

































 Программное обеспечение
Программное обеспечениеПохожие презентации:
. Технологии облачных вычислений")






")


Разработка ПО и облачные вычисления
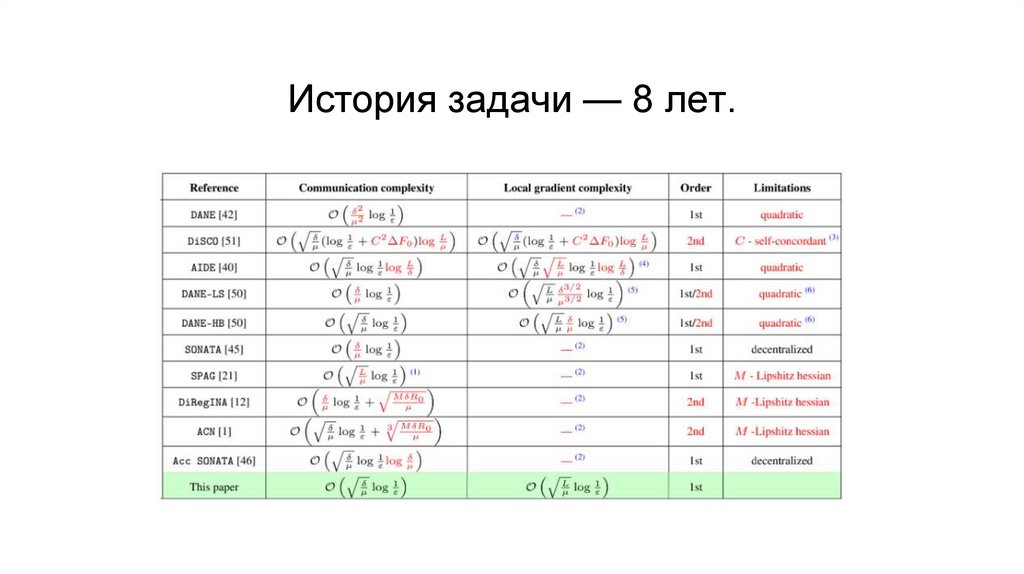
1.
Распределённаяоптимизация
Доклад по курсу
«Разработка ПО и облачные вычисления»
Онлайн-магистратуры МФТИ
Выполнил Волосатов Артём Олегович
Подготовлено на основе лекций
Александра Безносикова в МФТИ и SMILES
2.
План выступленияМотивировка и постановка проблемы
Организация коммуникаций
Сжатие
Локальные вычисления
3.
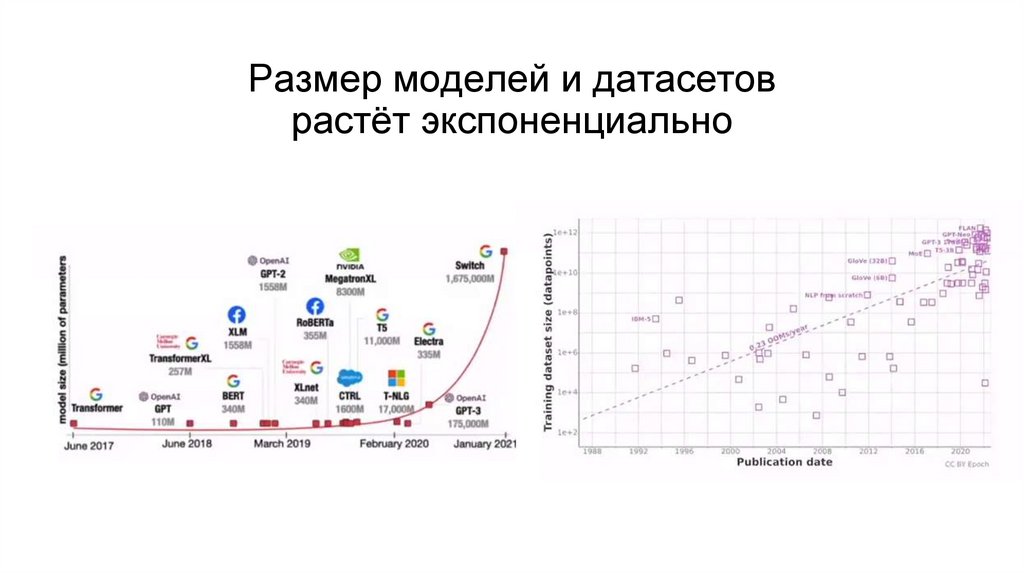
Размер моделей и датасетоврастёт экспоненциально
4.
