









 соответствует физическому и канальному уровням модели OSI. Уровень")
 выполняет функции трёх верхних уровней модели OSI. Протоколы прикладного")

















































")



")






























































































Тип случайной связности")

 Тип процедурной связности. Процедурно-связанные элементы появляются сгруппированными вместе вследствие того, что они")
 Тип коммуникационной связности. Диаграммы демонстрируют коммуникационные связи, когда блоки группируются вследствие того,")
 Тип последовательной связности. На диаграммах, имеющих последовательные связи, выход одной функции служит входными данными")
 Тип функциональной связности. Диаграмма отражает полную функциональную связность, при наличии полной зависимости одной")












")

































.")









")
")

")








































 Интернет
ИнтернетПохожие презентации:
")



")

")



Мультисервисная сеть следующего поколения
1. Мультисервисная сеть следующего поколения
Т.к. в мультисервисных сетях нового поколениядолжен передаваться и обрабатываться трафик
разных видов (речевой трафик реального
времени, трафик данных, видеоинформация),
можно выделить три направления работ:
1. Новые телекоммуникационные услуги с
универсальным доступом из ТфОП/ISDN и IPсетей
2. Новые подходы к проблеме качества
обслуживания
3. Проблема сигнализации и управления
2.
Современный этап развитияобщества характеризуется переходом
от постиндустриального к
информационному обществу,
предполагающему новые формы
социальной и экономической
деятельности, базирующиеся на
массовом использовании
информационных и
телекоммуникационных технологий.
3.
Технологической основойинформационного общества
является Глобальная
информационная
инфраструктура (ГИИ), которая
должна обеспечить возможность
недискриминационного доступа к
информационным ресурсам
каждого жителя планеты.
4.
Информационную инфраструктурусоставляет совокупность баз
данных, средств обработки
информации, взаимодействующих
сетей связи и терминалов
пользователя.
5.
Доступ к информационнымресурсам в ГИИ реализуется
посредством услуг связи нового
типа, получивших название
инфокоммуникационных услуг.
6.
Наблюдаемые в настоящее времявысокие темпы роста объемов
предоставления
инфокоммуникационных услуг
позволяют прогнозировать их
преобладание на сетях связи в
ближайшем будущем.
7.
На сегодняшний день развитиеинфокоммуникационных услуг
осуществляется, в основном, в
рамках компьютерной сети
Интернет, доступ к услугам которой
осуществляется через сети связи.
8.
Развитие инфокоммуникационныхуслуг требует решения задач
эффективного управлении
информационными ресурсами с
одновременным расширением
функциональности сетей связи.
Это стимулирует процесс
интеграции Интернет и сетей связи.
9.
Глобальная сеть Internet являетсячастным случаем IP-сети.
Под IP-сетью подразумевается
сеть, построенная на базе стека
протоколов TCP/IP, который
позволяет создавать как небольшие
локальные, так и глобальные сети.
10.
Корпоративная IP-сеть,построенная с применением
интернет-сервисов для внутреннего
пользования, называется Intranet.
11.
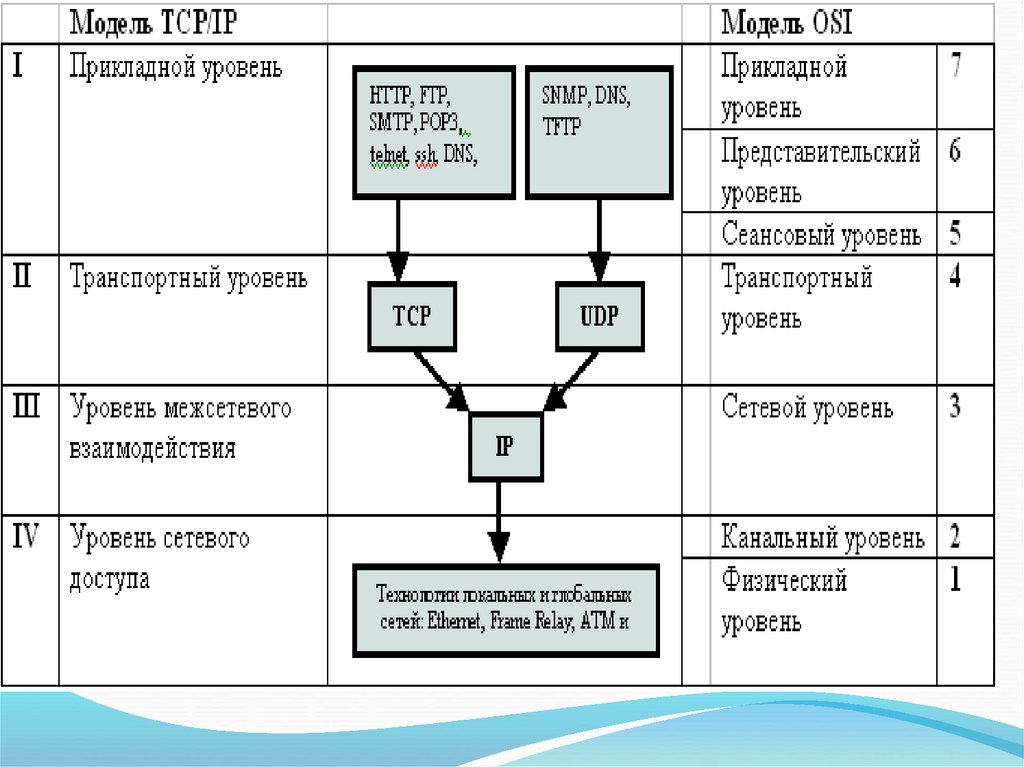
12. Уровень IV – уровень сетевого доступа (network access layer) соответствует физическому и канальному уровням модели OSI. Уровень
Уровень IV – уровень сетевого доступа (networkaccess layer) соответствует физическому и канальному
уровням модели OSI.
Уровень III - уровень межсетевого взаимодействия
(internetwork layer)соответствует сетевому уровню
модели OSI. На этом уровне находится
маршрутизируемый протокол IP.
Уровень II - транспортный уровень (transport
layer) соответствует транспортному уровню модели
OSI. На транспортном уровне находится протоколы
UDP и TCP, обеспечивающий надёжную доставку.
13. Уровень I - прикладной уровень (application layer) выполняет функции трёх верхних уровней модели OSI. Протоколы прикладного
Уровень I - прикладной уровень (applicationlayer) выполняет функции трёх верхних уровней
модели OSI. Протоколы прикладного уровня
обеспечивают работу интернет-служб, таких как
www, ftp и др. Прикладные протоколы используют
TCP и UDP в качестве транспортных протоколов
14. Порядок инкапсуляции : сегмент->пакет->фрейм
Порядок инкапсуляции : сегмент->пакет->фрейм15. IP-адресация V.4
IP-адрес является 32- битовымчислом, уникально
идентифицирующим компьютер в
IP-сети.
IP-адрес состоит из 2-х частей:
номер сети и номер компьютера
(хоста) в этой сети.
16.
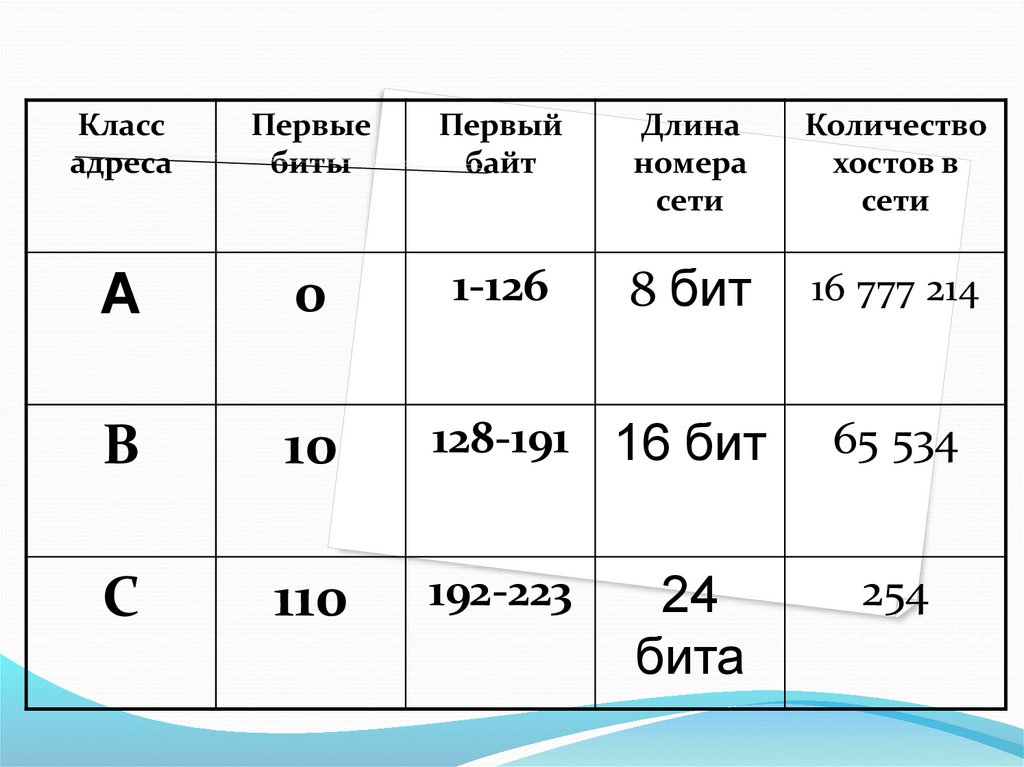
В адресах класса A 8 бит отводится наномер сети, 24 бита на номер хоста.
В адресах класса B 16 бит отводится на
номер сети, 16 бит на номер хоста.
В адресах класса C 24 бита отводится
на номер сети, 8 бит на номер хоста.
Также существует класс D,
используемый для группового вещания
(мультикастинга), и зарезервированный
класс E, в настоящее время не
используемый
17.
IP-адрес в двоичном виде 11001000011100100000011000110010Побайтовое разбиение 11001000 01110010 00000110 00110010
Десятичный эквивалент
200
114
6
50
IP-адрес в точечно-десятичной нотации 200.114.6.50
18.
В IP-адресах класса A первый битвсегда равен 0.
В IP-адресах класса B первые два
бита всегда равны 10.
В IP-адресах класса C первые три
бита всегда равны 110.
В IP-адресах класса D первые
четыре бита всегда равны 1110.
19.
Классадреса
Первые
биты
Первый
байт
Длина
номера
сети
Количество
хостов в
сети
A
0
1-126
8 бит
16 777 214
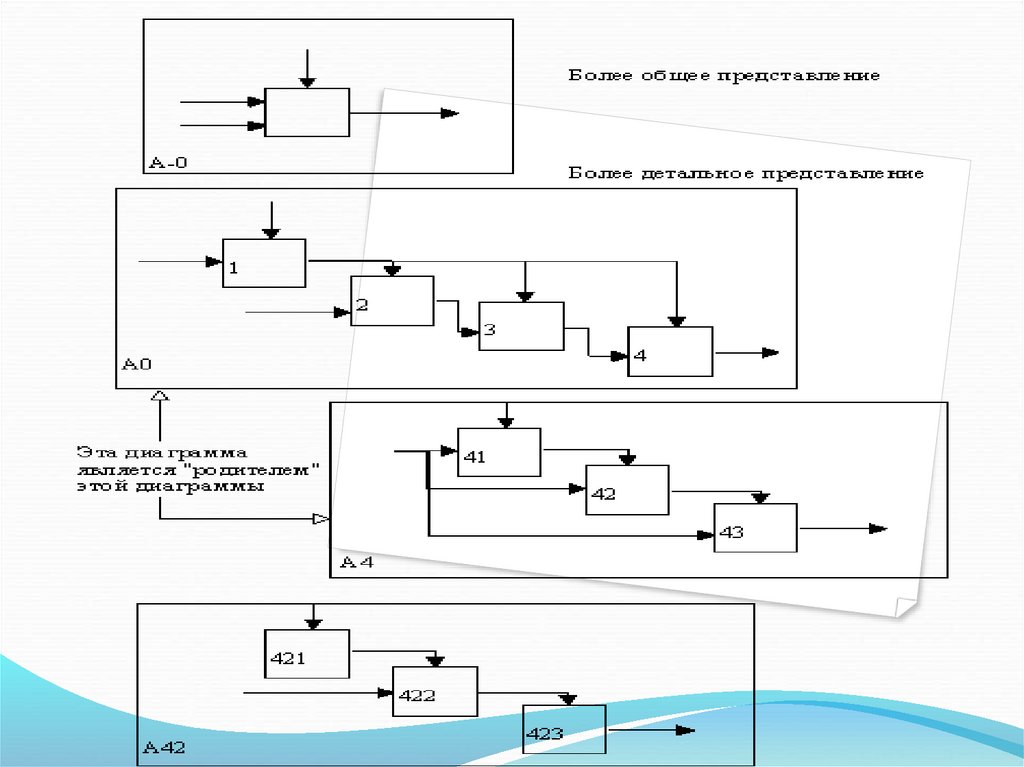
B
10
128-191 16 бит
65 534
C
110
192-223
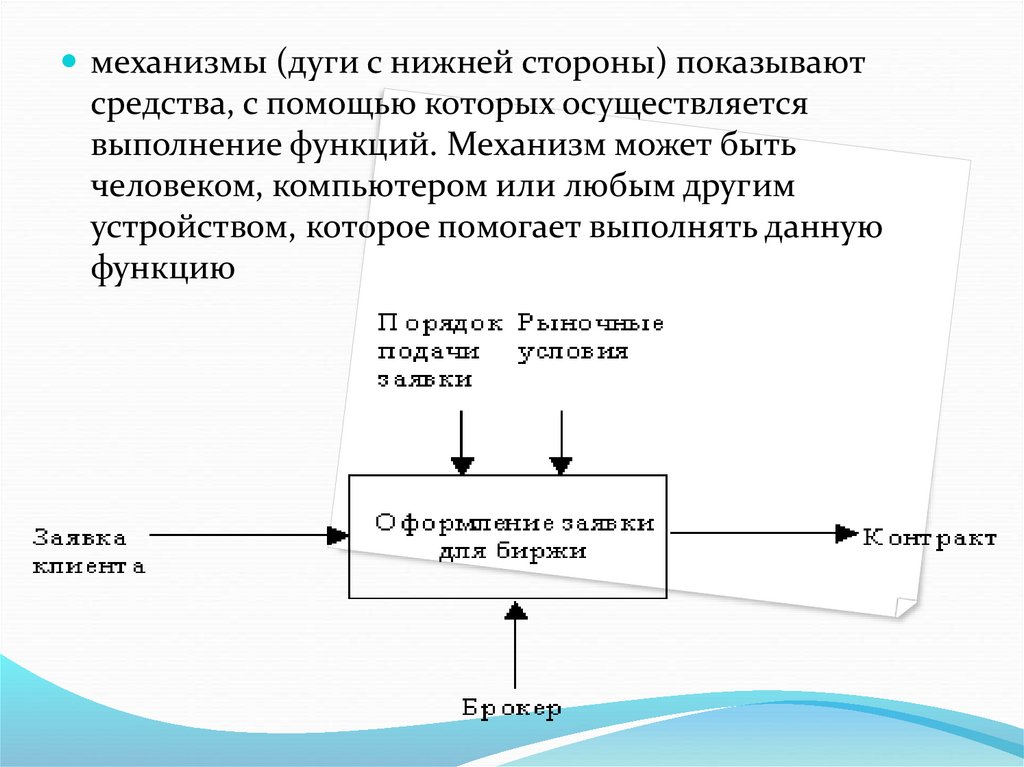
254
24
бита
20. Зарезервированные IP-адреса
Адрес сети – это IP-адрес, в котором номерхоста заполнен одними нулями, например
адрес 10.0.0.0. Адреса сетей используются
маршрутизаторами для составления таблиц
маршрутизации
Широковещательный адрес – это IP-адрес, в
котором номер хоста заполнен одними
единицами.
Например, для сети 10.0.0.0 широковещательный адрес будет
10.255.255.255. Пакеты с адресом 10.255.255.255 должны быть
доставлены всем компьютерам в сети 10.0.0.0.
