





























 Информатика
ИнформатикаПохожие презентации:




Multiple category method
1.
2.
思路– 将一个问题定义成几个变量 用这几个变量来描述该
问题的几个可能被选择的答案。
编码方式
– 多选项二分法 (multiple dichotomize method)
– 多选项分类法 (multiple category method)
3.
例 如果您家近年来生活水平提高了 那么主要原因是 任选2项
a.家庭就业人数增加
b. 工资增加
c.奖金和津贴增加
d. 其他收入来源增加
4.
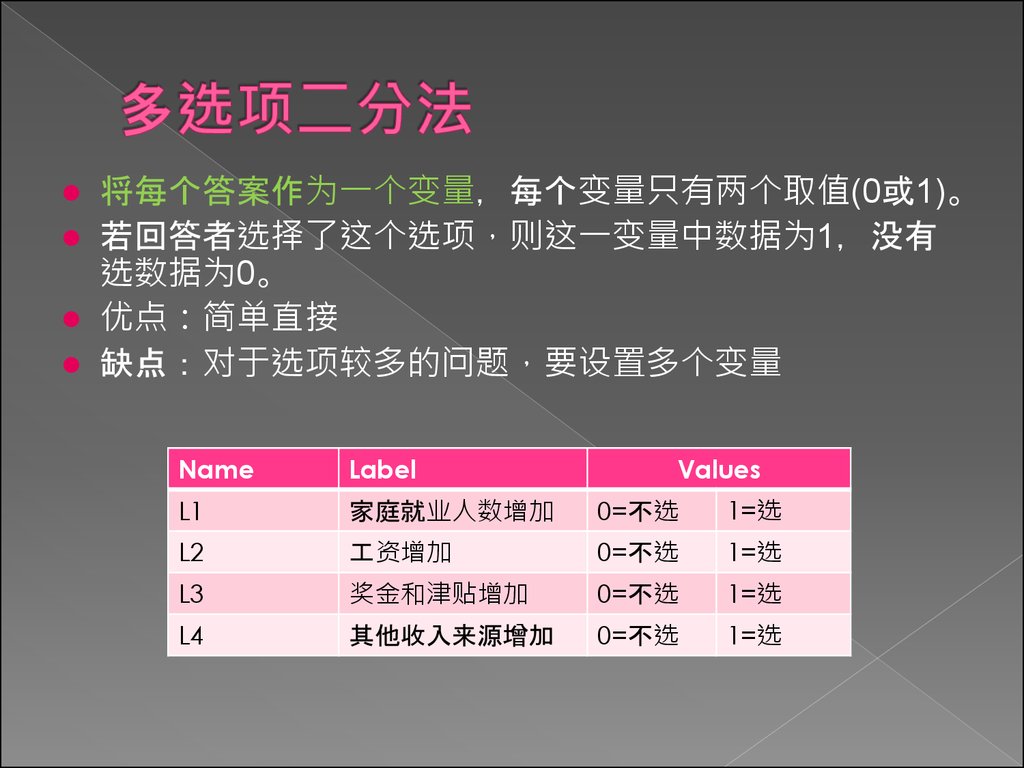
将每个答案作为一个变量 每个变量只有两个取值(0或1)。若回答者选择了这个选项 则这一变量中数据为1 没有
选数据为0。
优点 简单直接
缺点 对于选项较多的问题 要设置多个变量
Name
Label
Values
L1
家庭就业人数增加
0=不选
1=选
L2
工资增加
0=不选
1=选
L3
奖金和津贴增加
0=不选
1=选
L4
其他收入来源增加
0=不选
1=选
5.
预先估计多选项问题可能被选择的最多答案数.为每个答案建立一个变量,取值为多选项问题的可选答案.
譬如 一个多选题 如果有3个答案 就设置3个变量。
Name
Label
Values
V1
第一选项
1=家庭就业人数增加 2=工资增加
3=奖金和津贴增加 4=其他收入来源增加
V2
第二选项
1=家庭就业人数增加 2=工资增加
3=奖金和津贴增加 4=其他收入来源增加
6.
问题 以下运动方式中 选出你最喜欢的三项
(a) 足球 (b) 篮球 (c) 羽毛球 (d) 慢跑
(e) 瑜伽 (f) 游泳 (g) 其他
7.
采用多选项分类法 设置3个变量Name
Label
Values
V1
第一选项
1=足球 2=篮球 3=羽毛球 4=慢跑
5=瑜伽 6=游泳 7=其他
V2
第二选项
1=足球 2=篮球 3=羽毛球 4=慢跑
5=瑜伽 6=游泳 7=其他
V3
第三选项
1=足球 2=篮球 3=羽毛球 4=慢跑
5=瑜伽 6=游泳 7=其他
8.
打开数据 File —Open ---- Data 命令定义变量的属性
练习 在spss中打开“居民储蓄调查数据.xls”
9.
