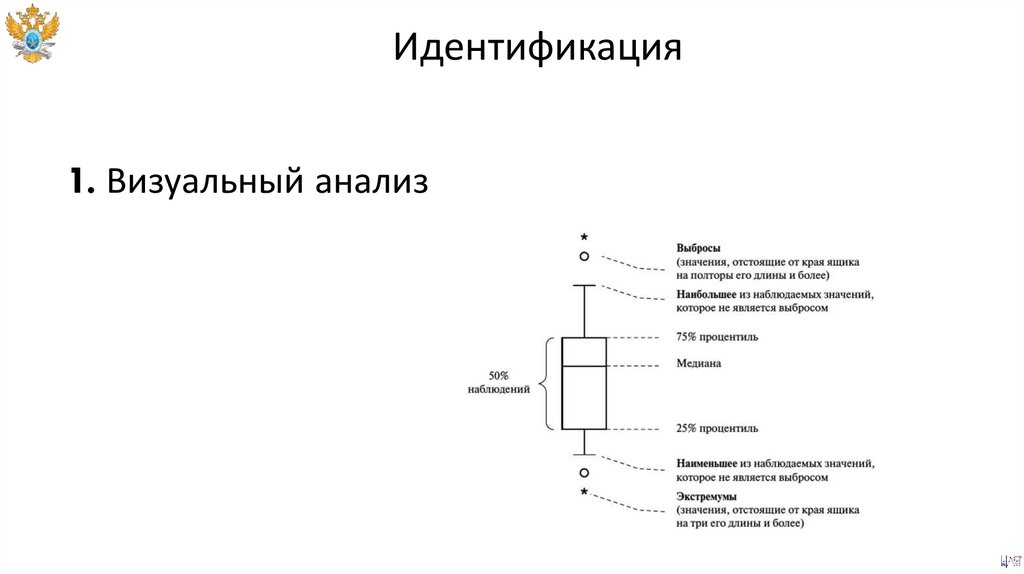
Выбросы и экстремальные значения72.
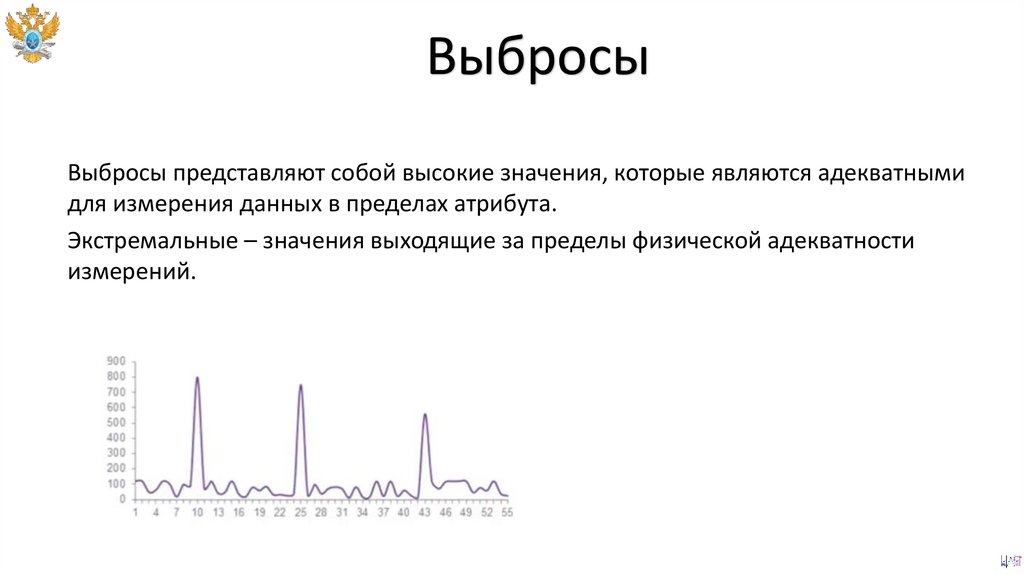
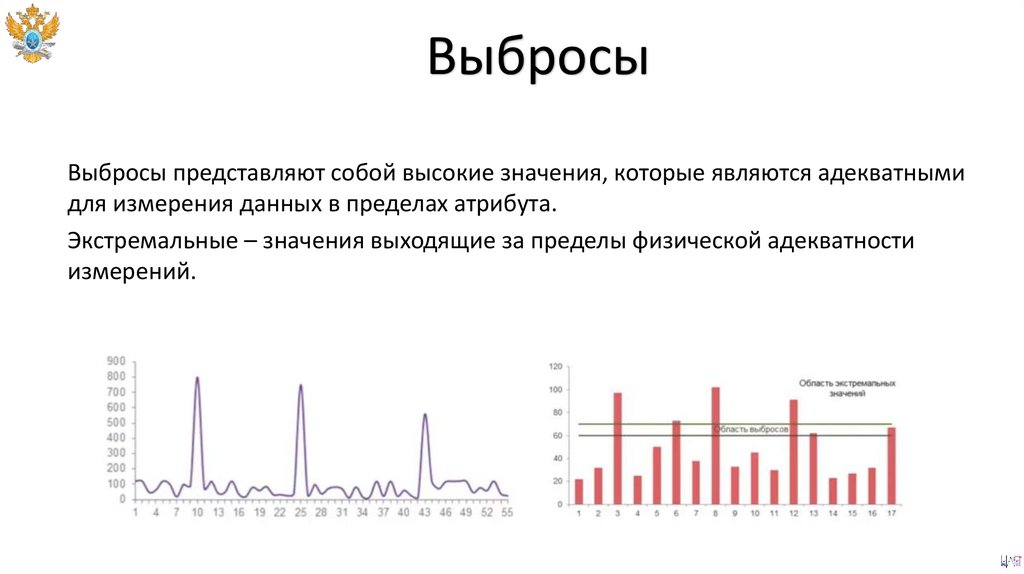
ВыбросыВыбросы представляют собой высокие значения, которые являются адекватными
для измерения данных в пределах атрибута.
73.
ВыбросыВыбросы представляют собой высокие значения, которые являются адекватными
для измерения данных в пределах атрибута.
Экстремальные – значения выходящие за пределы физической адекватности
измерений.
74.
