







 Базы данных
Базы данныхПохожие презентации:










Основы Apache Kafka и как с ней работать
1.
Основы Apache Kafka икак с ней работать
Пашков Константин
2.
Предыстория3.
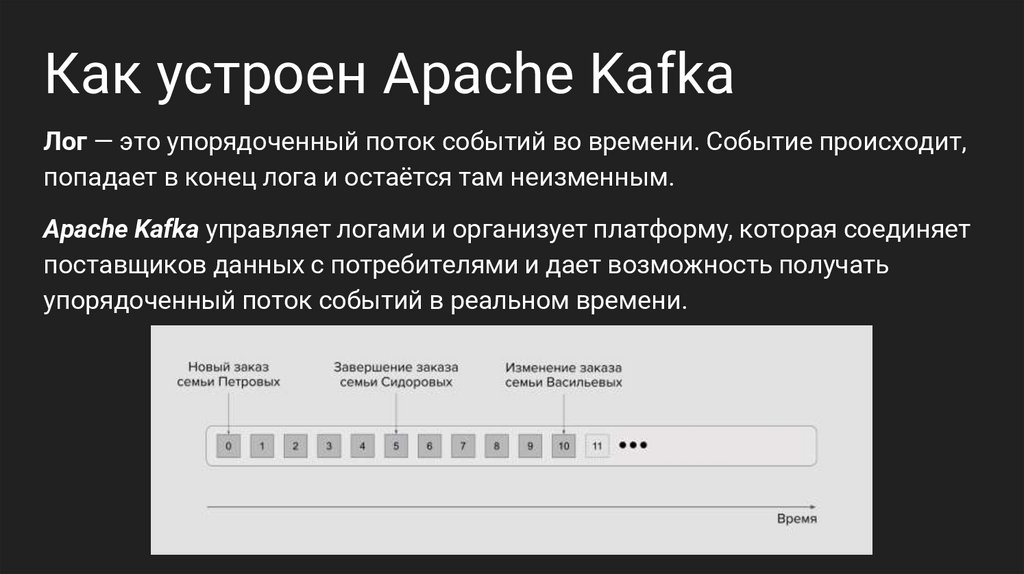
Как устроен Apache KafkaЛог — это упорядоченный поток событий во времени. Событие происходит,
попадает в конец лога и остаётся там неизменным.
Apache Kafka управляет логами и организует платформу, которая соединяет
поставщиков данных с потребителями и дает возможность получать
упорядоченный поток событий в реальном времени.
4.
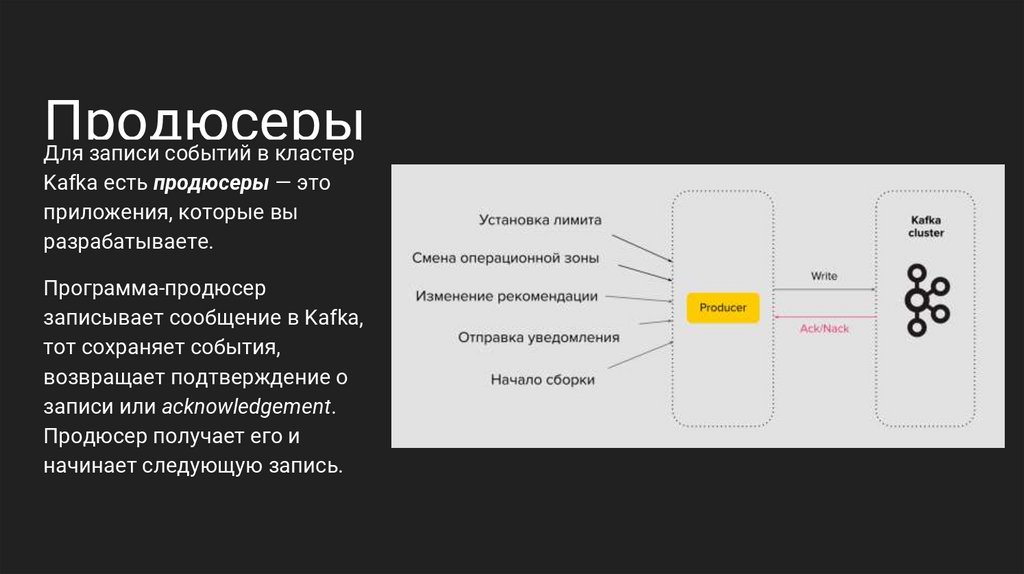
ПродюсерыДля записи событий в кластер
Kafka есть продюсеры — это
приложения, которые вы
разрабатываете.
