

















 Программирование
ПрограммированиеПохожие презентации:




")
")




Информатика. Работа с большими данными в строительстве и ЖКХ
1.
Информатика. Работа с большимиданными в строительстве и ЖКХ
НИУ МГСУ 2024
2.
Что такое pandas?Pandas — это библиотека
Python для обработки и
анализа структурированных
данных,
её
название
происходит от «panel data»
(«панельные
данные»).
Панельными
данными
называют
информацию,
полученную в результате
исследований
и
структурированную в виде
таблиц. Для работы с такими
массивами данных и создан
Pandas.
Функциональность pandas включает в себя преобразование данных.
Например, при помощи pandas можно сортировать строки и выделять
подмножества, вычислять сводную статистику, например, среднее
2
значение, изменять формы фреймов и объединять их.
3.
SeriesPandas Series (серия) — это одномерный массив.
Визуально он похож на пронумерованный список: слева в
колонке находятся индексы элементов, а справа — сами
элементы. Индексом может быть числовой показатель (0, 1,
2…) – по умолчанию, буквенные значения (a, b, c…) или
другие данные, выбранные программистом.
3
4.
DataFramePandas DataFrame — это двумерный массив, похожий на таблицу/лист Excel
(кстати, данные из табличных файлов Excel можно читать с помощью
команды pandas.read_excel('file.xls'). В нем можно проводить такие же
манипуляции с данными: объединять в группы, сортировать по определенному
признаку, производить вычисления.
4
5.
Типы данных в Pandas5
6.
Доступ по индексу вDataFrame
Для поиска данных в библиотеке Pandas используются два
метода: .loc и .iloc. Метод .loc предоставляет доступ к данным
по заданному имени строки (индексу) в DataFrame.
Метод .iloc позволяет осуществлять доступ к данным по
порядковому номеру строки в DataFrame.
6
7.
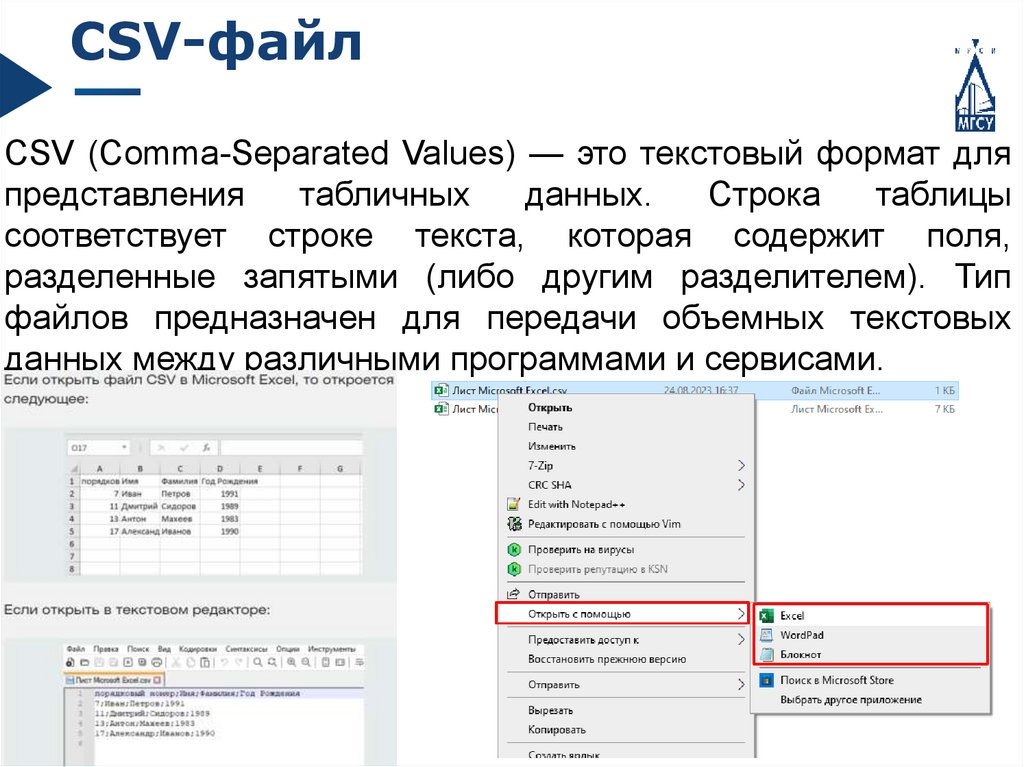
CSV-файлCSV (Comma-Separated Values) — это текстовый формат для
представления
табличных
данных.
