



















 Базы данных
Базы данныхПохожие презентации:






")


")
SQL astondevs.ru
1.
SQLastondevs.ru
2.
SQLSQL — это язык структурированных запросов (Structured Query Language), позволяющий
хранить, манипулировать и извлекать данные из реляционных баз данных.
Команды SQL можно разделить на 4 группы:
1. DDL — язык определения данных (Data Definition Language)
2. DML — язык изменения данных (Data Manipulation Language)
3. DCL — язык управления данными (Data Control Language)
4. TCL – язык управления транзакциями (Transaction Control Language)
3.
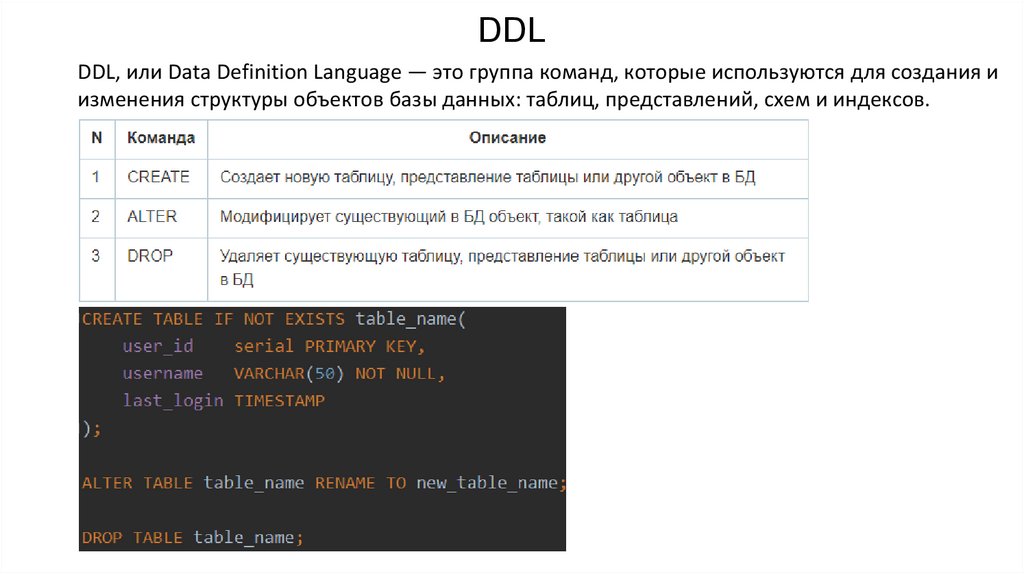
DDLDDL, или Data Definition Language — это группа команд, которые используются для создания и
изменения структуры объектов базы данных: таблиц, представлений, схем и индексов.
4.
DMLDML, или Data Manipulation Language — это группа операторов, которые позволяют получать и
изменять записи, присутствующие в таблице. Разберем отдельные DML-команды.
5.
DCLDCL, или Data Control Language — это команды SQL, которые используют для предоставления и
отзыва привилегий пользователя базы данных. При этом пользователь не может откатить
изменения.
6.
TCLTCL, или Transaction Control Language — одни из наиболее популярных команд SQL. Их
используют для обеспечения согласованности базы данных и для управления транзакциями.
7.
ОграниченияОграничения (constraints) — это правила, применяемые к данным. Они используются для ограничения данных,
которые могут быть записаны в таблицу. Это обеспечивает точность и достоверность данных в БД.
Ограничения могут устанавливаться как на уровне колонки, так и на уровне таблицы.
Среди наиболее распространенных ограничений можно назвать следующие:
1. NOT NULL — колонка не может иметь нулевое значение.
2. DEFAULT — значение колонки по умолчанию.
3. UNIQUE — все значения колонки должны быть уникальными.
4. PRIMARY KEY — первичный ключ, уникальный идентификатор записи в текущей таблице.
5. FOREIGN KEY — внешний ключ, уникальный идентификатор записи в другой таблице (ссылка на ПК).
6. CHECK — все значения в колонке должны удовлетворять определенному условию.
7. INDEX — быстрая запись и извлечение данных.
Любое ограничение может быть удалено с помощью команды ALTER TABLE и DROP CONSTRAINT + название
ограничения.
