


















 Информатика
ИнформатикаПохожие презентации:






")



Предобработка данных. Разделение данных, масштабирование, кодирование категорий, отбор признаков, балансировка классов
1.
Предобработкаданных
Разделение данных,
масштабирование,
кодирование
категорий, отбор
признаков,
балансировка
классов
2.
Разделениеданных
Метод:
train_test_split
Разделяет
данные на
обучающую и
тестовую
выборку
(80/20)
3.
X – это матрица признаков(фичи), а y – целевая
переменная.
Данные случайным образом
разбиваются на две части:
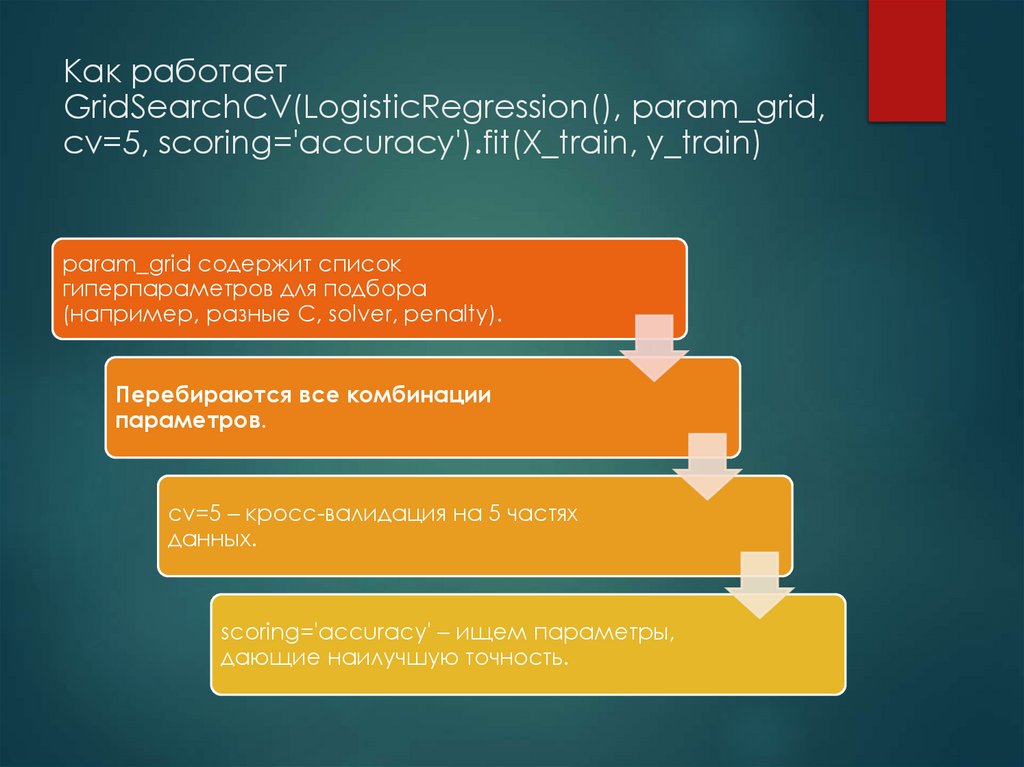
Как
работает
80% (train) – для обучения модели.
train_test_split(X, y, test_size=0.2, random_state=42)
20% (test) – для проверки модели.
random_state=42 делает
разбиение детерминированным,
т.е. при каждом запуске оно
будет одинаковым.
4.
Масштабированиеданных
Метод:
StandardScaler
Приводит
признаки к
среднему 0 и
дисперсии 1
5.
Как работаетStandardScaler().fit_transform(df)
•Стандартное
масштабирование
(Z-score normalization):