












 Программное обеспечение
Программное обеспечениеПохожие презентации:








")

Планирование и реализация хранилищ данных
1.
Планирование и реализацияхранилищ данных
Лекция 5
2.
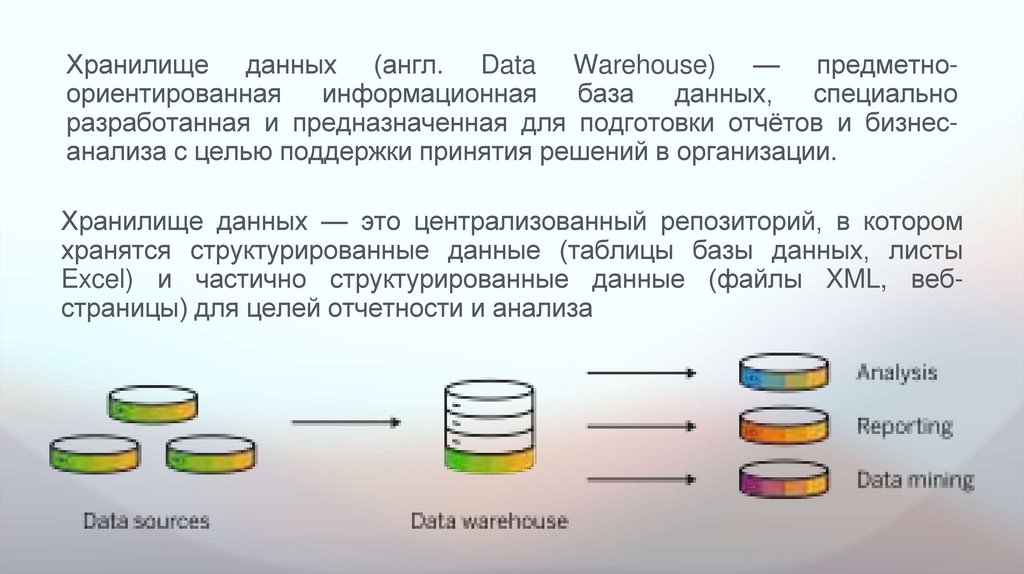
Хранилище данных (англ. Data Warehouse) — предметноориентированная информационнаябаза
данных,
специально
разработанная и предназначенная для подготовки отчётов и бизнесанализа с целью поддержки принятия решений в организации.
Хранилище данных — это централизованный репозиторий, в котором
хранятся структурированные данные (таблицы базы данных, листы
Excel) и частично структурированные данные (файлы XML, вебстраницы) для целей отчетности и анализа
3.
Цель ХД — предоставить бизнес-аналитику (BI), отчетность и аналитику, атакже обеспечить соблюдение нормативных требований, чтобы компании
могли превращать свои данные в ценную информацию и принимать
интеллектуальные решения на основе данных. Хранилища данных хранят
текущие и исторические данные в одном месте и выступают в качестве
единого источника достоверной информации для организации.
4.
• Объединение данных из нескольких источников в один надежныйисточник
• Хранение и анализ данных прошлых месяцев и лет
• Очистка и преобразование данных для точной, согласованной и
стандартизированной структуры и формы
• Сокращение времени запросов при сборе данных и обработке
аналитики, что повышает общую производительность в разных
системах
• Эффективная загрузка данных без затрат на развертывание или
инфраструктуру
• Обеспечение безопасности, конфиденциальности и защиты данных
• Подготовка данных для анализа с помощью интеллектуального
анализа данных, средств визуализации и других расширенных
средств аналитики
5.