IP-сети поддерживают ограниченное широковещание, т.е. можно
послать широковещательный пакет какой-то определённой сети,
но на всю интерсеть широковещательный пакет отправить
нельзя.
21.
Таким образом, в любой сети всегда 2 адресазарезервированы – это адрес сети, а также
широковещательный адрес для этой сети.
IP-адреса между адресом сети и
широковещательным адресом являются
диапазоном адресов, которые могут назначаться
хостам этой сети. Например, для сети 10.0.0.0
диапазон адресов хостов будет
10.0.0.0. -10.255.255.254.
Сеть 0.0.0.0 зарезервирована для специального
применения – задания маршрутов по умолчанию.
Поэтому адреса сети 0.0.0.0 нельзя использовать
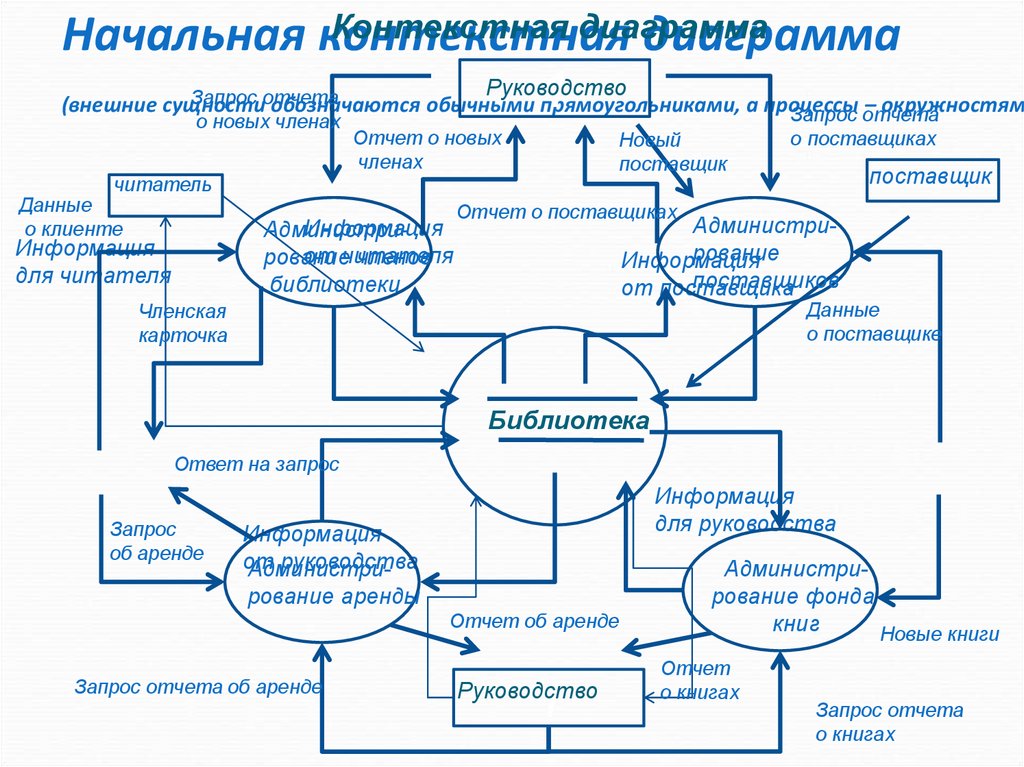
для адресации хостов.
22.
Сеть 127.0.0.0 зарезервирована длятестирования работоспособности протокола
IP. Все адреса сети 127.0.0.0 – это адреса
петли обратной связи для компьютера с
поддержкой IP. Т.о., IP-пакет, адресованный на
любой адрес из сети 127.0.0.0, будет
отправлен самому себе.
Адрес 255.255.255.255 это
широковещательный адрес для сети, в
которой находится отправитель пакета. Пакет,
направленный по этому адресу, должен быть
разослан всем компьютерам, находящимся в
одной сети с отправителем.
23. Распределение адресного пространства в сети Internet
в Европе - RIPE http://www.ripe.netRIPE передаёт IP-адреса Internet-провайдерам во
временное пользование на платной основе, а те в
свою очередь распределяют IP-адреса между
своими клиентами
24.
Для оптимизации имеющегосяадресного пространства можно
осуществлять деление сетей на
подсети, а также использовать частные
(private) диапазоны IP-адресов для
адресации в корпоративных сетях.
25. Деление сетей на подсети
26.
Номер хоста должен состоять какминимум из 2-х бит.
Номер подсети может состоять из
одного бита.
27. Маска подсети
Маска подсети является 32-х битнымчислом, при помощи которого можно
определить, сколько бит отводится на
подсеть.
Те биты маски подсети, которые
соответствуют номеру сети и номеру
подсети, заполняются единицами.
Биты, соответствующие номеру хоста,
заполняются нулями.
28.
Таким образом, класс IP-адресаопределяет количество бит, отводимых
на номер сети, а маска подсети
позволяет определить суммарное
количество бит, отводимых на номер
подсети и на номер сети.
29.
Маска подсети записывается в двух формах: или в точечно-десятичной нотации, или в виде количества бит, отводимых
суммарно на сеть и подсеть. Например, IP-адрес 195.1.1.66 с
маской 255.255.255.240 соответствует записи 195.1.1.66/28.
Запишем маску длиной 28 бит в десятично-точечной нотации:
11111111 11111111 11111111 11110000
255 255 255 240
30.
Таким образом, маска подсетидлиной 28 бит в десятичноточечной нотации выглядит как
255.255.255.240
31.
Зная класс IP-адреса и маску подсети,легко определить количество бит,
отводимых на номер хоста и на номер
подсети, а также определить, разбита ли
сеть на подсети. Например, 195.1.1.66/28
означает, что для адреса класса C длина
маски составляет 28 бит, т.е на сеть и
подсеть суммарно отводится 28бит.
Поскольку номер сети класса C занимает
24 бита, следовательно, в
рассматриваемом примере 4 бита
отводится на номер подсети.
32. Формат IP-пакета
33. Формат IP-пакета
10
2
3
4
5
VERS
7
8
9
1
0
HLEN
1
1
1
2
1
3
1
4
1
5
1
6
1
7
TTL
1
8
1
9
2
0
TOS
Flags
Protocol
2
2
2
3
2
4
2
5
2
6
2
7
2
8
2
9
Fragment offset
Header checksum
3
Source IP-address
4
Destination IP-address
5
2
1
Total lengnh
Identificatijn
1
2
6
Орtions
Padding
6
DATA
7
…
3
0
3
1
3
2
34.
Протокол IP версии 4 являетсямаршрутизируемым дейтаграммным
протоколом сетевого уровня
Перед отправкой пакета получатель не
уведомляется, при этом доставка пакета
не гарантируется и утерянный пакет
повторно не передаётся.
Если пакет получен, то отправитель также
не уведомляется.
Для обеспечением надёжной доставки
используется протокол TCP, также
надёжность может быть обеспечена на
прикладном уровне
35.
36.
Версия (Version)- 4-х битовое поле, в которомсодержится номер версии IP-протокола.
Длина заголовка (IP header length - HLEN) -4-х
битовое поле, в котором содержится длина
заголовка, измеренная в 32-битных словах.
Тип сервиса (Type-of-service - TOS)- 8-битовое
поле, используемое для управления QoS.
Длина пакета (Total length) – 16-битовое поле,
содержащее общую длину пакета, включая
заголовок и поле данных. Максимальная длина
пакета 65535 байт.
37.
Идентификация (Identification)– 16-битовое поле,используемое для управления фрагментацией.
Для каждого последующего отправляемого пакета
поле Identification увеличивается на 1. При
достижении максимального значения Identification
значение, следующее за максимальным равно 0,
после чего для каждого последующего пакета
снова осуществляется увеличение поля
Identification на 1.
Флаги (Flags) – 3-битовое поле, используемое для
управления фрагментацией.
Смещение фрагмента (Fragment offset) –
13 – битовое поле, используемое для управления
фрагментацией
38.
Время жизни пакета (Time-to-live - TTL)При прохождении пакета через
маршрутизатор время жизни уменьшается на
1. Если время жизни обнуляется,
маршрутизатор удаляет пакет и посылает
отправителю пакета соответствующее ICMPсообщение.
(Protocol). Содержит код протокола, данные
которого содержатся в поле данных IP-пакета.
Kонтрольная сумма заголовка(Header
checksum) – 16 бит. Позволяет определить
повреждён ли заголовок пакета.
IP-адрес отправителя (Source address) – 32
бита.
IP-адрес получателя (Destination address)–
32 бита.
39.
Опции (Options) – используется длянекоторых служебных целей.
(Padding). Поле переменной длины. Если
заголовок кратен 32 битам, поле не
используется. Если заголовок пакета не
кратен 32 битам, это поле заполняется
нулями, при этом длина поля выбирается так,
чтобы заголовок был кратен 32 битам.
Поле данных (Data) – содержит блок данных
протокола, который использует IP-пакет. Чаще
всего в поле данных содержится сегмент TCP
или UDP.
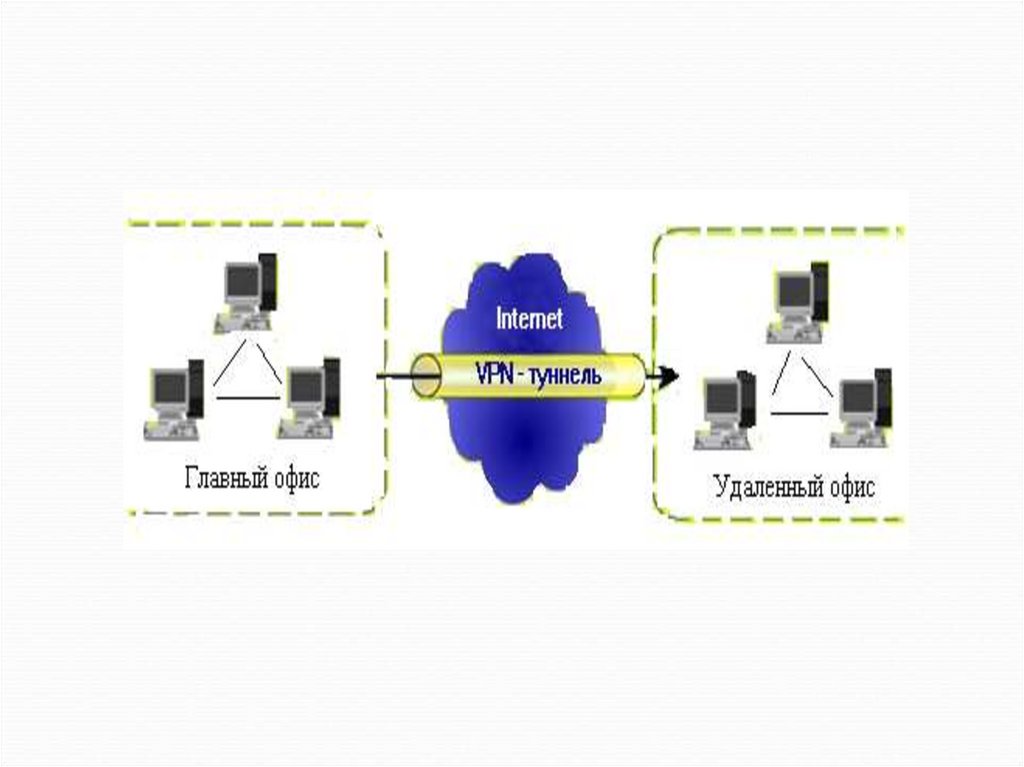
40. Виртуальная частная сеть – VPN
VPN (Virtual Private Networks) - корпоративныесистемы связи, построенные на сетях сторонних
операторов.
Чтобы объединить географически
распределенные офисы и подразделения,
заказчику не требуется создавать собственную
телекоммуникационную инфраструктуру или
арендовать каналы связи.
VPN действует поверх физических линий связи именно поэтому такая корпоративная сеть
называется виртуальной.
http://prezi.com/kjvwd39npx8x/?utm_campaign=
share&utm_medium=copy
41.
Широкое развитие Internet делает удобным егоиспользование в качестве среды передачи
информации между удалёнными филиалами
предприятия, позволяет организовать совместную
деятельность сотрудников компании, её деловых
партнёров и клиентов. При этом пользователи
сети могут получить доступ по Internet к
корпоративным базам данных, пересылать
электронную почту или использовать приложения
для коллективной работы.
42.
В сети функционируют любые системы,поддерживающие IP - Интернет протокол подавляющее большинство существующих
приложений, используемых на предприятии (базы
данных, электронная почта, телефония,
видеоконференция, каналы телевидения,
системы электронных торгов, системы охраны и
безопасности). При этом в IP-VPN, в отличие от
публичных сетей, гарантируются параметры
качества связи (Quality of Service).
43.
Данные, передаваемые по виртуальным частнымсетям, должны оставаться конфиденциальными и
должны быть защищены в процессе передачи
через Интернет. В виртуальных частных сетях
такая защита обеспечивается шифрованием
пакетов данных и созданием виртуального
"туннеля" через Internet, к которому не имеют
доступа посторонние системы или пользователи.
Туннелирование (tunneling) или инкапсуляция
(encapsulation) - это способ передачи полезной
информации через промежуточную сеть.
Такой информацией могут быть кадры (или
пакеты) другого протокола.
44.
При инкапсуляции кадр не передается всгенерированном узлом-отправителем виде, а
снабжается дополнительным заголовком,
содержащим информацию о маршруте,
позволяющую инкапсулированным пакетам
проходить через промежуточную сеть (Internet).
Инкапсуляция обеспечивает
мультиплексирование нескольких транспортных
протоколов по одному каналу. На конце туннеля
кадры деинкапсулируются и передаются
получателю. Логический путь передвижения
инкапсулированных пакетов в транзитной сети
называется туннелем.
45.
46.
Такой виртуальный канал имеет следующиеосновные особенности:
приватность – невозможно увидеть между какими
ресурсами устанавливается соединение через
VPN;
безопасность - нет доступ к информации, которая
транслируется по VPN;
аутентификация - доступ в VPN требует
авторизации.
47.
информация передается в зашифрованном виде.Прочитать полученные данные может лишь
обладатель ключа к шифру.
Наиболее часто используемым алгоритмом
кодирования является Triple DES(Data Encryption
Standard)- стандарт шифрования данных,
который обеспечивает тройное шифрование (168
разрядов) с использованием трех разных ключей.
Подтверждение подлинности включает в себя
проверку целостности данных и идентификацию
пользователей, задействованных в VPN. Первая
гарантирует, что данные дошли до адресата
именно в том виде, в каком были посланы. Далее
система проверяет, не были ли изменены данные
во время движения по сетям, по ошибке или
злонамеренно.
48.
Клиентский компьютер устанавливает спровайдером стандартное соединение типа
«точка - точка» , после чего подключается через
Интернет к центральному узлу. При этом
формируется канал VPN, представляющий собой
«туннель», по которому можно производить
обмен данными между двумя конечными узлами.
Этот туннель «непрозрачен» для всех остальных
пользователей, включая провайдера.
Для построения VPN необходимо иметь на обоих
концах линии связи программы шифрования
исходящего и дешифрования входящего
трафиков. Они могут работать как на
специализированных аппаратных устройствах,
так и на ПК- периферийных компьютерах с
такими операционными системами как Windows,
Linux или NetWare
49.
Виртуальная телефонная сеть - это объединениенескольких территориально распределенных
телефонных сетей в единую сеть с единым
планом нумерации. При этом телефоны
виртуальной сети имеют единую нумерацию, как
будто они подключены к одной учрежденческой
телефонной станции (УАТС). В качестве основной
транспортной среды для IP VPN операторы могут
использовать: волоконно-оптические каналы,
"медные" пары, беспроводные радиоканалы,
спутниковые каналы.
50. VPN на основе IP протокола
51. Пример построения корпоративной сети IP VPN
52. Варианты построения сети VPN
1. Вариант "Intranet VPN", позволяетобъединить в единую защищенную сеть
несколько распределенных филиалов одной
организации, взаимодействующих по открытым
каналам связи. Именно этот вариант получил
широкое распространение во всем мире, и
именно его в первую очередь реализуют
компании-разработчики.
53.
2. Вариант "Remote Access VPN", который позволяетреализовать защищенное взаимодействие между сегментом
корпоративной сети (центральным офисом или филиалом) и
одиночным пользователем, который подключается к
корпоративным ресурсам из дома (домашний пользователь)
или через notebook (мобильный пользователь).
