








 Информатика
ИнформатикаПохожие презентации:










Pipline (Конвейер)
1.
Pipline2.
• Pipline(Конвейер) - позволяет объединить несколько шагов врабочем
процессе
машинного
обучения,
которые
последовательно преобразуют ваши данные перед их передачей
на обучение. Следовательно, pipline может состоять из этапов
предварительной обработки, проектирования признаков и
выбора признаков перед передачей данных на обучение в
выбранную модель.
3.
• В целом использование pipline упрощает вашу жизнь и ускоряет разработку моделеймашинного обучения. Это потому, что pipline позволяет
• приводит к более чистому и понятному коду
• легко воспроизводить и понимать рабочие процессы с данными
• легче читать и корректировать
• ускоряет подготовку данных, поскольку pipline автоматизирует подготовку данных
• помогает избежать утечки данных
• позволяет одновременно выполнять оптимизацию гиперпараметров для всех моделей
используемых в pipline.
• удобно, поскольку вам нужно всего лишь один раз вызвать fit() и Predict(), чтобы запустить
весь pipline.
• После того как вы обучили и оптимизировали свою модель и остались довольны
результатами, вы можете легко сохранить обученный pipline. Затем, когда вы захотите
запустить свою модель, просто загрузите предварительно обученный pipline. Благодаря
этому вы также можете легко поделиться своей моделью которую будет легко
воспроизвести и понять.
4.
• В scikit-learn есть специальный класс Pipeline, с помощьюкоторого можно создавать конструктор определяющий
последовательность из шагов, трансформирующих данные в
нужном порядке.
• Выглядит это примерно так:
В данном случае в конвейер включен шаг трансформации данных, а
именно базовый scikit-learn-овский метод стандартизации данных.
5.
• Pipeline и ColumnTransformer• ColumnTransformer
• Ранее мы рассмотрели применение пайплайна для последовательного
преобразования данных.
• Что делать, если у нас есть как количественные, так и категориальные
признаки, и им соответственно нужны разные преобразования (более
того, разным количественным и категориальным признакам также
могут понадобиться разные преобразования)?
• Здесь выручает ColumnTransformer. Он позволяет «прописать»
отдельным признакам (т.е. столбцам, columns) свои преобразования, а
затем объединить результат и передать в модель. Рассмотрим пример.
6.
7.
• Собираем готовый пайплайн, компонуя его части с помощьюColumn Transformer. Он состоит из предобработки и
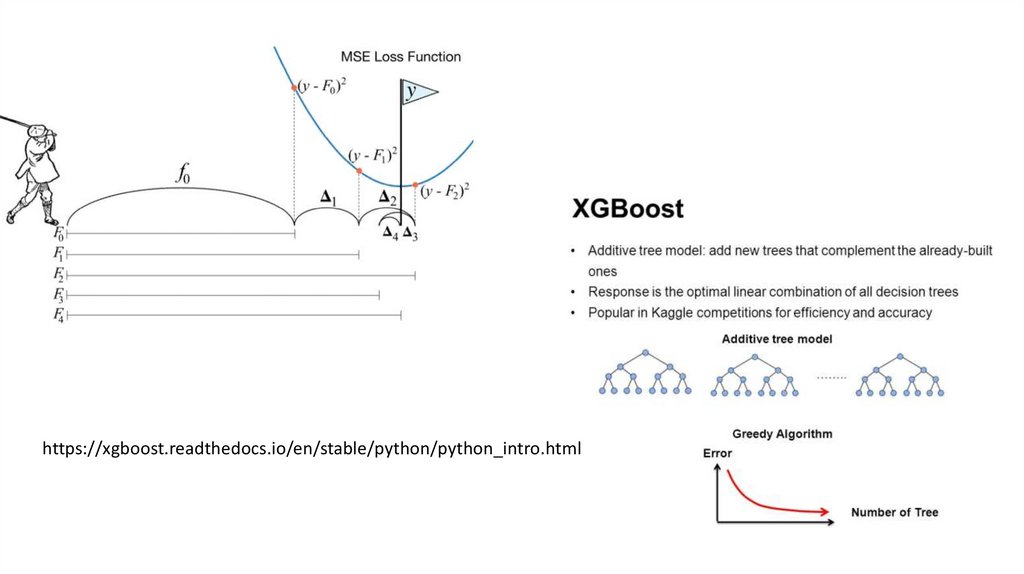
модели XGBclassifier - это одна из функций, используемых в
пакете xgboost для создания модели. Внутри XBGRegressor можно
установить гиперпараметры для модели.
