




























")







































 Информатика
Информатика Базы данных
Базы данныхПохожие презентации:


")





")

Большие данные в информационных системах
1. Большие данные в информационных системах
БОЛЬШИЕ ДАННЫЕ ВИНФОРМАЦИОННЫХ
СИСТЕМАХ
Серия подходов, инструментов и методов обработки
структурированных и неструктурированных данных
огромных объёмов
2. big data - Анализ - Google Trends
BIG DATA - АНАЛИЗ - GOOGLE TRENDS3. BBB
• B – данных много это когда данных больше, чем 100Гб (500Гб, 1ТБ• B – данных немного, но они поступают постоянно с большого
количества датчиков, скорость поступления данных больше, чем
скорость обработки
• В – разнообразие данных (часть в СУБД, часть в файлах, часть с
датчиков)
4. Примеры больших данных
ПРИМЕРЫ БОЛЬШИХ ДАННЫХ• Анализ ДНК
• Обработка картинок и видео
• Логи поведения пользователей в интернете
• GPS-сигналы от автомобилей для транспортной компании
• Информация о транзакциях всех клиентов банка
• Информация о всех покупках в крупной ритейл сети и т.д.
5. Варианты работы с большими данными
ВАРИАНТЫ РАБОТЫ С БОЛЬШИМИДАННЫМИ
• Горизонтальное расширение
• Много данных – деление на сервера + сбор данных вместе (например, подсчёт
суммы по каждому и общий подсчёт) – идея принадлежит Google
• + - неограниченная расширяемость (можно докупить сервера для обработки данных)
• - так как серверов много и потенциально не самые дорогие сервера –существует
проблема выхода из строя дисков для хранения данных, требуется отслеживать
работу серверов и корректно обрабатывать эту информацию
Понятие хорошего алгоритма – алгоритм может легко распараллелить на
k отдельных серверов при любом количестве k
6. Горизонтальное масштабирование
ГОРИЗОНТАЛЬНОЕМАСШТАБИРОВАНИЕ
разбиение системы на более
мелкие структурные
компоненты и разнесение их
по отдельным физическим
машинам (или их группам), и
(или) увеличение
количества серверов,
параллельно выполняющих
одну и ту же функцию
7. Три вида архитектур
ТРИ ВИДА АРХИТЕКТУР8. Shared memory архитектура
SHARED MEMORY АРХИТЕКТУРА• Классическая архитектура
• Если данные помешаются
• Процессоры делят диск и делят память
9. Shared disk
SHARED DISK• У каждого процессора используется отдельная оперативная память, а
жёсткий диск общий, что позволяет обрабатывать больше данных и
более расширяемая
10. Shared nothing
SHARED NOTHING• Ничего не «шарим»
компьютеры – это сеть
между
процессорами,
что
объединяет
• Принесение расчётов к данным
• Расчётные мощности принести ближе к данным
• Когда в результате предварительной обработки данных их
становиться меньше, тогда через сеть можно передать меньший
объём данных
11. Хранение данных
HDFS –распределённая
система хранения
данных
ХРАНЕНИЕ ДАННЫХ
12. +
• Перенос расчётные мощности к данных• Хранение копии данных
• Проверка работоспособности данных (если не работает одна из копий,
создаётся ещё одна, синхронизация данных и т.д.)
