



















 Математика
МатематикаПохожие презентации:






")



Text Mining в RapidMiner (построение характеристического вектора и кластеризация документов)
1.
Text Mining в RapidMiner(построение характеристического вектора и кластеризация документов)
Бленда Н.А.
2.
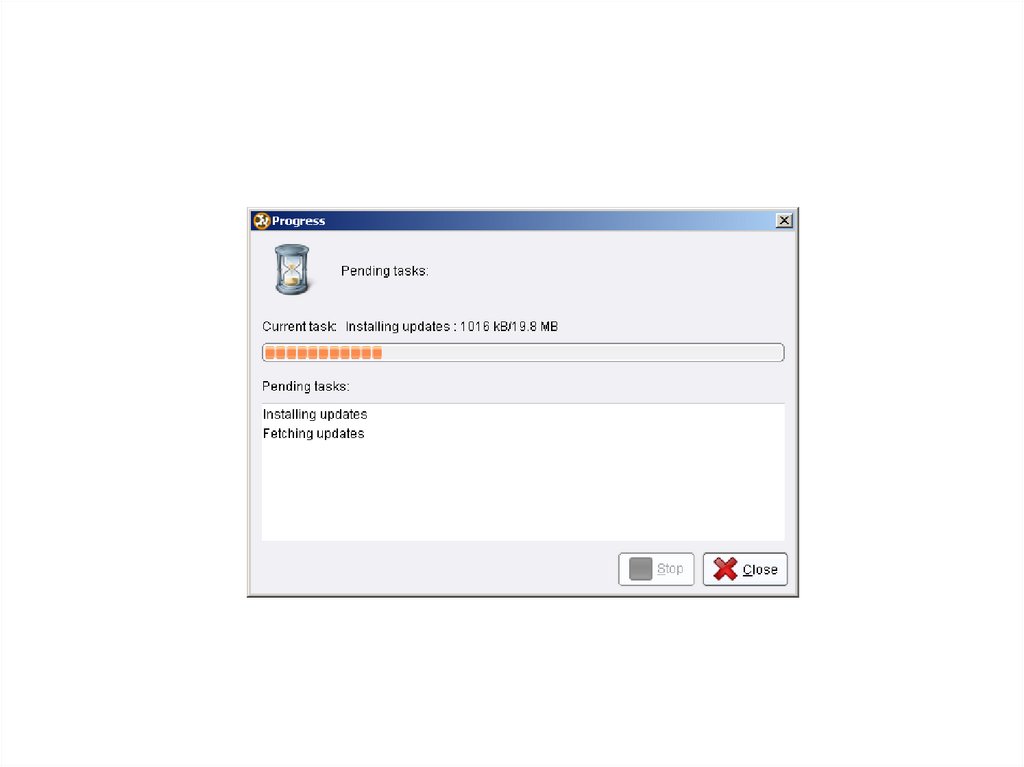
ШАГ 1: Установка расширения Text Mining и Web Mining3.
4.
5.
6.
7.