ВыбросыВыбросы представляют собой высокие значения, которые являются адекватными
для измерения данных в пределах атрибута.
Экстремальные – значения выходящие за пределы физической адекватности
измерений.
75.
ВыбросыВыбросы представляют собой высокие значения, которые являются адекватными
для измерения данных в пределах атрибута.
Экстремальные – значения выходящие за пределы физической адекватности
измерений.
76.
Идентификация77.
Идентификация1. Визуальный анализ
78.
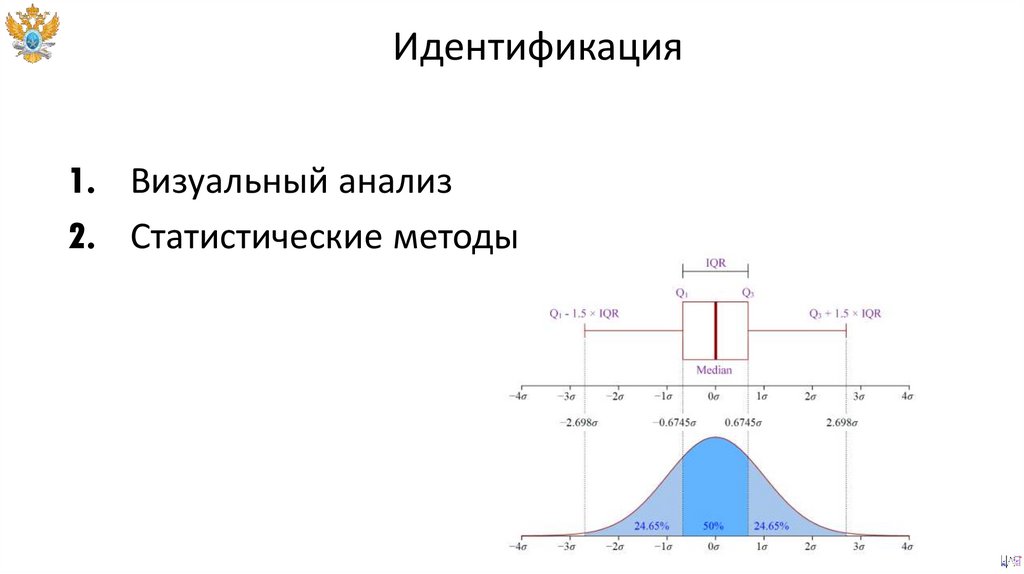
Идентификация1. Визуальный анализ
2. Статистические методы
79.