Данный вариант отличается от первого тем, что
удаленный пользователь, как правило, не имеет
статического адреса, и он подключается к защищаемому
ресурсу не через выделенное устройство VPN, а прямиком
со своего собственного компьютера, на котором и
устанавливается программное обеспечение, реализующее
функции VPN. Компонент VPN для удаленного пользователя
может быть выполнен как в программном, так и в
программно-аппаратном виде.
В первом случае программное обеспечение может
быть как встроенным в операционную систему (например, в
Windows 2000), так и разработанным специально.
Во втором случае для реализации VPN используются
небольшие устройства класса SOHO (Small Office\Home
Office), которые не требуют серьезной настройки.
54.
3. Вариант "Client/Server VPN", которыйобеспечивает защиту передаваемых данных
между двумя узлами (не сетями) корпоративной
сети. Особенность данного варианта в том, что
VPN строится между узлами, находящимися в
одном сегменте сети, например, между рабочей
станцией и сервером. Такая необходимость
часто возникает в тех случаях, когда в одной
физической сети необходимо создать несколько
логических сетей. Например, когда надо
разделить трафик между финансовым
департаментом и отделом кадров,
обращающихся к серверам, находящимся в
одном физическом сегменте. Этот вариант
похож на технологию VLAN- Virtual Local Area
Network, виртуальных локальных сетей. Но
вместо разделения трафика, используется его
шифрование.
55.
4. "Extranet VPN" предназначен для тех сетей, ккоторым подключаются так называемые
пользователи "со стороны" (партнеры, заказчики,
клиенты), уровень доверия к которым намного
ниже, чем к своим сотрудникам.
56. Вариант построения Extranet VPN
57.
Среди технологий построения VPN можноназвать такие технологии, как:
IPSec VPN Internet Protocol Security - протокол
для защищённого обмена в сети Internet,
MPLS VPN Multiprotocol Label Switching многопротокольная коммутация меток,
VPN на основе технологий туннелирования
PPTP и
L2TP Layer-2 Tunneling Protocol - протокол
туннелирования уровня 2 (канального уровня).
Во всех перечисленных случаях трафик
посылается в сеть провайдера по протоколу IP,
что позволяет провайдеру оказывать не только
услуги VPN, но и различные дополнительные
сервисы (контроль за работой клиентской сети,
хостинг Web и почтовых служб, хостинг
специализированных приложений клиентов).
58. Технология IPSec VPN
IP Security - это комплект протоколов,позволяющих обеспечить шифрование,
аутентификацию и обеспечить защиту при
транспортировке IP-пакетов.
IPSec действует на сетевом уровне,
обеспечивая защиту и аутентификацию пакетов
IP, пересылаемых между устройствами
(сторонами) IPSec - такими как маршрутизаторы,
клиенты и концентраторы VPN.
59. формат кадра протокола IPSec
Исходныйпакет
Заголовок
IP
Защищаемые
данные
Шифруемые данные
ESP
Заголовок
IP
Заголовок Защищенные
Хвост ESP
данные
ESP
Аутентифицируемые данные
АН
Заголовок
IP
Заголовок Защищенные
данные
АН
Аутентифицируемые данные
60.
В пакетах ESP-Encapsulation Security Payload -инкапсуляция защищенных данных и AH-Authentication Header аутентифицирующий заголовок , между заголовком IP (IP
header) и данными протокола верхнего уровня вставляется
заголовок ESP/AH (ESP/AH header).
ESP может обеспечивать как защиту данных, так и
аутентификацию, а также возможен вариант протокола ESP
без использования защиты данных или без аутентификации.
Однако, невозможно использовать протокол ESP одновременно
без защиты данных и без аутентификации, поскольку в данном
случае безопасность не обеспечивается. При
осуществлении защиты передаваемых данных заголовок ESP
не защищен, но защищены данные протокола верхнего уровня
и часть трейлера ESP.
А в случае аутентификации производится аутентификация
заголовка ESP, данных протокола верхнего уровня и части
трейлера ESP.
61. Как работает IPSec
Маршрутизатор АХост А
Маршрутизатор В
Поток данных к
хосту В
Шаг 1
Шаг 2
Ассоциация IKE
Фаза 1IKE
Ассоциация IKE
Шаг 3
Ассоциация IPSec
Фаза 2 IKE
Ассоциация IPSec
Шаг 4
Шаг 5
Туннель IPSec
Завершение работы туннеля IPSec
Хост В
62.
Шаг 1. Начало процесса IPSec. Трафик,которому требуется шифрование в соответствии
с политикой защиты IPSec, согласованной
сторонами IPSec, начинает IКЕ - Internet Key
Exchange процесс интернет-обмена ключами
Шаг 2. Первая фаза IKE. IKE-процесс
выполняет аутентификацию сторон IPSec и
ведет переговоры о параметрах ассоциаций
защиты IKE, в результате чего создается
защищенный канал для ведения переговоров о
параметрах ассоциаций защиты IPSec в ходе
второй фазы IKE.
Шаг 3. Вторая фаза IKE. IKE-процесс ведет
переговоры о параметрах ассоциации защиты
IPSec и устанавливает соответствующие
ассоциации защиты IPSec для устройств
сообщающихся сторон.
63.
Шаг 4. Передача данных. Происходит обменданными между сообщающимися сторонами
IPSec, который основывается на параметрах
IPSec и ключах, хранимых в базе данных
ассоциаций защиты.
Шаг 5. Завершение работы туннеля IPSec.
Ассоциации защиты IPSec завершают свою
работу либо в результате их удаления, либо по
причине превышения предельного времени их
существования.
64. VPN на основе туннелирования через IP
В VPN на основе туннелирования входят всетехнологии для образования VPN, которые
используют туннели через IP-сети. Применение
туннеля позволяет изолировать адресное
пространство клиента, что в свою очередь дает
клиенту возможность переносить
незашифрованный трафик (L2TP) или шифровать
его (PPTP).
65. Протокол PPTP (Point-to-Point Tunneling Protocol)
Протокол PPTP (Point-to-Point TunnelingProtocol)
Протокол PPTP устанавливается автоматически
вместе с протоколом TCP/IP -Transmission Control
Protocol/Internet Protocol протокол управления
передачей.
Главными функциями протокола PPTP и метода
MPPE (Microsoft Point-to-Point Encryption) при
работе с VPN являются инкапсуляция и
шифрование личных данных.
Кадр PPP (IP- или IPX-датаграмма) заключается в
оболочку с заголовком GRE- Generic Routing
Encapsulation - общая инкапсуляция маршрутов.
IP-заголовок содержит IP-адреса источника и
приемника, которые соответствуют VPN-клиенту
и VPN-серверу.
66. Шифрование и инкапсуляция кадра PPP протоколом PPTP
67. Структура данных для пересылки по туннелю PPTP
68.
Клиенты виртуальных частных сетей должныиспользовать для шифрования полезных данных
PPP протокол. PPTP не предоставляет средств
шифрования, а использует средства,
предоставляемые протоколом PPP, и
инкапсулирует предварительно зашифрованный
кадр PPP. Хотя PPTP обеспечивает достаточную
степень безопасности, но все же L2TP поверх
IPSec надежнее. L2TP поверх IPSec обеспечивает
аутентификацию на уровнях 'пользователь' и
'компьютер', а также выполняет аутентификацию и
шифрование данных.
69. Протокол L2TP (Layer Two Tunneling Protocol)
Кадры РРРИнформационное
сообщение L2TP
Управляющее
сообщение L2TP
Канал данных L2TP Канал управления L2TP
Транспорт для передачи пакетов
70.
Инкапсуляция данных происходит путемдобавления заголовков L2TP и IPSec к
данным, обработанным протоколом PPP.
Шифрование данных достигается путем
применения алгоритма DES (Data Encryption
Standard) или 3DES.
Протокол L2TP является промышленным
туннельным протоколом Интернета стандарта
IETF (Internet Engineering Task Force – рабочая
группа по стандартам для сети Internet).
Комбинация L2TP и IPSec известна как
L2TP/IPSec.
71.
Протоколы L2TP и IPSec должны поддерживатьсякак VPN-сервером, так и VPN-клиентом.
Протокол L2TP устанавливается автоматически
вместе со службой маршрутизации и удаленного
доступа (Routing and Remote Access service).
Главными функциями L2TP/IPSec при работе с
VPN являются инкапсуляция и шифрование
личных данных. Инкапсуляция пакетов L2TP
поверх IPSec выполняется в два этапа. В
качестве среды передачи данных между VPNклиентом и VPN-сервером удаленного доступа
может выступать любая сеть на основе протокола
TCP/IP, чаще всего является сеть Интернет.
72. Технология MPLS VPN
Один из основных принципов работы сети IPMPLS заключается в автоматическом связывании
всех сетей в одно целое за счет распространения
по сети маршрутной информации протоколами
маршрутизации, такими как BGP - Border Gateway
Protocol - протокол динамической
маршрутизации, OSPF - Open Shprtest Path First иерархический протокол маршрутизации, IS-IS Intermediate System-to-Intermediate System - связь
между промежуточными системами, RIP - Routing
Information Protocol - протокол маршрутизации.
73.
На каждом маршрутизаторе сети создаетсятаблица маршрутизации, в которой указываются
пути следования пакетов к каждой из сетей,
включенных в составную сеть
Сети VPN на базе MPLS разделяют на два
широких класса - сети, которые работают на 3-м
уровне, и сети, работающие на 2-м уровне.
В сетях MPLS L3VPN доставка трафика от
клиента до пограничного устройства сети
поставщика услуг осуществляется с помощью
технологии IP.
Сети MPLS L2VPN передают клиентский трафик
в сеть поставщика услуг с помощью какой-либо
технологии второго уровня, которой может быть
Ethernet, Frame Relay или ATM.
74. MPLS L3 VPN
MPLS позволяет создавать виртуальные частныесети Layer 3, не прибегая к туннелированию и
шифрованию (IPsec).
MPLS VPN сеть делится на две области: IP сети
клиентов и магистраль провайдера.
Классическая конструкция MPLS L3 VPN состоит
из следующих компонентов:
пограничные маршрутизаторы провайдера PE(Provider Edge router),
обращенные к клиентскому оборудованию CE(Customer Edge router),
соединеные между собой Р-(Provider router)
маршрутизаторы в MPLS домене.
75.
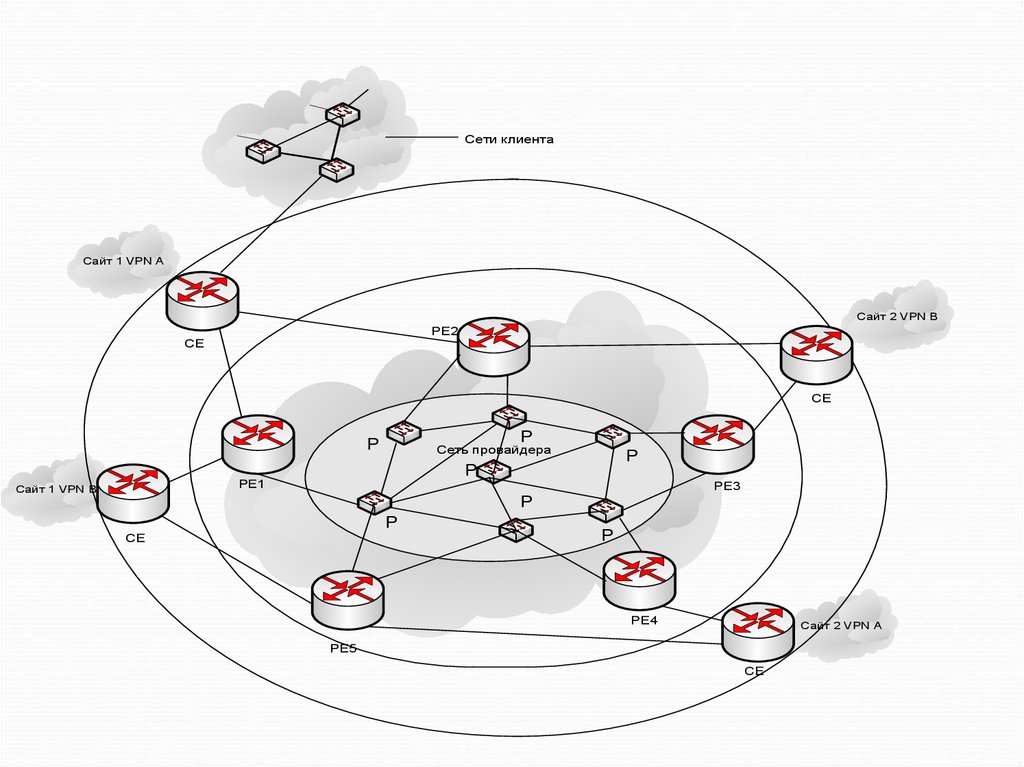
Сети клиентаСайт 1 VPN A
Сайт 2 VPN B
PE2
CE
CE
P
P
Сеть провайдера
P
P
PE1
Сайт 1 VPN B
PE3
P
P
CE
P
PE4
Сайт 2 VPN A
PE5
CE
76.
MPLS L3 VPN инфраструктура предполагаетобеспечение изоляции распределенных
клиентских IP сетей в рамках VPN.
То есть обеспечивается только обмен пакетами
между IP сетями одной VPN.
В терминах MPLS VPN отдельное CE
подключение называется сайтом.
Каждый сайт представляет собой отдельную
клиентскую подсеть, входящую в VPN структуру.
Каждая VPN логически связана с одним или
более комплексов маршрутизации и пересылки
(VPN Routing and Frowarding instance – VRF).
VRF определяет членство в VPN подсети за
узлом CE, подключенного к PE. Интерфейсы PE
маршрутизаторов, обращенные к CE, логически
связаны с индивидуальными VRF.
77.
VRF состоит из таблицы маршрутизации (IPv4),получаемого из нее набора интерфейсов,
использующих VRF и других данных.
VRF таблицы IP маршрутизации используются
для обмена информацией о маршрутах только
внутри VPN сети и не выходят за границу VPN, то
есть извне невозможно послать пакет на
маршрутизатор, находящийся внутри VPN (этот
маршрут попросту неизвестен).
В итоге VRF представляет собой виртуальный
маршрутизатор quot внутри PE.
78.
В рамках MPLS L3 VPN в VPN включается IPv4клиентские подсети.
В пределах одной VPN не допускаются
пересекающиеся IPv4 адреса.
Однако в разных VPN это допустимо.
Отсюда потенциальная неоднозначность для PE
маршрутизатора: разные VRF могут содержать
одинаковые IPv4 адреса.
Для получения уникальных адресов (и
соответственно маршрутов), называемых VPNIPv4, используется идентификатор VPN-Route
Distinguisher (RD).
VPN-IPv4 получается добавлением к IPv4
идентификатора RD.
В итоге PE оперирует уникальными VPN-IPv4.
79.
Для обмена маршрутной информацией междуVRF разных PE используется MP-BGP протокол.
MP-BGP оперирует VPN-IPv4 маршрутами. Таким
образом, с помощью MP-BGP получается
виртуальная связь между PE (между VRF
одинаковых VPN). Для выполнения политики
экспорта/импорта дополнительно вводится
понятие адресата маршрута - Route Target (RT).
80.
Каждый клиентский сайт (интерфейс на PE)имеет свою VRF (таблицу IPv4 маршрутизации).
PE может узнать IP префикс клиента разными
способами (статическая конфигурация, BGP, RIP,
OSPF, IS-IS). PE помещает IPv4 маршрут клиента
в VRF данного сайта. Кроме того, с помощью
заранее выбранного идентификатора VPN, в
которые входит данный сайт, IPv4 маршруты
(префиксы) преобразуются в VPN-IPv4 маршруты
и помещаются в MP-BGP. MP-BGP согласно
политике импорта/экспорта связывает между
собой все PE маршрутизаторы (их VRF). В итоге
в VRF разных PE, но принадлежащих одной VPN,
попадают все маршруты из данной VPN.
81.
Реальная передача пакетов (коммутация)происходит при помощи MPLS.
MPLS метки используются следующим образом:
пакет содержит два уровня меток (используется
стек).
Первая метка направляет пакет к требуемому PE
(next hop), а вторая указывает комплекс VRF,
логически связанный с выходным интерфейсом
CE маршрутизатора пункта назначения.
82. MPLS L2 VPN
Для создания VPN Layer 2 по схеме точка-точка(point-to-point) разработана технология Any
Transport Over MPLS (AToM), обеспечивающая
передачу Layer 2 фреймов через MPLS сеть.
AToM – это интегральная технология,
включающая Frame Relay over MPLS, ATM over
MPLS, Ethernet over MPLS.
83.
AToM использует непосредственные сессиимежду граничными маршрутизаторами
провайдерской сети (PE) для установления и
поддержки соединений.