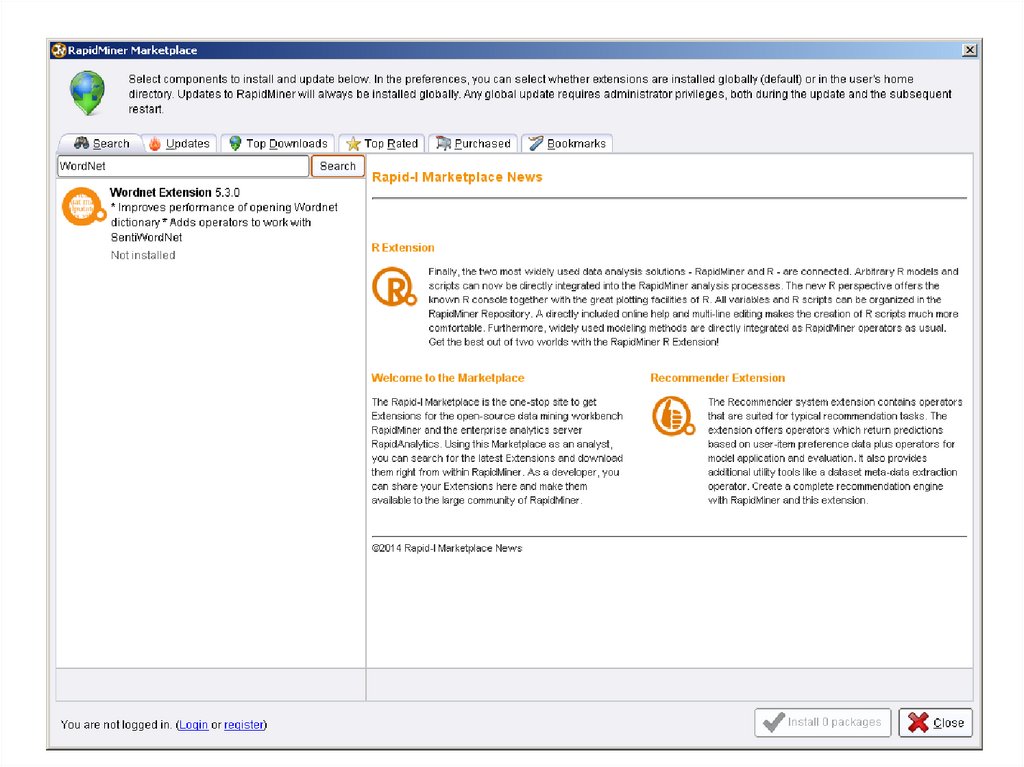
ШАГ 2: Установка словаря WordNet8.
9.
ШАГ 3: Получение характеристик текстовогодокумента
10.
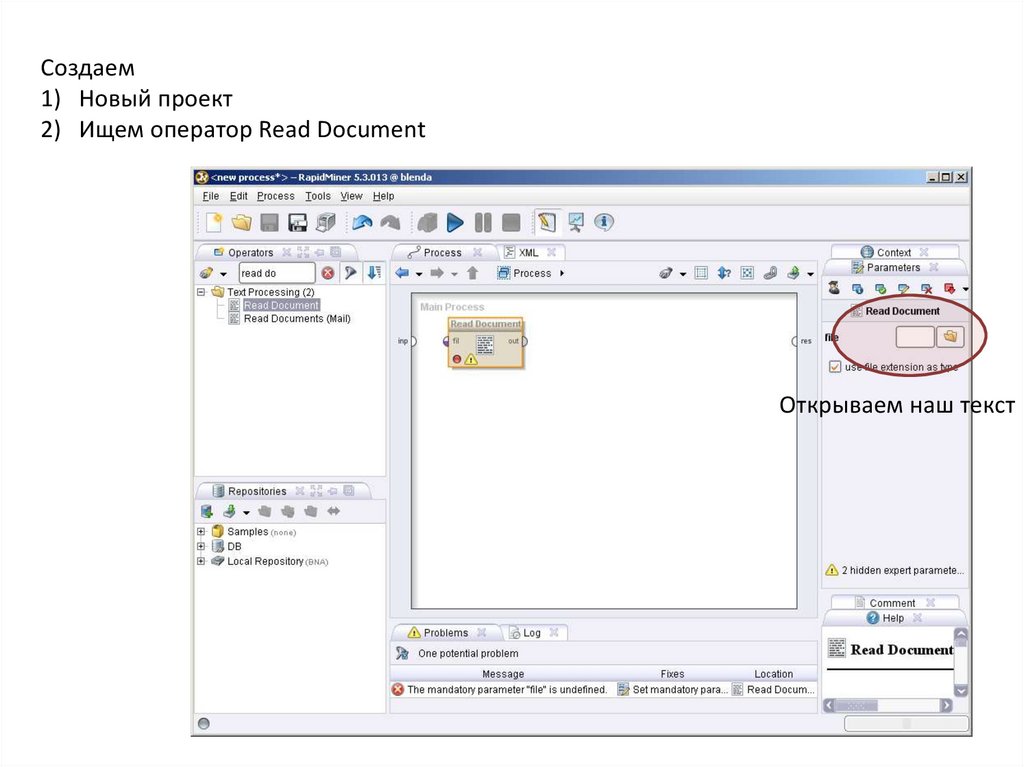
Создаем1) Новый проект
2) Ищем оператор Read Document
Открываем наш текст
11.
3) Настраиваем связи (без входа, выход на res)12.
4)Смотрим на результат13.