• Расширение на тысячи серверов
13. Принципы работы с большими данными
ПРИНЦИПЫ РАБОТЫ С БОЛЬШИМИДАННЫМИ
• Горизонтальная масштабируемость
• любая система, которая подразумевает обработку больших данных, должна быть расширяемой
• Отказоустойчивость
• Методы работы с большими данными должны учитывать возможность таких сбоев и
переживать их без каких-либо значимых последствий
• Локальность данных
• По возможности обрабатываем данные на той же машине, на которой их храним
14. ACID
Требования ACID — набор требований,которые обеспечивают сохранность
данных
Consistency —
Согласованность
Транзакция, достигающая
своего нормального
завершения (EOT — end of
transaction, завершение
транзакции) и, тем самым,
фиксирующая свои
результаты, сохраняет
согласованность базы
данных
Durability — Надёжность
Если пользователь получил
подтверждение от системы,
что транзакция выполнена,
он может быть уверен, что
сделанные им изменения не
будут отменены из-за
какого-либо сбоя
Atomicity —
Атомарность
гарантирует,
что каждая
транзакция
будет
выполнена
полностью или
не будет
выполнена
совсем. Не
допускаются
промежуточные
состояния
Isolation —
Изолированность
Во время выполнения
транзакции
параллельные
транзакции не
должны оказывать
влияния на её
результат
ACID
15. BASE
NoSQL были задуманы как БД дляаналитики в режиме реального времени,
и чтобы достигнуть бОльшую скорость,
они пожертвовали согласованностью
• BASE — это своеобразный контраст ACID, который говорит нам, что истинная
согласованность не может быть достигнута в реальном мире и не может быть
смоделирована в высокомасштабируемых системах
• Basic Availability. Система отвечает на любой запрос, но этот ответ может быть содержать
ошибку или несогласованные данные
• Soft-state. Состояние системы может меняться со временем из-за изменений конечной
согласованности
• Eventual consistency (конечная согласованность). Система, в конечном итоге, станет
согласованной. Она будет продолжать принимать данные и не будет проверять каждую
транзакцию на согласованность
16. CAP theotem
CAP THEOTEM• Теорема была представлена на симпозиуме по
распределенных вычислений в 2000 году Эриком Брюером
принципам
• В CAP говорится, что в распределенной системе возможно выбрать
только 2 из 3-х свойств:
• C (consistency) — согласованность. Каждое чтение даст вам самую последнюю
запись
• A (availability) — доступность. Каждый узел (не упавший) всегда успешно
выполняет запросы (на чтение и запись)
• P (partition tolerance) — устойчивость к распределению. Даже если между узлами
нет связи, они продолжают работать независимо друг от друга
17. CAP theotem – Consistency, Availability, Partirioning
CAP THEOTEM –CONSISTENCY, AVAILABILITY, PARTIRIONING
• Поддержка 2 из 3-х возможностей (A+P чаще всего)
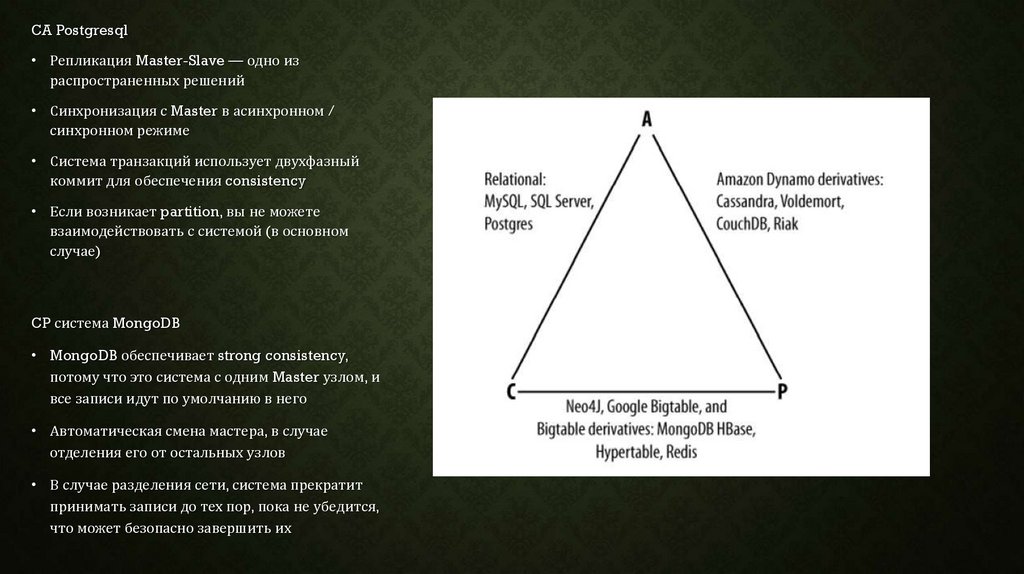
18.