Непосредственное продвижение пакетов
происходит с использованием стека меток MPLS,
когда одна метка соединяет граничные
маршрутизаторы, а вторая– определяет
непосредственно VPN клиента (интерфейс на PE
маршрутизаторе).
84.
Наиболее востребованной в настоящее времяявляется технология Ethernet over MPLS
(EoMPLS).
EoMPLS инкапсулирует Ethernet фреймы в MPLS
пакеты и использует стек меток для продвижения
через MPLS сеть. На каждом PE-CLE (Customet
Leading Edge) организуется Virtual Circuit (VC).
Непосредственно передача пакетов использует
стек меток.
Верхняя метка (Top Label), называемая еще
Tunnel Label, используется для достижения
выходного (Egress) PE-CLE.
85.
Нижняя метка (Bottom Label), называемая VCLabel, используется для определения
интерфейса на PE-CLE. VC Label
обеспечивается Egress PE-CLE для Ingress PECLE для направления трафика в нужный
интерфейс на Egress PE-CLE. VC Label
отождествляется с VC ID и устанавливается на
этапе VC setup.
86.
В общем случае у каждого клиента может бытьнесколько территориально обособленных сетей
IP, каждая из которых в свою очередь может
включать несколько подсетей, связанных
маршрутизаторами. Такие территориально
изолированные сетевые «островки»
корпоративной сети принято называть сайтами.
Принадлежащие одному клиенту сайты
обмениваются пакетами IP через сеть провайдера
и образуют виртуальную частную сеть этого
клиента. Для обмена маршрутной информацией в
пределах сайта узлы пользуются одним из
внутренних протоколов маршрутизации (Interior
Gateway Protocol, IGP), область действия которого
ограничена автономной системой: RIP, OSPF или
IS-IS.
87.
Будучи компонентом сети клиента, CE ничего незнает о существовании VPN. Он может быть
соединен с магистральной сетью провайдера
несколькими каналами.
Магистральная сеть провайдера является сетью
MPLS, где пакеты IP продвигаются на основе не
IP-адресов, а локальных меток. Сеть MPLS
состоит из маршрутизаторов с коммутацией меток
(Label Switch Router, LSR), которые направляют
трафик по предварительно проложенным путям с
коммутацией меток (Label Switching Path, LSP) в
соответствии со значениями меток.
88.
Устройство LSR — это своеобразный гибридмаршрутизатора IP и коммутатора, при этом от
маршрутизатора IP берется способность
определять топологию сети с помощью
протоколов маршрутизации и выбирать
рациональные пути следования трафика, а от
коммутатора — техника продвижения пакетов с
использованием меток и локальных таблиц
коммутации.
Устройства LSR для краткости часто называют
просто маршрутизаторами, они с таким же
успехом способны продвигать пакеты на основе
IP-адреса, если поддержка MPLS отключена.
89.
В магистральной сети провайдера толькопограничные маршрутизаторы PE должны быть
сконфигурированы для поддержки виртуальных
частных сетей, поэтому только они «знают» о
существующих VPN.
Если рассматривать сеть с позиций VPN, то
маршрутизаторы провайдера P непосредственно
не взаимодействуют с маршрутизаторами
заказчика CE, а просто располагаются вдоль
туннеля между входным и выходным
маршрутизаторами PE
90.
Маршрутизаторы PE являются функциональноболее сложными, чем P. На них возлагаются
главные задачи по поддержке VPN, а именно
разграничение маршрутов и данных,
поступающих от разных клиентов.
Маршрутизаторы PE служат также оконечными
точками путей LSP между сайтами заказчиков, и
именно PE назначает метку пакету IP для его
транзита через внутреннюю сеть
маршрутизаторов P.
91.
В VPN применяется различная топология связей:полносвязная, «звезда» (часто называемая в
англоязычной литературе hub-and-spoke) или
ячеистая. Для корректной работы VPN требуется,
чтобы информация о маршрутах через
магистральную сеть провайдера не
распространялась за ее пределы, а сведения о
маршрутах в клиентских сайтах не становились
известными за границами определенных VPN.
Барьеры на пути распространения маршрутных
объявлений могут устанавливаться
соответствующим конфигурированием
маршрутизаторов.
Протокол маршрутизации должен быть оповещен
о том, с каких интерфейсов и от кого он имеет
право принимать объявления определенного
сорта и на какие интерфейсы и кому их
распространять.
92.
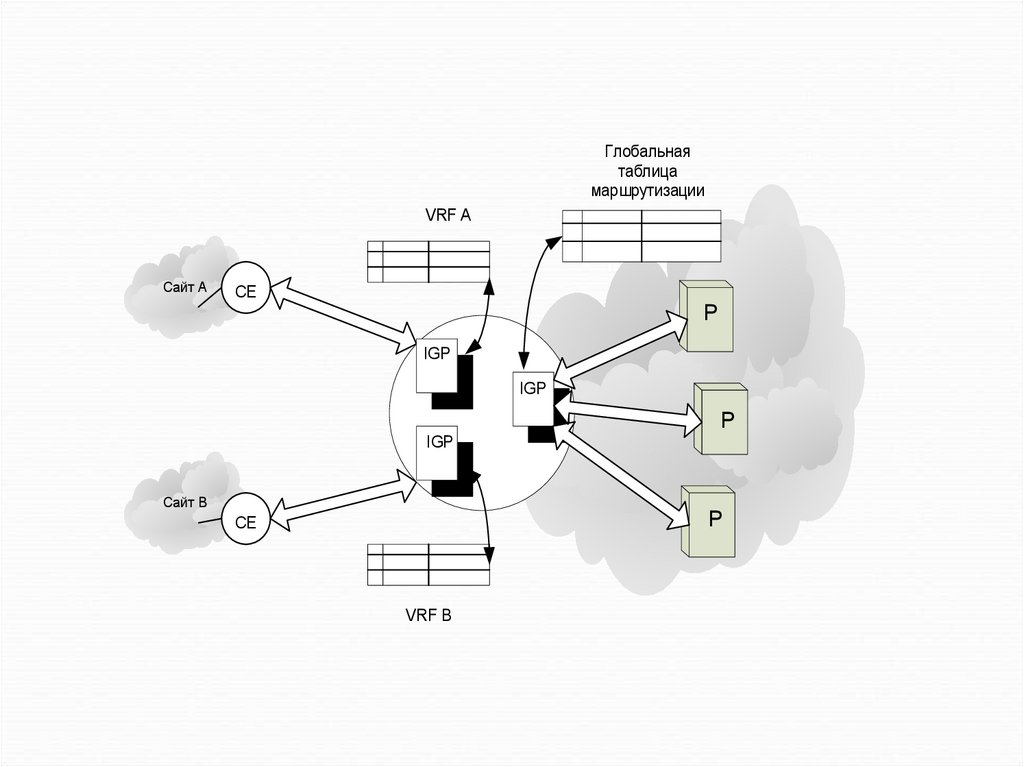
Глобальнаятаблица
маршрутизации
VRF A
Сайт A
СЕ
P
IGP
IGP
P
IGP
Сайт B
P
СЕ
VRF B
93.
Роль таких барьеров в сети MPLS VPN играютпограничные маршрутизаторы PE. Можно
представить, что через маршрутизатор PE
проходит невидимая граница между зоной
клиентских сайтов и зоной ядра сети провайдера.
По одну сторону располагаются интерфейсы,
через которые PE взаимодействует с
маршрутизаторами P, а по другую — интерфейсы,
к которым подключаются сайты клиентов. С одной
стороны на PE поступают объявления о
маршрутах магистральной сети, с другой стороны
— объявления о маршрутах в сетях клиентов.
Маршрутизатор PE, на котором установлены
несколько протоколов класса IGP
94.
Таблица маршрутизации, создаваемая напограничных маршрутизаторах PE на основе
объявлений из магистральной сети, имеет
специальное название «глобальная таблица
маршрутизации».
В отличие от нее таблицы, которые PE
формирует на основе объявлений, поступающих
из сайтов клиентов, получили название таблиц
VRF (VPN Routing and Forwarding, VRF), которые
PE формирует на основе объявлений,
поступающих из сайтов клиентов.
95.
На каждом PE создается столько таблиц VRF,сколько сайтов к нему подключено. Фактически на
маршрутизаторе PE организуется несколько
виртуальных маршрутизаторов, каждый из
которых работает со своей таблицей VRF.
Возможно и другое соотношение между сайтами и
таблицами VRF. На рисунке показаны две
таблицы VRF, одна из которых содержит описание
маршрутов к узлам сайта А, а другая — к узлам
сайта В. К каждой такой таблице можно получить
доступ только с сайтов, относящихся к этой же
VPN.
96.
97. CASE-технология анализа систем управления предприятий
Разработка сложных информационных систем(ИС) таких, какими являются ИС административноуправленческой деятельности предприятий
(организаций, учреждений и т.д.; в дальнейшем
ИС предприятий), невозможна без тщательно
обдуманного методологического подхода.
Какие этапы необходимо пройти, какие методы и
средства использовать, как организовать контроль
за продвижением проекта и качеством
выполнения работ - эти и другие вопросы
решаются методологиями программной
инженерии.
98.
В настоящее время существует ряд общихметодологий разработки ИС.
Главное в них - единая дисциплина работы на
всех этапах жизненного цикла системы, учет
критических задач и контроль их решения,
применение развитых инструментальных средств
поддержки процессов анализа, проектирования и
реализации ИС.
99.
Для различных классов систем используютсяразные методы разработки, определяемые типом
создаваемой системы и средствами реализации.
Спецификации этих систем, в большинстве
случаев, состоят из двух основных компонентов функционального и информационного.
По способу сочетания этих компонентов подходы
к представлению информационных систем можно
разбить на два основных типа –
структурный и
объектно-ориентированный.
100.
В области создания систем автоматизацииадминистративно-управленческой деятельности
доминируют структурные подходы, так как они
максимально приспособлены для
взаимодействия с пользователями (заказчиками),
не являющимися специалистами в области
информационных технологий.
Адекватными инструментальными средствами,
поддерживающими структурный подход к
созданию информационных систем, являются так
называемые CASE-системы автоматизации
проектирования.
101. Концептуальные основы создания ИС предприятия
Основополагающая концепциясостоит в построении совокупности логических
моделей предметной области при помощи
графических методов структурного анализа,
которые дали бы возможность пользователям,
аналитикам и разработчикам получить ясную
общую картину проекта, а также обеспечили бы
естественный переход к логической модели
будущей ИС.
102.
Объектом обсуждения являются методы иинструментальные средства, появившиеся в
результате развития дисциплины структурного
системного анализа, а также преимущества,
которые обеспечиваются применением указанных
методов и средств.
103.
Со многих точек зрения системный анализявляется наиболее трудной частью процесса
создания информационных систем.
Имеются в виду не только технические трудности
анализа, хотя многие проекты требуют, чтобы
аналитик обладал глубокими знаниями в области
современной технологии обработки данных.
И это не только политические трудности,
возникающие при разработке больших проектов,
в которых новая система будет обслуживать
несколько, возможно конфликтующих,
заинтересованных групп.
104.
Это не только проблемы, связанные снеобходимостью общения в условиях, когда
люди, обладающие разным уровнем образования
и различными взглядами на мир, должны
работать вместе.
Именно сочетание всех этих трудностей делает
системный анализ таким сложным и кропотливым
делом, имея в виду еще и тот факт, что аналитик
должен играть роль посредника между
заказчиком-пользователем и исполнителемразработчиком.
105.
Пользователи интуитивно понимают своипроблемы, но не могут объяснить их, и, кроме
того, имеют весьма туманное представление о
том, какую пользу могут принести
информационные технологии, основанные на
применении компьютеров.
Разработчики с энтузиазмом говорят о
существующих возможностях в области
построения систем обработки данных, но они не
имеют информации о том, что именно является
наилучшем для данного предприятия,
учреждения или организации.
106.
Аналитик должен выбрать золотую середину:выбрать, что является в настоящее время
возможным с точки зрения технологии обработки
данных, и что стоит делать для данного
конкретного предприятия.
107.
Осуществление такого выбора, который был быприемлемым для всех групп и выдержал бы
проверку временем, - наиболее
трудноразрешимая задача на этапе системного
анализа.
Если выполнить эту задачу наилучшим образом,
то независимо от того, насколько трудным
окажется проектирование и разработка,
созданная система будет удовлетворять
требованиям данного предприятия.
Если же задача будет выполнена
неудовлетворительно, то не имеет значения
насколько хорошо пройдет реализация, так как
созданная система не будет являться тем, что
действительно необходимо данному
предприятию, и затраты превзойдут полученные
преимущества
108.
Структурный анализ, как совокупность методовпостановки задач проектирования
информационных систем, в виду значительной
размерности решаемых задач, сам должен
опираться на мощные средства компьютерной
поддержки, обеспечивающей автоматизацию
труда системных аналитиков.
Такими средствами являются CASE-системы.
109.
За последние несколько лет сформировалось новоенаправление в программотехнике - CASE (Computer
Aided System/Software Engineering).
Хотя в настоящее время не существует общепринятого
определения CASE, и содержание этого понятия
обычно определяется перечнем решаемых задач, а
также совокупностью применяемых методов и средств,
грубо можно сказать, что CASE представляет собой
совокупность методологий анализа, разработки и
сопровождения сложных систем (в основном
заказных систем программного обеспечения АСУ),
поддержанную комплексом взаимосвязанных
средств автоматизации.
110.
CASE - это инструментарий для системныханалитиков и программистов, позволяющий
автоматизировать процессы анализа,
проектирования и реализации систем
111.
К настоящему моменту дисциплина CASEоформилась в самостоятельное наукоемкое
направление, повлекшее за собой образование
мощной CASE-индустрии, объединившей сотни фирм
различной ориентации. Среди них выделяются:
фирмы-разработчики средств анализа и
проектирования программного обеспечения;
фирмы-разработчики специальных CASE-средств,
ориентированных на узкие предметные области
применения или на отдельные этапы жизненного цикла
систем;
обучающие фирмы, организующие семинары и курсы
подготовки специалистов, оказывающие практическую
помощь при использовании CASE-систем для
разработки конкретных приложений;
фирмы, специализирующиеся на выпуске
периодических изданий по CASE-тематике
112.
Основными пользователями CASE-системявляются:
аналитические центры государственных, военных
и коммерческих организаций;
банки и страховые компании;
аудиторские и консалтинговые фирмы,
применяющие CASE-средства для спецификации
бизнес-процессов в системах управления
производством, коммерческой деятельностью и
финансами с целью их реорганизации и
автоматизации;
компании по разработке аппаратного и
программного обеспечения систем обработки
данных и, в частности, интегрированных
информационно-управляющих систем.
113.
CASE, наряду с системами визуальногопрограммирования, является наиболее
перспективным направлением в
программотехнике.
CASE - наиболее динамично развиваемое
направление.
Практически не один серьезный американский или японский
программный проект не осуществляется без использования
CASE-средств. Известная методология структурного
системного анализа SADT - Structured Analysis and Design
Technique (точнее ее подмножество IDEF0) принята в
качестве стандарта на разработку средств программного
обеспечения Министерством обороны США.
Среди менеджеров и руководителей компьютерных фирм
считается чуть ли не правилом хорошего тона знать основы
SADT и при обсуждении каких-либо вопросов нарисовать
простейшую диаграмму, поясняющую суть дела.
114.
Архитектура большинства CASE-средствоснована на парадигме "методология - метод нотация - средство".
Методология определяет критерии для оценки и
выбора проекта создаваемой системы, этапы
работы и их последовательность, а также
правила распределения и назначения методов.
Методы - это систематические процедуры,
применяемые для генерации описаний подсистем
и функциональных компонентов системы с
использованием соответствующих нотаций.
Нотации предназначены для представления
проектных данных о структуре системы и
способах ее функционирования, процессах,
информационных потоках, накопителях и т.д.
115.
Средства - инструментарий для поддержки иусиления методов.
Инструментальные средства поддерживают
работу аналитиков при реализации проекта в
сетевом интерактивном режиме, они
способствуют организации проекта,
обеспечивают управление процессами анализа и
проектирования.