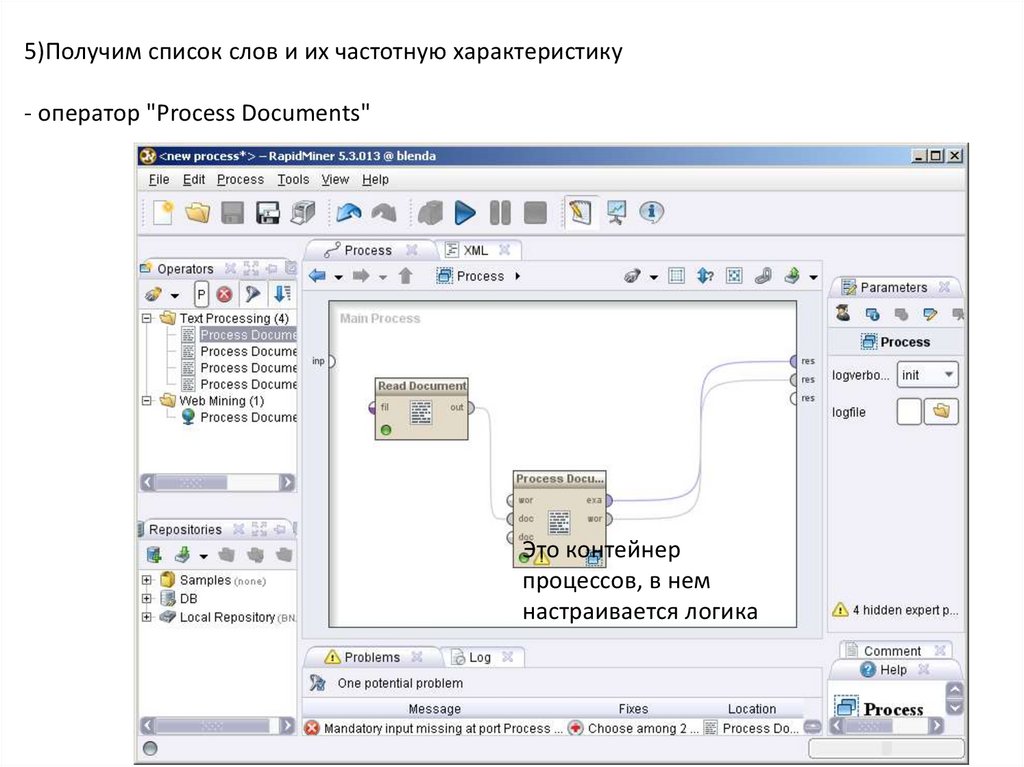
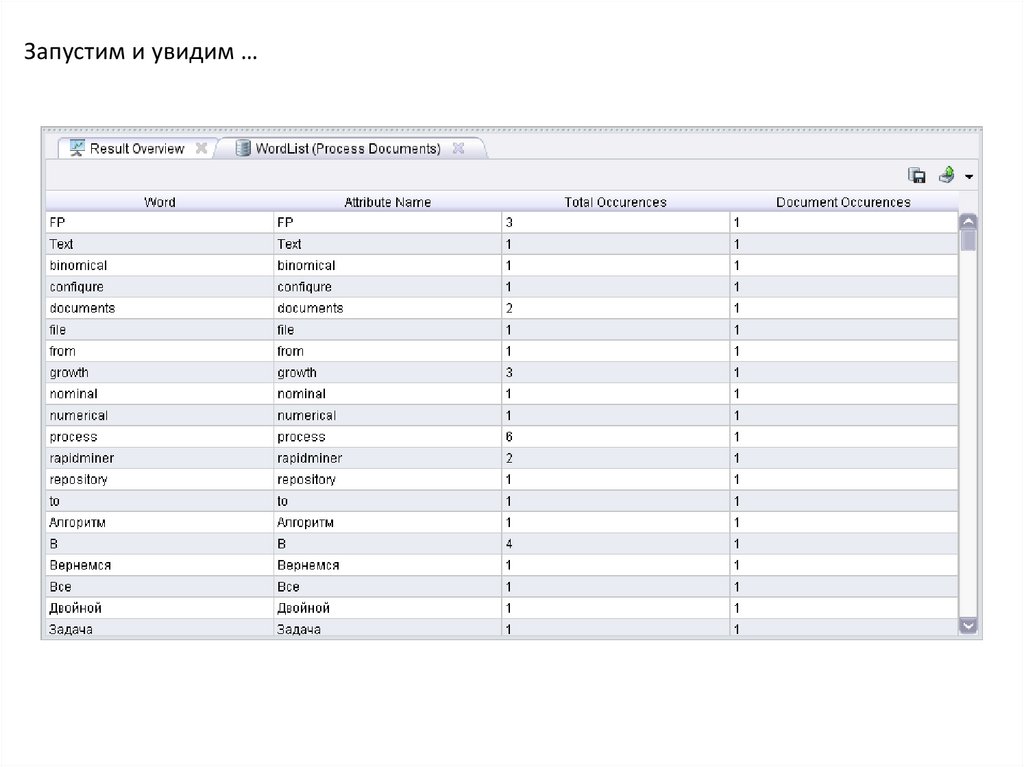
5)Получим список слов и их частотную характеристику- оператор "Process Documents"
Это контейнер
процессов, в нем
настраивается логика
14.