Строка
таблицы
соответствует строке текста, которая содержит поля,
разделенные запятыми (либо другим разделителем). Тип
файлов предназначен для передачи объемных текстовых
данных между различными программами и сервисами.
7
8.
Работа с DataFramehead() - по умолчанию выводит пять первых строк: df.head()
Если нужно посмотреть на другое количество строк, оно указывается в скобках,
например df.head(12). Последние строки фрейма выводятся методом .tail().
Также чтобы просто полностью красиво отобразить датасет, используется
функция display(). По умолчанию в Jupyter Notebook, если написать имя
переменной на последней строке какой-либо ячейки (даже без ключевого
слова display), ее содержимое будет отображено.
display(df) #эквивалентно команде df, если это последняя строка
ячейки
8
9.
Фильтрация данных вDataFrame
Иногда бывает нужно получить строки, удовлетворяющие определенному
условию; для этого используется «фильтрация» датафрейма. Условия
могут быть самые разные, рассмотрим несколько примеров и их
синтаксис:
Получение строки с конкретным значением какого-либо столбца (выведем
строку из датасета для Норвегии):
df[df['Страна или регион'] == 'Norway']
Здесь можете найти много
полезной информации
9
10.
Функция в PythonФункция в Python — это мини-программа внутри основной программы, которая отвечает за решение
определённой задачи.
Использование функций позволяет:
•ограничить область видимости переменных функциями, которые их используют;
•исключить дублирование кода;
•разбить большую и сложную программу на небольшие мини-программы, которые можно вызывать
в нужный момент;
•выстроить простую и понятную структуру программы.
Особенности функций:
1.Функция выполняется только тогда, когда её вызывает основная программа.
2.В функцию можно передавать различные данные.
3.Функции могут передавать результаты своей работы в основную программу или в другие функции.
В Python есть встроенные и пользовательские функции.
•Встроенные функции: print(), input(), map(), zip() и так далее.
•Пользовательские функции делятся на:
