











 Программирование
ПрограммированиеПохожие презентации:




")


")


Основи Pandas Series та DataFrame. Лекція 11
1.
Основи PandasSeries та DataFrame
Лекція 11
2.
У pandas є два види структур даних: Series та DataFrame.Series в pandas – це одновимірна структура
даних («одномірна ndarray»), яка зберігає
дані. Для кожного значення у ній є
унікальний індекс.
DataFrame - двомірна структура, що
складається з колонок та рядків. У колонок є
імена, а рядки — індекси.
3.
Серії - одновимірні масиви даних. Вони дуже схожі на списки, але відрізняються заповедінкою - наприклад, операції застосовуються до списку повністю, а в серіях поелементно.
Тобто якщо список помножити на 2, отримайте той же список, повторений 2 рази.
vector = [1, 2, 3]
vector * 2
[1, 2, 3, 1, 2, 3]
А якщо помножити серію, її довжина не зміниться, а елементи подвоїться.
import pandas as pd
series = pd.Series([1, 2, 3])
series * 2
02
14
26
dtype: int64
Зверніть увагу на перший стовпчик виводу. Це індекс, де зберігаються адреси кожного
елемента серії. Кожен елемент потім можна отримувати, звернувшись на потрібну адресу.
series = pd.Series(['foo', 'bar’])
series[0]'foo'
4.
Ще одна відмінність серій від списків - як індекси можнавикористовувати довільні значення, це робить дані наочнішими. Припустимо,
що ми аналізуємо помісячні продажі. Використовуємо як індекси назви
місяців, значеннями буде виручка:
months = ['jan', 'feb', 'mar', 'apr’]
sales = [100, 200, 300, 400]
data = pd.Series(data=sales, index=months)
data
jan 100
feb 200
mar 300
apr 400
dtype: int64
Тепер можемо набувати значення кожного місяця:
data['feb’]
200
5.
6.
ДатафреймиДатафрейми це таблиці. У них є рядки, колонки та клітини
(осередки). Технічно, колонки датафреймів – це серії. Оскільки в
колонках зазвичай описують одні й самі об'єкти, то всі колонки
мають один і той же індекс.
Існує кілька способів створити data frame. Найчастіше
використовують конструктор і передають дані у вигляді
двовимірного списку, кортежу чи масиву NumPy. Також їх можна
переформатувати на словник, Pandas Series або інші типи даних.
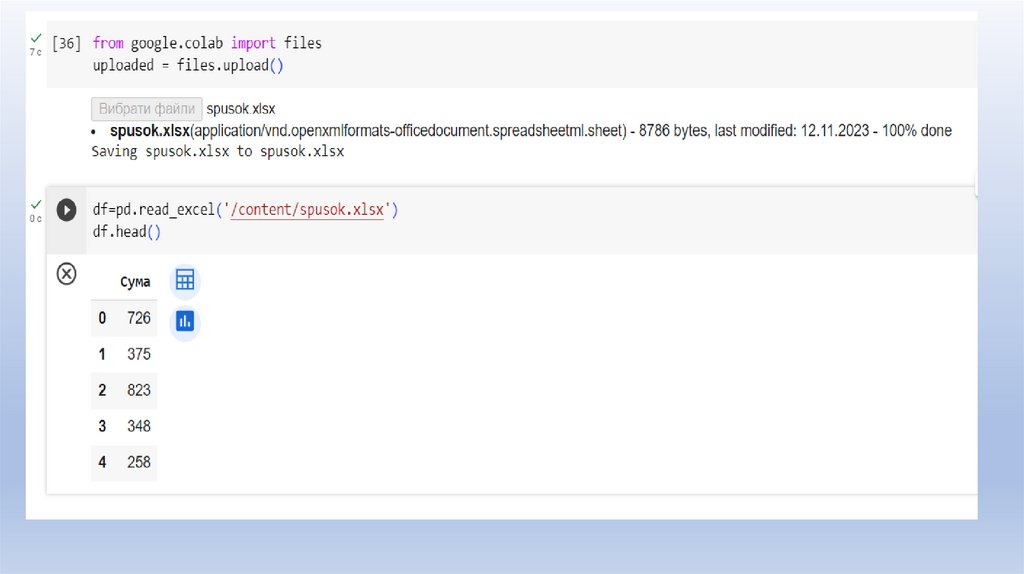