Идентификация1. Визуальный анализ
2. Статистические методы
3. Машинное обучение
80.
Обработка81.
Обработка1. Удаление выбросов
82.
Обработка1. Удаление выбросов
2. Замена выбросов
83.
Обработка1. Удаление выбросов
2. Замена выбросов
3. Использование специализированных моделей
84.
Обработка1.
2.
3.
4.
Удаление выбросов
Замена выбросов
Использование специализированных моделей
Интерпретация выбросов
85.
Фильтрация и сортировка данных86.
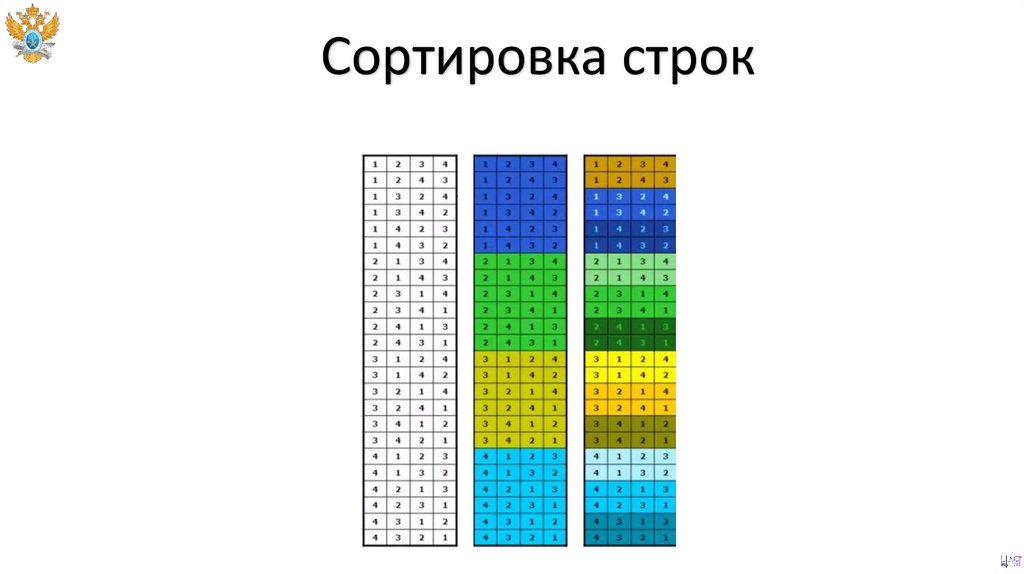
Сортировка данных87.
Сортировка данныхСортировка табличных данных – преобразование,
упорядочивающее набор объектов (строк) или
наблюдений в связи с правилом упорядочивания по
выбранным атрибутам.
88.
Сортировка строк89.
