















")





























































































")


























")



































")



 - это техника, благодаря которой компилятор имеет возможность встроить (скопировать) код функции напрямую")



































")













 – получение доступа к переменной, на которую ссылается указатель")
















![Результат действия выражения * (intarray + j) — тот же, что и выражения intarray[j]](https://cf2.ppt-online.org/files2/slide/b/btpXUA180KavJOeQZzGTojg39id5CIhlxkHuYN/slide-255.jpg "Результат действия выражения * (intarray + j) — тот же, что и выражения intarray[j]")



 Программирование
ПрограммированиеПохожие презентации:










Процедурное программирование на языке C++
1.
Процедурное программированиена языке C++
Виталий Полянский,
преподаватель кафедры
«Разработка программного обеспечения»
Одесского филиала Компьютерной Академии ШАГ
2.
Алгоритм – последовательностьдействий, направленных на
достижение конкретного результата
3.
Программа – последовательностькоманд (инструкций), выполняемых
процессором и описывающих алгоритм
на языке программирования
4.
Данные – информация, котораяобрабатывается в процессе
выполнения программы
5.
Машинный код6.
Ассемблерный код7.
Код на языке С8.
Современные языки программирования9. Основные преимущества языков низкого уровня
• Прямой доступ к аппаратным ресурсам• Малый размер исполняемого файла
• Высокая скорость выполнения
10. Основной недостаток языков низкого уровня – сложность программирования из-за огромных размеров исходного кода
11. Главное преимущество языков высокого уровня – быстрота разработки сложных программных продуктов
12. Основные недостатки языков высокого уровня
• Ограниченный доступ к аппаратным ресурсам• Большой размер исполняемого файла
• Сравнительно невысокая скорость выполнения
13. Основные этапы разработки программы
• Постановка задачи• Проектирование
• Кодирование
14.
На этапе постановки задачипрограммист выясняет у заказчика
требования к программе
15.
На этапе проектированияпрограммист выбирает алгоритм
для написания программы
16.
На этапе кодирования программистпереводит алгоритм на какой-либо
язык программирования
17. Этапы создания исполняемого файла (.exe)
18.
Препроцессор включает в исходныйтекст программы заголовочные файлы,
содержащие описания используемых
элементов
19.
Компилятор выявляет синтаксическиеошибки и, в случае их отсутствия,
строит объектный модуль (.obj)
20.
Компоновщик формируетисполняемый модуль программы
(.exe) из объектных модулей (.obj) и
библиотечных файлов (.lib)
21. Литералы
• Строковый• Символьный
• Целочисленный
• Вещественный
• Логический
22.
Строковый литерал –последовательность символов,
заключенная в двойные кавычки
“The C Programming Language”
23.
Символьный литерал – одиночныйсимвол, заключенный в одинарные
кавычки
‘!’
‘A’
‘8’
24.
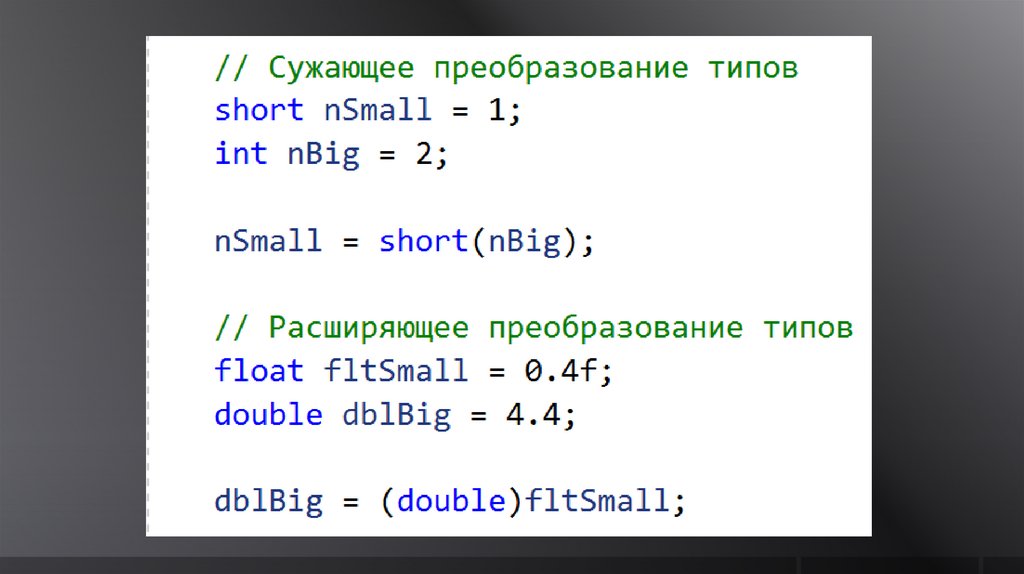
Целочисленный литерал – любоеположительное или отрицательное
целое число
-15
100
OxFF
25.
