




















 Электроника
ЭлектроникаПохожие презентации:

")


")



")
")
Архитектура процессора. Параллелизм
1.
Архитектура процессораПАРАЛЛЕЛИЗМ
2.
Конвейерная организация обработки командСовмещение операций
• «Совмещение операций», при котором аппаратура
компьютера в любой момент времени выполняет
одновременно более одной базовой операции,
включает два понятия: параллелизм и
конвейеризацию.
• При параллелизме совмещение операций достигается
путем воспроизведения в нескольких копиях
аппаратной структуры.
3.
ПАРАЛЛЕЛИЗМСуть параллелизма заключается в том, что
распределение команд между исполнительными
узлами производится не процессором в ходе
выполнения программы (динамически), а
компилятором при формировании машинного
кода (статически).
4.
Процессоры первого и второгопоколений
Процессоры первого и второго поколений представлены
CPU 8086/8088 и 80286.
Процессор 8086/8088 имел тактовую частоту 4,77МГц
и оперативную память 256 Кбайт.
Процессор второго поколения имел защищенный
режим работы, позволявший обращаться к 16 Мбайт
физической и 1 Гбайт виртуальной памяти.
Лучшие из процессоров 80286 достигли тактовой
частоты в 20 МГц.
5.
Процессоры третьего поколенияПроцессоры третьего поколения 80386 отличались от
своих предшественников
1.возможностью работы в виртуальном режиме,
2.наличием внешней кэш-памяти CPU, расположенной на
материнской плате, и
3.32-разрядным ядром CPU.
32-разрядный процессор 386 DX имел тактовую частоту
уже 33 МГц, обеспечивал адресацию физической памяти до 4
Гбайт и виртуальной -до 64 Гбайт.
6.
Процессоры четвертого поколенияПроцессоры четвертого поколения 80486 отличаются
от процессоров третьего поколения тем, что в само ядро
CPU интегрированы кэш-память и сопроцессор, а также
реализована конвейеризация вычислений.
Типичными
представителями
CPU
четвертого
поколения
являются
80486DX
и
80486SX
с
соответствующими диапазонами тактовых частот 33 ...
50 МГц и 2 ... МГц.
7.
СопроцессорСопроцессор, или математический процессор (Numeric Processing Unit
- NPU), предназначен для выполнения арифметических действий с
плавающей точкой. Он не управляет системой, а ждет команду от CPU
на выполнение арифметических действий и формирование результатов.
Фирма Intel полагает, что сопроцессор может на 80 % сократить время
выполнения таких операций, как умножение и возведение в степень.
8.
Модуль предсказания переходовМодуль предсказания переходов (прогнозирования
ветвлений) — устройство, входящее в
состав микропроцессоров, имеющих конвейерную
архитектуру, предсказывающее, будет ли
выполнен условный переход в исполняемой
программе. Предсказание ветвлений позволяет
сократить время простоя конвейера
9.
Процессоры пятого поколения типаPentium
Процессоры пятого поколения типа Pentium поддерживают 64разрядную системную шину с тактовой частотой 66 МГц, имеют
технологию предсказания переходов и параллельной конвейерной
обработки данных с помощью двух пятиступенчатых конвейеров.
Предсказание переходов реализуется благодаря хранению
данных о последних 256 переходах в специальном буфере адреса
перехода. Кэш-память объемом 16 Кбайт разделена на память данных
и память команд по 8 Кбайт, что исключает пересечение команд и
данных.
10.
Процессоры шестого поколенияПроцессоры шестого поколения поддерживают 64разрядную системную шину и работу многопроцессорных
систем. Первый CPU шестого поколения фирмы Intel носит
имя Pentium Pro.
По сравнению с Pentium процессоры Pentium Pro имеют
не два, а четыре конвейера с увеличением ступеней при
конвейерной обработке данных с пяти до 14,
усовершенствованную технологию предсказания переходов.
Особенностью CPU Pentium Pro является
интегрированная кэш-память второго уровня
11.