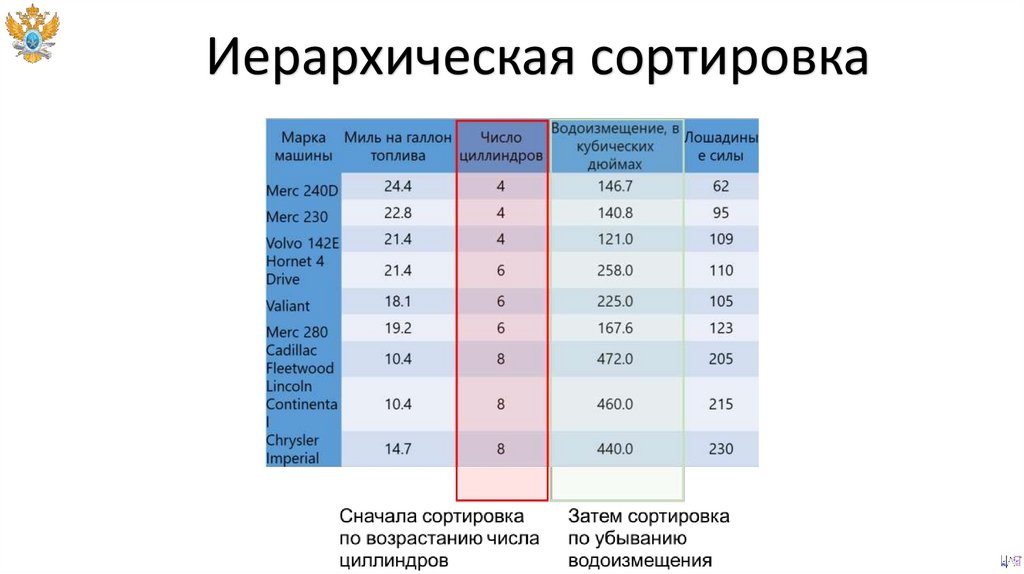
Иерархическая сортировка90.
Иерархическая сортировкаSELECT
марка машины,
миль на галлон топлива,
число циллиндров,
водоизмещение,
лошадиные силы
FROM
машины
ORDER BY
число циллиндров ASC,
водоизмещение DESC;
91.
Применение92.
Применение• Визуализация данных
93.
Применение• Визуализация данных
• Вычисления определенных статистических процедур (ABCанализ, XYZ-анализ)
94.
Применение• Визуализация данных
• Вычисления определенных статистических процедур (ABCанализ, XYZ-анализ)
• Упорядочивания данных для обеспечения логической
адекватности набора данных (если данные собираются не
синхронно)
95.
Фильтрация96.
ФильтрацияФильтрация данных — операция выборки строк
(объектов) или наблюдений из таблицы данных в
соответствии с логическим правилом сравнения
значений выбранного атрибута с определенным
значением.
97.
Фильтрация98.
Фильтрация99.
ФильтрацияСравнения >=, >, = (==), !=, <, <=;
100.
ФильтрацияСравнения >=, >, = (==), !=, <, <=;
В интервале, вне интервала, в полуинтервале, вне полуинтвервала (сложные
фильтры по одному столбцу);
101.
ФильтрацияСравнения >=, >, = (==), !=, <, <=;
В интервале, вне интервала, в полуинтервале, вне полуинтвервала (сложные
фильтры по одному столбцу);
В списке, вне списка (для строк);
102.
ФильтрацияСравнения >=, >, = (==), !=, <, <=;
В интервале, вне интервала, в полуинтервале, вне полуинтвервала (сложные
фильтры по одному столбцу);
В списке, вне списка (для строк);
Содержит, не содержит (для строк);
103.
ФильтрацияСравнения >=, >, = (==), !=, <, <=;
В интервале, вне интервала, в полуинтервале, вне полуинтвервала (сложные
фильтры по одному столбцу);
В списке, вне списка (для строк);
Содержит, не содержит (для строк);
Возможно использование сложных фильтров, содержащих несколько условий,
связанных логическими операциями «И», «ИЛИ», «НЕ», и использующих для
отбора несколько значений из разных столбцов.
104.
Фильтрация105.