Программа-продюсер
записывает сообщение в Kafka,
тот сохраняет события,
возвращает подтверждение о
записи или acknowledgement.
Продюсер получает его и
начинает следующую запись.
5.
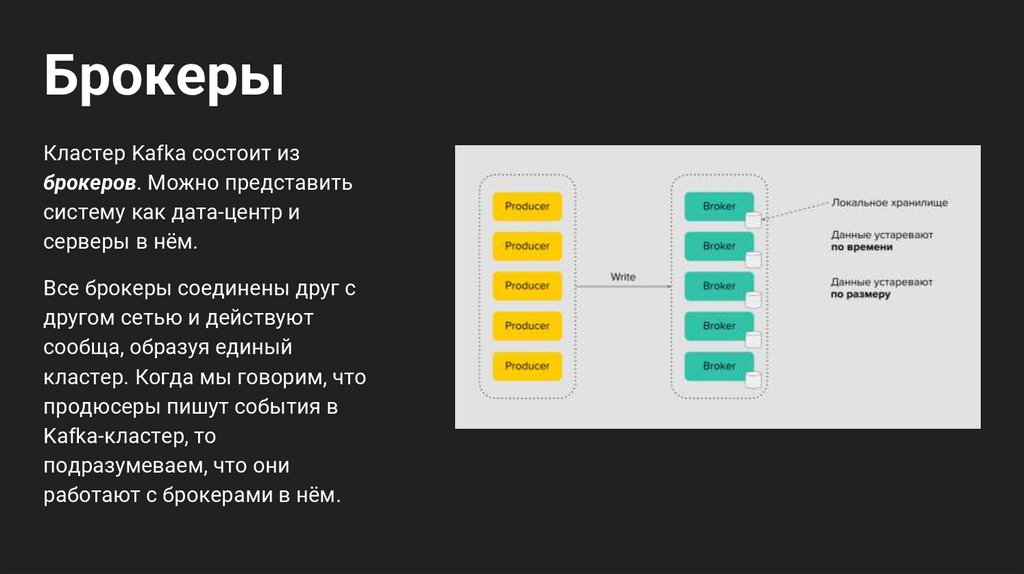
БрокерыКластер Kafka состоит из
брокеров. Можно представить
систему как дата-центр и
серверы в нём.
Все брокеры соединены друг с
другом сетью и действуют
сообща, образуя единый
кластер. Когда мы говорим, что
продюсеры пишут события в
Kafka-кластер, то
подразумеваем, что они
работают с брокерами в нём.
6.
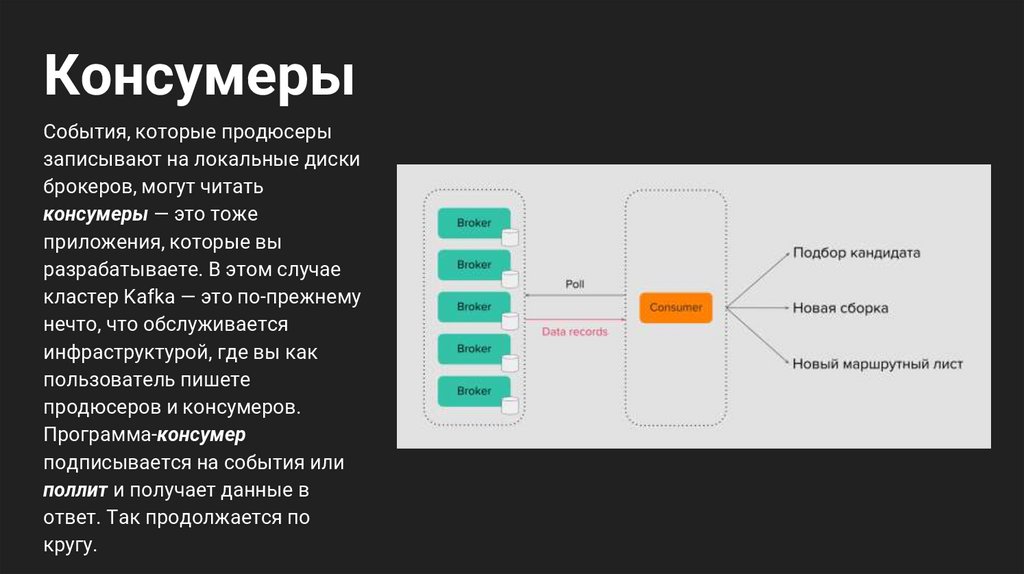
КонсумерыСобытия, которые продюсеры
записывают на локальные диски
брокеров, могут читать
консумеры — это тоже
приложения, которые вы
разрабатываете. В этом случае
кластер Kafka — это по-прежнему
нечто, что обслуживается
инфраструктурой, где вы как
пользователь пишете
продюсеров и консумеров.
