








































")
")












![Классификация методов [8]](https://cf.ppt-online.org/files1/slide/f/fnSE2Wr9mG0N3i8j4FxwCDXdIQyLotpvZReTsUYbK/slide-57.jpg "Классификация методов [8]")
![Классификация методов [8]](https://cf.ppt-online.org/files1/slide/f/fnSE2Wr9mG0N3i8j4FxwCDXdIQyLotpvZReTsUYbK/slide-58.jpg "Классификация методов [8]")
![Классификация методов [8]](https://cf.ppt-online.org/files1/slide/f/fnSE2Wr9mG0N3i8j4FxwCDXdIQyLotpvZReTsUYbK/slide-59.jpg "Классификация методов [8]")
![Классификация методов [8]](https://cf.ppt-online.org/files1/slide/f/fnSE2Wr9mG0N3i8j4FxwCDXdIQyLotpvZReTsUYbK/slide-60.jpg "Классификация методов [8]")
![Классификация методов [8]](https://cf.ppt-online.org/files1/slide/f/fnSE2Wr9mG0N3i8j4FxwCDXdIQyLotpvZReTsUYbK/slide-61.jpg "Классификация методов [8]")







 Интернет
ИнтернетПохожие презентации:










Извлечение знаний из Web — Web Mining
1. «Извлечение знаний из Web — Web Mining»
Методы извлечения информации из сетевых источниковLecture 2
Prykhodko Tatyana
2. Содержание
1ОПРЕДЕЛЕНИЕ WEB MINING и DATA MINING
2
ЗАДАЧИ WEB MINING
3
ЭТАПЫ WEB MINING
4
КАТЕГОРИИ WEB MINING
5
WEB SCRAPING
2
3. Поиск информации
Data miningБиблиотеки и архивы
WEB mining
3
4. Web Mining и Web Analytics
В конце 90-х годов европейскими ученымибыли предложены термины Web Mining
(WM) и Web Analytics (WA), соотносящиеся
примерно так же, как Data Mining (DM) и
Data Analytics:
WM в большей мере относится к формальным
методам выделения по заданным шаблонам
полезных данных из сырых
а WA ближе к семантике — извлечение
полезной информации из данных.
4
5. Понятие Data Mining
Data Mining - технология, предназначенная для поиска вбольших объемах данных неочевидных, объективных и
практически полезных закономерностей.
В основе Data Mining лежат эффективные методы и
алгоритмы, разработанные для анализа
неструктурированных данных большого объема и
размерности.
Ключевой момент состоит в том, что данные большого
объема и большой размерности представляются
лишенными структуры и связей. Цель технологии добычи
данных – выявить эти структуры и найти закономерности
там, где, на первый взгляд, царит хаос и произвол, т.е.
превратить данные в ЗНАНИЯ.
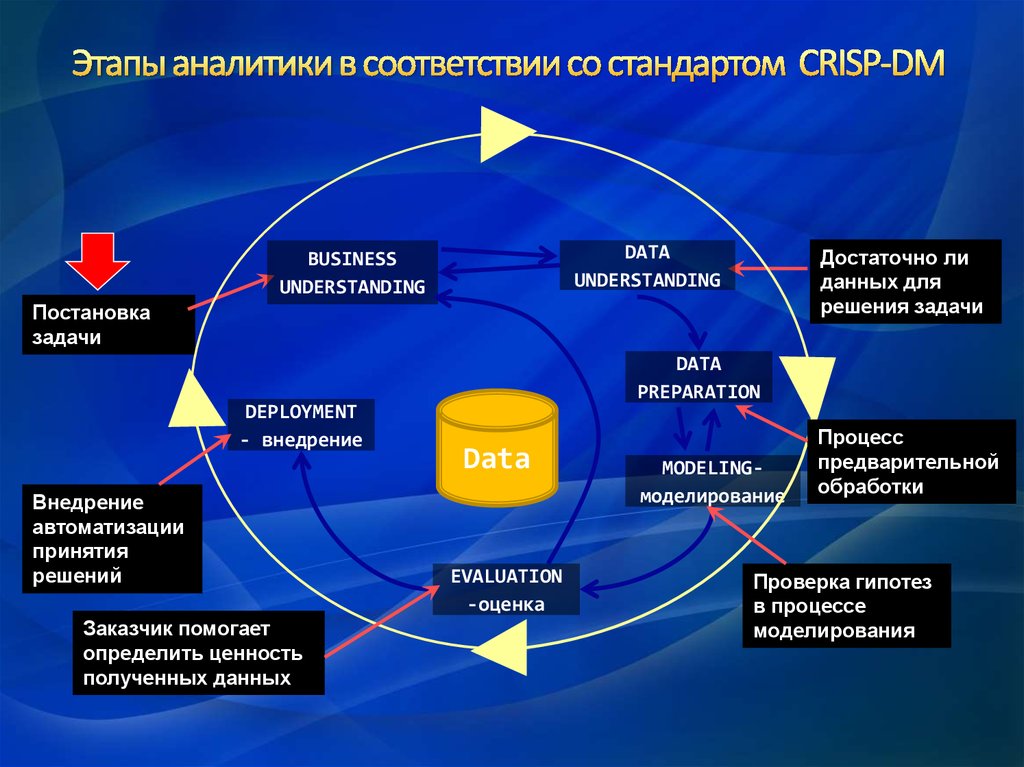
6.
