






















 Электроника
ЭлектроникаПохожие презентации:


")


")




Современные суперкомпьютеры и суперкомпьютерные задачи
1.
Современные суперкомпьютеры исуперкомпьютерные задачи
Игорь Одинцов
Глеб Мармузов
(Группа компаний РСК)
УрФУ, 2019
2.
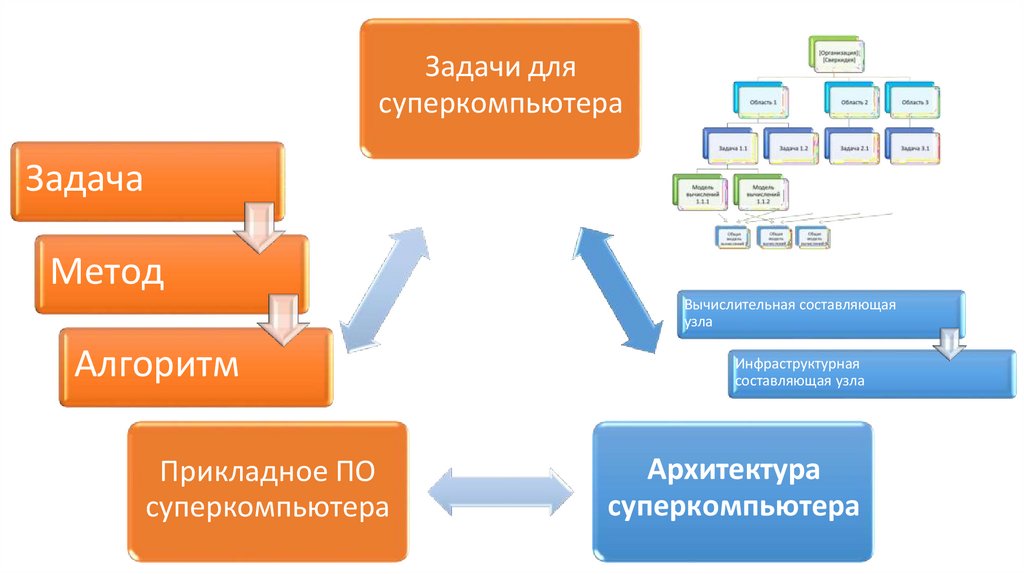
Задачи длясуперкомпьютера
Задача
Метод
Вычислительная составляющая
узла
Алгоритм
Прикладное ПО
суперкомпьютера
Инфраструктурная
составляющая узла
Архитектура
суперкомпьютера
3.
Что такое современный суперкомпьютер?Современные суперкомпьютерные задачи и их отображение на
архитектуру вычислительных узлов
Обзор вычислительной составляющей узла суперкомпьютера
(процессоры, сопроцессоры, память, ...)
Обзор инфраструктурной составляющей узла суперкомпьютера
(охлаждение, питание, мониторинг, ...)
4.
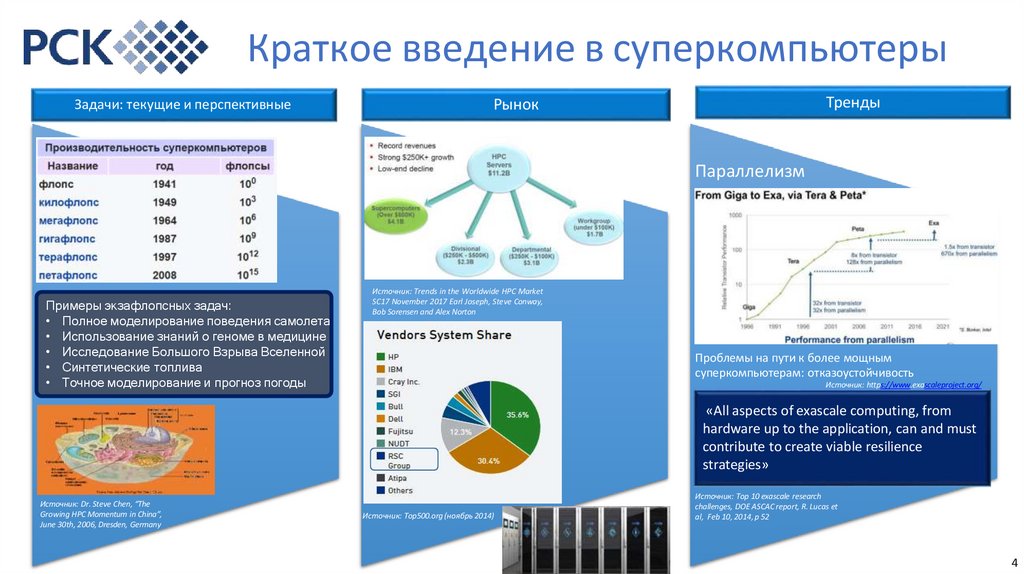
Краткое введение в суперкомпьютерыЗадачи: текущие и перспективные
Тренды
Рынок
Параллелизм
Примеры экзафлопсных задач:
• Полное моделирование поведения самолета
• Использование знаний о геноме в медицине
• Исследование Большого Взрыва Вселенной
• Синтетические топлива
• Точное моделирование и прогноз погоды
Источник: Trends in the Worldwide HPC Market
SC17 November 2017 Earl Joseph, Steve Conway,
Bob Sorensen and Alex Norton
Проблемы на пути к более мощным
суперкомпьютерам: отказоустойчивость
Источник: https://www.exascaleproject.org/
«All aspects of exascale computing, from
hardware up to the application, can and must
contribute to create viable resilience
strategies»
Источник: Dr. Steve Chen, “The
Growing HPC Momentum in China”,
June 30th, 2006, Dresden, Germany
Источник: Top500.org (ноябрь 2014)
Источник: Top 10 exascale research
challenges, DOE ASCAC report, R. Lucas et
al, Feb 10, 2014, p 52
4
5.
Аппаратная архитектура суперкомпьютера6.