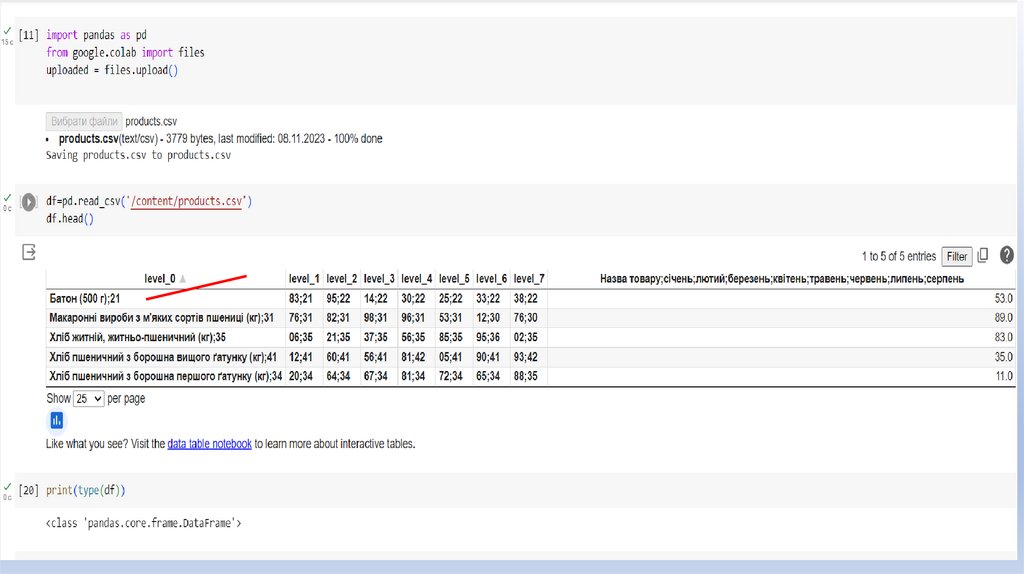
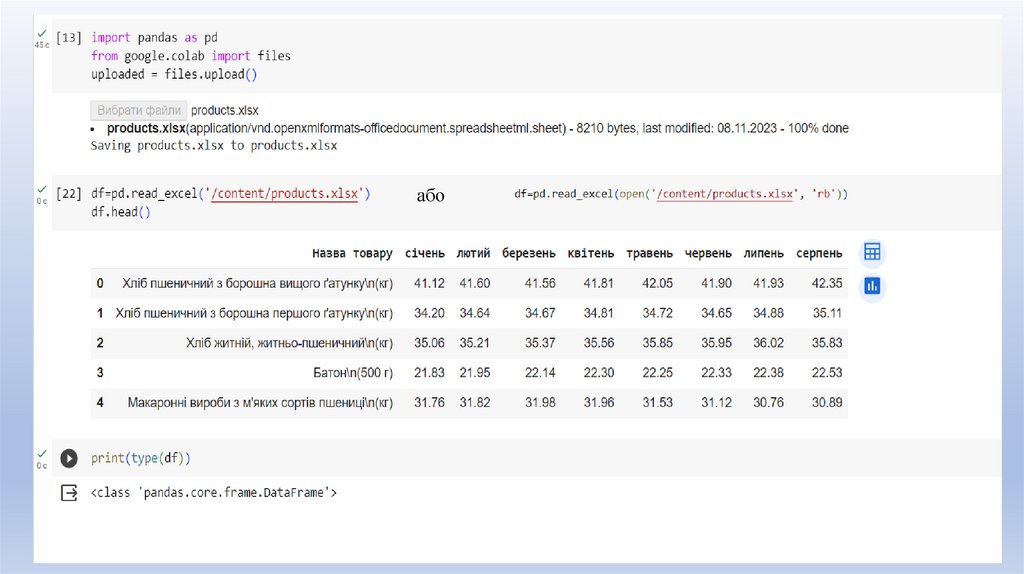
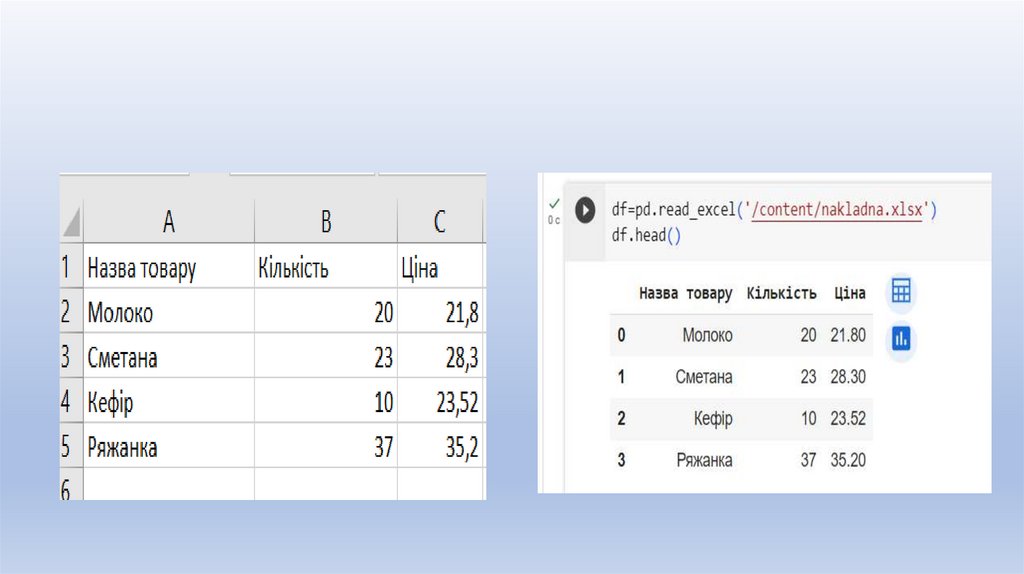
Можна завантажити із файлів CSV, Excel, SQL, JSON.
7.
Після створення DataFrame, можна отримувати з нього інформацію.Для цього типу об'єктів у Pandas доступні такі дії:
• отримання та зміна міток рядків та стовпців у вигляді
послідовностей;
• представлення даних як масивів NumPy;
• перевірка та налаштування типів даних;
• аналіз розмірів об'єктів DataFrame.
8.
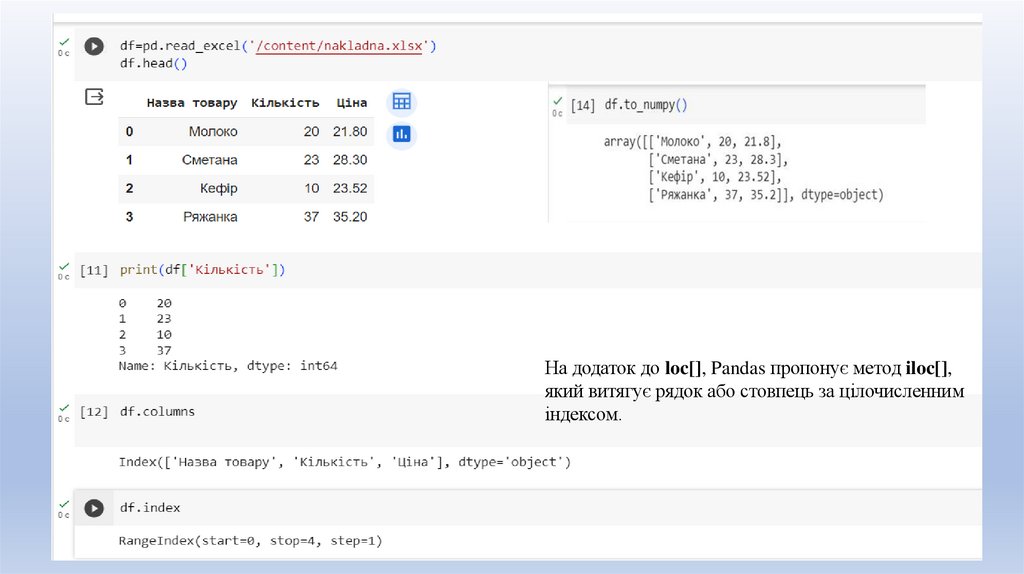
Можна отримати мітки рядків DataFrame за допомогою атрибутів index та міткистовпців за допомогою columns:
df.index
df.columns
Іноді може знадобитися витягти дані з Pandas DataFrame без тегів. Щоб отримати
масив NumPy з немаркованими даними, використовується метод to_numpy() або
властивість values:
df.to_numpy() # рекомендовано використовувати
df.values
Типи даних, або dtypes, важливі, оскільки визначають обсяг пам'яті, який
використовує ваш DataFrame, швидкість обчислень та рівень точності розрахунків.