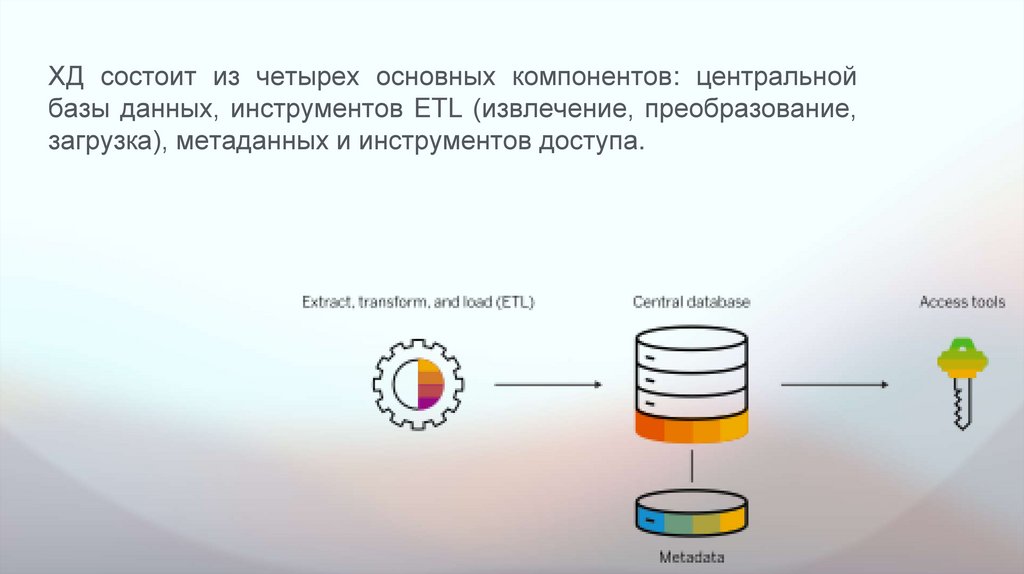
ХД состоит из четырех основных компонентов: центральнойбазы данных, инструментов ETL (извлечение, преобразование,
загрузка), метаданных и инструментов доступа.
6.
Центральная база данных: база данных служит основой хранилища
данных. Традиционно это были стандартные реляционные базы
данных, работающие локально или в облаке. Однако из-за больших
данных потребность в реальной производительности в реальном
времени и резкое снижение стоимости оперативной памяти быстро
набирают популярность баз данных in-memory.
Интеграция данных. Данные извлекаются из исходных систем и
изменяются
для
согласования
информации
для
быстрого
аналитического потребления с помощью различных подходов к
интеграции данных, таких как ETL (извлечение, преобразование,
загрузка) и ELT, а также репликация данных в реальном времени,
обработка массовой загрузки, преобразование данных, а также
сервисы обеспечения качества и пополнения данных.
7.
• Метаданные: метаданные — это данные о ваших данных. Онопределяет источник, использование, значения и другие функции
наборов данных в хранилище данных. Существуют бизнесметаданные, которые добавляют контекст к данным, и
технические метаданные, которые описывают доступ к данным, в
том числе место их хранения и структуру.
Инструменты доступа к хранилищу данных: инструменты
доступа позволяют пользователям взаимодействовать с данными
в хранилище данных. Примеры инструментов доступа:
инструменты запросов и отчетности, инструменты разработки
приложений, инструменты сбора данных и инструменты OLAP.
8.
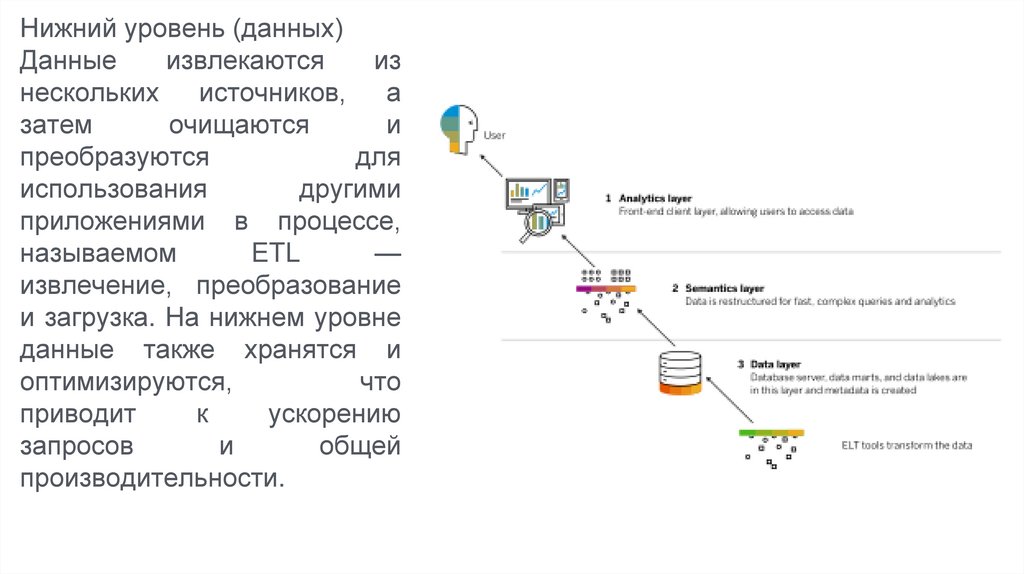
Нижний уровень (данных)Данные
извлекаются
из
нескольких источников, а
затем
очищаются
и
преобразуются
для
использования
другими
приложениями в процессе,
называемом
ETL
—
извлечение, преобразование
и загрузка. На нижнем уровне
данные также хранятся и
оптимизируются,
что
приводит
к
ускорению
запросов
и
общей
производительности.
