


















 Базы данных
Базы данныхПохожие презентации:


")







Как хранить данные? Витрины данных и объектные хранилища
1.
Как хранить данные?Витрины данных и объектные хранилища
Шмарловская Юлия Михайловна
Риск-аналитик (Центральный Аппарат, Сбербанк)
2.
ОглавлениеВведение
Зачем нужны витрины и система для их построения?
В чем разница между витриной данных и хранилищем?
Типы витрин
Как создать витрину данных?
Что такое AWS и Azure?
Тестирование, мониторинг, отчетность и визуализация
Объектные хранилища
3.
Ротшильд Н, основатель банковской династии Ротшильдов4.
ВведениеСколько данных создается
каждый день в 2024г?
5.
Сколько данных создается каждый день в 2024г?328.77 млн терабайт данных ежедневно
В 2024 году создается
За последние три года было создано около 90% всех мировых данных
Количество данных в мире увеличивается не менее чем на 22% в год
54% мирового трафика данных приходится на видео
Больше всего дата-центров в США, Германии и Великобритании
В 2023 году около 60% компаний по всему миру использовали большие данные для
внедрения инноваций
Размер мирового рынка больших данных достиг 349.56 млрд долларов.
6.
Внедрение Big Data в компанияхУровень внедрения больших данных остается стабильным – в 2023 году
миру использовали большие данные для внедрения инноваций.
60% компаний по всему
40% компаний управляют данными как бизнес-активом.
Компании все чаще используют данные для создания инноваций (60%) и создают культуру,
ориентированную на использование больших данных (20%).
7.
Основная информация8.
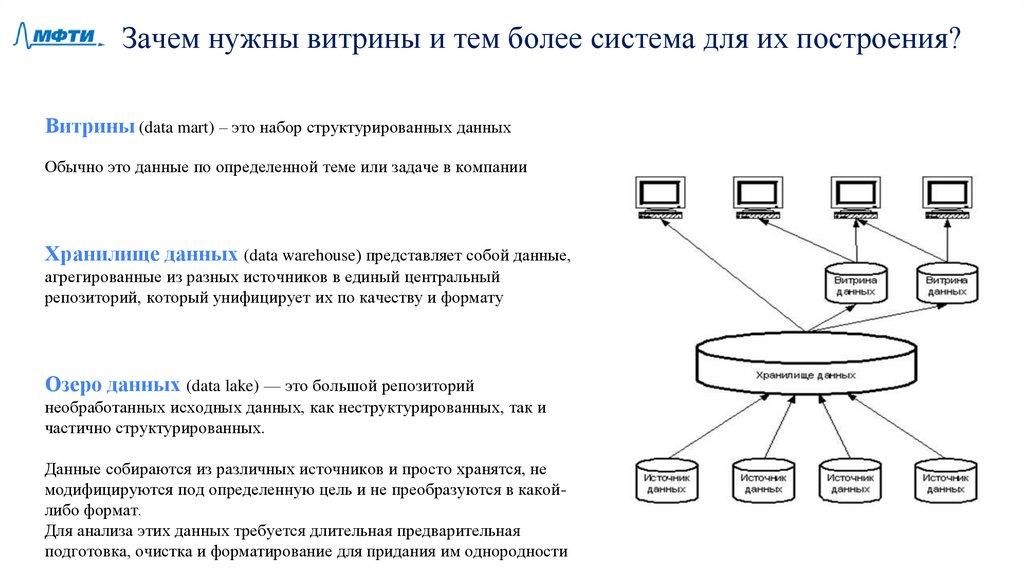
Зачем нужны витрины и тем более система для их построения?Витрины (data mart) – это набор структурированных данных
Обычно это данные по определенной теме или задаче в компании
Хранилище данных (data warehouse) представляет собой данные,
агрегированные из разных источников в единый центральный
репозиторий, который унифицирует их по качеству и формату
Озеро данных (data lake) — это большой репозиторий
необработанных исходных данных, как неструктурированных, так и
частично структурированных.
Данные собираются из различных источников и просто хранятся, не
модифицируются под определенную цель и не преобразуются в какойлибо формат.
Для анализа этих данных требуется длительная предварительная
подготовка, очистка и форматирование для придания им однородности
9.
В чем разница между витриной данных и хранилищемХранилище
Витрина данных
Используется для хранения данных из множества
предметных областей
Содержит данные, относящиеся к отделу, например витрину
транзакций, риск-индикаторов, финансов и т. д.