df.dtypes
Атрибути ndim, size та shape відображають, відповідно, кількість вимірювань,
кількість значень даних щодо кожного виміру та загальну кількість значень даних:
df_.ndim # для DataFrame-2, для Series-1
df_.shape # (кількість рядків, кількість колонок)
df_.size
# загальна кількість елементів
9.
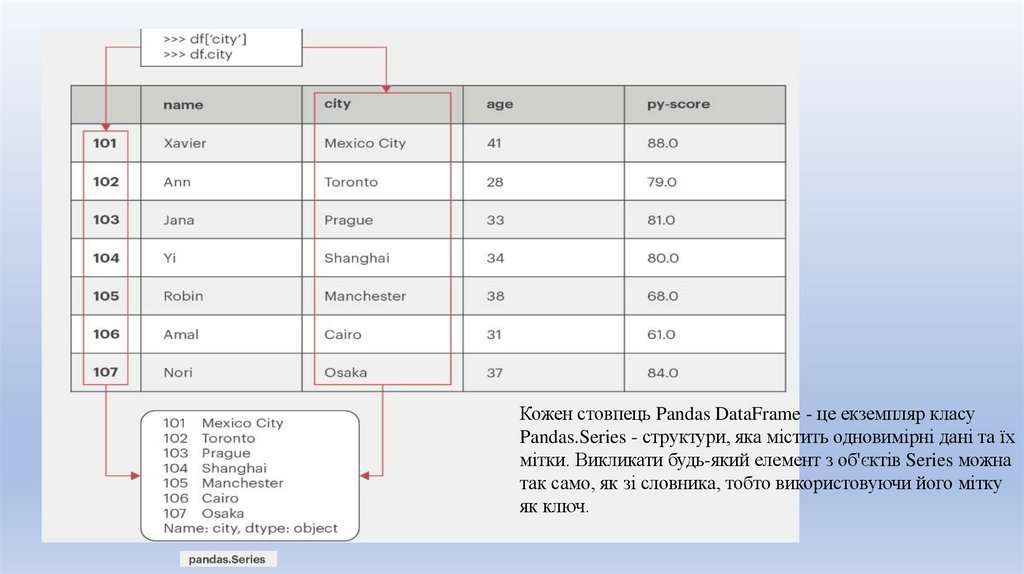
Кожен стовпець Pandas DataFrame - це екземпляр класуPandas.Series - структури, яка містить одновимірні дані та їх
мітки. Викликати будь-який елемент з об'єктів Series можна
так само, як зі словника, тобто використовуючи його мітку
як ключ.
10.
11.
або12.
13.
14.
15.
