





































 Информатика
ИнформатикаПохожие презентации:










Тренды ИИ в 2024. Языковые модели и агенты. Длинный контекст, Chain of thought
1.
Тренды ИИ в 2024Языковые модели и агенты
Длинный контекст, Chain of thought
Семинар 2
2.
Татьяна ШавринаMeta: LLama team
TG channel: @rybolos_channel
ex-Snapchat: Senior Manager, My AI
ex-SberDevices: Старший эксперт по технологиям
ex-AI Research Institute (AIRI): Руководитель
исследовательских проектов в NLP
● Проекты:
○
○
○
○
My AI
ruGPT-3
mGPT
книга в соавторстве ruGPT-3 и Павла Пепперштейна
3.
СегодняНовые рубежи для языковых моделей
— длинный контекст, RAG, работа со знаниями
— function calling
Оценка LLM, на что смотреть при выборе модели
— метрики качества, лицензии
— разница между closed source и open source
Агенты — что они уже умеют?
4.
Основные события 2023-2024Command-R, Command-R Pro
DALLE-3
GPT-4 and GPT-3.5 turbo
GPT-4o, Voice updates
Grounded LLM for search
Claude 3 family:
Haiku, Sonnet, Opus
image description
Grounded LLM for search
Image generation
5.
https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboardMeasuring LLM Progress in 2024
ELO rating on Human judgement + Specific benchmark results
6.
O1 preview/mini7.
О1 - апофеоз Chain-of-thoughtНовая модель OpenAI, дообученная на цепочках рассуждений и с
промптами сверху, контролирующими корректность генерации
каждого шага в многоступенчатом рассуждении.
Новый уровень в автономности модели!
И новый подход к работе с ней
- не нужен промпт-инжиниринг
- будут другие угрозы и джейлбрейки
- такой подход вообще нужен не всегда
- очень высокая latency
8.
9.
10.
О1 - апофеоз Chain-of-thoughtНовая модель OpenAI, дообученная на цепочках рассуждений и с
промптами сверху, контролирующими корректность генерации
каждого шага в многоступенчатом рассуждении.
Новый уровень в автономности модели!
И новый подход к работе с ней
- не нужен промпт-инжиниринг
- будут другие угрозы и джейлбрейки
- такой подход вообще нужен не всегда
- очень высокая latency
11.
ЭмерджентностьEmergent Properties
12.
Emergent Propertiesin the LLM papers
13.
New languagesnew data sources
In-context learning
14.
New languagesnew data sources
In-context learning
15.
Emergent Properties andUnexpected risks
https://www.techradar.com/news/samsung-workers-leaked-company-secrets-by-using-chatgpt
16.
Аргументы противPaLM emergent ability to translate
Что, если пройтись по всему обучающему корпусу и
замерить, сколько там было примеров с переводом?
Данные показывают (780 млрд токенов), что было
примерно 1.4% билингвальных текстов и 0.34%
примеров с параллельным переводом
Если их все автоматически вычистить из обучающего
корпуса и переобучить модель…
способности к переводу значительно ухудшаются!
https://arxiv.org/abs/2305.10266
17.
Аргументы противInvestigating Data Contamination in Modern Benchmarks for Large Language Models
Давайте возьмем наборы данных с несколькими
вариантами ответов (например, MMLU),
затем замаскируем один из неправильных вариантов
ответа и попросим модель восстановить его.
Есть еще несколько вариантов подобных тестов, но этот
самый интересный.
Результаты эксперимента:
MMLU слит в обучение! для GPT-3,5 и GPT-4
точное совпадение 52%
TruthfulQA слит в Mistral
также просочилась в корпуса Pile и C4
https://arxiv.org/abs/2311.09783
18.
Аргументы противhttps://genbench.org/assets/workshop2023_slides/rogers_genbench2023.pdf
19.
Что еще нового у LLM?20.
AnthropicClaude Haiku
Sonnet
Opus
https://www.anthropic.com/news/claude-3-family
21.
AnthropicOpus - конкурент GPT-4o
200k tokens длина контекста
Task automation: plan and execute
complex actions across APIs and
databases, interactive coding
R&D: research review, brainstorming and
hypothesis generation, drug discovery
Strategy: advanced analysis of charts &
graphs, financials and market trends,
forecasting
https://www.anthropic.com/news/claude-3-family
Opus
22.