Программа-консумер
подписывается на события или
поллит и получает данные в
ответ. Так продолжается по
кругу.
7.
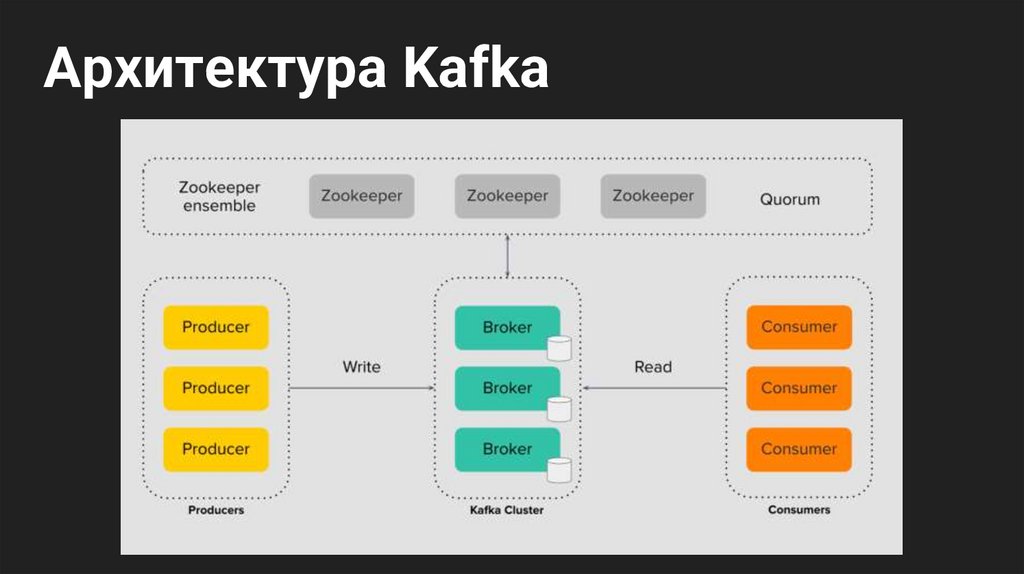
Архитектура Kafka8.
ZookeeperZookeeper — это выделенный кластер серверов для образования кворума-согласия и
поддержки внутренних процессов Kafka. Благодаря этому инструменту мы можем
управлять кластером Kafka: добавлять пользователей и топики, задавать им
настройки.
9.
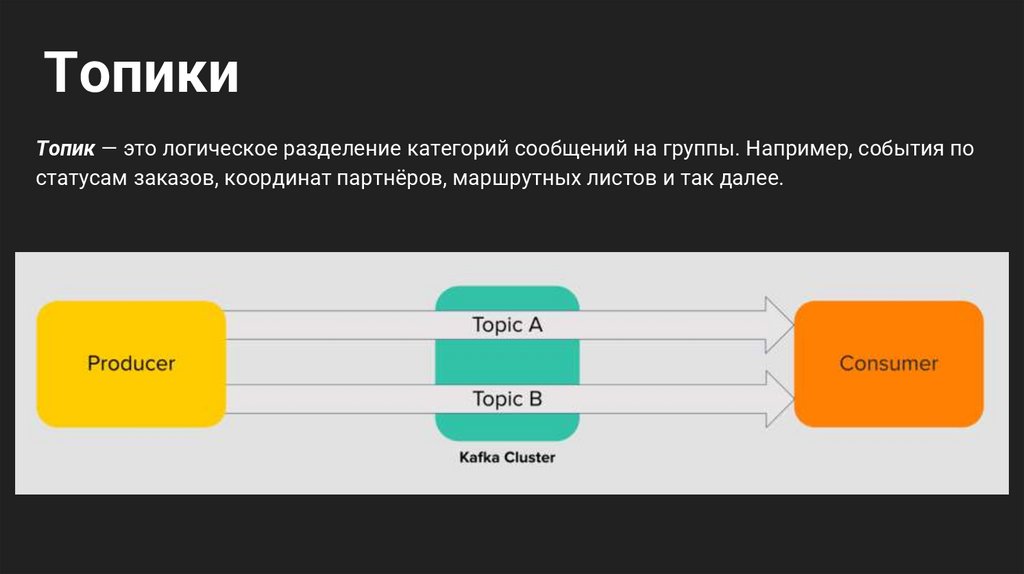
ТопикиТопик — это логическое разделение категорий сообщений на группы. Например, события по
статусам заказов, координат партнёров, маршрутных листов и так далее.