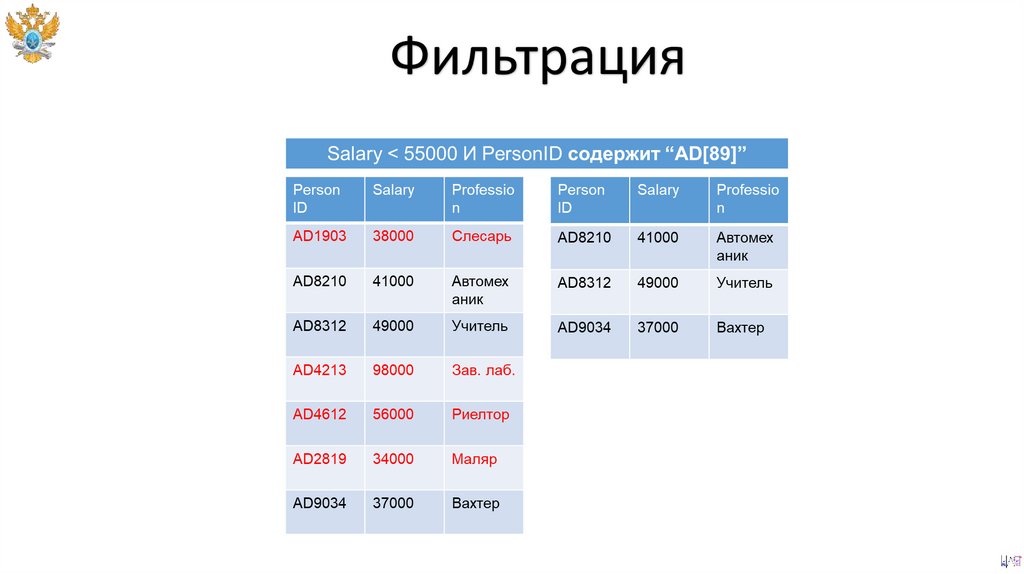
ФильтрацияПример на языке SQL по фильтрации таблицы users:
• SELECT
PersonID,
Salary,
Profession
• FROM
users
• WHERE
Salary < 55000 AND
PersonID LIKE “AD[89]_%”;
106.
ФильтрацияПримеры применения фильтрации наблюдений:
107.
ФильтрацияПримеры применения фильтрации наблюдений:
1. Выборка актуальных наблюдений по временному периоду
108.
ФильтрацияПримеры применения фильтрации наблюдений:
1. Выборка актуальных наблюдений по временному периоду
2. Выборка данных с заранее заданными значениями
категориальных атрибутов или столбцов
109.
ФильтрацияПримеры применения фильтрации наблюдений:
1. Выборка актуальных наблюдений по временному периоду
2. Выборка данных с заранее заданными значениями категориальных атрибутов
или столбцов
3. Выборка данных с определенными номерами строк индексированной строковой
таблицы данных
110.
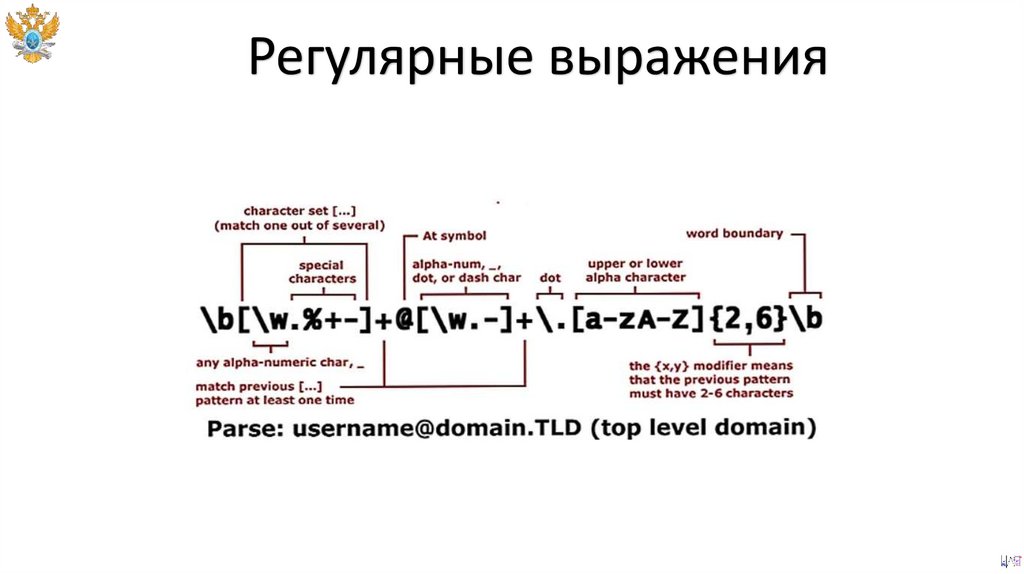
Регулярные выражения111.