Про типы суперкомпьютеровТипы
суперкомпьютеров
Универсальные
Проблемноориентированные
Некоторые специализированные:
Специализированные
Для большинства
измеряем
производительность с помощью
теста Linpack
(решение
больших систем
линейных
уравнений)
https://ru.wikipedia.org/wiki/TOP500
MDGrape-3 — суперкомпьютер предназначенный
для решения задач молекулярной динамики, а
именно моделирования сворачивания белков. На
момент ввода в работу обладал рекордной
теоретической производительностью в 1000
триллионов операций в секунду.
Антон — 512-процессорный суперкомпьютер,
созданный частной компанией D. E. Shaw Research
для моделирования молекул и лекарств, назван в
честь пионера микробиологии Антони ван
Левенгука. Процессоры с частотой всего 400 МГц,
машина имеет скромную память, но это
компенсируется архитектурой, которая позволяет
обойти эту проблему массивно-параллельным
методом.
7.
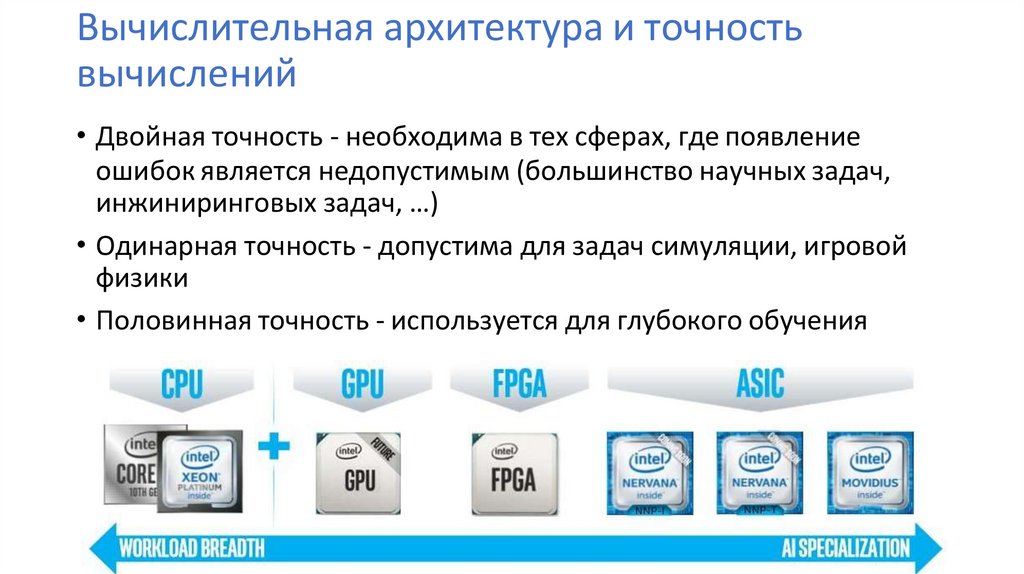
Вычислительная архитектура и точностьвычислений
• Двойная точность - необходима в тех сферах, где появление
ошибок является недопустимым (большинство научных задач,
инжиниринговых задач, …)
• Одинарная точность - допустима для задач симуляции, игровой
физики
• Половинная точность - используется для глубокого обучения
8.
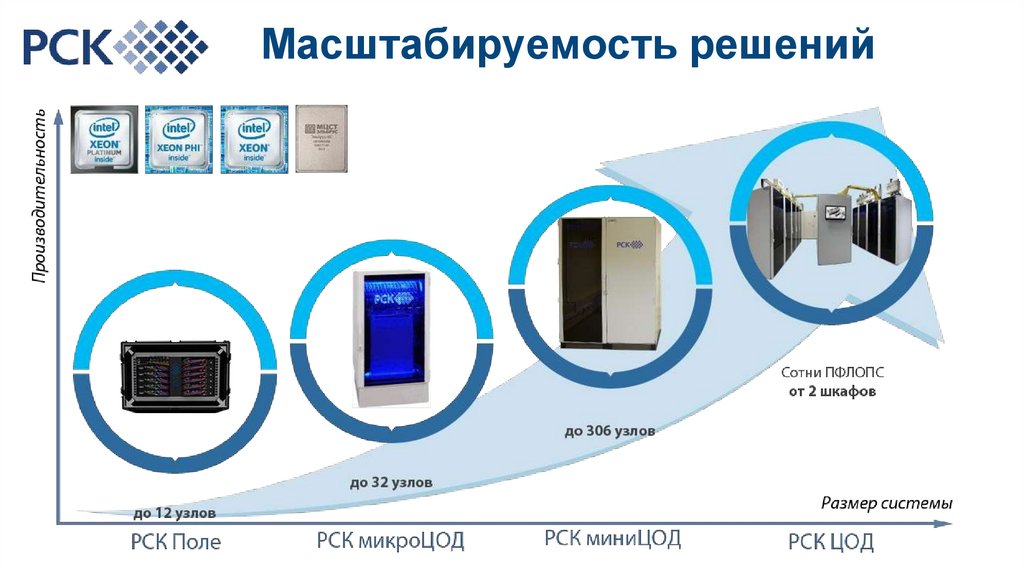
Масштабируемость решений9.
Современные суперкомпьютеры10
Решение актуальных проблем в:
• механике,
• гидро- и аэродинамике,
• физике твердого тела и плазмы,
• материаловедении,
• электронике,
• вычислительной и квантовой химии,
• биофизике и биотехнологиях.
10.
Что такое современный суперкомпьютер?Современные суперкомпьютерные задачи и их отображение на
архитектуру вычислительных узлов
Обзор вычислительной составляющей узла суперкомпьютера
(процессоры, сопроцессоры, память, ...)
Обзор инфраструктурной составляющей узла суперкомпьютера
(охлаждение, питание, мониторинг, ...)
11.
Современные суперкомпьютерныезадачи
Классические мощные
вычислительные задачи
Задачи из специфических
предметных областей
Обработка больших
данных
Искусственный интеллект
(глубокое обучение)
12
Предметная область
Аэродинамика
10 Petaflops
Лазерная оптика
20 Petaflops
Молекулярная динамика
200 Petaflops
Аэродинамический дизайн
1 Exaflops
Вычислительная космология
10 Exaflops
Турбулентность в физике
100 Exaflops
Вычислительная химия
1 Zettaflops
12.