116. Жизненный цикл ИС
Жизненный цикл - это модельсоздания и использования ИС,
отражающая ее различные состояния,
начиная с момента возникновения
необходимости в данном комплексе
средств и заканчивая моментом его
полного выхода из употребления у
пользователей
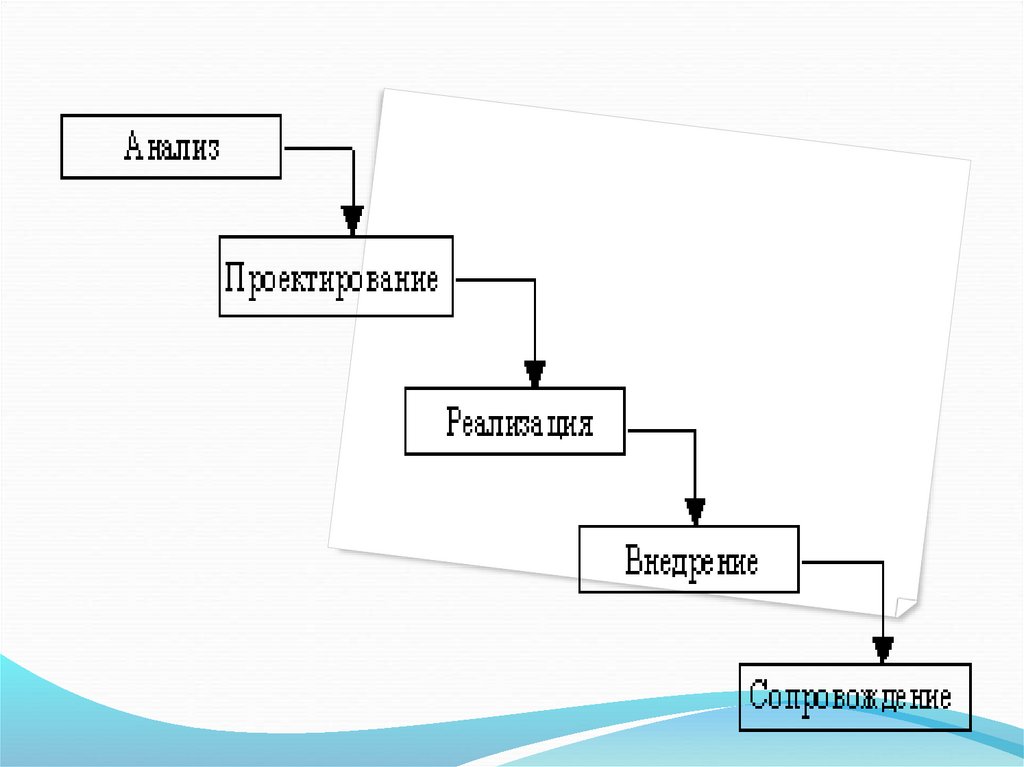
117. основные этапы жизненного цикла
анализ - определение того, что должнаделать система;
проектирование - определение того, как
система будет делать то, что она должна
делать. (Проектирование это, прежде
всего, спецификация подсистем,
функциональных компонентов и способов
их взаимодействия в системе);
118.
разработка - создание функциональныхкомпонентов и подсистем по отдельности
и соединение подсистем в единое целое;
тестирование - проверка
функционального и параметрического
соответствия системы показателям,
определенным на этапе анализа;
внедрение - установка и ввод системы в
действие;
сопровождение - обеспечение штатного
процесса эксплуатации системы на
предприятии заказчика.
119.
Этапы разработки, тестирования ивнедрения ИС обозначаются
единым, объемлющим термином реализация.
120.
Жизненный цикл образуется всоответствии с принципом нисходящего
проектирования и, как правило, носит
итерационный характер: реализованные
этапы, начиная с самых ранних,
циклически повторяются в соответствии
с изменениями требований и внешних
условий, введением дополнительных
ограничений и т.п.
121.
На каждом этапе жизненного циклапорождается определенный набор
технических решений и отражающих их
документов, при этом для каждого этапа
исходными являются документы и
решения, принятые на предыдущем
этапе.
122.
Существующие модели жизненногоцикла, определяют порядок исполнения
этапов в процессе создания ИС, а также
критерии перехода от этапа к этапу.
В соответствии с этим наибольшее
распространение получили три
следующие модели.
123.
1. Каскадная модель - предполагаетпереход на следующий этап после
полного завершения работ предыдущего
этапа (характерна для военнотехнических проектов).
124.
125.
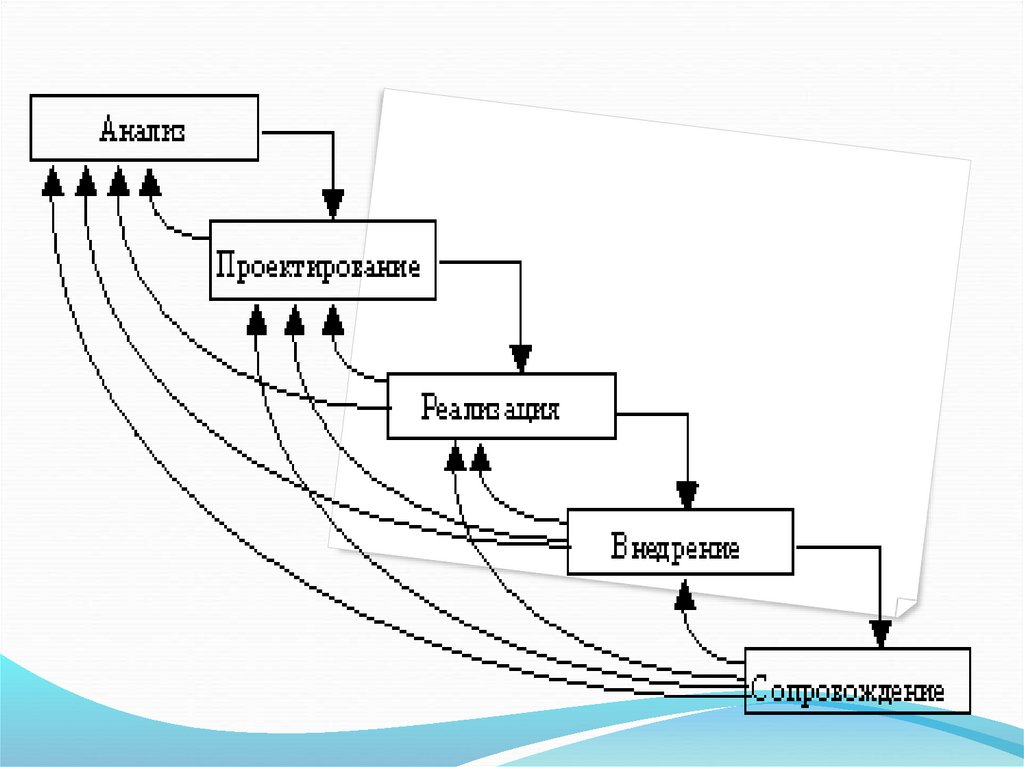
2. Поэтапная итерационная модель -модель создания ИС, предполагает
наличие циклов обратной связи между
этапами.
Преимущество такой модели заключается
в том, что межэтапные корректировки
обеспечивают большую гибкость и
меньшую трудоемкость по сравнению с
каскадной моделью.
Однако время жизни каждого из этапов
может растянуться на весь период
создания системы.
126.
127.
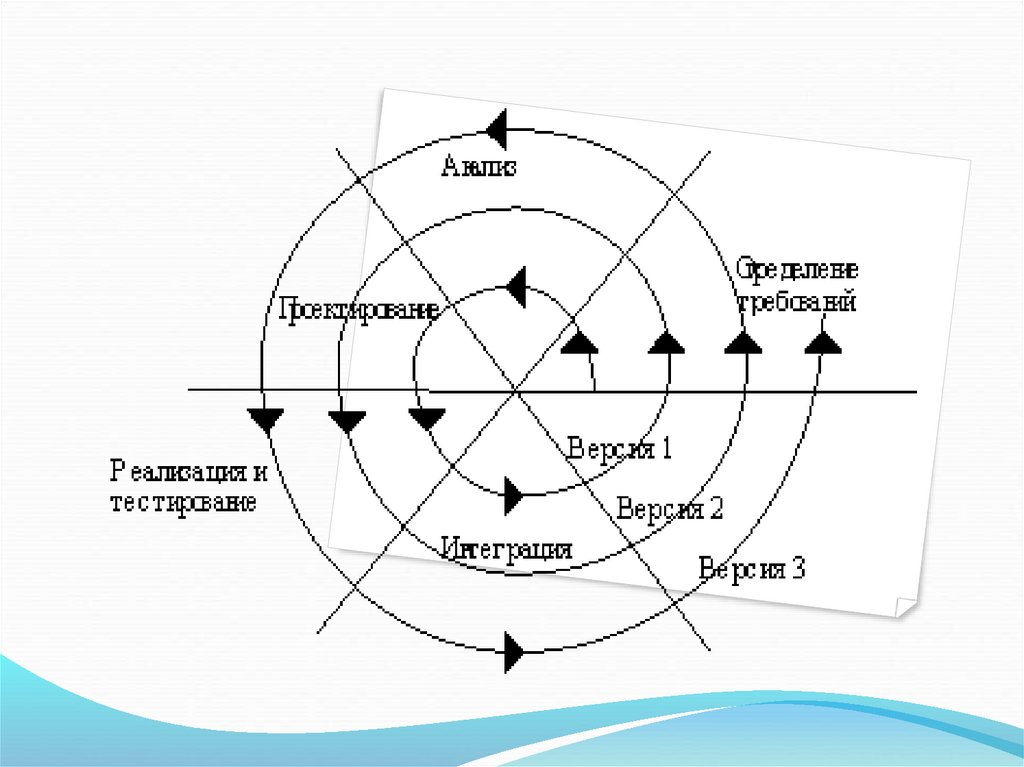
3. Спиральная модель - делает упорна начальные этапы жизненного цикла:
анализ, предварительное и детальное
проектирование.
Каждый виток спирали соответствует
поэтапной модели создания фрагмента
или версии системы, на нем уточняются
цели и характеристики проекта,
определяется его качество,
планируются работы следующего витка
спирали.
128.
129.
Нерешенные вопросы и ошибки,допущенные на этапах анализа и
проектирования ИС, порождают на
последующих этапах трудные, часто
неразрешимые проблемы и, в конечном
счете, приводят к неуспеху всего
проекта.
130.
Главная особенность современнойиндустрии заказных ИС состоит в
концентрации усилий на двух начальных
этапах ее жизненного цикла - анализе и
проектировании, при относительно
невысокой сложности и трудозатратах
на последующих этапах.
131. Структурный анализ
Целью анализа являетсяпреобразование общих,
расплывчатых знаний об исходной
предметной области в точные
определения и спецификации, а
также генерация функционального
описания системы.
На этом этапе специфицируются:
132.
внешние условия работы системы;функциональная структура системы;
распределение функций между
человеком и системой, интерфейсы;
требования к техническим,
информационным и программным
компонентам системы;
условия эксплуатации.
133.
Разработка перечисленных вышеспецификаций при создании ИС,
предназначенной для
автоматизации управленческих
процессов, в общем случае,
проходит четыре стадии.
134.
1 стадия.Структурный анализ начинается с
исследования того, как организована система
управления предприятием, с обследования
функциональной и информационной
структуры системы управления.
По результатам обследования строится
обобщенная логическая модель исходной
предметной области, отображающая ее
функциональную структуру, особенности
основной деятельности и информационное
пространство, в котором эта деятельность
осуществляется.
Используя специальную терминологию, можно
сказать, что это модель "как есть".
135. 2 стадия
Вторая стадия работы, к которойпривлекаются заинтересованные
представители заказчика, а при
необходимости и независимые
эксперты, состоит в анализе модели "как
есть", выявлении ее недостатков и узких
мест, определение путей
совершенствования системы
управления на основе выделенных
критериев качества
136. 3 стадия
Третья стадия анализа, содержащаяэлементы проектирования, - создание
усовершенствованной обобщенной
логической модели, отображающей
реорганизованную предметную область
или ее часть, которая подлежит
автоматизации.
Эту модель можно назвать моделью "как
надо".
137. 4 стадия
Заканчивается процесс разработкой "картыавтоматизации", представляющей собой
модель реорганизованной предметной
области, на которой обозначены "границы
автоматизации".
138.
Основным документом, отражающимрезультаты работ первого этапа создания
ИС, является техническое задание на
проект (разработку), содержащее, кроме
вышеперечисленных определений и
спецификаций, также сведения об
очередности создания системы, сведения
о выделяемых ресурсах, директивных
сроках проведения отдельных этапов
работы, организационных процедурах и
мероприятиях по приемке этапов, защите
проектной информации и т.д.
139.
Другими, не менее важными исамостоятельными по характеру
получаемых результатов, являются
задачи спецификации и
реорганизации процессов,
протекающих в системах управления.
Целенаправленное решение именно
этих задач в некоторых случаях может
привести к результатам, дающим
ощутимый экономический эффект без
значительных инвестиций в сферу
автоматизации предприятия.
140. Принципы структурного анализа
Анализ предметной области являетсяважнейшим этапом среди всех этапов
жизненного цикла системы.
На этом этапе, во-первых, необходимо
понять, что предполагается сделать,
а во-вторых, задокументировать
выдвинутые предложения, так как если
проектные требования не
зафиксированы и не сделаны
доступными для участников разработки,
то они вроде бы и не существуют вовсе.
141.
Системный анализ является наиболее трудной частьюпроцесса создания системы:
аналитику сложно получить исчерпывающую
информацию для оценки требований к системе с точки
зрения заказчика;
заказчик, в свою очередь, не имеет достаточной
информации о проблеме обработки данных;
аналитик сталкивается с чрезмерным количеством
подробных сведений о предметной области и о новой
системе;
спецификация системы из-за объема и технических
терминов непонятна для заказчика;
в случае понятности спецификации для заказчика, она
будет недостаточной для разработчиков, создающих
систему.
142.
Решение этих проблем может бытьсущественно облегчено за счет
применения современных структурных
методов, среди которых центральное
место занимают методологии
структурного анализа.
143.
Структурным анализом принято называтьметод исследования системы с помощью ее
графического модельного представления,
которое начинается с общего обзора и затем
детализируется, приобретая иерархическую
структуру с все большим числом уровней.
144.
Для структурного анализа характерно:разбиение на уровни абстракции с
ограничением числа элементов на каждом из
уровней (обычно от 3 до 9);
ограниченный контекст, включающий лишь
существенные на каждом уровне детали;
дуальность данных и операций над ними;
использование строгих формальных правил
записи;
последовательное приближение к конечному
результату.
145.
В качестве базовых принципов будемиспользовать:
принцип декомпозиции
и
принцип иерархического
упорядочения
146. Кроме того, будем пользоваться
Принцип концептуальной общности -заключается в следовании единой философии на
всех этапах жизненного цикла.
Принцип полноты - заключается в контроле на
присутствие лишних элементов.
Принцип непротиворечивости заключается в
обоснованности и согласованности элементов
системы.
Принцип абстрагирования - заключается в
выделении существенных аспектов системы и
отвлечение от несущественных с целью
представления проблемы в более простом, общем
виде.
147.
Принцип упрятывания - заключается вупрятывании несущественной на конкретном
этапе информации: каждая часть "знает" только
необходимую ей информацию.
Принцип логической независимости
заключается в концентрации внимания на
логическом описании системы, обеспечении
независимости от ее физической реализации.
Принцип независимости данных заключается
в том, что модели данных могут быть
проанализированы и спроектированы
независимо от процессов их логической
обработки, а также от их физической структуры и
распределения.
148.
Соблюдение указанных принциповнеобходимо при организации работ на
начальных этапах жизненного цикла
независимо от типа разрабатываемой
ИС и используемой при этом
методологии.
149. Средства структурного анализа
для целей моделирования системвообще, и структурного анализа в
частности, используются три группы
средств, отображающих:
функции, которые система должна
выполнять;
процессы, обеспечивающие
выполнение указанных функций;
данные, используемые при
выполнении функций, и отношения
между этими данными.
150.
Среди всего многообразия средств решенияуказанных задач в методологиях
структурного анализа наиболее часто и
эффективно применяемыми являются:
SADT (Structured Analysis and Design
Technique) модели и соответствующие
функциональные диаграммы
DFD (Data Flow Diagrams) - диаграммы
потоков данных;
ERD (Entity-Relationship Diagrams) диаграммы "сущность-связь"
151.
Все они содержат графические итекстовые средства моделирования:
первые - для удобства демонстрации
основных компонентов модели и их
связей,
вторые - для обеспечения точного
определения компонентов и связей.
152.
При помощи этих средств строятся каклогические модели исходной и
реорганизованной систем управления,
так и логическая модель
автоматизированной системы
управления - подробное описание того,
что и как должна делать система,
освобожденное, насколько это
возможно, от рассмотрения путей
реализации.
153. Структурный подход к проектированию ИС
В качестве двух базовых принциповиспользуются следующие:
принцип "разделяй и властвуй" - принцип
решения сложных проблем путем их
разбиения на множество меньших
независимых задач, легких для понимания
и решения;
принцип иерархического упорядочивания
- принцип организации составных частей
проблемы в иерархические древовидные
структуры с добавлением новых деталей
на каждом уровне.