CA Postgresql• Репликация Master-Slave — одно из
распространенных решений
• Синхронизация с Master в асинхронном /
синхронном режиме
• Система транзакций использует двухфазный
коммит для обеспечения consistency
• Если возникает partition, вы не можете
взаимодействовать с системой (в основном
случае)
CP система MongoDB
• MongoDB обеспечивает strong consistency,
потому что это система с одним Master узлом, и
все записи идут по умолчанию в него
• Автоматическая смена мастера, в случае
отделения его от остальных узлов
• В случае разделения сети, система прекратит
принимать записи до тех пор, пока не убедится,
что может безопасно завершить их
19. Теорема PACELC была впервые описана и формализована Даниелом Дж. Абади из Йельского университета в 2012 году
ТЕОРЕМА PACELC БЫЛА ВПЕРВЫЕ ОПИСАНАИ ФОРМАЛИЗОВАНА ДАНИЕЛОМ ДЖ. АБАДИ
ИЗ ЙЕЛЬСКОГО УНИВЕРСИТЕТА В 2012 ГОДУ
• PACELC основана на CAP, она также использует его определения
• Latency — это время, за
которое клиент получит
ответ и которое
регулируется каким-либо
уровнем consistency
(согласованности)
• Latency (задержка), в
некотором смысле
представляет собой
степень доступности
20. NoSQL базы данных
• SQL поддерживаетцелостность данных –
классическая база данных
поддерживает целостность
данных
• Для NoSQL это не всегда
возможно
• Часто хранение данных в
трёх копиях, две в одном
датацентре, одна копия в
другом датацентре
• В каком-то моменте все
данные будут единичны на
всех копиях
NOSQL БАЗЫ ДАННЫХ
21. NoSQL для неструктурированных данных
NOSQL ДЛЯ НЕСТРУКТУРИРОВАННЫХДАННЫХ
• Компания 10gen начала разрабатывать MongoDB в середине 2007 года в рамках
проекта «программная платформа как услуга»
• Данная технология баз данных стала очень популярной и сейчас это один из
классических примеров NoSQL-систем
• Появилась потребность хранить данные без определённой структуры
• Важная особенность NoSQL — множество типов баз данных, разработанных и
оптимизированных для конкретных видов моделей данных (документной, графовой,
колоночной или «ключ — значение»)
22. Типы NoSQL баз данных
ТИПЫ NOSQL БАЗ ДАННЫХ23. Ключ-значение
КЛЮЧ-ЗНАЧЕНИЕ• Хранение данных в виде ключ-значение
• Используется хэш-таблицы
• Хорошо расширяемость достигается, что можно по ключу найти
сервер, внутри сервера найти данные и их вернуть
• Это позволяет хранить данные на большом количестве серверов
• Виды операций
• сохранить данные
• прочитать данные
• Поиск реализован за счёт отдельной подсистемы
• Применение
–
модернизируются
когда
данные
часто
читаются,
редко
24. Extensible record
EXTENSIBLE RECORD• Не просто ключ значение
• Выглядит как таблицы в классической базе данных
• Одна из колонок – ключ, остальные значения определённых типов,
таких значений может быть много, колонки можно добавлять «на
лету»
• Можно искать по любому полю, не только по ключу, можно
фильтровать и сортировать
• Нельзя соединять данные между собой, нет транзакций
25. Document Store – хранилище документов
DOCUMENT STORE – ХРАНИЛИЩЕДОКУМЕНТОВ
• Можно представить как расширение предыдущей модели
• Объектная база данных, поддерживает связь между таблицами
• Поддерживает некую транзакционность
26. Graph DB графические базы данных
GRAPH DB ГРАФИЧЕСКИЕ БАЗЫ ДАННЫХ• Хранят данные в виде графов
• Существуют запросы по таким системам
• Хорошо масштабируются
27. Что объединяет эти системы
ЧТО ОБЪЕДИНЯЕТЭТИ СИСТЕМЫ
• Нет поддержки постоянной целостности
• Не сразу происходит синхронизация (например, после