Что такое суперкомпьютерные задачи?НРС:
• Математические проблемы:
• Криптография
• Статистика
• Физика высоких энергий:
• процессы внутри атомного ядра, физика плазмы, анализ данных экспериментов, проведённых на ускорителях
• разработка и совершенствование атомного и термоядерного оружия, управление ядерным арсеналом,
моделирование ядерных испытаний
• моделирование жизненного цикла ядерных топливных элементов, проекты ядерных и термоядерных реакторов
• Наука о Земле:
• прогноз погоды, состояния морей и океанов
• предсказание климатических изменений и их последствий
• исследование процессов, происходящих в земной коре, для предсказания землетрясений и извержений вулканов
• анализ данных геологической разведки для поиска и оценки нефтяных и газовых месторождений, моделирование
процесса выработки месторождений
• моделирование растекания рек во время паводка, растекания нефти во время аварий
• Вычислительная биология: фолдинг белка, расшифровка ДНК
• Вычислительная химия и медицина: изучение строения вещества и природы химической связи как в изолированных
молекулах, так и в конденсированном состоянии, поиск и создание новых лекарств
• Физика:
• газодинамика: турбины электростанций, горение топлива, аэродинамические процессы для создания совершенных
форм крыла, фюзеляжей самолетов, ракет, кузовов автомобилей
• гидродинамика: течение жидкостей по трубам, по руслам рек
• материаловедение: создание новых материалов с заданными свойствами, анализ распределения динамических
нагрузок в конструкциях, моделирование краш-тестов при конструировании автомобилей
ИИ:
• в качестве сервера для обучения искусственных нейронных сетей
• создание принципиально новых способов вычисления и обработки информации (Квантовый компьютер, Искусственный
интеллект)
https://ru.wikipedia.org/wiki/Суперкомпьютер
http://hpc-russia.ru
13.
Программное обеспечение для НРСПопулярные прикладные пакеты для НРС (с открытым программным кодом)
Биоинформатика: BLAST
Молекулярная динамика: GROMACS, LAMPPS, NAMD
Вычислительная химия: GAMESS
Вычислительная гидродинамика: OpenFOAM
Физика высоких энергий: GEANT4, MILC
Погода и климат: NEMO, WRF
14
14.
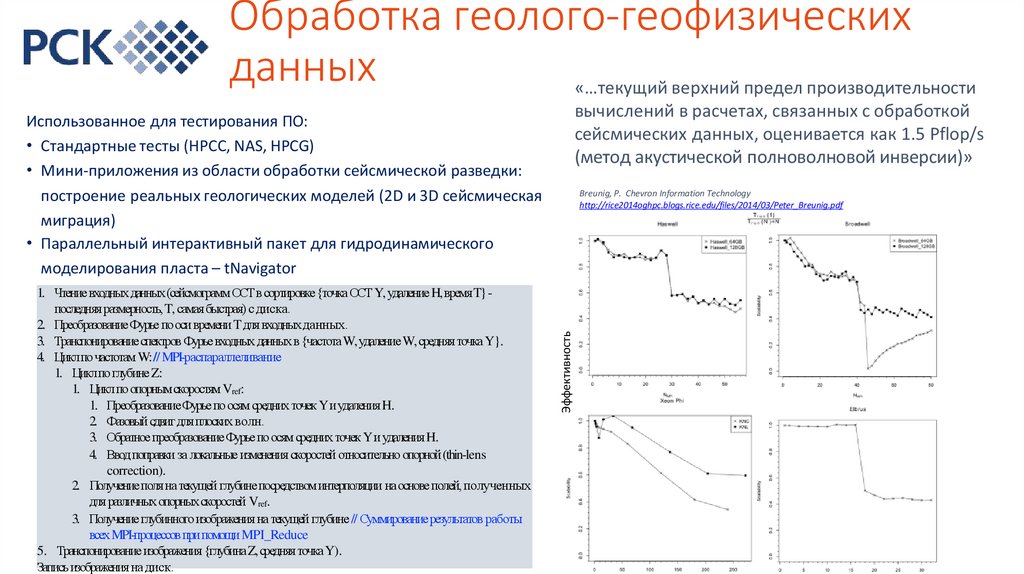
Обработка геолого-геофизическихданных
«…текущий верхний предел производительности
вычислений в расчетах, связанных с обработкой
сейсмических данных, оценивается как 1.5 Pflop/s
(метод акустической полноволновой инверсии)»
Использованное для тестирования ПО:
• Стандартные тесты (HPCC, NAS, HPCG)
• Мини-приложения из области обработки сейсмической разведки:
построение реальных геологических моделей (2D и 3D сейсмическая
миграция)
• Параллельный интерактивный пакет для гидродинамического
моделирования пласта – tNavigator
Эффективность
1. Чтение входных данных(сейсмограмм ОСТв сортировке{точка ОСТ Y, удаление H, времяT} последняя размерность, T, самая быстрая) с диска.
2. ПреобразованиеФурье пооси времени T для входных данных.
3. Транспонированиеспектров Фурье входных данных в {частота W, удаление W, средняя точка Y}.
4. Циклпо частотам W:// MPI-распараллеливание
1. Циклпо глубине Z:
1. Циклпо опорнымскоростям Vref:
1. ПреобразованиеФурье поосям средних точек Yиудаления H.
2. Фазовыйсдвиг для плоских волн.
3. Обратное преобразованиеФурье по осям средних точек Yи удаления H.
4. Ввод поправки за локальные изменения скоростей относительно опорной(thin-lens
correction).
2. Получение поля на текущей глубине посредством интерполяции на основе полей, полученных
для различных опорныхскоростей Vref.
3. Получение глубинного изображения на текущей глубине // Суммированиерезультатов работы
всех MPI-процессовпри помощи MPI_Reduce
5. Транспонирование изображения {глубинаZ,средняя точкаY).
Запись изображения на диск.
Breunig, P. Chevron Information Technology
http://rice2014oghpc.blogs.rice.edu/files/2014/03/Peter_Breunig.pdf
15.