154. остальные принципы
принцип абстрагирования - заключается ввыделении существенных аспектов системы и
отвлечения от несущественных;
принцип формализации - заключается в
необходимости строгого методического
подхода к решению проблемы;
принцип непротиворечивости - заключается
в обоснованности и согласованности
элементов;
принцип структурирования данных заключается в том, что данные должны быть
структурированы и иерархически
организованы.
155. Методология функционального моделирования SADT
Графика блоков и дуг SADT-диаграммы отображаетфункцию в виде блока, а интерфейсы входа/выхода
представляются дугами, соответственно
входящими в блок и выходящими из него.
Взаимодействие блоков друг с другом описываются
посредством интерфейсных дуг, выражающих
"ограничения", которые в свою очередь
определяют, когда и каким образом функции
выполняются и управляются;
156. Функциональный блок и интерфейсные дуги
157.
строгость и точностьВыполнение правил SADT требует достаточной
строгости и точности, не накладывая в то же время
чрезмерных ограничений на действия аналитика.
158. Правила SADT:
ограничение количества блоков на каждомуровне декомпозиции (правило 3-6 блоков);
связность диаграмм (номера блоков);
уникальность меток и наименований (отсутствие
повторяющихся имен);
синтаксические правила для графики (блоков и
дуг);
разделение входов и управлений (правило
определения роли данных).
отделение организации от функции, т.е.
исключение влияния организационной структуры на
функциональную модель.
159. Состав функциональной модели
Результатом применения методологии SADTявляется модель, которая состоит из
диаграмм, фрагментов текста и
глоссария, имеющих ссылки друг на друга.
Диаграммы - главные компоненты
модели.
Все функции ИС и интерфейсы на них
представлены как блоки и дуги.
Место соединения дуги с блоком
определяет тип интерфейса.
160. Функциональный блок и интерфейсные дуги
161.
Управляющая информациявходит в блок сверху, в то время
как информация, которая
подвергается обработке,
показана с левой стороны блока,
а результаты обработки
показаны с правой стороны.
162. Иерархия диаграмм
Построение SADT-модели начинается спредставления всей системы в виде
простейшей компоненты - одного блока и
дуг, изображающих интерфейсы с
функциями вне системы.
Поскольку единственный блок представляет
всю систему как единое целое, имя,
указанное в блоке, является общим.
Это верно и для интерфейсных дуг - они также
представляют полный набор внешних
интерфейсов системы в целом.
163.
Затем блок, который представляет систему вкачестве единого модуля, детализируется на
другой диаграмме с помощью нескольких
блоков, соединенных интерфейсными дугами.
Эти блоки представляют основные
подфункции исходной функции.
Данная декомпозиция выявляет полный набор
подфункций, каждая из которых представлена
как блок, границы которого определены
интерфейсными дугами.
Каждая из этих подфункций может быть
декомпозирована подобным образом для
более детального представления.
164.
165.
Модель SADT представляет собой сериюдиаграмм с сопроводительной
документацией, разбивающих сложный
объект на составные части, которые
представлены в виде блоков.
Детали каждого из основных блоков показаны в
виде блоков на других диаграммах.
Каждая детальная диаграмма является
декомпозицией блока из более общей
диаграммы.
На каждом шаге декомпозиции более общая
диаграмма называется родительской для
более детальной
166.
Некоторые дуги присоединены к блокамдиаграммы обоими концами, у других же один
конец остается неприсоединенным.
Неприсоединенные дуги соответствуют
входам, управлениям и выходам
родительского блока. Источник или
получатель этих пограничных дуг может быть
обнаружен только на родительской
диаграмме.
Неприсоединенные концы должны
соответствовать дугам на исходной
диаграмме. Все граничные дуги должны
продолжаться на родительской диаграмме,
чтобы она была полной и непротиворечивой.
167.
На SADT-диаграммах не указаны явно нипоследовательность, ни время.
Обратные связи, итерации, продолжающиеся
процессы и перекрывающиеся (по времени)
функции могут быть изображены с помощью
дуг.
Обратные связи могут выступать в виде
комментариев, замечаний, исправлений и т.д.
168. Пример обратной связи
169.
механизмы (дуги с нижней стороны) показываютсредства, с помощью которых осуществляется
выполнение функций. Механизм может быть
человеком, компьютером или любым другим
устройством, которое помогает выполнять данную
функцию
170. Иерархия диаграмм
171. Типы связей между функциями (0)Тип случайной связности
172.
(1) Тип логической связности.Логическое связывание происходит тогда, когда
данные и функции собираются вместе
вследствие того, что они попадают в общий класс
или набор элементов, но необходимых
функциональных отношений между ними не
обнаруживается.
(2) Тип временной связности.
Связанные по времени элементы возникают
вследствие того, что они представляют функции,
связанные во времени, когда данные
используются одновременно или функции
включаются параллельно, а не последовательно.
173. (3) Тип процедурной связности. Процедурно-связанные элементы появляются сгруппированными вместе вследствие того, что они
выполняются в течение одной итой же части цикла или процесса.
174. (4) Тип коммуникационной связности. Диаграммы демонстрируют коммуникационные связи, когда блоки группируются вследствие того,
что они используют одни ите же входные данные и/или производят одни и те же выходные
данные
175. (5) Тип последовательной связности. На диаграммах, имеющих последовательные связи, выход одной функции служит входными данными
для следующейфункции.
176. (6) Тип функциональной связности. Диаграмма отражает полную функциональную связность, при наличии полной зависимости одной
функции от другой.C = g(B) = g(f(A))
177.
178. Анализ и проектирование информационной системы
Фирма, занимающаяся дистанционным обучениемVTutor
178
179. Анализ работы фирмы
• Фирма VTutor является дочерним предприятиемобразовательного учреждения «Some Name»
• Основная деятельность компании заключается в дистанционном
обучении клиентов
• Дополнительные услуги, предоставляемые компанией,
заключаются в обучении сотрудников компаний-клиентов по
разработанным на заказ учебным курсам
• Целью деятельности фирмы является получение прибыли от
дистанционного обучения и расширение клиентской и
партнёрской баз
179
180. Требования к ИС
Разрабатываемая информационная система должна хранить данные о:• Сотрудниках – личная информация, квалификация, история работы
• Клиентах – личная информация, необходимые данные для заключения
деловых контрактов, статистика обучения
• Партнёрах – необходимые данные для ведения деловых отношений,
журнал взаимодействий
• Договорах – предмет заключения сделки, условия
• Учебно-методических комплексах – название, направление, описание,
содержимое УМК
• Системах сертификации – необходимые для взаимодействия данные,
требования к объектам сертификации
• Руководстве – личная информация, контактные данные, область интересов
180
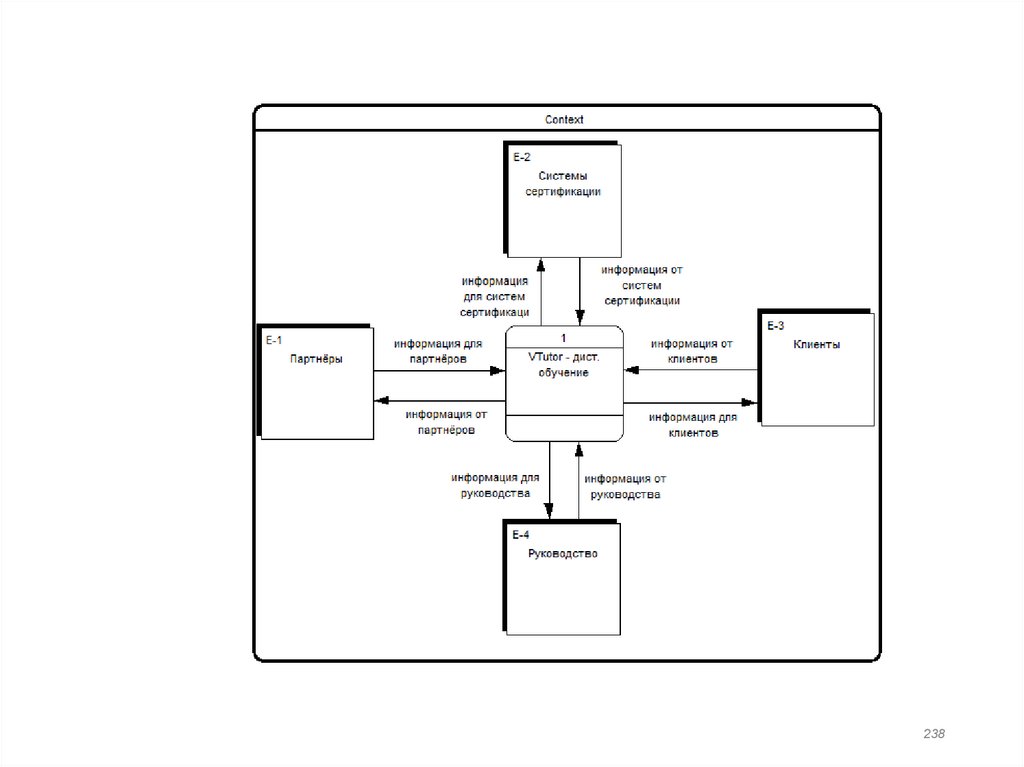
181. SADT-диаграмма Общее представление
Образовательныестандарты
Состояние рынка
Заявка от клиента
Заявка от партнёра
УМК
Vtutor
Репутация
Сотрудники
181
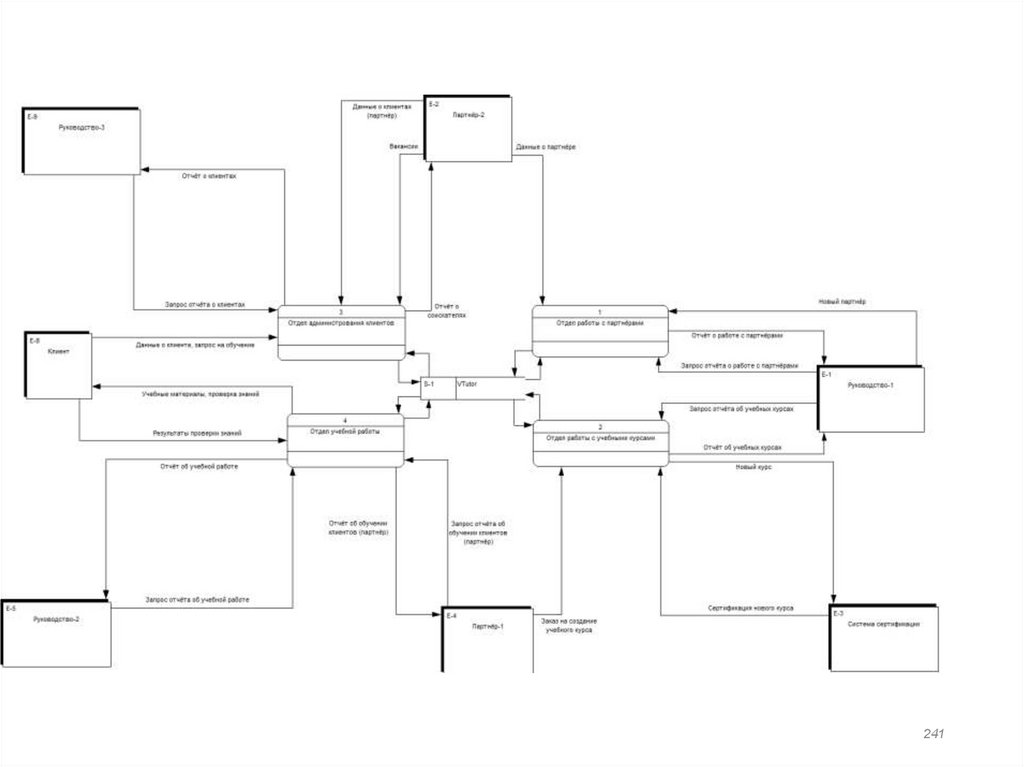
182. SADT-диаграмма А0
Состояние рынкаЗаявка от
партнёра
Образовательные
стандарты
Работа с партнёрами
А1
Заявка на
создание курса
Работа с курсами
А2
Заявка от
клиента
Клиенты от
партнёра
УМК
Работа с клиентами
А3
Слушатель
Обучение клиентов
А4
Репутация
Сотрудники
182
183. SADT-диаграмма А1
Состояниерынка
Зарегистрированный
партнёр
Заявка от
партнёра
Общение с партнёром
А11
Новый
партнёр
Регистрация партнёра
А12
Заказ на
создание
курса
Заказ на
обучение
Заявка на создание
курса
Оформление договора на
создание нового курса
А13
Оформление договора на
обучение
А14
Клиенты от
партнёра
Сотрудники
183
184. SADT-диаграмма А2
Образовательныестандарты
Заявка на создание
курса
Состояние
рынка
Внесение поправок
Создание курса
А21
УМК
Сертификация курса
А22
Созданный курс
Сертифицирован
ный курс
Формирование списка курсов
А23
Сотрудники
184
185. SADT-диаграмма А21
Образовательныестандарты
Заявка на создание
курса
Макетирование курса
А211
Внесение поправок
Требования к
содержимому
курса
Сбор учебного материала
А212
Созданный курс
Макет курса
Материалы
курса
Компоновка содержимого курса
А213
Сотрудники
185
186. SADT-диаграмма А3
КлиентыЗарегистрированный клиент
от партнёров
Регистрация клиентов
А31
Клиенты от
партнёров
Зарегистрированный
клиент
Оформление договора на
обучение
А32
Оплативший
клиент
Предоставление доступа к
обучению
А33
Слушатель
УМК
Сотрудники
186
187. SADT-диаграмма А4
УМКСлушатель
Неусвоенный
материал
Обучение
А41
Экзаменация
А42
Готовый к
экзамену
слушатель
Сдавший экзамен
слушатель
Выдача сертификата
А43
Репутация
Сотрудники
187
188. SADT – диаграмма А41
УМКНеусвоенный
материал
Слушатель
Чтение лекций
А411
Слушатель,
готовый к
практическим
занятиям
Слушатель, готовый к
промежуточному
тестированию
Проведение практических
занятий
А412
Готовый к
экзамену
слушатель
Промежуточное тестирование
А413
Сотрудники
188
189. Моделирование потоков данных (процессов)
Источники информации (внешние сущности)порождают информационные потоки (потоки
данных), переносящие информацию к подсистемам
или процессам.
Те в свою очередь преобразуют информацию и
порождают новые потоки, которые переносят
информацию к другим процессам или подсистемам,
накопителям данных или внешним сущностям потребителям информации.
190.
Таким образом, основными компонентамидиаграмм потоков данных являются:
внешние сущности;
системы/подсистемы;
процессы;
накопители данных;
потоки данных.
191. Внешние сущности представляют собой материальный предмет или физическое лицо, представляющее собой источник или приемник
информации (заказчики,персонал, поставщики, клиенты, склад). Определение
некоторого объекта или системы в качестве внешней
сущности указывает на то, что она находится за
пределами границ анализируемой ИС.
192. Подсистема
193. Процесс представляет собой преобразование входных потоков данных в выходные в соответствии с определенным алгоритмом.
194.
Номер процесса служит для его идентификации.В поле имени вводится наименование процесса
в виде предложения с активным
недвусмысленным глаголом в неопределенной
форме (вычислить, рассчитать, проверить,
определить, создать, получить), за которым
следуют существительные в винительном
падеже, например:
"Ввести сведения о клиентах";
"Выдать информацию о текущих расходах";
"Проверить кредитоспособность клиента".
195.
Использование таких глаголов, как"обработать", "модернизировать" или
"отредактировать" означает, как правило,
недостаточно глубокое понимание данного
процесса и требует дальнейшего анализа.
Информация в поле физической реализации
показывает, какое подразделение организации,
программа или аппаратное устройство
выполняет данный процесс.
196. Накопитель данных представляет собой абстрактное устройство для хранения информации
197.
Накопитель данных в общем случае являетсяпрообразом будущей базы данных и
описание хранящихся в нем данных должно
быть увязано с информационной моделью.
198. Поток данных определяет информацию, передаваемую через некоторое соединение от источника к приемнику
199. Построение иерархии диаграмм потоков данных
при проектировании относительно простыхИС строится единственная контекстная
диаграмма со звездообразной топологией, в
центре которой находится так называемый
главный процесс, соединенный с
приемниками и источниками информации,
посредством которых с системой
взаимодействуют пользователи и другие
внешние системы.
200.
Для сложных ИС строится иерархия контекстныхдиаграмм.
При этом контекстная диаграмма верхнего
уровня содержит не единственный главный
процесс, а набор подсистем, соединенных
потоками данных.
Контекстные диаграммы следующего уровня
детализируют контекст и структуру подсистем.