AnthropicHaiku, Sonnet - более дешевые и быстрые версии
Sonnet
200k tokens длина контекста
Data processing: RAG or search &
retrieval over vast amounts of
knowledge
Sales: product recommendations,
forecasting, targeted marketing
Time-saving tasks: code generation,
quality control, parse text from images
https://www.anthropic.com/news/claude-3-family
Haiku
200k tokens длина контекста
Customer interactions: quick and
accurate support in live interactions,
translations
Content moderation: catch risky
behavior or customer requests
Cost-saving tasks: optimized logistics,
inventory management, extract
knowledge from unstructured data
23.
AnthropicOpus - конкурент GPT-4
https://www.anthropic.com/news/claude-3-family
Opus
24.
Anthropic: документация и советыОчень хорошая документация для всех LLM в целом.
Подробные инструкции, как итеративно написать хорошую затравку
Сделать автоматическую оценку качества работы вашего прототипа
Как дальше оптимизировать – стоимость, скорость и т.д.
Несколько советов:
- описать точно критерии
успеха в промпте
- добавить туда примеры
- добавить формат ввода и
вывода
- составить несколько
десятков, в лучше сотен,
примеров, включая
краевые случаи
- сделать автоматическую
проверку результата
https://docs.anthropic.com/en/docs/prompt-engineering
https://docs.anthropic.com/en/docs/empirical-performance-evaluations
25.
CohereCommand-R
https://docs.cohere.com/docs/command-r
26.
GoogleGemini
2 million tokens длина контекста!
Список ожидания:
https://aistudio.google.com/app/waitlist/9
7595554/
Варианты:
Nano - для запусков на устройстве
Flash - самая быстрая продакшн-модель с
хорошим качеством
Pro - продакшн-модель с лучшим
качеством
https://ai.google.dev/
Ultra - самая мультимодальная версия
27.
Sber - GigachatМультимодальная нейросеть: текст, картинки, код
Gigachat Lite - Контекст: 8192 токенов
простых задач, требующих при этом максимальной скорости работы.
Lite+ - Контекст: 32768 токенов
суммаризация статьей или транскрибаций звонков, извлечение информации из
документов
Pro - Контекст: 8192 токенов
лучше следует сложным инструкциям и может выполнять более комплексные
задачи: значительно повышено качество суммаризации, переписывания и редактирования
текстов, ответов на различные вопросы. Модель хорошо ориентируется во многих
прикладных направлениях — в частности, в экономических и юридических вопросах
https://developers.sber.ru/portal/products/gigachat-api
https://developers.sber.ru/docs/ru/gigachat/models
28.
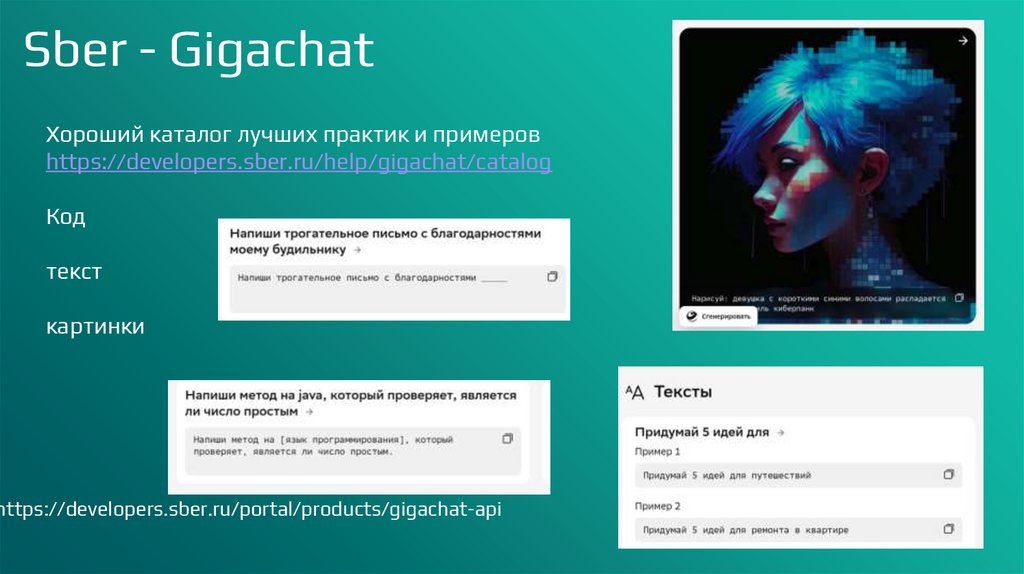
Sber - GigachatХороший каталог лучших практик и примеров
https://developers.sber.ru/help/gigachat/catalog
Код
текст
картинки
https://developers.sber.ru/portal/products/gigachat-api
29.