Действует как центральное хранилище данных
компании
Логический подраздел хранилища данных для конкретных
приложений ведомства
Сложно спроектировать и использовать из-за
большого размера (более 100 ГБ)
Сравнительно более управляем из-за небольшого
размера (менее 100 ГБ)
Является предметно-ориентированными и
зависящими от времени, при этом данные
существуют в течение более длительного
периода времени
Используются для определенных областей, связанных
с бизнесом, и сохраняют данные в течение более
короткого периода времени
10.
Типы витринЗависимые
Cоздаются путем извлечения информации напрямую из операционных систем, внешних источников или обоих
Этот тип обеспечивает преимущества централизации данных
Построение зависимой ВД в хранилище можно выполнить двумя способами:
пользователь может получить доступ как к самой витрине данных, так и к хранилищу в целом
доступ к сведениям может быть ограничен только через ВД
Независимые
ВД, которая создается без привлечения центрального хранилища данных
Не связана ни с центральным хранилищем данных компании, ни с другими ВД. Данные в независимой витрине вводятся отдельно,
и анализ проводится независимо от других источников данных
Гибридные
ВД, объединяющая вх. данные из различных источников, отличных от центрального хранилища данных.
Этот тип может быть особенно полезен в случаях, когда требуется временная интеграция
Хорошо подходит для разнообразных сред баз данных и обеспечивает быструю реализацию в любой организации. Он также
требует минимальных усилий по очистке данных.
11.
Как создать витрину данныхШаг 1: Определение требований
Необходимо определить, какие данные будут включены и какие бизнес-требования должны быть удовлетворены.
Например, для анализа продаж необходимо определить какие данные о продажах, клиентах и продуктах необходимы
Шаг 2: Согласование модели данных
Нужно согласовать модель данных с заинтересованными сторонами, чтобы убедиться, что она соответствует требованиям.
Пример: Создать схему, которая показывает связи между таблицами, такими как "Клиенты", «Транзакции" и "Продукты".
Шаг 3: Подготовка инфраструктуры
Определите необходимые ресурсы для хранения и обработки данных, например серверы, базы данных и программное
обеспечение.
Пример: Если вы используете облачное решение, выберите подходящую платформу (например, AWS или Azure) и создайте
необходимые экземпляры баз данных.
12.
Что такое AWS и AzureПредлагают реляционные и нереляционные облачные базы данных.
У AWS есть Amazon Aurora, Amazon RDS и универсальные базы данных NoSQL (Amazon DocumentDB). У Azure есть Azure
SQL, Azure Database для PostgreSQL, Azure Cosmos DB и многое другое.
AWS и Azure также предлагают комплексное руководство по развертыванию и мобильность лицензий для Microsoft SQL.
Однако Azure предлагает дополнительное преимущество гибридных преимуществ с функциями автоматического резервного
копирования. AWS и Azure также предоставляют некоторые руководства для Oracle и MySQL.
AWS
AWS ( Amazon Web Services, 2006 ) предоставляет услуги облачных вычислений компаниям
Самая популярная облачная платформа с открытым исходным кодом. Занимает самую большую долю рынка.
Azure
Облачный сервис (Microsoft,2010 г), позволяющий создавать, тестировать, развертывать и управлять приложениями и
сервисами через центры обработки данных Microsoft
Уникален, т.к. имеет больше центров обработки данных и точек доставки по сравнению с другими облачными сервисами, что
позволяет ему доставлять более быстрый контент.
Позволяет хранить любые типы данных и делиться ими между виртуальными машинами
13.
Как создать витрину данныхШаг 4: Извлечение данных (ETL)
Нужно разработать ETL-процессы для извлечения данных из источников, их трансформации и загрузки в витрину данных.
ELT - extraction, transformation и loading. Процесс сбора «сырых» данных из раздельных источников, передачи в
промежуточную базу данных для преобразования и загрузки подготовленных данных в единую целевую систему.
ETL - extraction, loading и transformation. После извлечения из баз данных данные загружаются напрямую в центральный
репозиторий, где происходят все преобразования. Промежуточная база данных отсутствует.
Пример:
Извлечение
Используйте SQL-запросы для извлечения данных из вашей основной базы данных
Трансформация
Обработайте данные для удаления дубликатов и преобразования форматов
Загрузка
Загрузите очищенные данные в витрину данных с помощью инструментов ETL (например,
Apache NiFi или Talend)
Шаг 5: Настройка доступа к данным
Нужно установите правила доступа к витрине данных для различных пользователей или групп пользователей.
Пример: Можно скрыть часть данных от пользователей, для которых эти данные не предназначены.