Иерархия контекстных диаграмм определяет
взаимодействие основных функциональных
подсистем проектируемой ИС как между
собой, так и с внешними входными и
выходными потоками данных и внешними
объектами (источниками и приемниками
информации), с которыми взаимодействует
ИС.
201. Моделирование данных Case-метод Баркера
Наиболее распространенным средствоммоделирования данных являются диаграммы
"сущность-связь" (ERD).
С их помощью определяются важные для
предметной области объекты (сущности), их
свойства (атрибуты) и отношения друг с
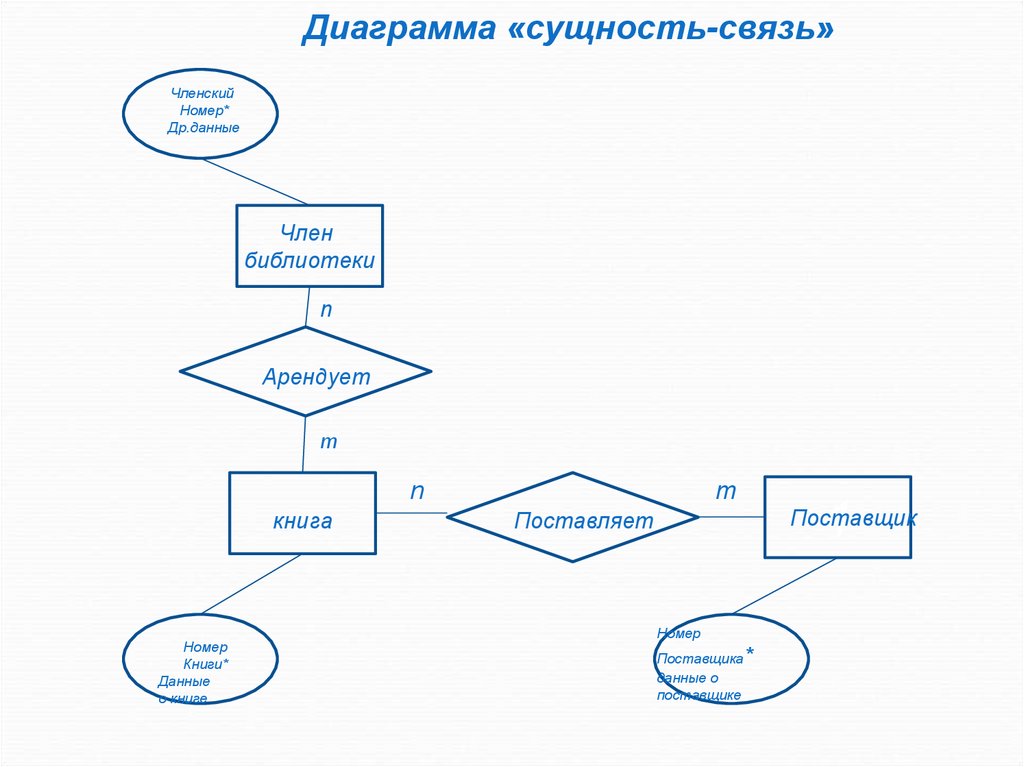
другом (связи).
ERD непосредственно используются для
проектирования реляционных баз данных.
202.
Менеджер: одна из основных обязанностей -содержание автомобильного имущества. Он должен
знать, сколько заплачено за машины и каковы
накладные расходы. Обладая этой информацией, он
может установить нижнюю цену, за которую мог бы
продать данный экземпляр. Кроме того, он несет
ответственность за продавцов и ему нужно знать, кто
что продает и сколько машин продал каждый из них.
Продавец: ему нужно знать, какую цену запрашивать
и какова нижняя цена, за которую можно совершить
сделку. Кроме того, ему нужна основная информация
о машинах: год выпуска, марка, модель и т.п.
Администратор: его задача сводится к составлению
контрактов, для чего нужна информация о покупателе,
автомашине и продавце, поскольку именно контракты
приносят продавцам вознаграждения за продажи.
203. Первый шаг моделирования - выделение сущностей
204. Следующим шагом моделирования является идентификация связей
Связь - это ассоциация между сущностями, прикоторой, как правило, каждый экземпляр одной
сущности, называемой родительской сущностью,
ассоциирован с произвольным (в том числе
нулевым) количеством экземпляров второй
сущности, называемой сущностью-потомком, а
каждый экземпляр сущности-потомка ассоциирован
в точности с одним экземпляром сущности-родителя.
Т.о., экземпляр сущности-потомка может
существовать только при существовании сущности
родителя.
205.
Связи может даваться имя, выражаемоеграмматическим оборотом глагола и
помещаемое возле линии связи. Имя каждой
связи между двумя данными сущностями должно
быть уникальным, но имена связей в модели не
обязаны быть уникальными. Имя связи всегда
формируется с точки зрения родителя, так что
предложение может быть образовано
соединением имени сущности-родителя, имени
связи, выражения степени и имени сущностипотомка.
206. - продавец может получить вознаграждение за 1 или более контрактов; - контракт должен быть инициирован ровно одним продавцом.
207. Получаем
208. Последним шагом моделирования является идентификация атрибутов
Атрибут - любая характеристика сущности, значимая длярассматриваемой предметной области и предназначенная
для квалификации, идентификации, классификации,
количественной характеристики или выражения состояния
сущности. Атрибут представляет тип характеристик или
свойств, ассоциированных со множеством реальных или
абстрактных объектов (людей, мест, событий и т.д.).
Экземпляр атрибута - это определенная характеристика
отдельного элемента множества. Экземпляр атрибута
определяется типом характеристики и ее значением,
называемым значением атрибута. В ER-модели атрибуты
ассоциируются с конкретными сущностями.
Т.о., экземпляр сущности должен обладать
единственным определенным значением для
ассоциированного атрибута.
209.
Атрибут может быть либо обязательным, либонеобязательным. Обязательность означает, что атрибут
не может принимать неопределенных значений (null
values). Атрибут может быть либо описательным (т.е.
обычным дескриптором сущности), либо входить в
состав уникального идентификатора (первичного
ключа).
210.
Уникальный идентификатор - это атрибут илисовокупность атрибутов и/или связей,
предназначенная для уникальной идентификации
каждого экземпляра данного типа сущности. В
случае полной идентификации каждый экземпляр
данного типа сущности полностью
идентифицируется своими собственными
ключевыми атрибутами, в противном случае в его
идентификации участвуют также атрибуты другой
сущности-родителя
211. Каждый атрибут идентифицируется уникальным именем, выражаемым грамматическим оборотом существительного, описывающим
представляемуюатрибутом характеристику. Атрибуты изображаются в
виде списка имен внутри блока ассоциированной
сущности, причем каждый атрибут занимает отдельную
строку. Атрибуты, определяющие первичный ключ,
размещаются наверху списка и выделяются знаком "#".
212.
Каждая сущность должна обладать хотя быодним возможным ключом. Возможный ключ
сущности - это один или несколько атрибутов, чьи
значения однозначно определяют каждый
экземпляр сущности. При существовании
нескольких возможных ключей один из них
обозначается в качестве первичного ключа, а
остальные - как альтернативные ключи.
213. Т.О. получим
214. Подтипы и супертипы: одна сущность является обобщающим понятием для группы подобных сущностей
215. Взаимно исключающие связи: каждый экземпляр сущности участвует только в одной связи из группы взаимно исключающих связей
216.
Рекурсивная связь: сущность может бытьсвязана сама с собой
Неперемещаемые (non-transferrable) связи:
экземпляр сущности не может быть перенесен из
одного экземпляра связи в другой
217. Пример использования структурного подхода
Описание предметной областиВ качестве предметной области используем
описание работы библиотеки, которая получает
запросы на книги от читателей и книги,
возвращаемые читателями.
Запросы рассматриваются администрацией
библиотеки с использованием информации о клиентах и
книгах. При этом проверяется записи о членстве в
библиотеке и обновляется список выданных книг.
Администрация контролирует также возвраты книг.
218.
Обработка запросов на книги и возвраты книгвключает следующие действия:
если клиент не является членом библиотеки, он
не имеет права на аренду.
Если требуемая книга имеется в наличии,
администрация информирует клиента об этом.
Однако, если клиент просрочил срок возврата
имеющихся у него книг, ему не разрешается
брать новые.
Когда книга возвращается, администрация это
регистрирует.
219.
Библиотека получает новые книги от своихпоставщиков.
Когда новые книги поступают в библиотеку,
необходимая информация о них фиксируется.
Информация о членстве в библиотеке содержится
отдельно от записей об аренде книг.
Администрация библиотеки регулярно готовит отчеты
за определенный период времени о членах
библиотеки, поставщиках книг, выдаче определенных
книг и о книгах, приобретенных библиотекой.
220. Организация проекта
Весь проект разделяется на 4 фазы:- анализ,
- глобальное проектирование (проектирование
архитектуры системы),
- детальное проектирование и
- реализация (программирование).
221.
На фазе анализа строится модель среды(Environmental Model).
Построение модели среды включает:
анализ поведения системы (определение
назначения ИС, построение начальной
контекстной диаграммы потоков данных
(DFD) и формирование матрицы списка
событий (ELM), построение контекстных
диаграмм);
анализ данных (определение состава
потоков данных и построение диаграмм
структур данных (DSD), конструирование
глобальной модели данных в виде ERдиаграммы).
222.
Назначение ИС определяет соглашение междупроектировщиками и заказчиками относительно
назначения будущей ИС, общее описание ИС для
самих проектировщиков и границы ИС.
Назначение фиксируется как текстовый
комментарий в "нулевом" процессе контекстной
диаграммы.
Например, в данном случае назначение ИС
формулируется следующим образом:
ведение базы данных о членах библиотеки,
книгах, аренде и поставщиках.
При этом руководство библиотеки должно
иметь возможность получать различные
виды отчетов для выполнения своих задач.
223.
Перед построением контекстной DFD необходимопроанализировать внешние события (внешние
объекты), оказывающие влияние на
функционирование библиотеки.
Эти объекты взаимодействуют с ИС путем
информационного обмена с ней.
Из описания предметной области следует, что в
процессе работы библиотеки участвуют следующие
группы людей:
клиенты,
поставщики и
руководство.
Эти группы являются внешними объектами. Они не
только взаимодействуют с системой, но также
определяют ее границы и изображаются на начальной
контекстной DFD как терминаторы (внешние
сущности).
224. Начальная контекстная диаграмма (внешние сущности обозначаются обычными прямоугольниками, а процессы – окружностями).
225.
Список событий строится в виде матрицы (ELM) иописывает различные действия внешних
сущностей и реакцию ИС на них.
Эти действия представляют собой внешние
события, воздействующие на библиотеку.
Различают следующие типы событий:
NC Нормальное управление
ND Нормальные данные
NCD Нормальное управление/данные
TC Временное управление
TD Временные данные
TCD Временное управление/данные
226.
Все действия помечаются как нормальныеданные.
Эти данные являются событиями, которые ИС
воспринимает непосредственно, например,
изменение адреса клиента, которое должно быть
сразу зарегистрировано.
Они появляются в DFD в качестве содержимого
потоков данных.
227. Матрица списка событий имеет следующий вид:
№1
2
3
4
5
6
7
8
Описание
Клиент желает стать
членом библиотеки
Клиент сообщает об
изменении данных
Клиент запрашивает
аренду книги
Клиент возвращает книгу
Руководство
предоставляет
полномочия новому
поставщику
Поставщик сообщает об
изменении адреса
Поставщик направляет
книгу в библиотеку
Руководство запрашивает
новый отчет
Тип
ND
Реакция
Регистрация клиента в
качестве члена библиотеки
ND Регистрация изменений
------данных клиента
ND
Рассмотрение запроса
ND
Регистрация возврата
ND
Регистрация поставщика
ND
Регистрация измененного
адреса поставщика
Регистрация данных книги
ND
ND
Формирование требуемого
отчета для руководства
228.
Для завершения анализа функционального аспектаповедения системы строится полная контекстная
диаграмма, включающая диаграмму нулевого уровня.
Процесс "библиотека" декомпозируется на
4 процесса, отражающие основные виды
административной деятельности библиотеки.
Существующие "абстрактные" потоки данных между
терминаторами и процессами трансформируются в
потоки, представляющие обмен данными на более
конкретном уровне.
Список событий показывает, какие потоки
существуют на этом уровне: каждое событие из списка
должно формировать некоторый поток (событие
формирует входной поток, реакция - выходной
поток). Один "абстрактный" поток может быть
разделен на более чем один "конкретный" поток.
229.
Потоки на диаграммеверхнего уровня
Информация от клиента
Информация для
клиента
Информация от
руководства
Информация для
руководства
Информация от
поставщика
Потоки на диаграмме нулевого
уровня
Данные о клиенте, Запрос об аренде
Членская карточка, Ответ на запрос
об аренде
Запрос отчета о новых членах, Новый
поставщик, Запрос отчета о
поставщиках, Запрос отчета об
аренде, Запрос отчета о книгах
Отчет о новых членах, Отчет о
поставщиках, Отчет об аренде,
Отчет о книгах
Данные о поставщике, Новые книги
230. Контекстная диаграмма
231.
Контекстная диаграммаНачальная контекстная
диаграмма
Руководство
1
(внешние сущности обозначаются обычными прямоугольниками,
а процессы – окружностями
Запрос отчета
о новых членах
Отчет о новых
членах
Новый
поставщик
читатель
Данные
о клиенте
Информация
Администриот читателя
рование
членов
библиотеки
Информация
для читателя
Запрос отчета
о поставщиках
поставщик
Отчет о поставщиках
Администрирование
Информация
поставщиков
от поставщика
Данные
о поставщике
Членская
карточка
Библиотека
Ответ на запрос
Запрос
об аренде
Информация
для руководства
Информация
от
руководства
Администрирование аренды
Отчет об аренде
Запрос отчета об аренде
Руководство
1
Администрирование фонда
книг
Новые книги
Отчет
о книгах
Запрос отчета
о книгах
232.
Диаграмма структур данныхИнформация от
Информация от поставщика
читателя
Данные о
читателе
Запрос об
аренде
Данные о
поставщике
Новые книги
Информация
для читателя
Членская
карточка
Ответ на запрос
об аренде
Информация
от руководства
Запрос отчета
о новых членах
Новый
поставщик
Запро
с
Информация
Запрос отчета Запрос отчета Запрос отчета
о поставщиках
об аренде
о книге
З
для руководства
Отчет о новых
членах
Отчет
о поставщиках
Отче
Отчет об аренде
Отчет о книге
233.
Диаграмма «сущность-связь»Членский
Номер*
Др.данные
Член
библиотеки
n
Арендует
m
n
книга
Номер
Книги*
Данные
о книге
m
1
Поставщик
Поставляет
Номер
Поставщика
данные о
поставщике
*
234.
На фазе проектирования архитектуры строитсяпредметная модель.
Процесс построения предметной модели включает
в себя:
детальное описание функционирования системы;
дальнейший анализ используемых данных и
построение логической модели данных для
последующего проектирования базы данных;
определение структуры пользовательского
интерфейса, спецификации форм и порядка их
появления;
уточнение диаграмм потоков данных и списка
событий, выделение среди процессов нижнего
уровня интерактивных и неинтерактивных,
определение для них миниспецификаций.
235.
Результатами детального проектированияявляются:
модель процессов (структурные схемы
интерактивных и неинтерактивных функций);
модель данных (определение в ERD всех
необходимых параметров для приложений);
модель пользовательского интерфейса
(диаграмма последовательности форм (FSD),
показывающая, какие формы появляются в
приложении и в каком порядке, взаимосвязь
между каждой формой и определенной
структурной схемой, взаимосвязь между каждой
формой и одной или более сущностями в ERD).
236.
На фазе реализации строится реализационнаямодель. Процесс ее построения включает в себя:
- генерацию SQL-предложений, определяющих
структуру целевой БД (таблицы, индексы,
ограничения целостности);
- уточнение структурных схем (SCD) и диаграмм
последовательности форм (FSD) с последующей
генерацией кода приложений.
237. Начальная контекстная диаграмма потоков данных (DFD)
КлиентыПартнёры
0
Vtutor
Руководство
Системы
сертификации
237
238.