9.
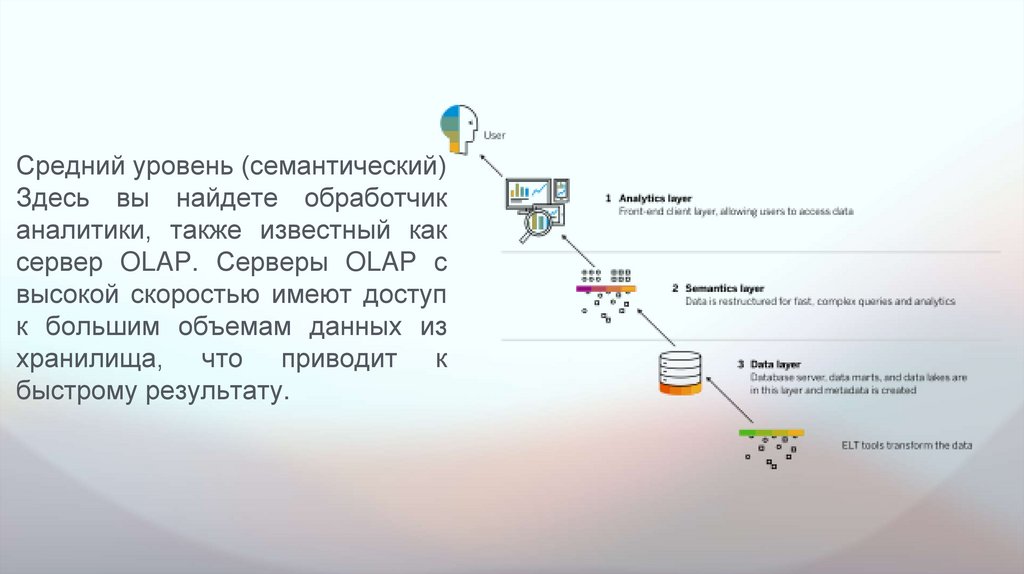
Средний уровень (семантический)Здесь вы найдете обработчик
аналитики, также известный как
сервер OLAP. Серверы OLAP с
высокой скоростью имеют доступ
к большим объемам данных из
хранилища, что приводит к
быстрому результату.
10.
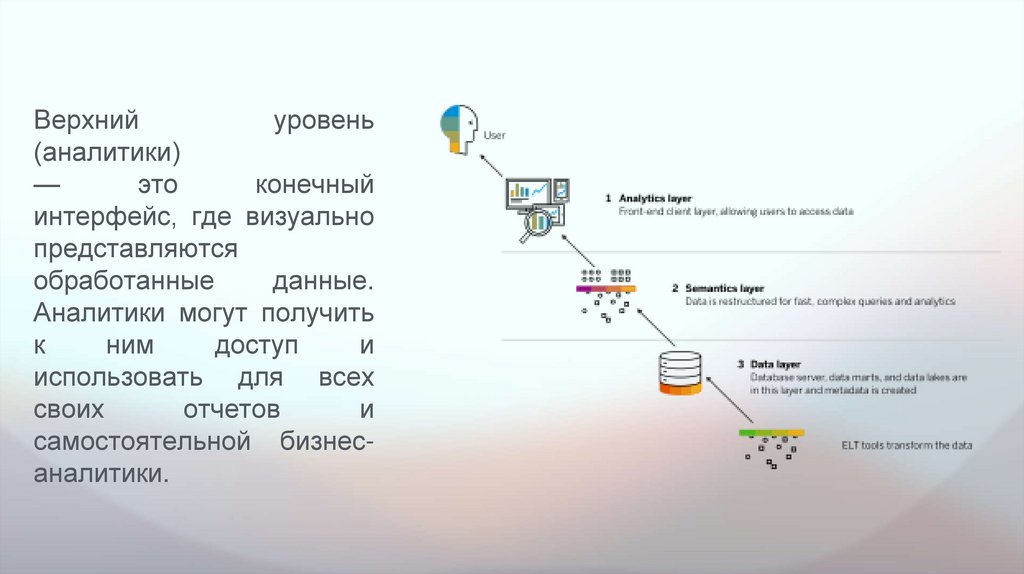
Верхнийуровень
(аналитики)
—
это
конечный
интерфейс, где визуально
представляются
обработанные
данные.