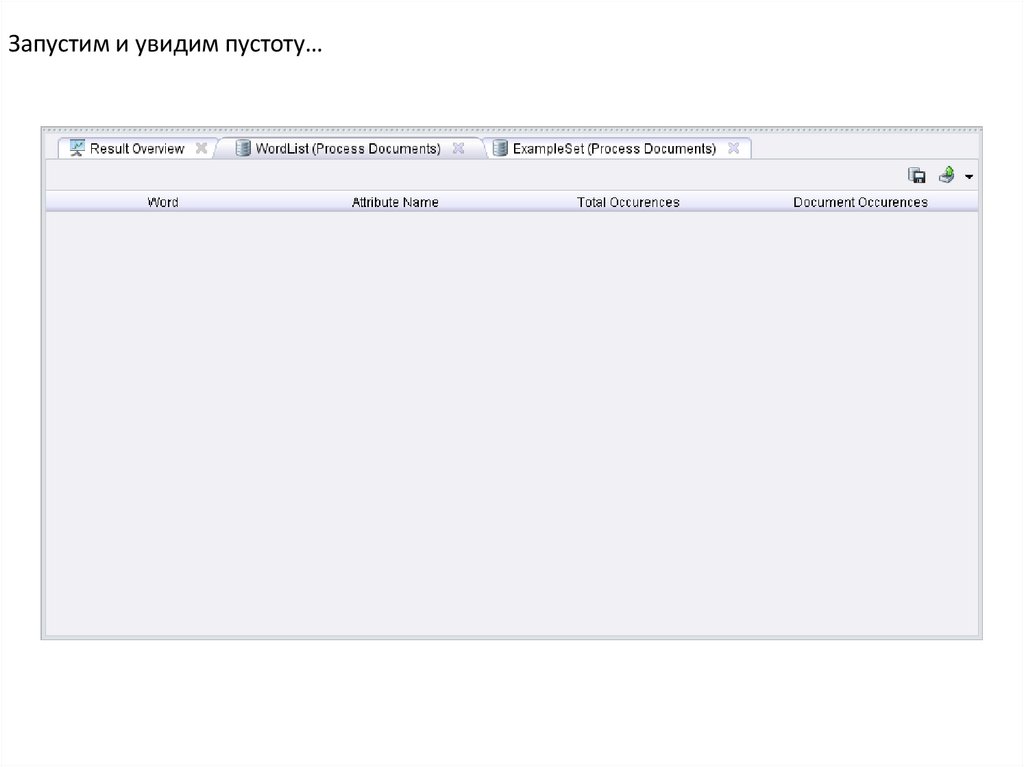
Запустим и увидим пустоту…15.
-токинизируем – то есть получаем список токенов(слов)16.
Запустим и увидим …17.
- Добавляем фильтры ( стоп слов и по длине слова)18.
- Для удобства, приведем все слова в нижний регистр (Transform Cases)19.
20.