Процессоры восьмого поколения• К процессорам восьмого поколения относится процессор
АМD Opteron и разные модификации Athlon 64 (Turion 64), а
также Intel Itanium. CPU Athlon 64 изначально предназначен для
использования в настольных ПК и ноутбуках. Семейство
процессоров Athlon 64 (2 800+, 3 000+, 3 200+, 3 400+, 3 500+, 3
700+, 3 800+ и 4 000+) изготовлены по технологии 0,09 и 0,13
мкм и позиционируются как промежуточное звено между 32и 64-разрядными процессорами. Они обладают тактовой
частотой до 2,4 ГГц и кэш-памятью второго уровня до 1 024
Кбайт.
12.
• Конвейерная обработка основана на разделенииподлежащей исполнению функции на более мелкие
части, называемые ступенями, и выделении для
каждой из них отдельного блока аппаратуры.
• При этом конвейерную обработку можно
использовать для совмещения этапов выполнения
разных команд.
• Производительность при этом возрастает
благодаря тому, что одновременно на различных
ступенях конвейера выполняются несколько
команд.
13.
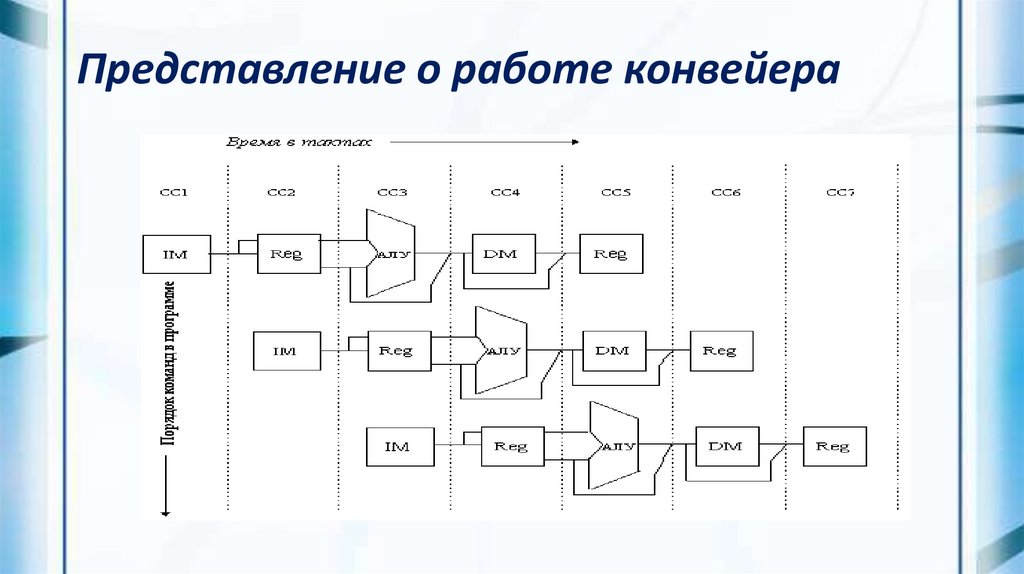
Выполнение типичной команды можноразделить на следующие этапы:
1.
Выборка команды - IF (по адресу, заданному счетчиком
команд, из памяти извлекается команда);
2.
Декодирование
регистров - ID;
3.
Выполнение операции / вычисление эффективного адреса
памяти - EX;
4.
Обращение к памяти - MEM;
5.
Запоминание результата - WB.
команды
/
выборка
операндов
из
14.