14.
Как создать витрину данныхШаг 6: Тестирование
Провести проверку корректности работы витрины.
Основные проверки включают в себя сравнение данных с данными в исходной системе, проверить хит, сравнить
распределения, кол-во нулей и NULL. Так же необходимо проверить что запросы к витрине обрабатывают быстро и без
ошибок
Шаг 7: Мониторинг и поддержка данных
При необходимости можно (и нужно) установить процессы мониторинга для отслеживания производительности
витрины данных и обеспечения ее корректной работы.
Для этого можно использовать инструменты мониторинга (пример, Grafana или Prometheus) для отслеживания
загрузки сервера и времени выполнения запросов. Регулярно проверяйте логи на наличие ошибок. Так же можно
настроить автоматическую рассылка на почту или на телефон об ошибках.
15.
Тестирование, мониторинг, отчетность и визуализация16.
Мониторинг данных и выявление аномалийAlmaz Monitoring (Росатом) – самообучающийся интеллектуальный мониторинг данных и выявления
аномалий
Возможности AI
Самообучающееся выявление
аномалий
и ошибок с учетом сезонности,
группировок, статистических
выбросов, специфики
предметной области и
автоматизированного анализа
поведения разнородных
данных.
Сфера применения
Озера больших разнородных
данных
Потоковые данные реального
времени
Неверифицированные данные
клиентов
Данные моделей и скоринга
Операционная и финансовая
отчетность
17.
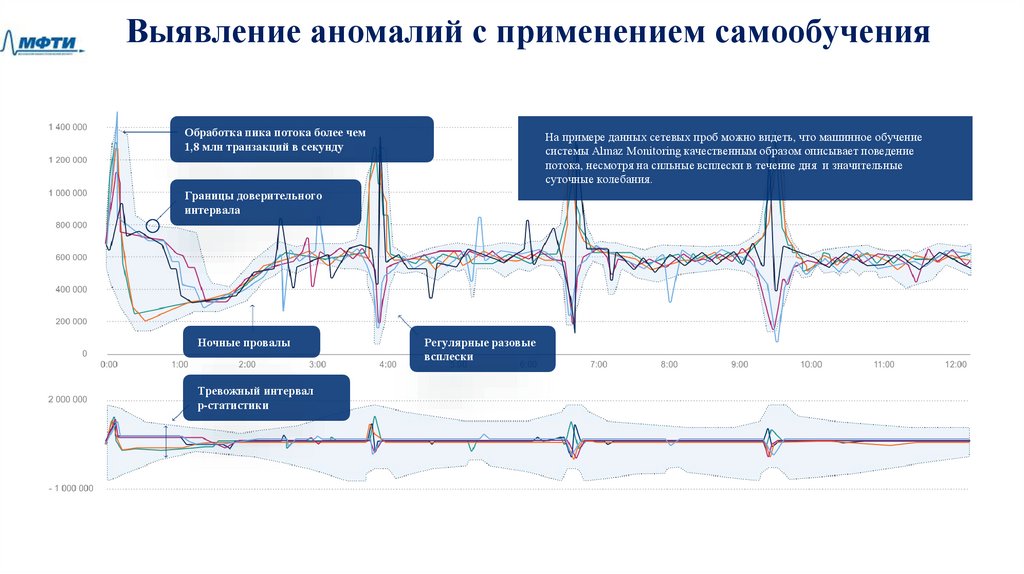
Выявление аномалий с применением самообученияОбработка пика потока более чем
1,8 млн транзакций в секунду
На примере данных сетевых проб можно видеть, что машинное обучение
системы Almaz Monitoring качественным образом описывает поведение
потока, несмотря на сильные всплески в течение дня и значительные
суточные колебания.
Границы доверительного
интервала
Ночные провалы
Тревожный интервал
р-статистики
Регулярные разовые
всплески
18.