Вещественный литерал – дробноечисло, представленное в форме с
десятичной точкой либо в
экспоненциальной форме
-5.7
5e10
11e-3
26. Логический литерал
• true (истина)• false (ложь)
27.
Понятие переменной28.
Переменная –именованная область оперативной
памяти, предназначенная для хранения
изменяемого значения указанного типа
29. Типы данных
• Целочисленный• Символьный
• Вещественный
• Логический
30. Целочисленные типы
• short (2 байта)-32768 … 32767
• unsigned short (2 байта)
0 … 65535
• int (4 байта – зависит от разрядности
платформы и компилятора)
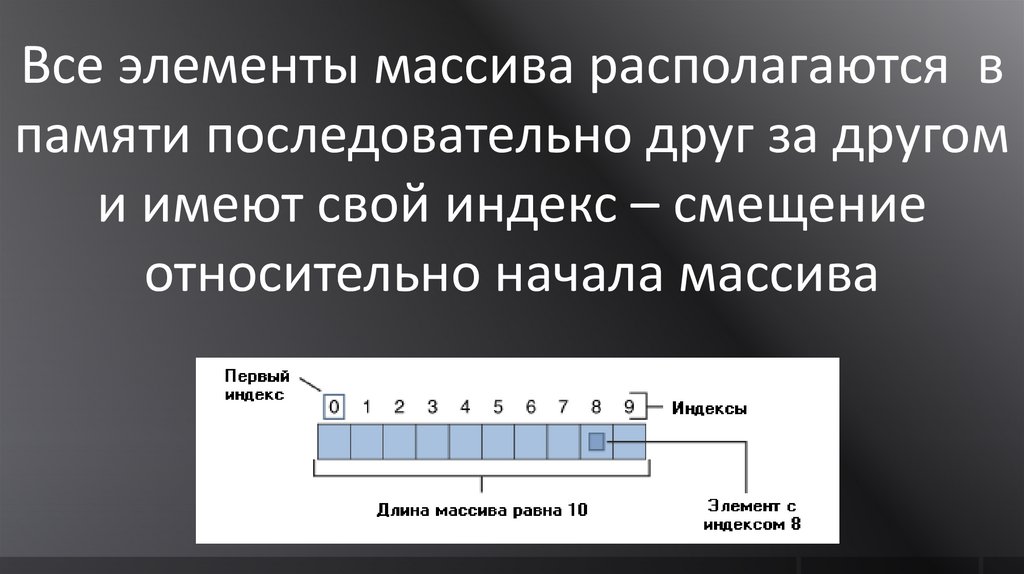
-2 147 483 648 … 2 147 483 647
31. Целочисленные типы
• unsigned int (4 байта – зависит отархитектуры платформы и компилятора)
0 … 4 294 967 295
• long (4 байта)
-2 147 483 648 … 2 147 483 647
• unsigned long (4 байта)
0 … 4 294 967 295
32. Целочисленные типы
• long long (8 байт)-9 223 372 036 854 775 808 …
9 223 372 036 854 775 807
• unsigned long long (8 байт)
0 … 18 446 744 073 709 551 615
33.
Тип данных int строго не определёнстандартом языка и должен иметь
«естественный» размер с учётом
архитектуры (разрядности) системы
34.
Тип данных int не должен бытьменьше short (2 байта) и не
должен превышать long (4 байта)
35. Символьные типы
• char(1 байт)-128 … 127
• unsigned char (1 байт)
0 … 255
36.
Тип данных char представляет одинсимвол в кодировке ASCII
37.
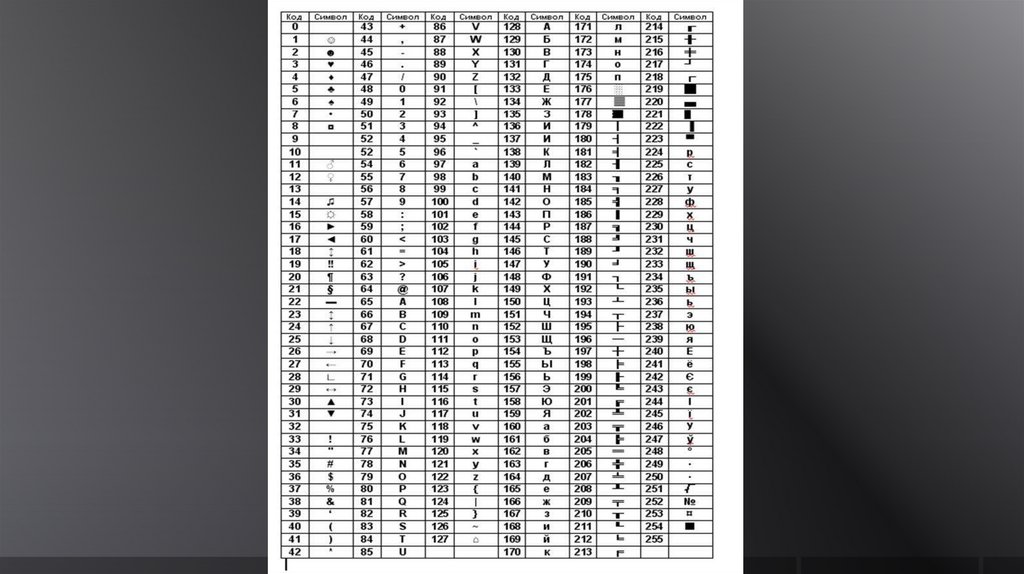
ASCII (American standard codefor information interchange) — название
таблицы (кодировки), в которой
символам сопоставлены числовые коды
38.