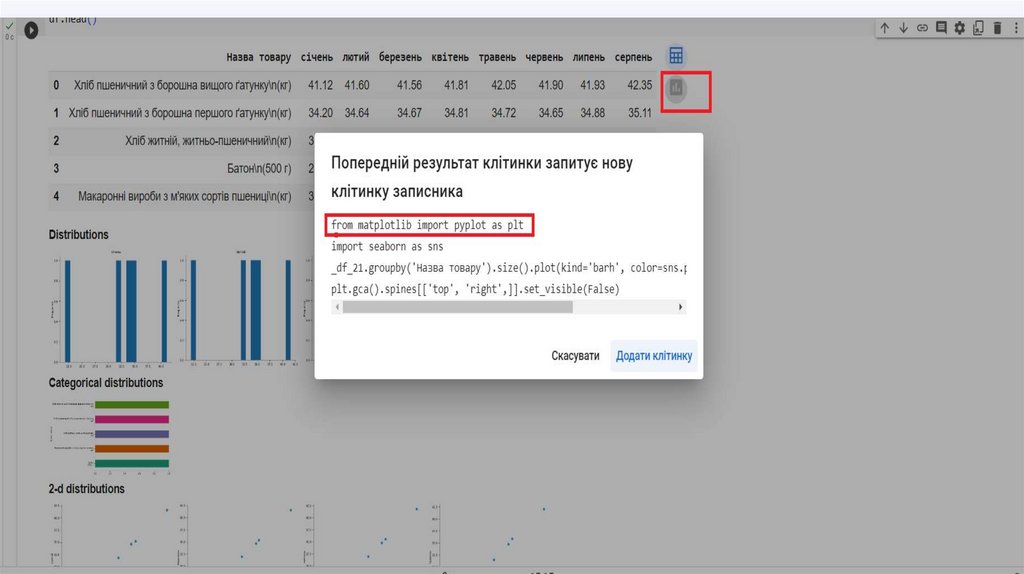
На додаток до loc[], Pandas пропонує метод iloc[],який витягує рядок або стовпець за цілочисленним
індексом.
16.
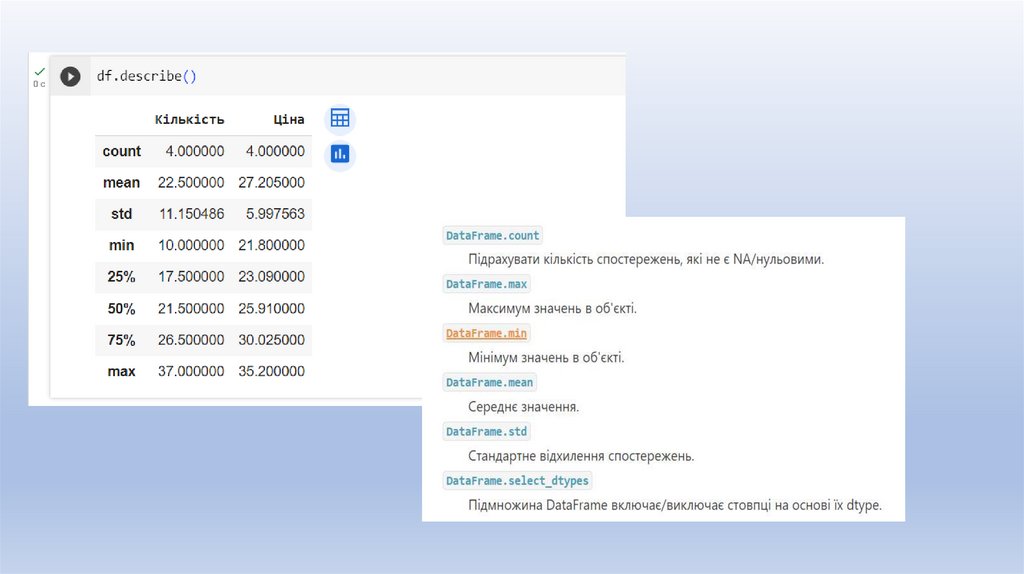
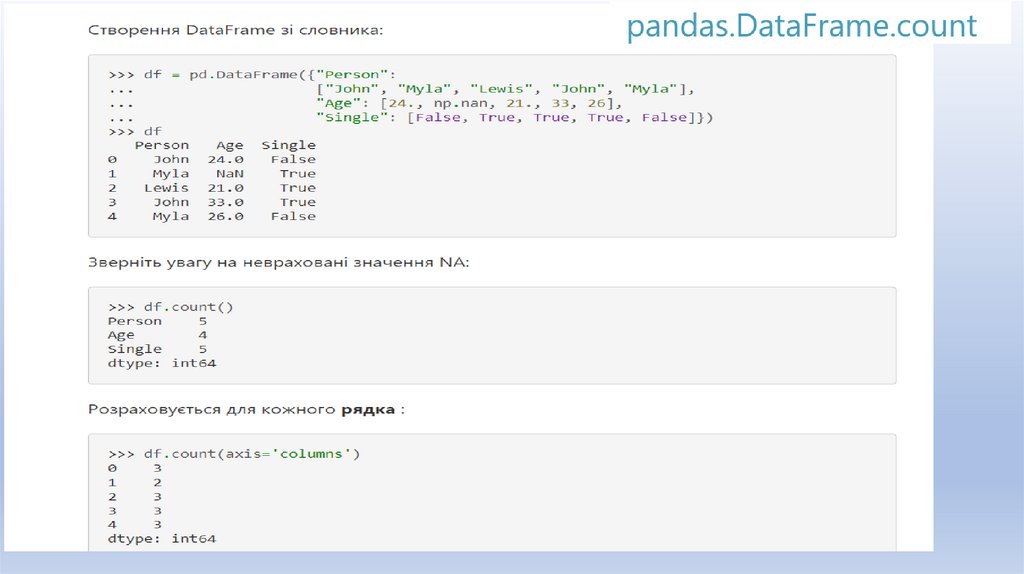
Статистичні розрахункиМетод describe() повертає новий DataFrame з кількістю рядків,
вказаним у count, а також середнім значенням, стандартним