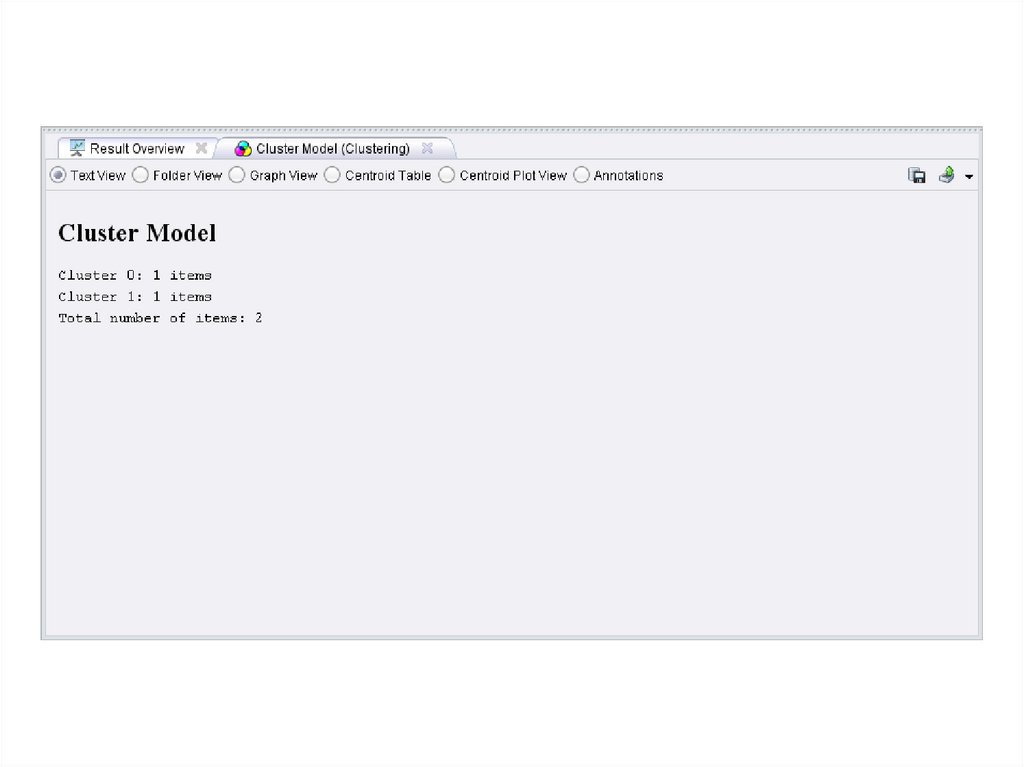
ШАГ 4: Кластеризация набора документов21.
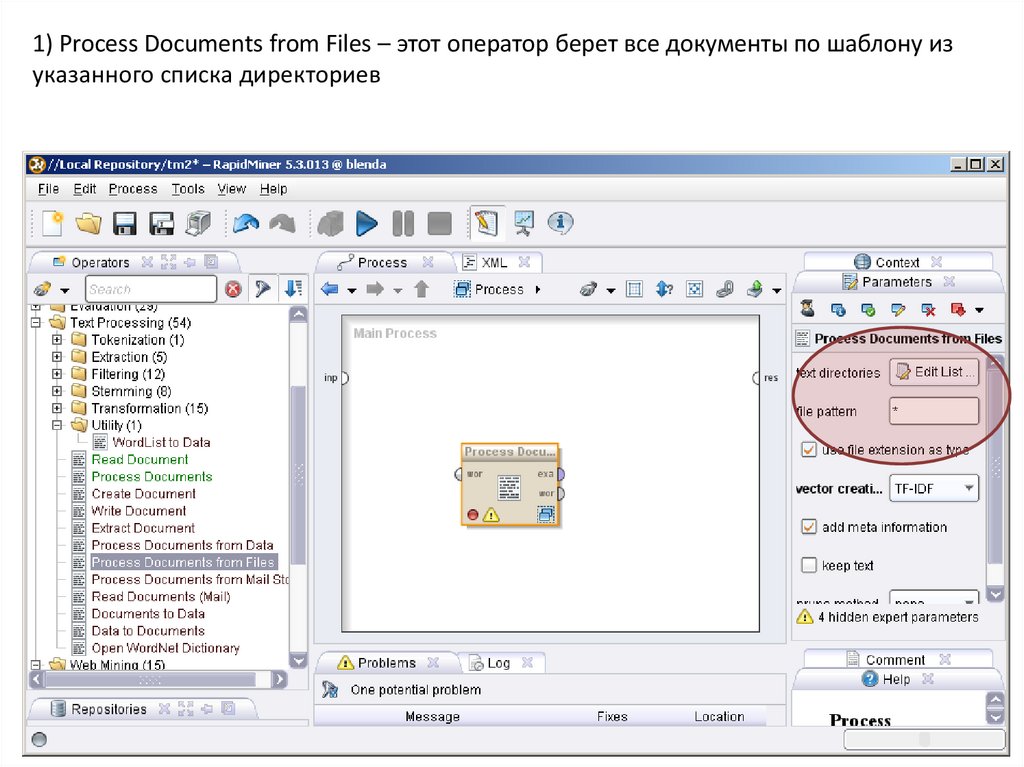