39.
Например, символу ‘D’соответствует ASCII-код 68, а
символу ‘d’ – ASCII-код 100
40. Вещественные типы
• float (4 байта)3.4E-38 … 3.4E+38
• double (8 байт)
1.7E-308 … 1.7E+308
41. Логический тип
• bool (1 байт)true false
42.
Для того чтобы использовать впрограмме переменную, ее
необходимо объявить
43.
Синтаксис объявления переменных:тип_переменной имя_переменной;
44.
Имя переменной называетсяидентификатором
45. Правила именования идентификаторов:
• Имя переменной не может начинаться с цифры• Имя переменной может содержать буквы,
цифры и знак подчеркивания «_»
• Имя переменной не может являться ключевым
или служебным словом
• Имя переменной должно быть уникальным
• Имя переменной должно быть осмысленным
46.
47.
Константа –именованная область оперативной
памяти, предназначенная для хранения
постоянного значения указанного типа
48.
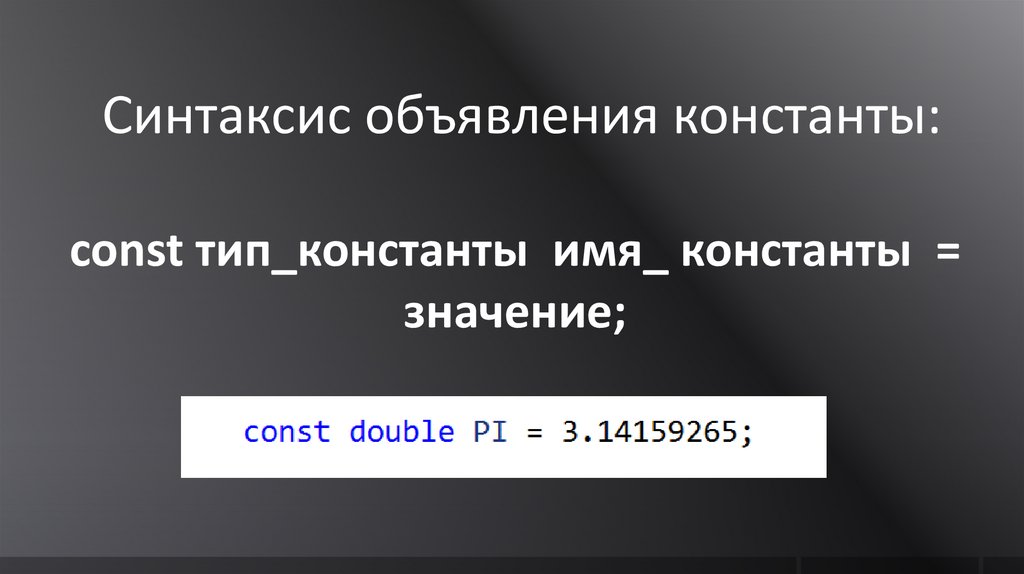
Синтаксис объявления константы:const тип_константы имя_ константы =
значение;
49.
Литералы, рассмотренные ранее,представляют собой константы,
непосредственно включаемые в текст
программы
50.
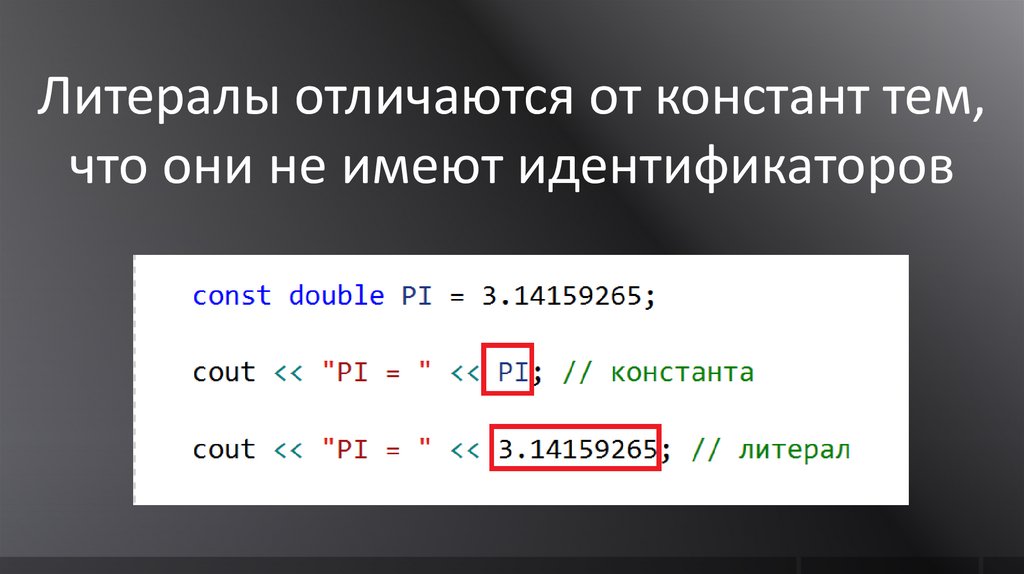
Литералы отличаются от констант тем,что они не имеют идентификаторов
51.
Ввод данных52.
Синтаксис ввода данных:cin >> имя_переменной;
53.
54.
Понятие оператора55.
Оператор – это конструкция языкапрограммирования, которая выполняет
определённое действие над
аргументами (операндами)
56.