Задача машинного обучения• Как решать?
• GD, Accelerated GD, SGD, Adam ...
• Что делать?
• Распараллеливать процесс обучения на несколько устройств
• Как это сделать?
• Распределить данные между устройствами/агентами/нодами
5.
5Виды распределённого обучения
Кластерное обучение
(Крупные игроки)
Коллаборативное обучение
(Все игроки)
Федеративное обучение
(Новая парадигма)
Обучение в пределах одного большого и
мощного вычислительного кластера
Данные разделяются равномерно,
локальные функции потерь схожи
Объединяем вычислительные ресурсы
по сети Интернет
Можем делить данные.
(неравномерно по количеству,
равномерно по природе)
Обучаемся на локальных данных
пользователей используя их
вычислительные устройства
Не можем обмениваться данными.
Разное количество и разная природа.
6.
Распределённый GDСодержание
7.
Коммуникации – главное узкое местоВыигрываем в параллельности, проиграем в коммуникациях
Проблема присутствует во всех методах
от кластерного до федеративного
8.
Типы коммуникации• Централизованная: есть некоторая машина-сервер (мастер),
с которой соединены все остальные устройства (рабочие)
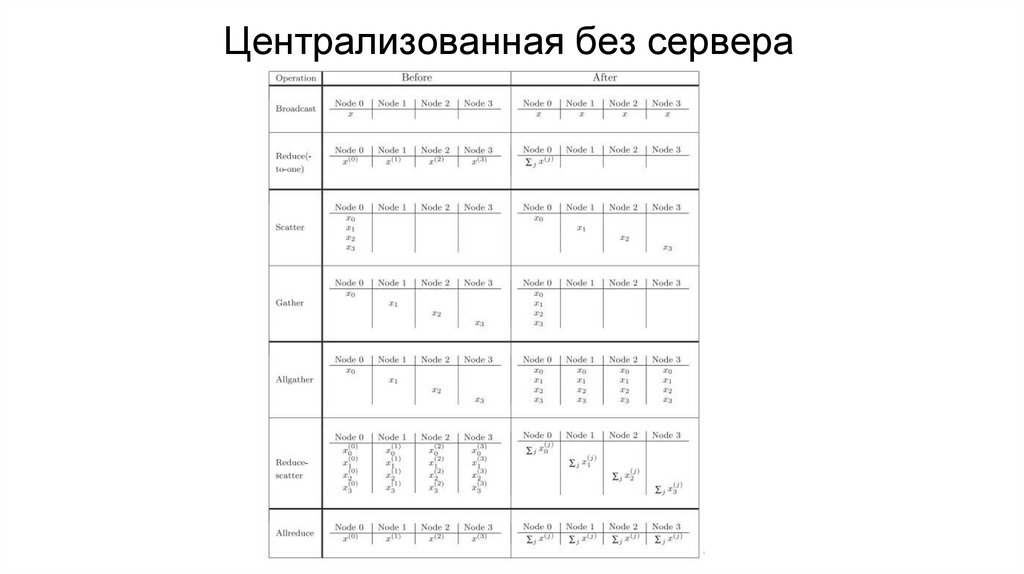
• Централизованная без сервера (в теории централизованная,
на практике нет): задан граф связей, обмен происходит
согласно этому графу
• Децентрализованная: есть граф связей, обмен происходит
согласно графу, нет полного усреднения
9.
Централизованная без сервера10.