відхиленням, мінімумом, максимумом та квартилами стовпців.
Якщо необхідно отримати конкретну статистику для деяких або
всіх ваших стовпців, можна викликати такі методи, як mean() або
std().
При застосуванні Pandas DataFrame ці методи дозволяють видати
Series з результатами для кожного стовпця. При застосуванні до
об'єкта Series або одного стовпця будуть видані скаляри.
17.
18.
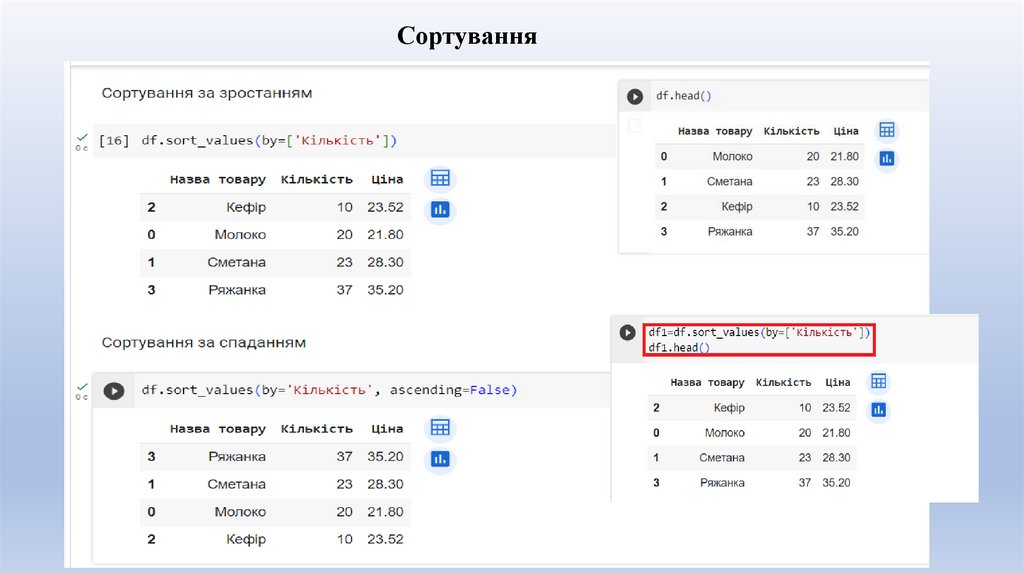
Сортування19.