Операнд - это аргумент оператора, тоесть то значение, над которым оператор
выполняет действие
57. В зависимости от количества операндов операторы бывают:
• Унарные• Бинарные
• Тернарные
58.
Оператор присваивания59.
Синтаксис оператора присваивания:имя_переменной = выражение;
60.
Выражение –конструкция, состоящая из операндов,
объединенных знаками операций
61.
62.
Множественные присваивания присваивания одного и того жезначения нескольким переменным
одновременно
63. Арифметические операторы
• Оператор сложения (бинарный)• Оператор вычитания (бинарный)
• Оператор умножения (бинарный)
• Оператор деления (бинарный)
64. Арифметические операторы
• Оператор остаток от деления (бинарный)• Оператор минус (унарный)
• Оператор инкремент (унарный)
• Оператор декремент (унарный)
65. Сокращённые формы операторов: += -= *= /= %=
66.
Приведение типов67.
Выражение –конструкция, состоящая из операндов,
объединенных знаками операций
68.
Результат вычисления выраженияхарактеризуется значением и типом
69.
В выражение могут входить операндыразличных типов
70.
Если операнды имеютодинаковый тип, то результат
операции будет иметь тот же тип
71.
Если операнды разного типа, передвычислениями выполняются
преобразования типов по
определенным правилам
72.
Эти правила обеспечиваютпреобразование более коротких типов
в более длинные для сохранения
значимости и точности
73.
74.
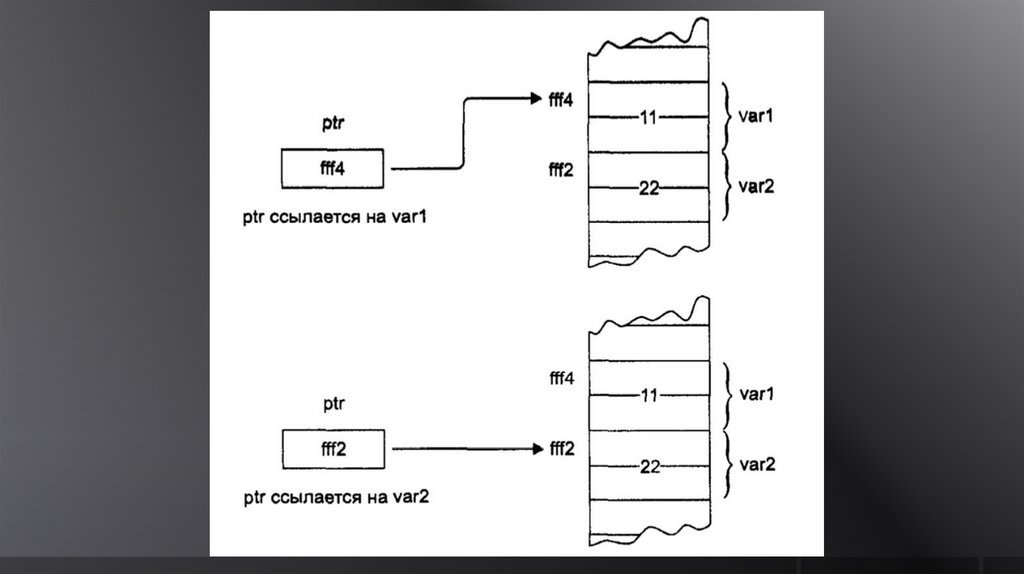
75.
Перед вычислением выражениясмешанного типа происходит неявное
(автоматическое) расширяющее
преобразование операндов
76.
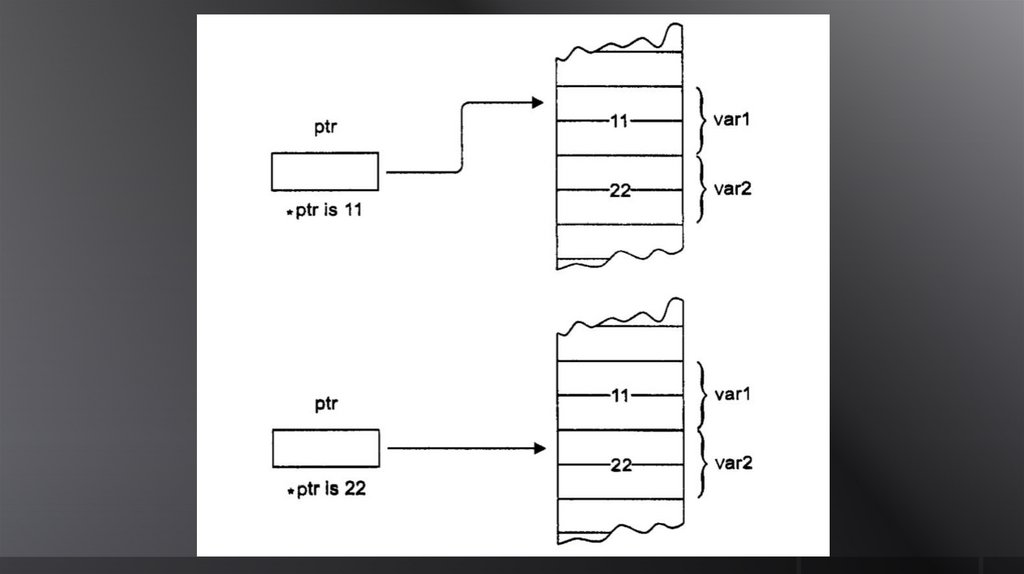
Неявное расширяющеепреобразование типа может также
происходить при присваивании
переменной результата выражения
77.
