






 Интернет
ИнтернетПохожие презентации:










W compliance system
1.
masack
W
compliance
system
W
2.
3.
4.
1. Готовая предобработанная модель для аугментации данных и высокой точностью2. Анализ эффективности модели по сравнению с аналогами
3. Высокоскоростная асинхронная работа
4. Понятный и простой интерфейс
5.
6.
Перенастраиваемостьадаптивным обучением
Ансамбли
Простота(скорость)
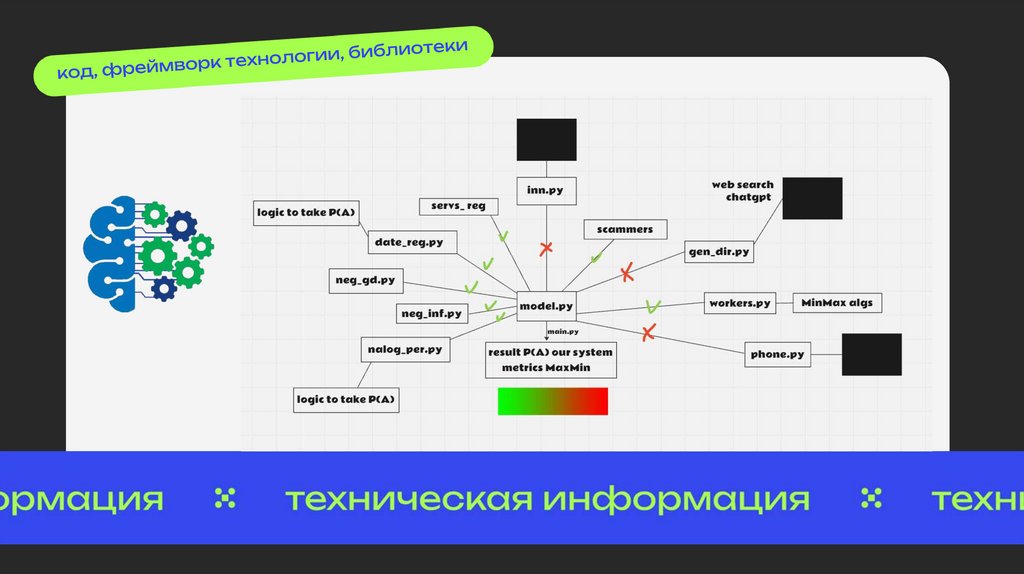
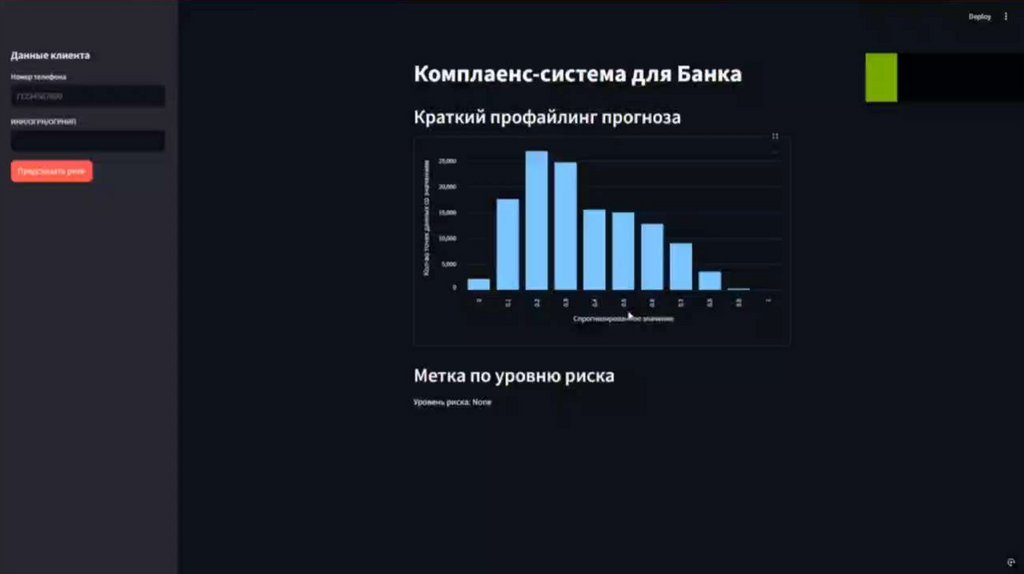
Фронтенд: streamlit
Асинхронность
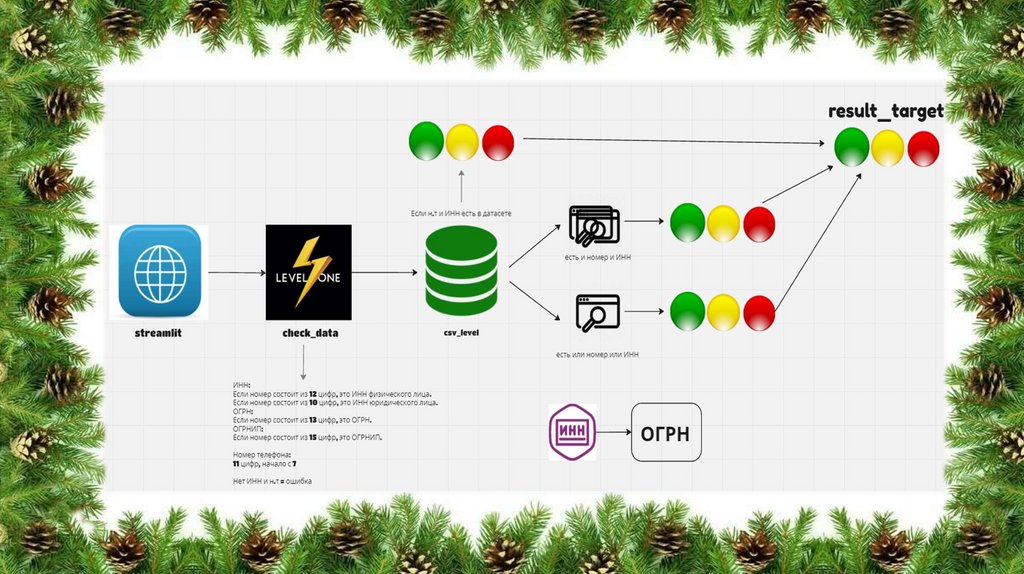
риски связанные с мошенничествами
Наша система может
импользовать жадный
алгоритм, который не позволит
Потенциальным мошенникам
обмануть систему или
провернуть спекуляцию.
Система хорошо себя
проявляет, если данные имеют
большой шум
7.
8.
КластеризацияМинусы:
1.Переобучение: Если пропуски преобладают в выборке, кластеризация может переобучиться на этих пропусках, что
приведет к неправильному разделению данных на кластеры.
2.Скорость: Кластеризационные алгоритмы, такие как K-means или DBSCAN, могут быть медленными, особенно на
больших наборах данных.
3.Интерпретируемость: Результаты кластеризации могут быть трудно интерпретируемы, особенно если данные имеют
сложную структуру.
4.Зависимость от начальных условий: Некоторые алгоритмы кластеризации, такие как K-means, могут давать разные
результаты в зависимости от начальных центроидов.
Нейронные сети
Минусы:
1.Переобучение: Нейронные сети могут переобучиться на пропусках, особенно если пропуски имеют определенное