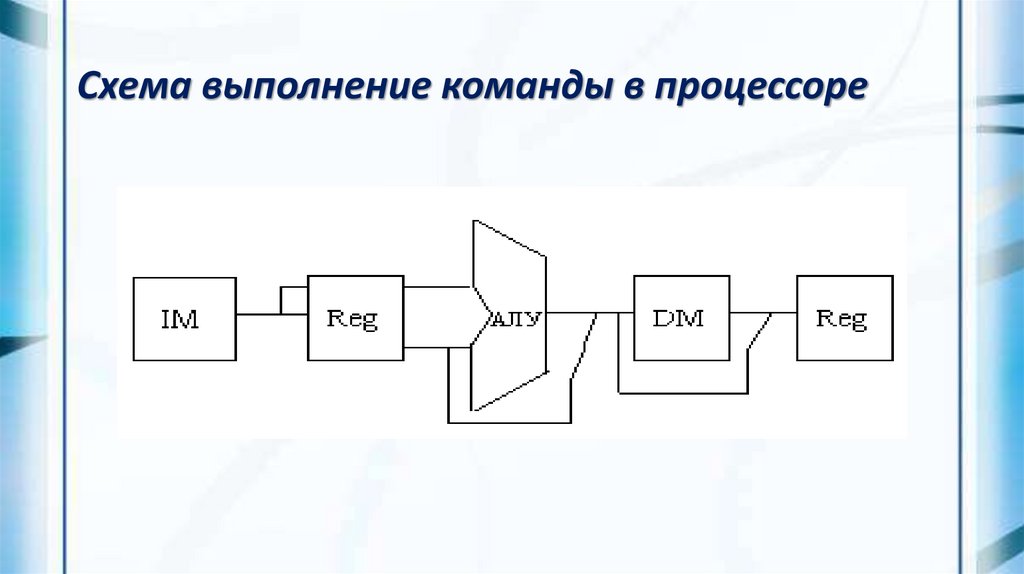
Схема выполнения команд без совмещенияСхема простейшего процессора, выполняющего указанные
выше этапы выполнения команд без совмещения.
Чтобы конвейеризовать эту схему, мы можем просто
разбить выполнение команд на указанные выше этапы, отведя
для выполнения каждого этапа один такт синхронизации, и
начинать в каждом такте выполнение новой команды.
Хотя общее время выполнения одной команды в таком
конвейере будет составлять пять тактов, в каждом такте
аппаратура будет выполнять в совмещенном режиме пять
различных команд.
15.
Схема выполнение команды в процессоре16.
Представление о работе конвейера17.
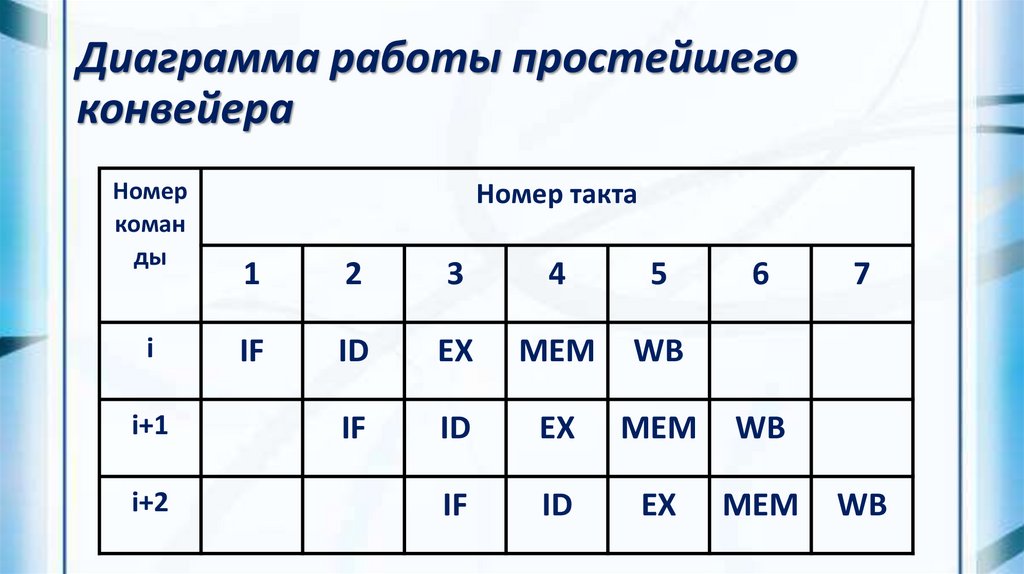
Диаграмма работы простейшегоконвейера
Номер
коман
ды
i
i+1
i+2
Номер такта
1
2
3
4
5
6
IF
ID
EX
MEM
WB
IF
ID
EX
MEM
WB
IF
ID
EX
MEM
7
WB
18.