Специализация конфигурацийДля оптимизации соотношения «производительность/стоимость»
в прикладных задачах геофизического моделирования
• Задачи обработки геолого-геофизических данных:
- узлы с процессорами упрощенной архитектуры (например, Intel Xeon Phi),
- 60 вычислительных ядер,
- умеренное количеством оперативной памяти в пересчете на одно
вычислительное ядро.
• Задачи гидродинамического моделирования:
- производительные узлы с процессорами сложной архитектуры (Intel Xeon и т.п.),
- 16-20 вычислительных ядер,
- большое количеством оперативной памяти в пересчете на одно вычислительное
ядро.
16.
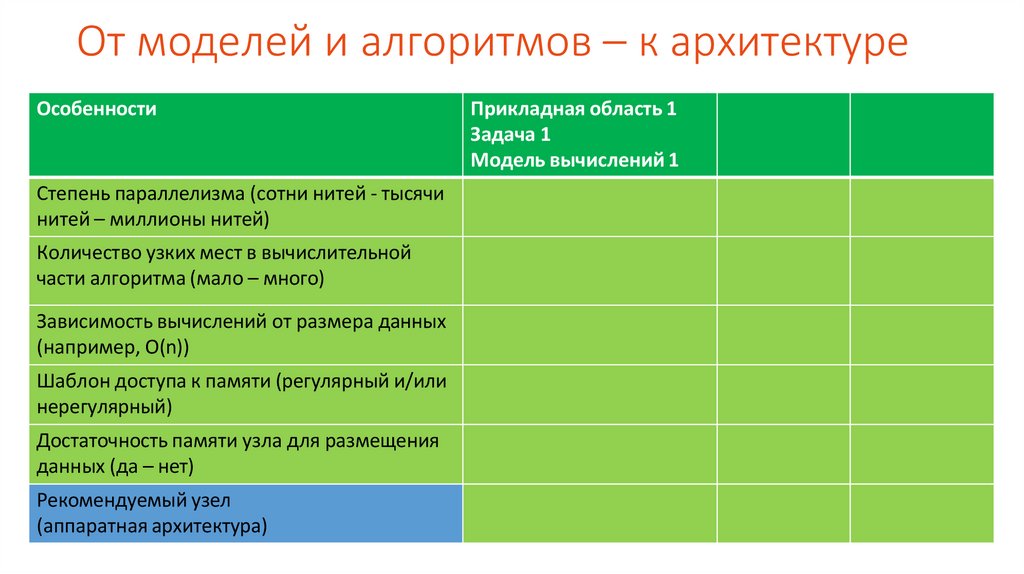
От моделей и алгоритмов – к архитектуреОсобенности
Степень параллелизма (сотни нитей - тысячи
нитей – миллионы нитей)
Количество узких мест в вычислительной
части алгоритма (мало – много)
Зависимость вычислений от размера данных
(например, О(n))
Шаблон доступа к памяти (регулярный и/или
нерегулярный)
Достаточность памяти узла для размещения
данных (да – нет)
Рекомендуемый узел
(аппаратная архитектура)
Прикладная область 1
Задача 1
Модель вычислений 1
17.
Программное обеспечение для ИИИсточник: https://www.intel.ai/hardware/
18.
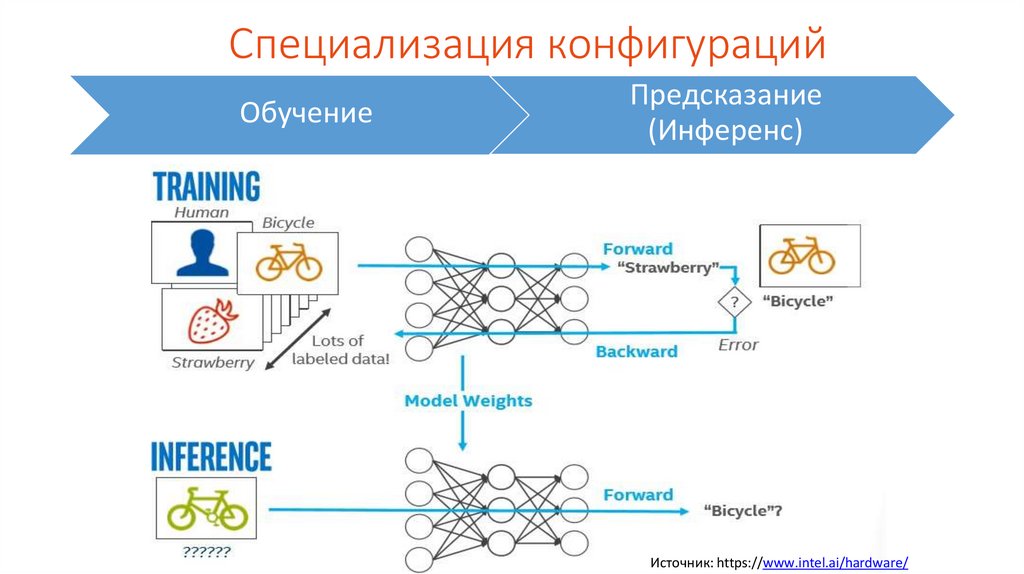
Специализация конфигурацийОбучение
Предсказание
(Инференс)
Источник: https://www.intel.ai/hardware/
19.
От моделей и алгоритмов – к архитектуреИскусственный
интеллект
Интеллектуальные
системы
Машинное
обучение
(индуктивное)
Экспертные
системы
Глубокое
обучение
Источник: https://research.fb.com/wp-content/uploads/2017/12/hpca-2018-facebook.pdf
Рекуррентные
нейронные
сети
Сверточные
нейронные
сети
20.
Что такое современный суперкомпьютер?Современные суперкомпьютерные задачи и их отображение на
архитектуру вычислительных узлов
Обзор вычислительной составляющей узла суперкомпьютера
(процессоры, сопроцессоры, память, ...)
Обзор инфраструктурной составляющей узла суперкомпьютера
(охлаждение, питание, мониторинг, ...)
21.
Современныесуперкомпьютерные узлы
Interconnect
Вычислительная составляющая
узла
22
Инфраструктурная
составляющая узла
22.
Вычислительные универсальные ядра(типичная роль – хост, базовые, «классические
вычислительные», «толстые ядра»)
Традиционный набор команд (CISC) - x86, IA-64, x8664 (Intel, AMD)
Упрощенный набор команд (RISC) - POWER (IBM),
ARM (много производителей)
Сверхдлинное командное слово (VLIW) - Эльбрус
23
23.