8.
Вопрос на 1 баллЧем unique отличается от primary key?
9.
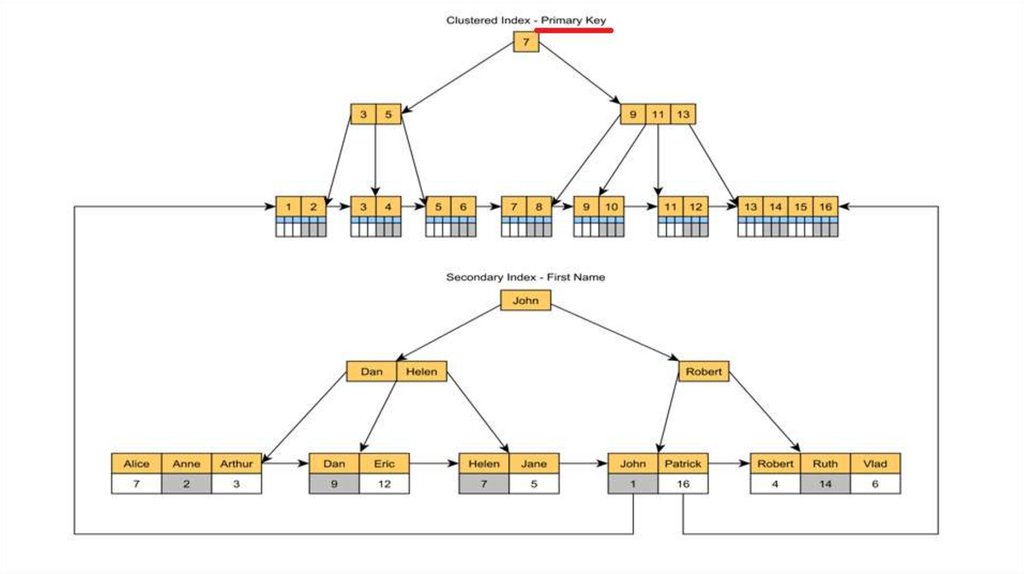
DB Indexes10.
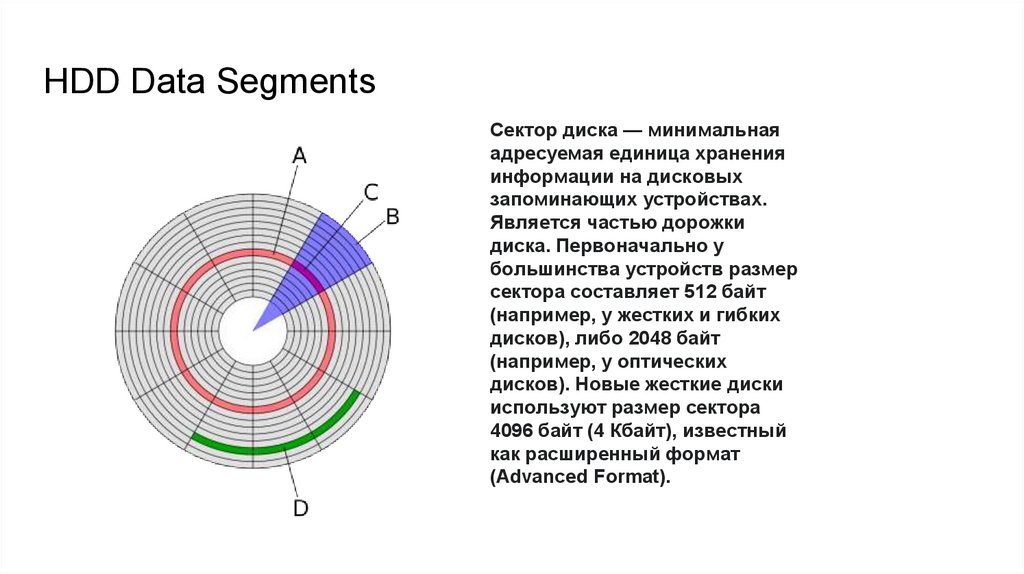
HDD Data SegmentsСектор диска — минимальная
адресуемая единица хранения
информации на дисковых
запоминающих устройствах.