Не конвейерная машина с пятью этапами -длительностьвыполнения операций 50, 50, 60, 50 и 50 нс
Среднее время выполнения команды в не конвейерной
машине будет равно 260 нс
Накладные расходы на организацию конвейерной
обработки составляют 5 нс
Конвейерная организация, длительность такта будет
равна длительности самого медленного этапа обработки
плюс накладные расходы, т.Е. 65 нс.
Ускорение, полученное в результате конвейеризации,
будет равно:
19.
Эффективность конвейеризацииКонвейеризация эффективна только тогда, когда
загрузка конвейера близка к полной, а скорость подачи новых
команд и операндов соответствует максимальной
производительности конвейера.
Если произойдет задержка, то параллельно будет
выполняться меньше операций и суммарная
производительность снизится.
Такие задержки могут возникать в результате
возникновения конфликтных ситуаций.
20.
Процессоры с множественной выдачей инструкций (multipleissue processors) ориентированы на исполнение нескольких инструкцийза такт и бывают двух видов: супер скалярные процессоры
(superscalar processors) и процессоры с архитектурой VLIW (Very Long
Instruction Word).
VLIW (англ. very long instruction word — «очень длинная
машинная команда») — архитектура процессоров с несколькими
вычислительными устройствами. Характеризуется тем, что одна
инструкция процессора содержит несколько операций, которые
должны выполняться параллельно.
Первые супер скалярные процессоры работали в режиме
упорядоченной выдачи команд.
21.
Супер скалярные процессорыСовременные суперскалярные процессоры исполняют
от 2 до 10 инструкций за такт и используют аппаратную
логику анализа архитектуры системы команд перед
выдачей команд. Такой аппаратный механизм
переупорядочивания исполнения инструкций (out-of-order
engine) называется динамическим планированием.
Компилятор и динамический планировщик не могут
обойти все конфликты (структурные, по данным, по
управлению) и задержки доступа к памяти (при кешпромахах).
22.
RISC - архитектура процессораRISC (англ. restricted (reduced) instruction set computer —
компьютер с сокращённым набором команд) —
архитектура процессора с сокращенным набором команд.
Система команд имеет упрощенный вид. Все команды
одинакового формата с простой кодировкой. Обращение к
памяти происходит посредством команд загрузки и записи,
остальные команды типа регистр-регистр. Команда,
поступающая в CPU, уже разделена по полям и не требует
дополнительной дешифрации.
Часть кристалла освобождается для включения
дополнительных компонентов. Степень интеграции ниже, чем
в предыдущем архитектурном варианте, поэтому при высоком
быстродействии допускается более низкая тактовая частота.
Команда меньше загромождает ОЗУ, CPU дешевле.
23.
MISC- архитектура процессораMISC (англ. minimal instruction set computer — «компьютер с
минимальным набором команд») — вид процессорной архитектуры.
Увеличение разрядности процессоров привело к идее укладки
нескольких команд в одно большое слово (связку, bound). Это позволило
использовать возросшую производительность компьютера и его возможность
обрабатывать одновременно несколько потоков данных. Кроме этого, MISC
использует стековую модель вычислительного устройства и основные
команды работы со стеком языка Forth.
Процессоры с MISC, как и процессоры RISC, характеризуются
небольшим числом чаще всего встречающихся команд. Вместе с этим принцип
«очень длинных командных слов» (VLIW) обеспечивает выполнение группы
непротиворечивых команд за один цикл работы процессора. Порядок
выполнения команд распределяется таким образом, чтобы в максимальной
степени загрузить маршруты, по которым проходят потоки данных.
24.
CISC архитектура процессора с полнымнабором команд
CISC (англ. Complex Instruction Set Computing) —
архитектура процессоров, которая характеризуется
следующим набором свойств:
• большим числом различных по формату и длине команд;
• введением большого числа различных режимов
адресации;
• обладает сложной кодировкой инструкции.
Процессору с архитектурой CISC приходится иметь дело с
более сложными инструкциями неодинаковой длины.