Шаблон112.
ШаблонОсновные классы символов:
• Указатели ^, $
113.
ШаблонОсновные классы символов:
• Указатели ^, $
• Метасимволы ., |, \
114.
ШаблонОсновные классы символов:
• Указатели ^, $
• Метасимволы ., |, \
• Классы символов [.], [^.], [:alpha:], ...
[:alnum:], [:alpha:], [:digit:], [:punct:], [:print:], [:space:], [:word:]
115.
ШаблонОсновные классы символов:
• Указатели ^, $
• Метасимволы ., |, \
• Классы символов [.], [^.], [:alpha:], ...
• Классы условных символов
\w, \s, \d, \W, \S, \D
116.
ШаблонОсновные классы символов:
• Указатели ^, $
• Метасимволы ., |, \
• Классы символов [.], [^.], [:alpha:], ...
• Классы условных символов
\w, \s, \d, \W, \S, \D
• Группа (...)
117.
ШаблонОсновные классы символов:
• Указатели ^, $
• Метасимволы ., |, \
• Классы символов [.], [^.], [:alpha:], ...
• Классы условных символов
\w, \s, \d, \W, \S, \D
• Группа (...)
• Квантификаторы {n}, {n, m}, ?
118.
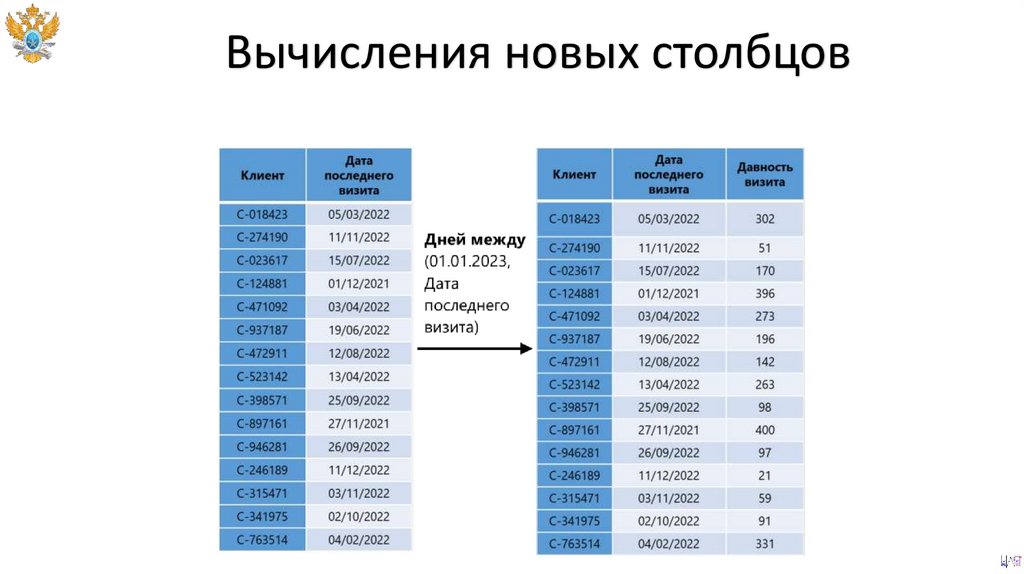
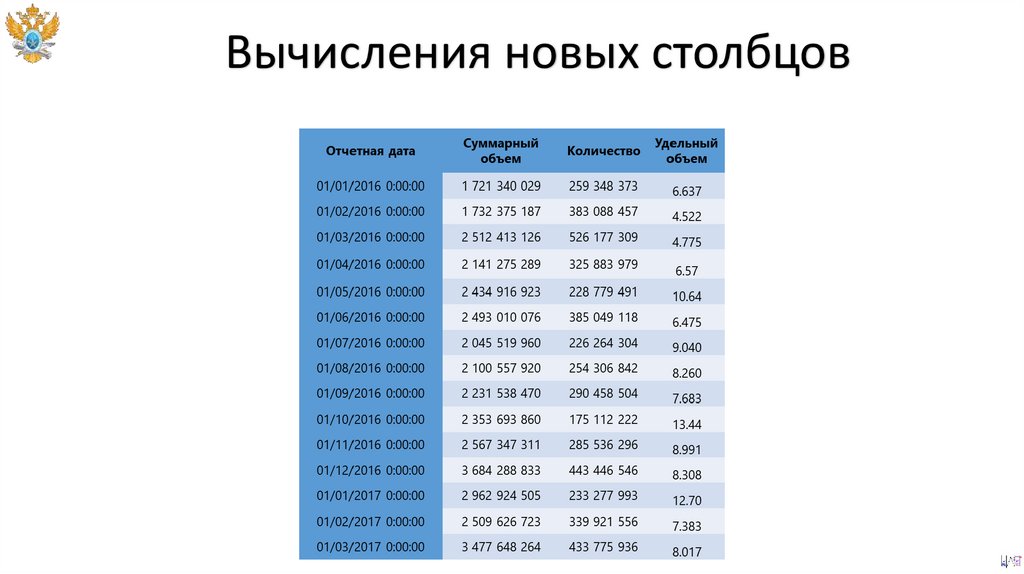
Вычисления новых столбцов119.
Вычисления новых столбцов120.
Вычисления новых столбцов121.
Вычисления новых столбцовSELECT
Отчетная дата,
Суммарный объем,
Количество,