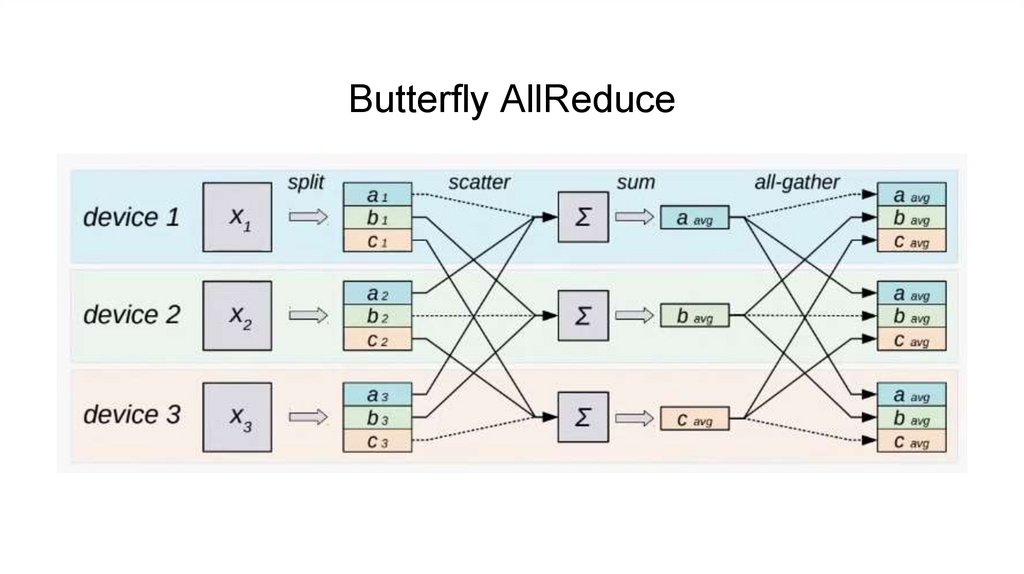
Butterfly AllReduce11.
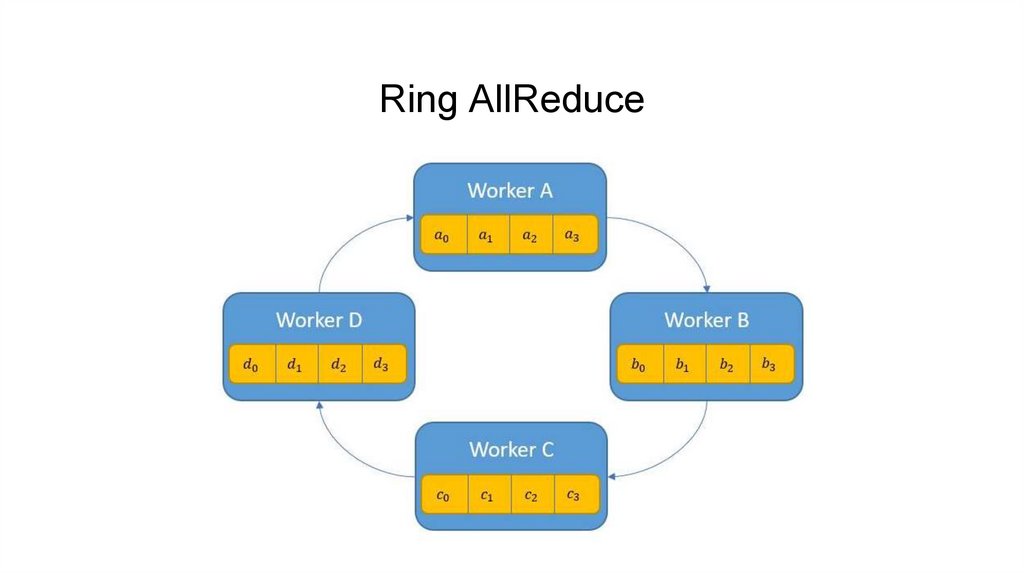