регистрации не сразу возможна авторизация)
• Нет или ограниченные транзакции
• Есть но не часто, документы позволяют внутри объекта
поддерживать транзакционность
• Поиск ограничен
• Например по одной колонке на равенство и по нескольким
на неравенство
• Нет или ограничены join операции внутри базы данных
• Поэтому это не реляционные базы данных
• Связи между данных практически нет в таблицах, за связи
нужно отвечать внутри приложения
• Нет расширения языка запросов
• Базы данных расширяемы на 1000 серверов, но пока не
являются реляционными базами данных
• если посмотреть на историю баз данных, то такое
стечение обстоятельств похоже на историю появлений баз
данных
• У всех этих баз данных только одно преимущество – это
расширяемость, поэтому если есть возможность
работать с реляционными базами данных, то проще
работать с ними
28. Сравнение
СРАВНЕНИЕSQL
NoSQL
Реляционная модель
Нереляционная модель
Данные хранятся в таблицах
Данные хранятся по-разному: как JSON,
ключ — значение и т. д. (в зависимости
от типа базы данных). Типы могут
варьироваться
Очень строгая структура базы
Нет жёстких требований к структуре
Подходит для решений, где каждая запись
имеет одинаковый вид и обладает
одинаковыми свойствами
Не каждая запись должна быть одинаковой.
Гибкий подход
С добавлением новового свойства нужно
изменить всю схему
Добавление новых свойств ничего
не нарушает
Поддерживает ACID-транзакции
Поддержка ACID-транзакций варьируется
и зависит от используемой базы данных
NoSQL
Масштабируется вертикально
Масштабируется горизонтально
и вертикально. Гибкая модель данных
29. субд mongodb
СУБД MONGODB• Нереляционная СУБД MongoDB представляет данные в виде коллекций из
документов в формате JSON и предоставляет разные способы обработки данных
• В MongoDB для каждого документа имеется уникальный идентификатор, который
называется _id
• Если в традиционном мире SQL есть таблицы, то в мире MongoDB есть коллекции
• Вся система MongoDB может представлять не только одну базу данных, которая
располагается на одном физическом сервере. Функциональность MongoDB
позволяет расположить несколько баз данных на нескольких физических серверах, и
эти базы данных смогут легко обмениваться данными и сохранять целостность
30. Формат данных в MongoDB
ФОРМАТ ДАННЫХ В MONGODB• Одним из популярных стандартов
обмена данными и их хранения является
JSON (JavaScript Object Notation)
• Для хранения в MongoDB применяется
формат, который называется BSON
(БиСон) или сокращение от binary JSON
• BSON позволяет работать с данными
быстрее: быстрее выполняется поиск и
обработка
31. BSON («Binary JavaScript Object Notation»)
BSON(«BINARY JAVASCRIPT OBJECT NOTATION»)
• Также как и JSON BSON поддерживает встраивание документов и массивы в другие
документы и массивы
• BSON также содержит расширения, которые позволяют оперировать с данными, не
являющимися частью спецификации JSON
• BSON не имеет схемы данных, что дает ему некоторые преимущества в гибкости и
некоторые недостатки в эффективности использования дискового пространства
(накладные расходы BSON связаны с хранением имен полей в сериализуемых
данных).
32. Коллекция
КОЛЛЕКЦИЯ• Коллекция — это набор документов, эквивалент таблицы реляционной базы
данных.
• Каждый документ может отличаться друг от друга размером, содержанием и
количеством полей.
• В документах MongoDB можно хранить даже бинарные данные: изображения, mp3 и
т. д.
