













































Похожие презентации:
")

")


")




Ассоциативные правила
1.
Ассоциативные правилаИС-1
2023
2.
Что это?O Ассоциативные правила позволяют
находить закономерности между
связанными событиями.
O Алгоритмы поиска ассоциативных
правил - один из популярных методов
обнаружения знаний.
O Associations rules learning (ARL) –
обучение на ассоциативных правилах
O Анализ рыночной корзины
2
3.
ОпределениеАссоциативные
правила представляют
собой механизм
нахождения
логических
закономерностей
между связанными
элементами
(событиями или
объектами).
3
4.
Associations rules learningO В общем виде ARL можно описать как
«Кто купил x, также купил y». В основе
лежит анализ транзакций, внутри
каждой из которых лежит свой
уникальный itemset из набора items.
O При помощи ARL алогритмов находятся
те самые «правила» совпадения items
внутри одной транзакции, которые
потом сортируются по их силе.
4
5.
Поиск покупательскихшаблонов
Если пара товаров X и Y часто покупается
вместе, то:
O Реклама товаров X может быть
направлена на покупателей товара Y
O Товары X и Y могут быть размещены на
одной полке
O Товары X и Y могут быть
скомбинированы в некий новый продукт
5
6.
Исследование TeradataВ 1992 году группа по консалтингу в
области ритейла компании Teradata под
руководством Томаса Блишока провела
исследование 1.2 миллиона транзакций в
25 магазинах для ритейлера Osco Drug
(Drug Store — формат разнокалиберных
магазинов у дома).
6
7.
Исследование TeradataПосле анализа всех этих транзакций
самым сильным правилом получилось
«Между 17:00 и 19:00 чаще всего пиво и
подгузники покупают вместе».
7
8.
Меры для определенияассоциаций
O Поддержка
O Достоверность
O Лифт
8
9.
ПоддержкаПоддержка показывает то, как часто
данный товарный набор появляется, что
измеряется долей покупок, в которых он
присутствует.
Например:
Яблоко появляется в четырех из восьми
покупок, значит, его поддержка 50 % (или ½).
Товарные наборы могут содержать и
несколько элементов.
9
10.
ДостоверностьДостоверность показывает, как часто товар Y
появляется вместе с товаром X, что выражается как {X>Y}. Это измеряется долей их одновременных появлений.
Например,
достоверность {яблоко->пиво} соответствует трем из
четырех, то есть 75 %.
достоверность {яблоко->пиво} =
поддержка {яблоко->пиво} / поддержка {яблоко}
Одним из недостатков этой меры является то, что она
может исказить степень важности предложенной
ассоциации
10
11.
ЛифтЛифт отражает то, как часто товары X и Y появляются
вместе, одновременно учитывая, с какой частотой
появляется каждый из них.
лифт {яблоко->пиво} =
достоверность {яблоко->пиво}/ поддержка {пиво}.
Значения лифта больше единицы означают, что товар
Y вероятно купят вместе с товаром X, а значение
меньше единицы — что их совместная покупка
маловероятна.
11
12.
Пример12
13.
Ассоциативные правиладля рассматриваемого примера
(можем наблюдать такие закономерности в
покупках):
O ¾ чаще всего покупают яблоки и
тропические фрукты;
O ¾ другая частая покупка: лук и овощи;
O ¾ если кто-то покупает сыр в нарезке, он,
скорее всего, возьмет и сосиски;
O ¾ если кто-то покупает чай, то он,
вероятно, возьмет и тропические фрукты.
13
14.
Меры на примере14
15.
Меры на примереПравило {пиво->газировка} имеет высокую достоверность —
17,8 %. Однако и пиво, и газировка вообще часто
появляются среди покупок, поэтому их ассоциация может
оказаться простым совпадением. Это подтверждается
значением лифта, указывающим на отсутствие связи между
газировкой и пивом.
15
16.
Меры на примереПравило {пиво->мужская косметика} имеет низкую
достоверность из-за того, что мужскую косметику вообще
реже покупают. Тем не менее, если кто-то покупает ее, он,
вероятно, купит также и пиво, на что указывает высокое
значение лифта в 2,6.
Для пары {пиво->ягоды} верно обратное. Видя лифт меньше
единицы, мы заключаем, что если кто-то покупает пиво, то
16
он, скорее всего, не возьмет ягод.