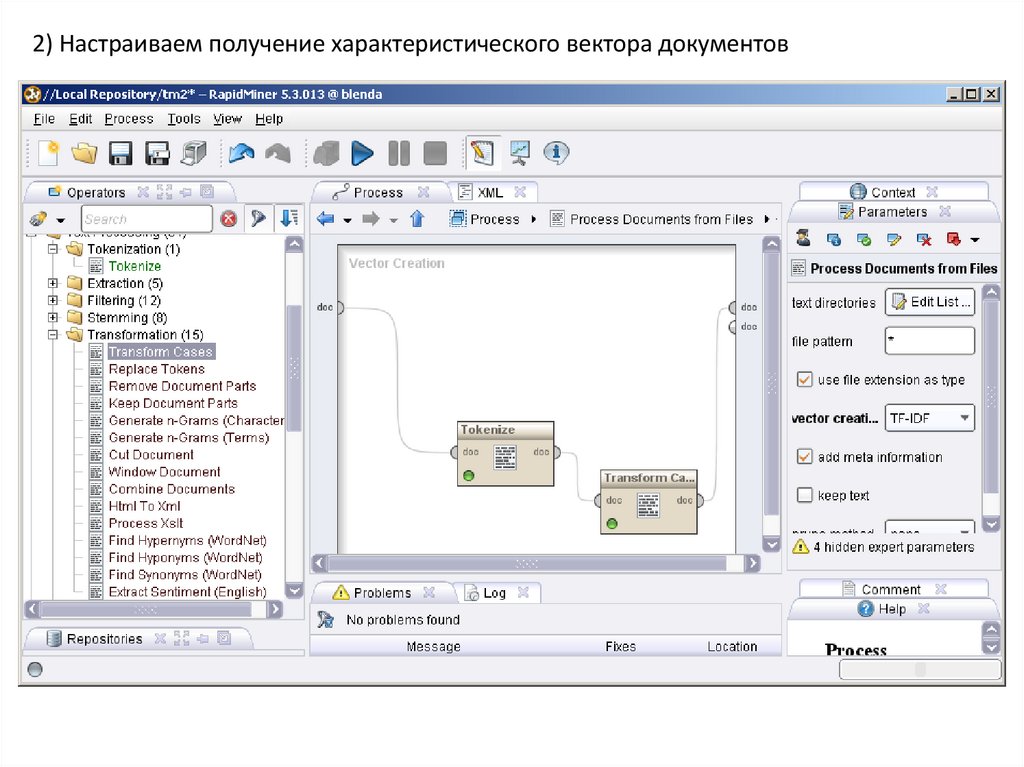
1) Process Documents from Files – этот оператор берет все документы по шаблону изуказанного списка директориев
22.