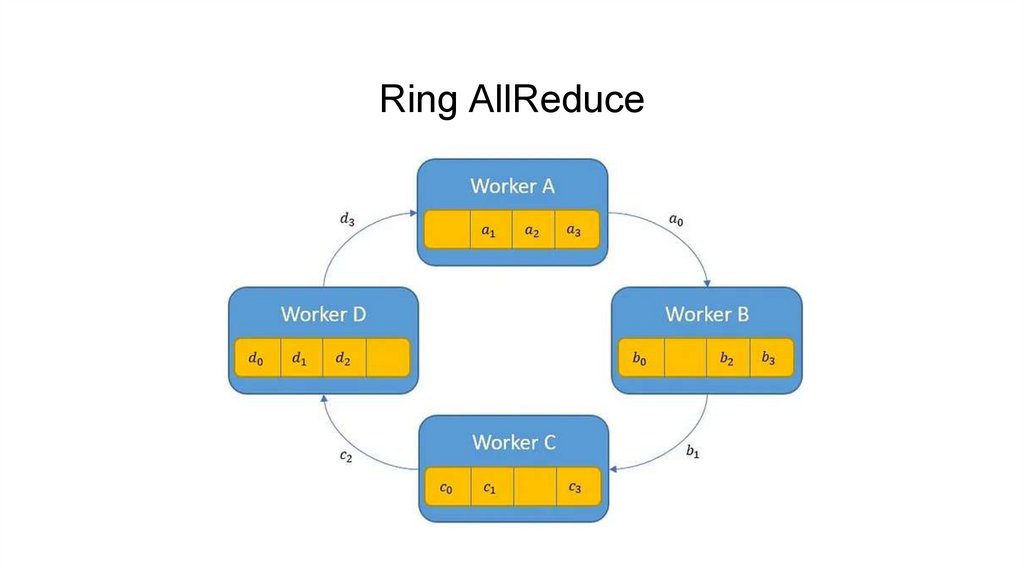
Ring AllReduce12.
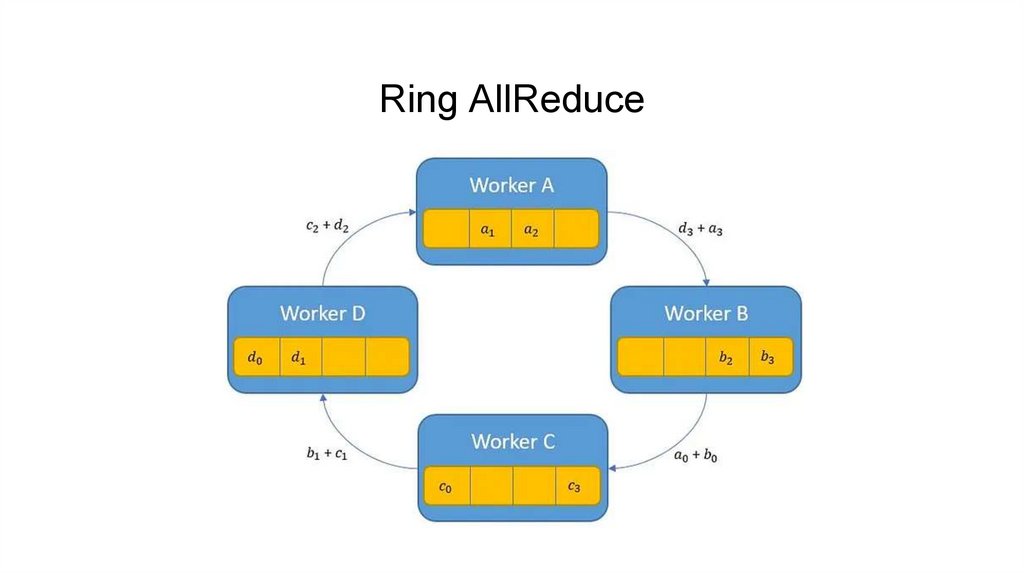
Ring AllReduce13.