Неявное преобразование типа приприсваивании переменной результата
выражения может быть сужающим
78. Сужающие преобразования бывают:
• с потерей точности (данных)• с переполнением разрядной сетки
• с изменением интерпретации
внутреннего представления данных
79.
Приведение типов может быть явным80.
Явное приведение типов указываетсяпрограммистом в коде программы
81.
Синтаксис явного приведения типа:(тип) выражение;
82.
83.
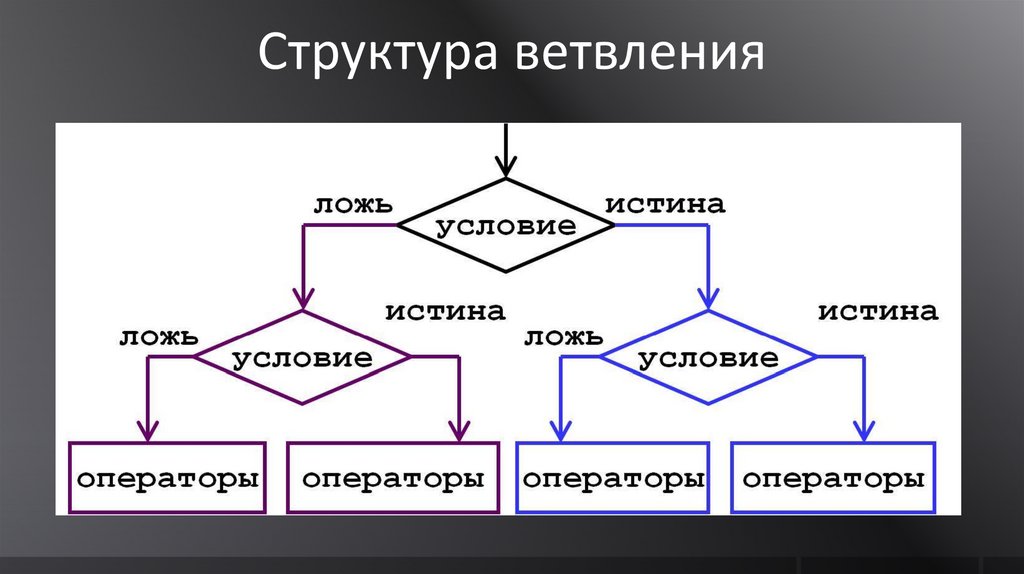
Структура ветвления84. Операторы отношения
• == (равно)• != (не равно)
• > (больше)
• >= (больше либо равно)
• < (меньше)
• <= (меньше либо равно)
85.
Операторы отношенияпредназначены для составления
логических выражений
86.
Результат вычисления любогологического выражения –
ИСТИНА или ЛОЖЬ
87.
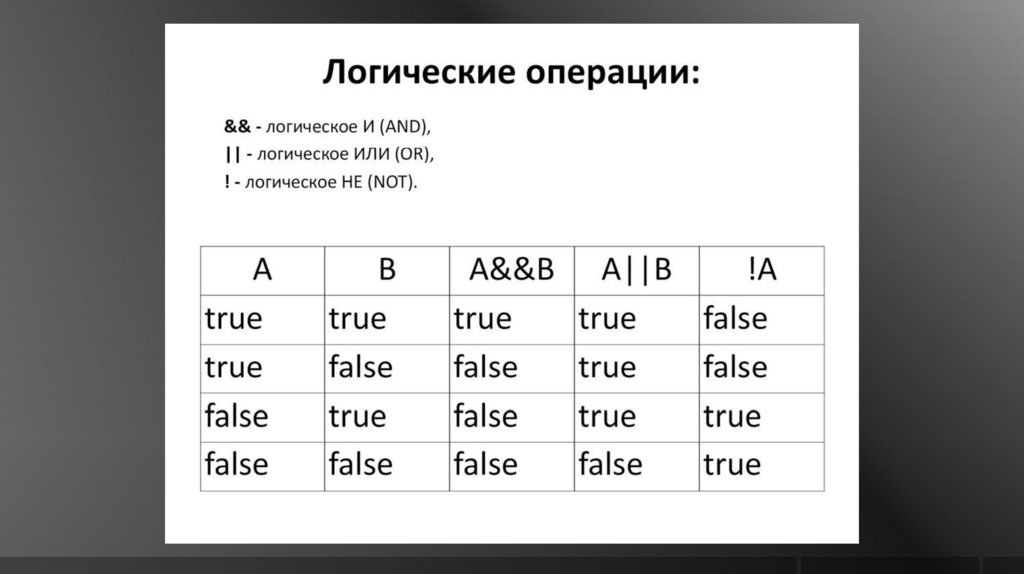
88. Логические операторы
• && (логическое умножение, логическое И)• || (логическое сложение, логическое ИЛИ)
• ! (логическое отрицание, логическое НЕ)
89.
Логические операторы предназначеныдля объединения логических
выражений
90.