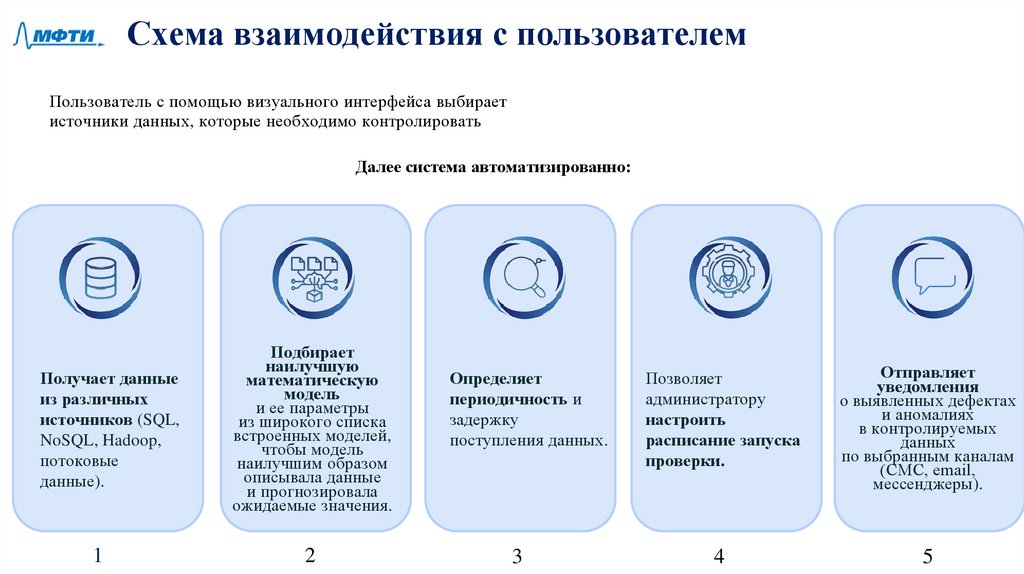
Схема взаимодействия с пользователемПользователь с помощью визуального интерфейса выбирает
источники данных, которые необходимо контролировать
Далее система автоматизированно:
Получает данные
из различных
источников (SQL,
NoSQL, Hadoop,
потоковые
данные).
1
Подбирает
наилучшую
математическую
модель
и ее параметры
из широкого списка
встроенных моделей,
чтобы модель
наилучшим образом
описывала данные
и прогнозировала
ожидаемые значения.
2
Определяет
периодичность и
задержку
поступления данных.
Позволяет
администратору
настроить
расписание запуска
проверки.
Отправляет
уведомления
о выявленных дефектах
и аномалиях
в контролируемых
данных
по выбранным каналам
(СМС, email,
мессенджеры).
3
4
5
19.
Что такое объектные хранилища?Объектные хранилища — способ хранения данных, созданный для работы с большими объемами
неструктурированной информации.
В отличие от обычных файловых систем, где файлы структурированы по папкам, они могут ссылаться друг на друга
различными путями, иметь разные уровни доступа и владельцев и в целом имеют строгую иерархию.
Примеры объектов: изображение, видео или текстовый документ.
Кроме идентификатора метаданные также содержат дополнительную информацию об объекте, такую как: дата создания, тип
файла, автор и другие атрибуты, почти не сказывающиеся на самих свойствах объекта, в отличие от аналогичных в файловой
системе, почти не сказывающиеся.
20.
Особенности объектных хранилищПреимущества
1. Масштабируемость: легко масштабируются горизонтально путем добавления новых узлов и увеличения емкости
хранилища.
2. Гибкость: можно хранить любые типы данных: от небольших текстовых файлов до крупных видеороликов (24ч+). Всё
в равной мере легко и просто контролируется через API.
3. Простота управления: нет сложностей с иерархией. Метаданные хранятся вместе с объектами, что позволяет их легко
и быстро индексировать.
4. Надежность и доступность: можно децентрализовать на физически удалённых устройствах, где данные
реплицируются на нескольких узлах, составляя при этом единую систему. Это гарантирует высокую надежность и
доступность даже в случае отказа одного или нескольких узлов
Недостатки
Не подходят для работы с большим количеством маленьких файлов и не максимально быстро происходит выполнение
операций
2. По определению не подходят для работы с данными, где нужна строгая иерархия, различные права доступа, ссылки и
т.п.
1.
21.
Применение объектных хранилищОбъектные хранилища широко используются в различных облачных сервисах и платформах, где зачастую требуется хранение и
совершение операций с большим объёмом информации
Резервное копирование и архивирование. Объектные хранилища идеально подходят для долгосрочного хранения
данных, например, для резервных копий и архивов. Особенно, когда бэкапов много, и их нужно сделать и забыть до следующего
обвала системы.
Хранение медиафайлов Как пример это может быть домашняя кинотека.
Облачные приложения. Облачные сервисы и приложения по модели SaaS или PaaS зачастую используют объектные
хранилища для хранения пользовательских данных, логов, отчетов и других неупорядоченных данных
Контейнеры и микросервисы. В контейнеризованных средах микросервисов объектные хранилища используются для
хранения и передачи данных между различными сервисами, обеспечивая переносимость и децентрализованность архитектуры
системы.