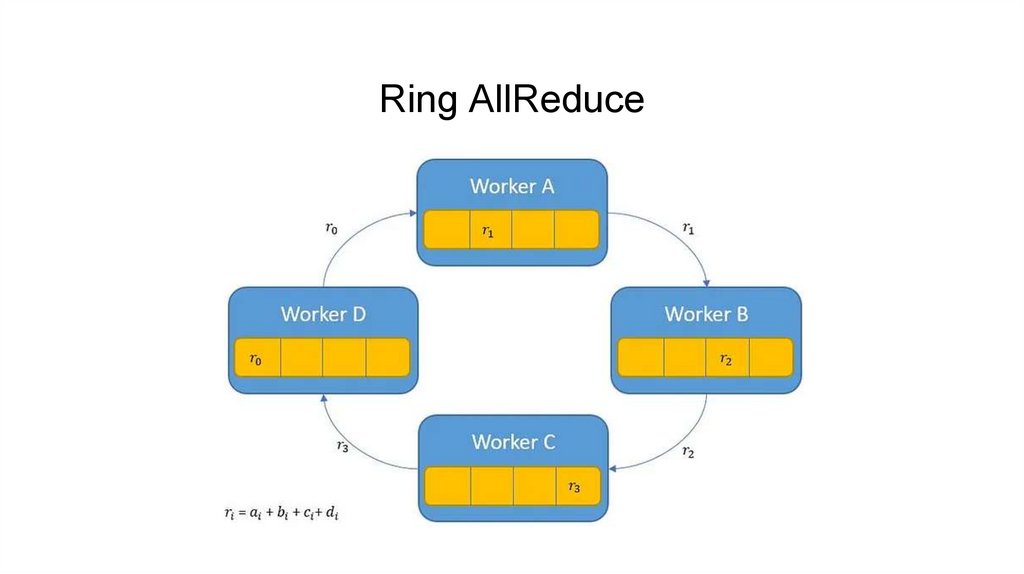
Ring AllReduce14.
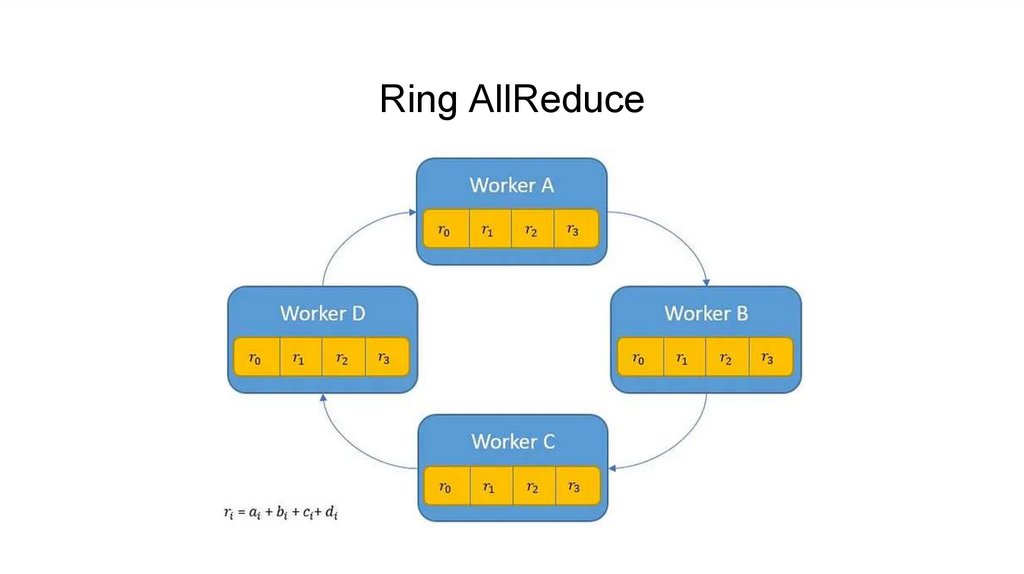
Ring AllReduce15.
Ring AllReduce16.
Несмещённая компрессия (квантизация)17.
Quantized GD (QGD)18.
Примеры несмещённой компрессии19.
Зависимый выбор случайных компонент20.