Является частью дорожки
диска. Первоначально у
большинства устройств размер
сектора составляет 512 байт
(например, у жестких и гибких
дисков), либо 2048 байт
(например, у оптических
дисков). Новые жесткие диски
используют размер сектора
4096 байт (4 Кбайт), известный
как расширенный формат
(Advanced Format).
11.
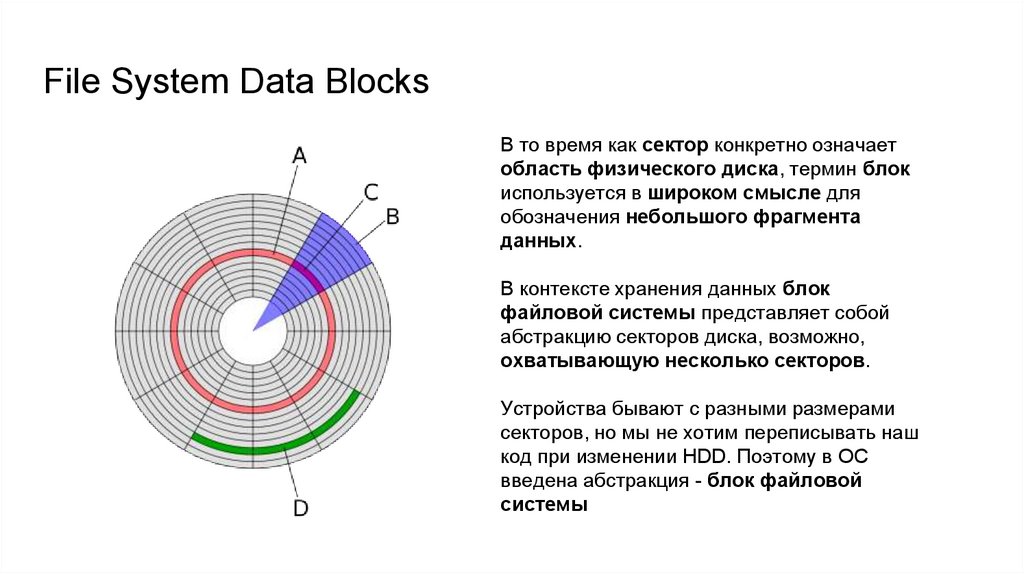
File System Data BlocksВ то время как сектор конкретно означает
область физического диска, термин блок
используется в широком смысле для
обозначения небольшого фрагмента
данных.
В контексте хранения данных блок
файловой системы представляет собой
абстракцию секторов диска, возможно,
охватывающую несколько секторов.
Устройства бывают с разными размерами
секторов, но мы не хотим переписывать наш
код при изменении HDD. Поэтому в ОС
введена абстракция - блок файловой
системы
12.
ИндексыИндекс – это ключ, построенный из одного или нескольких столбцов в базе данных, который
ускоряет выборку строк из таблицы или представления.
Таблицы в базе данных могут иметь большое количество строк, которые хранятся в
произвольном порядке, и их поиск по заданному критерию путём последовательного просмотра
таблицы строка за строкой может занимать много времени.
Виды индексов:
1. Простой
2. Составной
3. Уникальный
4. Кластеризованный
5. Некластеризованный
13.
Вопрос на 0,5 баллаВ каких операциях будут использоваться индексы?
14.