17.
АлгоритмыСуществует ряд часто используемых
классических алгоритмов,
позволяющих находить правила в
itemsets согласно перечисленным выше
понятиям — Наивный или брутфорсалгоритм, Apriori-алгоритм, ECLATалгоритм, FP-growth алгоритм и другие
17
18.
Принцип AprioriПринцип Apriori утверждает, что если
какой-то товарный набор редкий, то и
большие наборы, которые его включают,
тоже должны быть редки.
18
19.
Получение списка частотныхтоварных наборов
O Шаг 0: начать с товарных наборов, содержащих
всего один элемент, таких как {яблоки} или
{груши}.
O Шаг 1: вычислить поддержку для каждого
товарного набора. Оставить наборы,
удовлетворяющие порогу, и отбросить остальные.
O Шаг 2: увеличить размер анализируемого
товарного набора на единицу и сгенерировать все
возможные конфигурации, используя товарные
наборы из предыдущего шага.
O Шаг 3: повторять шаги 1 и 2, вычисляя поддержку
для возрастающих товарных наборов до тех пор,
пока они не закончатся.
19
20.
Сокращение товарныхнаборов
Если у элемента, например {яблоки}, низкая
поддержка, то он будет удален из списка
анализируемых товарных наборов вместе со
всем, что его содержит, тем самым это
сократит число наборов для анализа более
чем вдвое.
20
21.
Поиск товарных правил свысокой достоверностью
или лифтом.
Принцип Apriori также может помочь
найти товарные ассоциации с высокой
достоверностью или лифтом. Поиск этих
ассоциаций требует меньше вычислений,
поскольку если товарные наборы с
высокой поддержкой известны, то
достоверность и лифт вычисляются уже с
использованием значения поддержки.
21
22.
ОграниченияO Требует долгих вычислений
O Ложные ассоциации
O Заключение:
Принцип Apriori ускоряет поиск часто
встречающихся товарных наборов,
отбрасывая значительную долю редких.
22
23.
Описание Association rule23
24.
Определение(ассоциативное правило)
24
25.
Support25
26.
Support - пример26
27.
Confidence(достоверность)
27
28.
Lift (лифт)28
29.
Conviction(убедительность)
O В общем виде Conviction — это
«частотность ошибок» нашего правила.
O Т.е., например, как часто покупали пиво
без подгузников и наоборот
29
30.
АлгоритмыСуществует ряд часто используемых
классических алгоритмов,
позволяющих находить правила в
itemsets согласно перечисленным выше
понятиям — Наивный или брутфорсалгоритм, Apriori-алгоритм, ECLATалгоритм, FP-growth алгоритм и другие
30
31.
БрутфорсДля того чтобы найти все возможные Association rules применяя
брутфорс-алгоритм необходимо перечислить все подмножества X
из набора I и для каждого подмножества X рассчитать supp(X).
31
32.
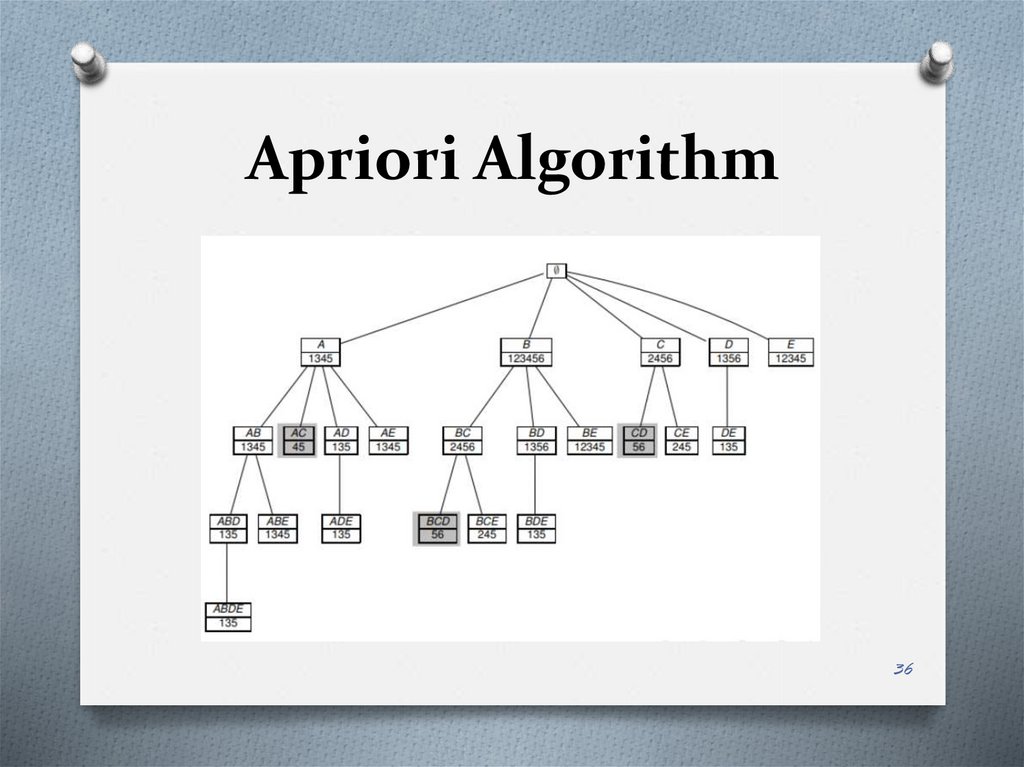
Apriori Algorithm32
33.
