




 Базы данных
Базы данныхПохожие презентации:






")



Поєднання векторних баз даних та RAG для LLM- додатків
1.
КВАЛІФІКАЦІЙНА РОБОТАСТЕПАНА БЛОНАРОВИЧА
НА ЗДОБУТТЯ ОСВІТНЬО-ПРОФЕСІЙНОГО СТУПЕНЯ ФАХОВИЙ МОЛОДШИЙ БАКАЛАВР
СПЕЦІАЛЬНОСТІ 123 КОМП’ЮТЕРНА ІНЖЕНЕРІЯ
ЗА ТЕМОЮ ПОЄДНАННЯ ВЕКТОРНИХ БАЗ ДАНИХ ТА RAG ДЛЯ LLM-
ДОДАТКІВ
2.
Метою даного дослідження є розробка та оцінкасистеми, яка поєднує векторні бази даних та RAG для
покращення роботи додатків на основі великих
мовних моделей.
Великі мовні моделі (Large Language
Model, LLM) - це тип системи штучного
інтелекту, який навчається на величезних
обсягах текстових даних для генерації тексту,
подібного до людського. LLM відноситься до
процесів, що включаються в побудову,
навчання та розгортання цих великих
моделей мови для практичних застосувань.
Генерація, доповнена пошуком (RetrievalAugmented Generation, RAG) - це метод, який
покращує великі мовні моделі (LLM), інтегруючи пошук
даних у реальному часі. Це дозволяє LLM надавати
більш точні та релевантні відповіді, що важливо для
високоточних корпоративних додатків.
3.
Векторна база даних (Vector Database) - це спеціалізована база даних, де дані представлені у векторнійформі. У такій базі кожен об'єкт або запис може бути представлений у вигляді вектора чисел. Цей підхід
особливо ефективний у випадках, коли дані можна виразити у вигляді числових ознак або векторів, таких як у
випадку тексту (де кожне слово може мати свій векторний представлення), зображень або аудіо-сигналів.
Основні концепції векторних баз даних включають:
Представлення об'єктів у векторній формі: Кожен об'єкт у базі даних представляється у вигляді вектора чисел, де
кожне число може відображати певну ознаку або характеристику цього об'єкта.
Пошук найближчих сусідів: Однією з основних операцій у векторних базах даних є пошук найближчих сусідів для
заданого вектора. Це корисно для пошуку схожих об'єктів у базі даних.
Індексація векторів: Для ефективного пошуку найближчих сусідів вектори зазвичай індексуються за допомогою
спеціалізованих алгоритмів, які дозволяють швидко відшукати сусідні вектори.
Використання в машинному навчанні і обробці природної мови: Векторні бази даних широко використовуються у
сферах машинного навчання та обробки природної мови для різних завдань, таких як класифікація, кластеризація, аналіз
сентиментів та інші.
Pinecone - це повністю керована, безсерверна векторна
база даних, пріоритетами якої є висока продуктивність і
простота використання. Вона поєднує в собі передові
алгоритми векторного пошуку з фільтрацією та
розподіленою інфраструктурою для швидкого, надійного
векторного пошуку в масштабах. Легко інтегрується з
фреймворками машинного навчання та джерелами даних
для таких додатків, як семантичний пошук, рекомендації,