Yandex - YaGPTYandexGPT Pro - единственная модель версии 3 (GPT-3) из всей линейки
https://ya.ru/ai/gpt-3
YandexGPT Lite - модель предыдущего поколения, GPT-2
Summary - отдельная модель по API для суммаризации текстов
Есть возможность дообучения всех моделей! С командой саппорта
Summarize and rewrite texts.
Generate questions and answers from text input.
Provide responses in a particular format or style.
Classify texts, forms of address, and dialogs.
Extract data from texts.
https://yandex.cloud/en/services/yandexgpt
https://yandex.cloud/en/docs/foundation-models/concepts/yandexgpt/models
30.
Yandex - YaGPTYandexGPT Pro - единственная модель версии 3 (GPT-3) из всей линейки
https://ya.ru/ai/gpt-3
YandexGPT Lite - модель предыдущего поколения, GPT-2
Summary - отдельная модель по API для суммаризации текстов
Есть возможность дообучения всех моделей! С командой саппорта
Summarize and rewrite texts.
Generate questions and answers from text input.
Provide responses in a particular format or style.
Classify texts, forms of address, and dialogs.
Extract data from texts.
https://yandex.cloud/en/services/yandexgpt
https://yandex.cloud/en/docs/foundation-models/concepts/yandexgpt/models
31.
2024: что сработало?32.
Длинное окно контекстаХранение длинных документов прямо в промпте
Хранение всего репозитория
Базы знаний
Длинные цепочки из затравок!
GPT-4: 128k tokens
Gemini: 1 million tokens!
Anthropic Claude 3: 200k tokens
Cohere Command-R: 128k tokens
Как измерить эффективность использования окна
контекста?
33.
RAG: Retrieval-Augmented GenerationСписок документов
Векторная модель (делает
эмбеддинги документов –
страниц, абзацев)
Векторный индекс документов,
векторная БД (хранит
эмбеддинги и осуществляет
быстрый поиск)
Добавление извлеченной
информации в промпт
LLM: Генерация ответа
Вместе с длинным окном контекста,
RAG делает дообучение ненужным для
большинства случаев
34.
Суммаризация множества источников35.
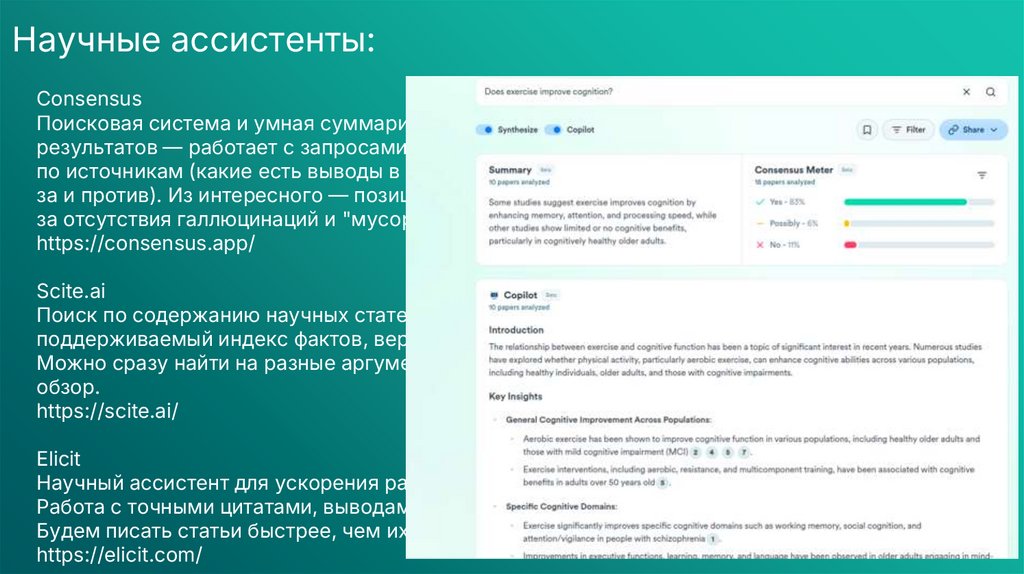
Научные ассистенты:Consensus
Поисковая система и умная суммаризация данных из научных
результатов — работает с запросами на простом языке, выдает статистику
по источникам (какие есть выводы в разных научных работах, в том числе
за и против). Из интересного — позиционируется как замена ChatGPT изза отсутствия галлюцинаций и "мусорных" текстов в обучении.
https://consensus.app/
Scite.ai
Поиск по содержанию научных статей, поиск источников утверждений,
поддерживаемый индекс фактов, верифицируемых в исследованиях.