DATAUNDERSTANDING
BUSINESS
UNDERSTANDING
Достаточно ли
данных для
решения задачи
Постановка
задачи
DEPLOYMENT
- внедрение
Внедрение
автоматизации
принятия
решений
Заказчик помогает
определить ценность
полученных данных
DATA
PREPARATION
Data
EVALUATION
-оценка
MODELINGмоделирование
Процесс
предварительной
обработки
Проверка гипотез
в процессе
моделирования
7. Задачи Data Mining
КлассификацияКластеризация
Прогнозирование
Ассоциация
Обнаружение и анализ и отклонений
Оценивание
Анализ связей
Визуализация
Подведение итогов
7
8. Data Mining и Web Mining
Web Mining отличается от Data Mining масштабом, способомдоступа и структурой данных.
В традиционном DM обработка базы данных с одним миллионом
записей считается большой работой, а в WM даже обработку 10
млн страниц нельзя назвать чем-то выдающимся.
DM имеет дело с корпоративными данными, что требует
соответствующих полномочий, а в WM обычно используются
публичные данные и нет необходимости в правах доступа, но
следует соблюдать определенные этические нормы. Хотя
краулеры (поисковые программы-роботы), распространяемые
поисковыми машинами, создают для сайтов дополнительную
нагрузку, администраторы им не противодействуют, поскольку в
результате создаются индексы, способствующие увеличению
посещаемости. Однако WM не придает сайтам дополнительных
качеств, поэтому краулеры должны быть тактичными.
Традиционный DM получает структурированные данные из баз
8
данных, а WM оперирует неструктурированными или
квазиструктурированными данными.
9. Определение
Web Mining — это использование методовинтеллектуального анализа данных для
автоматического обнаружения вебдокументов и услуг, извлечения информации
из веб-ресурсов и выявления общих
закономерностей в Интернете.
Понятие явилось эволюцией Data Mining,
использует те же методы интеллектуального
анализа данных, его продолжением
прогнозируется Cloud Mining.
9
10. Web Mining — технология, использующая методы Data Mining для исследования и извлечения информации из Web-документов и сервисов
Поиск значимой информации;Создание новых знаний из доступной на Web
информации;
Изучение потребностей индивидуального
пользователя;
Персонализация информации.
10
11. Поиск значимой информации
Из предыдущей лекции ясно, чтоинформационным поиск (information retrieval, IR)
с помощью обычных поисковиков далеко не
всегда эффективен:
небольшой процент действительно нужной
информации среди множества ссылок, которые
предоставляют поисковые системы;
низкая результативность, связанная с
невозможностью индексировать все Web-ресурсы. В
результате возникают трудности поиска
неиндексированной информации, которая может быть
необходима для пользователя.
11
12. Поиск значимой информации
Современный поиск выходит далеко за рамкииндексирования. Самая жестокая конкурентная
борьба среди фирм, занимающихся поисковыми
системами, не охватывает технологические
проблемы индексирования, но разворачивается
вокруг таких задач, как
оценка ссылок,
анализ экранных данных,
также обработка естественного языка.