• Структура документа похожа на то, как разработчики конструируют классы и
объекты на языках программирования, а у хранимых документов необязательно
должна быть заранее определённая схема
33. Возможности MongoDB
ВОЗМОЖНОСТИ MONGODB• Хранение почти любых данных: структурированных, частично структурированных или
даже полиморфных (различных типов)
• Хранение информации о модели в одном документе
• Отсутствие необходимости описывать схему данных
• Поддержка стандартных типов запросов: сопоставление (==), сравнение (<,>) или
регулярное выражение
• Вертикальное и горизонтальное масштабирование с помощью встроенного
шардирования (разбиение данных на строки и столбцы, хранимых в разных местах)
• Автоматическое переключение между серверами при сбое
34. Кроссплатформенность
КРОССПЛАТФОРМЕННОСТЬ• MongoDB написана на C++, поэтому ее легко портировать на самые разные
платформы. MongoDB может быть развернута на платформах
• Windows,
• Linux,
• MacOS,
• Solaris
35. Применение
ПРИМЕНЕНИЕ• MongoDB используют GitHub, SourceForge, Foursquare, Bitly, About.me, MTV, CNN,
New York Times, Forbes, Disney, EA и многие другие компании для
• Кеширования данных
• Электронная коммерция, каталоги товаров, соцсети, новостные форумы и другие
похожие сценарии, где много контента, в том числе видео и изображений
• Новый проект или стартап, если неизвестна итоговая структура данных или же вы точно
знаете, что у вас будут слабо связанные данные без чёткой схемы хранения
• Геоаналитика (обработка геопространственных данных — данных на основе
местоположения)
• Хранение данных с датчиков и устройств, собранных с решений интернета вещей, в том
числе промышленных
• Работа с большими данными в машинном обучении
• Исследования в ритейле (розничная продажа товаров и услуг) и других отраслях
36. Основные программные артефакты MongoDB
ОСНОВНЫЕ ПРОГРАММНЫЕАРТЕФАКТЫ MONGODB
1) mongod – исполняемый файл сервера баз данных;
2) mongo – командная оболочка MongoDB. Язык оболочки JavaScript
3) mongodump u mongorestore – стандартные утилиты резервного копирования
и восстановления базы данных
4) mongoexport u mongoimport – утилиты экспорта и импорта файлов в форматах JSON, CSV и
TSV
5) mongosniff – анализатор протокола для просмотра команд, посылаемых серверу базы данных.
6) mongostat – аналог iostat; постоянно опрашивает MongoDB и операционную систему для
выдачи полезной статистики, в том числе количества операций (вставки, выборки, обновления,
удаления и др.) в секунду, объема выделенной виртуальной памяти и числа подключений к
серверу.
37. Структура объектов в MongoDB
СТРУКТУРА ОБЪЕКТОВ В MONGODB• Структура объектов в MongoDB не декларируются схемой данных
• Наборы объектов хранятся в виде коллекций и каждый объект может иметь
собственную структуру, но данный подход редко встречается на практике. Обычно
объекты в коллекции имеют схожую структуру с небольшими отличиями
• Преимуществом беccхемного подхода является высокая гибкость при изменении
и уточнении предметной области
38. Пример – документ
ПРИМЕР –ДОКУМЕНТ
39. Значениями могут быть даже другие документы — их называют встроенными
ЗНАЧЕНИЯМИ МОГУТ БЫТЬ ДАЖЕ ДРУГИЕДОКУМЕНТЫ — ИХ НАЗЫВАЮТ
ВСТРОЕННЫМИ
40. id
ID• Подобно тому, как у строк в реляционных БД есть первичный ключ, у каждого
документа в MongoDB есть уникальный идентификатор (_id). Он формируется
автоматически или задаётся пользователем
41. Характеристики, присущие NoSQL базам данных
ХАРАКТЕРИСТИКИ,ПРИСУЩИЕ NOSQL БАЗАМ ДАННЫХ
–в NoSQL СУБД не используется SQL (имеется в виду DML4 )
–отсутствие необходимости хранить данные с определенной структурой
–высокая производительность решений, высокая доступность
– распределенное хранение данных
–способность к горизонтальному масштабированию по требованию для некоторого
набора операций на многих серверах
–эффективное использование распределенных индексов и памяти для запросов
–отсутствие транзакций
–простые протоколы доступа к хранимым данным
–отсутствие поддержки транзакционной целостности ACID (atomicity, consistency,
isolation, durability – атомарность, согласованность, изолированность, долговечность)
42. ключ-значение
КЛЮЧ-ЗНАЧЕНИЕ• В NoSQL БД данные хранятся в виде пар ключ-значение
• Любой записи в БД соответствует ключ. БД состоит из коллекций
• Коллекция является эквивалентом таблицы
• База данных может иметь нуль или больше коллекций
43. Пример базы данных
ПРИМЕР БАЗЫДАННЫХ
В нереляционном
виде база данных
будет хранить три
документа,
соответствующих
каждой из хранимых
записей. Причем
каждый документ
может содержать
присущие только ему
поля
44. Команды для работы
КОМАНДЫ ДЛЯ РАБОТЫ45. Аналогом SELECT из SQL в MongoDB
АНАЛОГОМ SELECT ИЗ SQL В MONGODB• Аналогом SELECT из SQL в MongoDB является «Find». Метод «Find» используется
для выборки документов из MongoDB. Возвращает массив документов в виде
коллекции, если документов нет – пустую коллекцию.
