






























































































 Программирование
ПрограммированиеПохожие презентации:









")
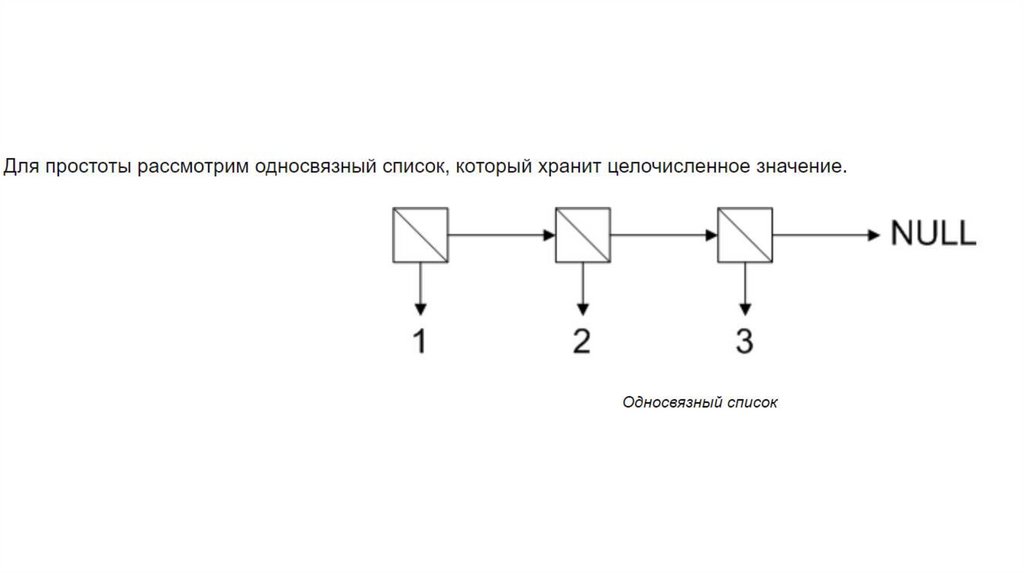
Односвязный список
1.
Односвязный список2.
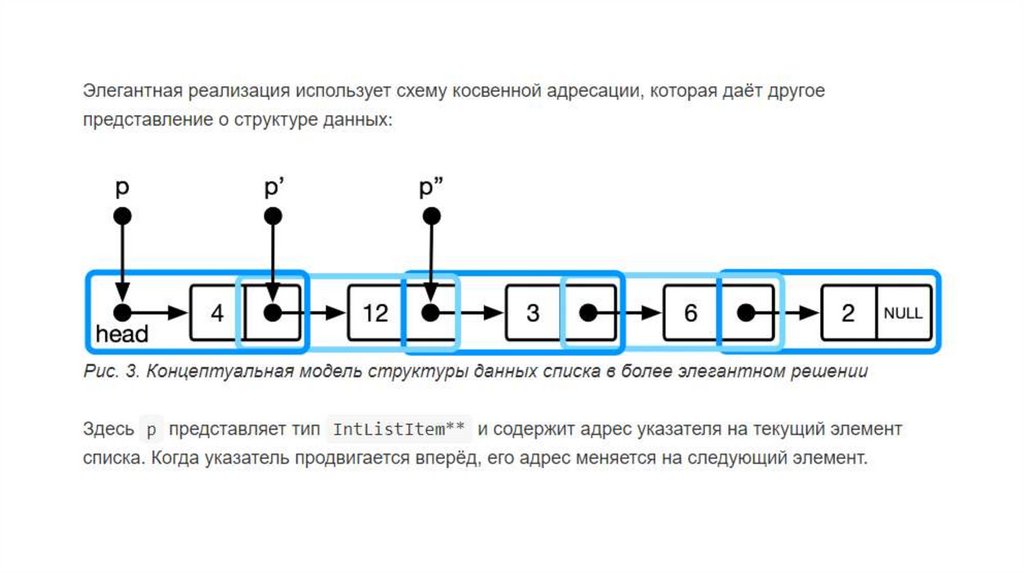
Односвязный список – структура данных, в которойкаждый элемент (узел) хранит информацию, а также
ссылку на следующий элемент. Последний элемент
списка ссылается на NULL.
3.
Для нас односвязный список полезен тем, что1) Он очень просто устроен и все алгоритмы интуитивно понятны
2) Односвязный список – хорошее упражнение для работы с
указателями
3) Его очень просто визуализировать, это позволяет "в картинках"
объяснить алгоритм
4) Несмотря на свою простоту, односвязные списки часто
используются в программировании, так что это не пустое
упражнение.
5) Эта структуру данных можно определить рекурсивно, и она часто
используется в рекурсивных алгоритмах.
4.
5.
Односвязный список состоит из узлов. Каждый узелсодержит значение и указатель на следующий узел,
поэтому представим его в качестве структуры:
6.
Теперь наша задача написать функцию, которая бы собираласписок из значений, которые мы ей передаём. Стандартное
имя функции – push, она должна получать в качестве
аргумента значение, которое вставит в список. Новое
значение будет вставляться в начало списка. Каждый новый
элемент списка мы должны создавать на куче.
Следовательно, нам будет удобно иметь один указатель на
первый элемент списка.
7.