238239. Матрица списка событий (ELM)
СущностьОписание
Реакция ИС
Система сертификации
Сертификация учебного курса
Внесение курса в список доступных для обучения
Заказ на создание нового учебного курса
Создание нового учебного курса
Направляет своих сотрудников для обучения
Регистрирует новых клиентов
Запрашивает отчёт по процессу обучения
своих сотрудников
Предоставляет отчёт по процессу обучения клиентов
Предоставляет вакансии для клиентов, закончивших
учебные курсы
Делает предложение по трудоустройству клиентам,
удовлетворяющим требованиям
Подача заявки на регистрацию
Регистрация нового клиента
Подача заявки на обучение по выбранному курсу
Допуск клиента к учебному процессу
Завершение учебного курса
Экзаменация клиента и выдача сертификата об
окончании учебного курса
Согласие на предложение по трудоустройству и
отправление контактных данных
Передача контактных данных и отчёта по процессу
обучения клиента партнёрам, заинтересованным в
клиенте
Заключает договор с новым партнёром
Регистрирует нового партнёра
Запрашивает отчёт
Предоставляет отчёт
Партнёр
Клиент
Руководство
239
240. Контекстная диаграмма потоков данных
Данные о клиентах(партнёр)
Партнёр
Данные о
партнёре
Отчёт о клиентах
Руководство
Вакансии
Запрос отчёта о
клиентах
Отдел
администрирования
клиентов
Отчёт о
соискателях
Запрос
отчёта о
работе с
партнёрами
Запрос на
обучение
Клиент
Vtutor
Данные о
клиенте
Учебные
материалы
Отчёт о
работе с
партнёрами
Запрос
отчёта об
учебных
курсах
Проверка
знаний
Руководство
Отчёт об
учебных курсах
Отдел работы с
учебными курсами
Отдел учебной работы
Результаты
проверки знаний
Новый
партнёр
Отдел работы с
партнёрами
Отчёт об обучении
клиентов (партнёр)
Руководство
Запрос отчёта об
учебной работе)
Новый курс
Сертификация
нового курса
Запрос отчёта об
обучении клиентов
(партнёр)
Партнёр
Заказ на создание
учебного курса
Система
сертификации
240
241.
241242. Диаграмма «сущность-связь» (ERD)
Выбирает УМК242
243.
На основе анализа потоков данных ивзаимодействия процессов с хранилищами данных
осуществляется окончательное выделение подсистем
(предварительное должно было быть сделано и
зафиксировано на этапе формулировки требований в
техническом задании).
При выделении подсистем необходимо
руководствоваться принципом функциональной
связанности и принципом минимизации информационной
зависимости.
Необходимо учитывать, что на основании таких
элементов подсистемы как процессы и данные на этапе
разработки должно быть создано приложение, способное
функционировать самостоятельно.
244.
С другой стороны при группировке процессови данных в подсистемы необходимо учитывать
требования к конфигурированию продукта, если
они были сформулированы на этапе анализа.
245.
246.
247. CASE-технология
Основные виды и последовательность работ,рекомендуемые при построении логических
моделей предметной области в рамках CASEтехнологии анализа системы управления
предприятием следующие:
248.
1. Проведение функционального и информационногообследования системы управления (административноуправленческой деятельности) предприятия:
определение организационно-штатной структуры
предприятия;
определение функциональной структуры предприятия;
определение перечня целевых функций структурных
элементов - подразделений и должностных лиц;
определение круга и очередности обследования
структурных элементов системы управления согласно
сформулированным целевым функциям;
обследование деятельности выделенных структурных
элементов;
построение FD-диаграммы системы управления с
указанием структурных элементов и функций,
реализация которых будет моделироваться на DFDуровне.
249.
2. Разработка моделей деятельности структурныхэлементов и системы управления в целом:
выделение множества внешних объектов, оказывающих
существенное влияние на деятельность структурного
элемента;
спецификация входных и выходных информационных
потоков;
выявление основных процессов, определяющих
деятельность структурного элемента и обеспечивающих
реализацию его целевых функций;
спецификация информационных потоков между основными
процессами деятельности, уточнение связей между
процессами и внешними объектами;
оценка объемов и интенсивности информационных потоков;
разработка иерархии диаграмм потоков данных,
образующих функциональную модель деятельности
структурного элемента;
объединение DFD-моделей структурных элементов в
единую модель системы управления предприятием.
250.
3. Разработка информационных моделейструктурных элементов и модели
информационного пространства системы
управления:
определение сущностей модели и их атрибутов;
проведение атрибутного анализа и оптимизация
сущностей;
идентификация отношений между сущностями и
определение типов отношений;
разрешение неспецифических отношений;
анализ и оптимизация информационной модели;
объединение информационных моделей в
единую модель информационного пространства.
251.
4. Разработка предложений по автоматизациисистемы управления предприятия:
определение границ автоматизации - составление
перечня автоматизируемых структурных элементов,
разбиение процессов основной деятельности на
автоматические, автоматизированные и ручные;
составление перечня подсистем и логических АРМов
(автоматизированных рабочих мест), определение
способов их взаимодействия;
разработка предложений по очередности
проектирования и реализации подсистем и
отдельных логических АРМов, входящих в состав ИС;
разработка требований к средствам базового
технического обеспечения ИС;
разработка требований к средствам базового
программного обеспечения ИС.
252.
Логическая модель, отображающая деятельностьсистемы управления предприятия и
информационное пространство, в котором эта
деятельность протекает, представляют собой
"снимок" положения дел (функциональная
структура, роли должностных лиц,
взаимодействие подразделений, принятые
технологии обработки управленческой
информации, автоматизированные и
неавтоматизированные процессы и т.д.) на
момент обследования. Эта модель позволяет
понять, что делает и как функционирует
предприятие с позиций системного анализа,
сформулировать предложения по улучшению
ситуации.
253.
Модель является не просто реализациейначальных этапов работы и основанием для
формирования технического задания на ее
последующие этапы. Она представляет собой
самостоятельный результат, имеющий большое
практическое значение.
254.
Построенная модель является законченнымрезультатом по следующим причинам:
Она включает в себя модель существующей
неавтоматизированной технологии, принятой на
предприятии.
Формальный анализ этой модели позволяет
выявить узкие места в управлении предприятием
и сформулировать рекомендации по его
улучшению (независимо от того, предполагается
ли дальнейшая разработка автоматизированной
системы или нет).
255.
Она позволяет осуществлять эффективноеобучение новых работников конкретным
направлениям деятельности предприятия, так как
соответствующие технологии содержатся в модели.
С ее помощью можно осуществлять
предварительное моделирование перспективных
направлений деятельности предприятия с целью
выявления новых потоков данных,
взаимодействующих процессов и структурных
элементов.
Она обеспечивает распространение накопленного
опыта на других предприятиях, дает возможность
унифицировать административно-управленческую
и финансовую деятельность этих предприятий.
256.
Развитие логической модели предметнойобласти, ее последовательное превращение в
модель целевой ИС, позволит интегрировать
перспективные предложения руководства и
ведущих сотрудников предприятия, экспертов и
системных аналитиков, сформировать видение
новой, реорганизованной и автоматизированной
деятельности предприятия.
257. Общие положения
Основу современной CASE-технологии анализа ипроектирования информационных систем составляют:
поддержка всех этапов жизненного цикла ИС, начиная с
самых общих описаний предметной области до
получения и сопровождения программного продукта;
методология структурного нисходящего анализа и
проектирования, при которой разработка ИС
представляется в виде последовательности четко
определенных этапов;
258.
ориентация на реализацию приложений вархитектуре "клиент-сервер" с использованием
всех особенностей современных серверов баз
данных (включая декларативные ограничения
целостности, хранимые процедуры, триггеры баз
данных) и поддержкой в клиентской части всех
современных стандартов и требований к
графическому интерфейсу конечного
пользователя;
наличие централизованной базы данных репозитория, обеспечивающего хранение
моделей предметной области и спецификаций
проекта прикладной системы на всех этапах ее
разработки;
возможность одновременной работы с
репозиторием многих пользователей;
259.
централизованное хранение проекта системы иуправление одновременным доступом к нему всех
участников разработки;
поддержка согласованности действий разработчиков,
не допускающая ситуации, когда каждый аналитик или
программист работает со своей версией проекта и
модифицирует ее независимо от других;
автоматизация последовательного перехода от одного
этапа разработки к другому, использование
специальных утилит, с помощью которых можно по
спецификациям концептуального уровня
автоматически получать первоначальные варианты
спецификации уровня проектирования (описание
структуры базы данных и состава программных
модулей), а по последним, после всех необходимых
уточнений и дополнений, автоматически генерировать
готовые к выполнению программы;
260.
автоматизация стандартных действий попроектированию и реализации ИС, например,
генерация многочисленных отчетов по
содержимому репозитория, обеспечивающих
полное документирование текущей версии
системы на всех этапах ее разработки.
261.
Реализация перечисленных технологическихвозможностей зависит от того, какая конкретная
CASE-система используется коллективом
аналитиков и разработчиков проекта.
262. Краткая характеристика CASE-системы Visible Analyst Workbench
Система Visible Analyst Workbench (VAW)относится к сетевым многопользовательским
CASE-системам, предназначенным для
поддержки процесса создания ИС от этапов
анализа текущей деятельности системы
управления предприятия до создания
законченных моделей ее реорганизованной
деятельности, а также разработки конечных
приложений в технологии "клиент-сервер".
Продукт реализует широкий набор методов
структурного системного анализа.
263. Централизованная база данных проекта
Система обеспечивает хранение всех моделей испецификаций, относящихся к проекту
прикладной системы и возникающих на
различных этапах ее жизненного цикла, в
централизованной базе данных - репозитории.
Работа над проектом во многом сводится к
работе с этой базой данных - вводу и коррекции
различных описаний, поверке их согласованности
и полноты, преобразованию одних моделей в
другие и т.д.
264.
Средства управления репозиторием с помощьюудобного интерфейса реализуют
административные функции управления, включая
создание и удаление приложений, управление
доступом к данным со стороны различных
пользователей, предоставление прав одному
приложению использовать часть спецификаций
другого, экспорт и импорт отдельного приложения
или всего репозитория.
265. Поддержка возможности коллективной разработки проекта
В этом продукте реализована возможностьработы над одним проектом коллектива
разработчиков.
Используемый VAW механизм блокировки,
гарантирует, что разработчик не может изменить
какой-либо элемент проекта, пока с ним работает
другой разработчик.
Каждый пользователь имеет возможность
самостоятельно определить пароль доступа к
своей части проекта
266. Возможность импорта-экспорта
VAW снабжен мощными встроенными средствамиимпорта-экспорта. Поддерживается связь с
такими популярными средами проектирования
конечных приложений, как PowerBuilder и SQL
Windows. Так же поддерживается возможность
импорта-экспорта данных для таких CASEсредств, как KnowledgeWare и Excelerator.
Кроме того, VAW располагает стандартным
форматом экспорта-импорта данных, который
позволяет получить доступ к данным, хранящихся
в репозитории, из других систем.
267. Связь с системами управления базами данных
VAW с помощью встроенных средств можетвзаимодействовать со следующими СУБД:
SQLBase, Oracle, Sybase.
268. Возможность реверс-инжиниринга
Средствами VAW можно проводить реинжинирингбаз данных, поддерживаемых следующими
СУБД: SQLBase, Oracle, Sybase.
Нотации, поддерживаемые системой
VAW поддерживает следующие нотации для
построения моделей: Yordon, Gane&Sarson, SDM,
IE. Однако система не позволяет изменять во
время работы выбранный для проекта
формализм.
269. Средства верификации моделей
VAW имеет мощные средства проверкисогласованности и корректности создаваемых
моделей. Система может проверять диаграммы
на соответствие синтаксису, осуществляет
проверку правильности ключевых атрибутов
сущностей, поиск не используемых элементов и
т.д. VAW также имеет средства проверки моделей
на сбалансированность и синхронность
используемых данных в DF- и ER-диаграммах
одного проекта.
270. Среда функционирования
MS Windows 3.x, 95/98, NT.Требования к аппаратной части
Требования, выдвигаемые системой к
аппаратуре, обусловлены средой
функционирования MS Windows. Для
использования системы требуется IBM
совместимый компьютер, оснащенный как
минимум процессором Intel 486, ОЗУ емкостью не
менее 8 Мб и жестким диском с объемом
свободного пространства не менее 6Мб.
271. Документируемость моделей
VAW поддерживает различные настраиваемыетипы отчетов. Пользователь может определить
область проекта, по которой нужно дать отчет; типы
элементов и их характеристики; задать сортировку
отбираемых элементов.
272. Процесс структурного анализа с применением CASE-системы Visible Analyst Workbench
Процесс структурного анализа с применением CASEсистемыVisible Analyst Workbench
В соответствии с общей технологией и архитектурой
CASE-систем при работе с VAW выделяются следующие
основные этапы процесса разработки информационной
системы:
моделирование и анализ функционирования существующей
системы управления;
построение и анализ информационной модели предметной
области;
проектирование концептуальной модели базы данных новой
системы;
проектирование функциональной структуры новой системы;
проектирование процессов обработки данных;
проектирование и реализация приложений.
273. Моделирование и анализ функционирования существующей системы
Целью этапа является построение моделейсуществующих процессов управления,
выявление их недостатков и возможных
источников усовершенствования.
Содержанием работы проектировщиков является
построение моделей двух типов функциональной, представленной в виде
диаграмм функциональной декомпозиции, и
поведенческой, представленной в виде
диаграмм потоков данных, описывающих
особенности процессов обработки данных при
реализации соответствующих функций
управления.
274. Построение и анализ информационной модели предметной области
На данном этапе осуществляется детальноеинформационное моделирование существующей
системы управления, описывающее
информационные потребности предприятия.
Результатом является информационная модель
системы управления, отображающая ее единое
информационное пространство.
275. Разработка концептуальной модели базы данных новой системы
Основным содержанием работ, проводимых наэтапе концептуального проектирования базы
данных, является построение формализованного
информационного описания будущей предметной
области.
Этот этап является одним из ключевых в
создании ИС, так как исправление ошибок,
допущенных на первых стадиях концептуального
проектирования являются дорогостоящим
процессом, особенно в том случае, когда к
моменту обнаружения ошибки уже пройдены
несколько последующих этапов проектирования и
реализации системы.
276.
Конечным результатом этапа является СУБД-независимое описание базы данных. Достижение этого
результата предполагает построение концептуальной
модели базы данных, являющейся подмножеством
концептуальной модели предметной области. Отличие
этих двух моделей состоит в том, что концептуальная
модель базы данных описывает лишь те данные,
которые подлежат непосредственному хранению в базе
данных проектируемой системы. Очевидно, что в
первую очередь такими данными являются первичные
технико-экономические показатели. Как правило, в
состав базы данных входят также производные
показатели, используемые в качестве справочной
информации другими системами, производные
показатели, необходимость хранения которых прямо
диктуется функциональной структурой системы.
277.
Следует отметить, что построениенормализованной концептуальной модели
предметной области гарантирует получение
нормализованной концептуальной модели базы
данных.
Методика концептуального проектирования
предполагает получение нормализованной
глобальной концептуальной ER-модели
предметной области как результата интеграции
локальных концептуальных моделей,
отображающих информационные потребности
отдельных подразделений и должностных лиц.
278.
Первоначальный вариант СУБД-ориентированной реляционной базы данных
может быть получен автоматически с помощью
специальных утилит на основании
спроектированной концептуальной модели базы
данных новой системы, представленной в виде
ER-диаграммы. Результаты проектирования
программных модулей приложений служат
основанием для совершенствования структуры
базы данных. Принятие соответствующих
решений по ее совершенствованию должно
фиксироваться в виде модификации ERдиаграммы базы данных
279. Проектирование функциональной структуры новой системы
Анализ полученных при выполнениипредыдущих этапов результатов позволяет перейти
к проектированию функциональной структуры
новой информационной системы. Результаты этих
работ представляются в виде диаграмм
функциональной декомпозиции, описывающих
функциональные возможности создаваемой
системы.
280. Проектирование процессов обработки данных новой системы
Результатом этапа является описание особенностейорганизации процессов обработки данных в новой
информационной системе. Фиксация результатов
проектирования на этом этапе осуществляется в виде
диаграмм потоков данных. Основой для их построения
служат, как правило, диаграммы потоков данных,
полученные на этапе анализа функционирования
существующей системы управления. Построение диаграмм
потоков данных для новой системы предполагает принятие
целого ряда проектных решений, например, таких, как
определение состава и мест ввода первичных данных,
владельцев данных, последовательности и способов
реализации процессов обработки данных, структур
первичных и выходных документов и т.д.
281. Проектирование и реализация приложений
Заключительными этапами проектированияявляются проектирование и реализация
пользовательских приложений. Функциональные
возможности создаваемой системы определяются
спецификацией модулей различных типов,
основными из которых являются экранные формы,
отчеты, меню, процедурные модули.
В процессе реализации пользовательских
приложений создаются программы, отвечающие
всем требованиям проектных спецификаций.
Использование для разработки приложений языков
четвертого поколения позволяет полностью
автоматизировать этот этап, существенно сократить
сроки разработки системы, повысить ее качество и
надежность