• Синтаксис метода «Find»: db.find(, )
• где: – критерий отбора с помощью формального запроса операторов. – задает поля, которые будут
возвращены в результате обработки запроса и поле «_id» если не указано
46. Примеры
ПРИМЕРЫ• db.phones.find() – получение документов коллекции, в которых поле «Brand» равно
"Apple" : 55
• db.phones.find({ Brand: "Apple"}) – получение документов коллекции, в которых поле
«Brand» равно "Nokia" и "OSFamily" равно «Windows»:
• db.phones.find({ Brand: "Nokia", OSFamily: "Windows"})
• Для получения только одного поля документа для всех документов необходимо ввести:
db.phones.find(null, {Brand: 1}) или db.phones.find({}, {Brand: 1})
• Поле «_id» возвращается всегда, но можно явно исключить его db.phones.find(null,
{Brand: 1, _id: 0})
47. метод «sort»
МЕТОД «SORT»• Для сортировки используется метод «sort»
• Синтаксис метода: sort(), где – документ, содержащий поля, по которым будет
производиться сортировка на результирующем наборе данных
48. Метод «limit»
МЕТОД «LIMIT»• Метод «limit» используется для ограничения количества документов, получаемых в
результате выполнения запроса.
• Синтаксис метода: limit()
• Для получения десяти документов в выводе необходимо вызвать «limit» с
параметром «10»: db.phones.find().limit(10)
49. Метод «skip»
МЕТОД «SKIP»• Метод «skip» используется для пропуска некоторого количества документов
результирующей выборки.
• Синтаксис метода: skip()
• Пропуск
первых
десяти
db.phones.find().limit(10)
результатов
выглядит
следующим
• Методы «limit» и «skip» используются для постраничного вывода данных
образом:
50. Метод «count»
МЕТОД «COUNT»• Метод «count» подсчитывает количество документов в результирующей выборке.
• Синтаксис метода: count(), где – указывает, следует ли учитывать влияние методов
«skip» и «limit».
• По умолчанию метод игнорирует применение методов «skip» и «limit».
• Для получения количества документов в результирующей выборке необходимо
ввести: db.phones.find().count()
• Метод «count» можно также использовать применительно к коллекции, передавая в
него запрос из find, например: db.phones.count({Brand:“Nokia”})
51. Запросы с условием
ЗАПРОСЫ С УСЛОВИЕМ• $lt – меньше чем
• $lte – меньше ли равно
• $gt – больше
• $gte – больше или равно
• $ne – не равно.
Синтаксис модификаторов:
{ <поле>: {<модификатор>: <значение>}},
Где:
<поле> – имя поля, для которого применяется модификатор;
<модификатор> – модификатор;
<значение> – значение модификатор
• $in – вхождение в массив значений.
• $nin – противоположность оператора $in
• $not – логический оператор НЕ
52. Пример
ПРИМЕР• В качестве примера рассмотрим запрос для выбора всех телефонов стоимостью от
10000 до 20000 тыс. руб.