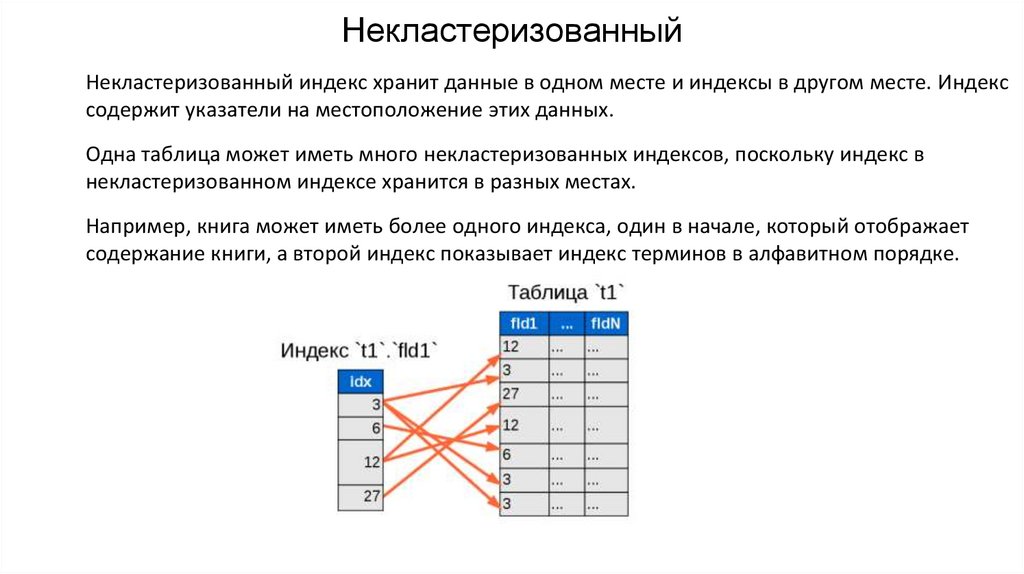
НекластеризованныйНекластеризованный индекс хранит данные в одном месте и индексы в другом месте. Индекс
содержит указатели на местоположение этих данных.
Одна таблица может иметь много некластеризованных индексов, поскольку индекс в
некластеризованном индексе хранится в разных местах.
Например, книга может иметь более одного индекса, один в начале, который отображает
содержание книги, а второй индекс показывает индекс терминов в алфавитном порядке.
15.
НекластеризованныйДопустим у нас есть такой запрос:
Совсем без индексации будет прочитана и проверена каждая строка, и неудовлетворяющие условию
строки просто не попадут в результат. Но прочитаны они будут.
При использовании «обычного», некластерного индекса, задача поиска сильно ускоряется.
1. Во-первых, индексная таблица весит много меньше таблицы с данными, а значит элементарно может
быть прочитана быстрее.
2. Во-вторых, СУБД чаще всего стараются кешировать индексы в оперативную память, которая сама по
себе много шустрее жёсткого диска*.
3. В-третьих, в индексах отсутствуют дублирующиеся строки. А значит, как только мы нашли первое
значение, поиск можно прекращать — оно же и последнее.
4. В-четвёртых, данные в индексе отсортированы. А в-третьих и в-четвёртых вместе позволяют
использовать алгоритм бинарного поиска, эффективность которого многократно превосходит простой
перебор.
Индексация — великая сила. Но если представить все указатели индексной таблицы на строки в таблице
данных ОДНОВРЕМЕННО, получится достаточно сложная «паутина»
16.
КластеризированныйКластерный индекс — это древовидная структура данных, при которой значения индекса
хранятся вместе с данными, им соответствующими. И индексы, и данные при такой
организации упорядочены. При добавлении новой строки в таблицу, она дописывается не в
конец файла, не в конец плоского списка, а в нужную ветку древовидной структуры,
соответствующую ей по сортировке.
Кластерные индексы отличаются от некластерных точно так же, как оглавление книги
отличается от алфавитного указателя. Алфавитный указатель (некластерный индекс) для
точного слова (значения) даёт точные номера страниц (строки в БД). Оглавление же указывает
диапазон страниц, соответствующих определённой главе, в которой уже найдётся искомое
слово. Причём каждая глава, если она достаточно велика, может содержать собственное
оглавление.
17.
18.
ИндексыИндексы могут улучшить производительность системы, т.к. они обеспечивают подсистему запросов быстрым
путем для нахождения данных. Однако, вы должны также принять во внимание то, как часто вы собираетесь
вставлять, обновлять или удалять данные. Когда вы изменяете данные, то индексы должны также быть
изменены, чтобы отразить соответствующие действия над данными, что может значительно снизить
производительность системы.
Общие советы по применению индексов:
1.
Для таблиц которые часто обновляются используйте как можно меньше индексов.
2.