91. Логическое «ИЛИ»
5 == 5 || 5 == 9// true, потому что первое выражение true
5 > 3 || 5 > 10
// true, потому что первое выражение true
5 > 8 || 5 < 10
// true, потому что второе выражение true
5 < 8 || 5 > 2
// true, потому что оба выражения true
5 > 8 || 5 < 2
// false, потому что оба выражения false
92. Логическое «И»
5 == 5 && 4 == 4// true, потому что оба выражения true
5 == 3 && 4 == 4
// false, потому что первое выражение false
5 > 3 && 5 > 10
// false, потому что второе выражение false
5 < 8 && 5 > 2
// true, потому что оба выражения true
5 > 8 && 5 < 2
// false, потому что оба выражения false
93. Логическое «НЕ»
!(10 != 10)// true, потому что выражение false
!(5 > 3)
// false, потому что выражение true
94. Оператор ветвления «if»
if (выражение){
// оператор_1;
}
else
{
// оператор_2;
}
95. Оператор ветвления «if»
if (выражение){
// оператор;
}
96. Оператор ветвления «if»
if (выражение_1){ // оператор_1; }
else if (выражение_2)
{ // оператор_2; }
else
{ // оператор_3; }
97.
Таблица приоритетов операций98.
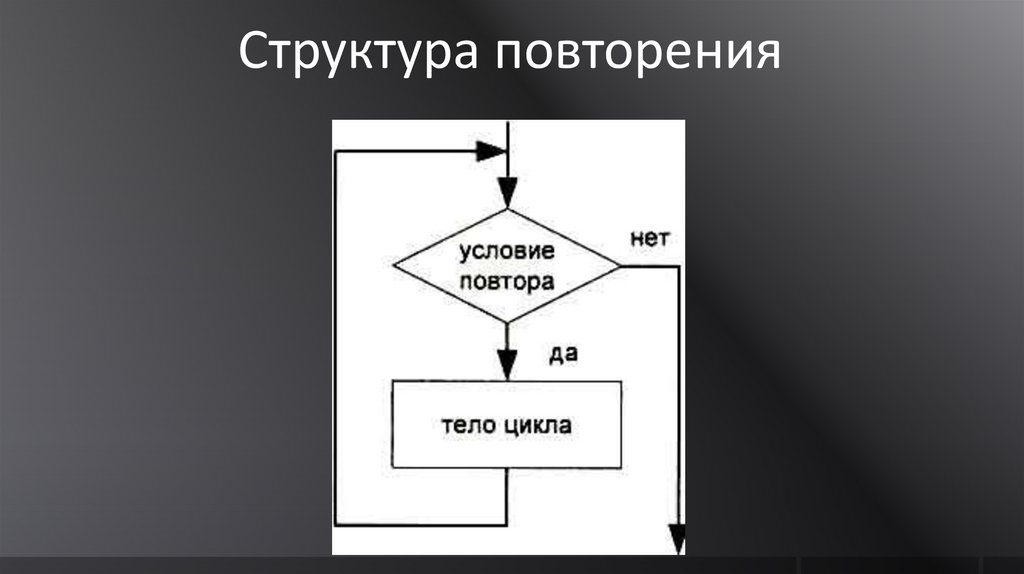
Структура повторения99.
Структура повторения позволяетпрограммисту определить действие,
которое должно повторяться, пока
некоторое условие остается истинным
100.
В языке программирования С++структура повторения реализуется с
помощью оператора цикла
101. Виды циклов
• Цикл с предусловием (while)• Цикл с постусловием (do while)
• Параметрический цикл (for)
102. Цикл с предусловием while
while (выражение){
// оператор
// или группа
// операторов
}
103. Цикл с постусловием do while
do{
// оператор
// или группа
// операторов
}
while (выражение);
104. Параметрический цикл for
105.
Массивы106.
Массив –это совокупность переменных,
объединенных под общим именем и
имеющих один и тот же тип данных
107.
Каждая переменная в массивеявляется самостоятельной единицей и
называется элементом массива
108.
Все элементы массива располагаются впамяти последовательно друг за другом
и имеют свой индекс – смещение
относительно начала массива
109. Объявление массива
Синтаксис объявления массива:тип_данных имя_массива[количество_элементов];
int numbers[4];
const int nSize = 6;
double arr[nSize];
110. Инициализация массива
тип_данных имя_массива[количество элементов] ={значение1, значение2, ... значение n};
111. Количество элементов массива можно не указывать. Размер массива определяется исходя из числа элементов в списке инициализации.
int arrayInit[] = { 2, 33, 4 }; // массив из трех элементов112. Если значений в списке инициализации меньше чем количество элементов массива, то оставшиеся значения автоматически заполняются
нулямиint arr[6] = { 1, 2, 3 };
// такая запись эквивалентна записи:
int arr[6] = { 1, 2, 3, 0, 0, 0 };
113. Если значений в списке инициализации больше чем количество элементов массива, то происходит ошибка на этапе компиляции
// int arr[2] = {1, 2, 3}; // Ошибка на этапе компиляции114. Расположение массива в памяти
Формула, согласно которой производится позиционированиепо массиву:
базовый адрес + размер базового типа * индекс;
115. Операция индексирования массива
Операция индексирования массиваЗапись значения в массив:
имя_массива[индекс_элемента] = значение;
Получение значения из массива:
cout << имя_массива[индекс_элемента];
const int nArraySize = 3;
int ar[nArraySize];
ar[1] = 7;
cout << ar[1] << endl;
116. Большинство операций с массивами разумно проводить с помощью циклов, по очереди перебирая элементы
117. Циклическая обработка массива
118. Линейный поиск элемента в массиве
119. Бинарный поиск элемента в массиве
120. Сортировка массива прямым обменом (метод «пузырька»)
121. Сортировка массива прямыми вставками
122. Двумерный массив, как частный случай многомерного массива
123. Двумерный массив представляет собой совокупность строк и столбцов, на пересечении которых находится конкретное значение
124. Двумерный массив располагается в памяти построчно: сначала нулевая строка, затем первая и т.д.
125. Объявление двумерного массива
Синтаксис объявления двумерного массива:тип_данных имя_массива [число_строк][число_столбцов];
const int ROW = 3; // строки
const int COL = 4; // столбцы
int arr[ROW][COL]; // массив размером 3х4
126. Инициализация массива
• Каждая строка заключается в отдельные фигурные скобкиint arr[2][2] = { { 1, 2 }, { 7, 8 } };
• Если значение пропущено, оно будет инициализировано
нулем
int arr[3][3] = { { 7, 8 }, { 10, 3, 5 } };
• Значения указываются подряд и построчно вписываются в
массив
int arr[2][2] = { 7, 8, 10, 3 };
127. Циклическая обработка массива
128. Функции в процедурном программировании
129. Один и тот же код может встречаться в программе несколько раз
130. Например, применение алгоритмов суммирования, сортировки, определения максимального значения массива в практической задаче
могутвстречаться очень часто
131. Как следствие, увеличивается количество и затрудняется чтение программного кода
132. С увеличением объема программы становится невозможным хранить в человеческой памяти все ее детали
133. Одним из естественных вариантов борьбы со сложностью является алгоритмическая декомпозиция -разбиение задачи на подзадачи
Одним из естественных вариантовборьбы со сложностью является
алгоритмическая декомпозиция разбиение задачи на подзадачи
134.
Процедурное программирование –подход, при котором исходная задача
разбивается на подзадачи, каждая из
которых оформляется в виде функции
135. Функция – это именованная последовательность описаний и операторов, выполняющая какое-либо законченное действие
136. Функция может принимать параметры и возвращать значение
137. Определение функции
Синтаксис определения функции:<тип> <имя_функции> ([список параметров])
{
тело функции
}
138. Определение функции
139.
Область видимости переменной–это некоторая область программы,
внутри которой возможно обратиться к
переменной
140. Начало области видимости переменной совпадает с ее объявлением
141. В зависимости от места объявления различают два типа переменных: локальные и глобальные
142.
Локальная переменная –переменная, объявленная внутри
функции или блока
143. Блок - область программного кода от открывающей до соответствующей закрывающей фигурной скобки
144. Локальная переменная
145. Конец области видимости локальной переменной совпадает с закрывающей фигурной скобкой, соответствующей открывающей фигурной
скобке, послекоторой была объявлена переменная
146. Локальные переменные создаются в специальной области оперативной памяти, которая называется стеком
147. Стек функционирует по правилу LIFO (Last In First Out)
148. Локальные переменные создаются при каждом вызове функции
149. После завершения работы функции соответствующий участок стека освобождается и локальные переменные функции уничтожаются
150. Поэтому значения локальных переменных между вызовами одной и той же функции не сохраняются
151.
Глобальная переменная –переменная, объявленная вне функции
152. Глобальная переменная
153. Конец области видимости глобальной переменной в текущем файле совпадает с концом этого файла
154. Глобальные переменные создаются в специальной области оперативной памяти, которая называется сегментом данных
155. Глобальные переменные создаются до вызова функции main и по умолчанию инициализируются нулем
156. Глобальные переменные уничтожаются после окончания работы функции main
157. Значения глобальных переменных сохраняются между вызовами одной и той же функции
158. Глобальные переменные видны во всех функциях, где не объявлены локальные переменные с теми же именами
159. Поэтому очень легко их использовать для передачи данных между функциями
160. Однако использование глобальных переменных не рекомендуется, поскольку это препятствует помещению функций в библиотеки общего
пользования161. Необходимо стремится к тому, чтобы функции были максимально независимы, а их интерфейс полностью определялся прототипом функции
162. Глобальная переменная может быть перекрыта локальной переменной с таким же именем
163.
Статическая локальная переменная –переменная, объявленная внутри
функции или блока
164. Статическая локальная переменная
165. Статические локальные переменные имеют такую же область видимости, что и обычные локальные переменные
166. Статические локальные переменные создаются в сегменте данных при первом вызове функции и по умолчанию инициализируются нулем
167. Статические локальные переменные уничтожаются после окончания работы функции main
168. Значения локальных статических переменных сохраняются между вызовами одной и той же функции
169. Перегрузка функций
170.
Перегруженные функции –это функции, которые имеют
одинаковые имена, но отличаются
сигнатурой
171.
Сигнатура –это тип, количество и порядок
следования формальных параметров
функции
172. Компилятор определяет, какую именно функцию требуется вызвать, по типу фактических параметров
173. Этот процесс называется разрешением перегрузки
174. Тип возвращаемого функцией значения в разрешении не участвует
175. Пример перегрузки функций
176. В процессе разрешения перегрузки компилятор выбирает функцию с наиболее подходящими параметрами
177. Пример перегрузки функций
178. Критерий разрешения перегрузки - однозначность вызова функции
Критерий разрешения перегрузки однозначность вызова функции179. Пример перегрузки функций
180. Пример перегрузки функций
181. Перегруженные функции должны находиться в одной области видимости, иначе произойдет сокрытие аналогично одинаковым именам
переменных вовложенных блоках
182. Пример перегрузки функций
183. Встраивание (Inline – функции)
184. Как известно, при вызове функции происходит:
Помещение аргументов в стек
Передача управления функции
Возврат из функции
Освобождение стека
185. Все это вносит издержки, которые немного влияют на скорость
186. Механизм встраивания предназначен для увеличения производительности кода
187. Встраивание (inline) - это техника, благодаря которой компилятор имеет возможность встроить (скопировать) код функции напрямую
в место её вызова188. Для того, чтобы сделать функцию встраиваемой, необходимо при определении функции указать ключевое слово inline
189.