Можно сразу найти на разные аргументы список литературы и дополнить
обзор.
https://scite.ai/
Elicit
Научный ассистент для ускорения работы с большм объемом статей.
Работа с точными цитатами, выводами и подборкой списка литературы.
Будем писать статьи быстрее, чем их читают!
https://elicit.com/
36.
Научные ассистенты:Consensus
Поисковая система и умная суммаризация данных из научных
результатов — работает с запросами на простом языке, выдает статистику
по источникам (какие есть выводы в разных научных работах, в том числе
за и против). Из интересного — позиционируется как замена ChatGPT изза отсутствия галлюцинаций и "мусорных" текстов в обучении.
https://consensus.app/
Scite.ai
Поиск по содержанию научных статей, поиск источников утверждений,
поддерживаемый индекс фактов, верифицируемых в исследованиях.
Можно сразу найти на разные аргументы список литературы и дополнить
обзор.
https://scite.ai/
Elicit
Научный ассистент для ускорения работы с большм объемом статей.
Работа с точными цитатами, выводами и подборкой списка литературы.
Будем писать статьи быстрее, чем их читают!
https://elicit.com/
37.
Anthropic: генератор промптовhttps://console.anthropic.com/
38.
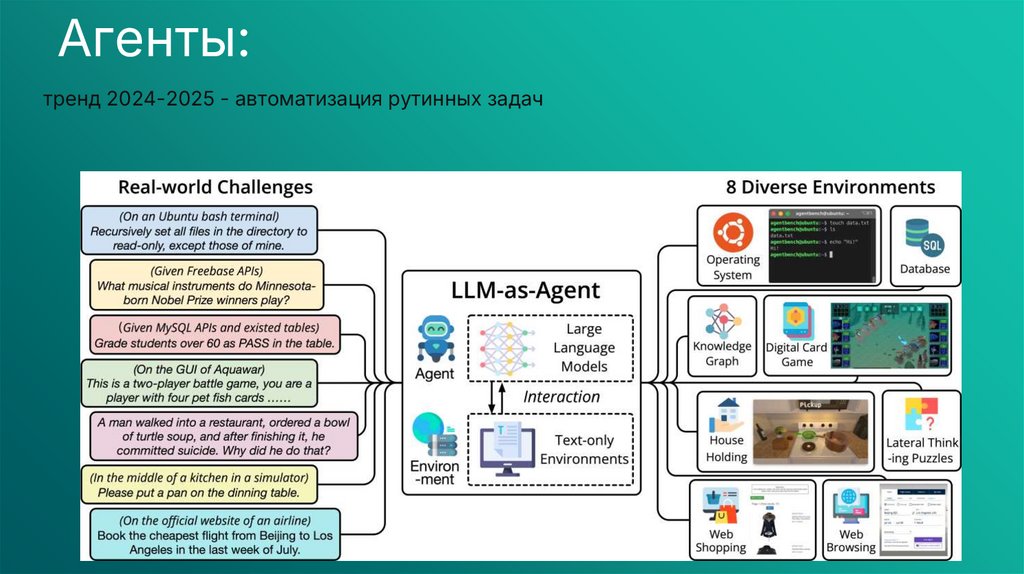
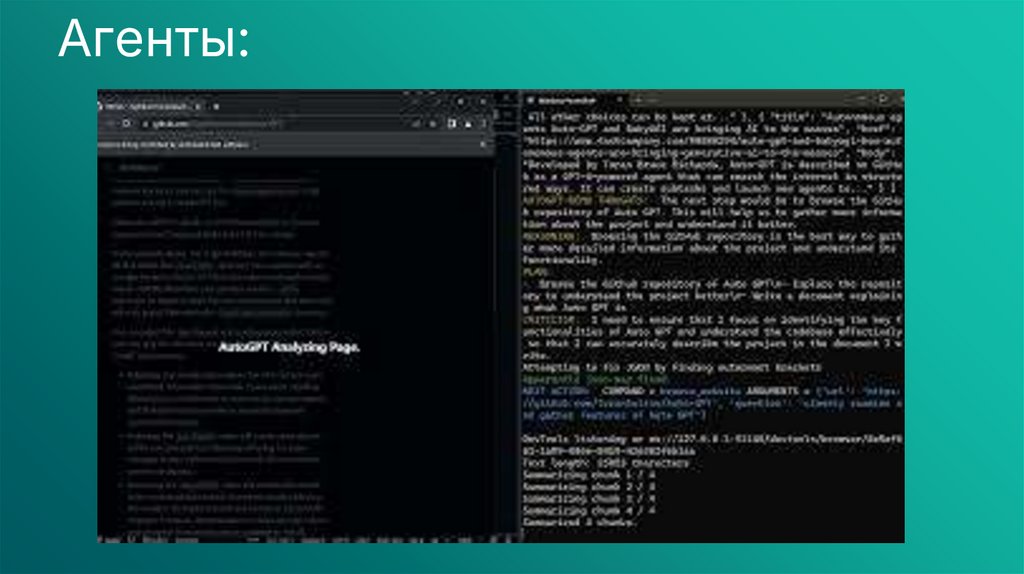
Агенты:тренд 2024-2025 - автоматизация рутинных задач
39.
Агенты:Агент — автономная система, в которой LLM является основными "мозгами", к
которым подключены API и возможность их самостоятельно вызывать и работать с
результатами этих вызовов. Проекты-прототипы:
— AutoGPT — фреймворк для создания агентов и автоматизации LLM, приме
проекта — https://godmode.space/
— GPT-Engineer — ассистент для написания кода, который может создать
репозиторий проекта, задать уточняющие вопросы походу, написать код и тесты.
— BabyAGI — Llama, RAG + планировщик в докере, такой Long Chain c доп
возможностями
40.
Агенты:41.
Составные части агента— Набор действий: генерация команд, релевантных домену, которые можно однозначно проинтерпретировать
(вызвать API, отправить поисковый запрос, отправить SQL-запрос в базу)