поведение или структуру.
2.Скорость: Обучение нейронных сетей может быть медленным и требовать значительных вычислительных ресурсов.
3.Требования к данным: Нейронные сети требуют большого объема данных для эффективного обучения, что может быть
проблематично при наличии значительного количества пропусков.
4.Интерпретируемость: Нейронные сети часто являются "черными ящиками", что затрудняет интерпретацию их
результатов.
Embeddings
Минусы:
1.Переобучение: Методы на основе embeddings могут переобучиться на пропусках, особенно если пропуски имеют
определенное поведение или структуру.
2.Скорость: Обучение embeddings может быть медленным и требовать значительных вычислительных ресурсов.
3.Требования к данных: Методы на основе embeddings требуют большого объема данных для эффективного обучения,
что может быть проблематично при наличии значительного количества пропусков.
4.Интерпретируемость: Embeddings могут быть трудно интерпретируемы, особенно если они обучены на сложных
данных.
9.
Применить аугментацию и заполнить исходный датасет данными из открытых источниковПримиенить больше ансамблей для улучшения качества и объективности решения
Применить методы снижения размерности или выбрать репрезентативные признаки(features importances)
Добавить подробную статистику для анализа клиента
Использование knn, вместо minmax
AI парсер для чтения информации о клиенте по странице по н.т или ИНН
Учитывать больше признаков
учитывать подозрительные транзакции
Учитывать черный список в реестрах по н.т
Использовать дерево связей