













 Интернет
Интернет Информатика
ИнформатикаПохожие презентации:










Информационно-поисковая система
1. Информационно-поисковая система
2. Классификация информационно-поисковых систем
Классификация информационнопоисковых систем3.
4. ИНФОРМАЦИОННО-ПОИСКОВАЯ СИСТЕМА
• Web server (веб-сервер) – сервер поисковой машины, которыйосуществляет взаимодействие между пользователем и остальными
компонентами системы.
• Spider (паук)- программа написанная по принципу браузера,
предназначена для скачивания веб-страниц. Браузер предназначен
для визуального использования страниц, а паук работает с HTML
кодом напрямую. Чтобы посмотреть "сырой" исходник нажмите в
меню браузера: Вид- Просмотр HTML кода
• Crawler («путешествующий» паук) – программа, которая
автоматически уходит по всем внешним ссылкам страницы. Ее задача
- поиск неизвестных (или измененных) документов и в расстановке
приоритетов, куда дальше должен идти Spider.
• Indexer (индексатор) - программа-анализатор скаченных пауками вебстраниц. Она "разбирает" на части скачанную страницу и анализирует
ее элементы, такие как текст, служебные html-теги, заголовки,
особенности стилистики и структурные формы
5. Индексный механизм
• 1. Получаем документ для индексирования;• 2. Регистрируем его в таблице document, запоминаем полученный его
уникальный id и будем его называть doc_id;
• 3. Разбиваем документ на отдельные слова;
• 4. Узнаем уникальные id этих слов из таблицы dictionary и будем их
называть dict_id;
• 5. Потом заносим записи с нашим одним doc_id и разными dict_id
(для каждого слова в документе) в таблицу match.
• Database (база данных) – хранилище для скачанных и обработанных
страниц - общая база данных поисковой машины.
• Search engine results engine (система выдачи результатов) – извлекает
результаты поиска из базы данных поисковой системы.
6.
7. Процесс поиска текстовой информации включает в себя следующие этапы:
Процесс поиска текстовой информации включает в себяследующие этапы
:
1. формализация пользователем поискового запроса;
2. предварительный отбор тестовых документов,
содержащих формальные признаки наличия
интересующей информации;
3. анализ отобранных документов (лексический,
морфологический, синтаксический, семантический);
4. оценка соответствия смыслового содержания
найденной информации требованиям поискового
запроса.
8. Реализация полного лингвистического анализа текстовой информации предполагает решение следующих задач:
9.
Лексический анализЗаключатся в разборе текстовой информации на отдельные абзацы, предложения, слова, определении
национального языка изложения, типа предложения, выявлении типа лексических выражений (бранных, жаргонных
слов) и т.д. Он не представляет существенной сложности для реализации.
Морфологический анализ
Сводится к автоматическому распознаванию частей речи каждого слова текста (каждому слову ставится в
соответствие лексико-грамматический класс). Данная задача может быть выполнена для русского языка практически
со стопроцентной точностью благодаря его развитой морфологии. В английском языке алгоритм, присваивающий
каждому слову в тексте наиболее вероятный для данного слова лексико-грамматический класс (синтаксическую часть
речи), работает с точностью около 90 %, что обусловлено лексической многозначностью английского языка.
Синтаксический анализ
Заключатся в автоматическом выделении семантических элементов предложения - именных групп,
терминологических целых, предикативных основ. Это позволяет повысить интеллектуальность процесса обработки
тестовой информации на основе обеспечения работы с более обобщенными семантическими элементами.
Семантический анализ
Заключатся в определении информативности текстовой информации и выделении информационно-логической
основы текста. Проведение автоматизированного семантического анализа текста предполагает решение задачи
выявления и оценки смыслового содержания текста. Данная задача является трудно формализуемой вследствие
необходимости создания совершенного аппарата экспертной оценки качества информации.
Реализация семантического анализа текстовой информации предполагает обязательное использование
экспертных систем, систем искусственного интеллекта для выявления смыслового содержания информации. В
настоящее время отсутствуют сложившиеся подходы к реализации задачи семантического анализа текстовой
информации, что во многом обусловлено исключительной сложностью проблемы и недостаточно полной проработкой
научного направления создания систем искусственного интеллекта. Поэтому существующие информационные
технологии не обеспечивают эффективной реализации поисковых систем.
10. Категории поиска
по ключевым словам;с булевой логикой объединения слов;
по словосочетаниям;
с учетом расстояния между словами;
с учетом регистра;
по семантике (концептуальный);
по шаблону (подобию);
по полям документа.
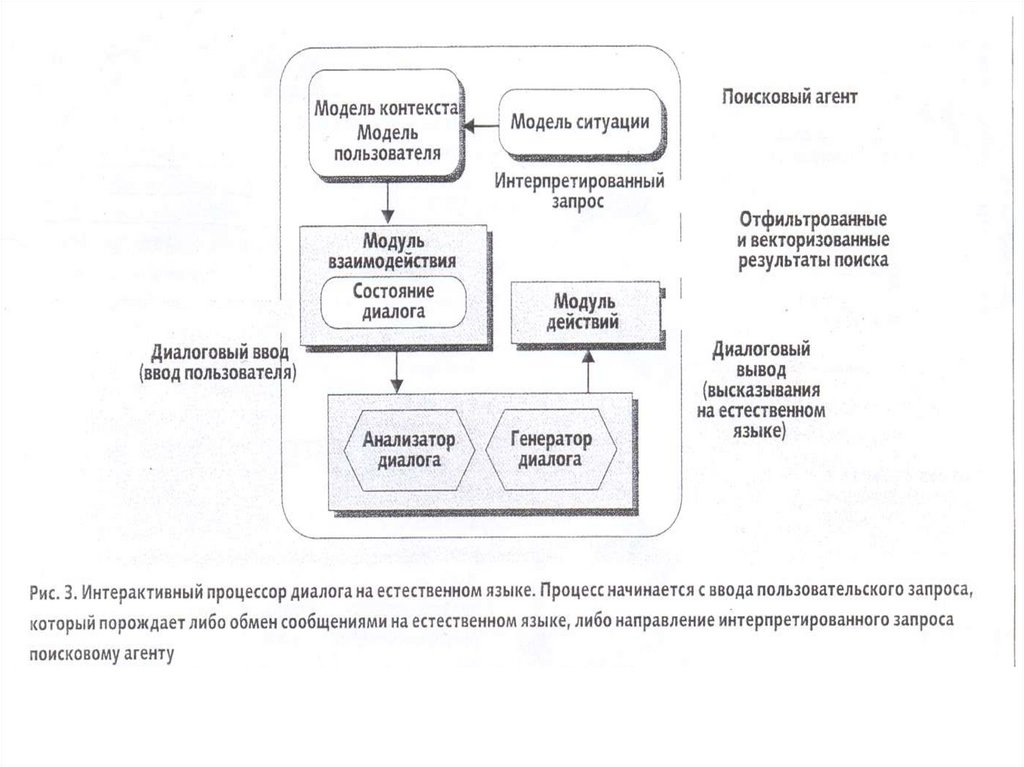
11. Структурная схема лингвистического процессора
12. Реализация указанных функциональных возможностей достигается за счет:
углубленноголексического
анализа
текстовой
информации,
обеспечивающего подготовительную нормализацию обрабатываемого теста;
уникальной структуры морфологического словаря, включающего все
морфологические и семантические характеристики слов, а также слова синонимы и тематически связанные слова;
детального морфологического анализа, обеспечивающего определение
частей речи с учетом семантики запроса пользователя и обрабатываемой
текстовой информации;
поиска текстовой информации по синонимам и тематически связанным
словам;
автоматизированного синтаксического анализа членов предложения и связей
между ними;
отбора текстовой информации на основе семантического анализа ее
соответствия запросу пользователя;
автоматической оценки релевантности предложений текстов запросу
пользователя с обеспечением синтеза семантически полного ответа
поисковой системы.
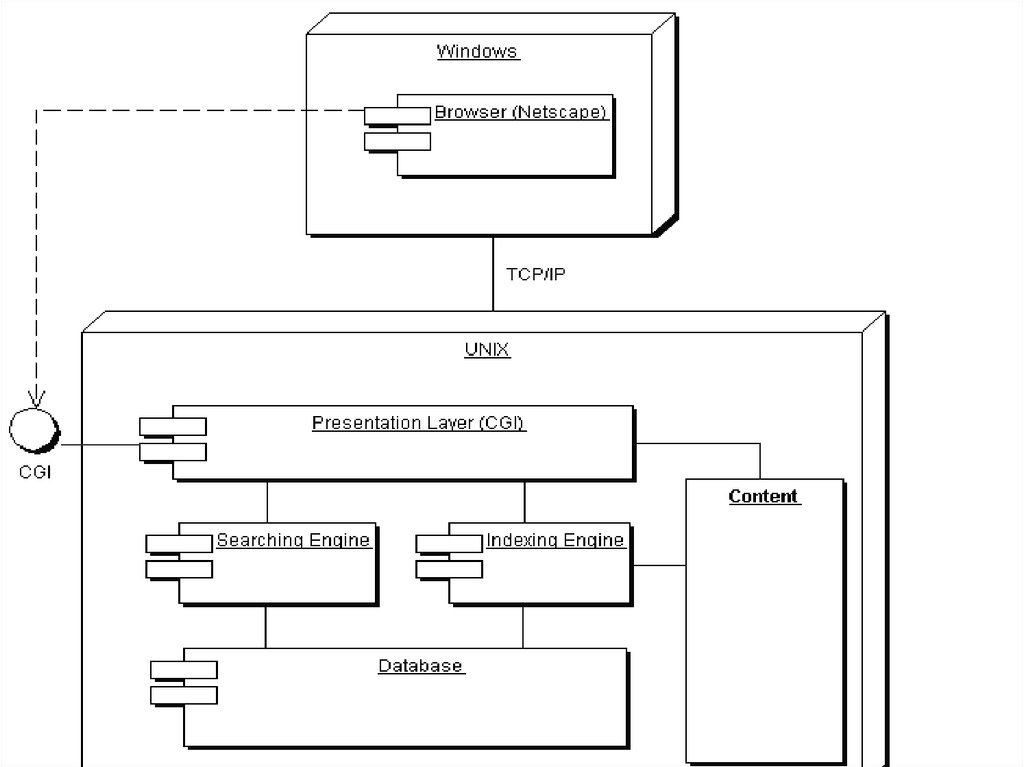
13. Пример структурной схемы интеллектуальной информационно-поисковой машины проекта Stocona Search
14. Новые качества интеллектуальной информационно-поисковой системы
1. Обработка запроса пользователя, представленного на естественном языке.2. Реализация диалога интеллектуальной поисковой системы с пользователем в
ходе уточнения введенного им запроса и формирования ответа системы.
3. Возможность автоматического перевода запроса пользователя с
естественного языка на формализованные языки запросов существующих
поисковых систем.
4. Обеспечение поиска с учетом смыслового содержания многозначных слов.
5. Реализация поиска с учетом синонимов и тематически связанных слов.
6. Повышение релевантности результатов поиска запросу пользователя на
основе учета семантики запроса и синтеза семантически полного ответа
поисковой системы.
7. Обеспечение автоматической интегральной оценки семантического смысла
проиндексированной текстовой информации.