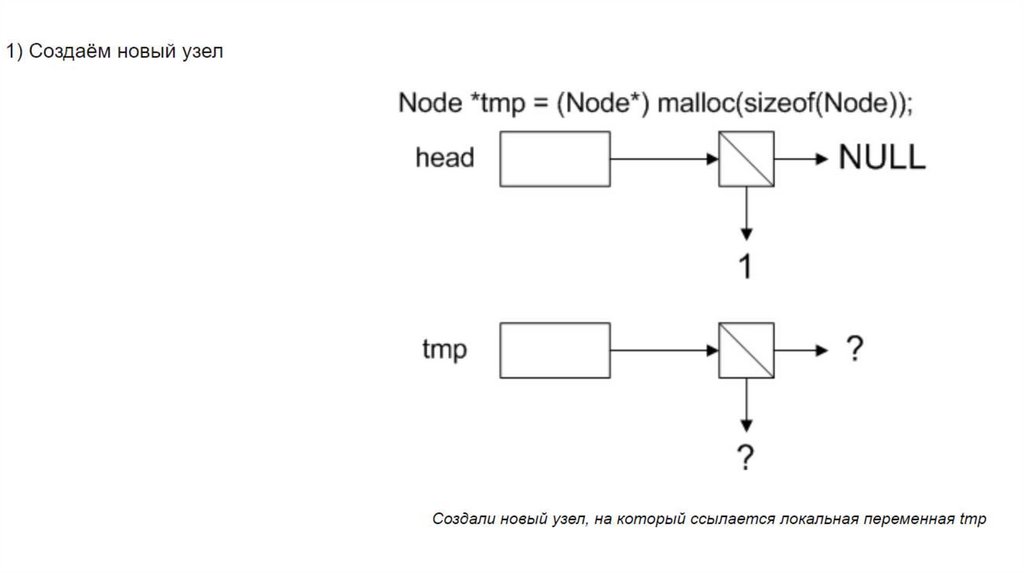
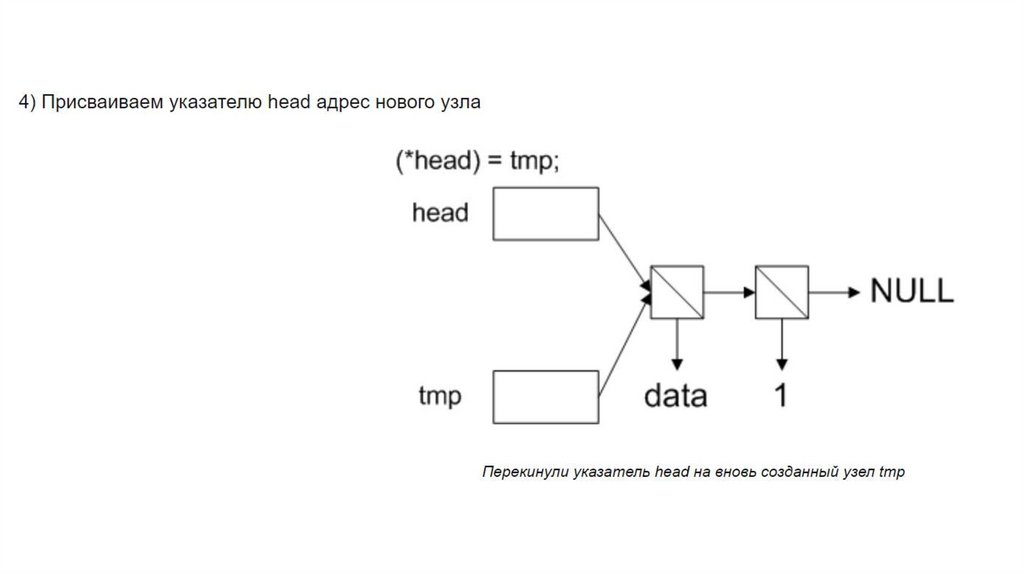
Для добавления нового узла необходимо:1) Выделить под него память.
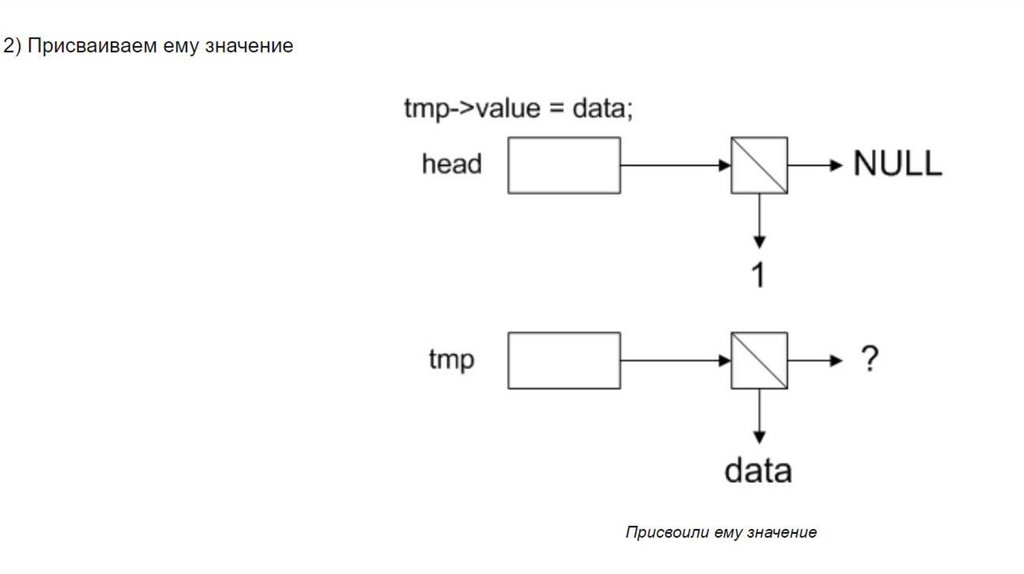
2) Задать ему значение
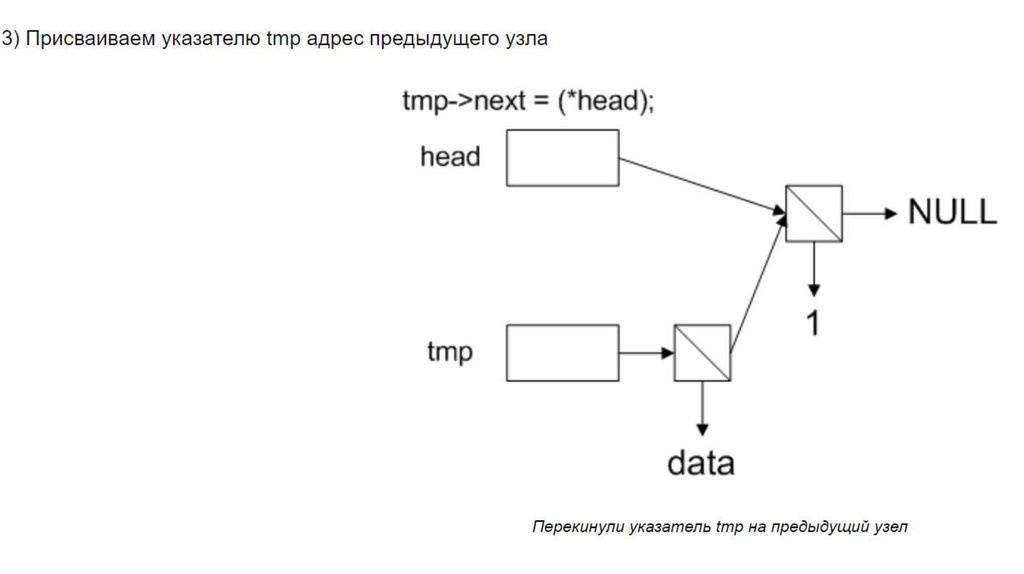
3) Сделать так, чтобы он ссылался на предыдущий
элемент (или на NULL, если его не было)
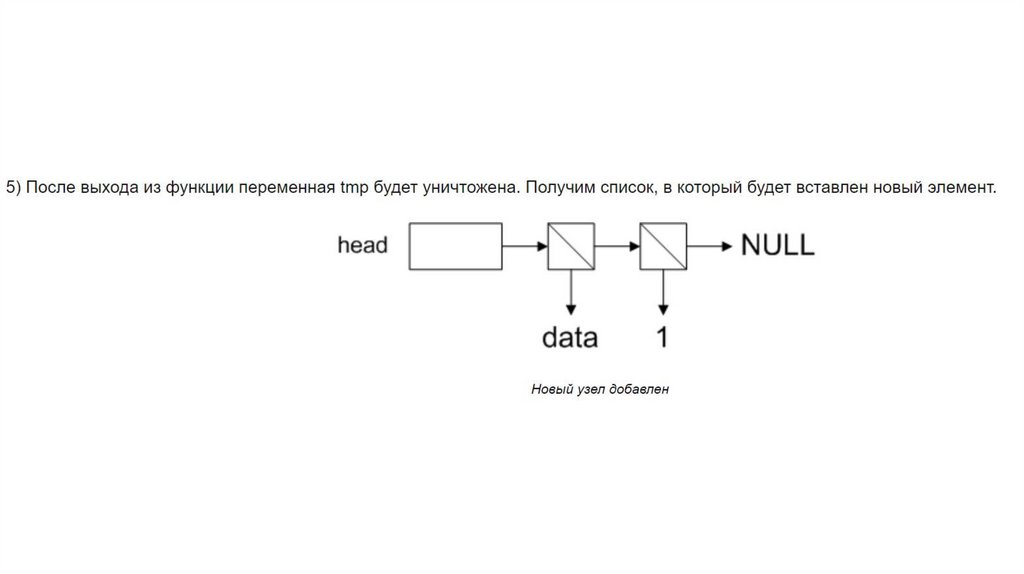
4) Перекинуть указатель head на новый узел.