Подобные методики повышают функциональные
возможности поиска, что иногда оборачивается
миллиардами долларов, как это было в случае
фирмы Google.
12
13. В бизнес-аналитике Web Mining решает следующие задачи:
описание посетителей сайта (кластеризация,классификация);
описание посетителей, которые совершают покупки
в интернет-магазине (кластеризация,
классификация);
определение типичных сессий и навигационных
путей пользователей сайта (поиск популярных
наборов, ассоциативных правил);
определение групп или сегментов посетителей
(кластеризация);
нахождение зависимостей при пользовании
услугами сайта (поиск ассоциативных правил).
13
14. Этапы Web Mining
1. Входной этап (input stage) — получение «сырых»данных из источников (логи серверов, тексты
электронных документов);
2. Этап предобработки (preprocessing stage) —
данные представляются в форме, необходимой
для успешного построения той или иной модели;
3. Этап моделирования (pattern discovery stage);
4. Этап анализа модели (pattern analysis stage) —
интерпретация полученных результатов.
14
15. Направления Web Mining
19961997
Web Mining
Web Usage
Mining
Web Content Mining
15
16. Направления Web Mining
1996Web Mining
1997
Web Content Mining
Web Usage
Mining
1999
Web
Content
Mining
Web Usage
Mining
Web
Structure
Mining
16
17. Категории Web Mining
В области Web Mining выделяют следующиенаправления анализа:
Извлечение Web-контента (Web Content Mining);
Извлечение Web-структур (Web Structure Mining);
Исследование использования Web-ресурсов (Web
Usage Mining).
17
18. Направления Web Mining: Характеристика
Web UsageMining
Web Structure
Mining
Web Content
Mining
• Логи вебсерверов;
• Ссылки
• HTML-страницы;
документы в
других форматах
• Предпочтений
посетителей.
• Взаимосвязь
между
страницами
• Информация и
знания.
18
19. Web Content Mining
Web UsageMining
Web Structure
Mining
Web Content
Mining
20. Web Content Mining
(Извлечение веб-контента) —процесс извлечения знаний из контента документов
или их описания, доступных в Интернете. Именно
это направление Web Mining решает трудоемкую
задачу поиска знаний в сети Интернет.
Оно основано на сочетании возможностей
информационного поиска, машинного обучения и
интеллектуального анализа данных. Включает
следующие направления:
Извлечение из Баз Данных - Database approach (DB)
Информационный поиск - Information retrieval (IR)
Обработка естественных языков Natural language
processing (NLP)
20
Глубокий синтаксический и семантический анализ
21. Web Content Mining
(WCM) имеет общие черты с DM и TextMining (TM):
DM
WCM
Структурированные, неструктурированные и
слабоструктурированные данные
TM
Неструктурированные
данные
За последние несколько лет WCM стал областью активных
исследований, и основные сложности здесь вызваны
гетерогенностью веб-данных и их низкой структуризацией,
21
затрудняющей выделение целевой информации
22. Web Content Mining
В WCM необходимо решать ряд специфическихзадач:
извлечение структурированных данных из веб-страниц с
использованием методов машинного обучения и
нейронных сетей;
формирование процедур унификации форматов
представления данных и их интеграции из разных
источников;
выделение оценок продуктов и услуг в отзывах,
размещаемых на форумах, в блогах и чатах.
Для отделения содержательной составляющей
страниц от служебных и рекламных текстов
требуются соответствующие процедуры
сегментации.
22
23.
В WCM для каждого из трех типов данных(структурированные, неструктурированные и
квазиструктурированные) используются собственные
методы обработки, но независимо от этого почти всегда
выполняется процедура перевода данных из формы,
предназначенной для чтения человеком, в форму,
удобную для обработки компьютером.
Такая процедура называется
, или «срезание
данных с поверхности».
Механизм, выполняющий преобразование, извлеченных
из WEB-страниц данных, в структурированный вид
называется
23
24.
Первые технологии data scraping применялись сначала намэйнфреймах и позже на миникомпьютерах.
Много лет спустя эта же идея возродилась как Web Scraping
— в какой-то степени их работа напоминает индексацию
WWW, но ее цель заключается не в составлении индексов,
а в преобразовании неструктурированных данных,
существующих в формате HTML, в структурированные и
сохранении их в базах данных или в электронных таблицах.
24
25.
Диапазон технологий, используемых для Web Scraping,чрезвычайно широк, но в ряде случаев невозможно обойтись
без вмешательства человека, и тогда берут на вооружение
классический прием copy-and-paste. Есть еще простой, но
эффективный прием, известный как Text grepping,
построенный на базе UNIX-утилиты grep.
Подобным же образом могут быть использованы средства
для работы с регулярными выражениями, имеющиеся,
например, в языках программирования Perl и Pyton.
Программы разбора HTML используют то обстоятельство, что
многие сайты имеют в своем составе страницы, динамически
сгенерированные из содержимого структурированных
источников (баз данных), и для их создания применяются
общие для схожих страниц шаблоны. В таких случаях
используют программы-упаковщики (wrapper), которые,
наоборот, извлекают содержимое и переводят его в
25
реляционную форму.
26.
Создание упаковщиков — непростая задача, решаемая вчеловеко-машинном режиме, что требует больших
трудозатрат на первичную разметку страниц и поддержку
разметки на протяжении жизненного цикла данных.
Полностью автоматизированная генерация возможна пока
только на экспериментальном уровне, а высшим
достижением Web Scraping являются анализаторы вебстраниц с элементами искусственного интеллекта на базе
систем компьютерного зрения и машинного обучения.
Очевидно, что проще всего выполнять WCM для
структурированных данных — здесь достаточно применить
служебные процедуры сначала обхода страниц, затем
генерации и исполнения упаковщика, а потом можно
переходить к анализу содержимого страницы.
26
27.
Для работы со слабоструктурированными даннымипредложены специальные языки класса Web Data
Extraction Language, такие как, например, ELOG,
предназначенные для программ-упаковщиков.
С их помощью описывается процедура выделения
данных Top Down Extraction, завершающаяся
созданием объектной модели данных Object
Exchange Model (OEM).
27
28.
Использует методы TM в приложении к специфике WWW ипризван облегчить восприятие пользователем больших
массивов текстов. Выделяют несколько типов такого рода
операций:
отслеживание тематики (Topic Tracking) — оценка области интересов
пользователя и формирование рекомендаций потенциально
интересных ему документов;
свертка (Summarization) — создание резюме документов,
сокращающего объем необходимого чтения;
ранжирование (Categorization) — упорядочение документов и их
распределение по заранее определенным категориям;
кластеризация (Clustering) — объединение схожих документов в
группы;
визуализация (Information Visualization) или визуализация данных
(Data Visualization) — решение проблемы коммуникации
28
пользователя с данными, и особо здесь интересна визуализация
текстов (Text Visualization).
29.
Около дюжины компаний производят сегодняинструменты для WCM в виде традиционных
загружаемых коммерческих и свободнораспространяемых программ и облачных
сервисов. Визуализация еще не вышла на
коммерческий уровень, и все продукты этого
класса распространяются свободно.
29
30.
По мере наполнения World Wide Web растетнеобходимость в средствах для доступа к
данным. И хотя задача WM пока еще остается
исследовательской, уже появились готовые
доступные продукты, помогающие в решении
ее отдельных частей.
30
31. Web Structure Mining
Web UsageMining
Web Structure
Mining
Web Content
Mining
32. Web Structure Mining
(Извлечение веб-структур) — процессобнаружения структурной информации в Интернете.
Данное направление рассматривает взаимосвязи между
веб-страницами, основываясь на связях между ними.
Построенные модели могут быть использованы для
категоризации и поиска схожих веб-ресурсов, а также для
распознавания авторских сайтов.
В веб-графе вершины — это страницы WWW, а дуги —
гиперссылки между ними. По графу устанавливаются связи
между страницами, людьми и любыми иными объектами.
32
33. Web Structure Mining
Основное предназначение WSM для подхода Web GraphMining состоит в обнаружении взаимосвязи между вебстраницами и формировании иерархии гиперссылок. Таким
образом WSM обеспечивает заготовку для установления
связей между фрагментами информации на сайте, доступа
к информации по ключевым словам и контентного WM.
Иерархия гиперссылок используется еще для установления
с помощью поисковых машин системы гиперссылок,
обеспечивающих переход со страниц собственного сайта к
внешним сайтам — например, к сайтам конкурентов, где
размещена близкая по содержанию информация. Далее
связанные страницы можно кластеризовать по логическим
связям между одним или более сайтами,
принадлежащими партнерам или конкурентам.
33
34. Web Structure Mining
К результатам WSM можноприменить алгоритмы
ранжирования PageRank или
HITS (Hyperlink Induced Topic
Search), позволяющие найти
наиболее значимые страницы,
что напоминает подсчет
индекса цитирования научных
статей.
Понимание того, как контент
соотносится с рангом страницы,
позволяет повышать качество
сайта.
34
35. Web Usage Mining
Web StructureMining
Web Content
Mining
36. Web Usage Mining
Паутина становится важным инструментомпривлечения клиентов, что делает актуальной оценку
качества работы сайта, — этой цели служит
нагрузочный WM (Web Usage Mining, WUM),
позволяющий обнаружить модели поведения
пользователей по их цифровым следам на сайте:
пути доступа,
посещаемые страницы,
лог-записи,
регистрационные данные и др.
По полученным данным можно, например, создавать
рекомендации пользователю по посещению
интересных для него страниц, которые остались еще
без его внимания. Обычно процедуры WUM состоят из
36
нескольких основных шагов [2].
37. Web Usage Mining
3738.
Разнообразные пользовательские данные собираются насерверной и пользовательской сторонах, а также в проксисерверах.
Веб-сервер собирает запросы пользователей и хранит их в
журналах, но достоверность данных в журналах страдает из-за
проблемы идентификации сессии (session identification
problem), возникающей из-за кэшей, посылающих ответ на
запрос без обращения к серверу.
Сбор данных на стороне пользователя (Client Side Collection)
осуществляется встроенными в браузер агентами (Javaскрипты или Java-апплеты), но теоретически пользователь
должен выразить свое согласие на такой способ отслеживания.
В этом случае проблема идентификации сессии исключается,
тем не менее сохраняется ситуация, когда собранные данные
не вполне достоверны. Прокси-сервер получает запросы в том
же формате, что и веб-сервер, и может использовать их для
38
обобщенной оценки запросов.
39.
На этапе обработки с помощью разнообразныхэвристических алгоритмов выполняется последовательность
операций над журналами с целью преобразования потока
сырых данных в набор пользовательских досье (профилей).
Данные очищаются путем удаления несущественных
сведений (для большинства сайтов несущественны медиа
файлы, а для распространителей контента именно они
представляют наибольшую важность). В процессе очистки
учитываются коды состояния HTTP, учитываются только
успешные запросы с кодом от 200 до 299 (2XX). И
отбрасываются другие обращения – неудачные (4ХХ) и
перенаправленные (3ХХ).
39
40.
Затем происходит идентификация пользователя (UserIdentification), в простейшем случае она осуществляется по
IP или UID, но и здесь есть множество вспомогательных
решений, особенно продуктивно использование формата
Extended Log Format.
После этого идентифицируется сессия (Session
Identification) — анализ набора страниц, посещенных
пользователем за визит. Для решения этой задачи создано
огромное число эвристических алгоритмов, основанных на
времени пребывания на страницах и навигации по сайту.
Завершающий этап предобработки — формирование
образа (Path Completion) пользователя.
40
41.
Распознавание образов и анализЭто самый наукоемкий этап WUM, и чаще всего для
анализа сессий и посетителей применяются
статистические методы (Session and Visitor Analysis).
Данные агрегируют по определенным признакам, по
дням, по сессиям, по пользователям или доменам, а
полученные отчеты содержат сведения о наиболее часто
посещаемых страницах, времени пребывания на
странице, длине пути по сайту и т. п.
41
42.
Кластерный анализ служит для объединения объектов собщими признаками для сегментации посетителей сайтов и
страниц по их посещаемости. Это позволяет объединить в
группы пользователей, имеющих общие образы, —
например, по показателям, необходимым для целей
адресного маркетинга.
Ассоциативный и корреляционный анализ позволяет
устанавливать связи между теми или иными явлениями или
процессами. Анализ навигационных образов служит для
предсказания поведения пользователей, что необходимо,
скажем, для размещения рекламы.
42
43. Категории Web Mining (задачи)
44. Категории Web Mining (подклассы)
Гиперссылки внедокумента
45. Таблица 1 . Классификация задач Web Mining
Задачи Web MiningХарактеристики
задач
Тип данных
Анализируемые
данные
Подходы
к представлению
данных
Метод
Извлечение Web-контента
В целях
информационного
поиска
Неструктурированные.
Слабоструктурированные
Гипертекстовые и
текстовые
документы
Наборы слов, n-граммов.
Термины, фразы.
Понятия или онтологии.
Отношения
TFIDF и его варианты.
Машинное обучение.
Статические методы,
в том числе и NLP
В целях размещения
в БД
Извлечение
Web-структур
Слабоструктурированн
ые.
Web-сайт как БД
Структуры
ссылок
"Следы"
взаимодействия
Гипертекстовые
документы
Структуры
ссылок
Протоколы сервера.
Протоколы браузера
Отношения.
Маркированный граф
Граф
Реляционные таблицы.
Графы
Частные алгоритмы.
NLP.
Модифицированные
ассоциативные
правила
Статистические.
Модифицированные
Частные алгоритмы ассоциативные
правила.
Машинного обучения
Кластеризация.
Прикладное
применение задач
Классификация.
Правила поиска
извлечения.
Поиск шаблонов в тексте.
Моделирование
пользователя
Исследование
использования
Web-ресурсов
Поиск частных
подструктур.
Обнаружение схем
Web-сайтов
Кластеризация
и классификация
Конструкция сайта,
адаптация
и управление.
Маркетинг.
Моделирование
пользователей
46. ВЫВОДЫ:
Web Mining включает в себя этапы: поиск ресурсов,извлечение информации, обобщение и анализ;
Различают следующие категории задач Web Mining:
извлечение Web-контента, извлечение Web-структур и
исследование использования Web-ресурсов;
В решении задачи извлечения структуры Web
используются подходы из области социальных сетей,
библиометрики, ранжирования документов и т. п.
Существуют два основных подхода анализа
использования Web-ресурсов:
преобразование данных использования Web-сервера в
реляционные таблицы до выполнения адаптированных
методов Data Mining
и использование информации из файла протокола
непосредственно, применяя специальные методы
предварительной обработки.
46
47. Web SCRAPING
48.
Веб-скрейпинг*) тесно связан с понятиями веб-индексация(web indexing) и веб-сканер (web crawler).
Компонент веб-скрейпер использует веб-индексацию,
которая индексирует информацию в Интернете с помощью
бота или веб-сканера и является универсальной методикой,
которая принята в пользование большинством поисковых
систем.
Но в отличие от веб-сканера, веб-скрейпер больше
внимания уделяет преобразованию неструктурированных
данных в сети, которые, как правило, хранятся в формате
HTML, в структурированные данные, которые могут
храниться и анализироваться в центральной базе данных
или электронных таблицах. Веб-скрейпинг также связан с
веб-автоматизацией, которая имитирует поведение
человека при просмотре веб-страниц, используя
программное обеспечение.
48
*(также называют Web harvesting или Web data extraction)
49.
4950.
5051.
5152.
34
2
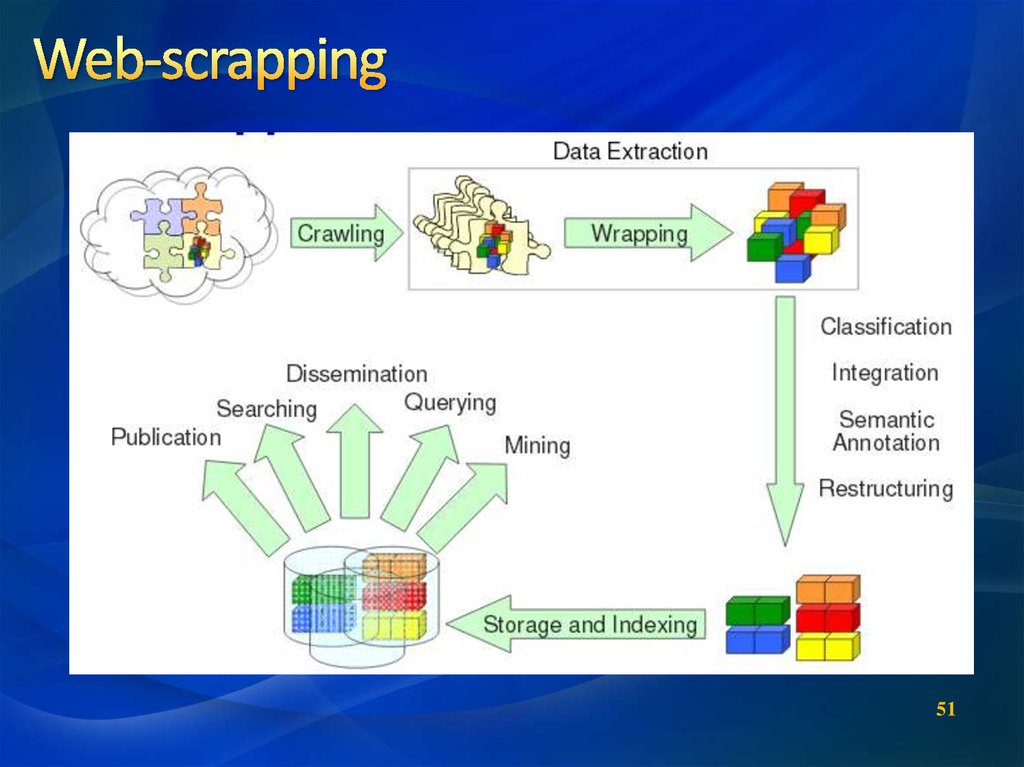
1
1. Connect : Соединение с
удаленным сайтом через
HTTP или FTP.
2. Extract : Извлечь
информацию с webсайта
3. Process : Выделить
важные данные из
ресурса и конвертировать в нужный формат
4. Save : Сохранить данные
в желаемом формате.
52
*(также называют Web harvesting или Web data extraction)
53.
Извлеченные с помощью веб-скрейпинга данные могутиспользоваться для выполнения следующих задач:
онлайн сравнение цен;
считывание контактной информации;
мониторинг данных о чем угодно (погоде, котировках …);
обнаружение изменения веб-сайта;
проведение научного исследования;
создание веб-коллажей;
интеграция веб-данных.
Учреждения и организации не всегда свою информацию
формируют в правильно структурированные и
отформатированные базы данных.
Веб-скрейпинг позволяет собирать в автоматическом
режиме свободно доступные данные практически любого
вида в онлайн формате.
53
54.
Инструменты и средстваПО для Web scraping
Описание
Скачать и проанализировать
нужный контент. Часто
требуется глубокое знание
технологии.
Пример
Visual Web Ripper and many
others.
Облачные сервисы (иногда
совместно с десктопными
приложениями)
Самообслуживание - никакой
необходимости загрузки нет,
но необходимо
Import.io, Mozenda, Kimonolab
взаимодействие с
поставщиком услуг.
Данные как сервис:
Data as a service (DaaS)
Служба делает все scrapeработы, но зачастую только
после подписки
Плагины для браузеров
По сути самообслуживание –
OutwitHub
самостоятельный сбор и
загрузка данных
Небольшие scrapingкомпании/Фрилансеры
Консалтинговые компании,
Огромное множество, например
которые выполняют от малых http://webдо средних scrape-проектов
harvest.sourceforge.net/
54
ScrapeHero, Import.io for
Enterprise, webRobots.io
55.
Существующие веб-скрейпинг компоненты работают поместу назначения, узконаправленно, зачастую только
относительно того веб-сайта для которого были написаны,
вследствие чего требуют больших человеческих усилий для
автоматизации систем преобразующих целые веб-сайты в
структурированную информацию.
В последнее время компании-разработчики создали вебскрейпинг системы имитации «человеческого» подхода к
просмотру веб-страницы и автоматического извлечения
полезной информации, основанные на использовании
DOM-парсинга, компьютерного зрения и обработки
естественного языка.
55
56.
На данный момент имеется несколько решенийдля веб-скрейпинга.
Некоторые из них преобразуют формат HTML в
другие форматы, такие как JSON, XLS, что
упрощает извлечение желаемого контента.
Другие решения читают непосредственно HTMLкод и позволяют пользователю определить
контент как функцию HTML-иерархии, в которой
размечены данные. К этой категории относится,
в частности, решение Nokogiri, которое
поддерживает парсинг HTML-документов и XMLдокументов средствами языка Ruby.
56
57.
Имеется еще два инструмента с открытымисходным кодом для веб-скрейпинга: pjscrape
для JavaScript и Beautiful Soup для Python.
Инструмент pjscrape базируется на использовании
командной строки и способен проанализировать
полностью отображенную страницу, включая
JavaScript-контент.
Инструмент Beautiful Soup прозрачно интегрируется в
среды Python 2 и Python 3.
Можно найти также примеры с использованием
языка R.