Для кластеризованных индексов старайтесь использовать настолько короткие поля насколько это
возможно. Наилучшим образом будет применение кластеризованного индекса на столбцах с
уникальными значениями и не позволяющими использовать NULL. Вот почему первичный ключ часто
используется как кластеризованный индекс.
3.
Уникальность значений в столбце влияет на производительность индекса. В общем случае, чем больше у
вас дубликатов в столбце, тем хуже работает индекс.
4.
Для составного индекса возьмите во внимание порядок столбцов в индексе. Столбцы, которые
используются в выражениях WHERE (к примеру, WHERE FirstName = 'Charlie') должны быть в индексе
первыми. Последующие столбцы должны быть перечислены с учетом уникальности их значений (столбцы
с самым высоким количеством уникальных значений идут первыми).
19.
20.
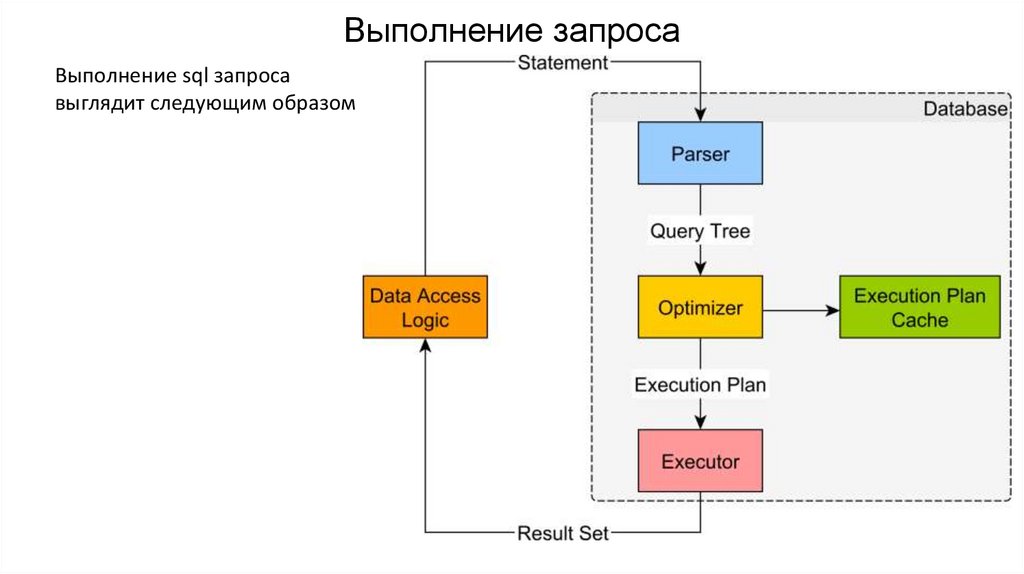
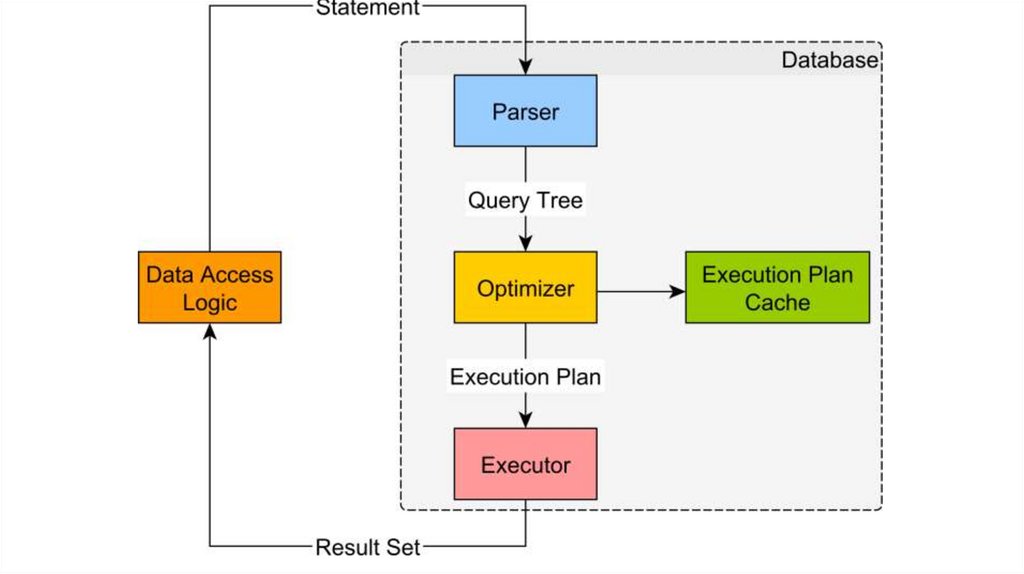
Выполнение запросаВыполнение sql запроса
выглядит следующим образом
21.