8.
9.
10.
11.
12.
13.
14.
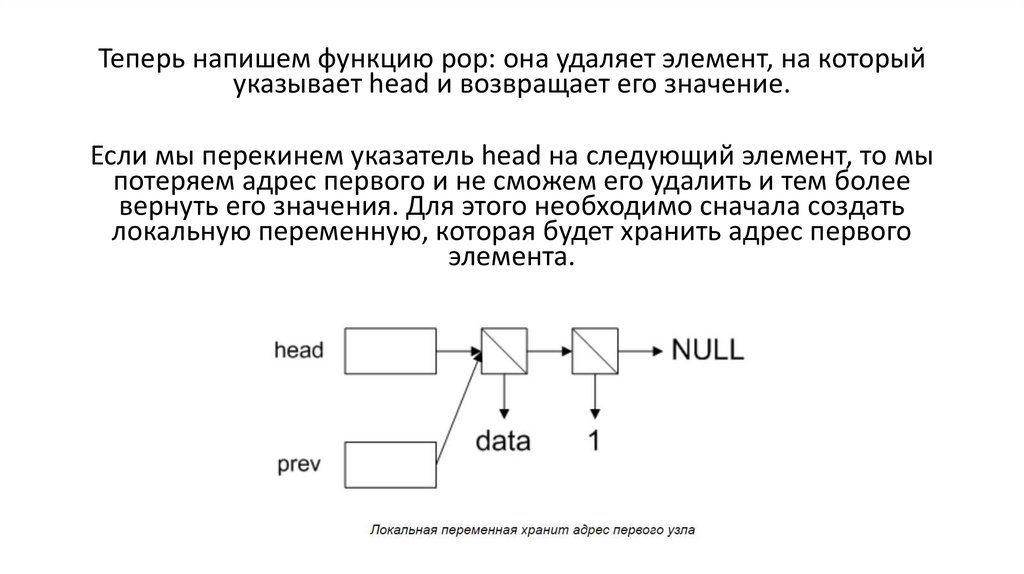
Теперь напишем функцию pop: она удаляет элемент, на которыйуказывает head и возвращает его значение.
Если мы перекинем указатель head на следующий элемент, то мы
потеряем адрес первого и не сможем его удалить и тем более
вернуть его значения. Для этого необходимо сначала создать
локальную переменную, которая будет хранить адрес первого
элемента.
15.
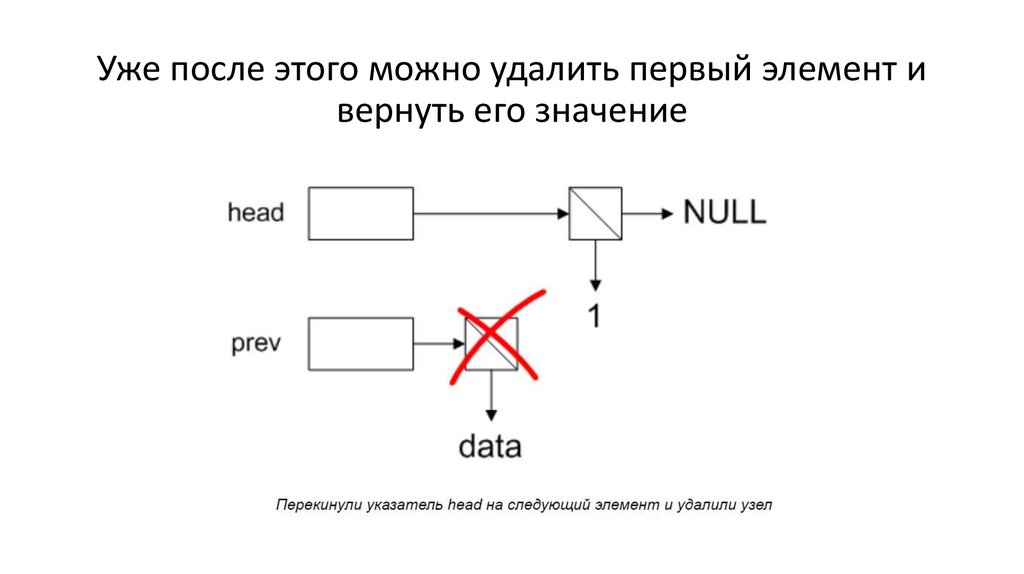
Уже после этого можно удалить первый элемент ивернуть его значение
16.
17.
Таким образом, мы реализовали две операции push и pop,которые позволяют теперь использовать односвязный
список как стек. Теперь добавим ещё две операции pushBack (её ещё принято называть shift или enqueue),
которая добавляет новый элемент в конец списка, и
функцию popBack (unshift, или dequeue), которая удаляет
последний элемент списка и возвращает его значение.
Для дальнейшего разговора необходимо реализовать
функции getLast, которая возвращает указатель на
последний элемент списка, и nth, которая возвращает
указатель на n-й элемент списка.
18.