57
58. Классификация методов [8]
Un-labeled TrainingWeb Pages
Test Page
Wrapper
Induction
System
Wrapper
Extracted Data
58
59. Классификация методов [8]
Manual | Supervised | Semi-supervised | Un-supervisedUn-labeled Training
Web Pages
Test Page
Wrapper
Induction
System
Wrapper
Extracted Data
Manual
59
60. Классификация методов [8]
Manual | Supervised | Semi-supervised | Un-supervisedUn-labeled Training
Web Pages
Test Page
Labeled Web
Pages
Supervised
Wrapper
Induction
System
Wrapper
Extracted Data
60
61. Классификация методов [8]
Manual | Supervised | Semi-supervised | Un-supervisedUn-labeled Training
Web Pages
Semi-supervised
Test Page
Wrapper
Induction
System
Wrapper
Extracted Data
61
62. Классификация методов [8]
Manual | Supervised | Semi-supervised | Un-supervisedUn-labeled Training
Web Pages
Test Page
Wrapper
Induction
System
Wrapper
Extracted Data
Unsupervised
62
63. Существующие подходы
ManualSupervised
Semi-supervised
Unsupervised
TSIMMIS
WIEN
IEPAD
RoadRunner
[Hammer1997]
[Kushmerick1997]
[Chang2001]
[Crescenzi2001]
OLERA
DeLa
Minerva [Crescenzi1998] SRV
[Freitag1998]
WebQOL
RAPIER
[Arocena1998]
[Califf1998]
XWRAP
NoDoSe
[Liu2000]
[Adelberg1998]
W4F
SoftMealy
[Saiiuguet2001]
[Hsu1998]
WHISK
[Soderland1999]
STALKER
[Muslea1999]
DEByE
[Laender2002]
[Chang2004]
Thresher
[Hogue2005]
IDE
[Zhai2005]
[Wang2002]
EXALG
[Arasu2003]
DEPTA
[Znai2005]
NET
[Zhai2005]
IEKA
[Wong2007]
ViDE
[Liu2010]
SinglePage
63
64.
Используя любой из приведенных либонайденных вами способов извлечения
информации с web страниц, разработать
программу и продемонстрировать результат ее
работы.
Для примеров воспользуйтесь приведенными
ниже ресурсами.
По данной работе необходимо представить
подробный отчет с кодом программы и
результатом выполнения.
Срок исполнения: до 20 мая
64
65. Группа «Manual»: Инструменты
http://web-harvest.sourceforge.net/65
66. WebHarvest: Easy Web Scraping from Java
http://web-harvest.sourceforge.net/http://scrapy.org/
67
67. Manual. Инструменты
http://www.visualwebripper.com/http://www.lixto.com/
http://www.denodo.com
http://digitalcommons.wayne.edu/cgi/viewcontent.cgi?article=1192&context=oa_
dissertations
Ahmed, Emdad, "Post Processing Wrapper Generated Tables For Labeling
Anonymous Datasets" (2011). Wayne State University Dissertations.
68 Paper 193.
68. Группы «Supervised» и «Semi-supervised» Инструменты
1.2.
3.
4.
5.
6.
7.
8.
Анализ данных и процессов: учеб. пособие / А. А. Барсегян, М. С.
Куприянов, И. И. Холод, М. Д. Тесс, С. И. Елизаров. —3-е изд.,
перераб. и доп. — СПб.: БХВ-Петербург, 2009. —512 с.: ил.
Инструменты анализа Web. Л.Черняк. «Открытые системы», № 06,
2014
Web Page Scraping using Java, ресурс: http://halfwit4u.blogspot.ru/2011/01/web-scraping-using-java-api.html
Web Page Scraping with Java, ресурс:
https://www.packtpub.com/books/content/creating-sample-web-scraper
Jaunt Java Web Scraping & JSON Querying , ресурс: jaunt-api.com
Web scraping с Node.js, ресурс:
http://www.webdesignmagazine.ru/internet-technology/other/webscraping-s-node-js/
Web-scraping средствами R, примеры. Ресурс:
kek.ksu.ru/EOS/WM/WebScraping.docx
Chang, C.-H.,Kayed, M.,Girgis, M. R.,and Shaalan, K. F. 2006. A survey of web
information extraction systems. IEEE Trans. on Knowl. and Data Eng. 18,10,
1411-1428.
69