


































) и")



 или Data Mining – «раскопка» данных)")
























")
")
 как мультидисциплинарная область")
































 Информатика
ИнформатикаПохожие презентации:

")








Введение в искусственный интеллект
1. Модуль «Общеинженерная подготовка» Учебная дисциплина Введение в искусственный интеллект для специальности 6-05-0612-01
Программная инженерияДневная форма обучения:
общее количество часов – 108 (3 з.е.),
в том числе 50 ауд. часов.
Из них: 24 лекционных часов (из них УСР–2 ч.),
24 часов – лабораторные занятия.
Форма отчётности – зачет во 2 семестре.
Доцент кафедры МПУИ УО ГГУ им.Ф.Скорины,
к.ф.-м.н. Осипенко Н.Б.
2. 2. Введение в анализ данных 2.1. Подходы к статистическому анализу данных 2.2. Основные факторы пересмотра технологий анализа
данных2.3. Этапы эволюции систем анализа данных
2.4. Структура исследований в области искусственного
интеллекта
2.5. Этапы трансформации данных и знаний при обработке
на ЭВМ
2.6. Особенности и признаки интеллектуальности
информационных систем
2
3. 2.1. Подходы к статистическому анализу данных
34.
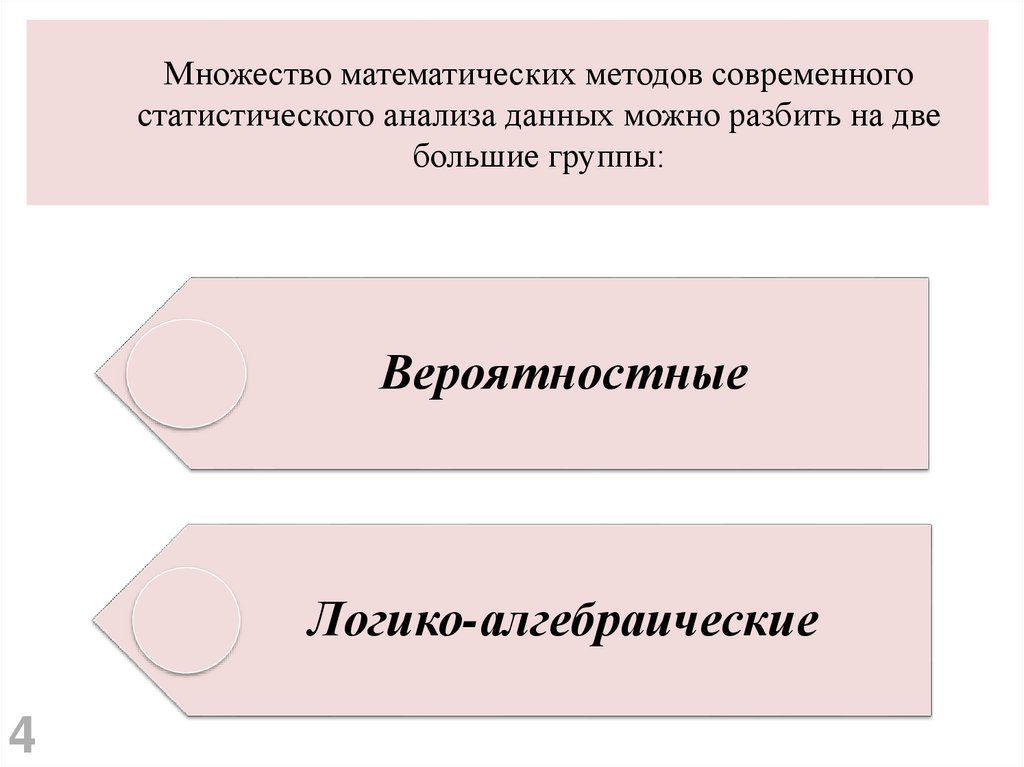
Множество математических методов современногостатистического анализа данных можно разбить на две
большие группы:
Вероятностные
Логико-алгебраические
4
5.
Вероятностный подходВключает методы математической статистики, которые:
предназначены для анализа данных, имеющих вероятностную
(случайную) природу;
позволяют по результатам наблюдений конкретного явления или
системы (исходным статистическим данным) строить статистическую
модель явления или системы;
предусматривают возможность вероятностной интерпретации
анализируемых данных и полученных в результате этого анализа
статистических выводов.
5
6.
Логико-алгебраический подходСодержит статистические методы, которые:
находятся за рамками научной дисциплины "математическая
статистика", предназначенные для обработки данных, не имеющих
вероятностной природы;
основаны на обычной логике и используют алгебраический и
геометрический подходы.
К данному подходу исследователь вынужден обращаться лишь тогда,
когда условия сбора исходных данных не укладываются в рамки
статистического ансамбля
6
7.
Типы реальных ситуацийработоспособности подходов
С позиции соблюдения условий статистического ансамбля можно
выделить три типа реальных ситуаций:
с высокой работоспособностью вероятностно-статистических
методов;
с допустимостью вероятностно-статистических приложений (при
этом нарушатся требования сохранения неизменными условия
эксперимента);
с недопустимостью вероятностно-статистических приложений (в
этом случае идея многократного повторения одного и того же
эксперимента в неизменных условиях является бессодержательной).
7
8.
Пример №1Цель статистического анализа – исследование возможностей
массового производства по исходным данным, представляющим
результаты контроля ограниченного ряда изделий, случайно
отобранных из продукции этого производства.
Если производство отлажено и действует в стационарном режиме
(т.е. его технологические возможности остаются на постоянном
уровне), то ряд наблюдений естественно интерпретировать как
ограниченную
выборку
из
соответствующей
бесконечной
совокупности, которую бы имели, если бы осуществляли сплошной
контроль всех изделий, производимых на этом производстве.
В этом случае выборку рассматривают как составную часть, или
представителя «стоящей за ней» бесконечной совокупности (т.е. всего
массового производства), а выборочные оценки статистических
характеристик
–
как
некое
приближение
показателей
генеральной совокупности
8
9.
Пример №2Исследуется совокупность средних городов России (с
численностью [100; 500] тысяч человек) .
По каждому городу регистрировались значения 32 признаков,
характеризующих этот город по уровню образования его жителей,
половозрастному и социальному составу, структуре занятости
жителей города.
Подробный анализ большого числа городов практически не
реален, поэтому в фиксированном пространстве небольшого числа
интегральных параметров города разделяются на типы,
выделяются эталоны, а для них проводят подробный анализ с
целью выявления наиболее характерных черт и закономерностей в
социально-экономическом облике средних по величине типичных
городов.
9
10.
Исходные статистические данные могут быть представлены в видепоследовательности 32-мерных векторов X 1 X N.
1
x
1
X1
1
X n xn
x1
32
x n
32
i
где x
– параметры, характеризующие среднее число жителей,
приходящихся на 1000 человек населения города.
x 1 … x 4– 4 параметра, характеризующие уровень образования
(высшее, незаконченное высшее, среднее специальное, среднее)
– 12 параметров, характеризующих половозрастной
состав;
– 5 параметров для описания социального характера
занятости населения;
– 11 параметров, характеризующих занятость в
материальном или нематериальном производстве и источники
доходов
10
11.
Пример №2Если допустить, что геометрическая близость двух точек –
городов Xi и X j в соответствующем 32-мерном пространстве
означает их однородность (сходство) по анализируемым признакам
и является основанием для их отнесения к одному типу, то для
решения задачи надо привлечь методы кластер-анализа и снижения
размерности.
Математический аппарат этих методов предполагает вычисление
средних, дисперсий, ковариаций, но эти характеристики описывают
уже природу и структуру только реально анализируемых данных,
т.е.
статистически
обследованную
совокупность
из
N
анализируемых городов.
11
12.
Отличия примеров №1 и №2В первом примере возможно, а во втором – нет:
интерпретировать исходные данные в качестве случайной
выборки генеральной совокупности;
использование вероятностной модели для построения и
выбора наилучших методов статистической обработки;
дать вероятностную интерпретацию выводам, основанным на
статистическом анализе исходных данных.
12
13.
Сходства примеров №1 и №2В обоих случаях выбор наилучшего из всех возможных методов
обработки данных производится в соответствии с некоторыми
функционалами качества метода.
Способ обоснования выбора этого функционала, а также его
интерпретация различны:
в первом случае выбор основан на допущении о вероятностной
природе исходных данных и интерпретация тоже.
во втором случае исследователь не пользуется априорными
сведениями о вероятностной природе исходных данных и при
обосновании выбора оптимального критерия качества опирается на
соображения содержательного (физического) плана – как именно и
для чего получены данные.
Когда критерий выбран, в обоих случаях используются методы
решения экстремальных задач. На этапе осмысления и
интерпретации каждый из подходов имеет свою специфику.
13
14. 2.2. Основные факторы пересмотра технологий анализа данных
1415.
Основные факторы пересмотратехнологий анализа данных
•Фактор реального времени (РВ):
Управляемость в режиме РВ проявилась особо значимо в военной
сфере, управлении производственными системами, медицине, экологии,
энергетики.