ParserParser проверяет запрос на валидность. Проверяется
1. Синтаксис запроса – все sql операторы написаны правильно и в правильном порядке.
2. Семантика запроса - ссылаемся на существующие таблицы и колонки в них.
Во время парсинга запрос трансформируется в query/syntax tree.
If the SQL statement is a high-level representation (being more meaningful from a human perspective),
the syntax tree is the logical representation of the database objects required for fulfilling the current
statement.
22.
OptimizerНа этом этапе определяется “самый эффективный” способ выполнения query tree. В частности:
1.
Каким образом сканировать таблицу, с использованием индекса index scan или сканировать всю
таблицу full scan.
2.
Если таблица сканируется при помощи индекса, то нужно выбрать какой именно индекс используется.
3.
Если в рамках запроса есть операции join, то нужно выбрать наиболее быстрый тип join для данного
запроса (Nested Loops Joins, Hash Joins, Merge Joins).
4.
И огромное количество других факторов.
Выбор наиболее эффективного плана запроса это не тривиальная задача, и чаще всего в бд есть лимит по
времени на построение плана выполнения.
Для оптимизации этого процесса бд хранят различного рода статистику (размер таблицы, как часто
повторяются данные в колонках и тд).
23.
ExecutorExecutor отправляет оптимизированный план выполнения запроса движку бд и возвращает ResultSet.
24.
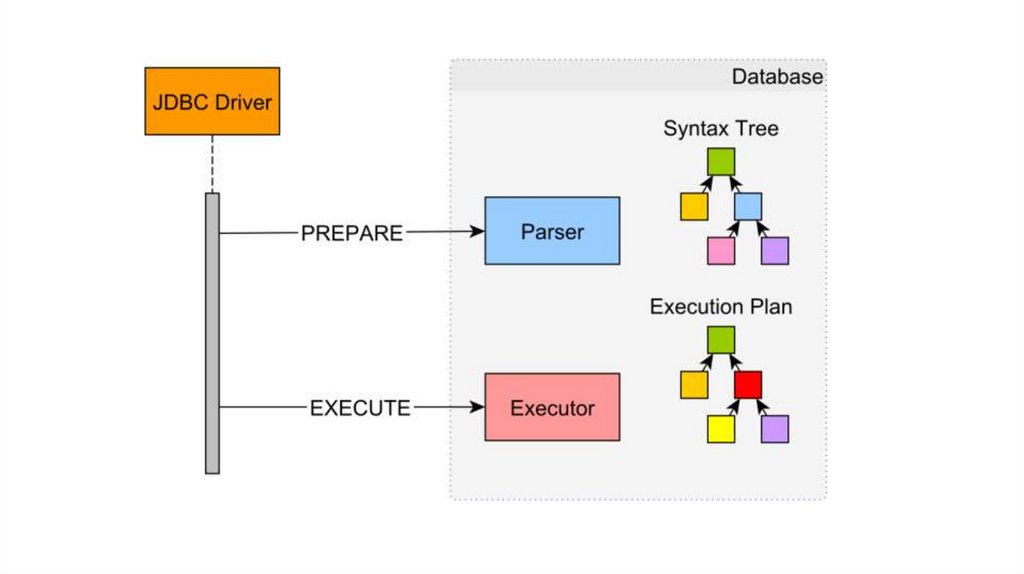
Вопрос на 1 баллЧем отличается Statement от PreparedStatement?
25.
26.
27.
Очень интересно, но зачем нам это знать?28.
ExplainExplain позволяет увидеть план запроса