Специализированные ядра(типичная роль – ускоритель, сопроцессор, «тонкие ядра»)
Гомогенные, на базе упрощенных универсальных – Xeon Phi (Intel)
Схемы специального назначения (ASIC) и перепрограммируемые (FPGA)
Вычислительные графические ускорители (GPGPU) – Tesla (NVidia)
Тензорные ускорители (матричное умножение и свертка) – TPU (Google)
Специализированные для ИНС - Nervana NNP-T и NNP-I (Intel)
Ускорители алгоритмов работы машинного зрения - Movidius (Intel)
Узкоспециализированные (например, оптическое быстрое преобразование Фурье)
Квантовые ускорители (криптография, молекулярное моделирование, погода)
24
24.
Памятьоперативная и энерго(не)зависимая
DDR-SDRAM (Double Data Rate Synchronous Dynamic Random Access Memory) — синхронная динамическая
память с произвольным доступом и удвоенной скоростью передачи данных
• Самая распространённая технология, поддерживается большинством процессоров. В настоящий момент лидирующий стандарт: DDR4
3D Stacked Memory - технология трехмерного размещения памяти, котрая позволяет интегрировать ОЗУ и
логические блоки микропроцессора, существенно увеличивая пропускную способность
• Следует отметить, что плотность организации 3D Stacked Memory требует специального подхода к охлаждению – требуется жидкостное
охлаждение
SDM (Software Defined Memory) - программно определяемая память. Программно-аппаратные решения
позволяют организовать дополнительный уровень ОЗУ на базе энергонезависимой памяти
• Достоинства - большой объем, недостатки - небольшая пропускная способность по сравнению с DDR. Примером может являться технология IMDT
на базе 3DXPoint NVMe накопителей
Создание промежуточного буфера (Burst Buffer) для работы с данными подразумевает наличие твердотельных
накопителей (в том числе возможно использование устройств SSD) для увеличения производительности ввода-вывода
Полная интеграция уровня хранения с уровнем обработки (гиперконвергентность) - это решение, которое используется в
больших, гипер-масштабируемых ЦОД. Многие современные HPC платформы видят будущее именно в создании
гиперконвергентных решений
25
25.
26.
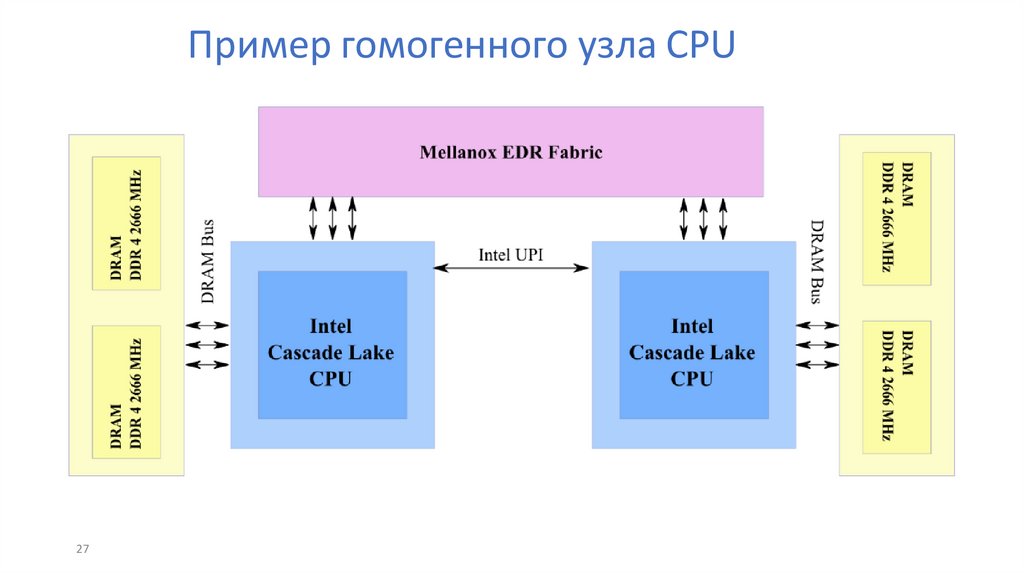
Пример гомогенного узла CPU27
27.
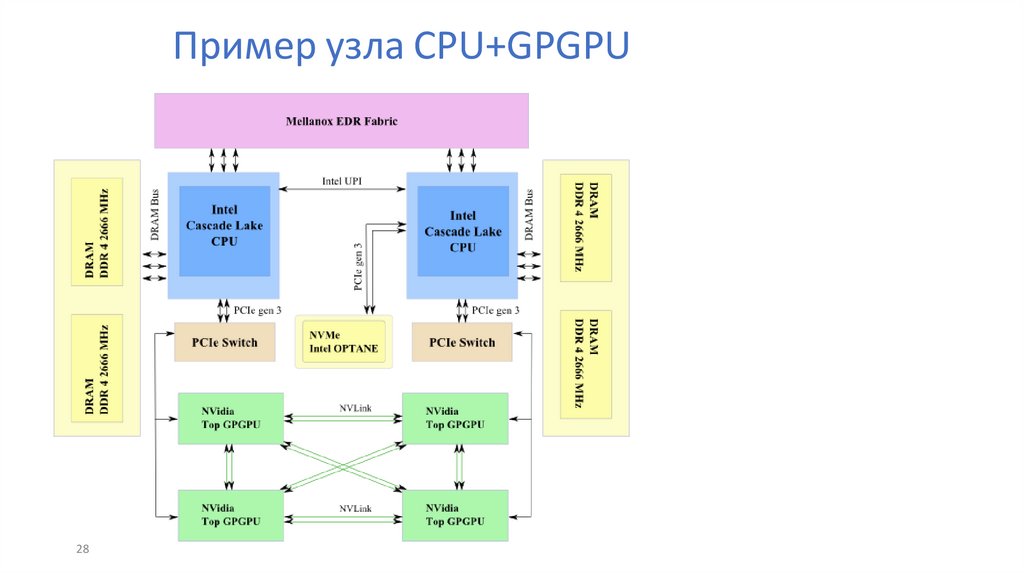
Пример узла CPU+GPGPU28
28.