Примеры несмещённой компрессии21.
Примеры несмещённой компрессии22.
Примеры несмещённой компрессии23.
Сходимость QGD24.
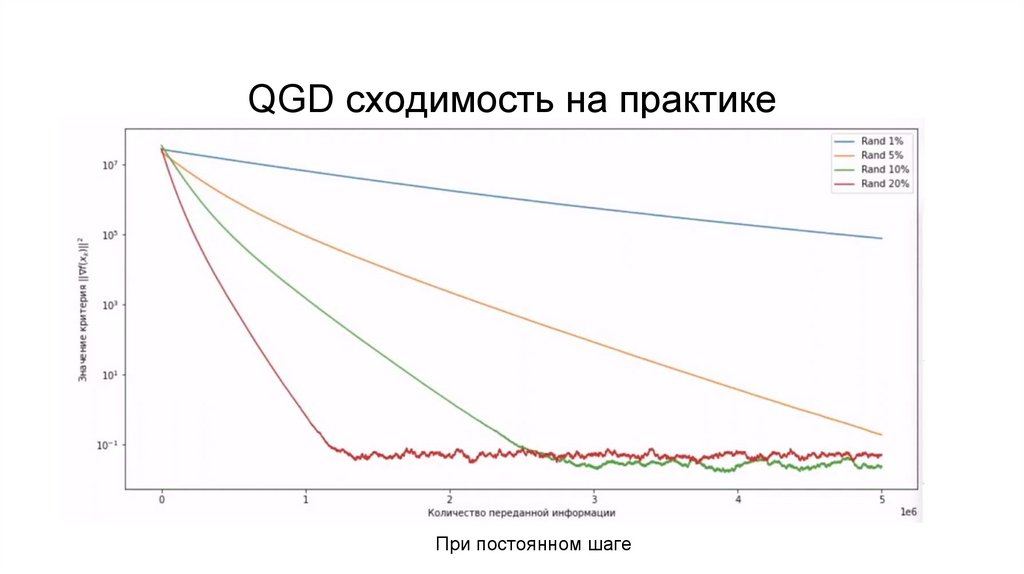
QGD сходимость на практикеПри постоянном шаге
25.
Метод DIANA – QGD с памятью26.
Сходимость DIANA:число коммуникаций
Оценка на число коммуникаций DIANA
Оценка на число коммуникаций GD
27.
Сходимость DIANA:количество информации
Компрессоры сжимают информацию в
раз
Оценка на число информации DIANA
Оценка на число информации GD
Выигрыш в числе информации в
раз
28.
Смещённая компрессияС
С
29.
Пример смещённой компрессии30.
QGD с компенсацией ошибки31.
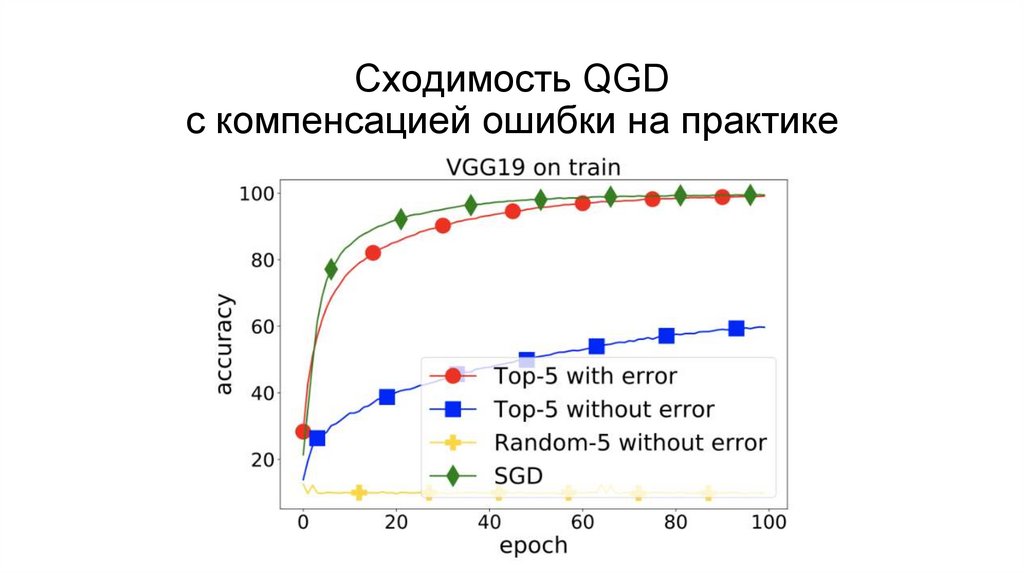
Сходимость QGDс компенсацией ошибки на практике
32.