Аналитики могут получить
к
ним
доступ
и
использовать для всех
своих
отчетов
и
самостоятельной бизнесаналитики.
11.
12.
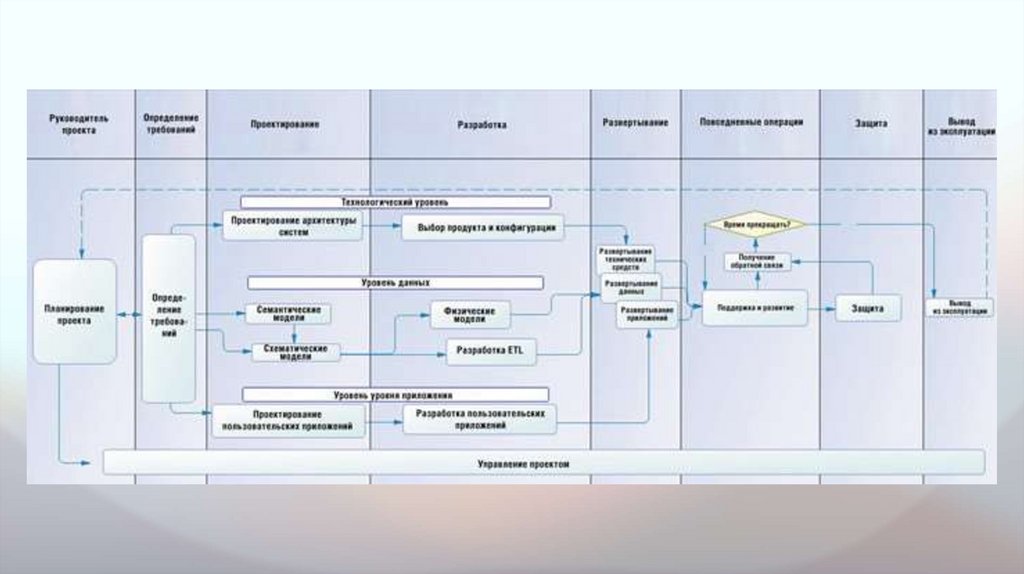
1. Этап определения требований.На данном этапе проводится анализ и определение требований,
учитываются задачи бизнеса, что особенно важно для проектов
создания хранилищ данных, поскольку хранилище данных формируется
для решения задач предприятия. На этой стадии проводится
всестороннее исследование, в рамках которого формулируются ответы
на шесть основных вопросов: Что? Как? Где? Кто? Когда? и Зачем?
(what, how, where, who, when, why)
13.
2. Этап проектирования.Состоит из разработки семантической и схематической моделей
хранилища данных. Эти модели должны соответствовать задачам
информационных систем управления management information
system (MIS) для бизнес-пользователей и отражать аналитические
потребности бизнес-анализа business intelligence (BI). Для проекта
хранилища данных можно построить концептуальные и
логические модели данных
Следует определить все источники данных (внутренние и
внешние), операционные/транзакционные базы данных, структуры
файлов данных, которые будут задействованы в хранилище
данных. Необходимо также определить, какие данные будут
импортироваться в хранилище данных, а какие — использоваться
по ссылке из внешних источников.
14.
3. Разработка.В первой части строится отображение моделей данных на
соответствующие физические составные части проекта (модели
хранилищ реляционных данных и кубы OLAP), при необходимости
задаются размеры баз данных и осуществляется разбиение таблиц,
определяются соглашения по именованию для объектов хранилища
данных бизнес-пользователей и технологических пользователей. Кроме
того,
разрабатывается
стратегия
индексирования
данных
и
определяется
порядок
индексирования.
Во
второй
части
разрабатывают технологии схем ETL (извлечение, преобразование и
загрузка данных из внешних источников в хранилище), настраивают и
тестируют пакеты для служб преобразования данных Data
Transformation Services (DTS) и служб интеграции SQL Server (SSIS,
SQL Server Integration Services). Здесь отлаживаются процессы
импорта/экспорта, разрабатываются и настраиваются сценарии T-SQL,
а также тестируется процесс интеграции данных с внешними
компонентами источников данных, не импортированными в хранилище
данных
15.