При этом особо жесткие требования (для анализа данных) к методам и
моделям выдвинули:
значительные объемы данных, эффективно участвующий в процессе
принятия решения;
разнородный
характер
данных
(числовые
и
символьные,
структурированные, неструктурированные, формализованные и в виде
текстов на естественном языке).
15
16.
Основные факторы пересмотратехнологий анализа данных
•Специфика открытых предметных областей
Выразилась в двух обстоятельствах:
возможность хранения больших массивов породила потребность
создания средств поддержки "открытых" множеств запросов к
хранимой информации
осознана потребность создания средств автоматического выделения и
анализа скрытых зависимостей.
16
17.
Основные факторы пересмотратехнологий анализа данных
•Сложный характер объекта управления
Взаимодействие большого множества разнородных процессов и
подсистем демонстрирует ограниченность:
традиционных моделей и методов теории управления
интеллектуальных систем 1-го поколения (экспертных систем
продукционного типа).
17
18.
Основные факторы пересмотратехнологий анализа данных
На основании вышеизложенных
факторов возникла острая
необходимость в поиске новых
подходов в анализе данных, адекватных
сложившимся потребностям.
18
19. 2.3. Этапы эволюции систем анализа данных
1920.
1. Технология БД – база данных2. Технология OLTP (On-Line Transaction
Processing)
–
оперативная
обработка
транзакций
3. Технология OLAP (On-Line Analytical
Processing) – интерактивная аналитическая
обработка данных
4. Технология DWH и DM (Data
WareHouse) – хранилище информации и (Data
Mining and Knowlelge Discovery in Databases)
– интеллектуальный анализ данных.
20
21. Технология БД
БД–
специальная
форма
организации
данных,
поддерживаемая СУБД для поиска нужного значения параметра в
системе формализованных отношений.
База данных (БД) – именованная совокупность данных,
отражающая состояние объектов и их отношений в рассматриваемой
предметной области, или иначе БД – это совокупность
взаимосвязанных данных при такой минимальной избыточности,
которая допускает их использование оптимальным образом для
одного или нескольких приложений в определенной предметной
области. БД состоит из множества связанных файлов.
Система управления базами данных (СУБД) – совокупность
языковых и программных средств, предназначенных для создания,
ведения и совместного использования БД многими пользователями.
21
22. Технология OLTP
Системы оперативной обработки данных OLTP рассчитаны на быстроеобслуживание относительно простых запросов большого числа
пользователей. Эти системы требуют защиты от несанкционированного
пользователя, от нарушения целостности данных, аппаратных и
программных сбоев. Их характеризует малое время ожидания выполнения
запросов.
Приложения OLTP, как правило, автоматизируют структурированные,
повторяющиеся задачи обработки данных, такие как ввод заказов и
банковские транзакции. Системы OLTP проектируются, настраиваются и
оптимизируются для выполнения максимального числа транзакций за
короткие промежутки времени. Как правило, большой гибкости здесь не
требуется, и чаще всего используется фиксированный набор надежных и
безопасных методов ввода, модификации, удаления данных и выпуска
оперативной отчетности. Показателем эффективности выступает количество
транзакций, выполняемых за секунду. Обычно аналитические возможности
OLTP-систем сильно ограничены (либо вообще отсутствуют).
22
23. Транзакция
Транзакция – это некоторое законченное с точкизрения пользователя действие над базой данных, неделимая с
позиции воздействия на базу данных последовательность
операций манипулирования данными. Это может быть
операция чтения, удаления, вставки и т.д. Транзакция
реализует некоторое осмысленное с точки зрения
пользователя действие, например перевод денег со счета,
резервирование места, доставление нового служащего.
23
24. Технология OLTP
OLTP-системы, являясь высокоэффективным средствомреализации оперативной обработки, часто оказываются мало
пригодными для решения задач аналитической обработки. При помощи
подобных систем можно построить аналитический отчет и даже прогноз
любой сложности, но, как правило, регламентированный заранее. Любой
шаг в сторону, любое дополнительное требование конечного
пользователя часто требует знаний о структуре данных и определенной
квалификации программиста и соответственно не могут быть
удовлетворены немедленно.
24
25.
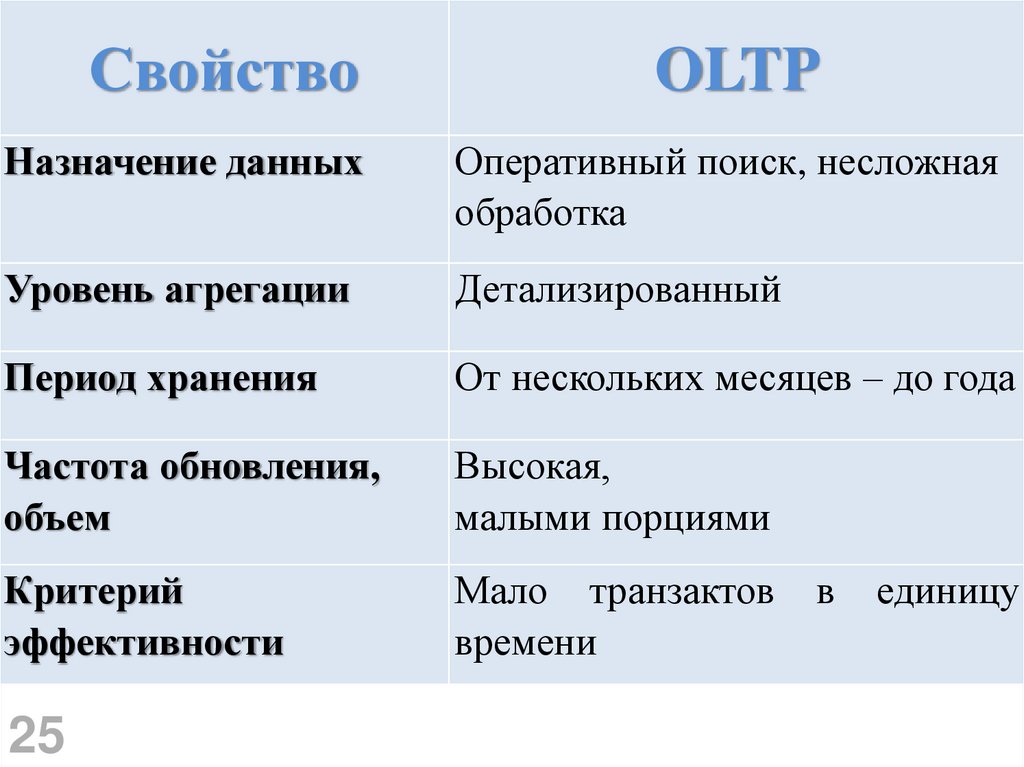
СвойствоOLTP
Назначение данных
Оперативный поиск, несложная
обработка
Уровень агрегации
Детализированный
Период хранения
От нескольких месяцев – до года
Частота обновления,
объем
Высокая,
малыми порциями
Критерий
эффективности
Мало транзактов
времени
25
в
единицу
26. Технология OLAP
OLAP – набор технологий для оперативной обработкиинформации, включающих динамическое построение отчётов в
различных разрезах, анализ данных, мониторинг и прогнозирование
ключевых показателей бизнеса. В основе OLAP-технологий лежит
представление информации в виде OLAP-кубов.
OLAP-кубы содержат бизнес-показатели, используемые для
анализа и принятия управленческих решений, например: прибыль,
рентабельность продукции, совокупные средства (активы),
собственные средства, заемные средства и т.д.
Благодаря детальному структурированию информации OLAPкубы позволяют оперативно осуществлять анализ данных и
формировать отчёты в различных разрезах и с произвольной глубиной
детализации.
26
27.
СвойствоOLAP
Назначение данных Аналитическая обработка,
прогнозирование, моделирование
Уровень агрегации Агрегированный
Период хранения
Несколько лет – до нескольких.
десятков лет
Частота обновления, Малая,
объем
большими порциями
Критерий
эффективности
27
Скорость выполнения сложных
запросов, прозрачность структуры
хранения
информации
для
пользователей
28. 4 этап эволюции систем анализа данных: Технология DWH и DM
2829. Знания как основной ресурс менеджмента
Управление знаниями (Knowledge Management, KM) – новая ибыстро развивающаяся область практической деятельности,
целью которой является систематизация работы с
интеллектуальными ресурсами (активами) и накопленным
опытом.
В силу своей нематериальности интеллектуальные ресурсы
(имя компании - имидж, торговые марки - бренды, клиентская база, корпоративная
культура, интеллектуальный капитал - знания и т.д.) могут показаться
невесомыми, однако именно они являются реальными
рычагами, обеспечивающими конкурентные преимущества
предприятия перед другими.
29
30.
Если раньше стоимость компаний составляли финансовыйкапитал, здания, оборудование и другие материальные
ценности, то в новой, постиндустриальной эпохе главным
источником богатства становится интеллектуальный капитал
(систематизированные и уникальные знания).
Знания – это выявленные закономерности предметной
области (принципы, связи, законы), позволяющие решать
задачи в этой области.
30
31. Управление знаниями предполагает широкое использование следующих информационных технологий:
баз данных и хранилищ данных (Data Warehousing – DW);систем управления документооборотом (Document
Management);
средств для организации совместной работы – сети Intranet,
систем бизнес аналитики, специализированных
программ обработки данных и поиска скрытых
закономерностей (Data Mining – DM);
экспертных систем и баз знаний.
Весь этот комплекс информационных технологий можно назвать
системой поддержки принятия решений
31
32. Технология DWH и DM
Широко распространены технологии Хранилищ информации(Data WareHouse) DWH и интеллектуального анализа данных (Data
Mining and Knowlelge Discovery in Databases) DM.
Data mining (интеллектуальный анализ данных, добыча данных,
«просев»
информации)
–
процесс
выявления
скрытых
закономерностей, обнаружения в сырых данных (RAW data) ранее
неизвестных, нетривиальных знаний, простых для интерпретации и
практически полезных в принятии решений во всех областях
человеческой жизни.
Технология Data Mining позволяет выявить среди больших
объемов данных закономерности, которые не могут быть обнаружены
стандартными способами обработки сведений, но являются
объективными и практически полезными.
Методы Data Mining основываются на базе различных научных
дисциплин: статистики, теории баз данных, искусственного
интеллекта, алгоритмизации, визуализации и других наук.
32
33. Технология DWH и DM
Хранилище данных (DataWarehouse, DWH) представляет собойспециально организованную единую базу данных предприятия, в которой
обеспечивается сбор, хранение и быстрый доступ к предметноориентированной, интегрированной и поддерживающей хронологию
корпоративной информации.
33
Компоненты хранилища данных предприятия
34. Технология DWH и DM. ETL-системы
• ETL (Extract, Transform, Load) – это системы корпоративного класса,которые применяются, чтобы привести к одним справочникам и загрузить в
DWH и EPM данные из нескольких разных учетных систем.
ETL-инструменты – промежуточный слой между OLTP системами и OLAP
системой или корпоративным хранилищем.
• Задачи ETL-системы :
Привести все данные к единой системе значений и детализации, попутно
обеспечив их качество и надежность;
• Обеспечить аудиторский след при преобразовании (Transform) данных,
чтобы после преобразования можно было понять, из каких именно
исходных данных и сумм собралась каждая строчка преобразованных
данных.
34
35. Технология DWH и DM
DWH – это специфическим образом организованныйдля целей поддержки принятия решения НД:
• предметно ориентированный
• интегрированный (объединяющий значения
различных параметров)
• неизменяемый
• поддерживающий хронологию
(Bill Inmon)
35
36.
Принципы организации хранилищаПроблемно-предметная ориентация. Данные объединяются в
категории и хранятся в соответствии с областями, которые они
описывают, а не с приложениями, которые они используют.
Интегрированность. Данные объединены так, чтобы они
удовлетворяли всем требованиям предприятия в целом, а не
единственной функции бизнеса.
Некорректируемость. Данные в хранилище данных
создаются: т.е. поступают из внешних источников,
корректируются и не удаляются.
не
не
Зависимость от времени. Данные в хранилище точны и
корректны только в том случае, когда они привязаны к
некоторому промежутку или моменту времени.
36
37. Технология DWH и DM
DM – это управляемый данными процесс (data driven)извлечения зависимостей из больших БД.
В этом процессе центральное место занимает автоматическое
порождение моделей правил и функциональных
зависимостей, характеризующих анализируемые данные.
Затем они предъявляются пользователю для оценки
«интересности», релевантности и полезности для целей
процесса Data Mining.
37
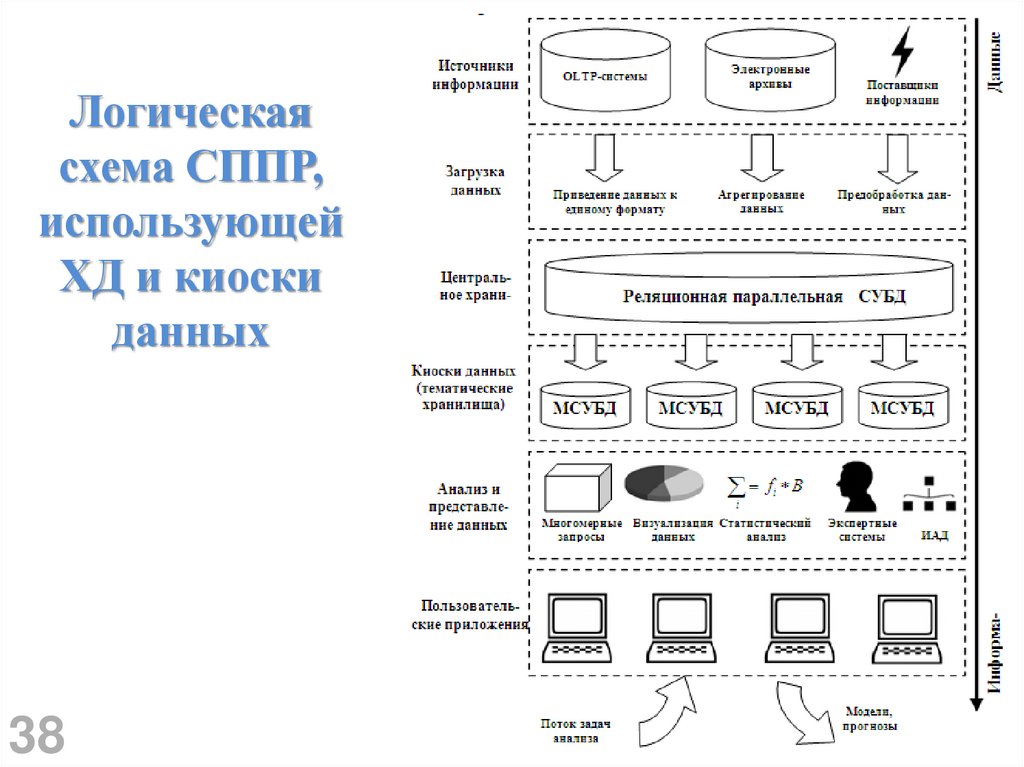
38.
Логическаясхема СППР,
использующей
ХД и киоски
данных
38
39. Современные методы добычи знаний: «Оперативная аналитическая обработка данных» (On-Line Analytical Processing или (OLAP)) и
«Обнаружение знаний в базах данных»(Knowledge discovery in databases (KDD) или даже
Data Mining – «раскопка» данных)
39
40. Хранилища данных
Основой для принятия решений является анализданных, выявление скрытых закономерностей и знаний,
содержащихся в данных, прогноз развития явления.
Для полнофункциональной работы СППР, как правило,
недостаточно иметь только корпоративную базу
данных, в которой данные отражают текущее состояние
дел, а нужно иметь специально организованное
хранилище данных (Data Warehousing – DW)
С термином «хранилище данных» неразрывно связан
термин «оперативная аналитическая обработка данных»
(On-Line Analytical Processing или: OLAP)
Данные в хранилище попадают из оперативных систем
(баз данных). Кроме того, хранилище может
пополняться за счет внешних источников, например
40
статистических отчетов.
41. Зачем строить хранилища данных - ведь они содержат заведомо избыточную информацию, которая и так есть в базах данных или файлах
оперативных систем?Предприятие,
как правило, имеет разрозненную
систему баз данных, разбросанную в разных уголках
корпоративной сети. Собирать данные для анализа в
этом случае крайне затруднительно.
Данные в базе данных обновляются. Сохранение всей
истории изменений данных приводит к «распуханию»
БД и замедлению ее работы, а для анализа нужна
именно динамика изменения данных.
Анализировать данные оперативных систем напрямую
невозможно или очень затруднительно.
41
42.
Технология OLAP – это инструмент оперативногоанализа данных, содержащихся в хранилище.
Главной особенностью является то, что эти средства
ориентированы на использование НЕ специалистом в
области информационных технологий, НЕ экспертомстатистиком, а профессионалом в прикладной области
управления - менеджером отдела, департамента,
управления, и, наконец, директором.
Различие OLAP и KDD состоит в том, что при
использовании технологии OLAP пользователь сам
формирует модель – гипотезу об отношениях между
данными – и после этого, используя серию запросов к
базе данных, подтверждает или отклоняет эту гипотезу.
OLAP очень часто используется в качестве
предварительной стадии перед применением KDD.
42
43. Обнаружение знаний в базах данных (Knowledge discovery in databases (KDD) или Data Mining – «раскопка» данных)
44. Задачи Data Mining
Классификация – обнаружение определенных признаков уобъектов (событий), позволяющих отнести их к тому или иному
ранее известному классу.
Кластеризация – это более сложная задача, решаемая
инструментами интеллектуального анализа, логически продолжает
идеи классификации. Позволяет группировать объекты при
изначальном отсутствии самих классов.
Ассоциация – поиск закономерностей между связанными
событиями. Например, ассоциативное правило, определяющее,
что за событием X следует событие Y. В отличие от
вышеописанных задач – это ассоциативное выявление
закономерностей основывается не на анализе характеристик
объекта, а на рассмотрении нескольких событий, происходящих в
один момент времени.
44
45. Задачи Data Mining
Последовательность – это установление закономерностей междусвязанными по времени событиями. Также называется нахождением
последовательных шаблонов. Правило последовательности говорит,
что через определенное время после события X наступит событие Y.
Регрессия и прогнозирование. Обнаружение зависимости выходных
данных от переменных входных сведений.
Визуализация – графическое представление анализируемой
информации. Аналитик данных (data analyst) использует сырые
данные для поиска осмысленных, практически важных сведений
методами «просева» информации. Задачи, решаемые data scientist,
обширны и затрагивают различные научные отрасли, но в то же время
дают превосходные результаты.
45
Внедрение Data Mining в OLAP позволяет обнаружить закономерности в
базах данных и использовать полученные сведения для принятия
различного рода решений.
46. Способности интеллектуального анализа данных
Выявлять скрытые взаимные влияния различных факторови вести причинный анализ (то есть давать ответы на
вопросы "Почему?")
Порождать возможные зависимости в накопленных данных
(причем не только заранее заданного вида, например,
линейные функции)
Анализировать наблюдаемые в накопленных данных
аномалии
Прогнозировать (на основе порожденных зависимостей)
характер поведения объекта исследования.
46
47. Data Mining
Собирательное название, используемое для обозначениясовокупности методов обнаружения в данных ранее
неизвестных, нетривиальных, практически полезных и
доступных интерпретаций знаний, необходимых для принятия
решений в различных сферах человеческой деятельности.
Методы Data mining могут быть применены как для работы
с большими данными, так и для обработки сравнительно малых
объемов данных (полученных, например, по результатам
отдельных экспериментов, либо при анализе данных о
деятельности компании).
Цель технологии Data Mining – нахождение в данных таких
моделей, которые не могут быть найдены обычными методами.
47
48. Data Mining
––
Задачи, решаемые методами Data Mining, принято разделять на
предсказательные (англ. predictive).
описательные (англ. descriptive)
В описательных задачах самое главное – это дать наглядное описание
имеющихся скрытых закономерностей, в то время как в предсказательных
задачах на первом плане стоит вопрос о предсказании для тех случаев, для
которых данных ещё нет.
Для построения рассмотренных моделей используются различные
методы и алгоритмы Data Mining. В виду того, что технология Data Mining
развивалась и развивается на стыке таких дисциплин, как статистика, теория
информации, машинное обучение, теория баз данных, вполне закономерно,
что большинство алгоритмов и методов Data Mining были разработаны на
основе различных технологий и концепций.
48
49. Описательные модели Data Mining
Описательные модели уделяют внимание сути зависимостей в набореданных, Взаимному влиянию различных факторов, т. е. на построении
эмпирических моделей различных систем. Ключевой момент в таких
моделях – легкость и прозрачность для восприятия человеком. Возможно,
обнаруженные закономерности будут специфической чертой именно
конкретных исследуемых данных и больше нигде не встретятся, но это
все равно может быть полезно и потому должно быть известно.
К ним относятся следующие виды моделей:
– регрессионные
– кластеров
– ассоциативные
– исключений
– итоговые
49
50. Описательные модели Data Mining
• Регрессионные модели – описывают функциональные зависимостимежду зависимыми и независимыми показателями и переменными в
понятной человеку форме. Необходимо заметить, что такие модели
описывают функциональную зависимость не только между
непрерывными числовыми параметрами но и между категориальными.
• Модели кластеров – описывают группы (кластеры), на которые
можно разделить объекты, данные о которых подвергаются анализу.
Группируются объекты (наблюдения, события) на основе
данных(свойств), описывающих сущность объектов. Объекты внутри
кластера должны быть «похожими» друг на друга и отличаться от
объектов, вошедших в другие кластеры. Чем больше похожи объекты
внутри кластера и чем больше отличий между кластерами, тем точнее
кластеризация.
50
• Ассоциативные модели – выявление закономерностей между
связанными событиями. Примером такой закономерности служит
правило, указывающее, что из события X следует событие Y. Такие
правила называются ассоциативными.
51. Описательные ассоциативные модели Data Mining
Результатом ассоциативного анализа являются правила вида:Если факт А является частью события, то с
вероятностью P факт B будет частью того же события.
Поиск ассоциативных правил является одним из самых популярных
приложений Data Mining.
Суть задачи заключается в определении часто встречающихся наборов
объектов в большом множестве таких наборов.
Данная задача является частным случаем задачи классификации.
Первоначально она решалась при анализе тенденций в поведении
покупателей в супермаркетах. Анализу подвергались данные о
совершаемых ими покупках, которые покупатели складывают в тележку
(корзину). Это послужило причиной второго часто встречающегося
названия – анализ рыночных корзин (Basket Analysis). При анализе
этих данных интерес прежде всего представляет информация о том,
какие товары покупаются вместе, в какой последовательности, какие
категории потребителей, какие товары предпочитают, в какие периоды
времени и т. п. Такая информация позволяет более эффективно
планировать закупку товаров, проведение рекламной кампании и т.д.
51
52. Описательные ассоциативные модели Data Mining
Например, в сфере торговли, из набора покупок, совершаемых в магазине,можно выделить следующие наборы товаров, которые покупаются вместе:
{чипсы, пиво}; {хлеб, молоко (масло)}. Следовательно, можно сделать
вывод, что если покупаются чипсы или хлеб, то, как правило, покупаются
пиво или молоко (масло) соответственно. Обладая такими знаниями,
можно разместить эти товары рядом, объединить их в один пакет со
скидкой или предпринять другие действия, стимулирующие покупателя
приобрести товар.
Например, в сфере обслуживания интерес представляет, какими услугами
клиенты предпочитают пользоваться в совокупности. Для получения этой
информации задача решается применительно к данным об услугах,
которыми пользуется один клиент в течение определенного времени
(месяца, года). Это помогает определить, например, как наиболее выгодно
составить пакеты услуг, предлагаемых клиенту.
В медицине анализу могут подвергаться симптомы и болезни, наблюдаемые у
пациентов. В этом случае знания о том, какие сочетания болезней и
симптомов встречаются наиболее часто, помогают в будущем правильно
ставить диагноз.
52
53. Описательные модели Data Mining
• Модели исключений – описывают исключительные ситуации в записях(например, отдельных пациентов), которые резко отличаются чем-либо от
основного множества записей (группы больных). Знание исключений может
быть использовано двояким образом. Возможно, что эти записи представляют
собой случайный сбой, например ошибки операторов, вводивших данные в
компьютер. Характерный случай: если оператор, ошибаясь, ставит
десятичную точку не в том месте, то такая ошибка сразу дает резкий
«всплеск»на порядок. Подобную «шумовую», случайную составляющую
имеет смысл отбросить, исключить из дальнейших исследований, поскольку
большинство методов очень чувствительно к наличию «выбросов» – резко
отличающихся точек, редких, нетипичных случаев. С другой стороны,
отдельные, исключительные записи могут представлять самостоятельный
интерес для исследования, т. к. они могут указывать на некоторые редкие, но
важные аномальные заболевания. Даже сама идентификация этих записей, не
говоря об их последующем анализе и детальном рассмотрении, может
оказаться очень полезной для понимания сущности изучаемых объектов или
явлений.
53
54. Нахождение исключений
Нахождение исключений (также обнаружение выбросов)— это опознавание во время интеллектуального анализа
данных редких данных, событий или наблюдений, которые
вызывают подозрения ввиду существенного отличия от
большей части данных. Обычно аномальные данные
превращаются в некоторый вид проблемы, такой
как мошенничество в банке, структурный дефект,
медицинские проблемы или ошибки в тексте. Аномалии
также упоминаются как выбросы, необычности, шум,
отклонения или исключения.
55. Нахождение исключений
Выявление аномалий в контексте обнаружениязлоумышленного использования и вторжения в сеть,
интересующие нас объекты часто не являются редкими, но
проявляют неожиданную вспышку активности. Это не
соответствует обычному статистическому определению
выбросов как редких объектов и многие методы
обнаружения выбросов (в частности, методы без учителя)
терпят неудачу на таких данных, пока данные не будут
сгруппированы подходящим образом. Зато
алгоритмы кластерного анализа способны заметить
микрокластеры, образованные таким поведением.
56. Нахождение исключений
Существует широкий набор категорий техник выявления аномалий.Техника выявления аномалий без учителя обнаруживает аномалии
в непомеченных наборах тестовых данных при предположении, что
большая часть набора данных нормальна, путём поиска
представителей, которые меньше подходят к остальному набору
данных.
Техника выявления аномалий с учителем требует предоставления
данных, помеченных как «нормальные» и «ненормальные», и
использует обучение классификатора (ключевое отличие от многих
других задач классификации заключается в неотъемлемой
несбалансированной природе выявления выбросов).
Техника выявления аномалий с частичным учителем строит
модель, представляющую нормальное поведение из заданного
набора нормального тренировочного набора, а затем проверяет
правдоподобие полученной модели.
57. Нахождение исключений
Выявление аномалий применимо к широкому кругуобластей, таких как система обнаружения
вторжений, обнаружение мошенничества, обнаружение
неисправностей, мониторинга здоровья, обнаружение
событий в сетях датчиков и обнаружение нарушений в
экологической сфере. Часто выявление аномалий
используется для предварительной обработки данных с
целью удаления аномалий. При обучении с
учителем удаление аномальных данных из набора часто
приводит к существенному статистическому увеличению
точности.
58. Популярные техники поиска аномалий
Техники, основанные на плотности.Обнаружение выбросов на основе подпространств и на основе
корреляции для данных высокой размерности
Метод опорных векторов для одного класса.
Репликатор нейронных сетей.
Байесовские сети.
Скрытые марковские модели.
Выявление выбросов на основе кластерного анализа.
Отклонения от ассоциативных правил и часто встречающихся
наборов.
Выявление выбросов на основе нечёткой логики.
Техника создания ансамблей, использующая бэггинг признаков
усреднение оценки и различение источников несхожести.
Эффективность различных методов зависит от данных и
параметров и имеют слабые систематические преимущества
один перед другим, если сравнивать по многим наборам данных
и параметров.
59. Нахождение исключений
Выявление аномалий предложила для систем обнаружениявторжений Дороти Деннинг в 1986. Выявление аномалий
для систем обнаружения вторжений обычно выполняется с
заданием порога и статистики, но может быть сделано с
помощью мягких вычислений и индуктивного обучения.
Типы статистики, предлагавшиеся в 1999, включали
профайлы пользователей, рабочих станций, сетей,
удалённых узлов, групп пользователей и программ,
основанных на частотах, средних и дисперсиях.
Эквивалентом выявления аномалий в обнаружении
вторжений является обнаружение злонамеренного
использования.
60. Описательные модели Data Mining
60Итоговые модели – выявление ограничений на данные
анализируемого массива. Например, при изучении выборки данных по
пациентам не старше 30 лет, перенесшим инфаркт миокарда,
обнаруживается, что все пациенты, описанные в этой выборке, либо
курят более 5 пачек сигарет в день, либо имеют вес не ниже 95 кг.
Подобные ограничения важны для понимания данных массива; по сути
дела – это новое знание, извлеченное в результате анализа.
Таким образом, Data Summarization – это нахождение каких-либо
фактов, которые верны для всех или почти всех записей в изучаемой
выборке данных, но которые достаточно редко встречались бы во всем
мыслимом многообразии и записей такого же формата и, например,
характеризовались бы теми же распределениями значений полей. Если
взять для сравнения информацию по всем пациентам, то процент либо
сильно курящих, либо чрезмерно тучных людей будет весьма невелик.
Можно сказать, что решается как бы неявная задача классификации, хотя
фактически задан только один класс, представленный имеющимися
данными.
Пример, метод ДСМ.
61. Предсказательные модели Data Mining
61Предсказательные модели строятся на основании набора данных с
известными результатами. Они используются для предсказания
результатов на основании других наборов данных. При этом,
естественно, требуется, чтобы модель работала максимально точно,
была статистически значима и оправданна и т. д.
К ним относятся следующие модели:
Модели последовательностей – описывают функции, позволяющие
прогнозировать изменение непрерывных числовых параметров. Они
строятся на основании данных об изменении некоторого параметра за
прошедший период времени;
Модели классификации – описывают правила или набор правил, в
соответствии с которыми можно отнести описание любого нового
объекта к одному из ИЗВЕСТНЫХ классов. Такие правила строятся на
основании информации о существующих объектах путем разбиения
их на классы;
Модели регрессионного анализа и анализа временных рядов.
62. Предсказательные модели последовательностей Data Mining
Выявление последовательностей• Последовательные
шаблоны
аналогичны
ассоциациям с той лишь разницей, что связывают
события, разнесенные во времени.
• Такая задача является разновидностью задачи
поиска ассоциативных правил и называется
сиквенциальным анализом.
62
63. Предсказательные модели последовательностей Data Mining
При анализе часто вызывает интерес последовательностьпроисходящих событий. При обнаружении закономерностей в
таких последовательностях можно с некоторой долей вероятности
предсказывать появление событий в будущем, что позволяет
принимать более правильные решения. Такая задача является
разновидностью задачи поиска ассоциативных правил и
называется сиквенциальным анализом. (Процесс обнаружения
закономерностей в последовательности происходящих событий с
целью предсказывать появление событий в будущем с некоторой
долей вероятности называется сиквенциальным анализом).
Основным отличием задачи сиквенциального анализа от поиска
ассоциативных правил является установление отношения
порядка между исследуемыми наборами. Данное отношение может
быть определено разными способами. При анализе
последовательности событий, происходящих во времени, объектам и
таких наборов являются события, а отношение порядка соответствует
хронологии их появления.
63
64. Предсказательные модели последовательностей Data Mining
Сиквенциальный анализ широко используется, например втелекоммуникационных компаниях, для анализа данных об
авариях на различных узлах сети. Информация о
последовательности совершения аварий может помочь в
обнаружении неполадок и предупреждении новых аварий.
Например, если известна последовательность сбоев:
{е , е , е , е , е ,е ...},
5 2 7 11 6 9
где еi – сбой с кодом i, то на основании факта появления сбоя е2
можно сделать вывод о скором появлении сбоя е7. Зная это, можно
предпринять профилактические меры, устраняющие причины
возникновения сбоя. Если дополнительно обладать и знаниями о
времени между сбоями, то можно предсказать не только факт его
появления, но и время, что часто не менее важно.
64
65. Алгоритмы обучения
Для задач классификации характерно «обучение с учителем», прикотором построение (обучение) модели производится по
выборке, содержащей входные и выходные векторы.
Для задач кластеризации и ассоциации применяется «обучение
без учителя», при котором построение модели производится по
выборке, в которой нет выходного параметра. Значение
выходного параметра («относится к кластеру …», «похож на
вектор …») подбирается автоматически в процессе обучения.
Для задач сокращения описания характерно отсутствие
разделения на входные и выходные векторы. Начиная с
классических работ К. Пирсона по методу главных компонент,
основное внимание уделяется аппроксимации данных.
65
66. Этапы обучения
Ряд этапов решения задач методами data mining:1. Постановка задачи анализа;
2. Сбор данных;
3. Подготовка данных (фильтрация, дополнение, кодирование);
4. Выбор модели (алгоритма анализа данных);
5. Подбор параметров модели и алгоритма обучения;
6. Обучение модели (автоматический поиск остальных
параметров модели);
7. Анализ качества обучения, если неудовлетворительный
переход на п. 5 или п. 4;
8. Анализ выявленных закономерностей, если
неудовлетворительный переход на п. 1, 4 или 5.
66
67. Подготовка данных
Перед использованием алгоритмов data mining необходимопроизвести подготовку набора анализируемых данных.
ИАД может обнаружить только присутствующие в данных
закономерности, исходные данные
должны иметь достаточный объём, чтобы эти закономерности в
них присутствовали,
быть достаточно компактными, чтобы анализ занял приемлемое
время.
Чаще всего в качестве исходных данных выступают
хранилища или витрины данных. Подготовка необходима для
анализа многомерных данных до кластеризации или
интеллектуального анализа данных.
67
68. Подготовка данных (фильтрация)
Фильтрация удаляет выборки с шумами и пропущеннымиданными.
Отфильтрованные данные сводятся к наборам признаков (или
векторам, если алгоритм может работать только с векторами
фиксированной размерности), один набор признаков на
наблюдение. Набор признаков формируется в соответствии с
гипотезами о том, какие признаки сырых данных имеют высокую
прогнозную силу в расчете на требуемую вычислительную
мощность для обработки.
Например, черно-белое изображение лица размером 100×100
пикселей содержит 10 тыс. бит сырых данных. Они могут быть
преобразованы в вектор признаков путём обнаружения в
изображении глаз и рта. В итоге происходит уменьшение
объёма данных с 10 тыс. бит до списка кодов положения,
значительно уменьшая объём анализируемых данных, а значит и
68
время анализа.
69. Подготовка данных (пропуски)
Существуют алгоритмы обработки пропущенных данных,имеющих прогностическую силу (например, отсутствие у
клиента покупок определенного вида). Скажем, при
использовании метода ассоциативных правил обрабатываются не
векторы признаков, а наборы переменной размерности.
Выбор целевой функции будет зависеть от того, что является
целью анализа; выбор «правильной» функции имеет
основополагающее значение для успешного интеллектуального
анализа данных.
Среди наблюдений выделяют: обучающие и тестовые.
Обучающий набор используется для «обучения» алгоритма data
mining, а тестовый набор – для проверки найденных
закономерностей.
69
70. Data mining (DM) как мультидисциплинарная область
7071. Постановка задачи DM
Первоначально задача ставится следующим образом:имеется достаточно крупная база данных;
предполагается, что в базе данных находятся некие
«скрытые знания».
Необходимо разработать методы обнаружения
знаний, скрытых в больших объёмах исходных
«сырых» данных. В текущих условиях глобальной
конкуренции именно найденные закономерности
(знания) могут быть источником дополнительного
конкурентного преимущества.
71
72. Постановка задачи DM
Что означает «скрытые знания»? Это должны быть обязательно знания:ранее неизвестные, новые, а не подтверждающими какие-то ранее
полученные сведения;
нетривиальные - которые нельзя просто так увидеть (при
непосредственном визуальном анализе данных или при вычислении
простых статистических характеристик);
практически полезные - которые представляют ценность для
исследователя или потребителя;
доступные для интерпретации - которые легко представить в
наглядной для пользователя форме и легко объяснить в терминах
предметной области.
Эти требования во многом определяют суть методов DM и то, в каком
виде и в каком соотношении в технологии DM используются системы
управления базами данных, статистические методы анализа и методы
искусственного интеллекта.
72
73.
Методы Data Mining• Переборные алгоритмы, эвристики,
статистические методы
• Нечеткая логика
• Генетические алгоритмы
• Нейронные сети
73
74. 2.4. Структура исследований в области искусственного интеллекта
7475.
Группы исследованийимитация творческих процессов,
интеллектуализация ЭВМ,
новейшая технология решения задач,
роботы.
В рамках исследований первой группы созданы программы, например,
шахматной игры или сочиняющие музыку, доказательства теорем или имитации
способностей человека к обучению. Результаты этих исследований носят
фундаментальный характер. Они позволяют формировать методы и приемы
искусственного интеллекта.
Основной целью второй группы исследований является построение ЭВМ, с
которыми могут общаться неподготовленные пользователи. В рамках этих
исследований созданы программные средства для систем общения, баз данных,
систем планирования решения задач.
К третьей группе отнесены все исследования, направленные на создание
новых принципов обработки информации и решения задач. Эти принципы
используют характерные особенности методов искусственного интеллекта (они
оперируют со знаниями так же, как это делают люди, когда выполняют
творческую работу.) В целом исследования этой группы ориентированы на
планирование в АСУ, САПР, оперативное управление и автоматизацию научных
исследований.
1)
2)
3)
4)
75
76.
РоботыК четвертой группе отнесены все исследования, связанные с разработкой роботов –
автоматических устройств, предназначенных для осуществления производственных,
научных и других работ. Роботы могут иметь различные внешний вид и размеры, но
все они выполняют действия на основании заложенной в них программы обработки
информации.
Промышленные роботы заменяют человека там, где требуется проведение
утомительных и однообразных работ (например, конвейерная сборка автомобилей и
электронных устройств), опасных технических работ (например, работа с
радиоактивными материалами), а также работ, где присутствие человека физически
невозможно (например, автоматические космические и глубоководные аппараты).
Разработаны роботы, оснащенные органами чувств, аналогичными органам чувств
человека (зрение, слух, тактильные ощущения), имеющие память и способные
обрабатывать полученную информацию и осуществлять целенаправленные действия.
Они способны работать дома (уже производится робот-пылесос), в больнице
(экспериментальные образцы разносят больным лекарства), на других планетах
(луноходы и марсоходы путешествуют по поверхностям небесных тел) и т. д.
76
77. 2.5. Этапы трансформации данных и знаний при обработке на ЭВМ
7778.
Определение данных и знанийПри изучении интеллектуальных систем возникает вопрос – что такое
знания и чем они отличаются от обычных десятилетиями обрабатываемых
данных. Можно предложить несколько рабочих определений, в рамках которых
это становится очевидным
Данные – это отдельные факты, характеризующие объекты, процессы и
явления в предметной области, а также их свойства.
При обработке на ЭВМ данные трансформируются, условно проходя
следующие этапы:
• данные как результат измерений и наблюдений;
• данные на материальных носителях информации (таблицы, протоколы,
справочники);
• модели (структуры) данных в виде диаграмм, графиков, функций;
• данные в компьютере на языке описания данных;
• базы данных на машинных носителях.
Знания связаны с данными, основываются на них, но представляют
результат мыслительной деятельности человека, обобщают его опыт,
полученный в ходе выполнения практической деятельности. Они получаются
78эмпирическим путем.
79.
Определение данных и знанийЗнания – это выявленные закономерности предметной области
(принципы, связи, законы), позволяющие решать задачи в этой области.
При обработке на ЭВМ знания трансформируются аналогично данным:
• знания в памяти человека как результат мышления;
• материальные носители знаний (учебники, методические пособия);
• поле знаний – условное описание основных объектов предметной
области, их атрибутов и закономерностей, их связывающих;
• знания, описанные на языках представления знаний (продукционные
языки, семантические сети, фреймы и др.);
• базы знаний.
Часто используются такие определения знаний: знания – это хорошо
структурированные данные, или данные о данных, или метаданные.
79
80.
Определение данных и знанийСуществует множество способов определять понятия. Один из
широко применяемых способов основан на идее интенсионала, другой –
экстенсионала.
Интенсионал понятия – это определение через понятие более
высокого уровня абстракции с указанием специфических свойств. Этот
способ определяет знания. Другой способ определяет понятие через
перечисление понятий более низкого уровня иерархии или фактов,
относящихся к определяемому. Этот – определяет данные, или
экстенсионал понятия.
Например, интенсионал понятия «персональный компьютер»:
«Персональный компьютер – это дружественная ЭВМ, которую можно
поставить на стол и купить менее чем да $2000 – 3000». Экстенсионал
этого понятия: «Персональный компьютер – это Mac, IBM PC, Sinker…»
80
81.
Определение данных и знанийДля хранения данных используются базы данных (для них характерны
большой объем и относительно небольшая удельная стоимость информации), для
хранения знаний – базы знаний (небольшого объема, но исключительно дорогие
информационные массивы). База знаний – основа любой интеллектуальной
системы.
Знания могут быть классифицированы по следующим категориям:
поверхностные – знания о видимых взаимосвязях между отдельными
событиями и фактами в предметной области,
глубинные – абстракции, аналогии, схемы, отображающие структуру и
процессы в предметной области
Знания можно разделить на процедурные и декларативные. Исторически
первичными были процедурные знания, т.е. знания, «растворенные» в
алгоритмах. Они управляли данными. Для их изменения требовалось изменять
программы. Однако с развитием искусственного интеллекта приоритет данных
постепенно изменялся, и все большая часть знаний сосредоточивалась в
структурах данных (таблицы, списки, абстрактные типы данных), т.е.
увеличивалась роль декларативных знаний.
81
82.
Определение данных и знанийСегодня знания приобрели чисто декларативную форму: знаниями
считаются предложения, записанные на языках представления знаний,
приближенных к естественному и понятных неспециалистам. Существуют
десятки моделей (или языков) представления знаний для различных
предметных областей.
Большинство из них может быть сведено к следующим классам:
продукционные,
семантические сети,
фреймы,
формальные логические модели.
82
83.
Этапы трансформации данных и знанийТермин «инженерия знаний» (русский эквивалент английского
термина knowledge engineering) используется для обозначения области
теории искусственного интеллекта, которая занимается языками для
представления знаний, методами пополнения знаний, процедурами
проверки их корректности и непротиворечивости и, наконец,
использованием знаний при решении различных задач и созданием
практических систем для хранения и обработки знаний. Термин «знание» в
области искусственного интеллекта употребляется весьма часто и в
несколько различающихся между собой значениях.
В теории и практике программирования используется термин
«данные», в какой-то мере родственный термину «знания». В процессе
эволюции программирования то, что понималось под термином «данные»,
видоизменялось и усложнялось.
83
84.
Этапы трансформации данных и знанийНа начальном этапе под данными подразумевались двоичные слова
фиксированной длины. Их длина определялась длиной машинного слова,
принятого в той или иной ЭВМ. Затем, например, путем «склеивания»
между собой нескольких машинных слов или выделения из машинного
слова части входящих в него разрядов. Затем стало возможным считать
данными упорядоченные совокупности машинных слов. Например, в виде
прямоугольных матриц, списков различной структуры, документов
заданной формы. В настоящее время в программировании начинают
использоваться так называемые абстрактные типы данных, структуру
которых можно задавать произвольно, описывая ее средствами
программирования.
84
85.
Этапы трансформации данных и знанийРазвитие работ в области искусственного интеллекта породило
новые типы языков программирования (Лисп, Пролог, Плэнер и другие),
работающие со сложно структурированными данными. Стали появляться
специальные языки для описания данных со сложной структурой (ФРЛ,
КРЛ и другие), в которых данные (их стали уже называть знаниями)
организованы в специальные структуры, носящие особые названия:
фреймы, семантические сети, сценарии, вычислительные модели и т.п.
другими словами, происходит постепенное усложнение данных и
превращение их в знания.
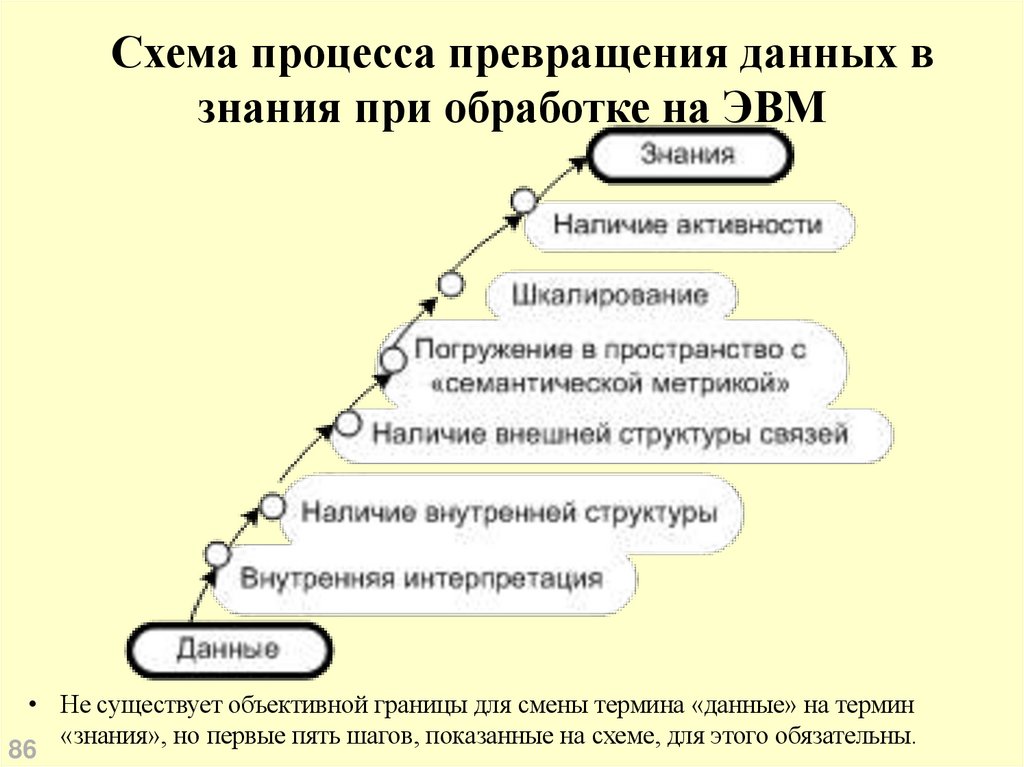
Не существует объективной границы для смены термина «данные»
на термин «знания», но первые пять шагов, показанные на схеме далее,
для этого обязательны.
85
86.
Схема процесса превращения данных взнания при обработке на ЭВМ
• Не существует объективной границы для смены термина «данные» на термин
«знания», но первые пять шагов, показанные на схеме, для этого обязательны.
86
87.
Этапы трансформации данных и знанийНаличие внутренней интерпретации позволяет ЭВМ отвечать на
вопросы, качающиеся содержимого ее памяти. И в настоящее время оно
полностью реализовано в широко распространенных реляционных базах
данных.
Наличие внутренней структуры связей еще больше упростило
работу с данными.
Когда отдельные машинные слова стали объединяться в более
сложные структуры (например в списки), появилась возможность работать
с информационными единицами более богатой внутренней структуры.
Будем считать, что в качестве значений слотов в этой структуре смогут
выступать новые информационные единицы. В этом случае слоты будут
как бы вкладываться друг в друга, напоминая игрушку «матрешка». И в
настоящее время оно реализовано в информационных единицах,
называемых фреймами.
Наличие внешней структуры связей реализовано в семантической
сети. Здесь информация упорядочена на основе классифицирующих и
ситуативных отношений.
87
88.
Этапы трансформации данных и знанийШкалирование. В памяти человека сведения об окружающем его
мире и возможных действиях в нем упорядочены не только
классифицирующими и ситуативными отношениями. Для фиксации
соотношений отдельных информационных единиц он использует
различные шкалы. Простейшие из них – метрические шкалы. С их
помощью можно устанавливать количественные соотношения и порядок
тех или иных совокупностей информационных единиц.
Множества абсолютных и относительных метрических шкал и
порядковых шкал, включая размытые шкалы, не исчерпывает всех шкал,
используемых в когнитивных структурах, характерных для человека.
Выделяют еще так называемые оппозиционные шкалы. Оппозиционные
шкалы образуются с помощью пар слов антонимов. Такие пары есть в
каждом естественном языке. Их число для различных языков колеблется
около 400, Примерами их могут служить Сильный-Слабый. КрасивыйБезобразный. Хороший-Плохой, Острый-Тупой, Тяжелый-Легкий и т. п. В
оппозиционных шкалах маркированы лишь концы шкалы.
88
89.
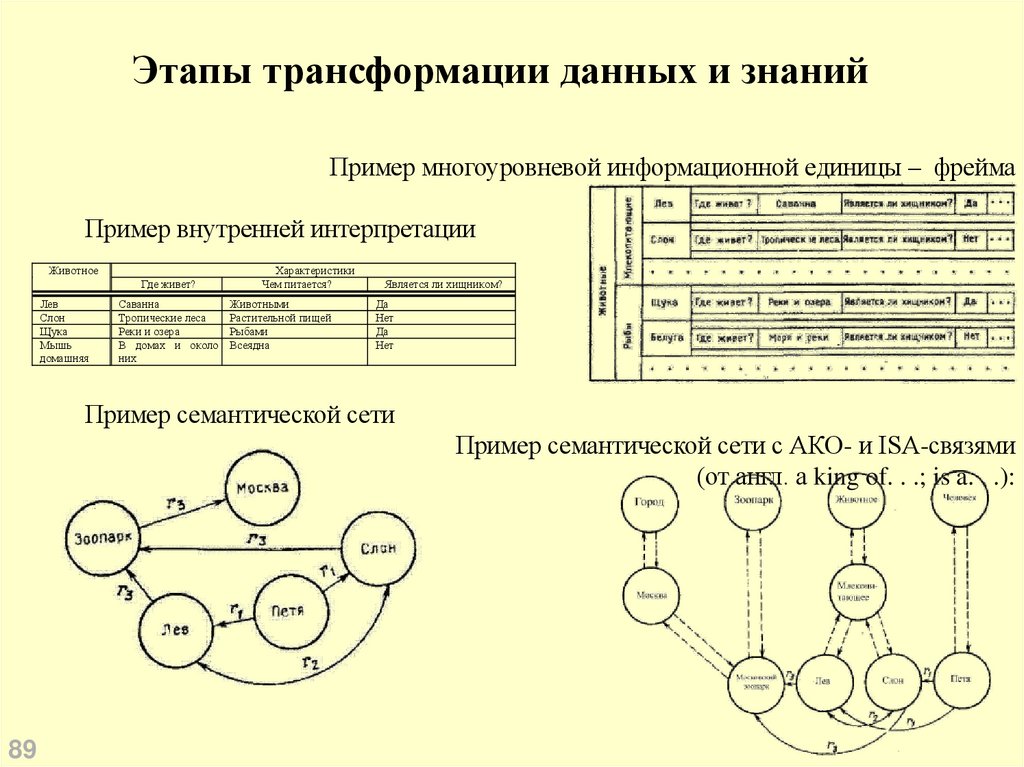
Этапы трансформации данных и знанийПример многоуровневой информационной единицы – фрейма
Пример внутренней интерпретации
Животное
Где живет?
Лев
Слон
Щука
Мышь
домашняя
Саванна
Тропические леса
Реки и озера
В домах и около
них
Характеристики
Чем питается?
Животными
Растительной пищей
Рыбами
Всеядна
Является ли хищником?
Да
Нет
Да
Нет
Пример семантической сети
Пример семантической сети с АКО- и ISA-связями
(от англ. a king of. . .; is a. . .):
89
90.
Этапы трансформации данных и знанийПространство с семантической метрикой
Упорядочение сведений в когнитивных структурах человека
происходит не только благодаря применению шкал. Уже давно
выдвигалась гипотеза, что когнитивные структуры человека погружены в
некое пространство, метрика которого характеризирует семантическую
близость тех или иных понятий, фактов и явлений. Первую попытку
построить такое пространство предпринял в конце 20-х годов
американский психолог Ч. Осгуд. Для построения пространства, куда
можно было бы погрузить человеческие знания, он воспользовался
набором оппозиционных шкал. Осгуд, его ученики и многочисленные
последователи собрали огромный статистический материал о способах
размещения людьми слов из заданного им списка по набору
оппозиционных шкал (число шкал колебалось около 400 при переходе от
одного естественного языка к другому).
90
91.
Этапы трансформации данных и знанийОказалось, что эти размещения не случайны, а отражают некоторые
характерные для той или иной социокультурной общности
закономерности. Например, для всех народов европейской культуры слово
«отец» на шкале Острый – Тупой смещается в сторону конца шкалы,
маркированного словом «тупой», а слово «молоток» на шкале Сильный –
Слабый явно тяготеет к левому концу шкалы. Полученный материал
подвергался статистической обработке по методу главных факторов. По
результатам обработки было построено трехмерное пространство
Осгуда, в котором факторы-оси можно интерпретировать как шкалы
оценок, силы и активности.
В семантическом пространстве человека существуют, по крайней
мере, две системы оценки близости информационных единиц. Одна
опирается на их ситуативную близость, а вторая – на частоту появления
тех или иных ситуаций или конкретных представителей в типовых
ситуациях.
91
92.
Этапы трансформации данных и знанийНаличие активности является шестым свойством знаний. С
самого начала своего развития программирование для ЭВМ пошло по
пути разделения программы и данных, с которыми эта программа
работает. В программе было сосредоточено процедурное знание. Оно
хранило в себе информацию о том, как надо действовать, чтобы получить
нужный результат. Знания в нужный момент использовались программой.
Таким образом, программа играла роль активатора данных. Знания другого
типа, которые обычно называют декларативными, хранили в себе
информацию о том, над чем надо выполнять эти действия. Процедурное
знание формировало обращение к декларативному знанию, воплощенному
на первом этапе развития программирования в пассивно лежащие в
памяти ЭВМ данные.
92
93.
Этапы трансформации данных и знанийКак показывают исследования когнитивных структур человека, для
него складывается как бы противоположная ситуация. Не процедурные
знания активизируют декларативные, а наоборот – та или иная структура
декларативных знаний оказывается активатором для процедурных знаний.
Для подхода такого типа к современным системам, когда та или иная
структура, сложившаяся между единицами определенного вида, является
источником вызова (или синтеза из готовых стандартных модулей)
процедур, цель которых в желании изменить когнитивные структуры через
воздействие на среду и окружающую систему, предпринимаются попытки
реализации (за счет больших объемов и мощных систем распознавания).
93
94.
Этапы трансформации данных и знанийВместо этого используются смешанные представления, в которых
декларативные и процедурные знания понимаются единообразно и могут
активизировать друг друга. В качестве примера смешанного
представления можно рассмотреть фрейм, у которого в качестве значения
какого-то его слота выступает имя процедуры, подлежащей выполнению.
Обращение к данному слоту может обусловливаться либо другими
слотами данного фрейма, либо другими фреймами. Это позволяет
формировать условия, необходимые для выполнения той или иной
процедуры, а следовательно, сделать активаторами процедур
декларативные знания, хранящиеся в определенных слотах фреймов,
образующих семантическую сеть.
94
95. 2.6. Особенности и признаки интеллектуальности информационных систем
9596.
Понятие информационной системыОснову ИС составляют «три кита»:
― База данных, как правило, реляционного типа, поддерживающая
ступ на основе стандарта SQL
― Программные средства, обеспечивающие логику обработки данных
― Интерфейс пользователя
96
Являются информационной системой:
― 1С-Бухгалтерия 8.0. Используется в целях формирования
бухгалтерской отчетности предприятия перед налоговыми
органами.
― Книга MS Excel, содержащая сведения о штатном расписании,
работниках предприятия, позволяющими рассчитывать заработную
плату и формировать платежные ведомости.
Не является информационной системой.
― MS Excel. Программное средство универсального характера,
предназначенное для манипуляций с данными, представленными в
табличной форме.
― Реляционная база данных DB-2 фирмы IBM.
97.
Функции ИСИнформационная система (ИС) выполняет следующие функции:
воспринимает вводимые пользователем информационные запросы и
необходимые исходные данные;
обрабатывает введенные и хранимые в системе данные в соответствии
с известным алгоритмом;
формирует требуемую выходную информацию.
С точки зрения реализации перечисленных функций ИС можно
рассматривать как фабрику, производящую информацию, в которой
заказом является информационный запрос, сырьем – исходные данные,
продуктом – требуемая информация, а инструментом (оборудованием) –
знание, с помощью которого данные преобразуются в информацию
97
98.
Двоякая природа знанийЗнание имеет двоякую природу:
фактуальную
операционную.
Фактуальное знание – это осмысленные и понятые данные. Данные сами
по себе – это специально организованные знаки на каком-либо носителе.
Операционное знание – это те общие зависимости между фактами,
которые позволяют интерпретировать данные или извлекать из них
информацию.
98
99.
1-й путь соединенияоперационного и фактуального знаний
Информация, по сути – это новое и полезное знание для решения какихлибо задач. Процесс извлечения информации из данных сводится к
адекватному соединению операционного и фактуального знаний и в
различных типах ИС выполняется по-разному. Самый простой путь их
соединения осуществляется в рамках одной прикладной программы по
схеме:
Программа =
Алгоритм (Правила преобразования данных + Управляющая структура) +
Структура данных
Здесь операционное знание (алгоритм) и фактуальное знание (структура
данных) неотделимы друг от друга.
У этого способа – плохая адаптивность к изменениям информационных
потребностей.
99
100.
2-й путь соединенияоперационного и фактуального знаний
В системах, основанных на обработке баз данных (СБД – Data Base
Systems), происходит отделение фактуального и операционного знаний
друг от друга. Первое организуется в виде базы данных, второе – в виде
программ. Причем программа может автоматически генерироваться по
запросу пользователя (например, реализация SQL запросов). В качестве
посредника между программой и базой данных выступает программный
инструмент доступа к данным – система управления базой данных
(СУБД):
СБД = Программа <=> СУБД <=> База данных
Концепция независимости программ от данных повышает гибкость ИС по
выполнению произвольных информационных запросов, но для
формулирования информационного запроса пользователь должен ясно
представлять себе структуру БД и алгоритм решения задачи. Схема БД
выступает в роли промежуточного звена в процессе отображения
логической структуры данных на структуру данных прикладной
программы
100
101.
3-й путь соединенияоперационного и фактуального знаний
Общие недостатки традиционных ИС, к которым относятся
системы первых двух типов, заключаются
в слабой адаптивности к изменениям в предметной области
и информационным потребностям пользователей,
в невозможности решать плохо формализуемые задачи, с
которыми управленческие работники постоянно имеют дело.
101
102.
3-й путь соединенияоперационного и фактуального знаний
Анализ структуры программы показывает возможность
выделения из программы операционного знания (правил
преобразования данных) в так называемую базу знаний, которая
в декларативной форме хранит общие для различных задач
единицы знаний. При этом управляющая структура приобретает
характер универсального механизма решения задач (механизма
вывода), который связывает единицы знаний в исполняемые
цепочки (генерируемые алгоритмы) в зависимости от
конкретной постановки задачи (сформулированной в запросе
цели и исходных условий). Такие ИС становятся системами,
основанными на обработке знаний (СБЗ – Knowledge Base
(Based) Systems):
СБЗ = База знаний <=>
Управляющая структура (Механизм вывода) <=> База данных
102
103.
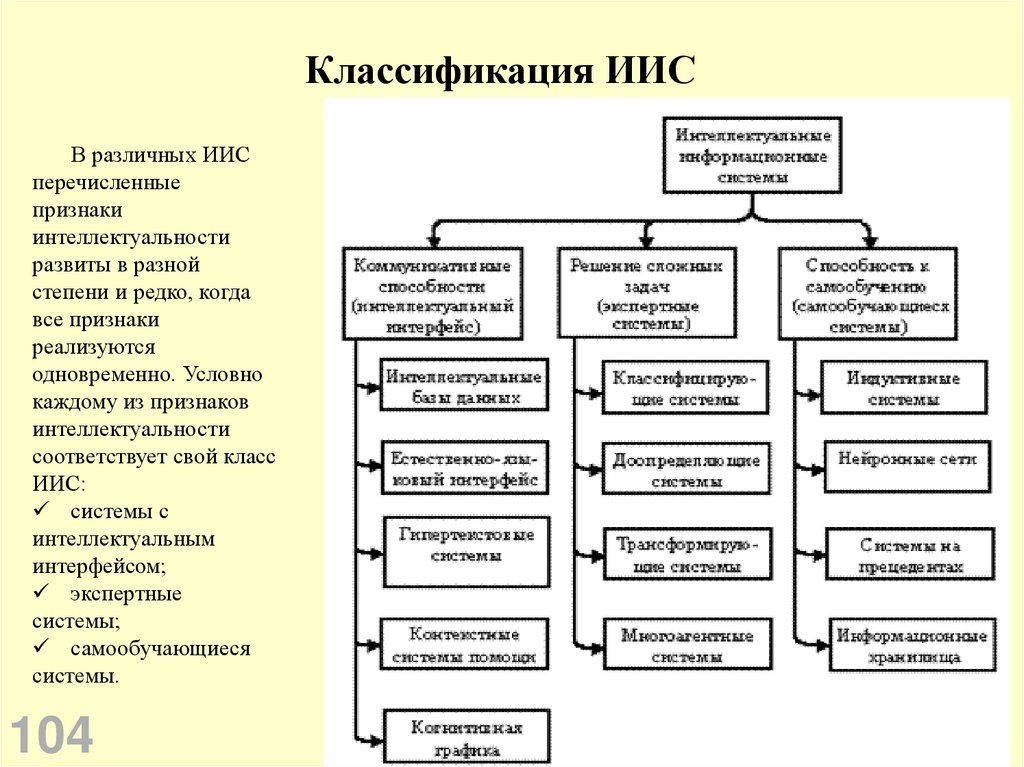
Признаки ИИСДля ИИС, ориентированных на генерацию алгоритмов решения задач,
характерны следующие признаки:
развитые коммуникативные способности,
умение решать сложные плохо формализуемые задачи,
способность к самообучению.
Коммуникативные способности ИИС характеризуют способ взаимодействия
(интерфейса) конечного пользователя с системой, в частности,
возможность формулирования произвольного запроса в диалоге с ИИС на
языке, максимально приближенном к естественному.
Сложные плохо формализуемые задачи – это задачи, которые требуют
построения оригинального алгоритма решения в зависимости от
конкретной ситуации, для которой могут быть характерны
неопределенность и динамичность исходных данных и знаний.
Способность к самообучению – это возможность автоматического извлечения
знаний для решения задач из накопленного опыта конкретных ситуаций.
103
104.
Классификация ИИСВ различных ИИС
перечисленные
признаки
интеллектуальности
развиты в разной
степени и редко, когда
все признаки
реализуются
одновременно. Условно
каждому из признаков
интеллектуальности
соответствует свой класс
ИИС:
системы с
интеллектуальным
интерфейсом;
экспертные
системы;
самообучающиеся
системы.
104