Сходимость QGD с компенсацией ошибки33.
DIANA: память + сжатие разности34.
Несмещённая против смещённойчисло коммуникаций
Число коммуникаций DIANA
Число коммуникаций EF21
35.
Несмещённая против смещённойколичество информации
Число коммуникаций DIANA
Число коммуникаций EF21
В общем случае смещённый оператор не уменьшает число информации
36.
Идея – больше локальных вычислений• В базовом подходе коммуникации происходят каждую итерацию
• Если вычисление (стохастического) градиента значимо дешевле
коммуникаций, можно делать несколько локальных шагов между
коммуникациями
• Делаем локальные шаги
• Каждые Т шагов отправляем данные на сервер, он их усредняет
• Каждое устройство получает Х от сервера
37.
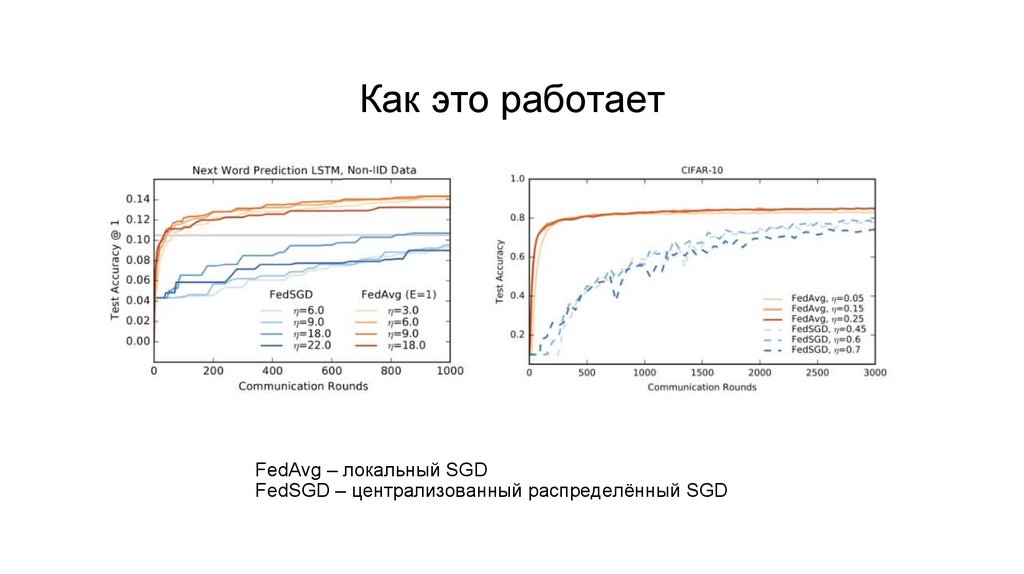
Как это работаетFedAvg – локальный SGD
FedSGD – централизованный распределённый SGD
38.