•рекурсивные (вызывают сами себя до тех пор, пока не будет достигнут нужный результат);
•анонимные (объявляются в любом участке кода и сразу же вызываются).
10
11.
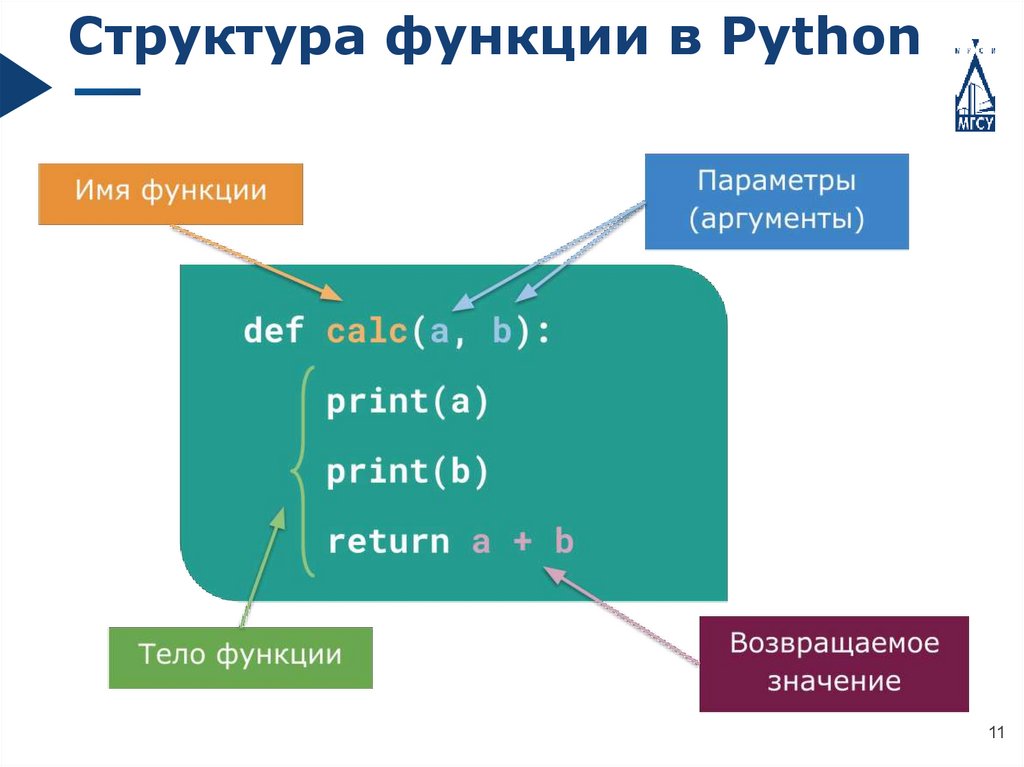
Структура функции в Python11
12.
Функция map в PythonВстроенная в Python функция map () используется для применения функции к
каждому элементу итерируемого объекта (например, списка или словаря) и
возврата нового итератора для получения результатов. Функция map ()
возвращает объект map (итератор), который мы можем использовать в других
частях нашей программы. Также мы можем передать объект map в функцию list
() или другой тип последовательности для создания итерируемого объекта.
12
13.
Лямбда-функции в PythonЛямбда-функции в Python – это встроенная функция для создания анонимных
«команд». Она возвращает выражение. Изначально оно представлено некой
последовательностью букв, чисел и символов, отвечающей за возврат того или
иного значения. Примеры выражений:
• арифметические операции типа a**b или a-b;
• вызовы command вроде sum (a,b), print (“Hi”).
13
14.
Функция filter в PythonФункция filter () в Python применяет другую функцию к заданному
итерируемому объекту (список, строка, словарь и так далее),
проверяя, нужно ли сохранить конкретный элемент или нет. Простыми
словами, она отфильтровывает то, что не проходит и возвращает все
остальное. Объект фильтра — это итерируемый объект. Он сохраняет
те элементы, для которых функция вернула True.
14
15.
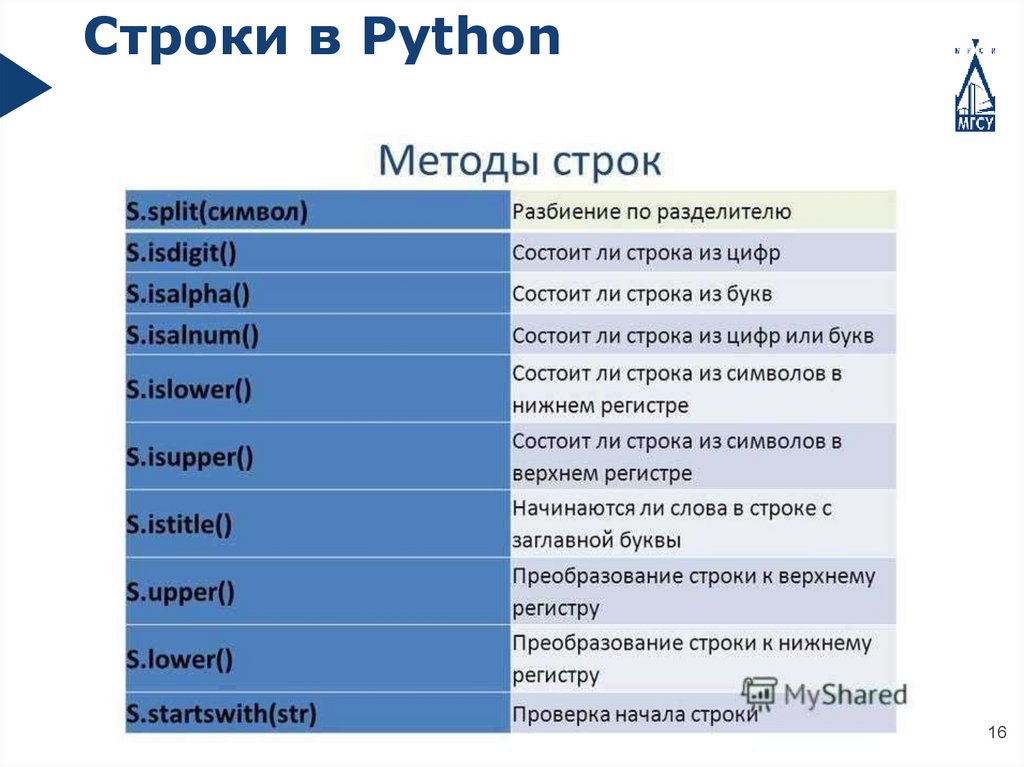
Строки в Python15
16.
Строки в Python16
17.
Строки в Python17
18.
Регулярные выражения вPython
Регулярные выражения - это шаблоны, используемые для сопоставления
комбинаций символов в строках. Они удобны в языке программирования Python
для поиска и даже замены указанного текстового шаблона.
В Python есть модуль под названием RE, который обеспечивает полную поддержку
регулярных выражений. Проще говоря, регулярные выражения Python – это
шаблоны для поиска, описываемые с помощью специального синтаксиса.
18
19.