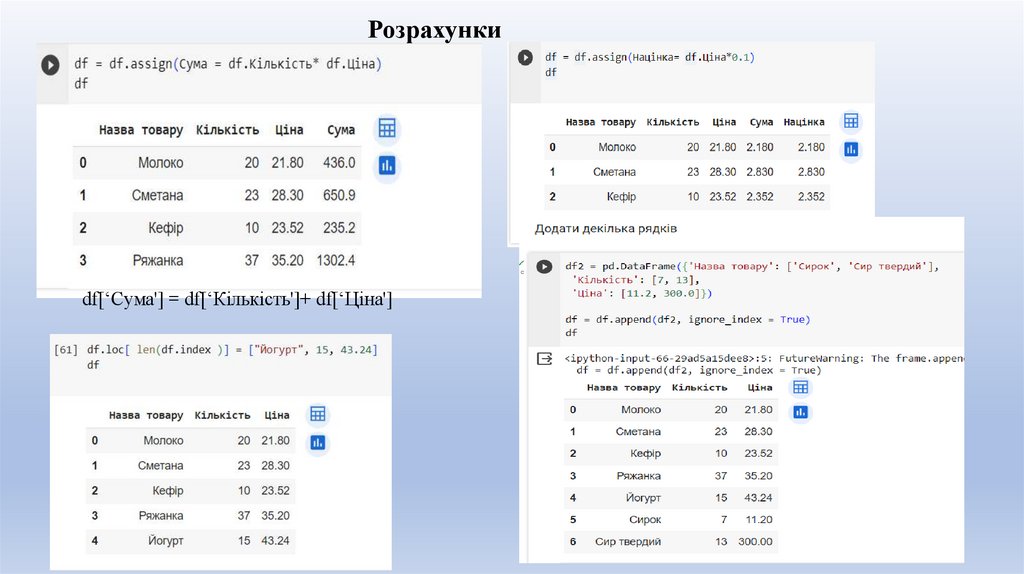
Розрахункиdf[‘Cума'] = df[‘Кількість']+ df[‘Ціна']
20.
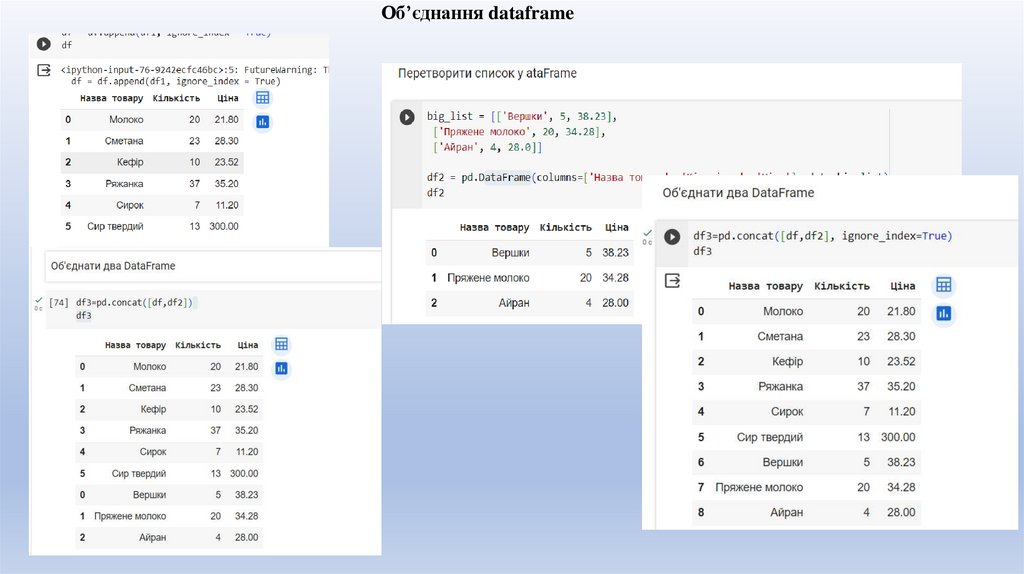
Об’єднання dataframe21.