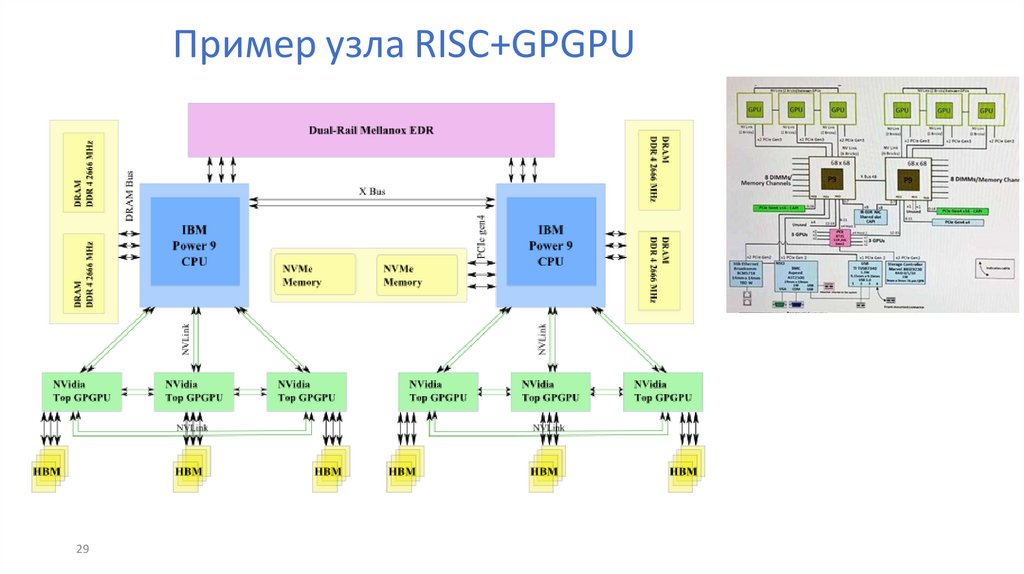
Пример узла RISC+GPGPU29
29.
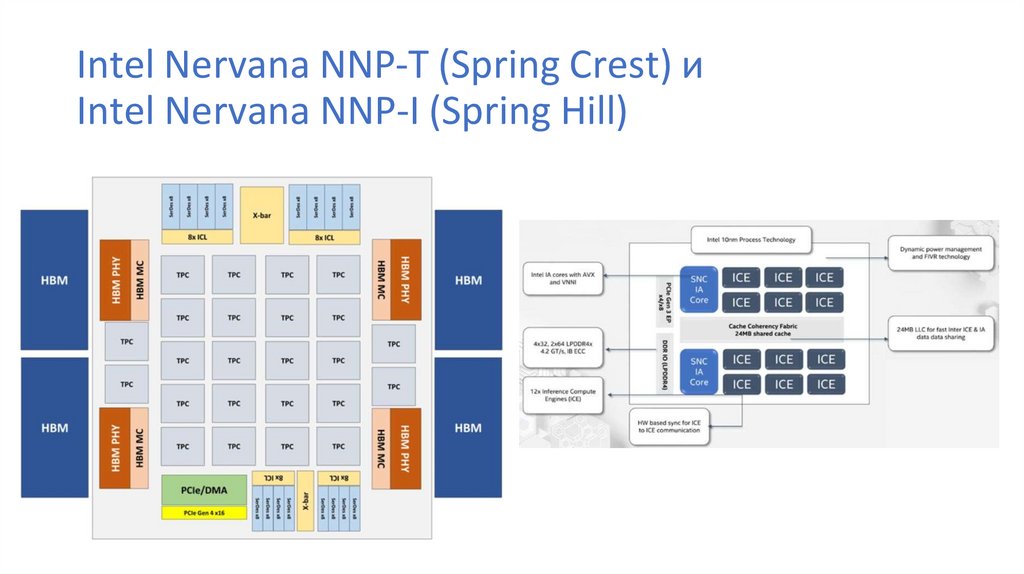
Intel Nervana NNP-T (Spring Crest) иIntel Nervana NNP-I (Spring Hill)
30.
От задачи …к выбору узлов
Классические мощные вычислительные задачи
Гомогенные узлы с
универсальными вычислителями.
При наличии ограничений по
энергопотреблению - узлы на базе
универсальных процессоров RISC
или CISC и дополнительных
ускорителей GPGPU.
31
Задачи из специфических предметных областей
Узлы на базе универсальных
процессоров RISC или CISC и
дополнительных ускорителей
FPGA, реализующих алгоритмы
для данных задач.
Обработка больших данных
Гиперконвергентные узлы.
Высокопроизводительную
систему хранения данных,
построенную с использованием
специальных технологий
организации промежуточных
буферов между системой
хранения и вычислительными
узлами.
Искусственный интеллект
(глубокое обучение)
Гиперконвергентные узлы на базе
современных универсальных
процессоров CISC с VNNI.
CISC или RISC и дополнительных
ускорителей GPGPU.
31.
Что такое современный суперкомпьютер?Современные суперкомпьютерные задачи и их отображение на
архитектуру вычислительных узлов
Обзор вычислительной составляющей узла суперкомпьютера
(процессоры, сопроцессоры, память, ...)
Обзор инфраструктурной составляющей узла суперкомпьютера
(охлаждение, питание, мониторинг, ...)
32.
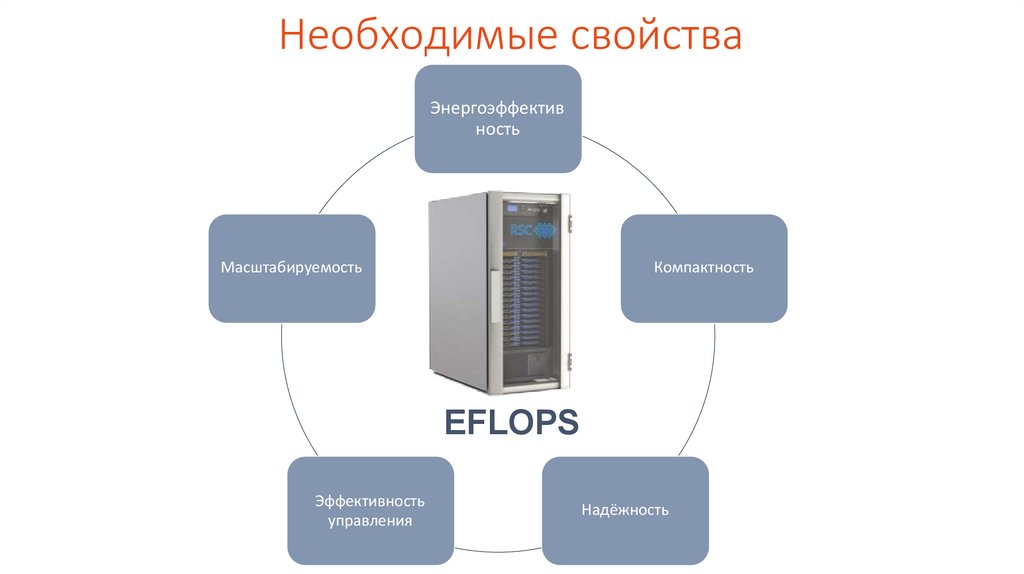
Необходимые свойстваЭнергоэффектив
ность
Масштабируемость
Компактность
EFLOPS
Эффективность
управления
Надёжность
33.
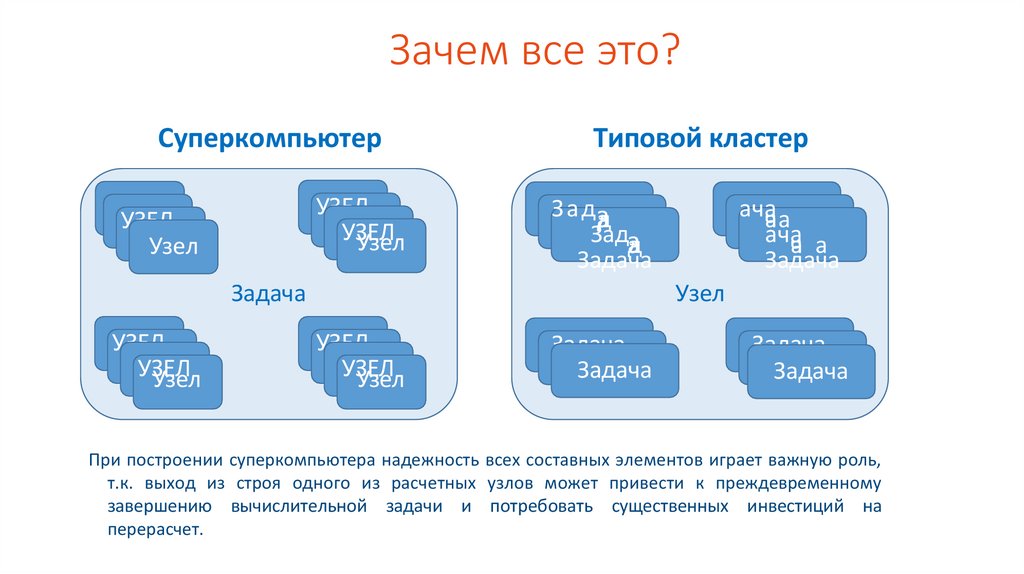
Зачем все это?Суперкомпьютер
УУ
ЗЕЗЛ
ЕЛ
УЗУЕзЛ
ел
УЗЕЛ
УУ
ЗЕЗЛ
ЕЛ
Узел
Типовой кластер
З а дд
аЗ
Задд
аЗ
Задача
Задача
УУ
ЗЕЗЛ
ЕЛ
УЗУЕзЛ
ел
ачача а
ачача а
Задача
Узел
УУ
ЗЕЗЛ
ЕЛ
УЗУЕзЛ
ел
ЗаЗд
ачаача
ад
Задача
ЗаЗд
ачаача
ад
Задача
При построении суперкомпьютера надежность всех составных элементов играет важную роль,
т.к. выход из строя одного из расчетных узлов может привести к преждевременному
завершению вычислительной задачи и потребовать существенных инвестиций на
перерасчет.
34.
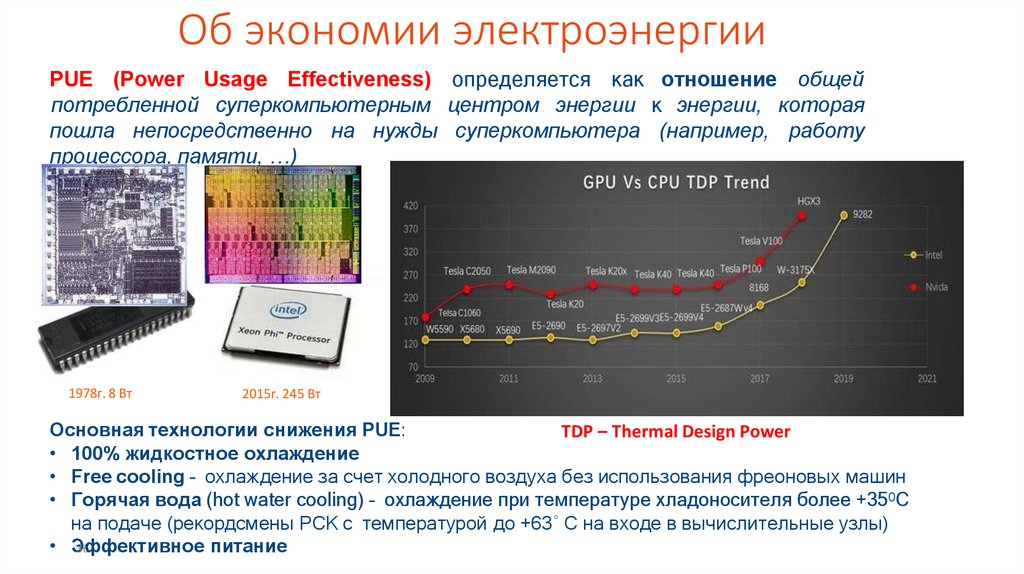
Об экономии электроэнергииPUE (Power Usage Effectiveness) определяется как отношение общей
потребленной суперкомпьютерным центром энергии к энергии, которая
пошла непосредственно на нужды суперкомпьютера (например, работу
процессора, памяти, …)
1978г. 8 Вт
2015г. 245 Вт
Основная технологии снижения PUE:
TDP – Thermal Design Power
• 100% жидкостное охлаждение
• Free cooling – охлаждение за счет холодного воздуха без использования фреоновых машин
• Горячая вода (hot water cooling) – охлаждение при температуре хладоносителя более +350C
на подаче (рекордсмены РСК с температурой до +63˚ С на входе в вычислительные узлы)
• Э36ффективное питание
35.
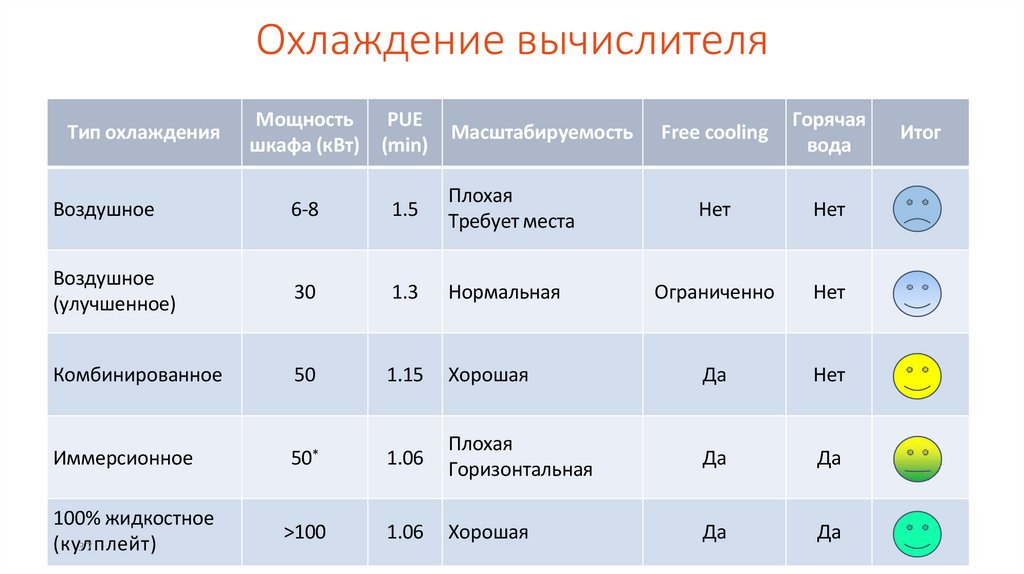
Охлаждение вычислителяТип охлаждения
Мощность
PUE
шкафа (кВт) (min)
Масштабируемость
Free cooling
Горячая
вода
Воздушное
6-8
1.5
Плохая
Требует места
Нет
Нет
Воздушное
(улучшенное)
30
1.3
Нормальная
Ограниченно
Нет
Комбинированное
50
1.15
Хорошая
Да
Нет
Иммерсионное
50*
1.06
Плохая
Горизонтальная
Да
Да
100% жидкостное
(ку3л7 плейт)
>100
1.06
Хорошая
Да
Да
Итог
36.
От задачи …к выбору узлов
Классические мощные вычислительные задачи
Гомогенные узлы с
универсальными
вычислителями.
При наличии ограничений по
энергопотреблению - узлы на
базе универсальных
процессоров RISC или CISC и
дополнительных ускорителей
GPGPU.
Задачи из специфических предметных областей
Узлы на базе универсальных
процессоров RISC или CISC и
дополнительных ускорителей
FPGA, реализующих алгоритмы
для данных задач.
Обработка больших данных
Гиперконвергентные узлы.
Высокопроизводительную
систему хранения данных,
построенную с использованием
специальных технологий
организации промежуточных
буферов между системой
хранения и вычислительными
узлами.
Искусственный интеллект
(глубокое обучение)
Гиперконвергентные узлы на
базе современных
универсальных процессоров
CISC с VNNI.
CISC или RISC и дополнительных
ускорителей GPGPU.
Охлаждение вычислителя: 100% жидкостное (кулплейт)
38
37.
Суперкомпьютер Говорун ОИЯИ• 535TFLOPS пиковой производительности - #10 в Top50
• Программно-определяема архитектура системы
• #1 в производитель-ти систем хранения в России >300GB/s
• Масштабируемое решение Storage-on-demand
• Многоуровневая система хранения для максимальной эфф-ти
• Охлаждение горячей водой (compute, storage, interconnect)
• Наиболее энергоэффективный центр в России (PUE = 1,027)
• Единый программный стек “РСК БазИС”
Гиперконвергентная составляющая
Вычислительные узлы
Узлы хранения
Intel® Xeon Phi™ nodes:
• Пиковая производительность – 72,576
ТФЛОПС
• Intel® Xeon Phi ™ 7190 CPUs (72 cores)
• Intel® Server Board S7200AP
• Intel® SSD DC S3520 (SATA, M.2)
• RAM – 96 GB DDR4 2400 ГГц
• Intel® Omni-Path 100 Гбит/с
• 48-port Intel® Omni-Path Edge Switch 100
Series 100% liquid cooling
Пиковая производительность – 463ТФЛОПС
Intel® Xeon® Platinum 8268 processors (24 cores)
Intel® Server Board S2600BP
Intel® SSD DC S4510 (SATA, M.2),
2 x Intel ® SSD DC P4511 (NVMe, M.2) 2TB
• RAM – 192 GB DDR4 2933 ГГц
• Intel® Omni-Path 100 Gbit/s
• 48-port Intel® Omni-Path Edge Switch 100 Series
со 100% жидкостным охлаждением
18 узлов с 12-ю NVMe SSD слотами
4 узла Optane с 3,4TB IMDT памяти
12 узлов OSS с NVMe SSD – 256TB
2 узла MDS c 12-ю Optane 375GB
ПФС Lustre как основная опция
Storage-on-Demand c RSC BasIS
на узлах кластера
38.
Спасибо!www.rscgroup.ru
igor_odintsov@rsc-tech.ru