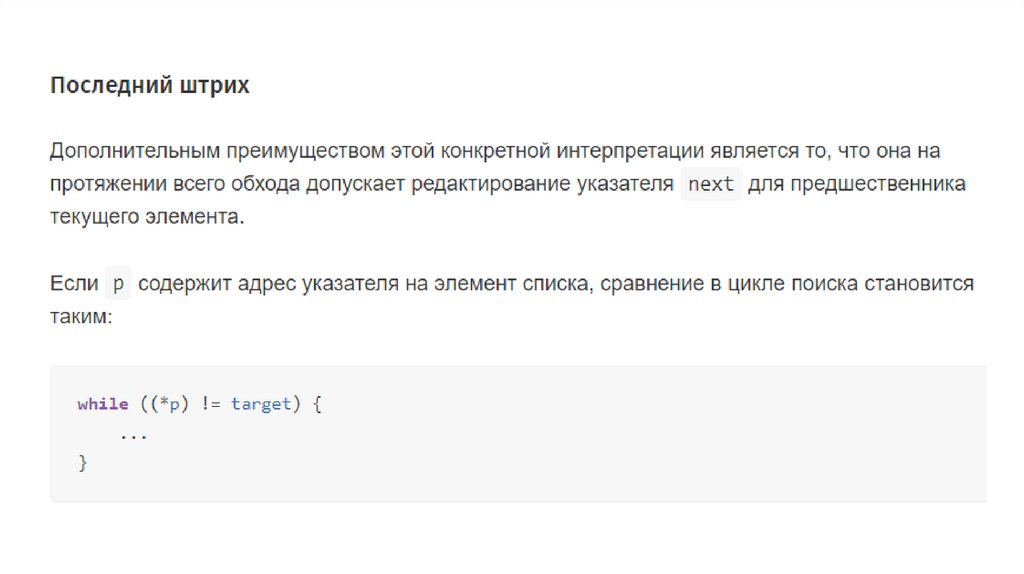
Так как мы знаем адрес только первого элемента, тоединственным способом добраться до n-го будет
последовательный перебор всех элементов списка. Для
того, чтобы получить следующий элемент, нужно
перейти к нему через указатель next текущего узла.
19.
Переходя на следующий элемент не забываем проверять,существует ли он. Вполне возможно, что был указан номер,
который больше размера списка. Функция вернёт в таком случае
NULL. Сложность операции O(n), и это одна из проблем
односвязного списка.
Для нахождение последнего элемента будем передирать друг за
другом элементы до тех пор, пока указатель next одного из
элементов не станет равным NULL.
20.
Теперь добавим ещё две операции - pushBack (её ещё принятоназывать shift или enqueue), которая добавляет новый элемент в
конец списка, и функцию popBack (unshift, или dequeue), которая
удаляет последний элемент списка и возвращает его значение.
Для вставки нового элемента в конец сначала получаем указатель
на последний элемент, затем создаём новый элемент,
присваиваем ему значение и перекидываем указатель next старого
элемента на новый.
21.
Односвязный список хранит адрес только следующегоэлемента. Если мы хотим удалить последний элемент, то
необходимо изменить указатель next предпоследнего
элемента. Для этого нам понадобится функция
getLastButOne, возвращающая указатель на
предпоследний элемент.
22.
Функция должна работать и тогда, когда список состоитвсего из одного элемента. Вот теперь есть возможность
удалить последний элемент.
23.
Можно написать алгоритм проще. Будем использовать двауказателя. Один – текущий узел, второй – предыдущий.
Тогда можно обойтись без вызова функции getLastButOne:
24.
Теперь напишем функцию insert, которая вставляет на n-е местоновое значение. Для вставки, сначала нужно будет пройти до
нужного узла, потом создать новый элемент и поменять
указатели. Если мы вставляем в конец, то указатель next нового
узла будет указывать на NULL, иначе на следующий элемент.
25.
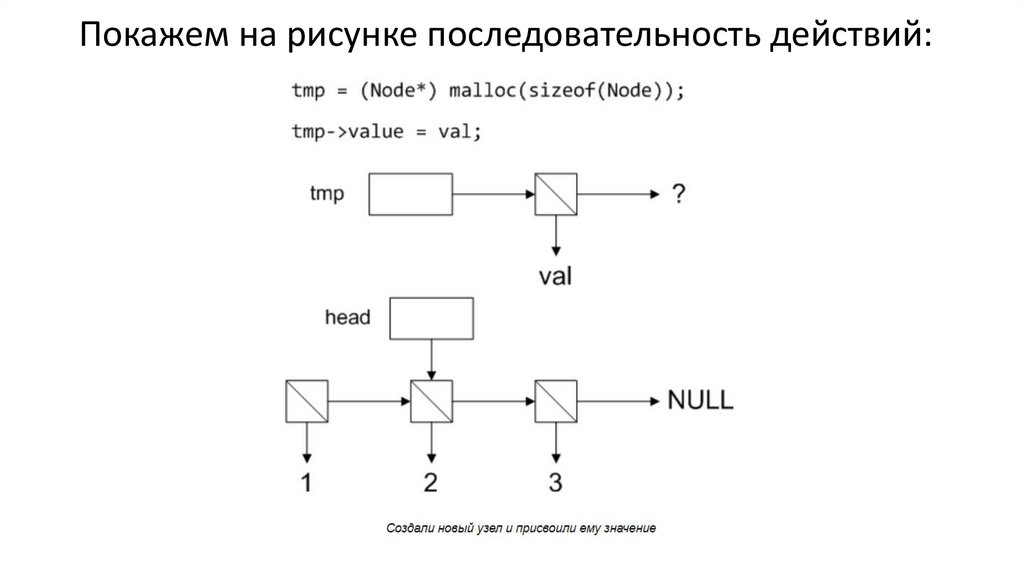
Покажем на рисунке последовательность действий:26.