— Планирование: Цели и их декомпозиция на последовательность действий: агент разбивает крупные задачи на
более мелкие действия. Интересный подход — LLM+P (arxiv), где внешняя модель, а не LLM, отвечает за формализм
планирования.
Рефлексия и уточнение своих ответов по ходу цепочки сообщений: Chain-of-thought (arxiv), Tree-of-thought (arxiv),
саморефлекция как в статье react (arxiv) или Chain of Hindsight (arxiv).
— Память: RAG, векторные БД, хранение полезной информации в окне контекста.
— API/Инструменты: имеет смысл подключать в первую очередь те инструменты, которые перекрывают недостатки
LLM в вашей области применения. Например, поиск часто изменяющейся информации (курс валют, погода), поиск
по StackOverflow, подключение песочницы для исполнения кода.
42.
WebArena: оценка агентовWebArena смотрит на качество работы агента на основании автоматизации различных веб-задач (найди за меня в
интернете, найди за меня в базе, подпиши меня на рассылку, сделай такую-то страничку), и с помощью
автоматических метрик оценивает в изолированной среде качество полученных ответов. Лидерборд пока выглядит
странновато, и на 1 месте не GPT-4!
43.
Чего еще ждать до конца 2024-2025OpenAI, Anthropic, Google – масштабированные модели более 1 трлн параметров, обучение
дороже 100 млн долл
Больше интеграции с поиском и платформами для развития агентов
Качественные человеческие данные закончатся – обучение будет развиваться в т.ч. а счет
синтетических, сгенерированных данных
Модели меньшего размера все еще нужны! Очень большая потребность для on premise –
все корпоративные ассистенты, работающие с документами, записями встреч, написанием
кода внутри компании с закрытой экосистемой (все банки и т.д.)
Безопасность – остается на откуп клиентам. По договору ответственность будет
распределена, но по факту все текущие модели 100% безопасными не являются, и риски
несете вы сами. Генерация оскорбительного контента, утечка корпоративной информации,
утечка ПД пользователей, генерация чужих данных под копирайтом – ваша проблема
Новое локальное регулирование! Больше законов, в РФ, в Европе, в США, в Китае
Послабления для опен сорса