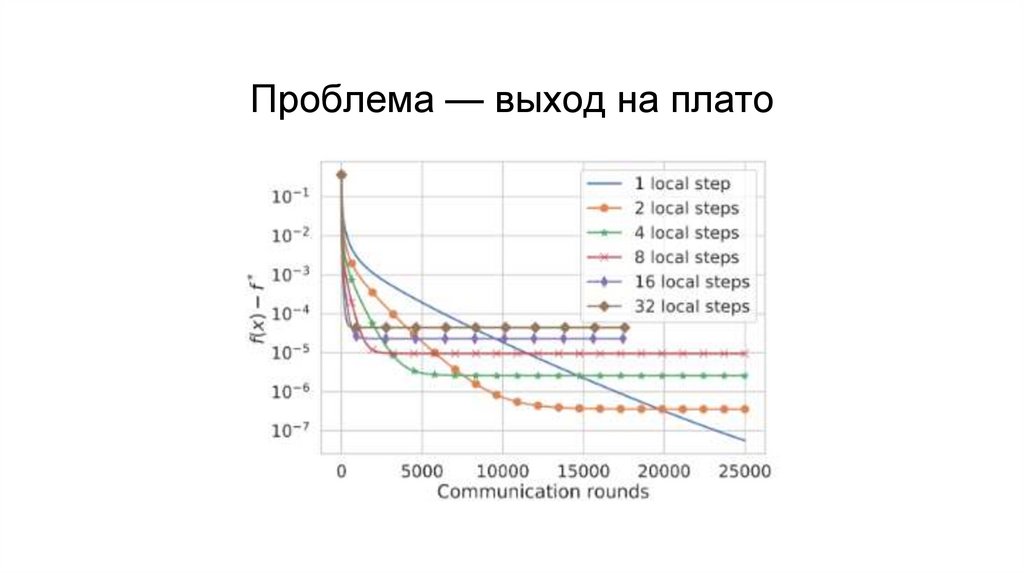
Проблема — выход на плато39.
Оценка сходимостиТеоретические оценки сходимости:\
Где гамма – размер шага, K – количество локальных итераций
40.
Помогает локальная регуляризацияРегуляризация локальной задачи
41.
Оценка сходимостиНижняя оценка на число коммуникаций:
Её даёт распределённый ускоренный градиентный спуск с одним
локальным шагом между коммуникациями.
В общем случае эта оценка не улучшается.
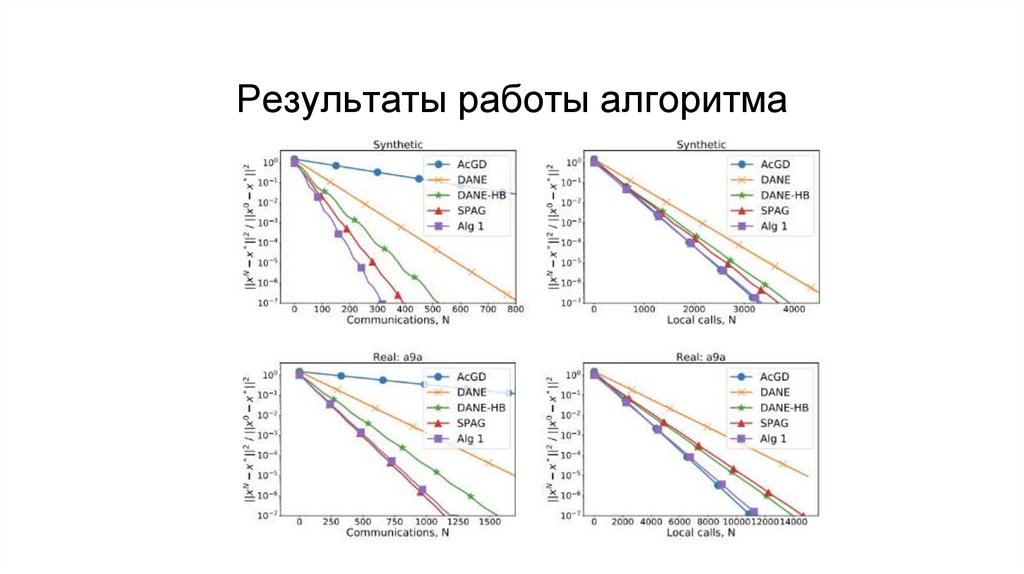
Но существую задачи, в которых локальные методы выстреливают
42.
Задача Data SimilarityРаспределённая задача обучения
Где мы можем однородно распределить данные по устройствам, например в кластере или
колаборативных вычислениях
Однородность означает, что для любого Х: