





 Программирование
ПрограммированиеПохожие презентации:










Реализация и исследование решения задачи классификации электронной почты
1.
Отчёт о научно-исследовательскойработе бакалавра
Семестр 7
Студент группы 6401-010302D
Стрельников Никита Арсеньевич
Самара 2025
2.
Тема и проблема исследованияТема научно исследовательской работы: Реализация и исследование решения задачи
классификации электронной почты на основе методов обработки естественного языка
Проблема: Низкая точность или высокая ресурсоёмкость существующих методов
классификации.
Актуальность: Рост объёмов спама и вредоносных писем.
Необходимость автоматической фильтрации и категоризации электронной почты.
Цель работы: Реализовать собственный многоклассовый классификатор электронной почты
и протестировать его на синтетических данных.
2
3.
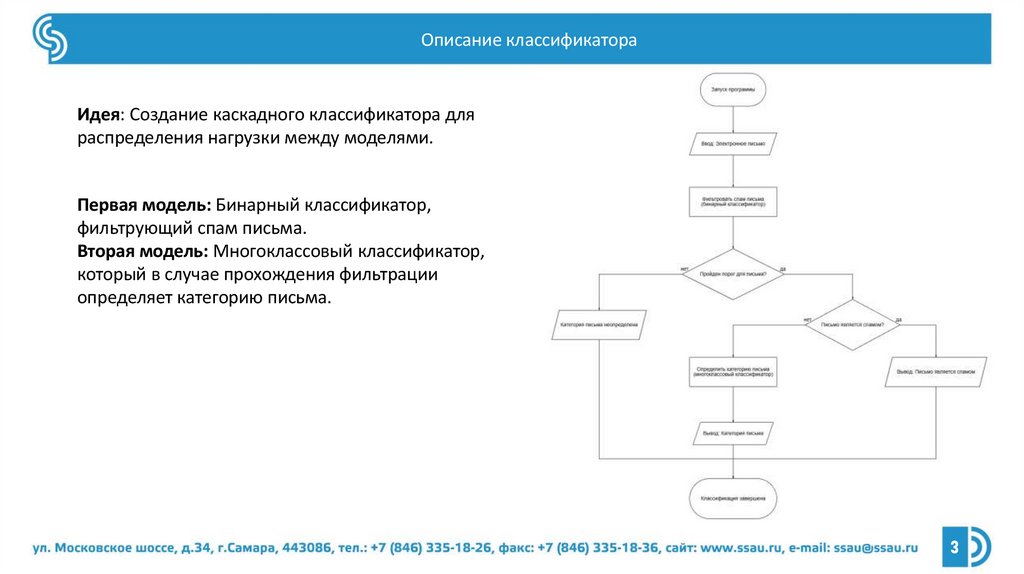
Описание классификатораИдея: Создание каскадного классификатора для
распределения нагрузки между моделями.
Первая модель: Бинарный классификатор,
фильтрующий спам письма.
Вторая модель: Многоклассовый классификатор,
который в случае прохождения фильтрации
определяет категорию письма.
3
4.
Метод опорных векторов (SVM)Принцип работы:
Построение гиперплоскости с максимальным зазором между классами.
Преимущества:
Высокая точность (99% на тестовых данных в бинарной классификации).
Эффективность на небольших наборах данных.
Реализация:
Библиотека sklearn.
Векторизация текстовых данных осуществлялась с помощью TF-IDF метода.
4
5.
DistilBERTПроблема LSTM и RNN:
Слабая вычислительная сложность, ограничивающая их применение в задачах
анализа больших текстовых корпусов.
Не способны улавливать двусторонний контекст и семантику.
Решение:
Использование моделей, основанных на Transformer архитектуре, в частности
DistilBERT.
DistilBERT является более облегченной версией BERT за счет меньшего числа
encoder-блоков
5
6.