Apriori AlgorithmБудем
рассматривать
дерево префиксов
(prefix tree), где 2
элемента X и Y
соединены, если X
является прямым
подмножеством Y.
Таким образом
можно
пронумеровать
все подмножества
множества I.
33
34.
Apriori Algorithm34
35.
Apriori Algorithm• Apriori алгоритм по-уровнево проходит по
префиксному дереву и рассчитывает
частоту встречаемости подмножеств X в D.
Таким образом, в соответствии с
алгоритмом:
• исключаются редкие подмножества и все
их супермножества
• рассчитывается supp(X) для каждого
подходящего кандидата X размера k на
уровне k
35
36.
Apriori Algorithm36
37.
Apriori Algorithm37
38.
Apriori Algorithm38
39.
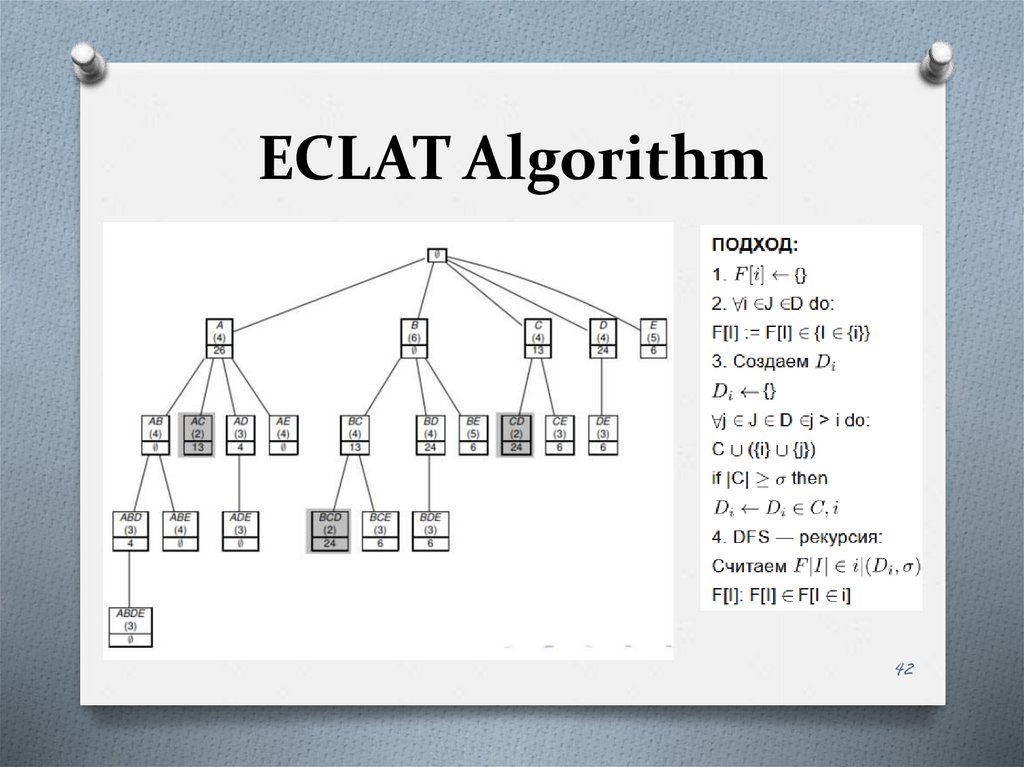
ECLAT Algorithm39
40.