(Суммарный объем / Количество) AS Удельный объем
FROM grouped_table;
122.
Агрегация данных123.
Агрегация данныхГруппировка данных – процесс получения обобщенных
статистик для некоторой большой выборки табличных
данных с целью получить важную информацию по
уникальным группам категорий объектов.
124.
Агрегация данныхГруппа – столбец, значения которого выбираются за
уникальные сущности в пределах которого считается
агрегированный показатель.
Синоним: измерение, категория
125.
Агрегация данныхПоказатель – столбец, значения которого берутся за
основу подсчитанной агрегированной меры на основе
статистических функций агрегации.
126.
Агрегация данныхГруппа: IDчека
Показатель:
Стоимость
(сумма)
127.
Агрегация данныхГруппа: IDчека
Показатель:
Стоимость
(сумма)
128.
Агрегация данныхПодсчёт суммарного чека по
транзакционным данным
• SELECT
IDчека,
SUM(Стоимость),
• FROM
pizza_transactions,
• GROUP BY IDчека;
129.
Дискретизация данных130.
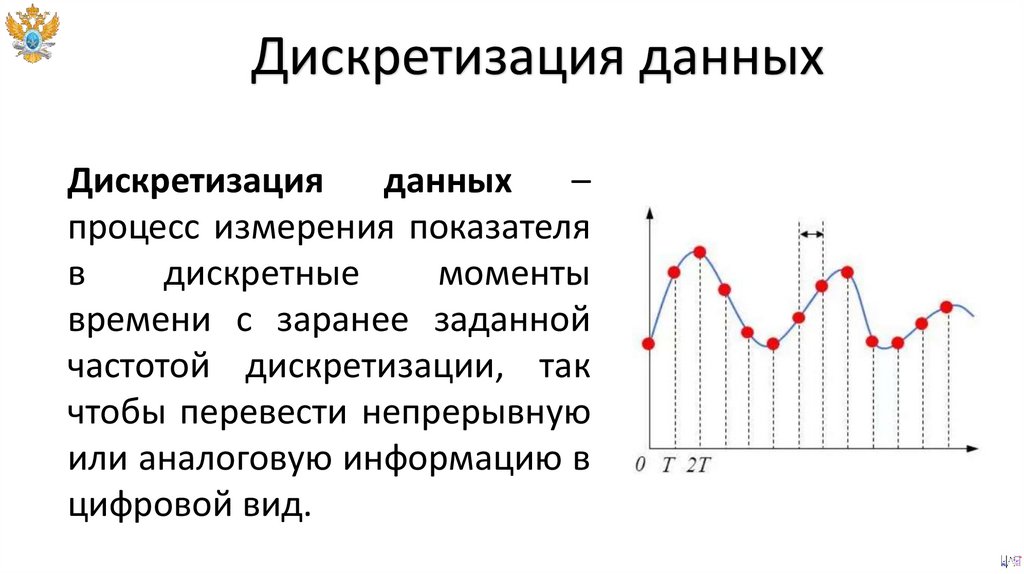
Дискретизация данныхДискретизация
данных
–
процесс измерения показателя
в
дискретные
моменты
времени с заранее заданной
частотой дискретизации, так
чтобы перевести непрерывную
или аналоговую информацию в
цифровой вид.