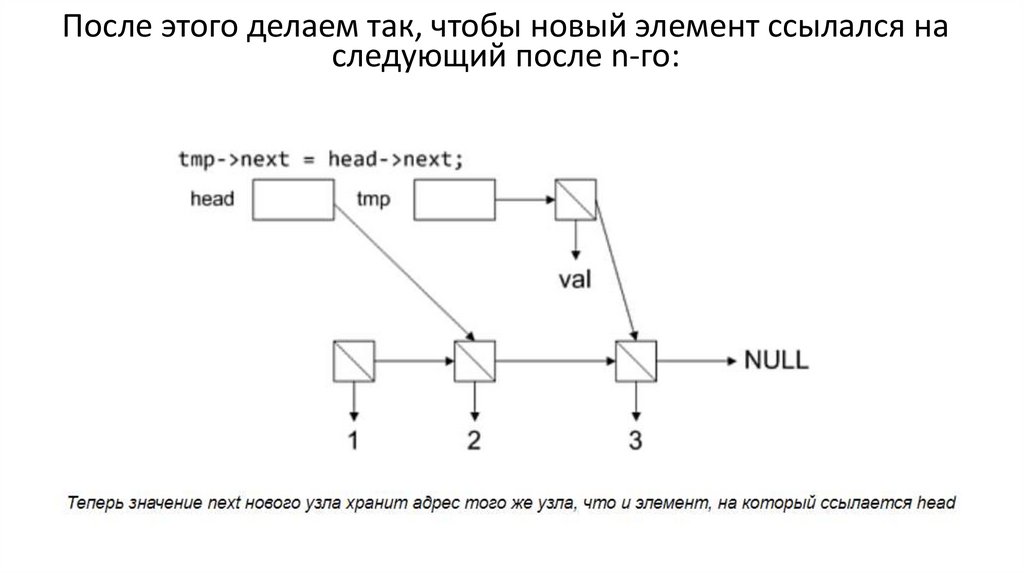
После этого делаем так, чтобы новый элемент ссылался наследующий после n-го:
27.
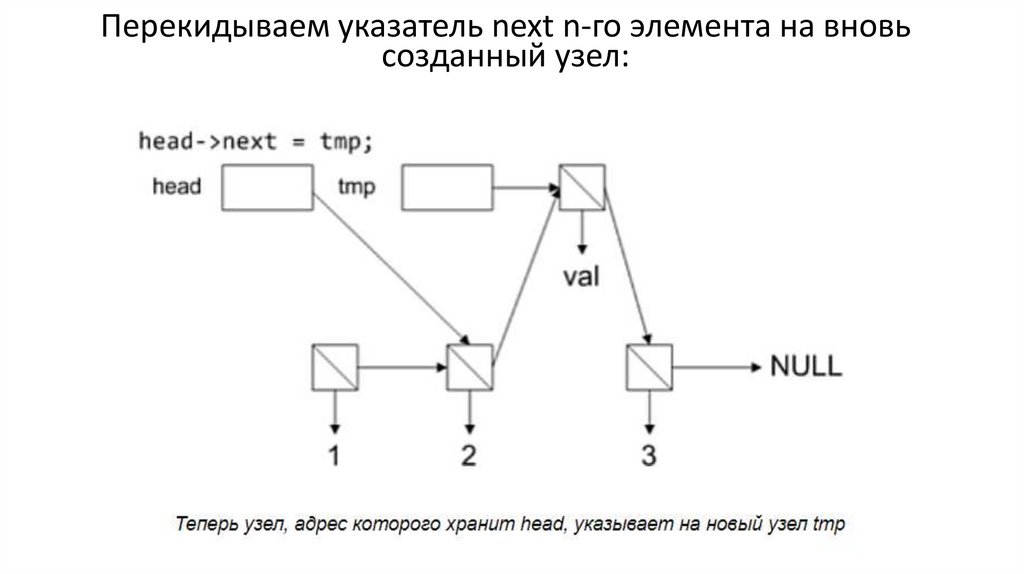
Перекидываем указатель next n-го элемента на вновьсозданный узел:
28.
Функция удаления элемента списка похожа на вставку. Сначалаполучаем указатель на элемент, стоящий до удаляемого, потом
перекидываем ссылку на следующий элемент за удаляемым,
потом удаляем элемент.
29.
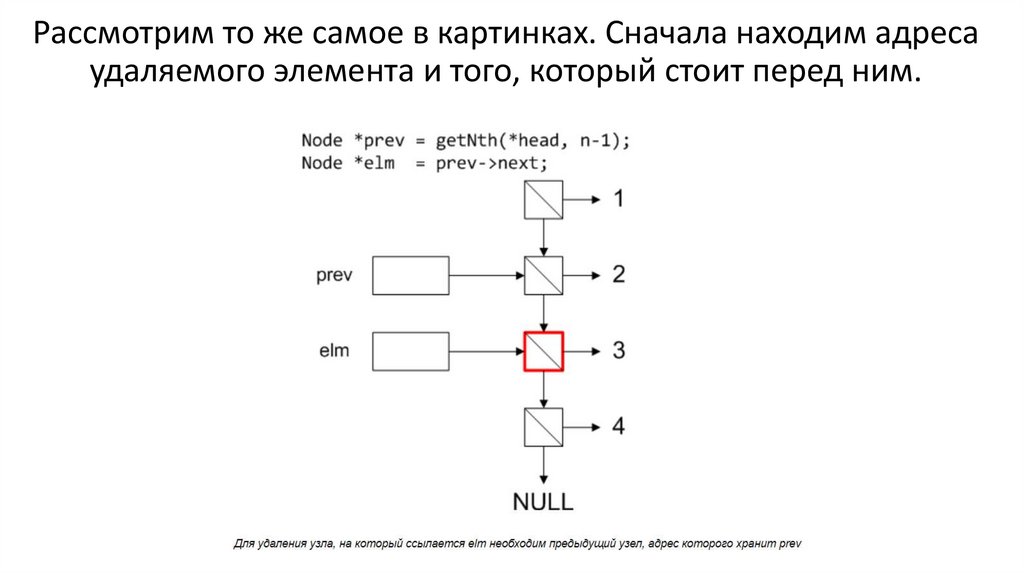
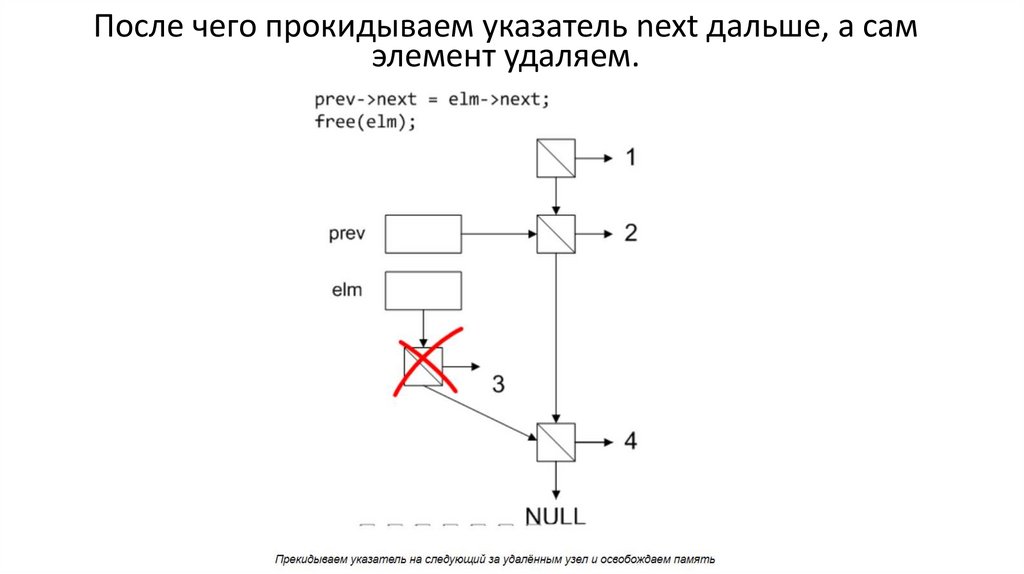
Рассмотрим то же самое в картинках. Сначала находим адресаудаляемого элемента и того, который стоит перед ним.