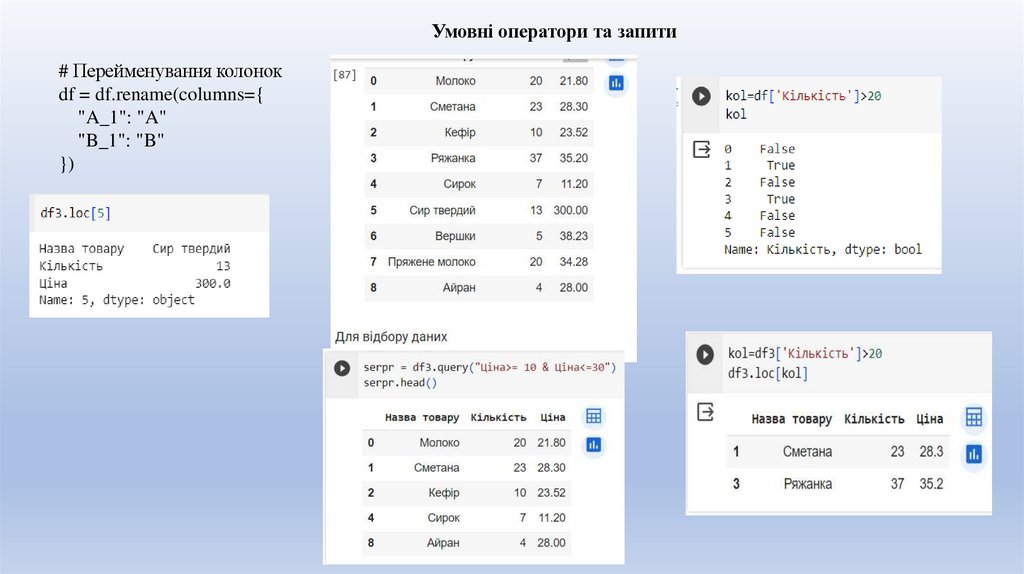
Умовні оператори та запити# Перейменування колонок
df = df.rename(columns={
"A_1": "A"
"B_1": "B"
})
22.
23.
Як зберегти dataframe у csv файл (python)CSV (від англ. comma-separated values 'значення, розділені комою',
іноді character-separated values 'значення, розділені символом') —
файловий формат для представлення табличних даних, у якому поля
відокремлюються символом коми (або крапкою з комою) та переходу на
новий рядок.
Поля, що містять коми, декілька рядків, або лапки (позначаються
подвійними лапками), мають обмежуватися з обох боків лапками. CSV
формат простий та зручний для програмної обробки, тому його часто
використовують для збереження різноманітних табличних даних з метою
подальшої обробки їх різноманітними програмами. Практично усі
сучасні мови, які займаються обробкою даних, мають зручні функції для
читання даних у даному форматі.
24.
Для збереження DataFrame у csv файл у Pythonвикористовується метод(функція) to_csv() класу pandas
import pandas as pd
df=pd.DataFrame({"Years": [1990, 1991, 1992, 1993, 1994, 1995, 1997],
"Price1": [1, 5, 6, 10, 8, 9, 2],
"Price2": [5, 6, 7, 8, 9, 15, 12], })
df.to_csv(r"C:\data\report_df.csv", index=False, sep=";")
r спереду адресу означає, що не потрібно враховувати службові символи у рядку
шляху. Без r у windows шлях прийшлось би писати через дві косі риски, так:
df.to_csv("C:\\data\\report_df2.csv", index=False, sep=";")
25.
Найбільш корисні аргументи методу to_csv наведено в таблиці.26.
Використані джерелаhttps://pandas.pydata.org/pandasdocs/stable/reference/api/pandas.DataFrame.describe.html#pandas.Data
Frame.describe pandas.DataFrame
https://w3schoolsua.github.io/python/index.html#gsc.tab=0
Python Підручник