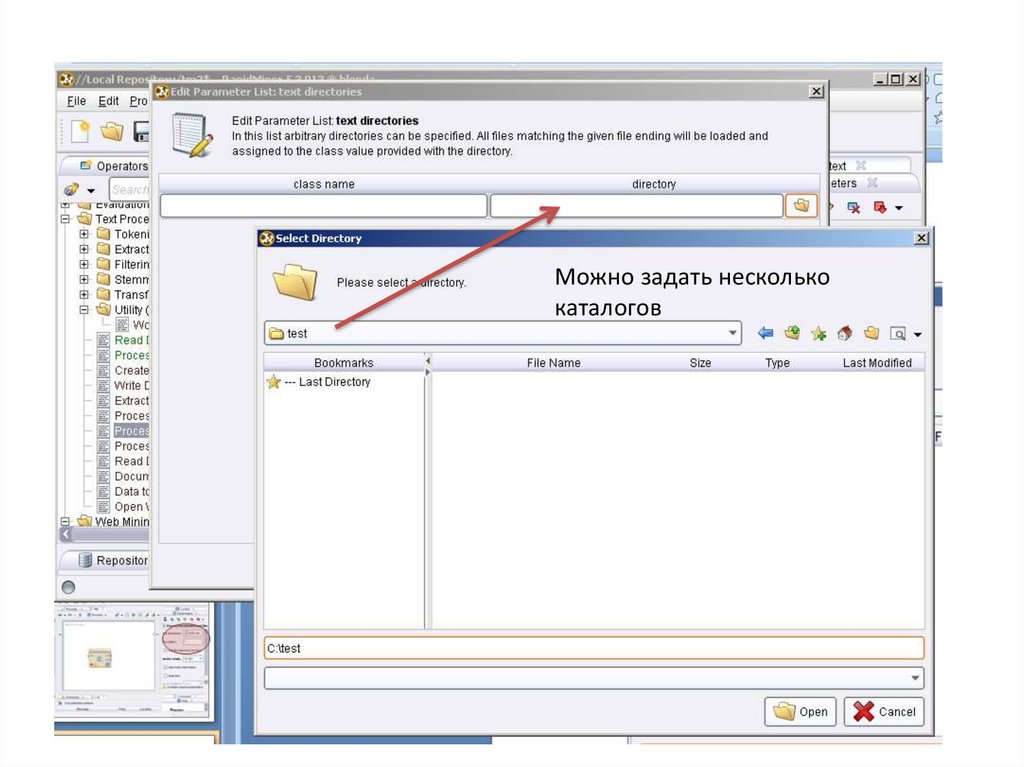
Можно задать несколькокаталогов
23.
2) Настраиваем получение характеристического вектора документов24.
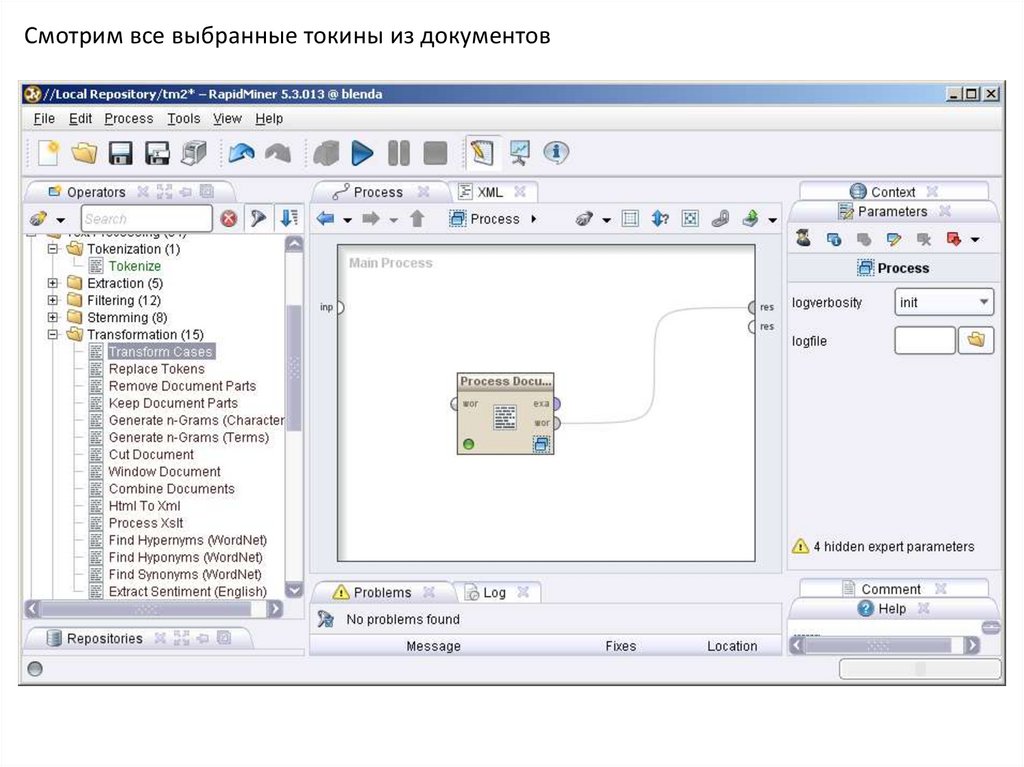
Смотрим все выбранные токины из документов25.
Продолжаем смотретьКоличество док в
которых
встречается слово