30.
После чего прокидываем указатель next дальше, а самэлемент удаляем.
31.
Кроме создания списка необходимо его удаление. Так каксамая быстрая функция у нас этот pop, то для удаления будем
последовательно выталкивать элементы из списка.
32.
Вызов pop можно заменить на тело функции и убратьненужные проверки и возврат значения.
33.
Осталось написать несколько вспомогательных функций,которые упростят и ускорят работу. Первая - создать список из
массива. Так как операция push имеет минимальную
сложность, то вставлять будем именно с её помощью. Так как
вставка произойдёт задом наперёд, то массив будем обходить
с конца к началу:
34.
И обратная функция, которая возвратит массивэлементов, хранящихся в списке. Так как мы будем
создавать массив динамически, то сначала определим
его размер, а только потом запихнём туда значения.
35.
И ещё одна функция, которая будет печататьсодержимое списка
36.
Теперь можнопровести проверку
и посмотреть, как
работает
односвязный
список.
37.
Улучшенный односвязныйсписок
38.
При реализации односвязного списка мы использовалидля работы указатель на первый узел односвязного
списка. При таком подходе некоторые операции имели
очень большую сложность. Например, для того, чтобы
узнать размер списка или получить последний элемент
списка, приходилось перебирать все элементы списка.
39.
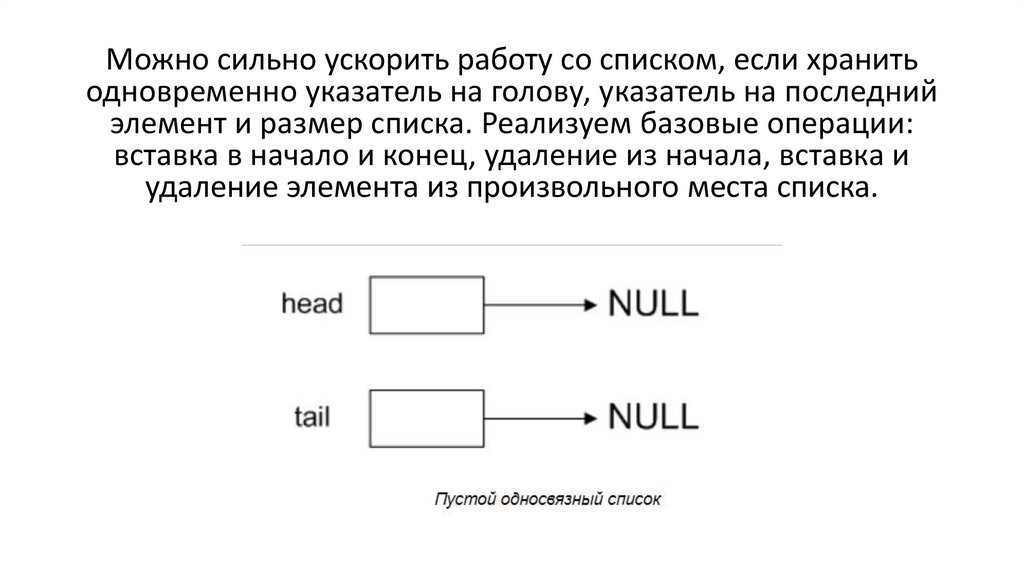
Можно сильно ускорить работу со списком, если хранитьодновременно указатель на голову, указатель на последний
элемент и размер списка. Реализуем базовые операции:
вставка в начало и конец, удаление из начала, вставка и
удаление элемента из произвольного места списка.
40.
Кроме того, будем хранить в узле не тип int, ауказатель на переменную произвольного типа.
41.
Далее, заведём набор ошибок, чтобы потом былопроще отлаживать программу.
42.
В первую очередь необходимо реализовать функцию,которая возвращает экземпляр нового односвязного
списка.
43.
Функция удаления списка:44.
Теперь самое интересное. Функция pushFront не сильноотличается от той, которую мы рассматривали ранее.
Единственная разница в том, что нужно проверять - если
указатель tail равнялся NULL, то это первый элемент и
ему надо присвоить указатель на вновь созданный узел.
45.
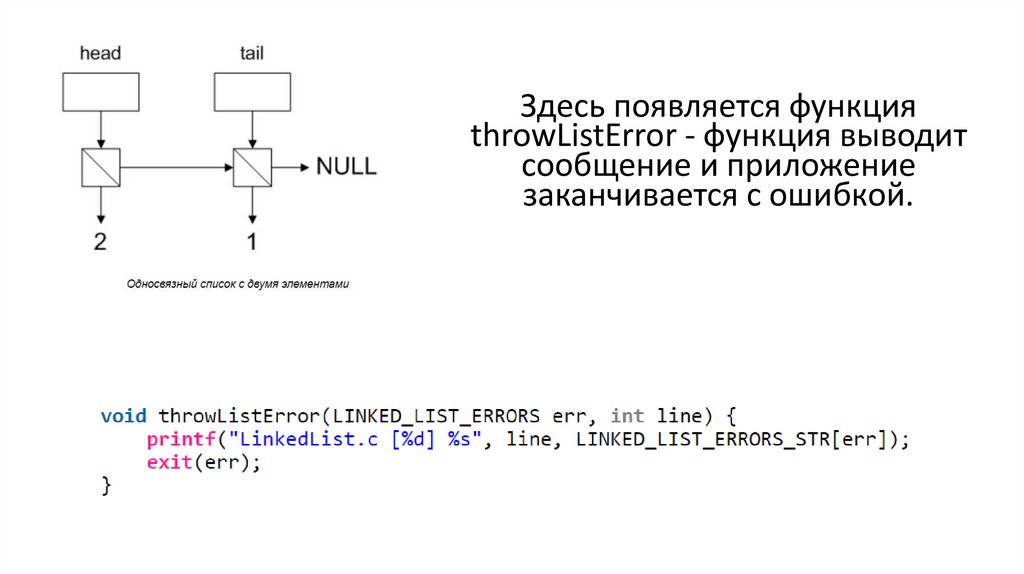
Здесь появляется функцияthrowListError - функция выводит
сообщение и приложение
заканчивается с ошибкой.
46.