4. Внедрение.Развертывание хранилища данных происходит в быстром каскадном
процессе по уровням. Сначала технологическая часть ставится на
место — серверы, хранение, коммуникационные каналы и т.д. Потом
устанавливается программное обеспечение систем, проверяется и
подготавливается к работе. Затем развертываются компоненты
уровня данных: создаются базы данных хранилища данных
(реляционные и OLAP) и запускаются процессы ETL в оперативном
режиме. Потом обычно процесс приостанавливается перед
добавлением финальных уровней прикладных программ, это время
отводится для потока данных от внешних источников и процессов
ETL в различные базы данных хранилища данных и кубы; по мере
необходимости проводится тестирование и настройка. Затем
развертывается уровень прикладных систем.
16.
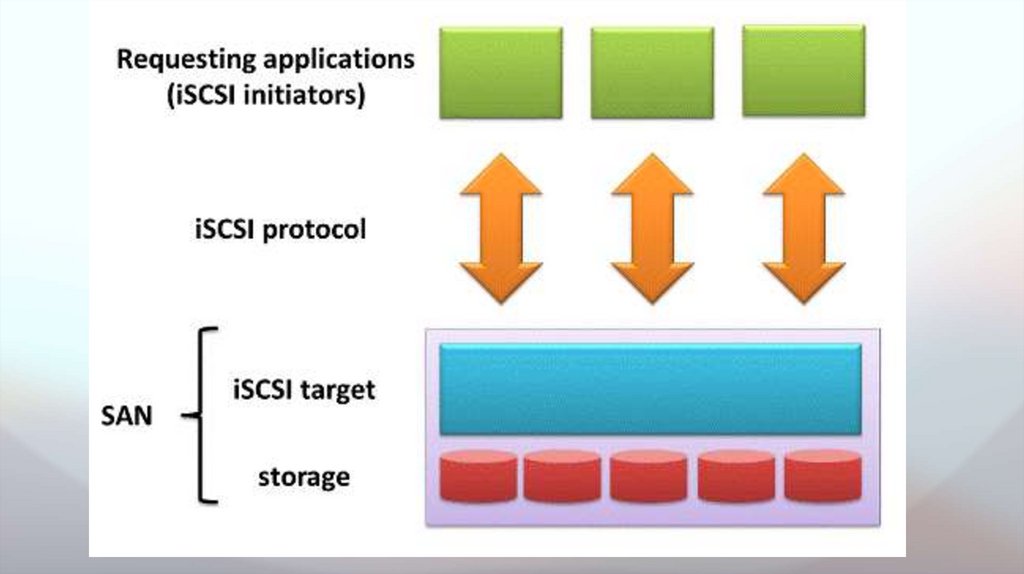
Планирование и внедрение iSCSI SANiSCSI - это сетевой протокол области хранения, который определяет, как
данные передаются между хост-системами и устройствами хранения. Он
обеспечивает передачу данных SCSI на уровне блоков между
инициатором iSCSI и целевым хранилищем по сетям TCP/IP. Хранилище
iSCSI также известно как хранилище iSCSI SAN, которое является
экономичной альтернативой традиционной Fiber Channel (FC) SAN. В
отличие от FC SAN, для которого требуется выделенное оборудование
(FC HBA, коммутатор FC и т. Д.), Хранилище iSCSI SAN может быть
построено на существующей сетевой инфраструктуре (оптический
коммутатор, маршрутизатор и т. д.), А не требует от нас покупки
дополнительного оборудования. Кроме того, iSCSI основан на стандарте
передачи блоков, который является более быстрым и эффективным.
17.
18.
iSCSI SAN подходит для малых и средних предприятий, у которых естьбольшие объемы данных для хранения и передачи по сети
Во-первых, хотя сеть хранения iSCSI может работать в существующей
сетевой инфраструктуре, лучше разместить трафик iSCSI в его
собственной VLAN, предпочтительно в полностью отдельной гигабитной
сети. Это помогает создать резервное соединение для хранения данных
в случае сбоя сети.
19.
Во-вторых, для iSCSI SAN лучше использовать неблокирующийкоммутатор Gigabit Ethernet корпоративного класса. Коммутатор
потребительского уровня часто не поддерживает соединения между
несколькими портами на скорости проводной сети, поэтому они
могут отбрасывать пакеты без предупреждения. Для приложений
центров обработки данных 10GbE iSCSI SAN более ориентирован
на будущее, поэтому предпочтительнее использовать коммутатор
10GbE.
20.
Наконец, если ваши серверы имеют одногигабитные подключения ккоммутатору Ethernet для доступа к дисковым массивам, они
уязвимы для сбоя на этом канале. Лучше всего использовать технику
многопутевого ввода-вывода (MPIO) для создания нескольких
подключений от инициатора iSCSI каждого сервера к вашему
дисковому массиву.