Регулярные выражения.Библиотека re
Функция
Что делает
re.match (pattern, string)
Ищет pattern в начале
строки string
re.search (pattern, string)
Ищет pattern по всей
строке string
re.finditer (pattern, string)
Ищет pattern по всей
строке string
re.findall (pattern, string)
Ищет pattern по всей
строке string
Если находит
совпадение
Возвращает Matchобъект
Возвращает Matchобъект с первым
совпадением, остальные
не находит
Возвращает итератор,
содержащий Matchобъекты для каждого
найденного совпадения
Возвращает список со
всеми найденными
совпадениями
Если не находит
совпадение
Возвращает None
Возвращает None
Возвращает пустой
итератор
Возвращает None
Возвращает список строк,
Разделяет строку string
Возвращает список строк, единственный элемент
re.split (pattern, string,
по подстрокам,
на которые разделила
которого —
[maxsplit=0])
соответствующим pattern исходную строку
неразделённая исходная
строка
Заменяет в строке string Возвращает строку в
Возвращает строку в
re.sub (pattern, repl, string)
все pattern на repl
изменённом виде
исходном виде
Собирает регулярное
Ничего не ищет, всегда
выражение в объект для
re.compile (pattern)
возвращает Pattern0
19
будущего использования
объект
в других re-функциях
20.
Чтение из файлов CSV(парсинг)
Для того чтобы прочитать данные из файла, программист должен создать объект reader:
reader_object = csv.reader(file, delimiter = ",")
reader имеет является итерируемым объектом, поэтому чтение из файла происходит следующим
образом:
import csv
with open("classmates.csv", encoding='utf-8') as r_file:
# Создаем объект reader, указываем символ-разделитель ","
file_reader = csv.reader(r_file, delimiter = ",")
# Счетчик для подсчета количества строк и вывода заголовков столбцов
count = 0
# Считывание данных из CSV файла
for row in file_reader:
if count == 0:
# Вывод строки, содержащей заголовки для столбцов
print(f'Файл содержит столбцы: {", ".join(row)}')
else:
# Вывод строк
print(f'
{row[0]} - {row[1]} и он родился в {row[2]} году.')
count += 1
print(f'Всего в файле {count} строк.')
20