В этом случае компиляторурекомендуется не использовать
привычный вызов функции, а встроить
её код напрямую в место использования
190.
Однако встраивание являетсярекомендацией для компилятора
и срабатывает не всегда
191.
Встраивание проходит для оченьпростых функций, состоящих из
нескольких инструкций, которые
не содержат сложных конструкций
192.
Если функция содержит сложныеконструкции (циклы, if/else, switch
и т.д.), то компилятор может
проигнорировать встраивание
193.
В таком случае, inline-функция ничем небудет отличаться от обычной
194.
Шаблоны функций195.
Шаблоны используются, когданеобходимо создать функции, которые
применяют один и тот же алгоритм к
различным типам данных
196.
Шаблон функции – этообобщенное описание функции
197.
У такой функции хотя бы одинформальный параметр имеет
обобщенный тип
198.
Определение шаблона функции199.
Использование шаблона функции200.
В момент вызова функции компиляторавтоматически создает
специализированную версию функции,
где вместо параметра типа
подставляется конкретный тип данных
201.
Этот процесс называетсяинстанцированием шаблона или
созданием экземпляра шаблона
202.
Повторный вызов функции с теми жетипами параметров не спровоцирует
генерацию дополнительной копии
функции, а вызовет уже существующую
203.
Использование шаблона функции204.
Определение шаблона функции невызывает самостоятельную генерацию
кода компилятором
205.
По этой причине реализацию шаблоновфункций следует размещать в
заголовочном файле
206.
Компилятор создает код функции тольков момент ее вызова, и генерирует при
этом соответствующую версию функции
207.
Перегруженные шаблоны208.
Важно понимать, что использованиешаблонов функций не приводит к
уменьшению результирующего
объектного кода
209.
Однако экономит времяразработки программы
210.
Рекурсия211.
Рекурсивная функция–функция, которая вызывает сама себя
212. Если функция производит собственный вызов напрямую, то такая рекурсия называется прямой
213. Существует также косвенная рекурсия, когда две функции вызывают друг друга
214. Итерационный метод решения задач
215. Рекурсивный метод решения задач
216. Процесс рекурсивных вызовов
217. Для завершения вычислений каждая рекурсивная функция должна содержать хотя бы одну нерекурсивную ветвь алгоритма, которая
заканчиваетсяоператором возврата
218. Достоинством рекурсии является компактная запись
219. Недостатки рекурсии – расход времени и памяти на повторные вызовы функции и передачу ей копий параметров
220. Главный недостаток рекурсии - опасность переполнения стека
Главный недостаток рекурсии опасность переполнения стека221. Рекурсивные функции обычно применяют для работы с древовидными структурами данных
222. Адреса и указатели
223. В языке С++ используется плоская модель памяти (Flat model)
224.
225. В плоской модели код и данные используют одно и то же адресное пространство
226. Каждый байт памяти имеет свой адрес
227. У каждой переменной есть свой адрес в памяти
228.
Адрес переменной –это целочисленное значение, индекс
первого байта области памяти, которую
занимает переменная
229. Адрес переменной – это целое число, которое обозначает смещение переменной от начала памяти
230. Операция получения адреса – взятие адреса &
Операция получения адреса –взятие адреса &
231.
Указатель –это переменная, значением которой
является адрес другой переменной
232. Указатель не является самостоятельным типом, он всегда связан с каким-либо другим конкретным типом
233. Базовый тип указателя определяется типом переменной, на которую он может ссылаться
234. Инициализация указателя
235. void * - это указатель без привязки к типу, т.е. обобщенный указатель
236. Операция разыменования указателя * – косвенная адресация
237. Разыменование указателя (косвенная адресация) – получение доступа к переменной, на которую ссылается указатель
238. Изменение значения указателя
239.
240.
241. Приоритет операций & и * выше, чем приоритет всех арифметических операторов, за исключением унарного минуса
Приоритет операций & и * выше, чемприоритет всех арифметических
операторов, за исключением унарного
минуса
242. Различная интерпретация оператора *
243. Указатель на переменную и указатель на константу
244. Указатель-константа на переменную и указатель-константа на константу
245. Размер указателя
246. В соответствии со стандартом C++, размер указателя зависит от конкретной реализации компилятора и не связан напрямую с
разрядностьюиспользуемой платформы
247. Однако на большинстве современных операционных систем размер указателя соответствует разрядности адресной шины у архитектуры
этих платформ248. Ширина шины адреса определяет объём адресуемой памяти
249. Например, если ширина адресной шины составляет 32 бита, то объём памяти, который можно адресовать, составляет 2^32 байт или 4
Гбайт250. Связь массивов и указателей
251. Имя массива без указания индексации - это адрес начала массива в оперативной памяти, т.е. адрес нулевого элемента массива
Имя массива без указания индексации это адрес начала массива воперативной памяти, т.е. адрес
нулевого элемента массива
252. Использование операции индексирования для обращения к элементам массива
253. Расположение массива в памяти
254. Расположение массива в памяти
Формула, согласно которой производится позиционированиепо массиву:
базовый адрес + размер базового типа * индекс;