8.
https://xgboost.readthedocs.io/en/stable/python/python_intro.html9.
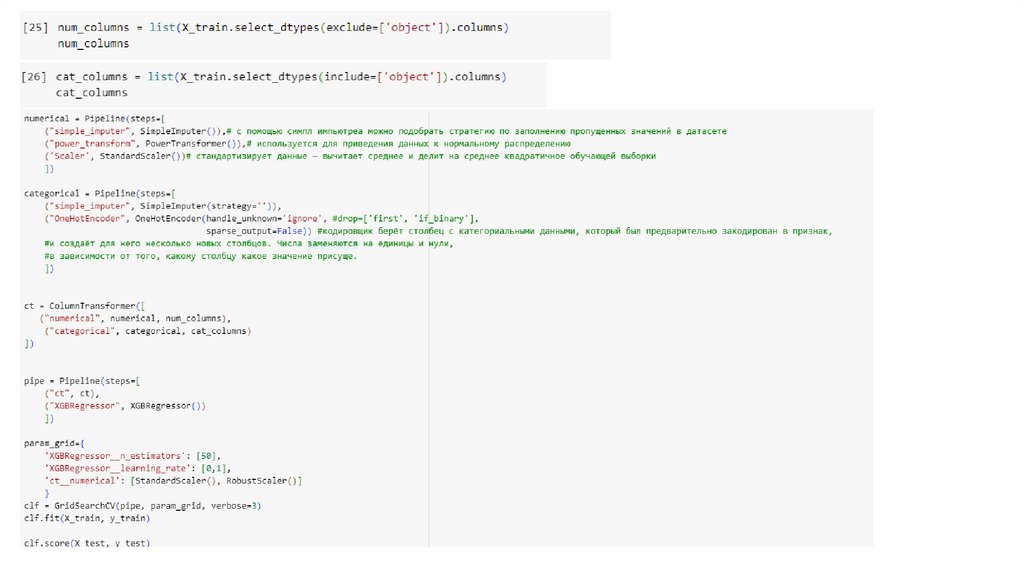
• После того, как Вы собрали готовый пайплайн, Вам необходимоотправить ваши данные на обучение. Однако, как нам известно,
модели содержат разные гиперпараметры. И в пайплайне есть
инструмент позволяющий оптимизировать подбор нужных
гиперпараметров. GridSearch - это очень мощный инструмент для
автоматического подбирания параметров для моделей
машинного обучения. GridSearchCV находит наилучшие
параметры, путем обычного перебора: он создает модель для
каждой возможной комбинации параметров. Важно отметить,
что такой подход может быть весьма времязатратным.
https://scikitlearn.org/stable/modules/generated/sklearn.model_selection.
GridSearchCV.html
10.
11.
ЗаданиеВыполняйте работу в гугл коллабе или локально на используемом IDE.
Скачайте датасет, выберите столбец Price в качестве целевого, удалите его из X, затем сделайте сплит.
Создайте переменные для категориальных и количественных типов данных и запишите в них данные.
Далее создайте пайплайн в соответствии с предыдущим слайдом
Для SimpleImputer подберите такую стратегию, чтобы код заработал. Не забывайте импортировать
недостающие библиотеки.
В param_grid подберите оптимальные значения следующих гиперпараметров:
n_estimators
learning_rate
max_depth
gamma
И один любой на выбор согласно технической документации
model=clf.best_estimator_
clf.best_params_ - используйте эти две переменные для оценки лучших параметров