• Запрос выглядит следующим образом: db.phones.find( { cost: { $gte: 10000, $lte:
20000 }} );
• Запрос для получения всех телефонов, выпущенных не фирмой «Apple»:
db.phones.find( {Brand: {$ne: “Apple”}})
• Получение всех телефонов, чья стоимость равна 10000, 15000, или 20000 тыс. руб:
db.phones.find({cost: {$in [10000, 15000, 20000]}})
53. Операторы $or и $and
ОПЕРАТОРЫ $OR И $AND• Операторы $or и $and применяются, когда нужно выбрать документы по
совпадению одного из значений или по совпадению всех значений соответственно.
• Являются реализациями логических операций ИЛИ и И.
• Синтаксис: { $or($and): [ { }, { }, ... } ] }, Где: - логическое выражение, применяемое для
сравнения
54. МОДИФИКАТОРЫ массивов
МОДИФИКАТОРЫ МАССИВОВ• Для добавления элемента в массив используется модификатор «$push», который
используется как параметр метода «update». Пример использования модификатора:
• db.phones.update({ name: "NL920" },{ $push: { cost: 19990 } })
• Для удаления элемента из массива используется модификатор «$pop». Синтаксис
модификатора: { $pop: { : } }. Удаление первого элемента в массиве выглядит
следующим образом:
• db.phones.update({ name: "NL920" },{ $pop: { cost: 1 } })
• Для доступа к конкретному элементу массива используется два способа: по
конкретной позиции, и с помощью использования позиционного оператора (символ
‘$’). Для доступа к элементу массива по номеру, после запроса на выборку
документа в качестве имени изменяемого поля используется: «.»
55. Запросы в массивах
ЗАПРОСЫ В МАССИВАХ• Синтаксис оператора: { : { $all: [, , …]}}, где: – поле, по которому проводится поиск; –
значения массива, которые нужно найти
• Для получения документов, в которых массив содержит элементы «19990», «20000»
и «20100» используется запрос: db.phones.find({cost: {$all: [19990, 20000, 20100]}})
56. Пример запроса в Compass и сравнение с запросами MongoDb и SQL
ПРИМЕР ЗАПРОСА В COMPASS И СРАВНЕНИЕС ЗАПРОСАМИ MONGODB И SQL
57. Источники
ИСТОЧНИКИ• (35) BigData Лекция №9 "Хранение и анализ больших данных" – YouTube
• https://www.mongodb.com/docs/compass/current/query/filter/?utm_source=comp
ass&utm_medium=product
58. Примеры
ПРИМЕРЫ59. Добавление данных
ДОБАВЛЕНИЕ ДАННЫХ60. Просмотр данных
ПРОСМОТР ДАННЫХ61. запрос для удаления всех документов, у которых поле value равно 10
ЗАПРОС ДЛЯ УДАЛЕНИЯ ВСЕХ ДОКУМЕНТОВ,У КОТОРЫХ ПОЛЕ VALUE РАВНО 10
62. запрос для изменения значения поля
ЗАПРОС ДЛЯ ИЗМЕНЕНИЯ ЗНАЧЕНИЯПОЛЯ
63. Добавить новое поле в документ
ДОБАВИТЬ НОВОЕ ПОЛЕ В ДОКУМЕНТ64. Удаление поля из документа
УДАЛЕНИЕ ПОЛЯ ИЗ ДОКУМЕНТА65. увеличение или уменьшение значения записи используется модификатор «$inc»
УВЕЛИЧЕНИЕ ИЛИ УМЕНЬШЕНИЕ ЗНАЧЕНИЯЗАПИСИ ИСПОЛЬЗУЕТСЯ МОДИФИКАТОР
«$INC»
66. Переименование поля
ПЕРЕИМЕНОВАНИЕ ПОЛЯ67. Вывод основных атрибутов части документов коллекции, удовлетворяющих некоторому условию
ВЫВОД ОСНОВНЫХ АТРИБУТОВ ЧАСТИДОКУМЕНТОВ КОЛЛЕКЦИИ,
УДОВЛЕТВОРЯЮЩИХ НЕКОТОРОМУ
УСЛОВИЮ