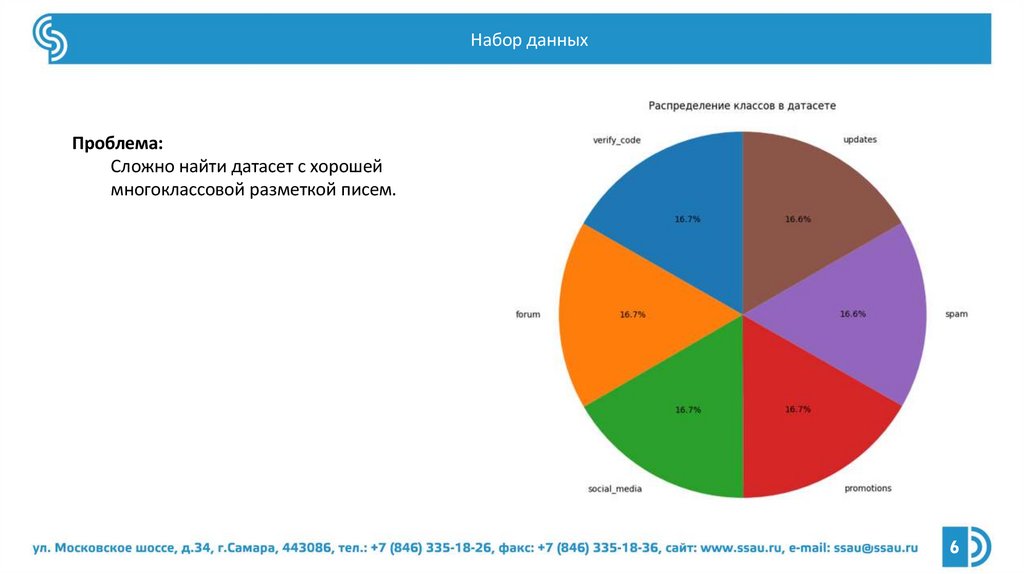
Набор данныхПроблема:
Сложно найти датасет с хорошей
многоклассовой разметкой писем.
6
7.
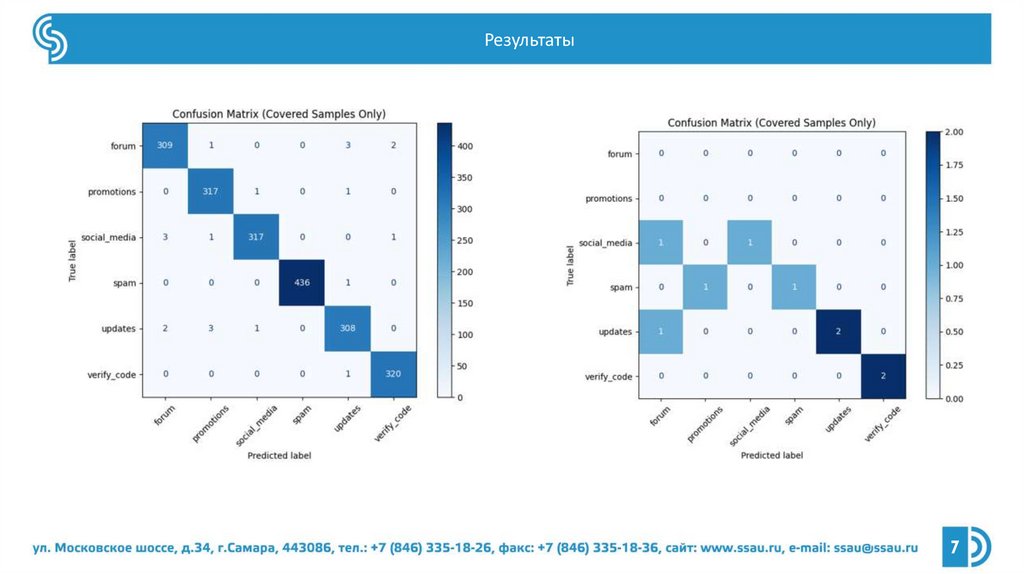
Результаты7
8.
ЗаключениеИтоги:
Реализованная модель демонстрирует высокую точность в пределах одного
набора данных, но её способность к обобщению на произвольные входные
письма требует дополнительной проверки на внешних и более разнообразных
наборах данных.
Перспективы:
Добавить открытые наборы данных.
Расширить имеющиеся синтетические данные.
Увеличить размер писем в синтетических данных.
8
9.
БЛАГОДАРЮЗА ВНИМАНИЕ