ECLAT Algorithm40
41.
ECLAT Algorithm41
42.
ECLAT Algorithm42
43.
ECLAT Algorithm43
44.
FP-ростаO Алгоритм FP предназначен для выявления часто
встречающихся шаблонов.
O При первом проходе алгоритм подсчитывает
встречаемость объектов (пары атрибут-значение) в
наборах и запоминает их в «таблице заголовков». При
втором проходе алгоритм строит структуру FP-дерева
путём вставки экземпляров. Объекты в каждом
экземпляре должны быть упорядочены по убыванию их
частоты встречаемости в наборе, так что дерево может
быть обработано быстро. Объекты в каждом
экземпляре, которые не достигают минимального
порога, отбрасываются. Если много экземпляров имеют
общими большинство часто встречаемых объектов, FPдерево обеспечивает высокое сжатие близко к корню
дерева.
44
45.
FP-Growth AlgorithmO
FP-Growth (Frequent Pattern Growth) алгоритм самый
молодой из перечисленных, впервые он описан в 2000 году.
O
FP-Growth предлагает отказаться от генерации кандидатов
(что лежит в основе Apriori и ECLAT). Теоретически, такой
подход позволит еще больше увеличить скорость
алгоритма и использовать еще меньше памяти.
O
Это достигается за счет хранения в памяти префиксного
дерева (trie) не из комбинаций кандидатов, а из самих
транзакций.
O
При этом FP-Growth генерирует таблицу заголовков для
каждого item, чей supp выше заданного пользователем. Эта
таблица заголовков хранит связанный список всех
однотипных узлов префиксного дерева. Таким образом,
алгоритм сочетает в себе плюсы BFS за счет таблицы
заголовков и DFS за счет построения trie.
45
46.
FP-Growth Algorithm46
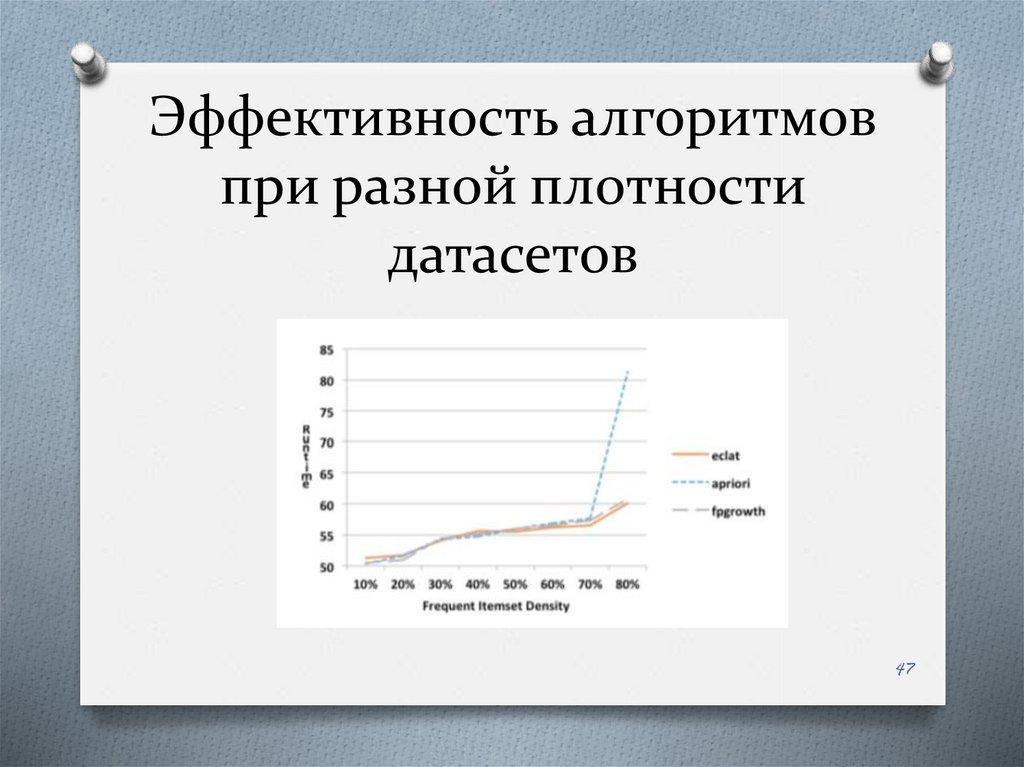
47.