И ещё одна вспомогательная функция – печать списка.Так как мы не знаем тип переменной, указатель на
которую мы храним, то необходимо передавать
функцию, позволяющую вывести значение.
47.
Теперь приступим к проверке. Вот здесь всё становится несколькосложнее.
48.
Так как узел хранит адрес переменной, то необходимо,чтобы, во-первых, передаваемая переменная имела адрес, а
во-вторых, эта переменная должна жить всё время, что мы
работаем со списком.
49.
Если требуется много работать с объектами, добавлять иудалять значения, то иногда будет сложно хранить их и
определять, какие из них удалены, а какие ещё живут. Одно
из решений – хранить в структуре списка указатель на
функции, которые бы работали с нужным типом данных. Так
как природа объектов может быть любой, то необходимо
уметь копировать объект, чтобы вставлять копию на него,
вместо указателя на оригинал, а также нужна функция
удаления объекта из узла.
50.
Не забываем, что мы не реализуем функцию сортировки, ведь втаком случае нам понадобилась бы ещё и функция сравнения.
Тогда создание объекта типа односвязный список будет выглядеть
как-то так:
51.
52.
53.
А вот выталкивание из начала не поменялось:удалением данных должен озаботится тот, кто их принял.
К сожалению,
выталкивание элемента с
конца не получится
реализовать так же
просто. Его сложность
останется n и потребует
прохода всех элементов,
пока мы не доберёмся до
предпоследнего.
54.
Поиск n-го элемента ничем не отличается от оного дляпрошлой реализации, его сложность n. Вставка и удаление
также остались со сложностью порядка n.
55.
Таким образом, для односвязного списка, имея толькоуказатель на первый элемент мы получили сложность
56.
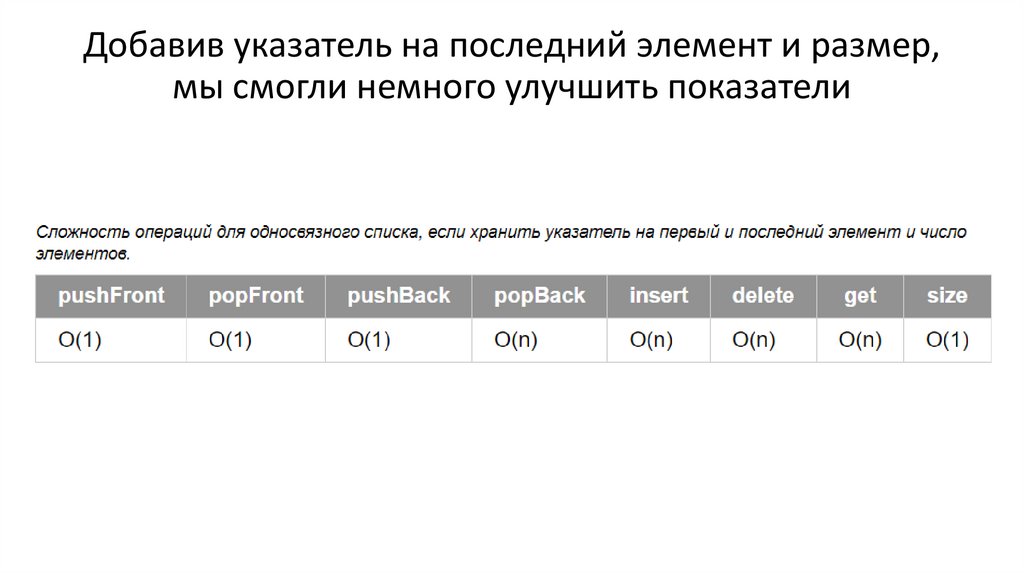
Добавив указатель на последний элемент и размер,мы смогли немного улучшить показатели
57.
Сортировка односвязногосписка
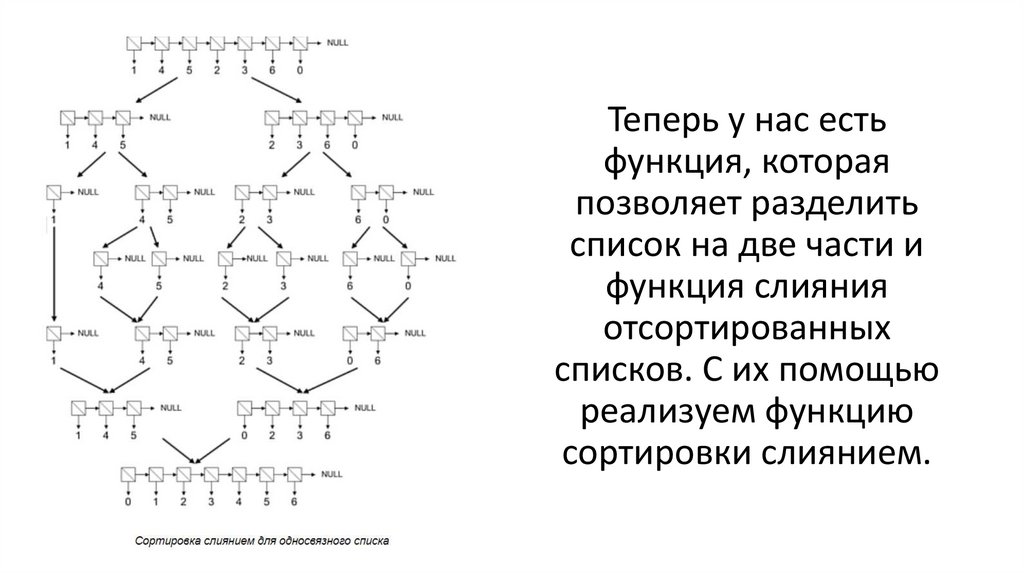
58.
Сортировать список будем слиянием. Этот метод оченьпохож на сортировку слиянием для массива. Для его
реализации нам понадобятся две функции: одна буде
делить список пополам, а другая будет объединять два
упорядоченных односвязных списка, не создавая при
этом новых узлов. Наша реализация не будет
оптимальной, однако, некоторые решения, которые мы
применим, могут быть использованы и в других
алгоритмах.
59.
Вспомогательная функция – слияние двухотсортированных списков. Функция не должна создавать
новых узлов, так что будем использовать только
имеющиеся. Для начала проверим, если хоть один из
списков пуст, то вернём другой.
60.
После этого нужно, чтобы наша локальнаяпеременная стала хранить адрес большего из узлов
двух списков, от него и будем танцевать дальше
61.
Теперь сохраним указатель c, так как в дальнейшемон будет использоваться для прохода по списку:
62.
В конце, может остаться один список, которыйпройден не до конца. Добавим его узлы.
63.
Теперь указатель c хранит адрес последнего узла, анам нужна ссылка на голову. Она как раз хранится
во второй переменной tmp.
64.
Весь алгоритм:65.
Ещё одна важная функция – нахождение серединысписка. Для этих целей будем использовать два
указателя. Один из них - fast – за одну итерацию будет
два раза изменять значение и продвигаться по списку
вперёд. Второй – slow, всего один раз. Таким образом,
если список чётный, то slow окажется ровно посредине
списка, а если список нечётный, то второй подсписок
будет на один элемент длиннее.
66.
Очевидно, что можнобыло один раз узнать
длину списка, а потом
передавать размер в
каждую функцию. Это
было бы проще и
быстрее. Но мы не
ищем лёгких путей.
67.
Теперь у нас естьфункция, которая
позволяет разделить
список на две части и
функция слияния
отсортированных
списков. С их помощью
реализуем функцию
сортировки слиянием.
68.
Функция рекурсивно вызывает сама себя, передавая частисписка. Если в функцию пришёл список длинной менее двух
элементов, то рекурсия прекращается. Идёт обратная сборка
списка. Сначала из двух списков, каждый из которых хранит
один элемент, создаётся отсортированный список, далее из
таких списков собирается новый отсортированный список,
пока все элементы не будут включены.
69.
Односвязные списки ирекурсия
70.
Для односвязного списка можно дать просторекурсивное определение. Односвязный список
либо пуст, либо состоит из головы и списка.
В данном случае, [] обозначает пустой список. Под
пустым списком будем понимать NULL, то есть
указатель типа Node, ссылающийся на NULL это тоже
список. Под головой будем понимать первый узел
списка.
71.
Из этого определения списка следует примерныйалгоритм обработки односвязного списка:
Конечно, всё зависит от ситуации, и условие выхода
из рекурсии может быть совсем другое. Посмотрим
теперь несколько простых рекурсивных алгоритмов.
72.
Я далее буду использовать немного странный псевдокод. Внём функция заканчивается точкой, а аргумент проверяется
на соответствие шаблону, то есть
означает, что если аргумент функции равен 0, то произойдёт
возврат значения 0, а если аргумент - какое-то число n, то
произойдёт возврат произведения функции f с аргументом
n-1 и n. Стрелка означает, что происходит возврат значения.
Выражение f([]) значит, что функция получила в качестве
аргумента пустой список, а f([H|L]) - что функция получила
непустой список, в котором к первому узлу мы будем
обращаться как к H, а к остальным элементам как к списку с
именем L (даже если он пуст).
73.
74.
75.
76.
77.
78.
79.
80.
81.
82.
83.
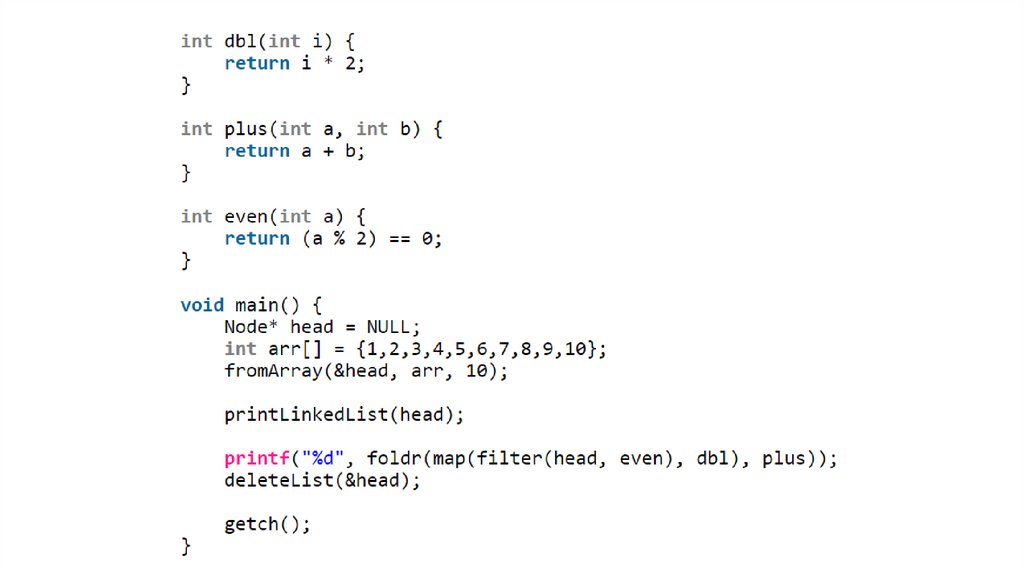
4. map - отображение. Для начала нам понадобитсяфункция повторения списка. Это достаточно простая
функция.
84.
Функция map применяет к каждому элементу спискафункцию и возвращает новый список. Например, если у
нас был список
85.
На основе функции repeat:86.
5. Рекурсивный оборот списка. Функция достаточнопростая. Нам понадобится новый указатель – новая
"голова" списка. Мы должны сначала пройти до конца
списка, и только с конца до начала проталкивать новые
элементы. Таким образом, push должны быть
завершающей командой.
87.
6. Правоассоциативная свёртка. Пусть у нас имеется списокзначений вида
[x1, x2, ..., xN]
и мы хотим получить из списка единственное атомарное
значение, применяя заданную функцию к списку
следующим образом
f(X1, f(x2, f(..., f(XN-1, XN)))),
например, мы хотим применить к списку
[1,2,3,4,5]
операцию суммирования
1+(2+(3+(4+5)))
88.
89.
90.
7. Левоассоциативная свёртка. Работает в обратномпорядке, то есть для
[x1, x2, ..., xN]
и мы хотим получить из списка единственное
атомарное значение, применяя заданную функцию
к списку следующим образом
f(f(f(...f(X1, X2))), xN)
91.
Очевидно, что если операция g коммутирует, то левая свёртка равнаправой свёртке, но в общем случае они могут давать разный результат.
92.
8. Фильтр. Из названия понятно, что функция получаетсписок и выбрасывает из него все элементы, которые не
удовлетворяют условию. По сути - это повторение списка,
только с пропуском "плохих" узлов.
93.
Последовательноевыполнение и утечка памяти
94.
Функции map, reduce (foldl и в большей степени foldr) иfilter нашли очень широкое применение в
программировании. Особенно привлекательным
выглядит объединение этих функций и передача
параметров от одной функции к другой. Такое
связывание ряда функций в цепочку, когда следующая
получает результаты предыдущей, обычно называют
chaining; в нашем случае, к сожалению, простое
последовательное применение не возможно, так как
будет происходить утечка памяти.
95.
96.
При вызове функции filter будет создан новый список L1, которыйбудет передан в функцию map. Функция map в свою очередь
создаст новый список L2, а переданный ей L1 не уничтожит. L2
также не будет уничтожен и продолжит храниться в памяти. Самым
простым решением будет явное сохранение значений в
переменных, а затем явное освобождение памяти.