为分析需要 有时需要对数据进行添加、修改、整理。
个案排序
个案的寻找
个案的插入或删除
变量的插入或删除
数据文件 “Employee data.sav”
10.
个案排序是重新排列数据的先后次序 以指定的某个变量值为基准进行升序或降序。
例 把所有的数据根据被调查者的工资进行排序
变量名为salary
例 把所有的数据根据被调查者的教育年限进行
排序 要求教育年限从小到大 变量名为educ
例 把所有的数据根据被调查者的工资及教育年
限同时进行排序
11.
当遇到两个或多个变量进行排序的情况是SPSS的排序规则是先按第一个变量升序或降
序排列 当第一个变量值相同时再根据第二
个变量值排序。
12.
想要对某个个体情况进行了解Data菜单中的Go to case 命令
例 快速寻找序号为364的调查者的相关情况
13.
仅需要对数据文件中部分数据进行分析。例
① 分析者只希望看见男性调查者的相关情况
② 分析者只希望对受教育年限超过16年的进行
分析
③ 分析者希望对受教育年限超过16年的男性进
行分析
④ 分析者希望对受教育年限超过16年、工资超
过20,000的男性进行分析
14.
插入一个新的个案1 菜单法 2 选中某行
插入一个新的变量
1 菜单法 2 选中某列 3 Variable
View 标签法
15.
为研究问题方便 在已存在变量的基础上建立新的变量
Transform----Compute
例 考虑工资salary的自然对数
例 打开数据文件“dietstudy.sav”。
1. 计算每个病人患病后体重与原始体重之间的差值
2. 计算每个病人不同时期体重的平均值
3. 计算每个男性病人不同时期体重的平均值
4. 计算每个年龄在50岁以上的男性病人不同时期体
重的平均值
16.
打开“credit_card.sav”.要求
1. 把所有的数据依据变量 spent 进行排序 降
序 。
2. 快速寻找第 15163 个调查者的信用卡基本情
况。
3. 提取交易类型为 travel 出生日期为197908-29的男性数据
4. 计算spent/12的值
17.
18.
统计数据的整理根据任务 对原始数据进行科学加工及汇总。
目的 更好展示数据
表现形式 统计图或表
数据类别 质别数据和量别数据
19.
质别数据非数字型
反映类别、一定次序、品质特征
即 分类数据 categorical)、顺序数据
(ordinal)
如 性别、企业、受教育程度等
20.
图饼图 (pie chart)
条形图 (bar chart)
Pareto图
表
频数表——一个
列联表——两个或两个以上
21.
表编制频数分布表
图
绘制条形图(simple)、饼图等
22.
问题1 分析员工的工作类别情况 即对变量名为 jobcat 的变量进行汇总
问题2 不同性别的员工基本情况
问题3 分析不同性别、不同工作类别的员工
的基本情况
23.
Analyze——Descriptive Statistics——Frequencies
Format 输出结果按一定次序排序
› 按变量值升序排列
› 按变量值降序排列
› 按频数升序排列
› 按频数降序排列
24.
对工资(salary)进行分组低收入 50,000以下
中等收入 50,000—100,000
高收入 100,000以上
问题 统计高中低收入各自人数
25.
数值型数据----频数分布表先按照一定次序分组 recode 得到新的变量
再利用新的变量绘制频数分布表
26.
表交叉表 crosstabs 列联表
图
条形图(clustered, stacked)
27.
Analyze——Descriptive Statistics——crosstabs
Cells 显示百分比percentages
对结果的分析
28.
低收入有264人 中等收入有173人 高收入有37人。
低收入占55.7% 中等收入占36.5% 高收入
占7.8%。
29.
问题对性别、收入及工作类别三者进行交叉汇
总。
Analyze——Descriptive Statistics——
crosstabs——layer
对结果的分析
30.
1、将 salbegin 进行分组 recode 生成的新变量叫salbeginnew 15,000以下为第一组 15,000到30,000为第
二组 30,000以上为第三组。
2、对 salbeginnew 及变量值 value 加标签
salbeginnew 的标签为初始收入分组 第一组 低收入 第
二组 中等收入 第三组 高收入。
3、做出初始收入分组的频数分布表 每个组各有多少人 各
占百分之多少
4、做出初始收入分组与 jobcat 的交叉频数表 高收入的
manager有多少人 高收入manager占所有人的百分比有多
少 高收入manager占高收入的人的百分比有多少
31.
打开“student.sav”数据1.
2.
3.
4.
分析不同学生血型 (blood_n)分布情况 用图和表进行
表示
分析不同性别 (sex)的学生的血型分布情况
学生血型与教育背景 (edu_b)有关系吗 请给出你的理
由
对男生身高进行分组 第一组 170以下 低 、第二
组 170-178 中等 、第三组 178以上 高 。并在
男生中对不同身高的人数进行统计。
要求 最后提交word和output 文件名 学
号+姓名 发送至xiongwei@uibe.edu.cn