10.
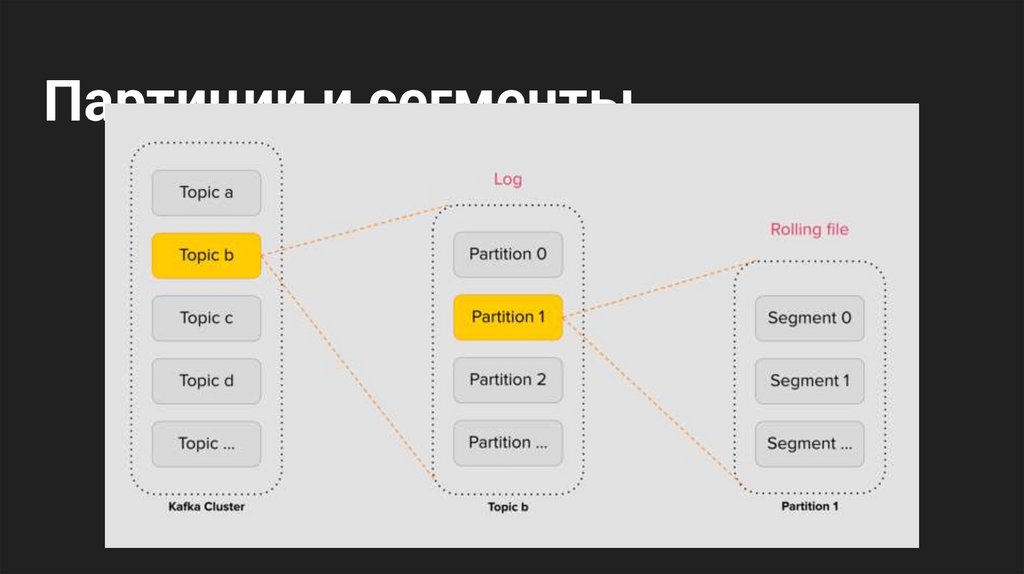
Партиции и сегменты11.
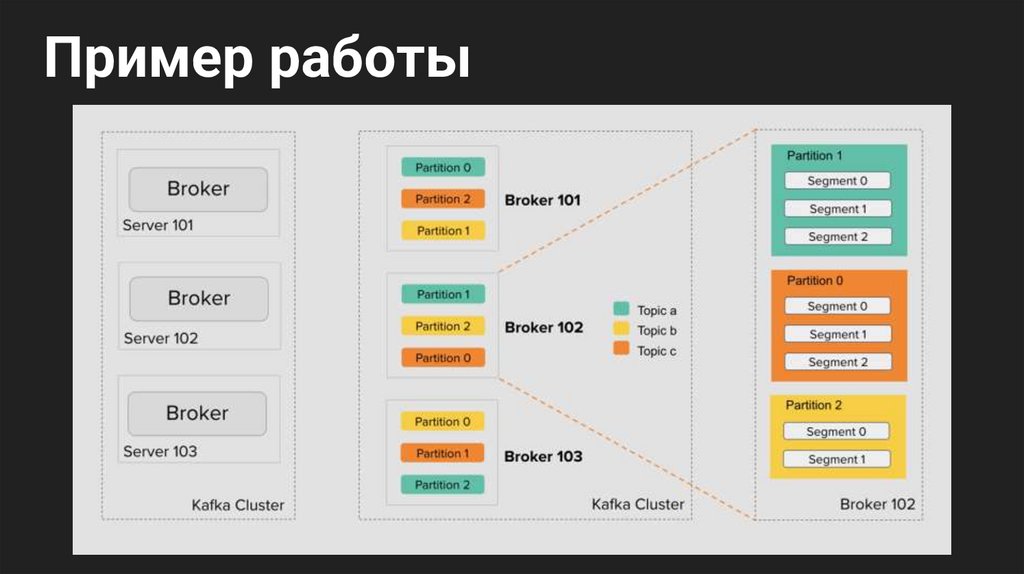
Пример работы12.