виявлення аномалій та відповіді на запитання.
4.
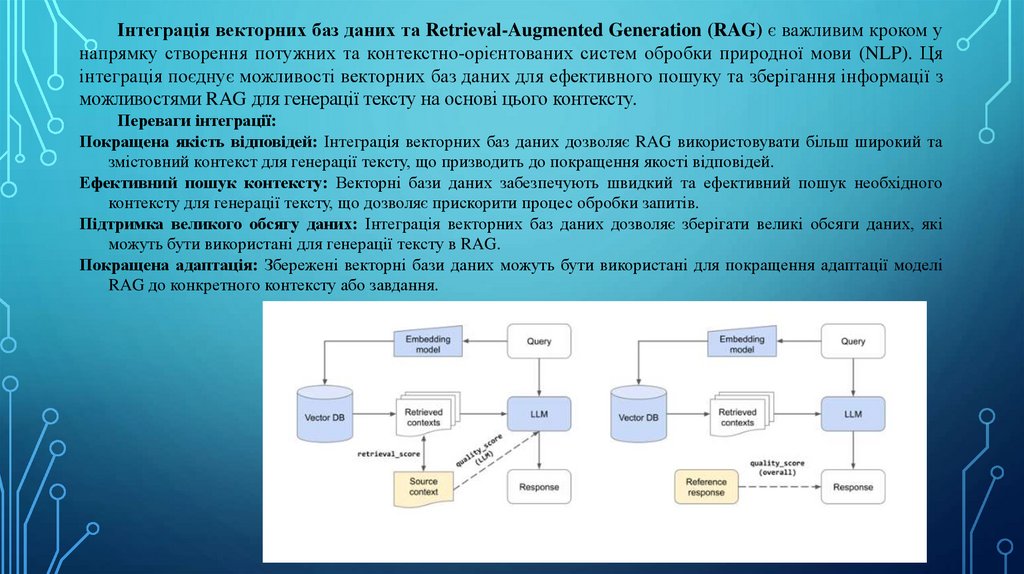
Інтеграція векторних баз даних та Retrieval-Augmented Generation (RAG) є важливим кроком унапрямку створення потужних та контекстно-орієнтованих систем обробки природної мови (NLP). Ця
інтеграція поєднує можливості векторних баз даних для ефективного пошуку та зберігання інформації з
можливостями RAG для генерації тексту на основі цього контексту.
Переваги інтеграції:
Покращена якість відповідей: Інтеграція векторних баз даних дозволяє RAG використовувати більш широкий та
змістовний контекст для генерації тексту, що призводить до покращення якості відповідей.
Ефективний пошук контексту: Векторні бази даних забезпечують швидкий та ефективний пошук необхідного
контексту для генерації тексту, що дозволяє прискорити процес обробки запитів.
Підтримка великого обсягу даних: Інтеграція векторних баз даних дозволяє зберігати великі обсяги даних, які
можуть бути використані для генерації тексту в RAG.
Покращена адаптація: Збережені векторні бази даних можуть бути використані для покращення адаптації моделі
RAG до конкретного контексту або завдання.
5.
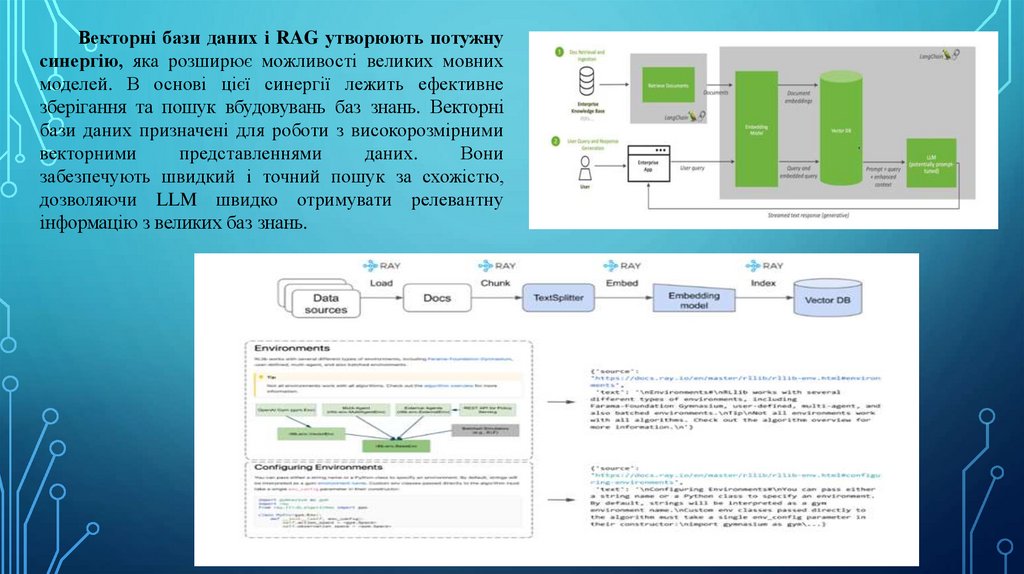
Векторні бази даних і RAG утворюють потужнусинергію, яка розширює можливості великих мовних
моделей. В основі цієї синергії лежить ефективне
зберігання та пошук вбудовувань баз знань. Векторні
бази даних призначені для роботи з високорозмірними
векторними
представленнями
даних.
Вони
забезпечують швидкий і точний пошук за схожістю,
дозволяючи LLM швидко отримувати релевантну
інформацію з великих баз знань.
6.
Великі моделі мови (LLM) спричинили революцію в галузі обробки природних мов. Вони проклали шлях дляширокого спектра операцій, таких як:
Чат-боти
Генерація контенту
Машинний переклад
Аналіз настрою
Підсумовування тексту
Системи відповідей на питання
Ці операції зробили LLM невід'ємною частиною сучасних систем штучного інтелекту, дозволивши машинам
розуміти та взаємодіяти з людьми більш природним та інтуїтивним способом.
Однак ці складні моделі стикаються з кількома викликами, включаючи:
Нечіткість у природних мовах
Галюцинації та упередження
Проблеми з вартістю та затримкою
Вирівнювання завершення
Професійність завдань
Прогалини в знаннях
Вирішення цих викликів є важливим для розкриття повного потенціалу LLM та закріплення їх позиції як
невід'ємного активу в сучасному світі, що керується штучним інтелектом.
Щоб усунути ці прогалини в знаннях, можна використовувати техніки доповнення даних, такі як включення
додаткових даних до набору даних для навчання або застосування переносу навчання. Крім того, комбінування
різних моделей, наприклад, моделі з доповненням вибірки, може допомогти подолати ці прогалини та покращити
продуктивність LLM.