Эффективность алгоритмовпри разной плотности
датасетов
47
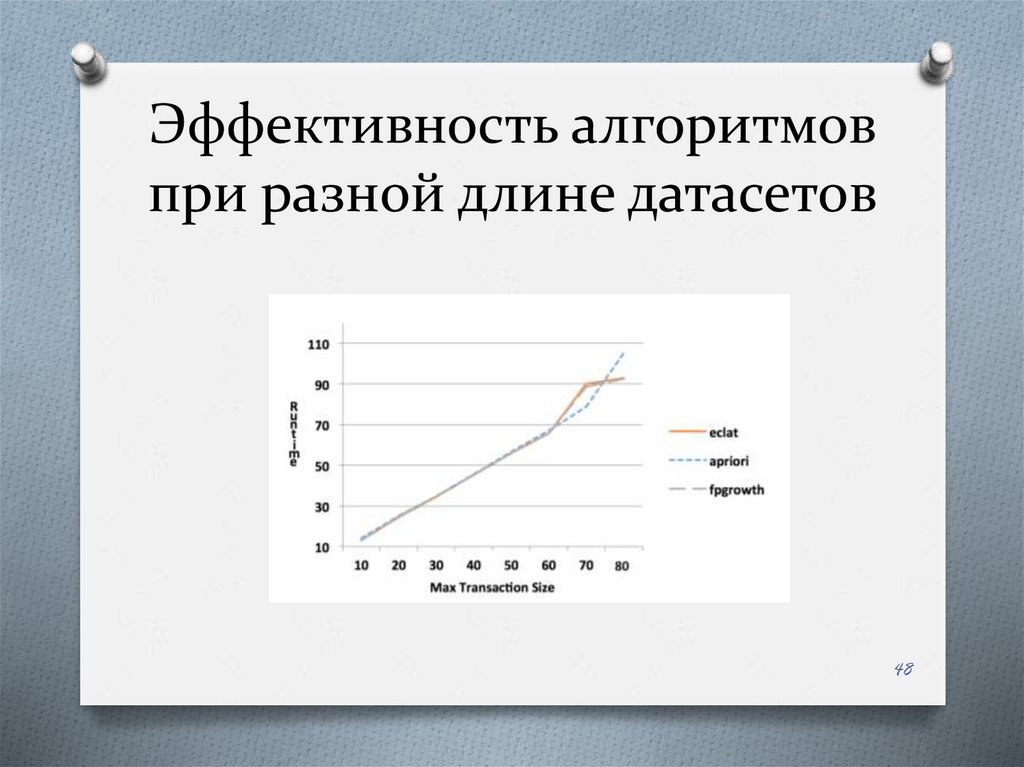
48.
Эффективность алгоритмовпри разной длине датасетов
48
49.
Другие типы обнаруженияассоциативных правил
O
Мультиассоциативные правила (англ. Multi-Relation Association
Rules, MRAR), это ассоциативные правила, в которых каждый объект
может иметь несколько связей. Эти связи показывают косвенные
связи между сущностями. Рассмотрим следующее
мультиассоциативное правило, в котором первый член состоит из
трёх отношений живёт в, рядом и влажный: «Двое, кто живут в
месте, которое находится рядом с городом с влажным климатом, и
моложе 20 лет => их состояние здоровья хорошее». Такие
ассоциативные правила могут быть получены из данных RDBMS или
семантических данных интернета.
O
Основанные на контексте ассоциативные правила являются
видом ассоциативных правил. Утверждается, что эти правила более
точны в анализе ассоциативных правил и работают путём
рассмотрения скрытой переменной, названной контекстной
переменной, которая меняет конечный набор ассоциативных правил
в зависимости от значений контекстных переменных. Например,
ориентация на покупательную корзину в анализе рыночной корзины
отражает странные результаты в начале месяца. Это может быть
вызвано контекстом, таким как выдача зарплаты в начале месяца
49
50.
СсылкиO
O
O
O
https://poisk-ru.ru/s49068t25.html?ysclid=lb6j4a7wv4299259211
https://habr.com/ru/company/ods/blog/353502/
https://ranalytics.github.io/data-mining/054-Association-Rules-Algos.html
https://loginom.ru/blog/associative-rules?ysclid=lb6ih2v5pg400749483
50