131.
Квантование данных132.
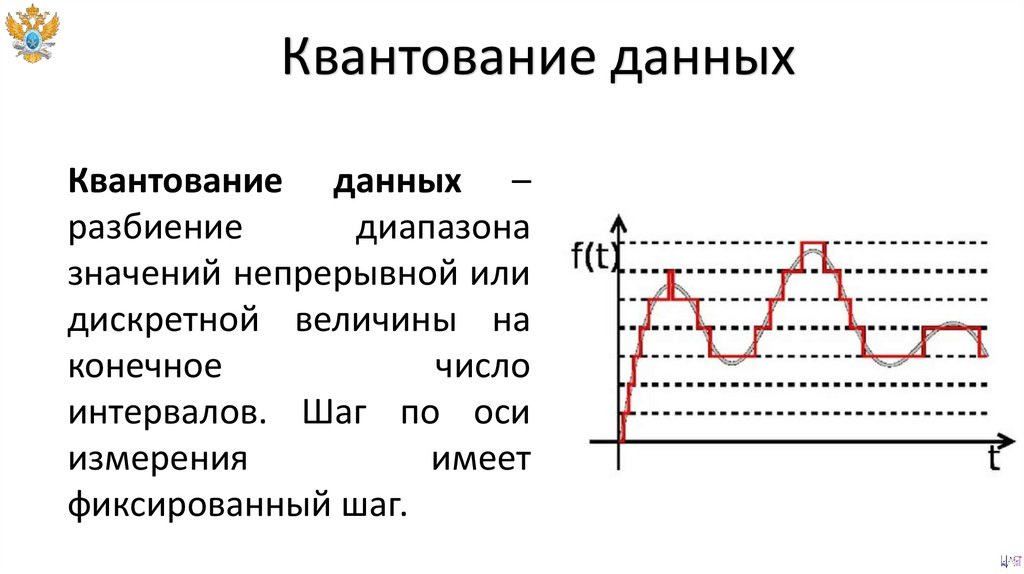
Квантование данныхКвантование данных –
разбиение
диапазона
значений непрерывной или
дискретной величины на
конечное
число
интервалов. Шаг по оси
измерения
имеет
фиксированный шаг.
133.
Задачи группировки134.
Задачи группировки• Визуализация данных
135.
Задачи группировки• Визуализация данных
• Глубокое понимание структуры данных (профайлинг данных)
136.
Задачи группировки• Визуализация данных
• Глубокое понимание структуры данных (аудит данных)
• Уменьшение гранулярности данных
137.
Задачи группировкиВизуализация данных
Глубокое понимание структуры данных (аудит данных)
Уменьшение гранулярности данных
Подведение итогов
138.
Задачи группировкиВизуализация данных
Глубокое понимание структуры данных (аудит данных)
Уменьшение гранулярности данных
Подведение итогов
Подсчёт статистик по уникальным категориям объектов
139.
Функции агрегации140.
Кросс-таблица141.
Заключение• Чистые и грязные данные
• Шкалы и виды данных
• Профайлинг данных
• Сортировка
• Фильтрация
• Агрегация
142.
Спасибо за внимание!ФИО лектора
Должность лектора
Контакты лектора