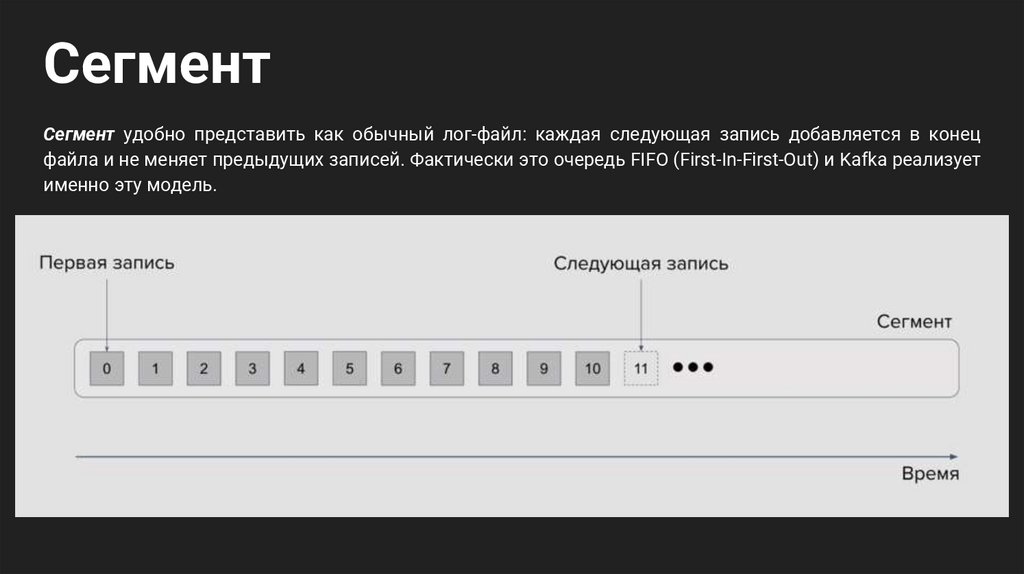
СегментСегмент удобно представить как обычный лог-файл: каждая следующая запись добавляется в конец
файла и не меняет предыдущих записей. Фактически это очередь FIFO (First-In-First-Out) и Kafka реализует
именно эту модель.
13.
Репликацияданных
Если одна партиция будет
существовать на одном
брокере, в случае сбоя часть
данных станет недоступной.
Такая система будет хрупкой и
ненадежной. Для решения
проблемы Kafka представляет
механизм репликации
партиций между брокерами.
14.
15.
Балансировка и партицирование16.
Надёжность доставки17.
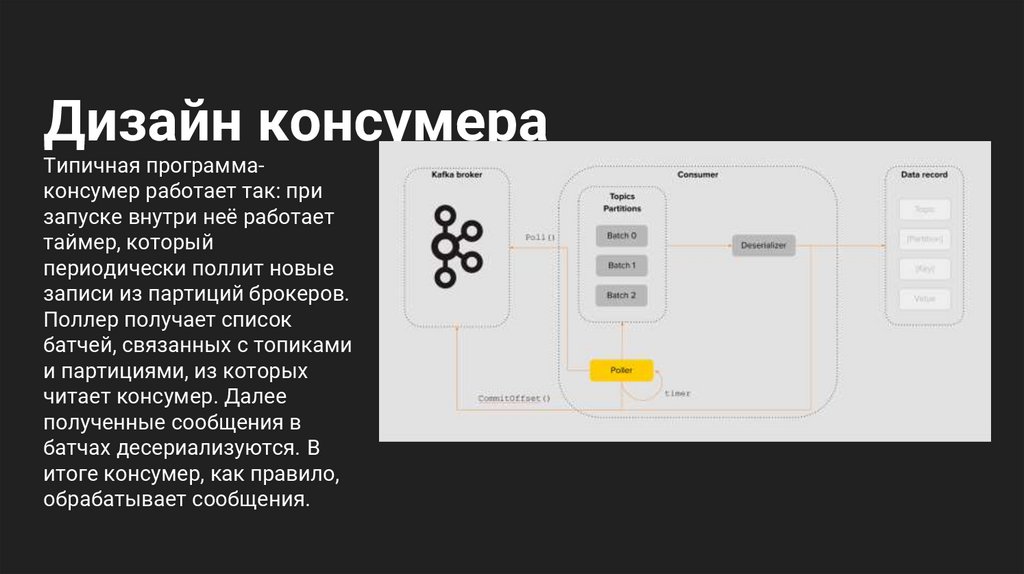
Дизайн консумераТипичная программаконсумер работает так: при
запуске внутри неё работает
таймер, который
периодически поллит новые
записи из партиций брокеров.
Поллер получает список
батчей, связанных с топиками
и партициями, из которых
читает консумер. Далее
полученные сообщения в
батчах десериализуются. В
итоге консумер, как правило,
обрабатывает сообщения.